
Python
How to download a Kaggle Competition dataset
Kaggle is a popular website for data science and machine learning, where users can participate in machine learning competitions, access an extensive library of open datasets, notebooks and training. It is used by Data scientists and students around the world to learn and test their skills on a wider variety of problems.
One of the first tasks any person using Kaggle will need to do is to download a dataset. One simple way of doing this is by logging into the website and manually downloading the dataset.
But what if you want to automate this step into your Notebook or other Python environment you might be using? Building repeatedly into your projects is an important step, as it can ilimate any postting errors that might occur when perform these manually. The examples give below were all run in a Jupyter Notebook.
First thing to do is to install the kaggle and kagglehub python packages.
!pip3 install kaggle!pip3 install kagglehub
Before we do anything else in the Jupyter Notebook, you will need to log into the Kaggle website and get and API Key Token for your account
Copy the Kaggle API Key and add it to an environment variable. Here is the code to do this in the Jupyter Notebook.
import osos.environ["KAGGLE_API_TOKEN"] = "..."
You can check that it has been set correctly by running
print(os.environ["KAGGLE_API_TOKEN"])
Now we can get on with accessing the Kaggle datasets. This first approach will use the kaggle python package. With this you can use a mixture of command line commands and package functions
#import kaggle packageimport kaggle#use command line to list the datasets - limited output!kaggle datasets list#use a kaggle package function to list competitionsfrom kaggle.api.kaggle_api_extended import KaggleApiapi = KaggleApi()api.authenticate()api.competitions_list_cli()
I’ve not listed the outputs above, as the output would be very long. I’ll leave that for you to explore.
To download a dataset or all the files for a competion, we can run the following:
#list the files that are part of a competition!kaggle competitions files -c "house-prices-advanced-regression-techniques"name size creationDate --------------------- ---------- -------------------------- data_description.txt 13370 2019-12-15 21:33:35.157000 sample_submission.csv 31939 2019-12-15 21:33:35.224000 test.csv 451405 2019-12-15 21:33:35.212000 train.csv 460676 2019-12-15 21:33:35.259000 #download the competion files!kaggle competitions download -c "house-prices-advanced-regression-techniques"Downloading house-prices-advanced-regression-techniques.zip to /Users/brendan.tierney100%|█████████████████████████████████████████| 199k/199k [00:00<00:00, 714kB/s]
If you get a 403 error when running the above commands, just open the kaggle website and log into your account. Then run again.
The download will create a Zip file on your computer, which you’ll need to unzip.
#!apt-get install unzip!unzip house-prices-advanced-regression-techniques.zip
When unzipped you can now load the dataset into a Pandas dataframe.
import pandas as pd#path to CSV filepath = "train.csv"train_data = pd.read_csv('train.csv')train_data
Or a Spark dataframe.
from pyspark.sql import SparkSession#Create a Spark Sessionspark = SparkSession.builder \ .appName('Kaggle-Data') \ .master('local[*]') \ .getOrCreate()#Spark dataframe - Read CSVdf = spark.read.csv(path)# or if the file has a header record#Spark dataframe - Read CSV with Header df2 = spark.read.option("header", True).csv(path)
An alternative to the above is to use kagglehub package. The download function in this package will download load the files into a local directory
#install kagglehub!pip3 install kagglehubimport kagglehub#download the data fileskagglehub.competition_download('house-prices-advanced-regression-techniques', output_dir='./Kaggle_data', force_download=True)Downloading to ./Kaggle_data/house-prices-advanced-regression-techniques.archive...100%|█████████████████████████████████████████████████████████████████████████████████| 199k/199k [00:00<00:00, 670kB/s]Extracting files...
!ls -l ./Kaggle_datatotal 1888-rw-r--r-- 1 brendan.tierney staff 13370 16 Mar 12:38 data_description.txt-rw-r--r-- 1 brendan.tierney staff 31939 16 Mar 12:38 sample_submission.csv-rw-r--r-- 1 brendan.tierney staff 451405 16 Mar 12:38 test.csv-rw-r--r-- 1 brendan.tierney staff 460676 16 Mar 12:38 train.csv
Handling Multi-Column Indexes in Pandas Dataframes
It’s a little annoying when an API changes the structure of the data it returns and you end up with your code breaking. In my case, I experienced it when a dataframe having a single column index went to having a multi-column index. This was a new experience for me, at this time, as I hadn’t really come across it before. The following illustrates one particular case similar (not the same) that you might encounter. In this test/demo scenario I’ll be using the yfinance API to illustrate how you can remove the multi-column index and go back to having a single column index.
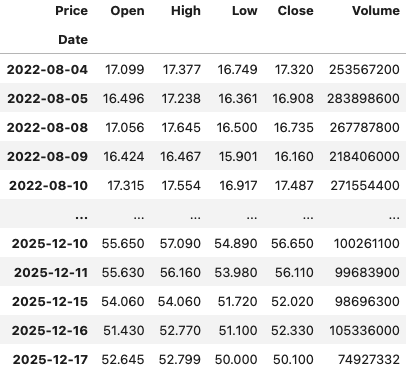
In this demo scenario, we are using yfinance to get data on various stocks. After the data is downloaded we get something like this.
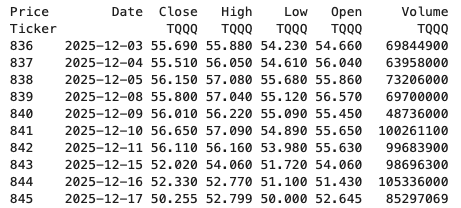
The first step is to do some re-organisation.
df = data.stack(level="Ticker", future_stack=True)
df.index.names = ["Date", "Symbol"]
df = df[["Open", "High", "Low", "Close", "Volume"]]
df = df.swaplevel(0, 1)
df = df.sort_index()
dfThis gives us the data in the following format.
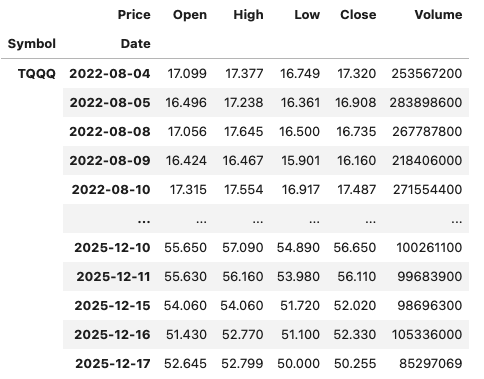
The final part is to extract the data we want by applying a filter.
df.xs(“TQQQ”)
And there we have it.
As I said at the beginning the example above is just to illustrate what you can do.
If this was a real work example of using yfinance, I could just change a parameter setting in the download function, to not use multi_level_index.
data = yf.download(t, start=s_date, interval=time_interval, progress=False, multi_level_index=False)
Creating Test Data in your Database using Faker
A some point everyone needs some test data for their database. There area a number of ways of doing this, and in this post I’ll walk through using the Python library Faker to create some dummy test data (that kind of looks real) in my Oracle Database. I’ll have another post using the GenAI in-database feature available in the Oracle Autonomous Database. So keep an eye out for that.
Faker is one of the available libraries in Python for creating dummy/test data that kind of looks realistic. There are several more. I’m not going to get into the relative advantages and disadvantages of each, so I’ll leave that task to yourself. I’m just going to give you a quick demonstration of what is possible.
One of the key elements of using Faker is that we can set a geograpic location for the data to be generated. We can also set multiples of these and by setting this we can get data generated specific for that/those particular geographic locations. This is useful for when testing applications for different potential markets. In my example below I’m setting my local for USA (en_US).
