
AI Vision
OCI Vision – Creating a Custom Model for Cats and Dogs
In this post, I’ll build on the previous work on preparing data, to using this dataset as input to building a Custom AI Vision model. In the previous post, the dataset was labelled into images containing Cats and Dogs. The following steps takes you through creating the Customer AI Vision model and to test this model using some different images of Cats.
Open the OCI Vision page. On the bottom left-hand side of the menu you will see Projects. Click on this to open the Projects page for creating a Custom AI Vision model.
On the Create Projects page, click on the Create Project button. A pop-up window will appear. Enter the name for the model and click on the Create Project bottom at the bottom of the pop-up.
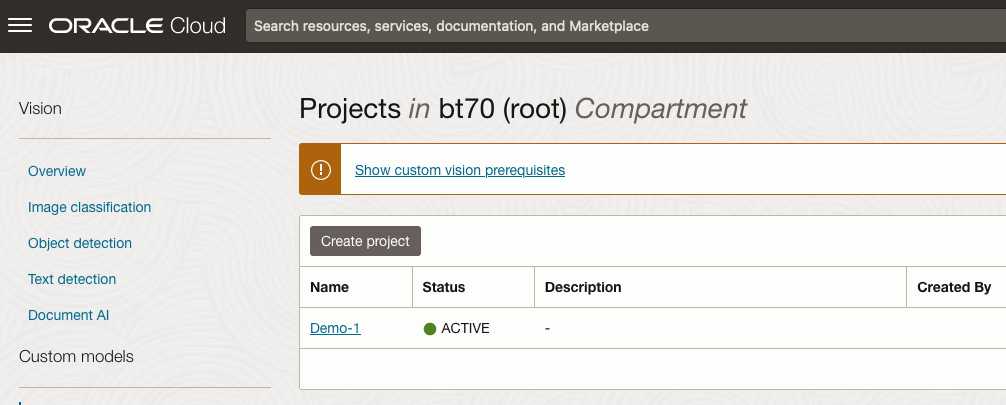
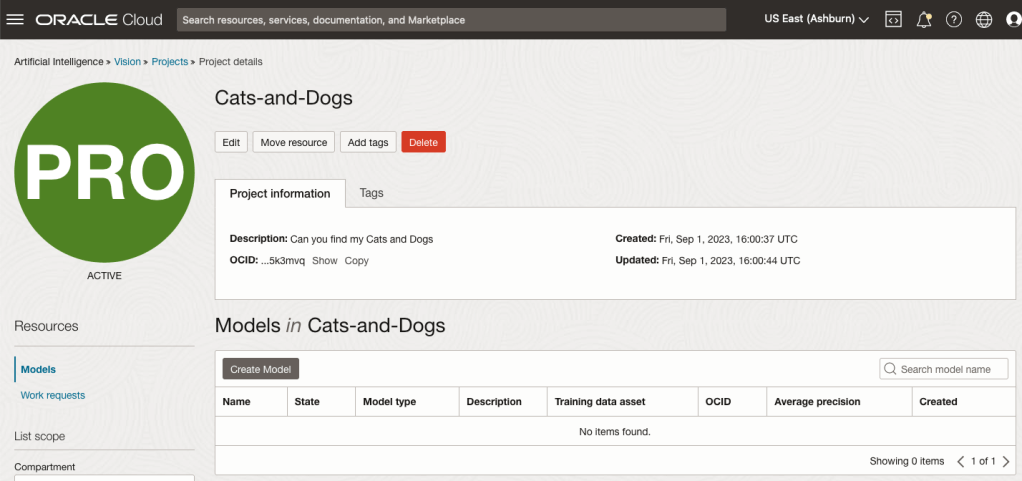
After the Project has been created, click on the project name from the list. This will open the Project specific page. A project can contain multiple models and they will be listed here. For the Cats-and-Dogs project we and to create our model. Click on the Create Model button.
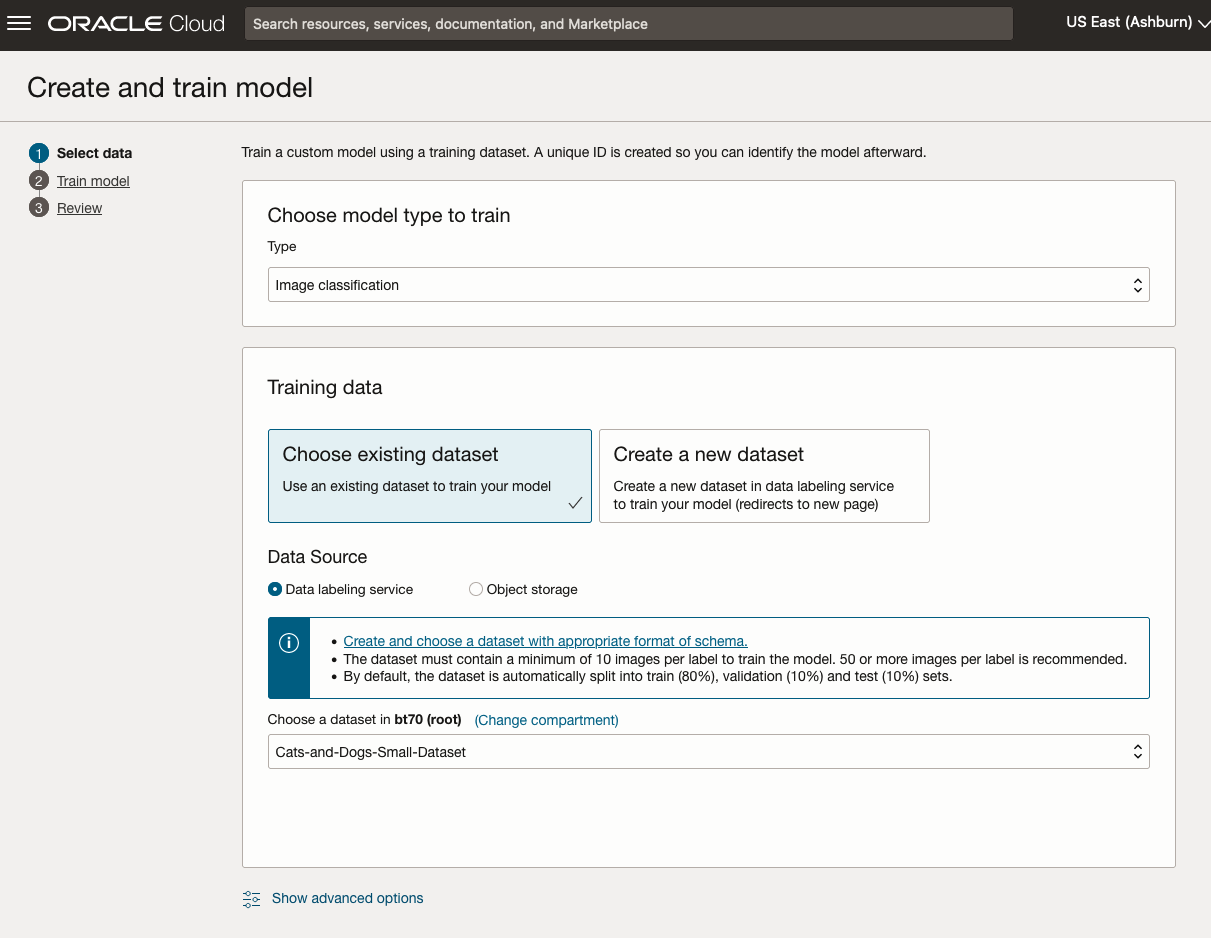
Next, you can define some of the settings for the Model. These include what dataset to use, or upload a new one, define what data labelling to use and the training duration. For this later setting, you can decide how much time you’d like to allocate to creating the custom model. Maybe consider selecting Quick mode, as that will give you a model within a few minutes (or up to an hour), whereas the other options can allow the model process to run for longer and hopefully those will create a more accurate model. As with all machine learning type models, you need to take some time to test which configuration works best for your scenario. In the following, the Quick mode option is selected. When read, click Create Model.

