
Machine Learning Models in Python – How long does it take
We keep hearing from people about all the computing resources needed for machine learning. Sometimes it can put people off from trying it as they will think I don’t have those kind of resources.
This is another blog post in my series on ‘How long does it take to create a machine learning model?‘
Check out my previous blog post that used data sets containing 72K, 210K, 660K, 2M and 10M records.
- Creating Machine Learning Models in Oracle Cloud Database service
- Creating Machine Learning Models using Oracle Autonomous Data Warehouse (ADW)
There was some surprising results in those these.
In this test, I’ll be using Python and SciKitLearn package to create models using the same algorithms. There are a few things to keep in mind. Firstly, although they maybe based on the same algorithms, the actual implementation of them will be different in each environment (SQL vs Python).
With using Python for machine learning, one of the challenges we have is getting access to the data. Assuming the data lives in a Database then time is needed to extract that data to the local Python environment. Secondly, when using Python you will be using a computer with significantly less computing resources than a Database server. In this test I used my laptop (MacBook Pro). Thirdly, when extracting the data from the database, what method should be used.
I’ve addressed these below and the Oracle Database I used was the DBaaS I used in my first experiment. This is a Database hosted on Oracle Cloud.
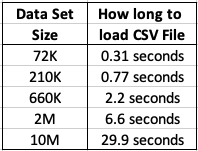
Extracting Data to CSV File
This kind of depends on how you do this. There are hundreds of possibilities available to you, but if you are working with an Oracle Database you will probably be using SQL Developer. I used the ‘export’ option to create a CSV file for each of the data sets. The following table shows how long it took for each data set.

As you can see this is an incredibly slow way of exporting this data. Like I said, there are quicker ways of doing this.
After downloading the data sets, the next step is to see how load it takes to load these CSV files into a pandas data frame in Python. The following table show the timings in seconds.
Extracting Data using cx_Oracle Python package
As I’ll be using Python to create the models and the data exists in an Oracle Database (on Oracle Cloud), I can use the cx_Oracle package to download the data sets into my Python environment. After using the cx_Oracle package to download the data I then converted it into a pandas data frame.
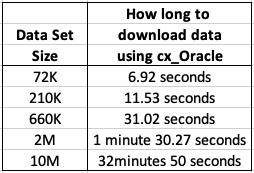
I had the array fetch size set to 10,000. I also experimented with smaller and larger numbers for the array fetch size, but 10,000 seemed to give a quickest results.
How long to create Machine Learning Models in Python
Now we get onto checking out the timings of how long it takes to create a number of machine learning models using different algorithms and using the default settings. The algorithms include Naive Bayes, Decision Tree, GLM, SVM and Neural Networks.
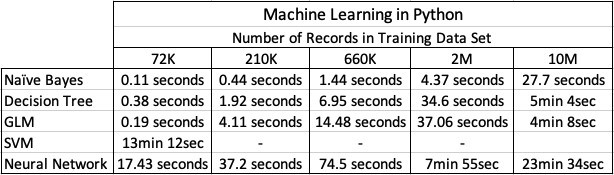
I had to stop including SVM in the tests as it was taking way too long to run. For example I killed the SVM model build on the 210K data set after it was running for 5 hours.
The Neural Network models created had 3 hidden layers.
In addition to creating the models, there was some minor data preparation steps performed including factorizing, normalization and one-hot-coding. This data preparation would be comparable to the automatic data preparation steps performed by Oracle, although Oracle Automatic Data Preparation does a bit of extra work.
At the point I would encourage you to look back at my previous blog posts on timings using Oracle DBaaS and ADW. You will see that Python, in these test cases, was quicker at creating the machine learning models. But with Python the data needed to be extracted from the database and that can take time!
A separate consideration is being able to deploy the models. The time it takes to build models is perhaps not the main consideration. You need to consider ease of deployment and use of the models.