Here’s the Python code to generate the Test Data with 15,000 records, which I also save to a CSV file.
import pandas as pd
from faker import Faker
import random
from datetime import date, timedelta
#####################
NUM_RECORDS = 15000
LOCALE = 'en_US'
#Initialise Faker
Faker.seed(42)
fake = Faker(LOCALE)
#####################
#Create a function to generate the data
def create_customer_record():
#Customer Gender
gender = random.choice(['Male', 'Female', 'Non-Binary'])
#Customer Name
if gender == 'Male':
name = fake.name_male()
elif gender == 'Female':
name = fake.name_female()
else:
name = fake.name()
#Date of Birth
dob = fake.date_of_birth(minimum_age=18, maximum_age=90)
#Customer Address and other details
address = fake.street_address()
email = fake.email()
city = fake.city()
state = fake.state_abbr()
zip_code = fake.postcode()
full_address = f"{address}, {city}, {state} {zip_code}"
phone_number = fake.phone_number()
#Customer Income
# - annual income between $30,000 and $250,000
income = random.randint(300, 2500) * 100
#Credit Rating
credit_rating = random.choices(['A', 'B', 'C', 'D'], weights=[0.40, 0.30, 0.20, 0.10], k=1)[0]
#Credit Card and Banking details
card_type = random.choice(['visa', 'mastercard', 'amex'])
credit_card_number = fake.credit_card_number(card_type=card_type)
routing_number = fake.aba()
bank_account = fake.bban()
return {
'CUSTOMERID': fake.unique.uuid4(), # Unique identifier
'CUSTOMERNAME': name,
'GENDER': gender,
'EMAIL': email,
'DATEOFBIRTH': dob.strftime('%Y-%m-%d'),
'ANNUALINCOME': income,
'CREDITRATING': credit_rating,
'CUSTOMERADDRESS': full_address,
'ZIPCODE': zip_code,
'PHONENUMBER': phone_number,
'CREDITCARDTYPE': card_type.capitalize(),
'CREDITCARDNUMBER': credit_card_number,
'BANKACCOUNTNUMBER': bank_account,
'ROUTINGNUMBER': routing_number,
}
#Generate the Demo Data
print(f"Generating {NUM_RECORDS} customer records...")
data = [create_customer_record() for _ in range(NUM_RECORDS)]
print("Sample Data Generation complete")
#Convert to Pandas DataFrame
df = pd.DataFrame(data)
print("\n--- DataFrame Sample (First 10 Rows) : sample of columns ---")
# Display relevant columns for verification
display_cols = ['CUSTOMERNAME', 'GENDER', 'DATEOFBIRTH', 'PHONENUMBER', 'CREDITCARDNUMBER', 'CREDITRATING', 'ZIPCODE']
print(df[display_cols].head(10).to_markdown(index=False))
print("\n--- DataFrame Information ---")
print(f"Total Rows: {len(df)}")
print(f"Total Columns: {len(df.columns)}")
print("Data Types:")
print(df.dtypes)The output from the above code gives the following:
Generating 15000 customer records...
Sample Data Generation complete
--- DataFrame Sample (First 10 Rows) : sample of columns ---
| CUSTOMERNAME | GENDER | DATEOFBIRTH | PHONENUMBER | CREDITCARDNUMBER | CREDITRATING | ZIPCODE |
|:-----------------|:-----------|:--------------|:-----------------------|-------------------:|:---------------|----------:|
| Allison Hill | Non-Binary | 1951-03-02 | 479.540.2654 | 2271161559407810 | A | 55488 |
| Mark Ferguson | Non-Binary | 1952-09-28 | 724.523.8849x696 | 348710122691665 | A | 84760 |
| Kimberly Osborne | Female | 1973-08-02 | 001-822-778-2489x63834 | 4871331509839301 | B | 70323 |
| Amy Valdez | Female | 1982-01-16 | +1-880-213-2677x3602 | 4474687234309808 | B | 07131 |
| Eugene Green | Male | 1983-10-05 | (442)678-4980x841 | 4182449353487409 | A | 32519 |
| Timothy Stanton | Non-Binary | 1937-10-13 | (707)633-7543x3036 | 344586850142947 | A | 14669 |
| Eric Parker | Male | 1964-09-06 | 577-673-8721x48951 | 2243200379176935 | C | 86314 |
| Lisa Ball | Non-Binary | 1971-09-20 | 516.865.8760 | 379096705466887 | A | 93092 |
| Garrett Gibson | Male | 1959-07-05 | 001-437-645-2991 | 349049663193149 | A | 15494 |
| John Petersen | Male | 1978-02-14 | 367.683.7770 | 2246349578856859 | A | 11722 |
--- DataFrame Information ---
Total Rows: 15000
Total Columns: 14
Data Types:
CUSTOMERID object
CUSTOMERNAME object
GENDER object
EMAIL object
DATEOFBIRTH object
ANNUALINCOME int64
CREDITRATING object
CUSTOMERADDRESS object
ZIPCODE object
PHONENUMBER object
CREDITCARDTYPE object
CREDITCARDNUMBER object
BANKACCOUNTNUMBER object
ROUTINGNUMBER objectHaving generated the Test data, we now need to get it into the database. There a various ways of doing this. As we are already using Python I’ll illustrate getting the data into the Database below. An alternative option is to use SQL Command Line (SQLcl) and the LOAD feature in that tool.
Here’s the Python code to load the data. I’m using the oracledb python library.
### Connect to Database
import oracledb
p_username = "..."
p_password = "..."
#Give OCI Wallet location and details
try:
con = oracledb.connect(user=p_username, password=p_password, dsn="adb26ai_high",
config_dir="/Users/brendan.tierney/Dropbox/Wallet_ADB26ai",
wallet_location="/Users/brendan.tierney/Dropbox/Wallet_ADB26ai",
wallet_password=p_walletpass)
except Exception as e:
print('Error connecting to the Database')
print(f'Error:{e}')
print(con)### Create Customer Table
drop_table = 'DROP TABLE IF EXISTS demo_customer'
cre_table = '''CREATE TABLE DEMO_CUSTOMER (
CustomerID VARCHAR2(50) PRIMARY KEY,
CustomerName VARCHAR2(50),
Gender VARCHAR2(10),
Email VARCHAR2(50),
DateOfBirth DATE,
AnnualIncome NUMBER(10,2),
CreditRating VARCHAR2(1),
CustomerAddress VARCHAR2(100),
ZipCode VARCHAR2(10),
PhoneNumber VARCHAR2(50),
CreditCardType VARCHAR2(10),
CreditCardNumber VARCHAR2(30),
BankAccountNumber VARCHAR2(30),
RoutingNumber VARCHAR2(10) )'''
cur = con.cursor()
print('--- Dropping DEMO_CUSTOMER table ---')
cur.execute(drop_table)
print('--- Creating DEMO_CUSTOMER table ---')
cur.execute(cre_table)
print('--- Table Created ---')### Insert Data into Table
insert_data = '''INSERT INTO DEMO_CUSTOMER values (:1, :2, :3, :4, :5, :6, :7, :8, :9, :10, :11, :12, :13, :14)'''
print("--- Inserting records ---")
cur.executemany(insert_data, df )
con.commit()
print("--- Saving to CSV ---")
df.to_csv('/Users/brendan.tierney/Dropbox/DEMO_Customer_data.csv', index=False)
print("- Finished -")### Close Connections to DB
con.close()and to prove the records got inserted we can connect to the schema using SQLcl and check.
What a difference a Bind Variable makes
To bind or not to bind, that is the question?
Over the years, I heard and read about using Bind variables and how important they are, particularly when it comes to the efficient execution of queries. By using bind variables, the optimizer will reuse the execution plan from the cache rather than generating it each time. Recently, I had conversations about this with a couple of different groups, and they didn’t really believe me and they asked me to put together a demonstration. One group said they never heard of ‘prepared statements’, ‘bind variables’, ‘parameterised query’, etc., which was a little surprising.
The following is a subset of what I demonstrated to them to illustrate the benefits and potential benefits.
Here is a basic example of a typical scenario where we have a SQL query being constructed using concatenation.
select * from order_demo where order_id = || 'i';That statement looks simple and harmless. When we try to check the EXPLAIN plan from the optimizer we will get an error, so let’s just replace it with a number, because that’s what the query will end up being like.
select * from order_demo where order_id = 1;When we check the Explain Plan, we get the following. It looks like a good execution plan as it is using the index and then doing a ROWID lookup on the table. The developers were happy, and that’s what those recent conversations were about and what they are missing.
-------------------------------------------------------------
| Id | Operation | Name | E-Rows |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | TABLE ACCESS BY INDEX ROWID| ORDER_DEMO | 1 |
|* 2 | INDEX UNIQUE SCAN | SYS_C0014610 | 1 |
-------------------------------------------------------------
The missing part in their understanding was what happens every time they run their query. The Explain Plan looks good, so what’s the problem? The problem lies with the Optimizer evaluating the execution plan every time the query is issued. But the developers came back with the idea that this won’t happen because the execution plan is cached and will be reused. The problem with this is how we can test this, and what is the alternative, in this case, using bind variables (which was my suggestion).
Let’s setup a simple test to see what happens. Here is a simple piece of PL/SQL code which will look 100K times to retrieve just one row. This is very similar to what they were running.
DECLARE
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF4'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = '||i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF4'));
END;
/When we run this test against a 23.7 Oracle Database running in a VM on my laptop, this completes in little over 2 minutes
Start time : 16:26:04:5527
End time : 16:28:13:4820
PL/SQL procedure successfully completed.
