
Data Science
How to download a Kaggle Competition dataset
Kaggle is a popular website for data science and machine learning, where users can participate in machine learning competitions, access an extensive library of open datasets, notebooks and training. It is used by Data scientists and students around the world to learn and test their skills on a wider variety of problems.
One of the first tasks any person using Kaggle will need to do is to download a dataset. One simple way of doing this is by logging into the website and manually downloading the dataset.
But what if you want to automate this step into your Notebook or other Python environment you might be using? Building repeatedly into your projects is an important step, as it can ilimate any postting errors that might occur when perform these manually. The examples give below were all run in a Jupyter Notebook.
First thing to do is to install the kaggle and kagglehub python packages.
!pip3 install kaggle!pip3 install kagglehub
Before we do anything else in the Jupyter Notebook, you will need to log into the Kaggle website and get and API Key Token for your account
Copy the Kaggle API Key and add it to an environment variable. Here is the code to do this in the Jupyter Notebook.
import osos.environ["KAGGLE_API_TOKEN"] = "..."
You can check that it has been set correctly by running
print(os.environ["KAGGLE_API_TOKEN"])
Now we can get on with accessing the Kaggle datasets. This first approach will use the kaggle python package. With this you can use a mixture of command line commands and package functions
#import kaggle packageimport kaggle#use command line to list the datasets - limited output!kaggle datasets list#use a kaggle package function to list competitionsfrom kaggle.api.kaggle_api_extended import KaggleApiapi = KaggleApi()api.authenticate()api.competitions_list_cli()
I’ve not listed the outputs above, as the output would be very long. I’ll leave that for you to explore.
To download a dataset or all the files for a competion, we can run the following:
#list the files that are part of a competition!kaggle competitions files -c "house-prices-advanced-regression-techniques"name size creationDate --------------------- ---------- -------------------------- data_description.txt 13370 2019-12-15 21:33:35.157000 sample_submission.csv 31939 2019-12-15 21:33:35.224000 test.csv 451405 2019-12-15 21:33:35.212000 train.csv 460676 2019-12-15 21:33:35.259000 #download the competion files!kaggle competitions download -c "house-prices-advanced-regression-techniques"Downloading house-prices-advanced-regression-techniques.zip to /Users/brendan.tierney100%|█████████████████████████████████████████| 199k/199k [00:00<00:00, 714kB/s]
If you get a 403 error when running the above commands, just open the kaggle website and log into your account. Then run again.
The download will create a Zip file on your computer, which you’ll need to unzip.
#!apt-get install unzip!unzip house-prices-advanced-regression-techniques.zip
When unzipped you can now load the dataset into a Pandas dataframe.
import pandas as pd#path to CSV filepath = "train.csv"train_data = pd.read_csv('train.csv')train_data
Or a Spark dataframe.
from pyspark.sql import SparkSession#Create a Spark Sessionspark = SparkSession.builder \ .appName('Kaggle-Data') \ .master('local[*]') \ .getOrCreate()#Spark dataframe - Read CSVdf = spark.read.csv(path)# or if the file has a header record#Spark dataframe - Read CSV with Header df2 = spark.read.option("header", True).csv(path)
An alternative to the above is to use kagglehub package. The download function in this package will download load the files into a local directory
#install kagglehub!pip3 install kagglehubimport kagglehub#download the data fileskagglehub.competition_download('house-prices-advanced-regression-techniques', output_dir='./Kaggle_data', force_download=True)Downloading to ./Kaggle_data/house-prices-advanced-regression-techniques.archive...100%|█████████████████████████████████████████████████████████████████████████████████| 199k/199k [00:00<00:00, 670kB/s]Extracting files...
!ls -l ./Kaggle_datatotal 1888-rw-r--r-- 1 brendan.tierney staff 13370 16 Mar 12:38 data_description.txt-rw-r--r-- 1 brendan.tierney staff 31939 16 Mar 12:38 sample_submission.csv-rw-r--r-- 1 brendan.tierney staff 451405 16 Mar 12:38 test.csv-rw-r--r-- 1 brendan.tierney staff 460676 16 Mar 12:38 train.csv
Creating Test Data in your Database using Faker
A some point everyone needs some test data for their database. There area a number of ways of doing this, and in this post I’ll walk through using the Python library Faker to create some dummy test data (that kind of looks real) in my Oracle Database. I’ll have another post using the GenAI in-database feature available in the Oracle Autonomous Database. So keep an eye out for that.
Faker is one of the available libraries in Python for creating dummy/test data that kind of looks realistic. There are several more. I’m not going to get into the relative advantages and disadvantages of each, so I’ll leave that task to yourself. I’m just going to give you a quick demonstration of what is possible.
One of the key elements of using Faker is that we can set a geograpic location for the data to be generated. We can also set multiples of these and by setting this we can get data generated specific for that/those particular geographic locations. This is useful for when testing applications for different potential markets. In my example below I’m setting my local for USA (en_US).
Here’s the Python code to generate the Test Data with 15,000 records, which I also save to a CSV file.
import pandas as pd
from faker import Faker
import random
from datetime import date, timedelta
#####################
NUM_RECORDS = 15000
LOCALE = 'en_US'
#Initialise Faker
Faker.seed(42)
fake = Faker(LOCALE)
#####################
#Create a function to generate the data
def create_customer_record():
#Customer Gender
gender = random.choice(['Male', 'Female', 'Non-Binary'])
#Customer Name
if gender == 'Male':
name = fake.name_male()
elif gender == 'Female':
name = fake.name_female()
else:
name = fake.name()
#Date of Birth
dob = fake.date_of_birth(minimum_age=18, maximum_age=90)
#Customer Address and other details
address = fake.street_address()
email = fake.email()
city = fake.city()
state = fake.state_abbr()
zip_code = fake.postcode()
full_address = f"{address}, {city}, {state} {zip_code}"
phone_number = fake.phone_number()
#Customer Income
# - annual income between $30,000 and $250,000
income = random.randint(300, 2500) * 100
#Credit Rating
credit_rating = random.choices(['A', 'B', 'C', 'D'], weights=[0.40, 0.30, 0.20, 0.10], k=1)[0]
#Credit Card and Banking details
card_type = random.choice(['visa', 'mastercard', 'amex'])
credit_card_number = fake.credit_card_number(card_type=card_type)
routing_number = fake.aba()
bank_account = fake.bban()
return {
'CUSTOMERID': fake.unique.uuid4(), # Unique identifier
'CUSTOMERNAME': name,
'GENDER': gender,
'EMAIL': email,
'DATEOFBIRTH': dob.strftime('%Y-%m-%d'),
'ANNUALINCOME': income,
'CREDITRATING': credit_rating,
'CUSTOMERADDRESS': full_address,
'ZIPCODE': zip_code,
'PHONENUMBER': phone_number,
'CREDITCARDTYPE': card_type.capitalize(),
'CREDITCARDNUMBER': credit_card_number,
'BANKACCOUNTNUMBER': bank_account,
'ROUTINGNUMBER': routing_number,
}
#Generate the Demo Data
print(f"Generating {NUM_RECORDS} customer records...")
data = [create_customer_record() for _ in range(NUM_RECORDS)]
print("Sample Data Generation complete")
#Convert to Pandas DataFrame
df = pd.DataFrame(data)
print("\n--- DataFrame Sample (First 10 Rows) : sample of columns ---")
# Display relevant columns for verification
display_cols = ['CUSTOMERNAME', 'GENDER', 'DATEOFBIRTH', 'PHONENUMBER', 'CREDITCARDNUMBER', 'CREDITRATING', 'ZIPCODE']
print(df[display_cols].head(10).to_markdown(index=False))
print("\n--- DataFrame Information ---")
print(f"Total Rows: {len(df)}")
print(f"Total Columns: {len(df.columns)}")
print("Data Types:")
print(df.dtypes)The output from the above code gives the following:
Generating 15000 customer records...
Sample Data Generation complete
--- DataFrame Sample (First 10 Rows) : sample of columns ---
| CUSTOMERNAME | GENDER | DATEOFBIRTH | PHONENUMBER | CREDITCARDNUMBER | CREDITRATING | ZIPCODE |
|:-----------------|:-----------|:--------------|:-----------------------|-------------------:|:---------------|----------:|
| Allison Hill | Non-Binary | 1951-03-02 | 479.540.2654 | 2271161559407810 | A | 55488 |
| Mark Ferguson | Non-Binary | 1952-09-28 | 724.523.8849x696 | 348710122691665 | A | 84760 |
| Kimberly Osborne | Female | 1973-08-02 | 001-822-778-2489x63834 | 4871331509839301 | B | 70323 |
| Amy Valdez | Female | 1982-01-16 | +1-880-213-2677x3602 | 4474687234309808 | B | 07131 |
| Eugene Green | Male | 1983-10-05 | (442)678-4980x841 | 4182449353487409 | A | 32519 |
| Timothy Stanton | Non-Binary | 1937-10-13 | (707)633-7543x3036 | 344586850142947 | A | 14669 |
| Eric Parker | Male | 1964-09-06 | 577-673-8721x48951 | 2243200379176935 | C | 86314 |
| Lisa Ball | Non-Binary | 1971-09-20 | 516.865.8760 | 379096705466887 | A | 93092 |
| Garrett Gibson | Male | 1959-07-05 | 001-437-645-2991 | 349049663193149 | A | 15494 |
| John Petersen | Male | 1978-02-14 | 367.683.7770 | 2246349578856859 | A | 11722 |
--- DataFrame Information ---
Total Rows: 15000
Total Columns: 14
Data Types:
CUSTOMERID object
CUSTOMERNAME object
GENDER object
EMAIL object
DATEOFBIRTH object
ANNUALINCOME int64
CREDITRATING object
CUSTOMERADDRESS object
ZIPCODE object
PHONENUMBER object
CREDITCARDTYPE object
CREDITCARDNUMBER object
BANKACCOUNTNUMBER object
ROUTINGNUMBER objectHaving generated the Test data, we now need to get it into the database. There a various ways of doing this. As we are already using Python I’ll illustrate getting the data into the Database below. An alternative option is to use SQL Command Line (SQLcl) and the LOAD feature in that tool.