It can take a little bit of time to create the model. We selected the Quick mode, which has a maximum of one hour. In my scenario, the model build process was completed after four minutes. The Precentage Complete is updated during the build allowing you to monitor it’s progress.

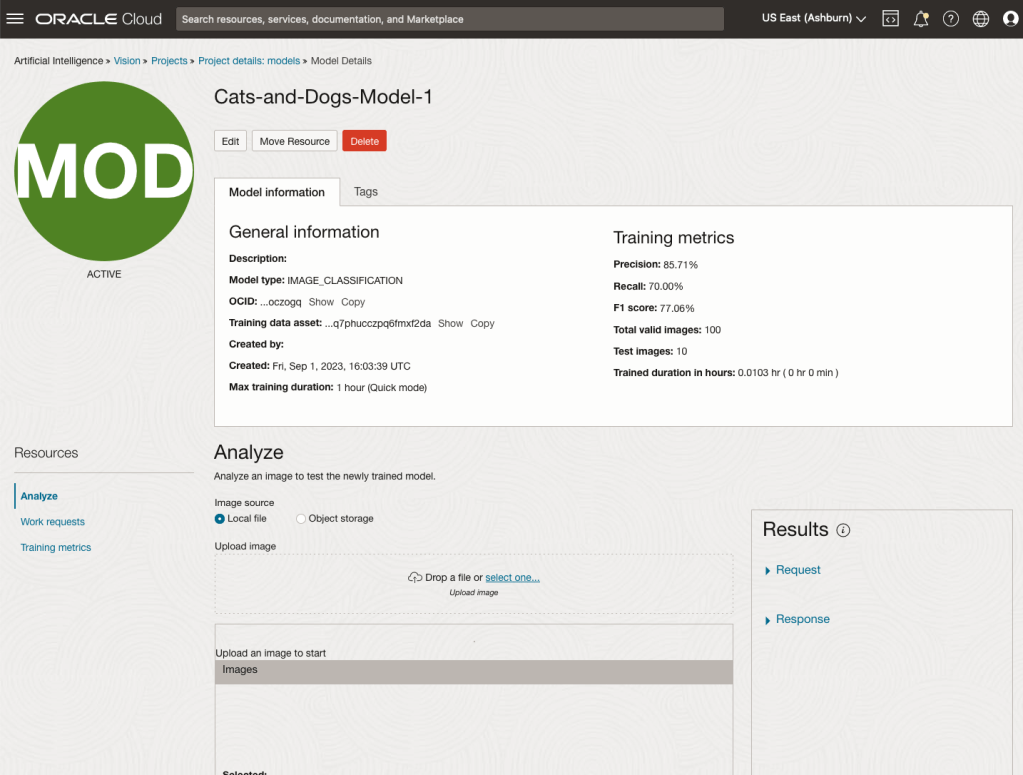
When the model is completed, you can test it using the Model page. Just click on the link for the model and you’ll get a page like the one to the right.
