
Why Choose Apache Iceberg for Data Interoperability?
Modern data platforms increasingly separate compute from storage, using object stores as durable data lakes while scaling processing engines. Traditional “data lakes” built on Parquet files and Hive-style partitioning have limitations around atomicity, schema evolution, metadata scalability, and multi-engine interoperability. Apache Iceberg addresses these challenges by defining a high-performance table format with transactional guarantees, scalable metadata structures, and engine-agnostic semantics.
Apache Iceberg, an open-source table format that has become the industry standard for data sharing in modern data architectures. Let’s have a look at some of the key features, some of its limitations and a brief look at some of the alternatives.
What is Apache Iceberg and Why Do We Need It? Apache Iceberg is not a storage engine or a compute engine; it’s a table format. It acts as a metadata layer that sits between your physical data files (Parquet, ORC, Avro) and your compute engines.
Before Iceberg, data lakes managed tables as directories of files. To find data, an engine had to list all files in a directory—a slow operation on cloud storage. There was no guarantee of data consistency; a reader might see a partially written file from a running job. Iceberg solves this by tracking individual data files in a persistent tree of metadata. This effectively brings semi-database level reliability, with ACID transactions and snapshot isolation, together with the flexible, low-cost world of object storage.
Iceberg has several important features that bridge the gap between data lakes and traditional warehouses like Oracle:
- ACID Transactions: Iceberg ensures that readers never see partial or uncommitted data. Every write operation creates a new, immutable snapshot. Commits are atomic, meaning they either fully succeed or fully fail. This is the same level of integrity that database administrators have come to expect from Oracle Database for decades.
- Reliable Schema Evolution: In the past, adding or renaming a column in a data lake could require a complete rewrite of your data. Iceberg supports full schema evolution—adding, dropping, updating, or renaming columns—as a metadata operation. It ensures that “zombie” data or schema mismatches never crash your production pipelines.
- Hidden Partitioning: This is a massive usability improvement. Instead of forcing users to know the physical directory structure (e.g.,
WHERE year=2026), Iceberg handles partitioning transparently. You can partition by a timestamp, and Iceberg handles the logic. This makes the data lake feel more like a standard SQL table in a relational Database, where the physical storage details are abstracted away from the analyst. - Time Travel and Rollback: Because Iceberg maintains a history of table snapshots, you can query the data as it existed at any point in history. This is invaluable for auditing, reproducing machine learning models, or quickly rolling back accidental bad writes without needing to restore from a massive tape backup.
While the benefits of Apache Iceberg Tables are critical for its adaption, there are also some limitations:
- Metadata Overhead: The metadata layer adds complexity. For extremely small, high-frequency “single-row” writes, the overhead of managing metadata files can be significant compared to a highly tuned RDBMS.
- Tooling Maturity: While major players like AWS, Snowflake, Oracle, etc have adopted it, support across the entire data ecosystem is still evolving. You may occasionally encounter older tools that don’t natively understand Iceberg tables.
- Write Latency: Every commit involves writing new manifest and metadata files. While this is fine for batch and micro-batch processing, it may not replace the sub-second latency required for OLTP (Online Transactional Processing) workloads where relational Database still reign supreme.
Alternatives to Apache Iceberg tables include Delta Lake (from Databricks) and Apache Hudi. While Delta Lake is highly optimized for the Spark ecosystem and offers a rich feature set, its governance has historically been closely tied to Databricks. Apache Hudi is optimized in streaming ingestion and near-real-time upsert use cases due to its unique indexing and log-merge capabilities. etc it can take some time to consolidate the data change logs. Apache Iceberg is often the choice for organizations seeking maximum interoperability. Its design allows diverse engines, from Spark and Trino to Snowflake and Oracle, to interact with the same data without vendor lock-in and with minimum data copying.

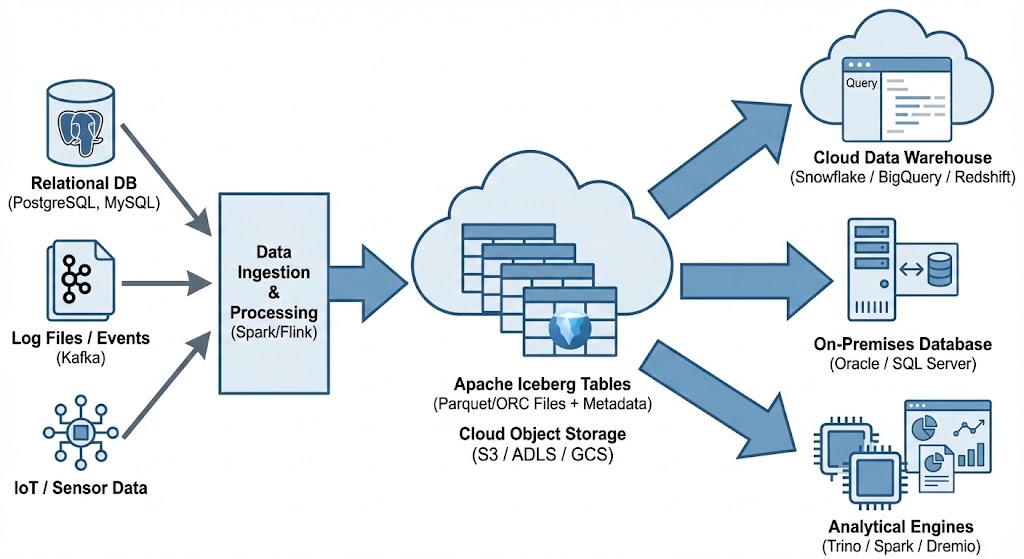
One of Apache Iceberg’s greatest strengths is its ability to act as a central, interoperable layer for data sharing across different platforms. By standardizing on Iceberg, you break down silos. Data ingested once into your data lake becomes immediately available to multiple consuming systems without complex ETL pipelines. Data from various sources is ingested and stored as Apache Iceberg tables in cloud object storage. From there, it can be seamlessly queried by cloud data warehouses like Snowflake and Oracle, etc, and synced to on-premises databases, like Oracle and others, or accessed by various analytical engines for BI and data science.
