
Hive
Hivemall: Feature Scaling based on Min-Max values
Once of the most common tasks when preparing data for data mining and machine learning is to take numerical data and scale it. Most enterprise and advanced tools and languages do this automatically for you, but with lower level languages you need to perform the task. There are a number of approaches to doing this. In this example we will use the Min-Max approach.
With the Min-Max feature scaling approach, we need to find the Minimum and Maximum values of each numerical feature. Then using a scaling function that will re-scale the data to a Zero to One range. The general formula for this is.

Using the IRIS data set as the data set (and loaded in previous post), the first thing we need to find is the minimum and maximum values for each feature.
select min(features[0]), max(features[0]),
min(features[1]), max(features[1]),
min(features[2]), max(features[2]),
min(features[3]), max(features[3])
from iris_raw;
we get the following results.
4.3 7.9 2.0 4.4 1.0 6.9 0.1 2.5
The format of the results can be a little confusing. What this list gives us is the results for each of the four features.
For feature[0], sepal_length, we have a minimum value of 4.3 and a maximum value of 7.9.
Similarly,
feature[1], sepal_width, min=2.0, max=4.4
feature[2], petal_length, min=1.0, max=6.9
feature[3], petal_width, min=0.1, max=2.5
To use these minimum and maximum values, we need to declare some local session variables to store these.
set hivevar:feature0_min=4.3;
set hivevar:feature0_max=7.9;
set hivevar:feature1_min=2.0;
set hivevar:feature1_max=4.4;
set hivevar:feature2_min=1.0;
set hivevar:feature2_max=6.9;
set hivevar:feature3_min=0.1;
set hivevar:feature3_max=2.5;After setting those variables we can now write a SQL SELECT and use the add_bias function to perform the calculations.
select rowid, label,
add_bias(array(
concat("1:", rescale(features[0],${f0_min},${f0_max})),
concat("2:", rescale(features[1],${f1_min},${f1_max})),
concat("3:", rescale(features[2],${f2_min},${f2_max})),
concat("4:", rescale(features[3],${f3_min},${f3_max})))) as features
from iris_raw;
and we get
> 1 Iris-setosa ["1:0.22222215","2:0.625","3:0.0677966","4:0.041666664","0:1.0"]
> 2 Iris-setosa ["1:0.16666664","2:0.41666666","3:0.0677966","4:0.041666664","0:1.0"]
> 3 Iris-setosa ["1:0.11111101","2:0.5","3:0.05084745","4:0.041666664","0:1.0"]
...Other feature scaling methods, available in Hivemall, include L1/L2 Normalization and zscore.
HiveMall: Docker image setup
In a previous blog post I introduced HiveMall as a SQL based machine learning language available for Hadoop and integrated with Hive.
If you have your own Hadoop/Big Data environment, I provided the installation instructions for Hivemall, in that blog post
An alternative is to use Docker. There is a HiveMall Docker image available. A little warning before using this image. It isn’t updated with the latest release but seems to get updated twice a year. Although you may not be running the latest version of HiveMall, you will have a working environment that will have almost all the functionality, bar a few minor new features and bug fixes.
To get started, you need to make sure you have Docker running on your machine and you have logged into your account. The docker image is available from Docker Hub. Take note of the version number for the latest version of the docker image. In this example it is 20180924