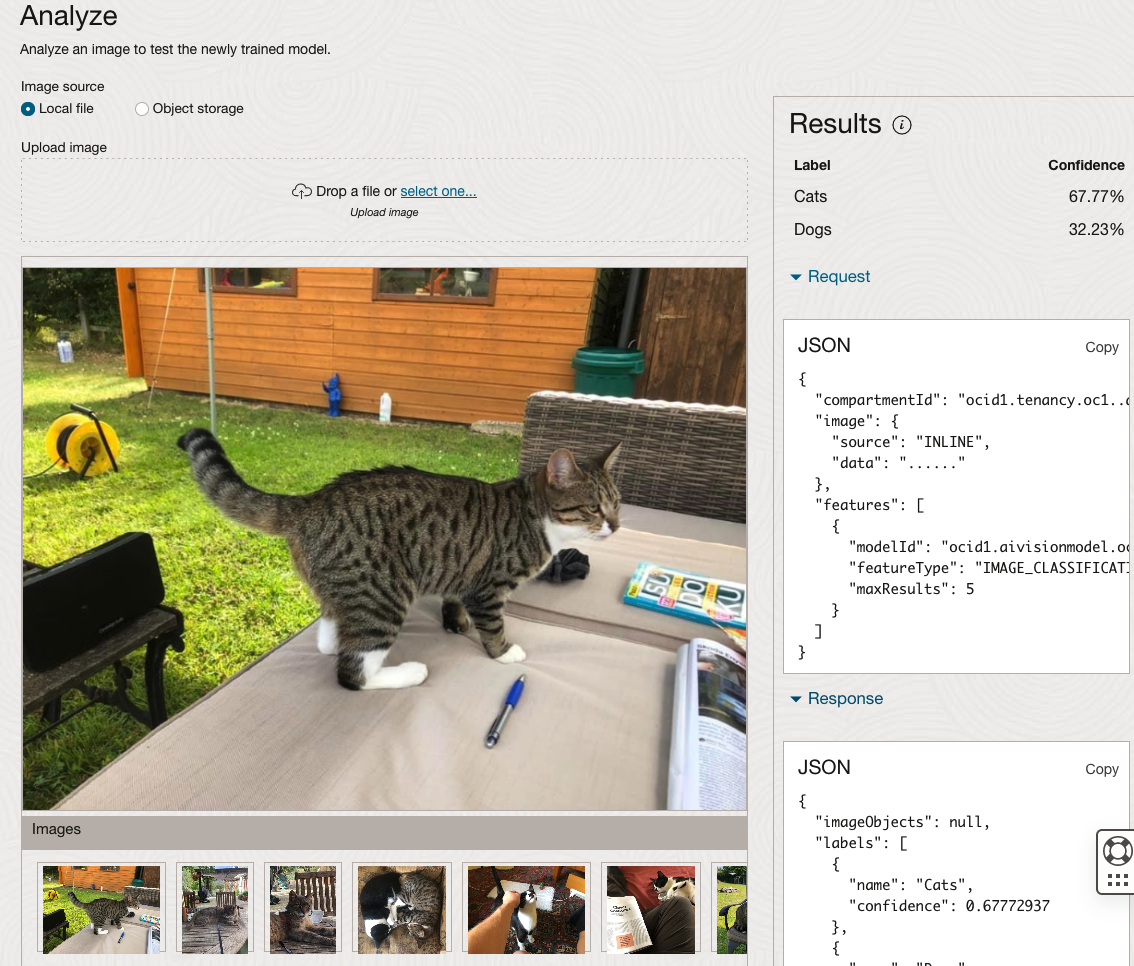
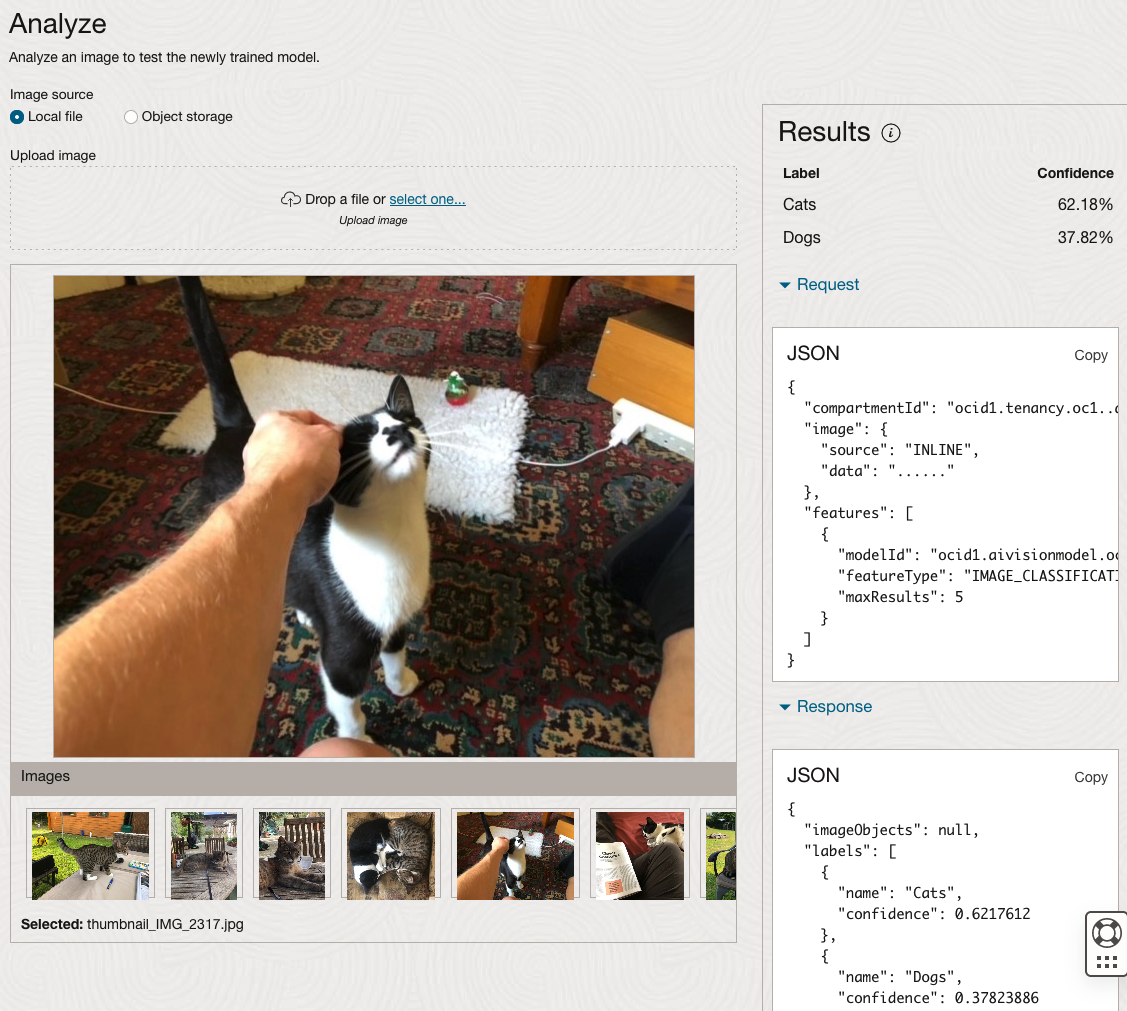
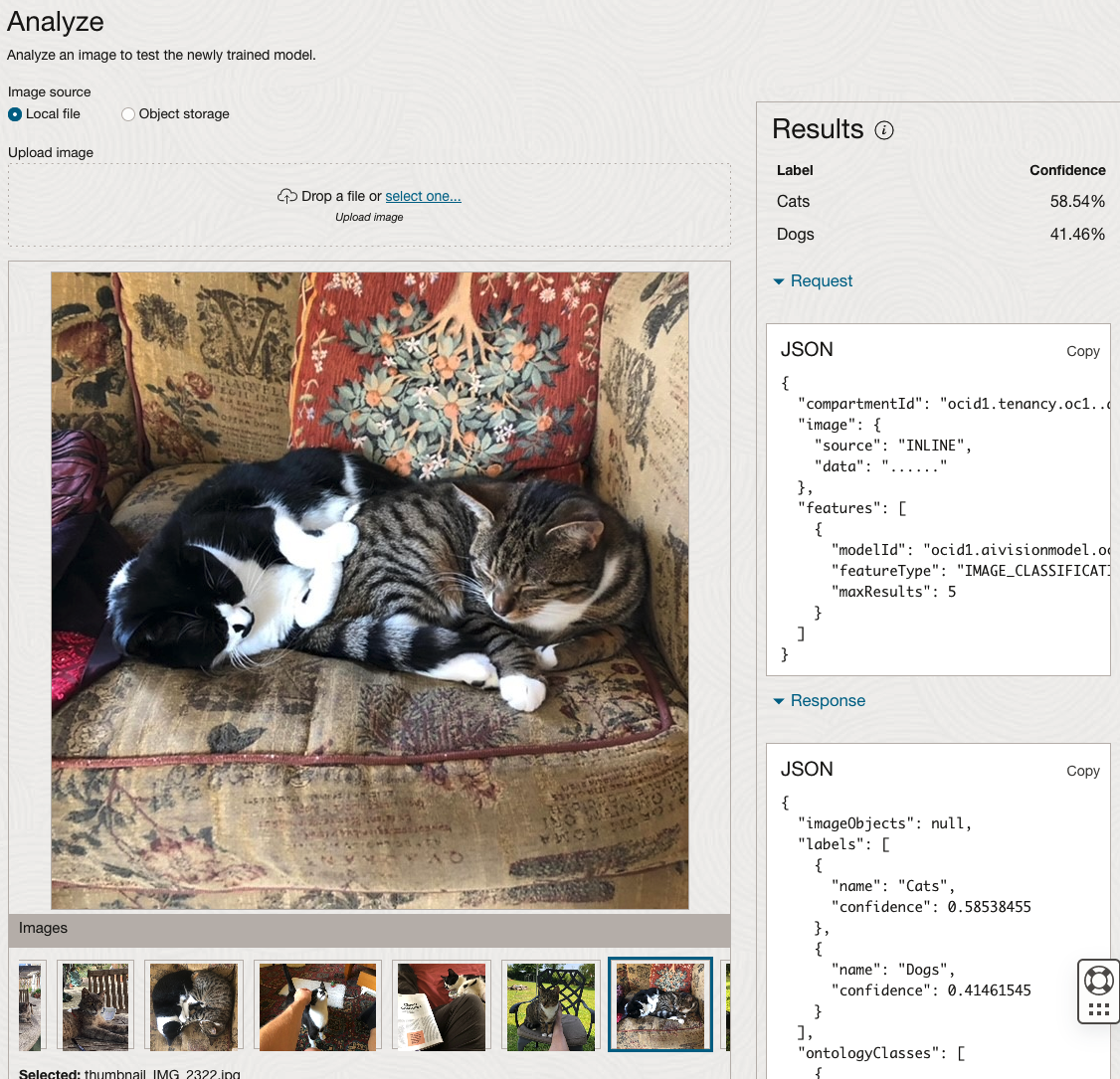
The bottom half of this page allows you to upload and evaluate images. The following images are example images of cats (do you know the owner) and the predictions and information about these are displayed on the screen. Have a look at the following to see which images scored better than others for identifying a Cat.
