
kaggle
How to download a Kaggle Competition dataset
Kaggle is a popular website for data science and machine learning, where users can participate in machine learning competitions, access an extensive library of open datasets, notebooks and training. It is used by Data scientists and students around the world to learn and test their skills on a wider variety of problems.
One of the first tasks any person using Kaggle will need to do is to download a dataset. One simple way of doing this is by logging into the website and manually downloading the dataset.
But what if you want to automate this step into your Notebook or other Python environment you might be using? Building repeatedly into your projects is an important step, as it can ilimate any postting errors that might occur when perform these manually. The examples give below were all run in a Jupyter Notebook.
First thing to do is to install the kaggle and kagglehub python packages.
!pip3 install kaggle!pip3 install kagglehub
Before we do anything else in the Jupyter Notebook, you will need to log into the Kaggle website and get and API Key Token for your account
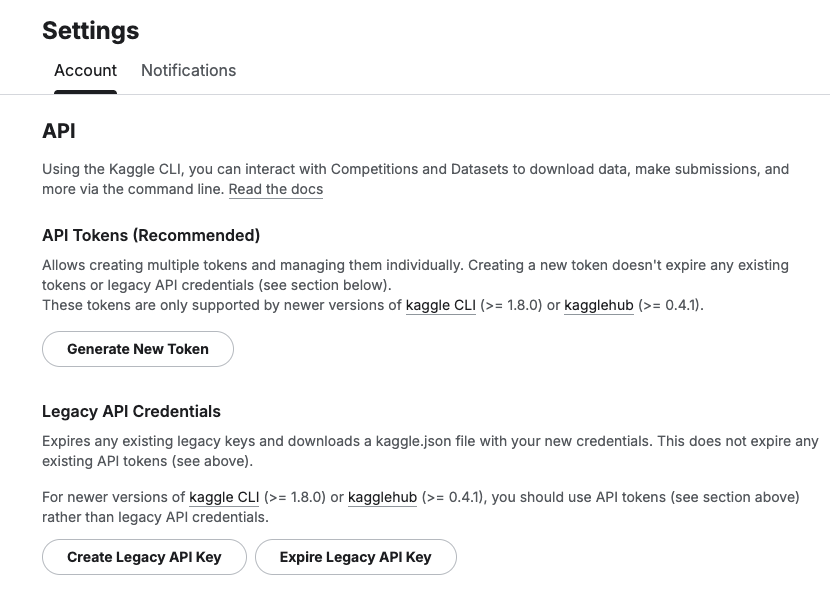
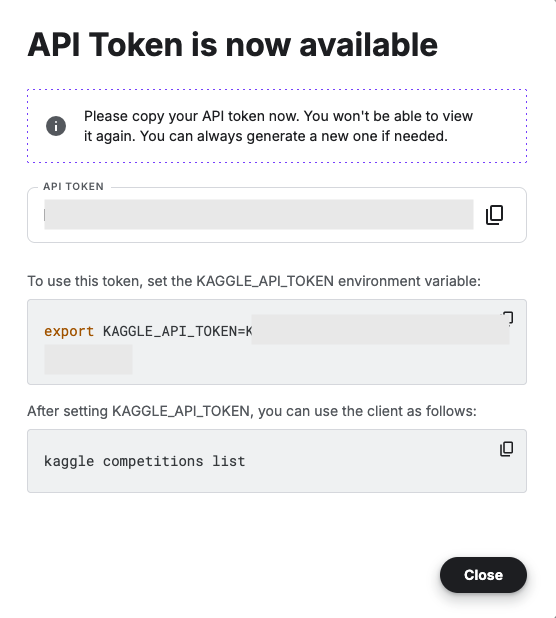
Copy the Kaggle API Key and add it to an environment variable. Here is the code to do this in the Jupyter Notebook.
import osos.environ["KAGGLE_API_TOKEN"] = "..."
You can check that it has been set correctly by running
print(os.environ["KAGGLE_API_TOKEN"])
Now we can get on with accessing the Kaggle datasets. This first approach will use the kaggle python package. With this you can use a mixture of command line commands and package functions
#import kaggle packageimport kaggle#use command line to list the datasets - limited output!kaggle datasets list#use a kaggle package function to list competitionsfrom kaggle.api.kaggle_api_extended import KaggleApiapi = KaggleApi()api.authenticate()api.competitions_list_cli()
I’ve not listed the outputs above, as the output would be very long. I’ll leave that for you to explore.
To download a dataset or all the files for a competion, we can run the following:
#list the files that are part of a competition!kaggle competitions files -c "house-prices-advanced-regression-techniques"name size creationDate --------------------- ---------- -------------------------- data_description.txt 13370 2019-12-15 21:33:35.157000 sample_submission.csv 31939 2019-12-15 21:33:35.224000 test.csv 451405 2019-12-15 21:33:35.212000 train.csv 460676 2019-12-15 21:33:35.259000 #download the competion files!kaggle competitions download -c "house-prices-advanced-regression-techniques"Downloading house-prices-advanced-regression-techniques.zip to /Users/brendan.tierney100%|█████████████████████████████████████████| 199k/199k [00:00<00:00, 714kB/s]
If you get a 403 error when running the above commands, just open the kaggle website and log into your account. Then run again.
The download will create a Zip file on your computer, which you’ll need to unzip.
#!apt-get install unzip!unzip house-prices-advanced-regression-techniques.zip
When unzipped you can now load the dataset into a Pandas dataframe.
import pandas as pd#path to CSV filepath = "train.csv"train_data = pd.read_csv('train.csv')train_data
Or a Spark dataframe.
from pyspark.sql import SparkSession#Create a Spark Sessionspark = SparkSession.builder \ .appName('Kaggle-Data') \ .master('local[*]') \ .getOrCreate()#Spark dataframe - Read CSVdf = spark.read.csv(path)# or if the file has a header record#Spark dataframe - Read CSV with Header df2 = spark.read.option("header", True).csv(path)
An alternative to the above is to use kagglehub package. The download function in this package will download load the files into a local directory
#install kagglehub!pip3 install kagglehubimport kagglehub#download the data fileskagglehub.competition_download('house-prices-advanced-regression-techniques', output_dir='./Kaggle_data', force_download=True)Downloading to ./Kaggle_data/house-prices-advanced-regression-techniques.archive...100%|█████████████████████████████████████████████████████████████████████████████████| 199k/199k [00:00<00:00, 670kB/s]Extracting files...
!ls -l ./Kaggle_datatotal 1888-rw-r--r-- 1 brendan.tierney staff 13370 16 Mar 12:38 data_description.txt-rw-r--r-- 1 brendan.tierney staff 31939 16 Mar 12:38 sample_submission.csv-rw-r--r-- 1 brendan.tierney staff 451405 16 Mar 12:38 test.csv-rw-r--r-- 1 brendan.tierney staff 460676 16 Mar 12:38 train.csv

You must be logged in to post a comment.