
Vector Databases – Part 2
In this post on Vector Databases, I’ll look at the main components:
- Vector Embedding Models. What they do and what they create.
- Vectors. What they represent, and why they have different sizes.
- Vector Search. An overview of what a Vector Search will do. A more detailed version of this is in a separate post.
- Vector Search Process. It’s a multi-step process and some care is needed.

Vector Embedding Models
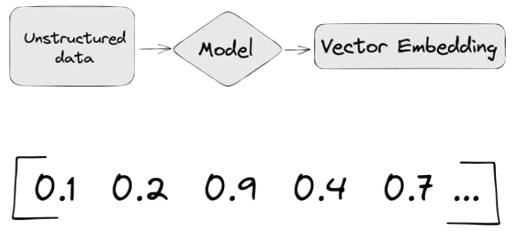
A vector embedding model is a type of machine learning model that transforms data into vectors (embeddings) in a high-dimensional space. These embeddings capture the semantic or contextual relationships between the data points, making them useful for tasks such as similarity search, clustering, and classification.
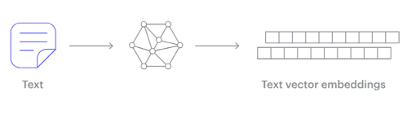
Embedding models are trained to convert the input data point (text, video, image, etc) into a vector (a series of numeric values). The model aims to identify semantic similarity with the input and map these to N-dimensional space. For example, the words “car” and “vehicle” have very different spelling but are semantically similar. The embedding model should map this to have similar vectors. Similarly with documents. The embedding model will map the documents to be able to group similar documents together (in N-dimensional space).
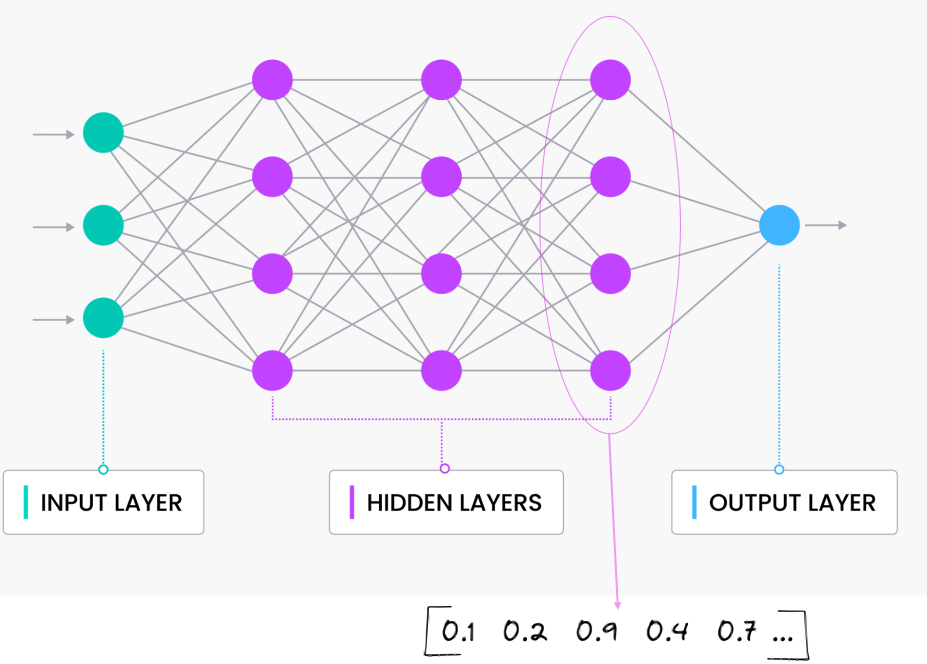
An embedding model is typically a Neural Network (NN) model. There are many different embedding models available from various vendor such as OpenAI, Cohere, etc., or you can build your own. Some models are open source and some are available for a fee. Typically, the output from the embedding model (the Vector) come from the last layer of the neural network
Vectors
A Vector is a sequence of numbers, called dimensions, used to capture the important “features” or “characteristics” of a piece of data. A vector is a mathematical object that has both magnitude (length) and direction. In the context of mathematics and physics, a vector is typically represented as an arrow pointing from one point to another in space, or as a list of numbers (coordinates) that define its position in a particular space.