Here’s the Python code to load the data. I’m using the oracledb python library.
### Connect to Database
import oracledb
p_username = "..."
p_password = "..."
#Give OCI Wallet location and details
try:
con = oracledb.connect(user=p_username, password=p_password, dsn="adb26ai_high",
config_dir="/Users/brendan.tierney/Dropbox/Wallet_ADB26ai",
wallet_location="/Users/brendan.tierney/Dropbox/Wallet_ADB26ai",
wallet_password=p_walletpass)
except Exception as e:
print('Error connecting to the Database')
print(f'Error:{e}')
print(con)### Create Customer Table
drop_table = 'DROP TABLE IF EXISTS demo_customer'
cre_table = '''CREATE TABLE DEMO_CUSTOMER (
CustomerID VARCHAR2(50) PRIMARY KEY,
CustomerName VARCHAR2(50),
Gender VARCHAR2(10),
Email VARCHAR2(50),
DateOfBirth DATE,
AnnualIncome NUMBER(10,2),
CreditRating VARCHAR2(1),
CustomerAddress VARCHAR2(100),
ZipCode VARCHAR2(10),
PhoneNumber VARCHAR2(50),
CreditCardType VARCHAR2(10),
CreditCardNumber VARCHAR2(30),
BankAccountNumber VARCHAR2(30),
RoutingNumber VARCHAR2(10) )'''
cur = con.cursor()
print('--- Dropping DEMO_CUSTOMER table ---')
cur.execute(drop_table)
print('--- Creating DEMO_CUSTOMER table ---')
cur.execute(cre_table)
print('--- Table Created ---')### Insert Data into Table
insert_data = '''INSERT INTO DEMO_CUSTOMER values (:1, :2, :3, :4, :5, :6, :7, :8, :9, :10, :11, :12, :13, :14)'''
print("--- Inserting records ---")
cur.executemany(insert_data, df )
con.commit()
print("--- Saving to CSV ---")
df.to_csv('/Users/brendan.tierney/Dropbox/DEMO_Customer_data.csv', index=False)
print("- Finished -")### Close Connections to DB
con.close()and to prove the records got inserted we can connect to the schema using SQLcl and check.
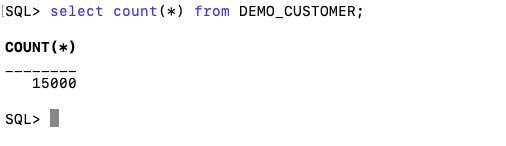
Automated Data Visualizations in Python
Creating data visualizations in Python can be a challenge. For some it an be easy, but for most (and particularly new people to the language) they always have to search for the commands in the documentation or using some search engine. Over the past few years we have seem more and more libraries coming available to assist with many of the routine and tedious steps in most data science and machine learning projects. I’ve written previously about some data profiling libraries in Python. These are good up to a point, but additional work/code is needed to explore the data to suit your needs. One of these Python libraries, designed to make your initial work on a new data set easier is called AutoViz. It’s good to see there is continued development work on this library, which can be really help for creating initial sets of charts for all the variables in your data set, plus it has some additional features which help to make it very useful and cuts down on some of the additional code you might need to write.
The outputs from AutoViz are very extensive, and are just too long to show in this post. The images below will give you an indication of what if typically generated. I’d encourage you to install the library and run it on one of your data sets to see the full extent of what it can do. For this post, I’ll concentrate on some of the commands/parameters/settings to get the most out of AutoViz.
Firstly there is the install via pip command or install using Anaconda.
pip3 install autovizFor comparison purposes I’m going to use the same data set as I’ve used in the data profiling post (see above). Here’s a quick snippet from that post to load the data and perform the data profiling (see post for output)
import pandas as pd
import pandas_profiling as pp
#load the data into a pandas dataframe
df = pd.read_csv("/Users/brendan.tierney/Downloads/Video_Games_Sales_as_at_22_Dec_2016.csv")We can not skip to using AutoViz. It supports the loading and analzying of data sets direct from a file or from a pandas dataframe. In the following example I’m going to use the dataframe (df) created above.
from autoviz import AutoViz_Class
AV = AutoViz_Class()
df2 = AV.AutoViz(filename="", dfte=df) #for a file, fill in the filename and remove dfte parameterThis will analyze the data and create lots and lots of charts for you. Some are should in the following image. One the helpful features is the ‘data cleaning improvements’ section where it has performed a data quality assessment and makes some suggestions to improve the data, maybe as part of the data preparation/cleaning step.

There is also an option for creating different types of out put with perhaps the Bokeh charts being particularly useful.
chart_format='bokeh': interactive Bokeh dashboards are plotted in Jupyter Notebooks.chart_format='server', dashboards will pop up for each kind of chart on your web browser.chart_format='html', interactive Bokeh charts will be silently saved as Dynamic HTML files underAutoViz_Plotsdirectory
df2 = AV.AutoViz(filename="", dfte=df, chart_format='bokeh')
The next example allows for the report and charts to be focused on a particular dependent or target variable, particular in scenarios where classification will be used.
df2 = AV.AutoViz(filename="", dfte=df, depVar="Platform")
A little warning when using this library. It can take a little bit of time for it to run and create all the different charts. On the flip side, it save you from having to write lots and lots of code!
CAO Points 2022 – Grade inflation, deflation or in-line
Last week I wrote a blog post analysing the Leaving Cert results over the past 3-8 years. Part of that post also looked at the claim from the Dept of Education saying the results in 2022 would be “in-line on aggregate” with the results from 2021. The outcome of the analysis was grade deflation was very evident in many subjects, but when analysed and profiled at a very high level, they did look similar.
I didn’t go into how that might impact on the CAO (Central Applications Office) Points. If there was deflation in some of the core and most popular subjects, then you might conclude there could be some changes in the profile of CAO Points being awarded, and that in turn would have a small change on the CAO Points needed for a lot of University courses. But not all of them, as we saw last week, the increased number of students who get grades in the H4-H7 range. This could mean a small decrease in points for courses in the 520+ range, and a small increase in points needed in the 300-500-ish range.
The CAO have published the number of students of each 10 point range. I’ve compared the 2022 data, with each year going back to 2015. The following table is a high level summary of the results in 50 point ranges.
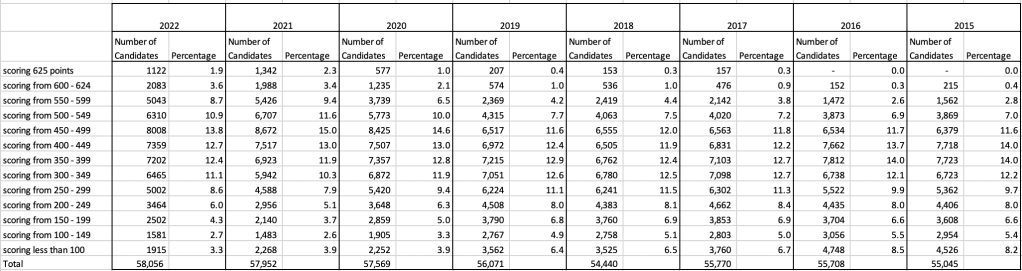
An initial look at these numbers and percentages might look like points are similar to last year and even 2020. But for 2015-2019 the similarity is closer. Again looking back at the previous blog post, we can see the results profiles for 20215-2019 are broadly similar and does indicate some normalisation might have been happening each year. The following chart illustrate the percentage of students who achieved points in each range.
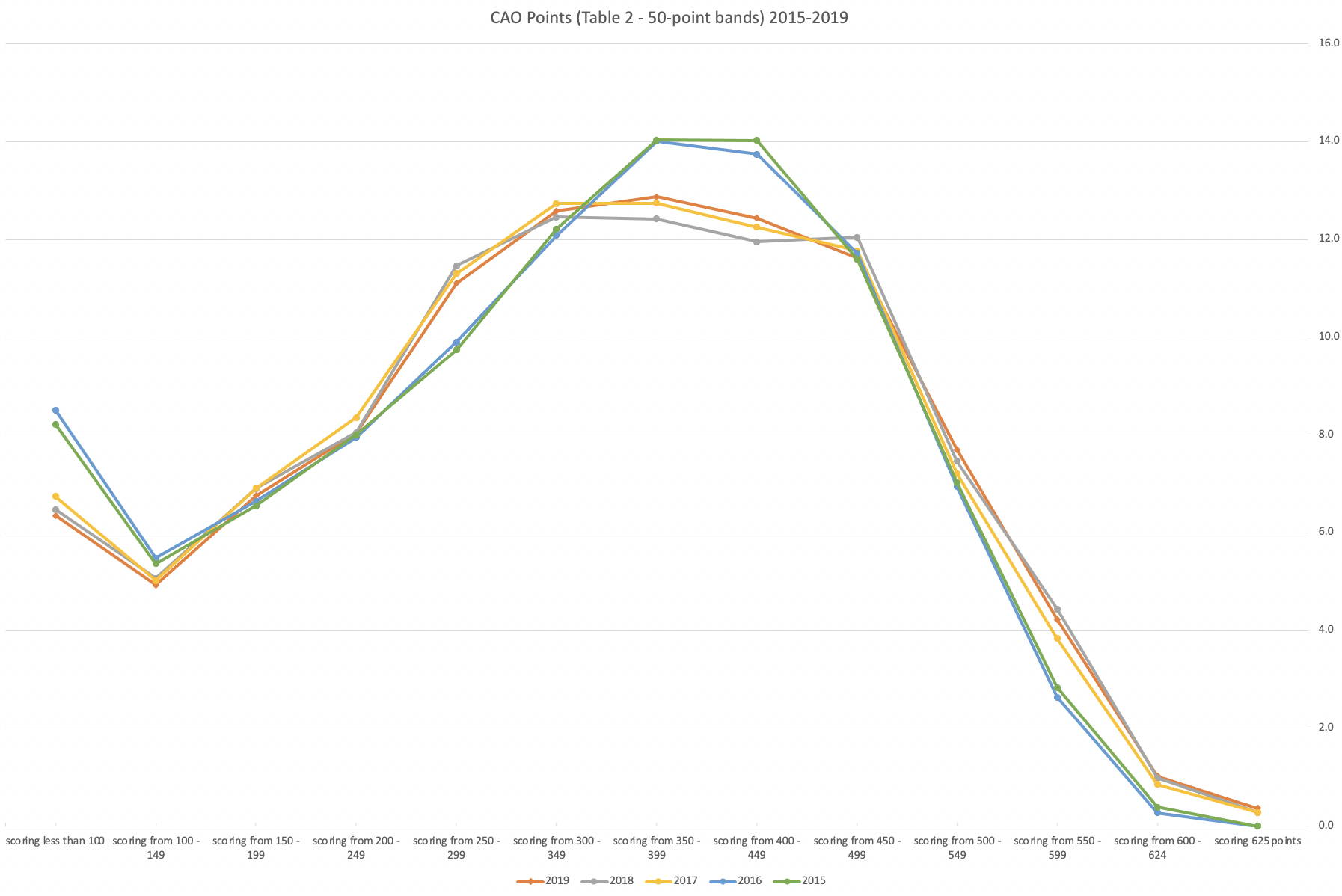
From the above we can see the profile is similar across 2015-2019, although there does seem to be a flattening of the curve between 2015-2016!