OCI:Vision – AI for image processing – the Basics
Every cloud service provides some form of AI offering. Some of these can range from very basic features right up to a mediocre level. Only a few are delivering advanced AI services in a useful way.
Oracle AI Services have been around for about a year now, and with all new products or cloud services, a little time is needed to let it develop from an MVP (minimum viable produce) to something that’s more mature, feature-rich, stable and reliable. Oracle’s OCI AI Services come with some pre-training models and to create your own custom models based on your own training datasets.
Oracle’s OCI AI Services include:
- Digital Assistant
- Language
- Speech
- Vision
- Document Understand
- Anomaly Detection
- Forecasting
In this post, we’ll explore OCI Vision, and what the capabilities are available with their pre-trained models. To demonstrate this their online/webpage application will be used to demonstrate what it does and what it creates and identifies. You can access the Vision AI Services from the menu as shown in the following image.
From the main AI Vision webpage, we can see on the menu (on left-hand side of the page), we have three main Vision related options. These are Image Classification, Object Detection and Document AI. These are pre-trained models that perform slightly different tasks.
Let’s start with Image Classification and explore what is possible. Just Click on the link.
Note: The Document AI feature will be moving to its own cloud Service in 2024, so it will disappear from them many but will appear as a new service on the main Analytics & AI webpage (shown above).