Different Embedding Models create different numbers of Dimensions. Size is important with vectors as the greater the number number of dimensions the larger the Vector. The larger the number of dimensions the better the semantic similarity matches will be. As Vector size increases, so does space required to store them (not really a problem for Databases, but at Big Data scale it can be a challenge)
As vector size increases so does the Index space, and correspondingly search time can increase as the number of calculations for Distance Measure increases. There are various Vector indexes available to help with this (see my post covering this topic)
Basically, a vector is an array of numbers, where each number represents a dimension. It is easy for us to comprehend and visualise 2 dimensions. Here is an example of using 2 dimensions to represent different types of vehicles. The vectors give us a way to map or chart the data.
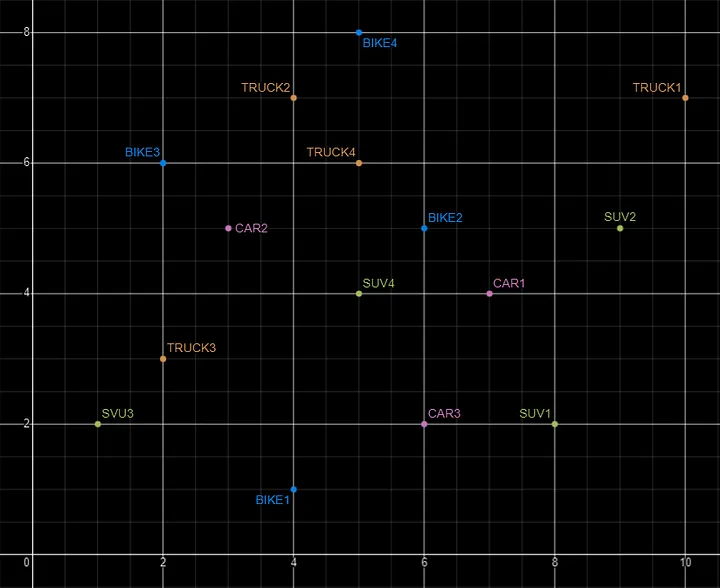
Here is SQL code for this data. I’ll come back to this data in the section on Vector Search.
INSERT INTO PARKING_LOT VALUES('CAR1','[7,4]');
INSERT INTO PARKING_LOT VALUES('CAR2','[3,5]');
INSERT INTO PARKING_LOT VALUES('CAR3','[6,2]');
INSERT INTO PARKING_LOT VALUES('TRUCK1','[10,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK2','[4,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK3','[2,3]');
INSERT INTO PARKING_LOT VALUES('TRUCK4','[5,6]');
INSERT INTO PARKING_LOT VALUES('BIKE1','[4,1]');
INSERT INTO PARKING_LOT VALUES('BIKE2','[6,5]');
INSERT INTO PARKING_LOT VALUES('BIKE3','[2,6]');
INSERT INTO PARKING_LOT VALUES('BIKE4','[5,8]');
INSERT INTO PARKING_LOT VALUES('SUV1','[8,2]');
INSERT INTO PARKING_LOT VALUES('SUV2','[9,5]');
INSERT INTO PARKING_LOT VALUES('SUV3','[1,2]');
INSERT INTO PARKING_LOT VALUES('SUV4','[5,4]');The vectors created by the embedding models can have a different number of dimensions. Common Dimension Sizes are:
- 100-Dimensional: Often used in older or simpler models like some configurations of Word2Vec and GloVe. Suitable for tasks where computational efficiency is a priority and the context isn’t highly complex.
- 300-Dimensional: A common choice for many word embeddings (e.g., Word2Vec, GloVe). Strikes a balance between capturing sufficient detail and computational feasibility.
- 512-Dimensional: Used in some transformer models and sentence embeddings. Offers a richer representation than 300-dimensional embeddings.
- 768-Dimensional: Standard for BERT base models and many other transformer-based models. Provides detailed and contextual embeddings suitable for complex tasks.
- 1024-Dimensional: Used in larger transformer models (e.g., GPT-2 large). Provides even more detail but requires more computational resources.
Many of the newer embedding models have >3000 dimensions!
- Cohere’s embedding model embed-english-v3.0 has 1024 dimensions.
- OpenAI’s embedding model text-embedding-3-large has 3072 dimensions.
- Hugging Face’s embedding model all-MiniLM-L6-v2 has 384 dimensions
Here is a blog post listing some of the embedding models supported by Oracle Vector Search.
Vector Search
Vector search is a method of retrieving data by comparing high-dimensional vector representations (embeddings) of items rather than using traditional keyword or exact-match queries. This technique is commonly used in applications that involve similarity search, where the goal is to find items that are most similar to a given query based on their vector representations.