Let’s now have a look at 2019 (the last pre-coivd year), 2021 and 2022. This will allow use to compare the “inflated” years to the last “normal” year.
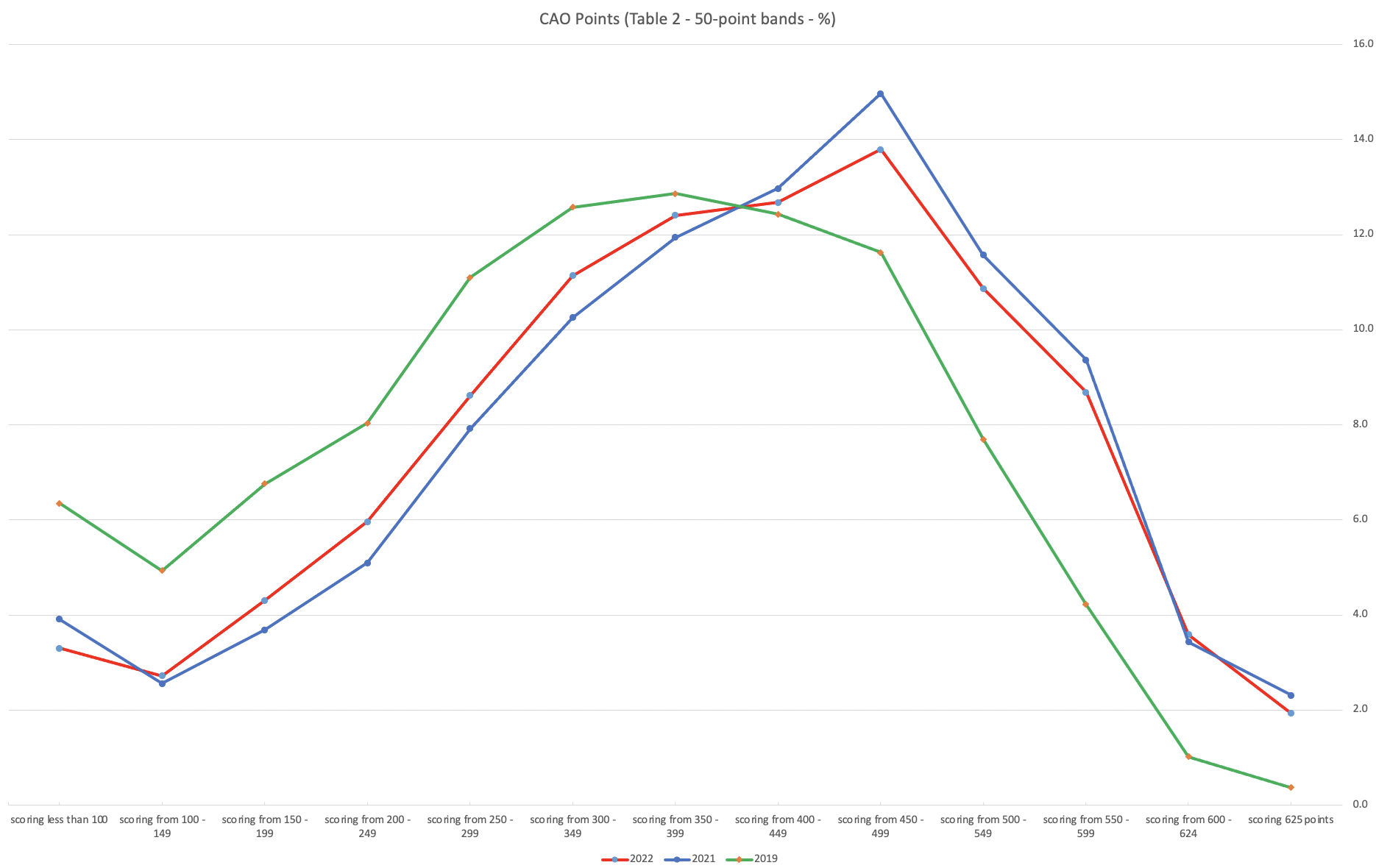
This chart clearly shows a shifting of the profile to the left for the red line which represents 2022. This also supports my blog post last week, and that the Dept of Education has started the process of deflating marks.
Based on this shifting/deflating of marks, we could see the grade/CAO Points profiles reverting back to almost 2019 profile by 2025. For students sitting the Leaving Cert in 2023, there will be another shift to the left, and with another similar shift in 2024. In 2024, the students will be the last group to sit the Leaving Cert who were badly affected during the Covid years. Many of them lost large chunks on school and many didn’t sit the Junior Cert. I’d predict 2025 will see the first time the marks/points profiles will match pre-covid years.
For this analysis I’ve used a variety of tools including Excel, Python and Oracle Analytics.
The Dataset used can be found under Dataset menu, and listed as ‘CAO Points Profiles 2015-2022’. Also, check out the Leaving Certificate 2015-2022 dataset.
Leaving Cert 2022 Results – Inflation, deflation or in-line!
The Leaving Certificate 2022 results are out. Up and down the country there are people who are delighted with their results, while others are disappointed, and lots of other emotions.
The Leaving Certificate is the terminal examination for secondary education in Ireland, with most students being examined in seven subjects, with their best six grades counting towards their “points”, which in turn determines what university course they might get. Check out this link for learn more about the Leaving Certificate.
The Dept of Education has been saying, for several months, this results this year (2022) will be “in-line on aggregate” with the results from 2021. There has been some concerns about grade inflation in 2021 and the impact it will have on the students in 2022 and future years. At some point the Dept of Education needs to address this grade inflation and look to revert back to the normal profile of grades pre-Covid.
Let’s have a look to see if this is true, and if it is true when we look a little deeper. Do the aggregate results hide grade deflation in some subjects.
For the analysis presented in this blog post, I’ve just looked at results at Higher Level across all subjects, and for the deeper dive I’ll look at some of the most popular subjects.
Firstly let’s have a quick look at the distribution of grades by subject for 2022 and 2021.
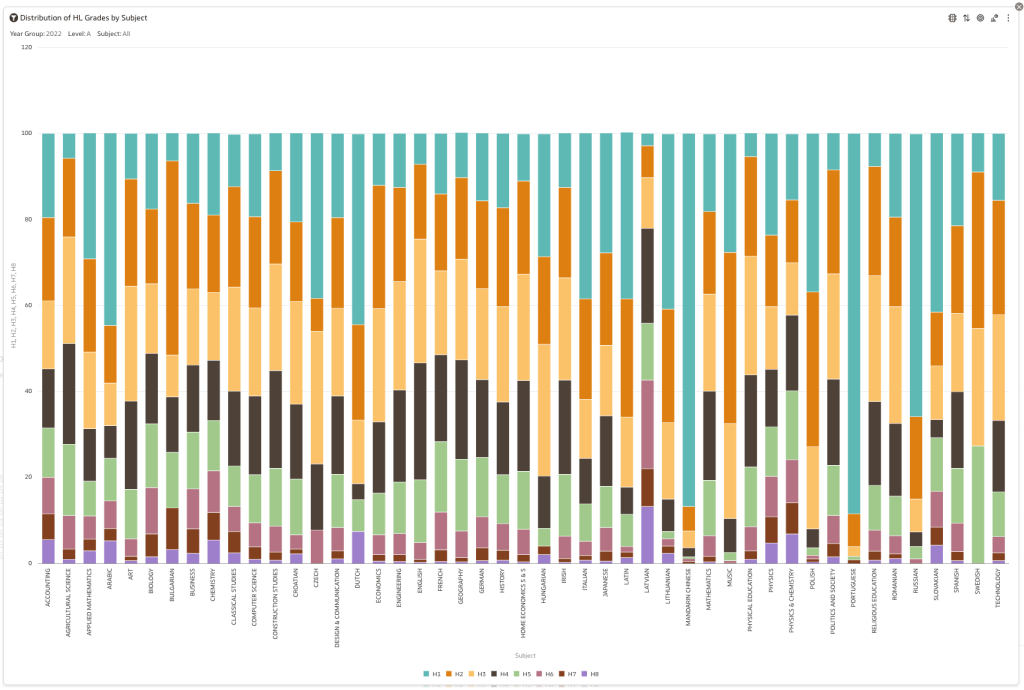
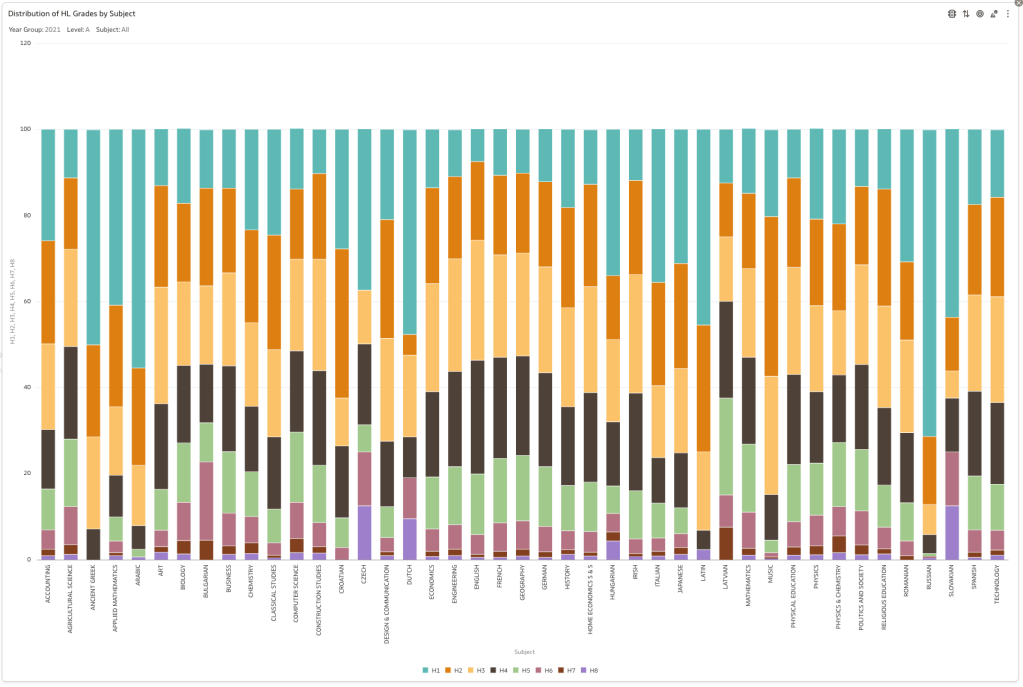
Remember the Dept of Education said the 2022 results should be in-line with the results of 2021. This required them to apply some adjustments, after marking the exam scripts, to give an updated profile. The following chart shows this comparison between the two years. On initial inspection we can see it is broadly similar. This is good, right? It kind of is and at a high level things look broadly in-line and maybe we can believe the Dept of Education. Looking a little closer we can see a small decrease in the H2-H4 range, and a slight increase in the H5-H8.