Elapsed: 00:02:09.158The developers seemed happy with that time! Ok, but let’s test it using bind variables and see if it’s any different. There are a few different ways of setting up bind variables. The PL/SQL code below is one example.
DECLARE
order_rec ORDER_DEMO%rowtype;
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF9'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = :1' using i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF9'));
END;
/
Start time : 16:31:39:162619000
End time : 16:31:40:479301000
PL/SQL procedure successfully completed.
Elapsed: 00:00:01.363This just took a little over one second to complete. Let me say that again, a little over one second to complete. We went from taking just over two minutes to run, down to just over one second to run.
The developers were a little surprised or more correctly, were a little shocked. But they then said the problem with that demonstration is that it is running directly in the Database. It will be different running it in Python across the network.
Ok, let me set up the same/similar demonstration using Python. The image below show some back Python code to connect to the database, list the tables in the schema and to create the test table for our demonstration

The first demonstration is to measure the timing for 100K records using the concatenation approach. I
# Demo - The SLOW way - concat values
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
# only loop 10,000 instead of 100,000 - impact of network latency
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = " + str(i))
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:45:29:523020
End time: 16:49:15:610094This took just under four minutes to complete. With PL/SQL it took approx two minutes. The extrat time is due to the back and forth nature of the client-server communications between the Python code and the Database. The developers were a little unhappen with this result.
The next step for the demonstrataion was to use bind variables. As with most languages there are a number of different ways to write and format these. Below is one example, but some of the others were also tried and give the same timing.
#Bind variables example - by name
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = :order_num", order_num=i )
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:53:00:479468
End time: 16:54:14:197552This took 1 minute 14 seconds. [Read that sentence again]. Compared to approx four minutes, and yes the other bind variable options has similar timing.
To answer the quote at the top of this post, “To bind or not to bind, that is the question?”, the answer is using Bind Variables, Prepared Statements, Parameterised Query, etc will make you queries and applications run a lot quicker. The optimizer will see the structure of the query, will see the parameterised parts of it, will see the execution plan already exists in the cache and will use it instead of generating the execution plan again. Thereby saving time for frequently executed queries which might just have a different value for one or two parts of a WHERE clause.
OCI Speech Real-time Capture
Capturing Speech-to-Text is a straight forward step. I’ve written previously about this, giving an example. But what if you want the code to constantly monitor for text input, giving a continuous. For this we need to use the asyncio python library. Using the OCI Speech-to-Text API in combination with asyncio we can monitor a microphone (speech input) on a continuous basis.
There are a few additional configuration settings needed, including configuring a speech-to-text listener. Here is an example of what is needed
lass MyListener(RealtimeSpeechClientListener):
def on_result(self, result):
if result["transcriptions"][0]["isFinal"]:
print(f"1-Received final results: {transcription}")
else:
print(f"2-{result['transcriptions'][0]['transcription']} \n")
def on_ack_message(self, ackmessage):
return super().on_ack_message(ackmessage)
def on_connect(self):
return super().on_connect()
def on_connect_message(self, connectmessage):
return super().on_connect_message(connectmessage)
def on_network_event(self, ackmessage):
return super().on_network_event(ackmessage)
def on_error(self, error_message):
return super().on_error(error_message)
def on_close(self, error_code, error_message):
print(f'\nOCI connection closing.')
async def start_realtime_session(customizations=[], compartment_id=None, region=None):
rt_client = RealtimeSpeechClient(
config=config,
realtime_speech_parameters=realtime_speech_parameters,
listener=MyListener(),
service_endpoint=realtime_speech_url,
signer=None, #authenticator(),
compartment_id=compartment_id,
)
asyncio.create_task(send_audio(rt_client))
if __name__ == "__main__":
asyncio.run(
start_realtime_session(
customizations=customization_ids,
compartment_id=COMPARTMENT_ID,
region=REGION_ID,
)
)Additional customizations can be added to the Listener, for example, what to do with the Audio captured, what to do with the text, how to mange the speech-to-text (there are lots of customizations)
Unlock Text Analytics with Oracle OCI Python – Part 2
This is my second post on using Oracle OCI Language service to perform Text Analytics. These include Language Detection, Text Classification, Sentiment Analysis, Key Phrase Extraction, Named Entity Recognition, Private Data detection and masking, and Healthcare NLP.
In my Previous post (Part 1), I covered examples on Language Detection, Text Classification and Sentiment Analysis.
In this post (Part 2), I’ll cover:
- Key Phrase
- Named Entity Recognition
- Detect private information and marking
Make sure you check out Part 1 for details on setting up the client and establishing a connection. These details are omitted in the examples below.
Key Phrase Extraction
With Key Phrase Extraction, it aims to identify the key works and/or phrases from the text. The keywords/phrases are selected based on what are the main topics in the text along with the confidence score. The text is parsed to extra the words/phrase that are important in the text. This can aid with identifying the key aspects of the document without having to read it. Care is needed as these words/phrases do not represent the meaning implied in the text.
Using some of the same texts used in Part-1, let’s see what gets generated for the text about a Hotel experience.
t_doc = oci.ai_language.models.TextDocument(
key="Demo",
text="This hotel is a bad place, I would strongly advise against going there. There was one helpful member of staff",
language_code="en")
key_phrase = ai_language_client.batch_detect_language_key_phrases((oci.ai_language.models.BatchDetectLanguageKeyPhrasesDetails(documents=[t_doc])))
print(key_phrase.data)
print('==========')
for i in range(len(key_phrase.data.documents)):
for j in range(len(key_phrase.data.documents[i].key_phrases)):
print("phrase: ", key_phrase.data.documents[i].key_phrases[j].text +' [' + str(key_phrase.data.documents[i].key_phrases[j].score) + ']'){
"documents": [
{
"key": "Demo",
"key_phrases": [
{
"score": 0.9998106383818767,
"text": "bad place"
},
{
"score": 0.9998106383818767,
"text": "one helpful member"
},
{
"score": 0.9944029848214838,
"text": "staff"
},
{
"score": 0.9849306609397931,
"text": "hotel"
}
],
"language_code": "en"
}
],
"errors": []
}
==========
phrase: bad place [0.9998106383818767]
phrase: one helpful member [0.9998106383818767]
phrase: staff [0.9944029848214838]
phrase: hotel [0.9849306609397931]The output from the Key Phrase Extraction is presented into two formats about. The first is the JSON object returned from the function, containing the phrases and their confidence score. The second (below the ==========) is a formatted version of the same JSON object but parsed to extract and present the data in a more compact manner.
The next piece of text to be examined is taken from an article on the F1 website about a change of divers.
text_f1 = "Red Bull decided to take swift action after Liam Lawsons difficult start to the 2025 campaign, demoting him to Racing Bulls and promoting Yuki Tsunoda to the senior team alongside reigning world champion Max Verstappen. F1 Correspondent Lawrence Barretto explains why… Sergio Perez had endured a painful campaign that saw him finish a distant eighth in the Drivers Championship for Red Bull last season – while team mate Verstappen won a fourth successive title – and after sticking by him all season, the team opted to end his deal early after Abu Dhabi finale."
t_doc = oci.ai_language.models.TextDocument(
key="Demo",
text=text_f1,
language_code="en")
key_phrase = ai_language_client.batch_detect_language_key_phrases(oci.ai_language.models.BatchDetectLanguageKeyPhrasesDetails(documents=[t_doc]))
print(key_phrase.data)
print('==========')
for i in range(len(key_phrase.data.documents)):
for j in range(len(key_phrase.data.documents[i].key_phrases)):
print("phrase: ", key_phrase.data.documents[i].key_phrases[j].text +' [' + str(key_phrase.data.documents[i].key_phrases[j].score) + ']')I won’t include all the output and the following shows the key phrases in the compact format
phrase: red bull [0.9991468440416812]
phrase: swift action [0.9991468440416812]
phrase: liam lawsons difficult start [0.9991468440416812]
phrase: 2025 campaign [0.9991468440416812]
phrase: racing bulls [0.9991468440416812]
phrase: promoting yuki tsunoda [0.9991468440416812]
phrase: senior team [0.9991468440416812]
phrase: sergio perez [0.9991468440416812]
phrase: painful campaign [0.9991468440416812]
phrase: drivers championship [0.9991468440416812]
phrase: red bull last season [0.9991468440416812]
phrase: team mate verstappen [0.9991468440416812]
phrase: fourth successive title [0.9991468440416812]
phrase: all season [0.9991468440416812]
phrase: abu dhabi finale [0.9991468440416812]
phrase: team [0.9420016064526977]While some aspects of this is interesting, care is needed to not overly rely upon it. It really depends on the usecase.