The webpage for each Vision feature comes with a couple of images for you to examine to see how it works. But a better way to explore the capabilities of each feature is to use your own images or images you have downloaded. Here are examples.
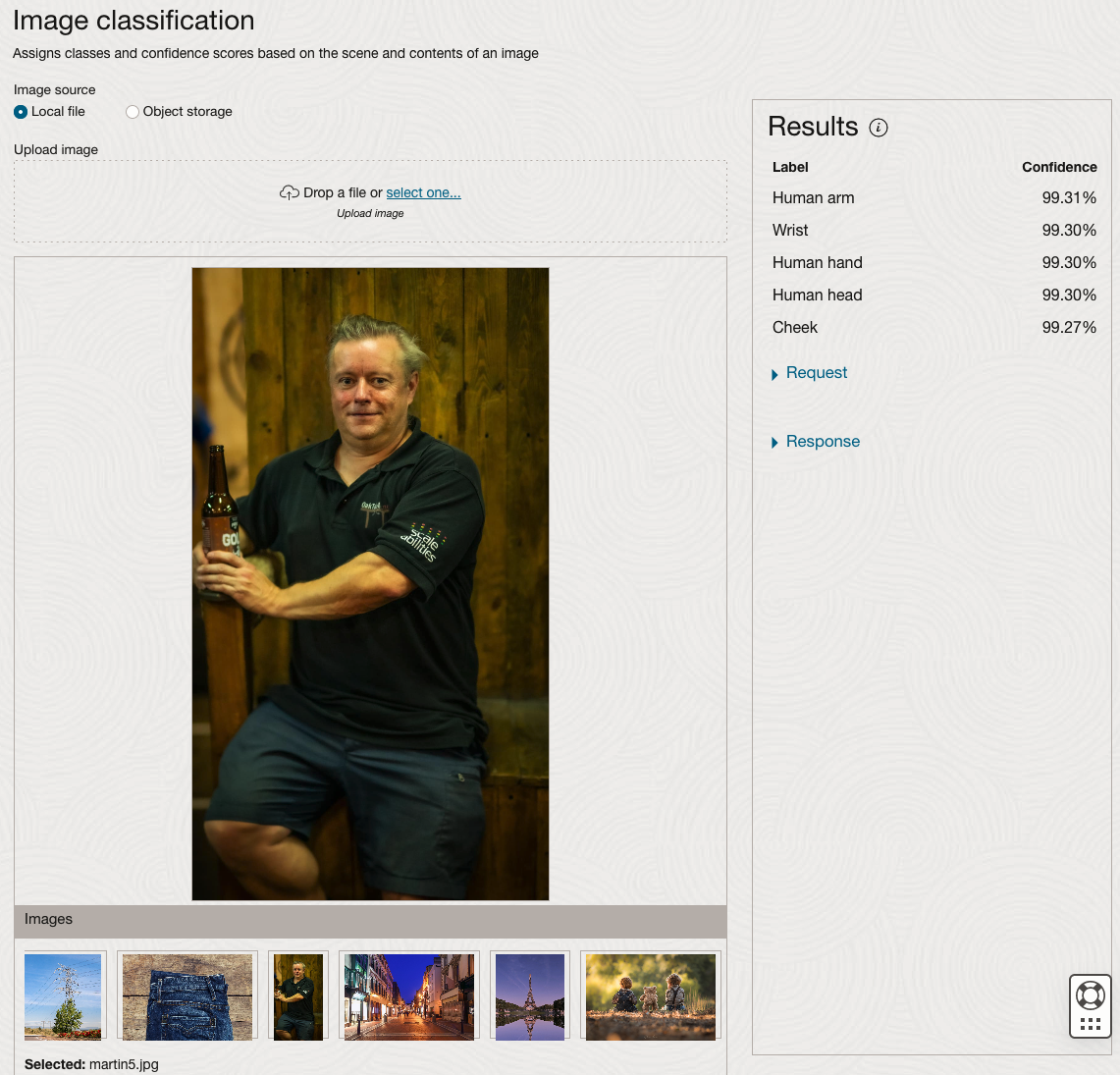
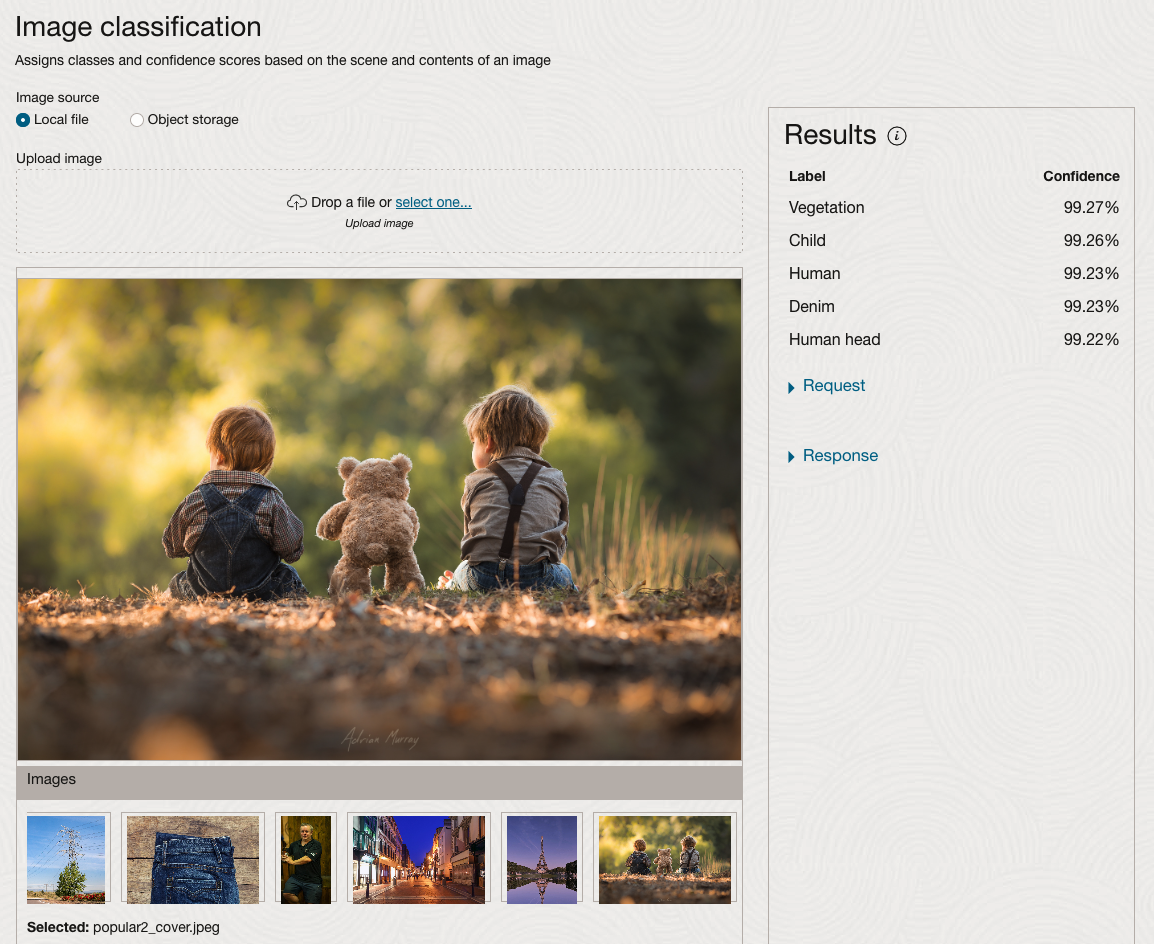
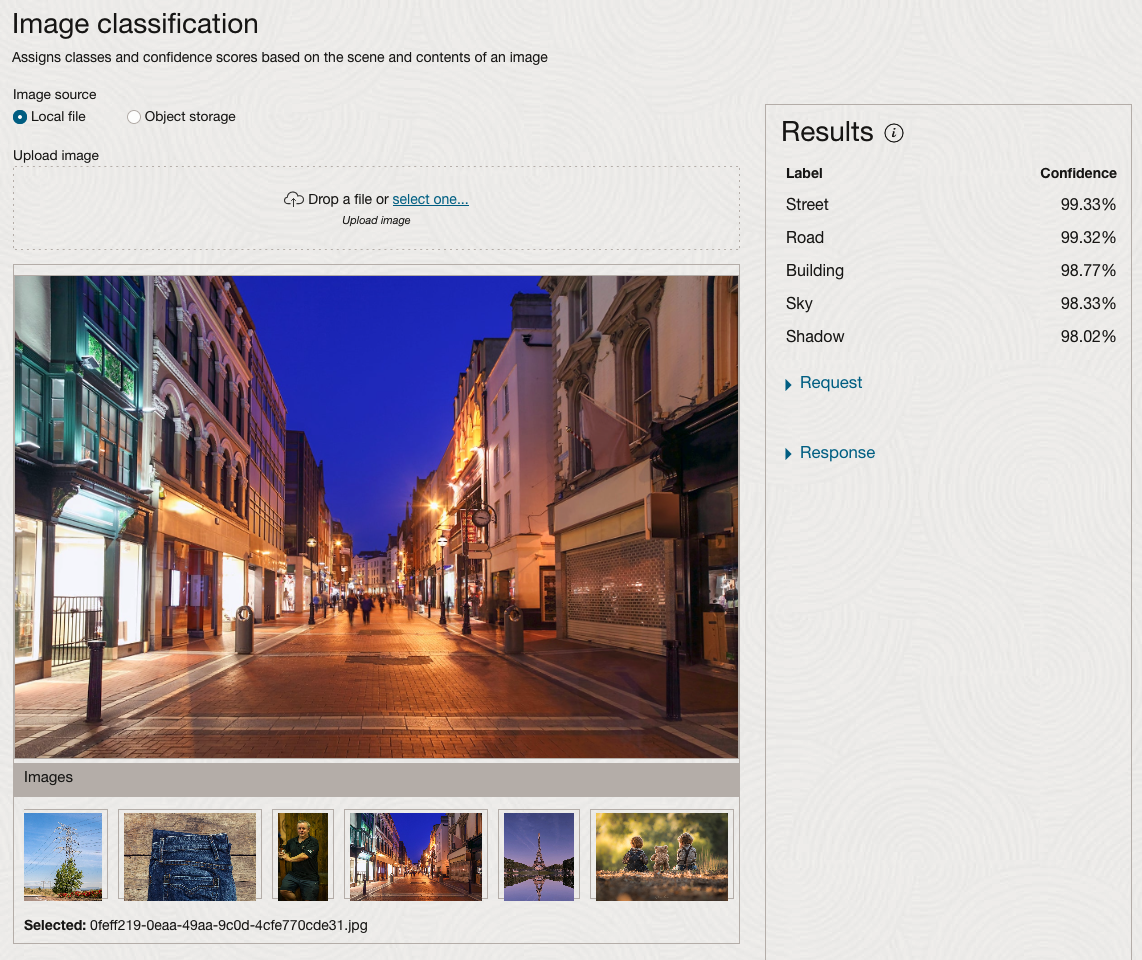
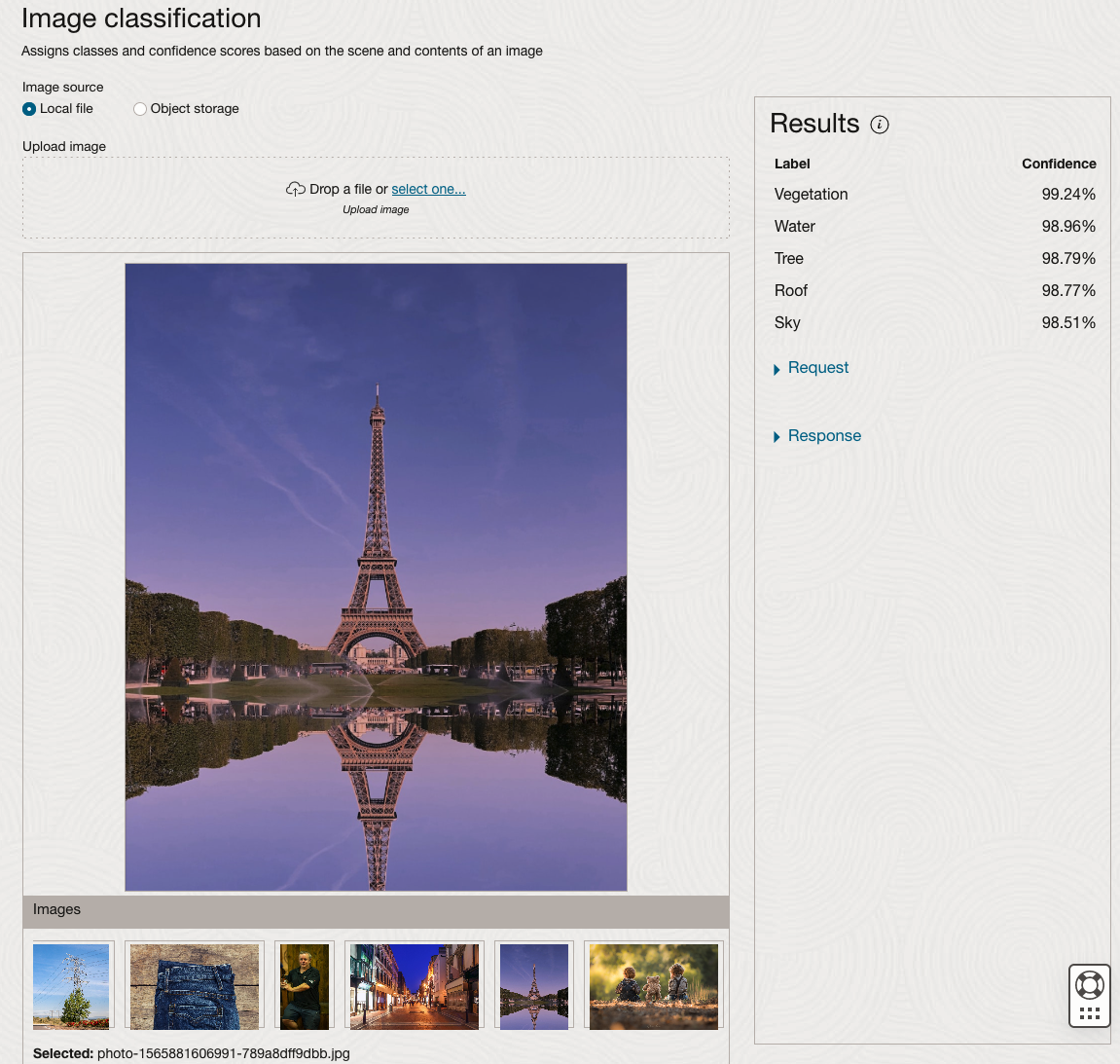
We can see the pre-trained model assigns classes and confidence for each image based on the main components it has identified in the image. For example with the Eiffel Tower image, the model has identified Water, Trees, Sky, Vegetation and Roof (of build). But it didn’t do so well with identifying the main object in the image as being a tower, or building of some form. Where with the streetscape image it was able to identify Street, Road, Building, Sky and Shadow.