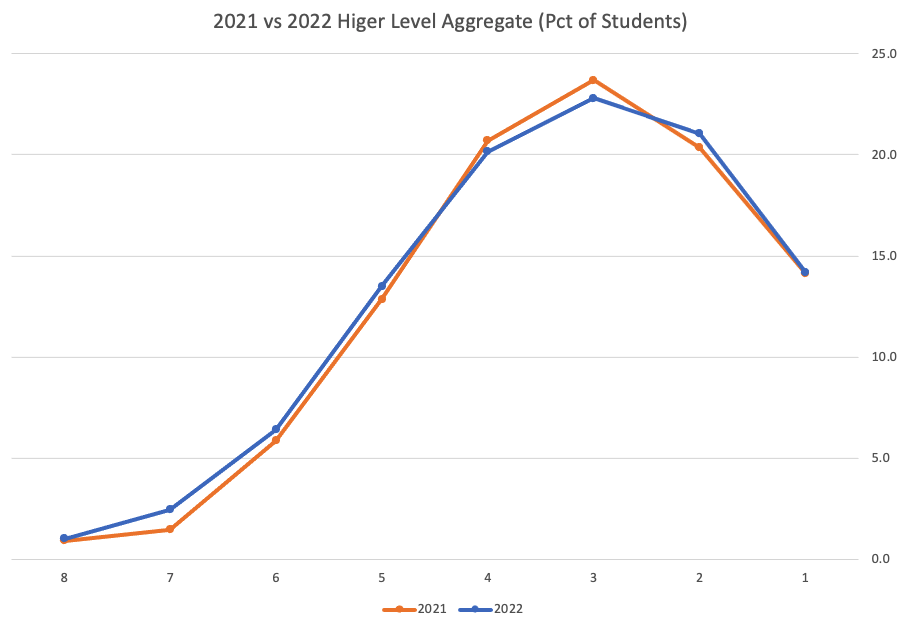
Let’s dive a little deeper. When we look at the grade profile of students in 2021 and 2022, How many subjects increased the number of students at each grade vs How many subjects decreased grades vs How many approximately stated the same. The table below shows the results and only counts a change if it is greater than 1% (to allow for minor variations between years).

This table in very interesting in that more subjects decreased their H1s, with some variation for the H2-H4s, while for the lower range of H5-H7 we can see there has been an increase in grades. If I increased the margin to 3% we get a slightly different results, but only minor changes.
“in-line on aggregate” might be holding true, although it appears a slight increase on the numbers getting the lower grades. This might indicate either more of an adjustment to weaker students and/or a bit of a down shifting of grades from the H2-H4 range. But at the higher end, more subjects reduced than increase. The overall (aggregate) numbers are potentially masking movements in grade profiles.
Let’s now have a look at some of the core subjects of English, Irish and Mathematics.
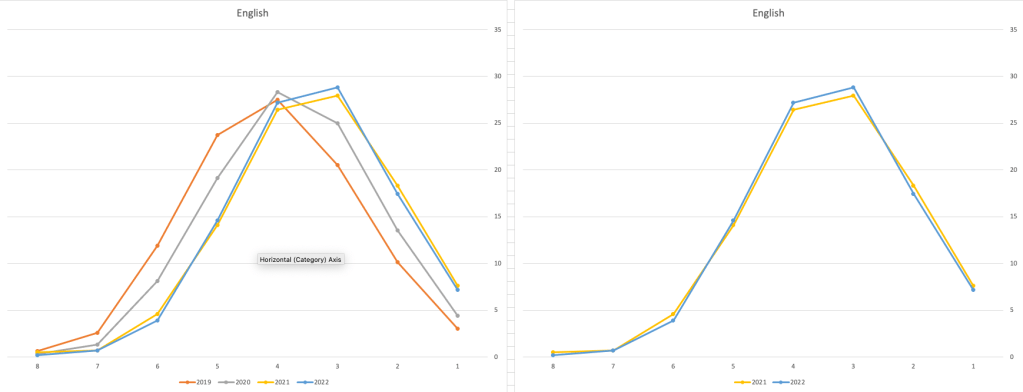
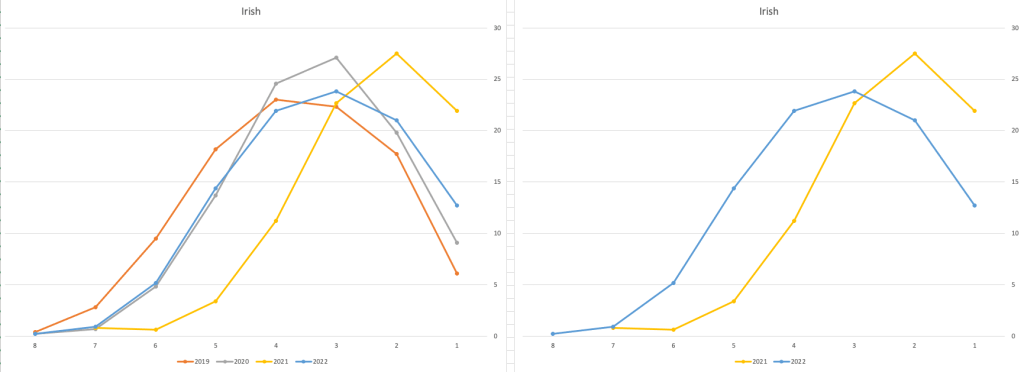
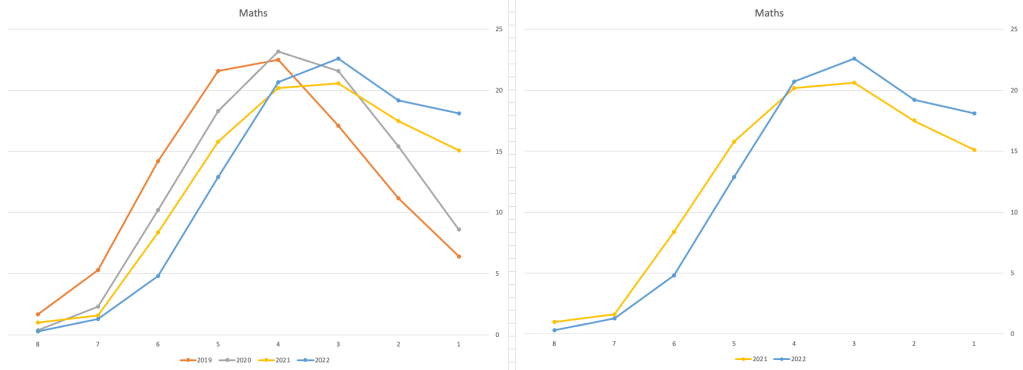
For English, it looks like they fitted to the curve perfectly! keeping grades in-line between the two years. Mathematics is a little different with a slight increase in grades. But when you look at Irish we can see there was definite grade deflation. For each of these subjects, the chart on the left contains four years of data including 2019 when the last “normal” leaving certificate occurred. With Irish the grade profile has been adjusted (deflated) significantly and is closer to 2019 profile than it is to 2021. There was been lots and lots of discussions nationally about how and when grades will revert to normal profile. The 2022 profile for Irish seems to show this has started to happen in this subject, which raises the question if this is occurring in any other subjects, and is hidden/masked by the “in-line on aggregate” figures.
This blog post would become just too long if I was to present the results profile for each of the 42+ subjects.
Let’s have a look as two of the most common foreign languages, French and Spanish.