Named Entity Recognition
For Named Entity Recognition is a natural language process for finding particular types of entities listed as words or phrases in the text. The named entities are a defined list of items. For OCI Language there is a list available here. Some named entities have a sub entities. The return JSON object from the function has a format like the following.
{
"documents": [
{
"entities": [
{
"length": 5,
"offset": 5,
"score": 0.969588577747345,
"sub_type": "FACILITY",
"text": "hotel",
"type": "LOCATION"
},
{
"length": 27,
"offset": 82,
"score": 0.897526216506958,
"sub_type": null,
"text": "one helpful member of staff",
"type": "QUANTITY"
}
],
"key": "Demo",
"language_code": "en"
}
],
"errors": []
}For each named entity discovered the returned object will contain the Text identifed, the Entity Type, the Entity Subtype, Confidence Score, offset and length.
Using the text samples used previous, let’s see what gets produced. The first example is for the hotel review.
t_doc = oci.ai_language.models.TextDocument(
key="Demo",
text="This hotel is a bad place, I would strongly advise against going there. There was one helpful member of staff",
language_code="en")
named_entities = ai_language_client.batch_detect_language_entities(
batch_detect_language_entities_details=oci.ai_language.models.BatchDetectLanguageEntitiesDetails(documents=[t_doc]))
for i in range(len(named_entities.data.documents)):
for j in range(len(named_entities.data.documents[i].entities)):
print("Text: ", named_entities.data.documents[i].entities[j].text, ' [' + named_entities.data.documents[i].entities[j].type + ']'
+ '[' + str(named_entities.data.documents[i].entities[j].sub_type) + ']' + '{offset:'
+ str(named_entities.data.documents[i].entities[j].offset) + '}')Text: hotel [LOCATION][FACILITY]{offset:5}
Text: one helpful member of staff [QUANTITY][None]{offset:82}The last two lines above are the formatted output of the JSON object. It contains two named entities. The first one is for the text “hotel” and it has a Entity Type of Location, and a Sub Entitity Type of Location. The second named entity is for a long piece of string and for this it has a Entity Type of Quantity, but has no Sub Entity Type.
Now let’s see what is creates for the F1 text. (the text has been given above and the code is very similar/same as above).
Text: Red Bull [ORGANIZATION][None]{offset:0}
Text: swift [ORGANIZATION][None]{offset:25}
Text: Liam Lawsons [PERSON][None]{offset:44}
Text: 2025 [DATETIME][DATE]{offset:80}
Text: Yuki Tsunoda [PERSON][None]{offset:138}
Text: senior [QUANTITY][AGE]{offset:158}
Text: Max Verstappen [PERSON][None]{offset:204}
Text: F1 [ORGANIZATION][None]{offset:220}
Text: Lawrence Barretto [PERSON][None]{offset:237}
Text: Sergio Perez [PERSON][None]{offset:269}
Text: campaign [EVENT][None]{offset:304}
Text: eighth in the [QUANTITY][None]{offset:343}
Text: Drivers Championship [EVENT][None]{offset:357}
Text: Red Bull [ORGANIZATION][None]{offset:382}
Text: Verstappen [PERSON][None]{offset:421}
Text: fourth successive title [QUANTITY][None]{offset:438}
Text: Abu Dhabi [LOCATION][GPE]{offset:545}Detect Private Information and Marking
The ability to perform data masking has been available in SQL for a long time. There are lots of scenarios where masking is needed and you are not using a Database or not at that particular time.
With Detect Private Information or Personal Identifiable Information the OCI AI function search for data that is personal and gives you options on how to present this back to the users. Examples of the types of data or Entity Types it will detect include Person, Adddress, Age, SSN, Passport, Phone Numbers, Bank Accounts, IP Address, Cookie details, Private and Public keys, various OCI related information, etc. The list goes on. Check out the documentation for more details on these. Unfortunately the documentation for how the Python API works is very limited.
The examples below illustrate some of the basic options. But there is lots more you can do with this feature like defining you own rules.
For these examples, I’m going to use the following text which I’ve assigned to a variable called text_demo.
Hi Martin. Thanks for taking my call on 1/04/2025. Here are the details you requested. My Bank Account Number is 1234-5678-9876-5432 and my Bank Branch is Main Street, Dublin. My Date of Birth is 29/02/1993 and I’ve been living at my current address for 15 years. Can you also update my email address to brendan.tierney@email.com. If toy have any problems with this you can contact me on +353-1-493-1111. Thanks for your help. Brendan.
m_mode = {"ALL":{"mode":'MASK'}}
t_doc = oci.ai_language.models.TextDocument(key="Demo", text=text_demo,language_code="en")
pii_entities = ai_language_client.batch_detect_language_pii_entities(oci.ai_language.models.BatchDetectLanguagePiiEntitiesDetails(documents=[t_doc], masking=m_mode))
print(text_demo)
print('--------------------------------------------------------------------------------')
print(pii_entities.data.documents[0].masked_text)
print('--------------------------------------------------------------------------------')
for i in range(len(pii_entities.data.documents)):
for j in range(len(pii_entities.data.documents[i].entities)):
print("phrase: ", pii_entities.data.documents[i].entities[j].text +' [' + str(pii_entities.data.documents[i].entities[j].type) + ']')
Hi Martin. Thanks for taking my call on 1/04/2025. Here are the details you requested. My Bank Account Number is 1234-5678-9876-5432 and my Bank Branch is Main Street, Dublin. My Date of Birth is 29/02/1993 and I've been living at my current address for 15 years. Can you also update my email address to brendan.tierney@email.com. If toy have any problems with this you can contact me on +353-1-493-1111. Thanks for your help. Brendan.
--------------------------------------------------------------------------------
Hi ******. Thanks for taking my call on *********. Here are the details you requested. My Bank Account Number is ******************* and my Bank Branch is Main Street, Dublin. My Date of Birth is ********** and I've been living at my current address for ********. Can you also update my email address to *************************. If toy have any problems with this you can contact me on ***************. Thanks for your help. *******.
--------------------------------------------------------------------------------
phrase: Martin [PERSON]
phrase: 1/04/2025 [DATE_TIME]
phrase: 1234-5678-9876-5432 [CREDIT_DEBIT_NUMBER]
phrase: 29/02/1993 [DATE_TIME]
phrase: 15 years [DATE_TIME]
phrase: brendan.tierney@email.com [EMAIL]
phrase: +353-1-493-1111 [TELEPHONE_NUMBER]
phrase: Brendan [PERSON]The above this the basic level of masking.
A second option is to use the REMOVE mask. For this, change the mask format to the following.
m_mode = {"ALL":{'mode':'REMOVE'}} For this option the indentified information is removed from the text.
Hi . Thanks for taking my call on . Here are the details you requested. My Bank Account Number is and my Bank Branch is Main Street, Dublin. My Date of Birth is and I've been living at my current address for . Can you also update my email address to . If toy have any problems with this you can contact me on . Thanks for your help. .
--------------------------------------------------------------------------------
phrase: Martin [PERSON]
phrase: 1/04/2025 [DATE_TIME]
phrase: 1234-5678-9876-5432 [CREDIT_DEBIT_NUMBER]
phrase: 29/02/1993 [DATE_TIME]
phrase: 15 years [DATE_TIME]
phrase: brendan.tierney@email.com [EMAIL]
phrase: +353-1-493-1111 [TELEPHONE_NUMBER]
phrase: Brendan [PERSON]For the REPLACE option we have.
m_mode = {"ALL":{'mode':'REPLACE'}} Which gives us the following, where we can see the key information is removed and replace with the name of Entity Type.
Hi <PERSON>. Thanks for taking my call on <DATE_TIME>. Here are the details you requested. My Bank Account Number is <CREDIT_DEBIT_NUMBER> and my Bank Branch is Main Street, Dublin. My Date of Birth is <DATE_TIME> and I've been living at my current address for <DATE_TIME>. Can you also update my email address to <EMAIL>. If toy have any problems with this you can contact me on <TELEPHONE_NUMBER>. Thanks for your help. <PERSON>.
