
Vector Databases
Vector Databases – Part 4 – Vector Indexes
In this post on Vector Databases, I’ll explore some of the commonly used indexing techniques available in Databases. I’ll also explore the Vector Indexes available in Oracle 23c. Be sure to check that section towards the end of the post, where I’ll also include links to other articles in this series.
As with most data in a Databases, indexes are used for fast access to data. They create an organised structure (typically B+ tree) for storing the location of certain values within a table. When searching for data, if an index exists on that data, the index will be used for matching and the location of the records is used to quickly retrieve the data.
Similarly, for Vector searches, we need some way to search through thousands or millions of vectors to find those that best match our search criteria (vector search). For vector search, there are many more calculations to perform. We want to avoid a MxN search space.

Given the nature of Vectors and the the type of search performed on these, databases need to have different types of indexes. Common Vector Index types include Hash-base, Tree-based, Graph-base and Inverted-file. Let’s have a look at each of these.

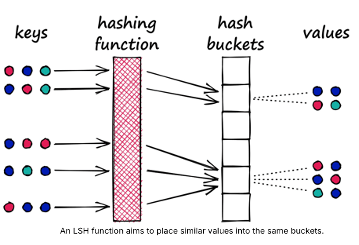
Hash-based Vector Indexes
Locality-Sensitive Hashing (LSH) uses hash functions to bucket similar vectors into a hash table. The query vectors are also hashed using the same hash function and it is compared with the other vectors already present in the table. This method is much faster than doing an exhaustive search across the entire dataset because there are fewer vectors in each hash table than in the whole vector space. While this technique is quite fast, the downside is that it is not very accurate. LSH is an approximate method, so a better hash function will result in a better approximation, but the result will not be the exact answer.
Tree-based Vector Indexes
Tree-based indexing allows for fast searches by using a data structure such as a binary tree. The tree gets created in a way that similar vectors are grouped in the same subtree. Approximate Nearest Neighbour (ANN) uses a forest of binary trees to perform approximate nearest neighbors search. ANN performs well with high-dimension data where doing an exact nearest neighbors search can be expensive. The downside of using this method is that it can take a significant amount of time to build the index. Whenever a new data point is received, the indices cannot be restructured on the fly. The entire index has to be rebuilt from scratch.
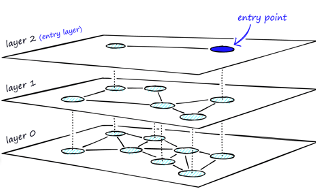
Graph-based Vector Indexes
Similar to tree-based indexing, graph-based indexing groups similar data points by connecting them with an edge. Graph-based indexing is useful when trying to search for vectors in a high-dimensional space. Hierarchical Navigable Small Worlds (HNSW) creates a layered graph with the topmost layer containing the fewest points and the bottom layer containing the most points. When an input query comes in, the topmost layer is searched via ANN. The graph is traversed downward layer by layer. At each layer, the ANN algorithm is run to find the closest point to the input query. Once the bottom layer is hit, the nearest point to the input query is returned. Graph-based indexing is very efficient because it allows one to search through a high-dimensional space by narrowing down the location at each layer. However, re-indexing can be challenging because the entire graph may need to be recreated
Inverted-FIle Vector Indexes
IVF (InVerted File) narrows the search space by partitioning the dataset and creating a centroid(random point) for each partition. The centroids get updated via the K-Means algorithm. Once the index is populated, the ANN algorithm finds the nearest centroid to the input query and only searches through that partition. Although IVF is efficient at searching for similar points once the index is created, the process of creating the partitions and centroids can be quite slow.

Oracle 23ai comes with two main types of indexes for Vectors. These are:
In-Memory – Neighbor Graph Vector Index
Hierarchical Navigable Small World (HNSW) is the only type of In-Memory Neighbor Graph vector index supported. With Navigable Small World (NSW), the idea is to build a proximity graph where each vector in the graph connects to several others based on three characteristics:
- The distance between vectors
- The maximum number of closest vector candidates considered at each step of the search during insertion (EFCONSTRUCTION)
- Within the maximum number of connections (NEIGHBORS) permitted per vector
Navigable Small World (NSW) graph traversal for vector search begins with a predefined entry point in the graph, accessing a cluster of closely related vectors. The search algorithm employs two key lists:
- Candidates, a dynamically updated list of vectors that we encounter while traversing the graph,
- and Results, which contains the vectors closest to the query vector found thus far.
As the search progresses, the algorithm navigates through the graph, continually refining the Candidates by exploring and evaluating vectors that might be closer than those in the Results. The process concludes once there are no vectors in the Candidates closer than the farthest in the Results, indicating

Neighbor Partition Vector Index
Inverted File Flat (IVF) index is the only type of Neighbor Partition vector index supported.
Inverted File Flat Index (IVF Flat or simply IVF) is a partitioned-based index which balance high search quality with reasonable speed.
The IVF index is a technique designed to enhance search efficiency by narrowing the search area through the use of neighbor partitions or clusters.

Here is an example of creating such an index in Oracle 23ai.
CREATE VECTOR INDEX galaxies_ivf_idx ON galaxies (embedding)
ORGANIZATION NEIGHBOR
PARTITIONS DISTANCE COSINE
WITH TARGET ACCURACY 95;
Check out my other posts in this series on Vector Databases.

You must be logged in to post a comment.