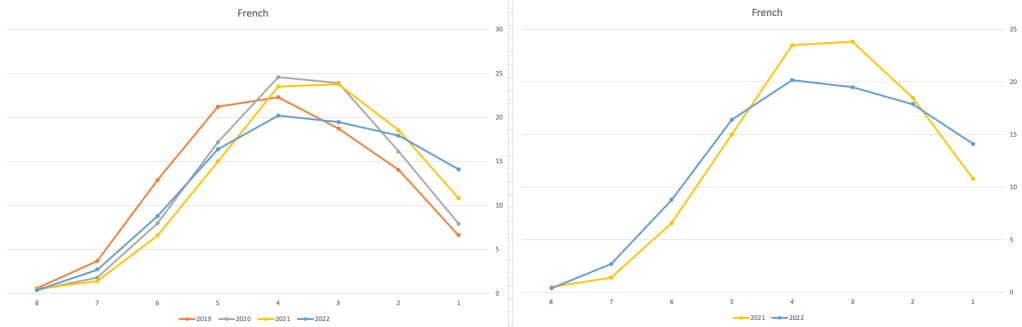
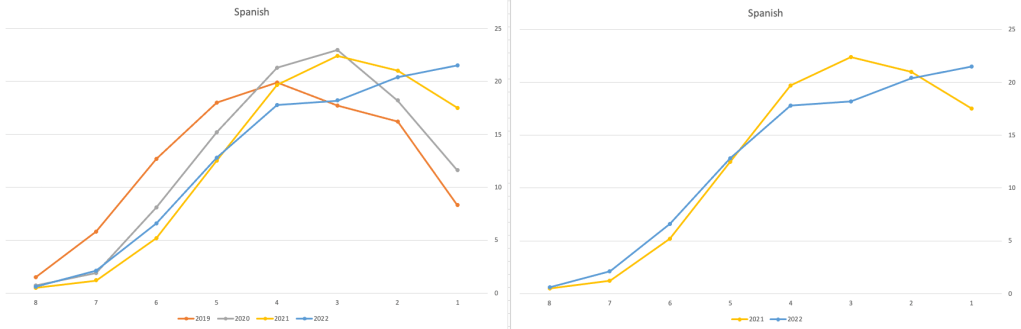
Again we can see some grade deflation, although not to be same extent as Irish. For both French and Spanish, we have reduced numbers for the H2-H4 range and a slight increase for H5-H7, and shift to the left in the profile. A slight exception is for those getting a H1 for both subjects. The adjustment in the results profile is more pronounced for French, and could indicate some deflation adjustments.
Next we’ll look at some of the science subjects of Physics, Chemistry and Biology.
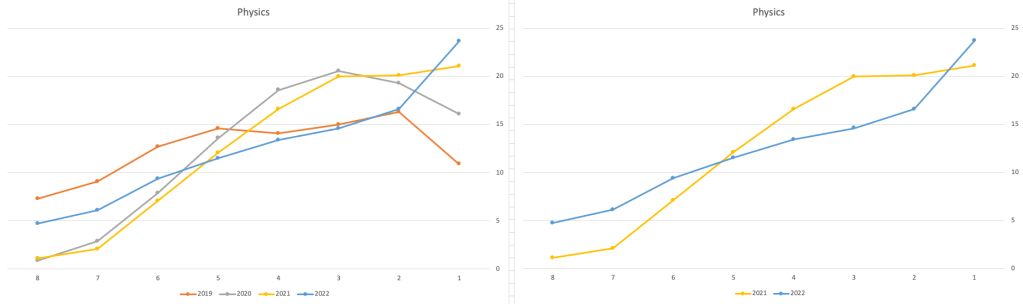
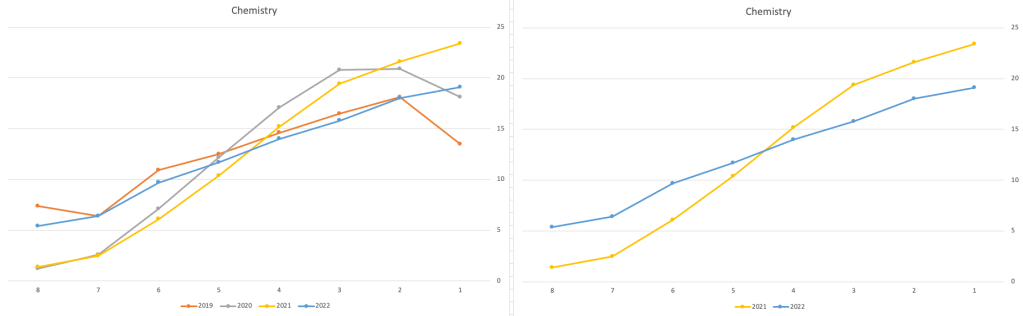
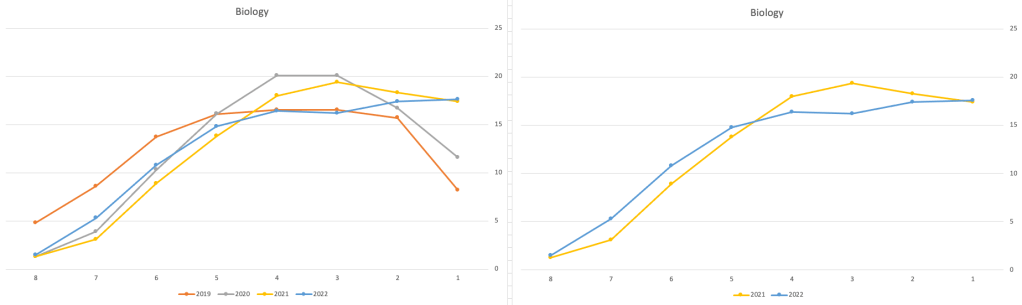
These three subjects also indicate some adjusts back towards the pre-Covid profile, with exception of H1 grades. We can see the 2022 profile almost reflect the 2019 profile (excluding H1s) and for Biology appears to be at a half way point between 2019 and 2022 (excluding H1s)
Just one more example of grade deflation, and this with Design, Communication and Graphics (or DCG)
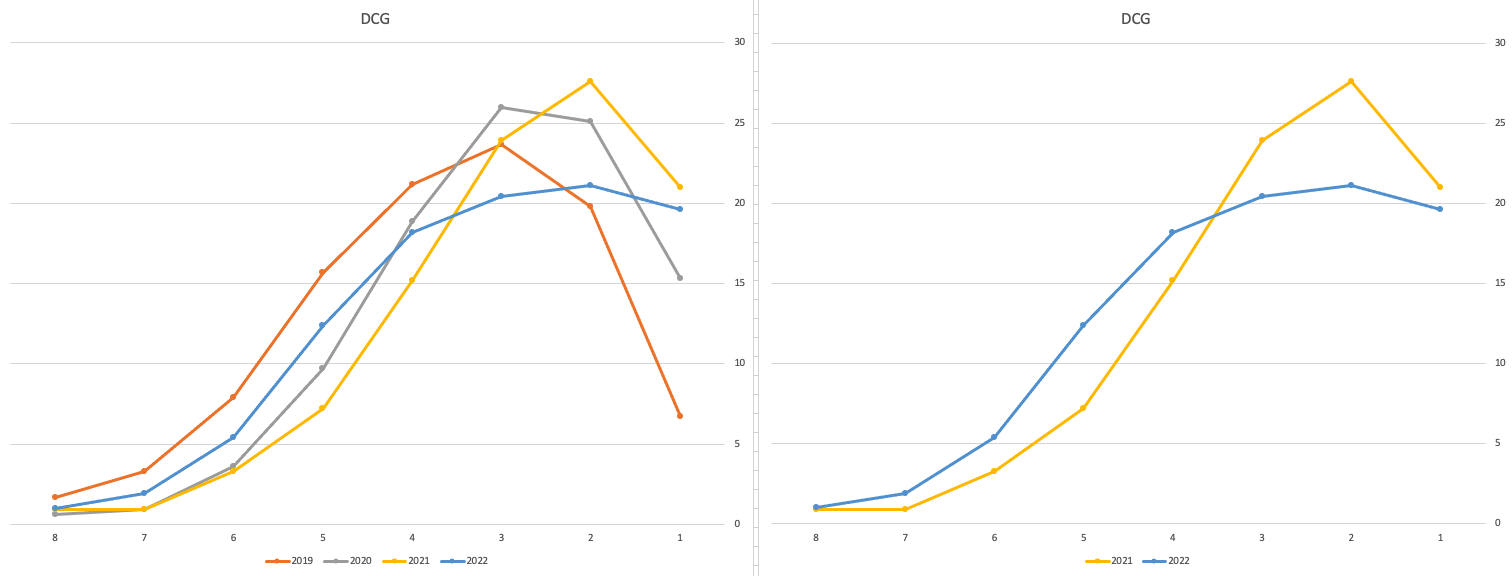
Yes there is obvious grade deflation and almost back to 2019 profile, with the exception of H1s again.
I’ve mentioned some possible grade deflation in various subjects, but there are also subjects where the profile very closely matches the 2021 profile. We have seen above English is one of those. Others include Technology, Art and Computer Science.
I’ve analyzed many more subjects and similar shifting of the profile is evident in those. Has the Dept of Education and State Examinations Commission taken steps to start deflating grades from the highs of 2021? I’d said the answer lies in the data, and the data I’ve looked at shows they have started the deflation process. This might take another couple of years to work out of the system and we will be back to “normal” pre-covid profiles. Which raises another interesting question, Was the grade profile for subjects, pre-covid, fitted to the curve? For the core set of subjects and for many of the more popular subjects, the data seems to indicate this. Maybe the “normal” distribution of marks is down to the “normal” distribution of abilities of the student population each year, or have grades been normalised in some way each year, for years, even decades?
For this analysis I’ve used a variety of tools including Excel, Python and Oracle Analytics.
The Dataset used can be found under Dataset menu, and listed as ‘Leaving Certificate 2015-2022’. An additional Dataset, I’ll be adding soon, will be for CAO Points Profiles 2015-2022.