For example, using the vehicle data given above, we can easily visualise the search for similar vehicles. If we took “CAR1” as our initiating data point and wanted to know what other vehicles are similar to it. Vector Search looks at the distance between “CAR1” and all other vehicles in the 2-dimensional space.
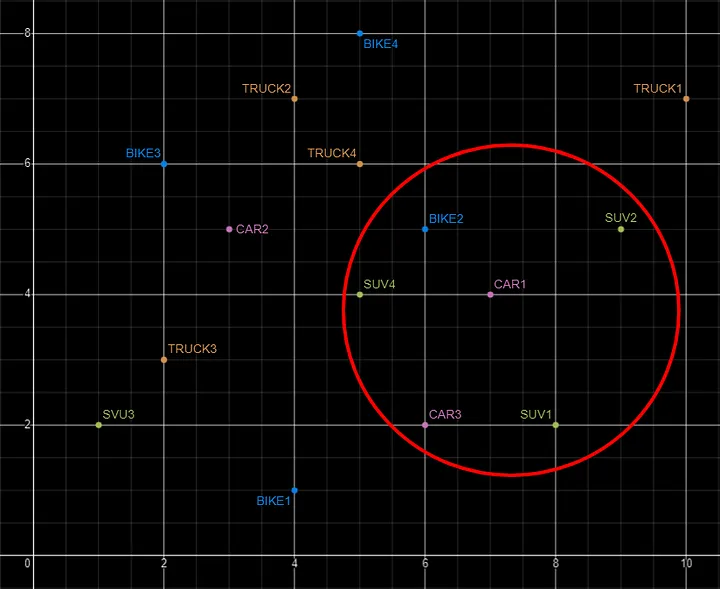
Vector Search becomes a bit more of a challenge when we have 1000+ dimensions, requiring advanced distance algorithms. I’ll have more on these in the next post.
Vector Search Process
The Vector Search process is divided into two parts.
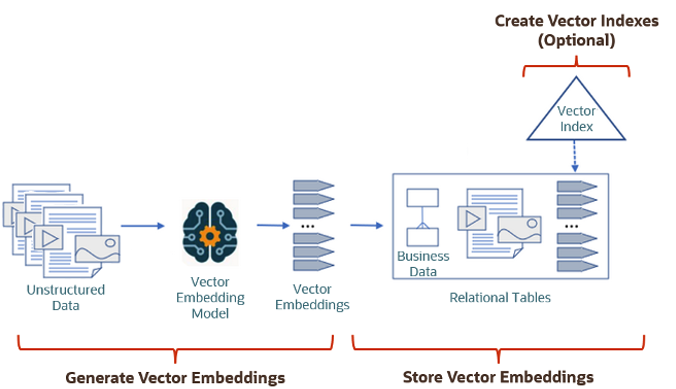
The first part involved creating Vectors for your existing data and for any new data generated and needs to be stored. This data can be used for Semantic Similarity searches (part two of the process). The first part of the process takes your data, applies a vector embedding model to it, generates the vectors and stores them in your Database. When the vectors are stored, Vector Indexes can be created.
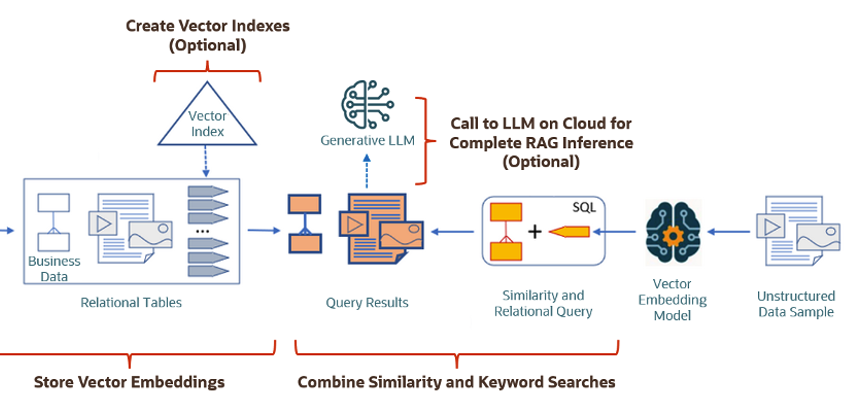
The second part if the process involves Vector Search. This involves having some data you want to search on (e.g. “CARS1” in the previous example). This data will need to be passed to the Vector Embedding model. A Vector for this data is generated. The Vector Search will use this vector to compare to all other vectors in the Database. The results returned will be those vectors (and their corresponding data) that closely match the vector being searched.
Check out my other posts in this series on Vector Databases.