--------------------------------------------------------------------------------
phrase: Martin [PERSON]
phrase: 1/04/2025 [DATE_TIME]
phrase: 1234-5678-9876-5432 [CREDIT_DEBIT_NUMBER]
phrase: 29/02/1993 [DATE_TIME]
phrase: 15 years [DATE_TIME]
phrase: brendan.tierney@email.com [EMAIL]
phrase: +353-1-493-1111 [TELEPHONE_NUMBER]
phrase: Brendan [PERSON]We can also change the character used for the masking. In this example we change the masking character to + symbol.
m_mode = {"ALL":{'mode':'MASK','maskingCharacter':'+'}} Hi ++++++. Thanks for taking my call on +++++++++. Here are the details you requested. My Bank Account Number is +++++++++++++++++++ and my Bank Branch is Main Street, Dublin. My Date of Birth is ++++++++++ and I've been living at my current address for ++++++++. Can you also update my email address to +++++++++++++++++++++++++. If toy have any problems with this you can contact me on +++++++++++++++. Thanks for your help. +++++++.I mentioned at the start of this section there was lots of options available to you, including defining your own rules, using regular expressions, etc. Let me know if you’re interested in exploring some of these and I can share a few more examples.
Unlock Text Analytics with Oracle OCI Python – Part 1
Oracle OCI has a number of features that allows you to perform Text Analytics such as Language Detection, Text Classification, Sentiment Analysis, Key Phrase Extraction, Named Entity Recognition, Private Data detection and masking, and Healthcare NLP.

While some of these have particular (and in some instances limited) use cases, the following examples will illustrate some of the main features using the OCI Python library. Why am I using Python to illustrate these? This is because most developers are using Python to build applications.
In this post, the Python examples below will cover the following:
- Language Detection
- Text Classification
- Sentiment Analysis
In my next post on this topic, I’ll cover:
- Key Phrase
- Named Entity Recognition
- Detect private information and marking
Before you can use any of the OCI AI Services, you need to set up a config file on your computer. This will contain the details necessary to establish a secure connection to your OCI tendency. Check out this blog post about setting this up.
The following Python examples illustrate what is possible for each feature. In the first example, I include what is needed for the config file. This is not repeated in the examples that follow, but it is still needed.
Language Detection
Let’s begin with a simple example where we provide a simple piece of text and as OCI Language Service, using OCI Python, to detect the primary language for the text and display some basic information about this prediction.
import oci
from oci.config import from_file
#Read in config file - this is needed for connecting to the OCI AI Services
CONFIG_PROFILE = "DEFAULT"
config = oci.config.from_file('~/.oci/config', profile_name=CONFIG_PROFILE)
###
ai_language_client = oci.ai_language.AIServiceLanguageClient(config)
# French :
text_fr = "Bonjour et bienvenue dans l'analyse de texte à l'aide de ce service cloud"
response = ai_language_client.detect_dominant_language(
oci.ai_language.models.DetectLanguageSentimentsDetails(
text=text_fr
)
)
print(response.data.languages[0].name)
----------
FrenchIn this example, I’ve a simple piece of French (for any native French speakers, I do apologise). We can see the language was identified as French. Let’s have a closer look at what is returned by the OCI function.
print(response.data)
----------
{
"languages": [
{
"code": "fr",
"name": "French",
"score": 1.0
}
]
}We can see from the above, the object contains the language code, the full name of the language and the score to indicate how strong or how confident the function is with the prediction. When the text contains two or more languages, the function will return the primary language used.
Note: OCI Language can detect at least 113 different languages. Check out the full list here.
Let’s give it a try with a few other languages, including Irish, which localised to certain parts of Ireland. Using the same code as above, I’ve included the same statement (google) translated into other languages. The code loops through each text statement and detects the language.
import oci
from oci.config import from_file
###
CONFIG_PROFILE = "DEFAULT"
config = oci.config.from_file('~/.oci/config', profile_name=CONFIG_PROFILE)
###
ai_language_client = oci.ai_language.AIServiceLanguageClient(config)
# French :
text_fr = "Bonjour et bienvenue dans l'analyse de texte à l'aide de ce service cloud"
# German:
text_ger = "Guten Tag und willkommen zur Textanalyse mit diesem Cloud-Dienst"
# Danish
text_dan = "Goddag, og velkommen til at analysere tekst ved hjælp af denne skytjeneste"
# Italian
text_it = "Buongiorno e benvenuti all'analisi del testo tramite questo servizio cloud"
# English:
text_eng = "Good day, and welcome to analysing text using this cloud service"
# Irish
text_irl = "Lá maith, agus fáilte romhat chuig anailís a dhéanamh ar théacs ag baint úsáide as an tseirbhís scamall seo"
for text in [text_eng, text_ger, text_dan, text_it, text_irl]:
response = ai_language_client.detect_dominant_language(
oci.ai_language.models.DetectLanguageSentimentsDetails(
text=text
)
)
print('[' + response.data.languages[0].name + ' ('+ str(response.data.languages[0].score) +')' + '] '+ text)
----------
[English (1.0)] Good day, and welcome to analysing text using this cloud service
[German (1.0)] Guten Tag und willkommen zur Textanalyse mit diesem Cloud-Dienst
[Danish (1.0)] Goddag, og velkommen til at analysere tekst ved hjælp af denne skytjeneste
[Italian (1.0)] Buongiorno e benvenuti all'analisi del testo tramite questo servizio cloud
[Irish (1.0)] Lá maith, agus fáilte romhat chuig anailís a dhéanamh ar théacs ag baint úsáide as an tseirbhís scamall seoWhen you run this code yourself, you’ll notice how quick the response time is for each.
Text Classification
Now that we can perform some simple language detections, we can move on to some more insightful functions. The first of these is Text Classification. With Text Classification, it will analyse the text to identify categories and a confidence score of what is covered in the text. Let’s have a look at an example using the English version of the text used above. This time, we need to perform two steps. The first is to set up and prepare the document to be sent. The second step is to perform the classification.
### Text Classification
text_document = oci.ai_language.models.TextDocument(key="Demo", text=text_eng, language_code="en")
text_class_resp = ai_language_client.batch_detect_language_text_classification(
batch_detect_language_text_classification_details=oci.ai_language.models.BatchDetectLanguageTextClassificationDetails(
documents=[text_document]
)
)
print(text_class_resp.data)
----------
{
"documents": [
{
"key": "Demo",
"language_code": "en",
"text_classification": [
{
"label": "Internet and Communications/Web Services",
"score": 1.0
}
]
}
],
"errors": []
}We can see it has correctly identified the text is referring to or is about “Internet and Communications/Web Services”. For a second example, let’s use some text about F1. The following is taken from an article on F1 app and refers to the recent Driver issues, and we’ll use the first two paragraphs.
{
"documents": [
{
"key": "Demo",
"language_code": "en",
"text_classification": [
{
"label": "Sports and Games/Motor Sports",
"score": 1.0
}
]
}
],
"errors": []
}We can format this response object as follows.
print(text_class_resp.data.documents[0].text_classification[0].label
+ ' [' + str(text_class_resp.data.documents[0].text_classification[0].score) + ']')
----------
Sports and Games/Motor Sports [1.0]It is possible to get multiple classifications being returned. To handle this we need to use a couple of loops.
for i in range(len(text_class_resp.data.documents)):
for j in range(len(text_class_resp.data.documents[i].text_classification)):
print("Label: ", text_class_resp.data.documents[i].text_classification[j].label)
print("Score: ", text_class_resp.data.documents[i].text_classification[j].score)
----------
Label: Sports and Games/Motor Sports
Score: 1.0Yet again, it correctly identified the type of topic area for the text. At this point, you are probably starting to get ideas about how this can be used and in what kinds of scenarios. This list will probably get longer over time.
Sentiement Analysis
For Sentiment Analysis we are looking to gauge the mood or tone of a text. For example, we might be looking to identify opinions, appraisals, emotions, attitudes towards a topic or person or an entity. The function returned an object containing a positive, neutral, mixed and positive sentiments and a confidence score. This feature currently supports English and Spanish.
The Sentiment Analysis function provides two way of analysing the text:
- At a Sentence level
- Looks are certain Aspects of the text. This identifies parts/words/phrase and determines the sentiment for each
Let’s start with the Sentence level Sentiment Analysis with a piece of text containing two sentences with both negative and positive sentiments.
#Sentiment analysis
text = "This hotel was in poor condition and I'd recommend not staying here. There was one helpful member of staff"
text_document = oci.ai_language.models.TextDocument(key="Demo", text=text, language_code="en")
text_doc=oci.ai_language.models.BatchDetectLanguageSentimentsDetails(documents=[text_document])
text_sentiment_resp = ai_language_client.batch_detect_language_sentiments(text_doc, level=["SENTENCE"])
print (text_sentiment_resp.data)The response object gives us:
{
"documents": [
{
"aspects": [],
"document_scores": {
"Mixed": 0.3458947,
"Negative": 0.41229093,
"Neutral": 0.0061426135,
"Positive": 0.23567174
},
"document_sentiment": "Negative",
"key": "Demo",
"language_code": "en",
"sentences": [
{
"length": 68,
"offset": 0,
"scores": {
"Mixed": 0.17541811,
"Negative": 0.82458186,
"Neutral": 0.0,
"Positive": 0.0
},
"sentiment": "Negative",
"text": "This hotel was in poor condition and I'd recommend not staying here."