Python Data Profiling libraries
One of the most common, and sometimes boring, task when working with datasets is writing some code to profile the data. Most data scientists will have built a set of tools/scripts to help them with this regular and slightly boring task. As with most IT tasks we should be trying to automate what we can, to allow us to spend more time on more important tasks, such as deriving insights and delivering value to the business, instead of repeatedly writing code to produce various statistics about the data and drawing pretty pictures.
I’ve written previously about automating and using some data profiling libraries to help us with this task. There are lots of packages available on pypi.og and on GitHub. Below I give examples of 5 Python Data Profiling libraries, with links to their GitHubs.
This is probably one of the better and more popular Python libraries for exploring data. The aim is to make it as simple as possible using one line of code.
pandas-profilingpackage naming was changed. To continue profiling data useydata-profilinginstead
import pandas_profiling as pp
df2.profile_report()





2. skimpy
Following the line line of code approach skimpy is a light weight tool that provides summary statistics about variables in data frames. They like to thing skimpy is a super-charged version of df.describe(). Skimpy also has some automated data cleaning functions.
from skimpy import skim
skim(df)
3. dataprep
Dataprep has multiple features with the two main features being EDA (Exploratory Data Analysis) and Data Cleaning. For EDA functionality, it is build to scale for larger data sets and provides some interactive charts.
from dataprep.eda import *
from dataprep.datasets import load_dataset
from dataprep.eda import plot, plot_correlation, plot_missing, plot_diff, create_report
df = load_dataset("titanic")
plot(df)
plot_missing(df)
plot_missing(df, "Age")

4. SweetViz
Sweetviz creates high-density visualizations to help kickstart EDA with just two lines of code. Output is a fully self-contained HTML application.
import pandas as pd
import sweetviz as sv
df = pd.read_csv('../input/titanic/train.csv')
report = sweetviz.analyze(df, "Survived")
5. AutoViz
Autoviz works on visualizing the relationship of the data, it can find the most impactful features and plot creative visualization.
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
df = AV.AutoViz('titanic_train.csv')
Always try to automate the boring tasks, and using one of these packages is a step towards doing for for any Data Analysts, Data Sciences, Data Engineers, Machine Learning Engineer, AI Engineer, etc.
Comparing Cluster Algorithms on Density Data
In a previous posted I gave a detailed description of using DBScan to create clusters for a dataset containing different density based data. This “manufactured” dataset was created to illustrate how and why DBScan can be used.
But taking the previous post in isolation is perhaps not recommended. As a Data Scientist you will need to use many Clustering algorithms to determine which algorithm can best identify the patterns in your data, and this can be determined by the type of data distributions within the dataset.
The DBScan post created the following diagrams. The diagram on the left is a plot of the dataset where we can easily identify different groupings/clusters. The diagram on the right illustrates the clusters identified by DBScan. As you can see it did a good job.
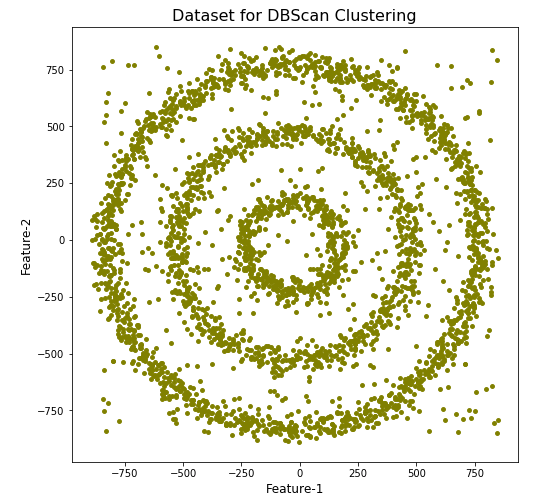
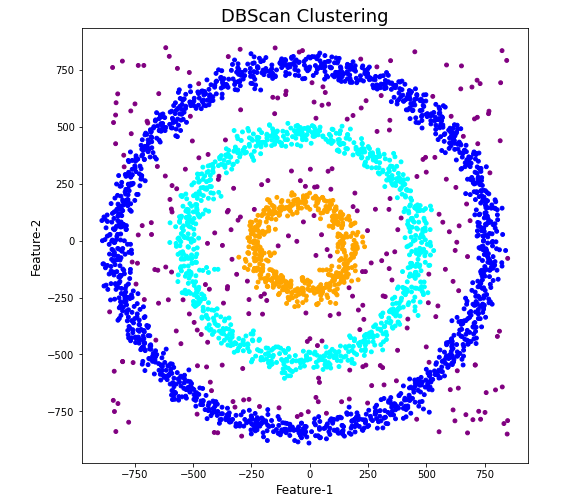
We can see the three clusters and the noisy data point which were added to the dataset.
But what about other Clustering algorithms? What about k-Means and Hierarchical Clustering algorithms? How would they perform on this dataset?
Here is the code for k-Means with three clusters. Three clusters was selected as we have three clear clusters in the dataset.
#k-Means with 3 clusters
from sklearn.cluster import KMeans
k_means=KMeans(n_clusters=3,random_state=42)
k_means.fit(df[[0,1]])
df['KMeans_labels']=k_means.labels_
# Plotting resulting clusters
colors=['purple','red','blue','green']
plt.figure(figsize=(10,10))
plt.scatter(df[0],df[1],c=df['KMeans_labels'],cmap=matplotlib.colors.ListedColormap(colors),s=15)
plt.title('K-Means Clustering',fontsize=18)
plt.xlabel('Feature-1',fontsize=12)
plt.ylabel('Feature-2',fontsize=12)
plt.show()
Here is the code for Hierarchical Clustering, again three clusters was selected.
from sklearn.cluster import AgglomerativeClustering
model = AgglomerativeClustering(n_clusters=3, affinity='euclidean')
model.fit(df[[0,1]])
df['HR_labels']=model.labels_
# Plotting resulting clusters
plt.figure(figsize=(10,10))
plt.scatter(df[0],df[1],c=df['HR_labels'],cmap=matplotlib.colors.ListedColormap(colors),s=15)
plt.title('Hierarchical Clustering',fontsize=20)
plt.xlabel('Feature-1',fontsize=14)
plt.ylabel('Feature-2',fontsize=14)
plt.show()
The diagrams from both of these are shown below.
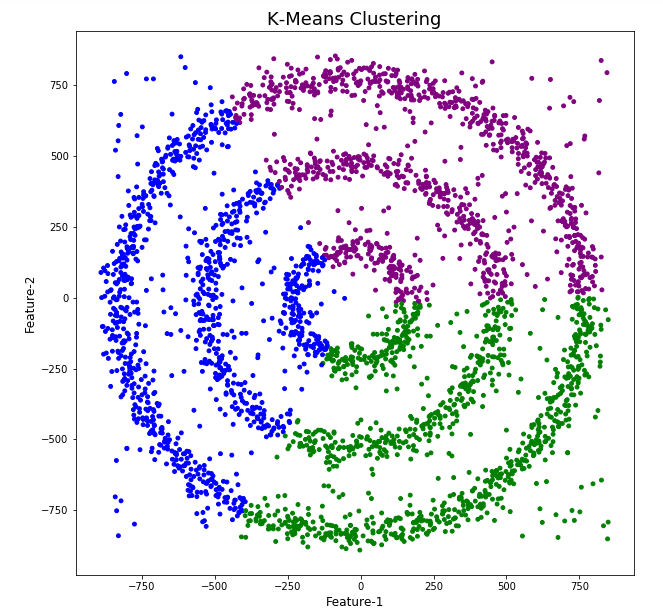
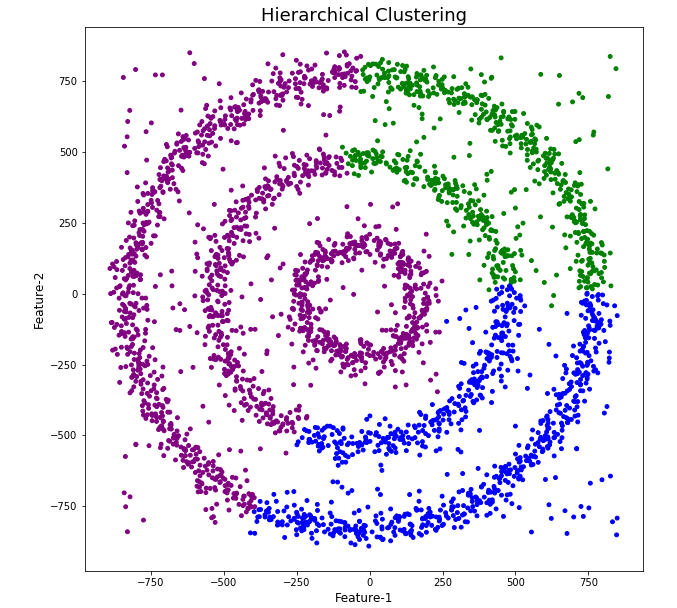
As you can see the results generated by these alternative Clustering algorithms produce very different results to what was produced by DBScan (see image at top of post) and we can easily see which algorithm best fits the dataset used.
Make sure you check out the post on DBScan.
DBScan Clustering in Python
Unsupervised Learning is a common approach for discovering patterns in datasets. The main algorithmic approach in Unsupervised Learning is Clustering, where the data is searched to discover groupings, or clusters, of data. Each of these clusters contain data points which have some set of characteristics in common with each other, and each cluster is distinct and different. There are many challenges with clustering which include trying to interpret the meaning of each cluster and how it is related to the domain in question, what is the “best” number of clusters to use or have, the shape of each cluster can be different (not like the nice clean examples we see in the text books), clusters can be overlapping with a data point belonging to many different clusters, and the difficulty with trying to decide which clustering algorithm to use.
The last point above about which clustering algorithm to use is similar to most problems in Data Science and Machine Learning. The simple answer is we just don’t know, and this is where the phases of “No free lunch” and “All models are wrong, but some models are model that others”, apply. This is where we need to apply the various algorithms to our data, and through a deep process of investigation the outputs, of each algorithm, need to be investigated to determine what algorithm, the parameters, etc work best for our dataset, specific problem being investigated and the domain. This involve the needs for lots of experiments and analysis. This work can take some/a lot of time to complete.