Just under the Result section, we see two labels that can be expanded. One of these is the Response which contains JSON structure containing the labels, and confidences it has identified. This is what the pre-trained model returns and if you were to use Python to call this pre-trained model, it is this JSON object that you will get returned. You can then use the information contained in the JSON object to perform additional tasks for the image.
As you can see the webpage for OCI Vision and other AI services gives you a very simple introduction to what is possible, but it over simplifies the task and a lot of work is needed outside of this page to make the use of these pre-trained models useful.
Moving onto the Object Detection feature (left-hand menu) and using the pre-trained model on the same images, we get slightly different results.
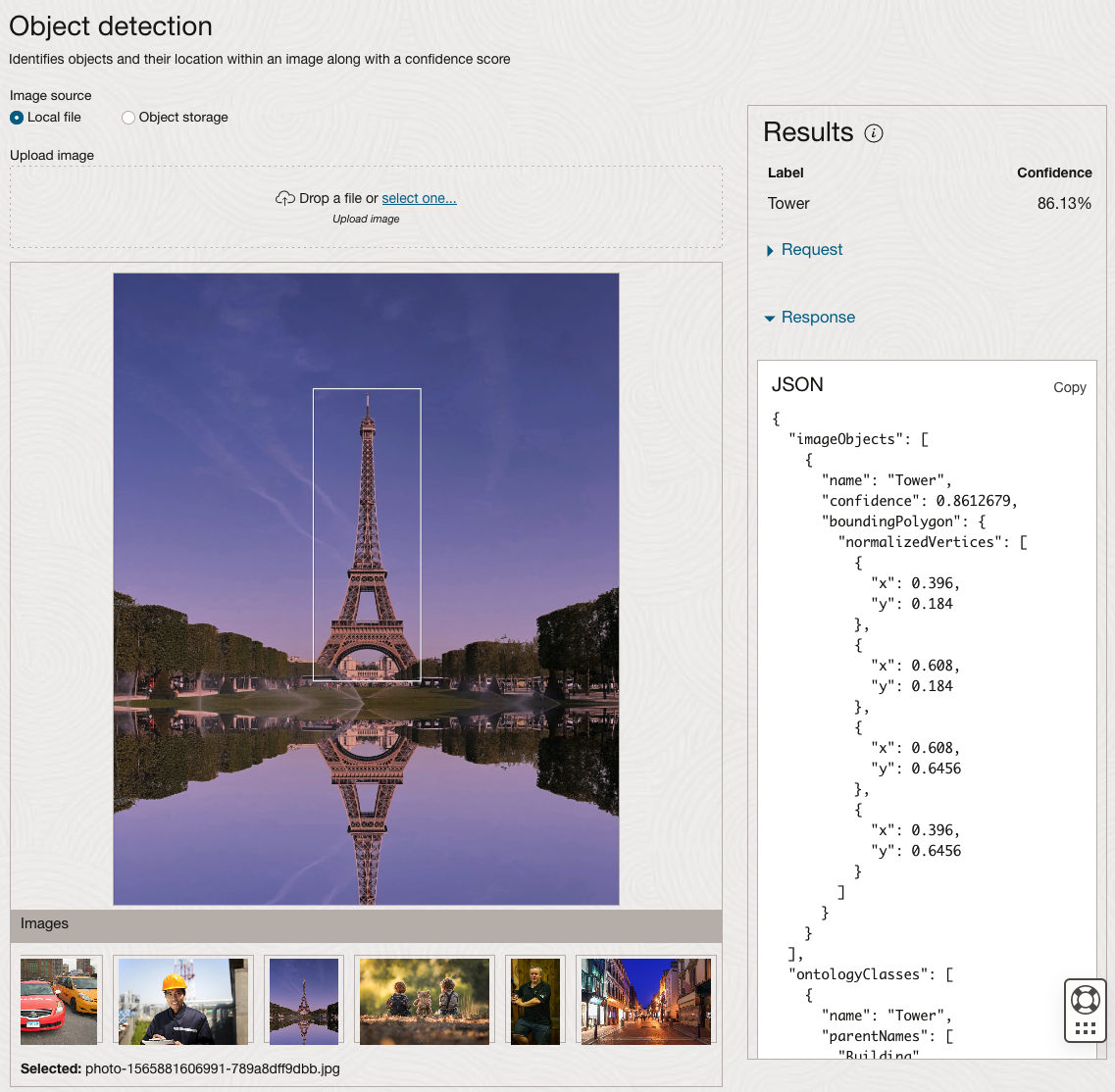
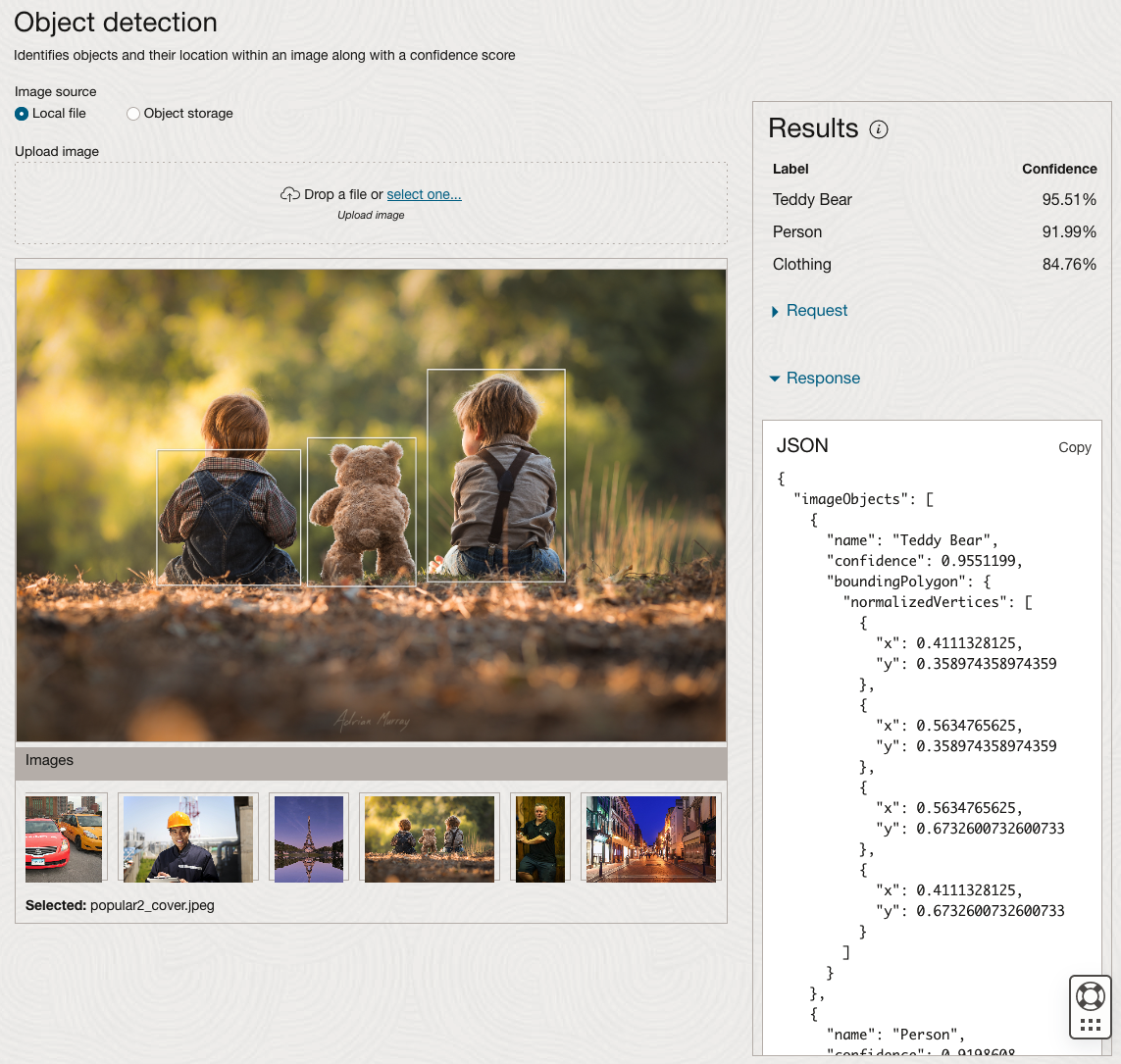
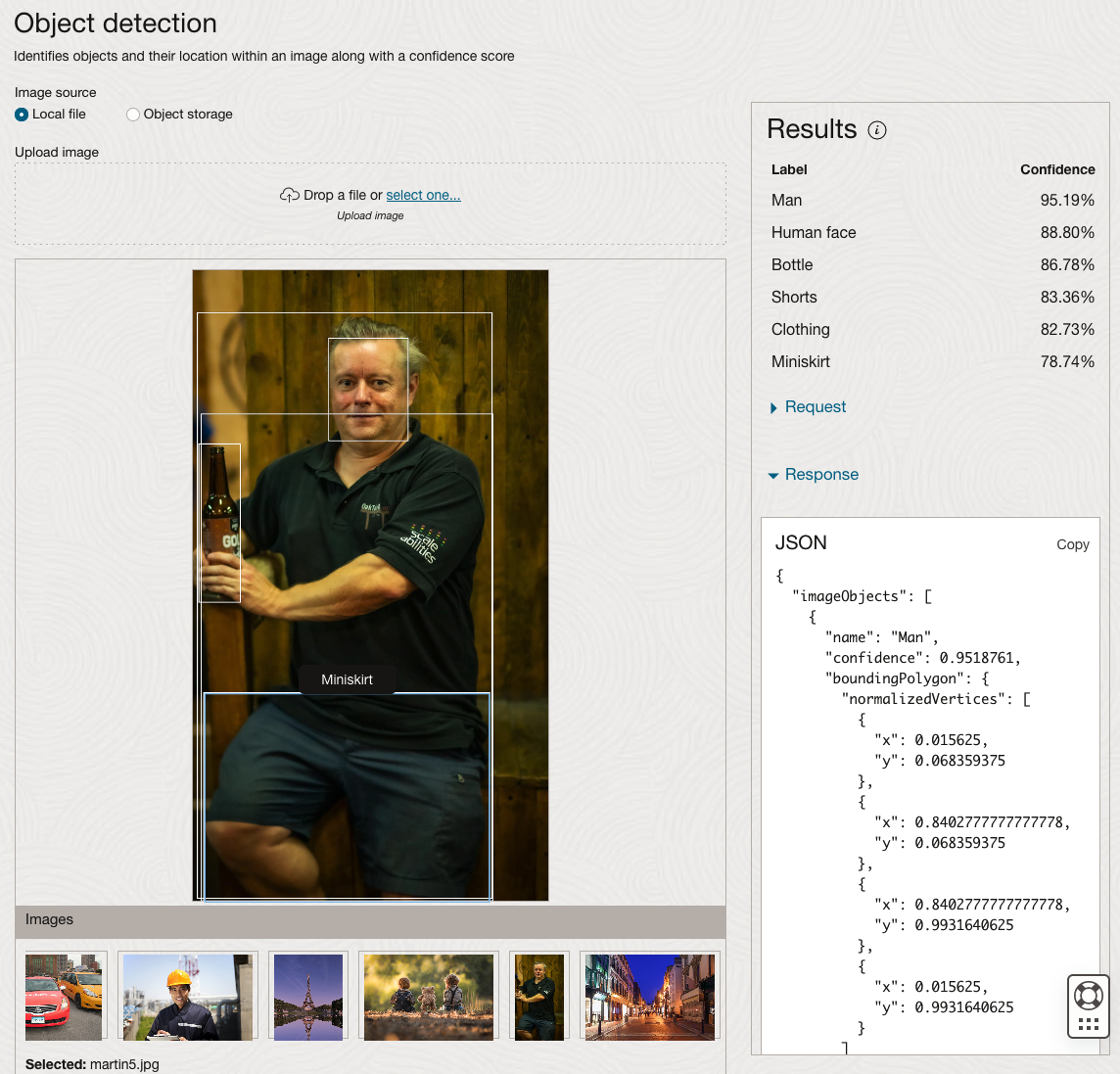
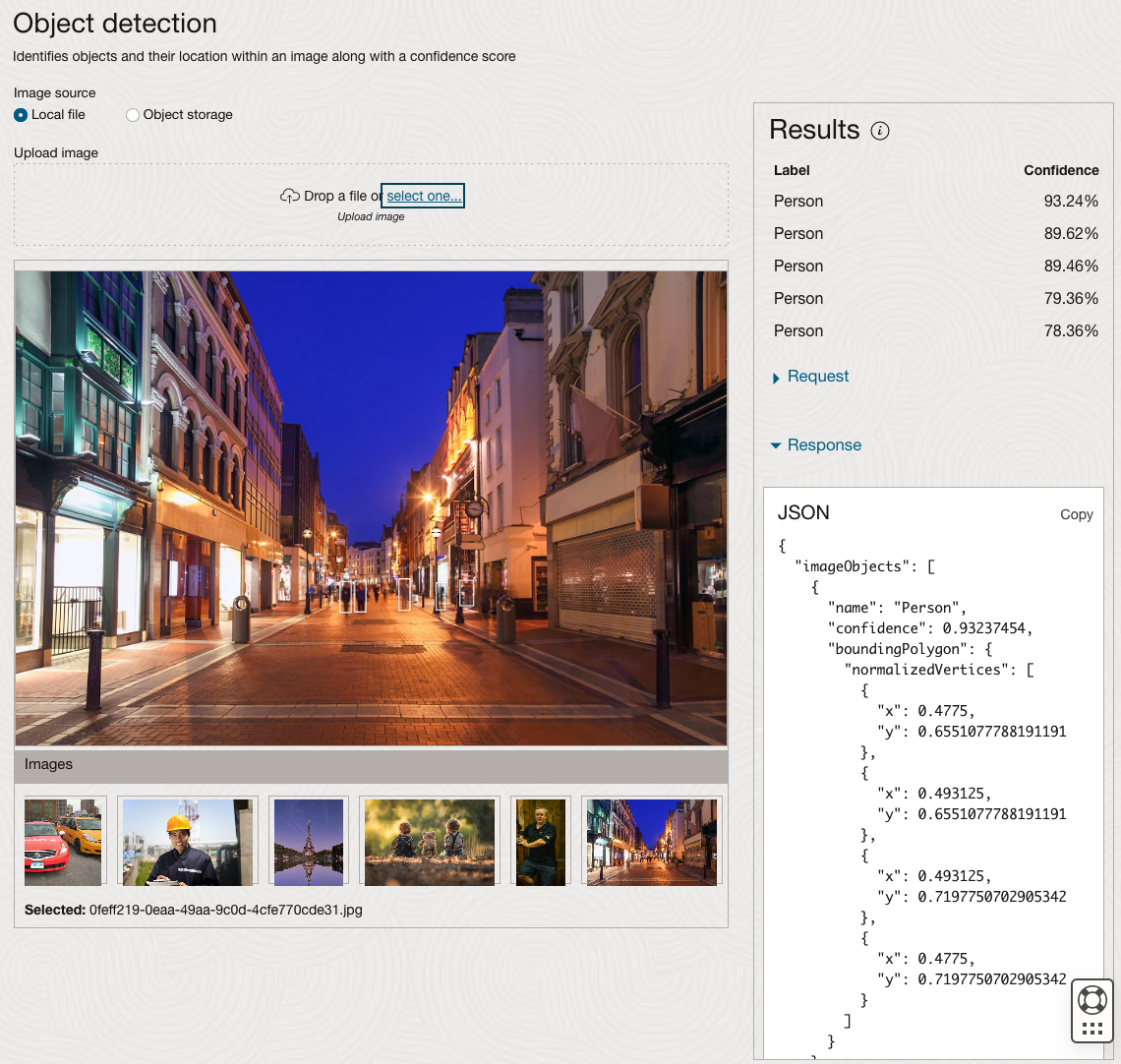
The object detection pre-trained model works differently as it can identify different things in the image. For example, with the Eiffel Tower image, it identifies a Tower in the image. In a similar way to the previous example, the model returns a JSON object with the label and also provides the coordinates for a bounding box for the objects detected. In the street scape image, it has identified five people. You’ll probably identify many more but the model identified five. Have a look at the other images and see what it has identified for each.
As I mentioned above, using these pre-trained models are kind of interesting, but are of limited use and do not really demonstrate the full capabilities of what is possible. Look out of additional post which will demonstrate this and steps needed to create and use your own custom model.

You must be logged in to post a comment.