},
{
"length": 37,
"offset": 69,
"scores": {
"Mixed": 0.5163713,
"Negative": 0.0,
"Neutral": 0.012285227,
"Positive": 0.4713435
},
"sentiment": "Mixed",
"text": "There was one helpful member of staff"
}
]
}
],
"errors": []
}There are two parts to this object. The first part gives us the overall Sentiment for the text, along with the confidence scores for all possible sentiments. The second part of the object breaks the test into individual sentences and gives the Sentiment and confidence scores for the sentence. Overall, the text used in “Negative” with a confidence score of 0.41229093. When we look at the sentences, we can see the first sentence is “Negative” and the second sentence is “Mixed”.
When we switch to using Aspect we can see the difference in the response.
text_sentiment_resp = ai_language_client.batch_detect_language_sentiments(text_doc, level=["ASPECT"])
print (text_sentiment_resp.data)The response object gives us:
{
"documents": [
{
"aspects": [
{
"length": 5,
"offset": 5,
"scores": {
"Mixed": 0.17299445074935532,
"Negative": 0.8268503302365734,
"Neutral": 0.0,
"Positive": 0.0001552190140712097
},
"sentiment": "Negative",
"text": "hotel"
},
{
"length": 9,
"offset": 23,
"scores": {
"Mixed": 0.0020200687053503,
"Negative": 0.9971282906307877,
"Neutral": 0.0,
"Positive": 0.0008516406638620019
},
"sentiment": "Negative",
"text": "condition"
},
{
"length": 6,
"offset": 91,
"scores": {
"Mixed": 0.0,
"Negative": 0.002300517913679934,
"Neutral": 0.023815747524769032,
"Positive": 0.973883734561551
},
"sentiment": "Positive",
"text": "member"
},
{
"length": 5,
"offset": 101,
"scores": {
"Mixed": 0.10319573538533408,
"Negative": 0.2070680870320537,
"Neutral": 0.0,
"Positive": 0.6897361775826122
},
"sentiment": "Positive",
"text": "staff"
}
],
"document_scores": {},
"document_sentiment": "",
"key": "Demo",
"language_code": "en",
"sentences": []
}
],
"errors": []
}The different aspects are extracted, and the sentiment for each within the text is determined. What you need to look out for are the labels “text” and “sentiment.
python-oracledb driver version 3 – load data into pandas df
The Python Oracle driver had a new release recently (version 3) and with it comes a new way to load data from a Table into a Pandas dataframe. This can now be done using the pyarrow library. Here’s an example:
import oracledb ora
import pyarrow py
import pandas
#create a connection to the database
con = ora.connect( <enter your connection details> )
query = "select cust_id, cust_first_name, cust_last_name, cust_city from customers"
#get Oracle DF and set array size - care is needed for setting this
ora_df = con.fetch_df_all(statement=query, arraysize=2000)
#run query and return into Pandas Dataframe
# using pyarrow and the to_pandas() function
df = py.Table.from_arrays(ora_df.column_arrays(), names=ora_df.columns()).to_pandas()
print(df.columns)Once you get used to the syntax it is a simpler way to get the data into dataframe.
Oracle Object Storage – Parallel Downloading
In previous posts, I’ve given example Python code (and functions) for processing files into and out of OCI Object and Bucket Storage. One of these previous posts includes code and a demonstration of uploading files to an OCI Bucket using the multiprocessing package in Python.
Building upon these previous examples, the code below will download a Bucket using parallel processing. Like my last example, this code is based on the example code I gave in an earlier post on functions within a Jupyter Notebook.
Here’s the code.
import oci
import os
import argparse
from multiprocessing import Process
from glob import glob
import time
####
def upload_file(config, NAMESPACE, b, f, num):
file_exists = os.path.isfile(f)
if file_exists == True:
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_storage_client.put_object(NAMESPACE, b, os.path.basename(f), open(f,'rb'))
print(f'. Finished {num} uploading {f} in {round(time.time()-start_time,2)} seconds')
except Exception as e:
print(f'Error uploading file {num}. Try again.')
print(e)
else:
print(f'... File {f} does not exist or cannot be found. Check file name and full path')
####
def check_bucket_exists(config, NAMESPACE, b_name):
#check if Bucket exists
is_there = False
object_storage_client = oci.object_storage.ObjectStorageClient(config)
l_b = object_storage_client.list_buckets(NAMESPACE, config.get("tenancy")).data
for bucket in l_b:
if bucket.name == b_name:
is_there = True
if is_there == True:
print(f'Bucket {b_name} exists.')
else:
print(f'Bucket {b_name} does not exist.')
return is_there
####
def download_bucket_file(config, NAMESPACE, b, d, f, num):
print(f'..Starting Download File ({num}):',f, ' from Bucket', b, ' at ', time.strftime("%H:%M:%S"))
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
get_obj = object_storage_client.get_object(NAMESPACE, b, f)
with open(os.path.join(d, f), 'wb') as f:
for chunk in get_obj.data.raw.stream(1024 * 1024, decode_content=False):
f.write(chunk)
print(f'..Finished Download ({num}) in ', round(time.time()-start_time,2), 'seconds.')
except:
print(f'Error trying to download file {f}. Check parameters and try again')
####
if __name__ == "__main__":
#setup for OCI
config = oci.config.from_file()
object_storage = oci.object_storage.ObjectStorageClient(config)
NAMESPACE = object_storage.get_namespace().data
####
description = "\n".join(["Upload files in parallel to OCI storage.",
"All files in <directory> will be uploaded. Include '/' at end.",
"",
"<bucket_name> must already exist."])
parser = argparse.ArgumentParser(description=description,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(dest='bucket_name',
help="Name of object storage bucket")
parser.add_argument(dest='directory',
help="Path to local directory containing files to upload.")
args = parser.parse_args()
####
bucket_name = args.bucket_name
directory = args.directory
if not os.path.isdir(directory):
parser.usage()
else:
dir = directory + os.path.sep + "*"
start_time = time.time()
print('Starting Downloading Bucket - Parallel:', bucket_name, ' at ', time.strftime("%H:%M:%S"))
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_list = object_storage_client.list_objects(NAMESPACE, bucket_name).data
count = 0
for i in object_list.objects:
count+=1
print(f'... {count} files to download')
proc_list = []
num=0
for o in object_list.objects:
p = Process(target=download_bucket_file, args=(config, NAMESPACE, bucket_name, directory, o.name, num))
p.start()
num+=1
proc_list.append(p)
for job in proc_list:
job.join()
print('---')
print(f'Download Finished in {round(time.time()-start_time,2)} seconds.({time.strftime("%H:%M:%S")})')
#### the end ####
I’ve saved the code to a file called bucket_parallel_download.py.
To call this, I run the following using the same DEMO_Bucket and directory of files I used in my previous posts.
python bucket_parallel_download.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
This creates the following output, and between 3.6 seconds to 4.4 seconds to download the 13 files, based on my connection.
[16:30~/Dropbox]> python bucket_parallel_download.py DEMO_Bucket /Users/brendan.tierney/DEMO_BUCKET
Starting Downloading Bucket - Parallel: DEMO_Bucket at 16:30:05
... 13 files to download
..Starting Download File (0): 2017-08-31 19.46.42.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (1): 2017-10-16 13.13.20.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (2): 2017-11-22 20.18.58.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (3): 2018-12-03 11.04.57.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (11): thumbnail_IMG_2333.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (5): IMG_2347.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (9): thumbnail_IMG_1711.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (4): 347397087_620984963239631_2131524631626484429_n.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (10): thumbnail_IMG_1712.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (8): thumbnail_IMG_1710.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (7): oug_ire18_1.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (6): IMG_6779.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (12): thumbnail_IMG_2336.jpg from Bucket DEMO_Bucket at 16:30:08
..Finished Download (9) in 0.67 seconds.
..Finished Download (11) in 0.74 seconds.
..Finished Download (10) in 0.7 seconds.
..Finished Download (5) in 0.8 seconds.
..Finished Download (7) in 0.7 seconds.
..Finished Download (1) in 1.0 seconds.
..Finished Download (12) in 0.81 seconds.
..Finished Download (4) in 1.02 seconds.
..Finished Download (6) in 0.97 seconds.
..Finished Download (2) in 1.25 seconds.
..Finished Download (8) in 1.16 seconds.
..Finished Download (0) in 1.47 seconds.