The k-Means clustering algorithm gets a lot of attention and focus for Clustering. It’s easy to understand what it does and to interpret the outputs. But it isn’t perfect and may not describe your data, as it can have different characteristics including shape, densities, sparseness, etc. k-Means focuses on a distance measure, while algorithms like DBScan can look at the relative densities of data. These two different approaches can produce by different results. Careful analysis of the data and the results/outcomes of these algorithms needs some care.
Let’s illustrate the use of DBScan (Density Based Spatial Clustering of Applications with Noise), using the scikit-learn Python package, for a “manufactured” dataset. This example will illustrate how this density based algorithm works (See my other blog post which compares different Clustering algorithms for this same dataset). DBSCAN is better suited for datasets that have disproportional cluster sizes (or densities), and whose data can be separated in a non-linear fashion.
There are two key parameters of DBScan:
- eps: The distance that specifies the neighborhoods. Two points are considered to be neighbors if the distance between them are less than or equal to eps.
- minPts: Minimum number of data points to define a cluster.
Based on these two parameters, points are classified as core point, border point, or outlier:
- Core point: A point is a core point if there are at least minPts number of points (including the point itself) in its surrounding area with radius eps.
- Border point: A point is a border point if it is reachable from a core point and there are less than minPts number of points within its surrounding area.
- Outlier: A point is an outlier if it is not a core point and not reachable from any core points.
The algorithm works by randomly selecting a starting point and it’s neighborhood area is determined using radius eps. If there are at least minPts number of points in the neighborhood, the point is marked as core point and a cluster formation starts. If not, the point is marked as noise. Once a cluster formation starts (let’s say cluster A), all the points within the neighborhood of initial point become a part of cluster A. If these new points are also core points, the points that are in the neighborhood of them are also added to cluster A. Next step is to randomly choose another point among the points that have not been visited in the previous steps. Then same procedure applies. This process finishes when all points are visited.
Let’s setup our data set and visualize it.
import numpy as np
import pandas as pd
import math
import matplotlib.pyplot as plt
import matplotlib
#initialize the random seed
np.random.seed(42) #it is the answer to everything!
#Create a function to create our data points in a circular format
#We will call this function below, to create our dataframe
def CreateDataPoints(r, n):
return [(math.cos(2*math.pi/n*x)*r+np.random.normal(-30,30),math.sin(2*math.pi/n*x)*r+np.random.normal(-30,30)) for x in range(1,n+1)]
#Use the function to create different sets of data, each having a circular format
df=pd.DataFrame(CreateDataPoints(800,1500)) #500, 1000
df=df.append(CreateDataPoints(500,850)) #300, 700
df=df.append(CreateDataPoints(200,450)) #100, 300
# Adding noise to the dataset
df=df.append([(np.random.randint(-850,850),np.random.randint(-850,850)) for i in range(450)])
plt.figure(figsize=(8,8))
plt.scatter(df[0],df[1],s=15,color='olive')
plt.title('Dataset for DBScan Clustering',fontsize=16)
plt.xlabel('Feature-1',fontsize=12)
plt.ylabel('Feature-2',fontsize=12)
plt.show()

We can see the dataset we’ve just created has three distinct circular patterns of data. We also added some noisy data too, which can be see as the points between and outside of the circular patterns.
Let’s use the DBScan algorithm, using the default setting, to see what it discovers.
from sklearn.cluster import DBSCAN
#DBSCAN without any parameter optimization and see the results.
dbscan=DBSCAN()
dbscan.fit(df[[0,1]])
df['DBSCAN_labels']=dbscan.labels_
# Plotting resulting clusters
colors=['purple','red','blue','green']
plt.figure(figsize=(8,8))
plt.scatter(df[0],df[1],c=df['DBSCAN_labels'],cmap=matplotlib.colors.ListedColormap(colors),s=15)
plt.title('DBSCAN Clustering',fontsize=16)
plt.xlabel('Feature-1',fontsize=12)
plt.ylabel('Feature-2',fontsize=12)
plt.show()
#Not very useful !
#Everything belongs to one cluster.
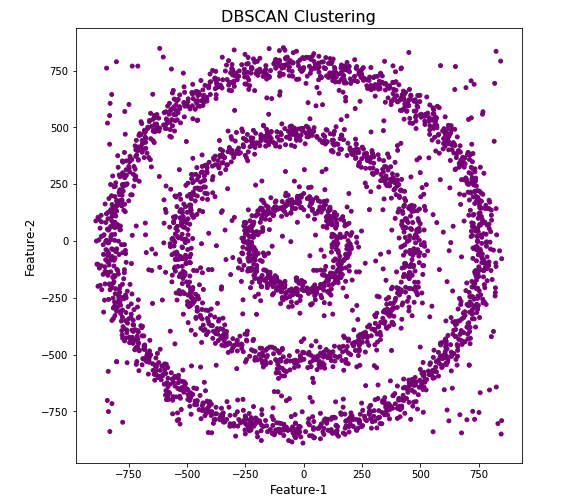
Everything is the one color! which means all data points below to the same cluster. This isn’t very useful and can at first seem like this algorithm doesn’t work for our dataset. But we know it should work given the visual representation of the data. The reason for this occurrence is because the value for epsilon is very small. We need to explore a better value for this. One approach is to use KNN (K-Nearest Neighbors) to calculate the k-distance for the data points and based on this graph we can determine a possible value for epsilon.
#Let's explore the data and work out a better setting
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors(n_neighbors=2)
nbrs = neigh.fit(df[[0,1]])
distances, indices = nbrs.kneighbors(df[[0,1]])
# Plotting K-distance Graph
distances = np.sort(distances, axis=0)
distances = distances[:,1]
plt.figure(figsize=(14,8))
plt.plot(distances)
plt.title('K-Distance - Check where it bends',fontsize=16)
plt.xlabel('Data Points - sorted by Distance',fontsize=12)
plt.ylabel('Epsilon',fontsize=12)
plt.show()
#Let’s plot our K-distance graph and find the value of epsilon

Look at the graph above we can see the main curvature is between 20 and 40. Taking 30 at the mid-point of this we can now use this value for epsilon. The value for the number of samples needs some experimentation to see what gives the best fit.
Let’s now run DBScan to see what we get now.
from sklearn.cluster import DBSCAN
dbscan_opt=DBSCAN(eps=30,min_samples=3)
dbscan_opt.fit(df[[0,1]])
df['DBSCAN_opt_labels']=dbscan_opt.labels_
df['DBSCAN_opt_labels'].value_counts()
# Plotting the resulting clusters
colors=['purple','red','blue','green', 'olive', 'pink', 'cyan', 'orange', 'brown' ]
plt.figure(figsize=(8,8))
plt.scatter(df[0],df[1],c=df['DBSCAN_opt_labels'],cmap=matplotlib.colors.ListedColormap(colors),s=15)
plt.title('DBScan Clustering',fontsize=18)
plt.xlabel('Feature-1',fontsize=12)
plt.ylabel('Feature-2',fontsize=12)
plt.show()

When we look at the dataframe we can see it create many different cluster, beyond the three that we might have been expecting. Most of these clusters contain small numbers of data points. These could be considered outliers and alternative view of this results is presented below, with this removed.
df['DBSCAN_opt_labels']=dbscan_opt.labels_ df['DBSCAN_opt_labels'].value_counts() 0 1559 2 898 3 470 -1 282 8 6 5 5 4 4 10 4 11 4 6 3 12 3 1 3 7 3 9 3 13 3 Name: DBSCAN_opt_labels, dtype: int64
The cluster labeled with -1 contains the outliers. Let’s clean this up a little.
df2 = df[df['DBSCAN_opt_labels'].isin([-1,0,2,3])]
df2['DBSCAN_opt_labels'].value_counts()
0 1559
2 898
3 470
-1 282
Name: DBSCAN_opt_labels, dtype: int64
# Plotting the resulting clusters
colors=['purple','red','blue','green', 'olive', 'pink', 'cyan', 'orange']
plt.figure(figsize=(8,8))
plt.scatter(df2[0],df2[1],c=df2['DBSCAN_opt_labels'],cmap=matplotlib.colors.ListedColormap(colors),s=15)
plt.title('DBScan Clustering',fontsize=18)
plt.xlabel('Feature-1',fontsize=12)
plt.ylabel('Feature-2',fontsize=12)
plt.show()

See my other blog post which compares different Clustering algorithms for this same dataset.
Biases in Data
We work with data in a variety of different ways throughout our organisation. Some people are consumers of data and in particular data that is the output of various data analytics, machine learning or artificial intelligence applications. Being a consumer of data from these applications we (easily) made the assumption that the data used is correct and the results being presented to us (in various forms) is correct.
But all too often we hear about some adjustments being made to the data or the processing to correct “something” that was discovered. One the these “something” can be classified as a Data Bias. This kind of problem has been increasing in importance over the past couple of years. Some of this importance has been led by the people involved in creating and process this data discovering certain issues or “something” in the data. Some has been identified by the consumer when the discover “something” odd or unusual about the data. This list could get very long, but another aspect is with the introduction of EU GDPR, there is now a legal aspect to ensuring no data biases exist. Part of the problem with EU GDPR, in this aspect, is it is very vague on what is required. This in turn has caused some confusion on what is required of organisations and their staff. But with the arrival of the EU AI Regulations there is a renewed focus on identifying and addressing Data Bias. With the EU AI Regulations there is a requirement that Data Bias is addressed at each step when data is collected, processed and generated.
The following list outlines some of the typical Data Bias scenarios you or you organisation may encounter.
- Definition bias: Occurs when someone words or phrases a problem or description of data based on their own requirements, rather than based on the organisational or domain definitions. This can lead to misleading results or when commencing an analytics project can lead the project is a specific (biased) direction
- Sample bias: This occurs when the dataset created for input to the analytics or machine learning does not reflect the data from the original data sources. The sampling method used fails to attain true randomness before selection This can result in models having lower accuracy with certain sub-groups of the data (i.e. Customers) which might not have been included or under-represented in the sampled dataset. Sometimes this type of bias is referred to as selection bias.