Open a terminal window and run the following command. This will download and extract all the image files.
docker pull hivemall/latest:20180924
Until everything is completed.
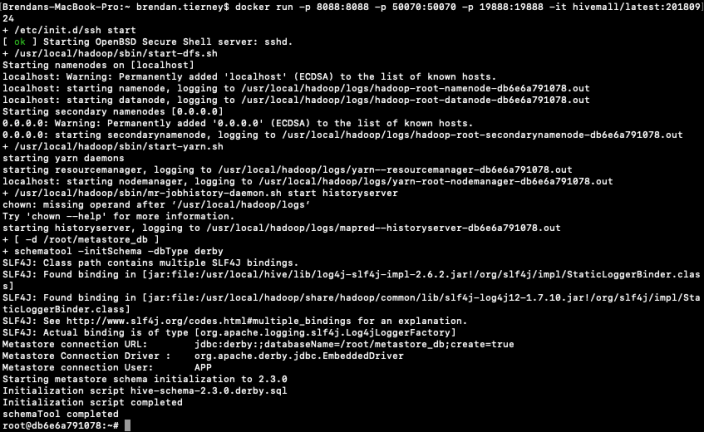
This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run
docker run -p 8088:8088 -p 50070:50070 -p 19888:19888 -it hivemall/latest:20180924Consider creating a shell script for this, to make it easier each time you want to run the image.
Now seed Hive with some data. The typical example uses the IRIS data set. Run the following command to do this. This script downloads the IRIS data set, creates a number directories and then creates an external table, in Hive, to point to the IRIS data set.
cd $HOME && ./bin/prepare_iris.sh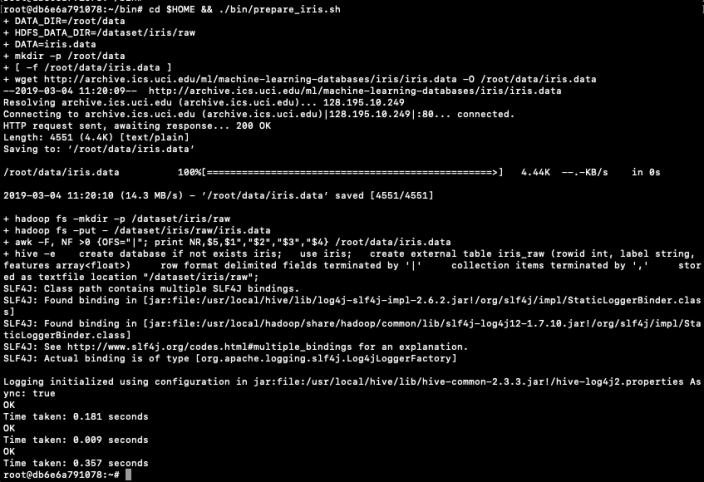
Now open Hive and list the databases.
hive -S hive> show databases; OK default iris Time taken: 0.131 seconds, Fetched: 2 row(s)
Connect to the IRIS database and list the tables within it.
hive> use iris; hive> show tables; iris_raw
Now query the data (150 records)
hive> select * from iris_raw; 1 Iris-setosa [5.1,3.5,1.4,0.2] 2 Iris-setosa [4.9,3.0,1.4,0.2] 3 Iris-setosa [4.7,3.2,1.3,0.2] 4 Iris-setosa [4.6,3.1,1.5,0.2] 5 Iris-setosa [5.0,3.6,1.4,0.2] 6 Iris-setosa [5.4,3.9,1.7,0.4] 7 Iris-setosa [4.6,3.4,1.4,0.3] 8 Iris-setosa [5.0,3.4,1.5,0.2] 9 Iris-setosa [4.4,2.9,1.4,0.2] 10 Iris-setosa [4.9,3.1,1.5,0.1] 11 Iris-setosa [5.4,3.7,1.5,0.2] 12 Iris-setosa [4.8,3.4,1.6,0.2] 13 Iris-setosa [4.8,3.0,1.4,0.1 ...
Find the min and max values for each feature.
hive> select
> min(features[0]), max(features[0]),
> min(features[1]), max(features[1]),
> min(features[2]), max(features[2]),
> min(features[3]), max(features[3])
> from
> iris_raw;
4.3 7.9 2.0 4.4 1.0 6.9 0.1 2.5
You are now up and running with HiveMall on Docker.
HiveML : Using SQL for ML on Big Data
It is widely recognised that SQL is one of the core languages that every data scientist needs to know. Not just know but know really well. If you are going to be working with data (big or small) you are going to use SQL to access the data. You may use some other tools and languages as part of your data science role, but for processing data SQL is king.
During the era of big data and hadoop it was all about moving the code to where the data was located. Over time we have seem a number of different languages and approaches being put forward to allow us to process the data in these big environments. One of the most common one is Spark. As with all languages there can be a large learning curve, and as newer languages become popular, the need to change and learn new languages is becoming a lot more frequent.
We have seen many of the main stream database vendors including machine learning in their databases, thereby allowing users to use machine learning using SQL. In the big data world there has been many attempts to do this, to building some SQL interfaces for machine learning in a big data environment.
One such (newer) SQL machine learning engine is called HiveMall. This will allow anyone with a basic level knowledge of SQL to quickly learn machine learning. Apache Hivemall is built to be a scalable machine learning library that runs on Apache Hive, Apache Spark, and Apache Pig.

Hivemall is currently at incubator stage under Apache and version 0.6 was released in December 2018.
I’ve a number of big data/hadoop environments in my home lab and build on a couple of cloud vendors (Oracle and AWS). I’ve completed the installation of Hivemall easily on my Oracle BigDataLite VM and my own custom build Hadoop environment on Oracle cloud. A few simple commands you will have Hivemall up and running. Initially installed for just Hive and then updated to use Spark.
Hivemall expands the analytical functions available in Hive, as well as providing data preparation and the typical range of machine learning functions that are necessary for 97+% of all machine learning use cases.
Download the hivemall-core-xxx-with-dependencies.jar file
# Setup Your Environment $HOME/.hiverc add jar /home/myui/tmp/hivemall-core-xxx-with-dependencies.jar; source /home/myui/tmp/define-all.hive;
This automatically loads all Hivemall functions every time you start a Hive session
# Create a directory in HDFS for the JAR hadoop fs -mkdir -p /apps/hivemall hdfs dfs -chmod -R 777 /apps/hivemall cp hivemall-core-0.4.2-rc.2-with-dependencies.jar hivemall-with-dependencies.jar hdfs dfs -put hivemall-with-dependencies.jar /apps/hivemall/ hdfs dfs -put hivemall-with-dependencies.jar /apps/hive/warehouse
You might want to create a new DB in Hive for your Hivemall work.
CREATE DATABASE IF NOT EXISTS hivemall;
USE hivemall;Then list all the Hivemall functions
show functions "hivemall.*"; +-----------------------------------------+--+ | tab_name | +-----------------------------------------+--+ | hivemall.add_bias | | hivemall.add_feature_index | | hivemall.amplify | | hivemall.angular_distance | | hivemall.angular_similarity | ...
Hivemall for ML using SQL is now up and running. Next step is to do try out the various analytical and ML functions.

You must be logged in to post a comment.