..Finished Download (3) in 1.47 seconds.
---
Download Finished in 4.09 seconds.(16:30:09)Oracle Object Storage – Parallel Uploading
In my previous posts on using Python to work with OCI Object Storage, I gave code examples and illustrated how to create Buckets, explore Buckets, upload files, download files and delete files and buckets, all using Python and files on your computer.
- Oracle Object Storage – Setup and Explore
- Oracle Object Storage – Buckets & Loading files
- Oracle Object Storage – Downloading and Deleting
- Oracle Object Storage – Parallel Uploading
Building upon the code I’ve given for uploading files, which did so sequentially, in his post I’ve taken that code and expanded it to allow the files to be uploaded in parallel to an OCI Bucket. This is achieved using the Python multiprocessing library.
Here’s the code.
import oci
import os
import argparse
from multiprocessing import Process
from glob import glob
import time
####
def upload_file(config, NAMESPACE, b, f, num):
file_exists = os.path.isfile(f)
if file_exists == True:
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_storage_client.put_object(NAMESPACE, b, os.path.basename(f), open(f,'rb'))
print(f'. Finished {num} uploading {f} in {round(time.time()-start_time,2)} seconds')
except Exception as e:
print(f'Error uploading file {num}. Try again.')
print(e)
else:
print(f'... File {f} does not exist or cannot be found. Check file name and full path')
####
def check_bucket_exists(config, NAMESPACE, b_name):
#check if Bucket exists
is_there = False
object_storage_client = oci.object_storage.ObjectStorageClient(config)
l_b = object_storage_client.list_buckets(NAMESPACE, config.get("tenancy")).data
for bucket in l_b:
if bucket.name == b_name:
is_there = True
if is_there == True:
print(f'Bucket {b_name} exists.')
else:
print(f'Bucket {b_name} does not exist.')
return is_there
####
if __name__ == "__main__":
#setup for OCI
config = oci.config.from_file()
object_storage = oci.object_storage.ObjectStorageClient(config)
NAMESPACE = object_storage.get_namespace().data
####
description = "\n".join(["Upload files in parallel to OCI storage.",
"All files in <directory> will be uploaded. Include '/' at end.",
"",
"<bucket_name> must already exist."])
parser = argparse.ArgumentParser(description=description,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(dest='bucket_name',
help="Name of object storage bucket")
parser.add_argument(dest='directory',
help="Path to local directory containing files to upload.")
args = parser.parse_args()
####
bucket_name = args.bucket_name
directory = args.directory
if not os.path.isdir(directory):
parser.usage()
else:
dir = directory + os.path.sep + "*"
#### Check if Bucket Exists ####
b_exists = check_bucket_exists(config, NAMESPACE, bucket_name)
if b_exists == True:
try:
proc_list = []
num=0
start_time = time.time()
#### Start uploading files ####
for file_path in glob(dir):
print(f"Starting {num} upload for {file_path}")
p = Process(target=upload_file, args=(config, NAMESPACE, bucket_name, file_path, num))
p.start()
num+=1
proc_list.append(p)
except Exception as e:
print(f'Error uploading file ({num}). Try again.')
print(e)
else:
print('... Create Bucket before uploading Directory.')
for job in proc_list:
job.join()
print('---')
print(f'Finished uploading all files ({num}) in {round(time.time()-start_time,2)} seconds')
#### the end ####
I’ve saved the code to a file called bucket_parallel.py.
To call this, I run the following using the same DEMO_Bucket and directory of files I used in my previous posts.
python bucket_parallel.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
This creates the following output, and between 3.3 seconds to 4.6 seconds to upload the 13 files, based on my connection.
[15:29~/Dropbox]> python bucket_parallel.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
Bucket DEMO_Bucket exists.
Starting 0 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2336.jpg
Starting 1 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-08-31 19.46.42.jpg
Starting 2 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2333.jpg
Starting 3 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/347397087_620984963239631_2131524631626484429_n.jpg
Starting 4 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1712.jpg
Starting 5 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1711.jpg
Starting 6 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-11-22 20.18.58.jpg
Starting 7 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1710.jpg
Starting 8 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2018-12-03 11.04.57.jpg
Starting 9 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_6779.jpg
Starting 10 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/oug_ire18_1.jpg
Starting 11 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-10-16 13.13.20.jpg
Starting 12 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_2347.jpg
. Finished 2 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2333.jpg in 0.752561092376709 seconds
. Finished 5 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1711.jpg in 0.7750208377838135 seconds
. Finished 4 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1712.jpg in 0.7535321712493896 seconds
. Finished 0 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2336.jpg in 0.8419861793518066 seconds
. Finished 7 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1710.jpg in 0.7582859992980957 seconds
. Finished 10 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/oug_ire18_1.jpg in 0.8714470863342285 seconds
. Finished 12 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_2347.jpg in 0.8753311634063721 seconds
. Finished 1 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-08-31 19.46.42.jpg in 1.2201581001281738 seconds
. Finished 11 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-10-16 13.13.20.jpg in 1.2848408222198486 seconds
. Finished 3 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/347397087_620984963239631_2131524631626484429_n.jpg in 1.325110912322998 seconds
. Finished 9 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_6779.jpg in 1.6633048057556152 seconds
. Finished 8 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2018-12-03 11.04.57.jpg in 1.8549730777740479 seconds
. Finished 6 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-11-22 20.18.58.jpg in 2.018144130706787 seconds
---
Finished uploading all files (13) in 3.9126579761505127 secondsOracle Object Storage – Downloading and Deleting
In my previous posts on using Object Storage I illustrated what you needed to do to setup your connect, explore Object Storage, create Buckets and how to add files. In this post, I’ll show you how to download files from a Bucket, and to delete Buckets.
- Oracle Object Storage – Setup and Explore
- Oracle Object Storage – Buckets & Loading files
- Oracle Object Storage – Downloading and Deleting
- Oracle Object Storage – Parallel Uploading
Let’s start with downloading the files in a Bucket. In my previous post, I gave some Python code and functions to perform these steps for you. The Python function below will perform this for you. A Bucket needs to be empty before it can be deleted. The function checks for files and if any exist, will delete these files before proceeding with deleting the Bucket.
Namespace needs to be defined, and you can see how that is defined by looking at my early posts on this topic.
def download_bucket(b, d):
if os.path.exists(d) == True:
print(f'{d} already exists.')
else:
print(f'Creating {d}')
os.makedirs(d)
print('Downloading Bucket:',b)
object_list = object_storage_client.list_objects(NAMESPACE, b).data
count = 0
for i in object_list.objects:
count+=1
print(f'... {count} files')
for o in object_list.objects:
print(f'Downloading object {o.name}')
get_obj = object_storage_client.get_object(NAMESPACE, b, o.name)
with open(os.path.join(d,o.name), 'wb') as f:
for chunk in get_obj.data.raw.stream(1024 * 1024, decode_content=False):
f.write(chunk)
print('Download Finished.')Here’s an example of this working.
download_dir = '/Users/brendan.tierney/DEMO_BUCKET'
download_bucket(BUCKET_NAME, download_dir)
/Users/brendan.tierney/DEMO_BUCKET already exists.
Downloading Bucket: DEMO_Bucket
... 14 files
Downloading object .DS_Store
Downloading object 2017-08-31 19.46.42.jpg
Downloading object 2017-10-16 13.13.20.jpg
Downloading object 2017-11-22 20.18.58.jpg
Downloading object 2018-12-03 11.04.57.jpg
Downloading object 347397087_620984963239631_2131524631626484429_n.jpg
Downloading object IMG_2347.jpg
Downloading object IMG_6779.jpg
Downloading object oug_ire18_1.jpg
Downloading object thumbnail_IMG_1710.jpg
Downloading object thumbnail_IMG_1711.jpg
Downloading object thumbnail_IMG_1712.jpg
Downloading object thumbnail_IMG_2333.jpg
Downloading object thumbnail_IMG_2336.jpg
Download Finished.