- Measurement bias: This occurs when data collected for training differs from that collected in the original data sources. It can also occur when incorrect measurements or calculations are applied to the data. An example of this bias occurs with inconsistent annotation labeling and/or with re-coding of data to give incorrect or misleading meaning.
- Selection bias: This occurs when the dataset created for analytics is not large enough or representative enough to include all possible data combinations. This can occur due to human or algorithmic data processing biases. Sample bias plays a sub-role within Selection bias. This can happen at both record and attribute/feature selection levels. Selection bias is sometimes referred to as Exclusion bias, as certain data is excluded by the whoever is creating the dataset.
- Recall bias: This bias arises when labels (target feature) are inconsistently given based on subjective observations. This results in lower accuracy.
- Observer bias: This is the effect of seeing what you expect to see or want to see in data. The observers have subjective thoughts about their study, either conscious or unconscious. This leads to incorrectly labelled or recorded data. For example, two data scientist give different labels for an event. Their labeling is based on the subjective thoughts rather than following provided guidelines or seeking verification for their decisions. Sometimes this type of bias is referred to as Confirmation bias.
- Racial & Gender bias & Similar: Racial bias occurs when data skews in favor of particular demographics. Similar scenarios can occur for gender and other similar types of data. For example, facial recognition fails to recognize people of color as these have been under represented in the training datasets.
- Minority bias: This is similar to the previous Racial and Gender bias. This occurs when a minority group(s) are excluded from the dataset.
- Association bias: This occurs when the data reinforces or multiplies a cultural bias. Your dataset may have a collection of jobs in which all men have job X and all women have job Y. A machine learning model built using this data will preclude women from job X and men from job Y. Association bias is known for creating gender bias.
- Algorithmic bias: Occurs when the algorithm is selective on what data it uses to create a model for the data and problem. Extra validation checks and testing is needed to ensure no additional biases have been created and no biases (based on the previous types above) have been amplified by the algorithm.
- Reporting bias: Occurs when only a selection of results or outcomes are present. The person preparing the data is selective on what information they share with others. This typically leads to under reporting of certain, and somethings important, information.
- Confirmation bias: Occurs when the data/results are interpreted favoring information that confirms previously existing beliefs.
- Response / Non-Response bias: Occurs when results from surveys can be considered misleading based on the questions asked and subset of population who responded to the survey. If 95% of respondents said they link surveys, then is misleading. The quality and accuracy of the data will be poor in such situations
Ireland AI Strategy (2021)
Over the past year or more there was been a significant increase in publications, guidelines, regulations/laws and various other intentions relating to these. Artificial Intelligence (AI) has been attracting a lot of attention. Most of this attention has been focused on how to put controls on how AI is used across a wide range of use cases. We have heard and read lots and lots of stories of how AI has been used in questionable and ethical scenarios. These have, to a certain extent, given the use of AI a bit of a bad label. While some of this is justified, some is not, but some allows us to question the ethical use of these technologies. But not all AI, and the underpinning technologies, are bad. Most have been developed for good purposes and as these technologies mature they sometimes get used in scenarios that are less good.
We constantly need to develop new technologies and deploy these in real use scenarios. Ireland has a long history as a leader in the IT industry, with many of the top 100+ IT companies in the world having research and development operations in Ireland, as well as many service suppliers. The Irish government recently released the National AI Strategy (2021).
“The National AI Strategy will serve as a roadmap to an ethical, trustworthy and human-centric design, development, deployment and governance of AI to ensure Ireland can unleash the potential that AI can provide”. “Underpinning our Strategy are three core principles to best embrace the opportunities of AI – adopting a human-centric approach to the application of AI; staying open and adaptable to innovations; and ensuring good governance to build trust and confidence for innovation to flourish, because ultimately if AI is to be truly inclusive and have a positive impact on all of us, we need to be clear on its role in our society and ensure that trust is the ultimate marker of success.” Robert Troy, Minister of State for Trade Promotion, Digital and Company Regulation.
The eight different strands are identified and each sets out how Ireland can be an international leader in using AI to benefit the economy and society.
- Building public trust in AI
- Strand 1: AI and society
- Strand 2: A governance ecosystem that promotes trustworthy AI
- Leveraging AI for economic and societal benefit
- Strand 3: Driving adoption of AI in Irish enterprise
- Strand 4: AI serving the public
- Enablers for AI
- Strand 5: A strong AI innovation ecosystem
- Strand 6: AI education, skills and talent
- Strand 7: A supportive and secure infrastructure for AI
- Strand 8: Implementing the Strategy
Each strand has a clear list of objectives and strategic actions for achieving each strand, at national, EU and at a Global level.
Check out the full document here.

Listed in 2 categories of “Who’s Who in Data Science & Machine Learning?”
I’ve received notification I’ve been listed in the “Who’s Who in Data Science & Machine Learning?” lists created by Onalytica. I’ve been listed in not just one category but two categories. These are:
- Key Opinion Leaders discussing Data Science & Machine Learning
- Big Data

This is what Onalytica says about their report and how the list for each category was put together. “The influential experts are selected using Onalytica’s 4 Rs methodology (Reach, Resonance, Relevance and Reference). Quantitative data is pulled through LinkedIn, Twitter, Personal Blogs, YouTube, Podcast, and Forbes channels, and our qualitative data is pulled by our insights and analytics team, capturing offline influenc”. “All the influential experts featured are categorised by influencer persona, the sector they work in, their role within that sector, and more from our curated database of 1m+ influencers”. “Our Who’s Who lists are created using the Onalytica platform which has a curated database of over 1 million influencers. Our platform allows you to discover, validate and categorise influencers quickly and easily via keyword searches. Our lists are made using carefully created Boolean queries which then rank influencers by resonance, relevance, reach and reference, meaning influencers are not only ranked by themselves, but also by how much other influencers are referring to them. The lists are then validated, and filters are used to split the influencers up into the categories that are seen in the list.”
Check out the full report on “Who’s Who in Data Science & Machine Learning?“
AutoML, what is it good for? It Depends!
Automated Machine Learning (AutoML) seems to be everywhere and every Analytics product and SaaS offering seems to have some element of AutoML built into them. Part of the reason for this is because most of the market analysts, such as Gartner etc., have been rating Machine Learning (ML) products and services based on them having an AutoML feature.

Some of the benefits of AutoML is it will automatically generate a ML model for you without you having to worry about any of the technical details and the various statistical tests to measure if the model is useful. This kind of message has resulted is lots and lots of articles talking about the death of the Data Scientist, as they are no longer needed. We must remember ML is only one of the tools and skills of the data scientist.
This can all sound great. No need to hire these expensive data scientists, I can just use this AutoML software to create a ML model, for my data, and life will be good with all these wonderful predictions. Just think of the money I’ll be making and saving!
Where the fun comes into all of this is when someone issues legal proceedings based on what one of these AutoML models has predicted. The AutoML has made an incorrect prediction. The problem you now face, probably in court, is trying to justify the prediction by saying the machine/computer/algorithm made it, and you have no idea how or what it is doing to make the prediction. Good luck in a court explaining that to a judge and/or jury. Be prepared to hand over lots of money
What is missing is the human in the loop, and in most cases this will be the data scientist or machine learning engineer (or someone else with a really cool job title). Part of their job is to evaluate lots of difference models for you data (remember they will create lots and lots of models and not just one!), determine (from experimentation) what algorithms work best with your data and problem, optimize these models and assess the impact of changing hyperparameters, look at how these ML models are behaving, are there any biases in the model or data, use a wide variety of statistic tests to assess the models, examine how the model works with different sub-parts of the data (customers), look at any potential legal and legislative issues not just in one geographic but across many disparate regions all of which have different legal requirements, etc.
As you can see there are many additional tasks beyond the ML steps needed to create, verify and select a ML to use. All of this is before you look at how it can be deployed in your production systems/architecture and building out you MLOps.
One importing characteristic of having the human in the loop is Explainability. Explainability of the process followed, what models were produced, the effect of tuning and opimizing, possible biases and mitigating steps, etc etc The list goes on and on. This the role of the data scientist and now it might look like a good idea to hire a good data scientist who understands all of this.

Taking a little step back, AutoML is kind of good cool feature/tool. A lot of the main steps of creating all those ML models, tuning them and evaluating them, etc can be very boring work. You do same steps for each model and do it all over again for the next, and so on for the tens or hundreds of models you will be creating. Most data scientists will have scripts in their toolbox (based from their experience) to automatically perform all of these steps and output the results. I mentioned the word experience in the last sentence. It can take a bit of time to build up to this. The AutoML products will do all of this automatically for you hence you don’t have to hire a data scientist to do it (see what I said above about this).
I mentioned above some of the challenges and the need to keep a human in the loop. AutoML can be seen as another tool to assist the data scientist and not to replace them. AutoML can be used to to help the data scientist work towards identifying what ML models to use. But this can be a bit of a challenge to do. It depends on what product or library you use. Some AutoML solutions act as a black box. Kind of like the image at the top of this post. These are simple to use but the draw back is there is not explainability or ability of the data scientist to really assess what is happening at each step. There are AutoML products/solutions that allow you to inspect and monitor what is happening at each step within AutoML. The diagram given able is one example of this. This allows for the human in the loop and allows for explainability. If the data scientist sees some unusual direction being taken by AutoML they can see where and why this is happening and can take corrective action. AutoML isn’t a black box in this scenario.
I mentioned above, AutoML can be another tool for the data scientist to use. Look on AutoML as quick way to see what might be possible. Using the information from each step of AutoML, the data scientist can use this information to guide them towards creating a more suitable and usable ML model, and do so in perhaps a slightly shorter space of time.
Going back to the title of the post ‘AutoML, what is it good for?’, the answer really is ‘It Depends!’, but if you do use it, be careful how you use the models and results beyond doing some simple investigation. And be careful of product offerings saying you don’t need anything else.

You must be logged in to post a comment.