We can also download individual files. Here’s a function to do that. It’s a simplified version of the previous function
def download_bucket_file(b, d, f):
print('Downloading File:',f, ' from Bucket', b)
try:
get_obj = object_storage_client.get_object(NAMESPACE, b, f)
with open(os.path.join(d, f), 'wb') as f:
for chunk in get_obj.data.raw.stream(1024 * 1024, decode_content=False):
f.write(chunk)
print('Download Finished.')
except:
print('Error trying to download file. Check parameters and try again')
download_dir = '/Users/brendan.tierney/DEMO_BUCKET'
file_download = 'oug_ire18_1.jpg'
download_bucket_file(BUCKET_NAME, download_dir, file_download)
Downloading File: oug_ire18_1.jpg from Bucket DEMO_Bucket
Download Finished.The final function is to delete a Bucket from your OCI account.
def delete_bucket(b_name):
bucket_exists = check_bucket_exists(b_name)
objects_exist = False
if bucket_exists == True:
print('Starting - Deleting Bucket '+b_name)
print('... checking if objects exist in Bucket (bucket needs to be empty)')
try:
object_list = object_storage_client.list_objects(NAMESPACE, b_name).data
objects_exist = True
except Exception as e:
objects_exist = False
if objects_exist == True:
print('... ... Objects exists in Bucket. Deleting these objects.')
count = 0
for o in object_list.objects:
count+=1
object_storage_client.delete_object(NAMESPACE, b_name, o.name)
if count > 0:
print(f'... ... Deleted {count} objects in {b_name}')
else:
print(f'... ... Bucket is empty. No objects to delete.')
else:
print(f'... No objects to delete, Bucket {b_name} is empty')
print(f'... Deleting bucket {b_name}')
response = object_storage_client.delete_bucket(NAMESPACE, b_name)
print(f'Deleted bucket {b_name}') Before running this function, lets do a quick check to see what Buckets I have in my OCI account.
list_bucket_counts()
Bucket name: ADW_Bucket
... num of objects : 2
Bucket name: Cats-and-Dogs-Small-Dataset
... num of objects : 100
Bucket name: DEMO_Bucket
... num of objects : 14
Bucket name: Demo
... num of objects : 210
Bucket name: Finding-Widlake-Bucket
... num of objects : 424
Bucket name: Planes-in-Satellites
... num of objects : 89
Bucket name: Vision-Demo-1
... num of objects : 10
Bucket name: root-bucket
... num of objects : 2I’ve been using DEMO_Bucket in my previous examples and posts. We’ll use this to demonstrate the deleting of a Bucket.
delete_bucket(BUCKET_NAME)
Bucket DEMO_Bucket exists.
Starting - Deleting Bucket DEMO_Bucket
... checking if objects exist in Bucket (bucket needs to be empty)
... ... Objects exists in Bucket. Deleting these objects.
... ... Deleted 14 objects in DEMO_Bucket
... Deleting bucket DEMO_Bucket
Deleted bucket DEMO_Bucket
Oracle Object Storage – Buckets & Loading files
In a previous post, I showed what you need to do to setup your local PC/laptop to be able to connect to OCI. I also showed how to perform some simple queries on your Object Storage environment. Go check out that post before proceeding with the examples in this blog.
- Oracle Object Storage – Setup and Explore
- Oracle Object Storage – Buckets & Loading files
- Oracle Object Storage – Downloading and Deleting
- Oracle Object Storage – Parallel Uploading
In this post, I’ll build upon my previous post by giving some Python functions to:
- Check if Bucket exists
- Create a Buckets
- Delete a Bucket
- Upload an individual file
- Upload an entire directory
Let’s start with a function to see if a Bucket already exists.
def check_bucket_exists(b_name):
#check if Bucket exists
is_there = False
l_b = object_storage_client.list_buckets(NAMESPACE, COMPARTMENT_ID).data
for bucket in l_b:
if bucket.name == b_name:
is_there = True
if is_there == True:
print(f'Bucket {b_name} exists.')
else:
print(f'Bucket {b_name} does not exist.')
return is_thereA simple test for a bucket called ‘DEMO_bucket’. This was defined in a variable previously (see previous post). I’ll use this ‘DEMO_bucket’ throughout these examples.
b_exists = check_bucket_exists(BUCKET_NAME)
print(b_exists)
---
Bucket DEMO_Bucket does not exist.
FalseNext we can more onto a function for creating a Bucket.
def create_bucket(b):
#create Bucket if it does not exist
bucket_exists = check_bucket_exists(b)
if bucket_exists == False:
try:
create_bucket_response = object_storage_client.create_bucket(
NAMESPACE,
oci.object_storage.models.CreateBucketDetails(
name=demo_bucket_name,
compartment_id=COMPARTMENT_ID
)
)
bucket_exists = True
# Get the data from response
print(f'Created Bucket {create_bucket_response.data.name}')
except Exception as e:
print(e.message)
else:
bucket_exists = True
print(f'... nothing to create.')
return bucket_existsA simple test for a bucket called ‘DEMO_bucket’. This was defined in a variable previously (see previous post).
b_exists = create_bucket(BUCKET_NAME)
---
Bucket DEMO_Bucket does not exist.
Created Bucket DEMO_BucketNext, let’s delete a Bucket and any files stored in it.
def delete_bucket(b_name):
bucket_exists = check_bucket_exists(b_name)
objects_exist = False
if bucket_exists == True:
print('Starting - Deleting Bucket '+b_name)
print('... checking if objects exist in Bucket (bucket needs to be empty)')
try:
object_list = object_storage_client.list_objects(NAMESPACE, b_name).data
objects_exist = True
except Exception as e:
objects_exist = False
if objects_exist == True:
print('... ... Objects exists in Bucket. Deleting these objects.')
count = 0
for o in object_list.objects:
count+=1
object_storage_client.delete_object(NAMESPACE, b_name, o.name)
if count > 0:
print(f'... ... Deleted {count} objects in {b_name}')
else:
print(f'... ... Bucket is empty. No objects to delete.')
else:
print(f'... No objects to delete, Bucket {b_name} is empty')
print(f'... Deleting bucket {b_name}')
response = object_storage_client.delete_bucket(NAMESPACE, b_name)
print(f'Deleted bucket {b_name}') The example output below shows what happens when I’ve already loaded data into the Bucket (which I haven’t shown in the examples so far – but I will soon).
delete_bucket(BUCKET_NAME)
---
Bucket DEMO_Bucket exists.
Starting - Deleting Bucket DEMO_Bucket
... checking if objects exist in Bucket (bucket needs to be empty)
... ... Objects exists in Bucket. Deleting these objects.
... ... Bucket is empty. No objects to delete.
... Deleting bucket DEMO_Bucket
Deleted bucket DEMO_Bucket
Now that we have our functions for managing Buckets, we can now have a function for uploading a file to a bucket.
def upload_file(b, f):
file_exists = os.path.isfile(f)
if file_exists == True:
#check to see if Bucket exists
b_exists = check_bucket_exists(b)
if b_exists == True:
print(f'... uploading {f}')
try:
object_storage_client.put_object(NAMESPACE, b, os.path.basename(f), io.open(f,'rb'))
print(f'. finished uploading {f}')
except Exception as e:
print(f'Error uploading file. Try again.')
print(e)
else:
print('... Create Bucket before uploading file.')
else:
print(f'... File {f} does not exist or cannot be found. Check file name and full path')Just select a file from your computer and give the full path to that file and the Bucket name.
up_file = '/Users/brendan.tierney/Dropbox/bill.xls'
upload_file(BUCKET_NAME, up_file)
---
Bucket DEMO_Bucket does not exist.
... Create Bucket before uploading file.Our final function is an extended version of the previous one. This function takes a Directory path and uploads all the files to the Bucket.
def upload_directory(b, d):
count = 0
#check to see if Bucket exists
b_exists = check_bucket_exists(b)
if b_exists == True:
#loop files
for filename in os.listdir(d):
print(f'... uploading {filename}')
try:
object_storage_client.put_object(NAMESPACE, b, filename, io.open(os.path.join(d,filename),'rb'))
count += 1
except Exception as e:
print(f'... ... Error uploading file. Try again.')
print(e)
else:
print('... Create Bucket before uploading files.')
if count == 0:
print('... Empty directory. No files uploaded.')
else:
print(f'Finished uploading Directory : {count} files into {b} bucket')and to call it …
up_directory = '/Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/'
upload_directory(BUCKET_NAME, up_directory)
---
Bucket DEMO_Bucket exists.
... uploading thumbnail_IMG_2336.jpg
... uploading .DS_Store
... uploading 2017-08-31 19.46.42.jpg
... uploading thumbnail_IMG_2333.jpg
... uploading 347397087_620984963239631_2131524631626484429_n.jpg
... uploading thumbnail_IMG_1712.jpg
... uploading thumbnail_IMG_1711.jpg
... uploading 2017-11-22 20.18.58.jpg
... uploading thumbnail_IMG_1710.jpg
... uploading 2018-12-03 11.04.57.jpg
... uploading IMG_6779.jpg
... uploading oug_ire18_1.jpg
... uploading 2017-10-16 13.13.20.jpg
... uploading IMG_2347.jpg
Finished uploading Directory : 14 files into DEMO_Bucket bucket
You must be logged in to post a comment.