
cx_oracle
oracledb Python Library – Connect to DB & a few other changes
Oracle have released a new Python library for connecting to Oracle Databases on-premises and on the Cloud. It’s called (very imaginatively, yet very clearly) oracledb. This new Python library replaces the previous library called cx_Oracle. Just consider cx_oracle as obsolete, and use oracledb going forward, as all development work on new features and enhancements will be done to oracledb.
cx_oracle has been around a long time, and it’s about time we have a new and enhanced library that is more flexible and will suit many different deployment scenarios. The previous library (cx_Oracle) was great, but it did require additional software installation with Oracle Client, and some OS environment settings, which at times took a bit of debugging. This makes it difficult/challenging to deploy in different environments, for example IOTs, CI/CD, containers, etc. Deployment environments have changed and the new oracledb library makes it simpler.
To check out the following links for a full list of new features and other details.
Home page: oracle.github.io/python-oracledb
Installation instructions: python-oracledb.readthedocs.io/en/latest/installation.html
Documentation: python-oracledb.readthedocs.io
One of the main differences between the two libraries is how you connect to the Database. With oracledb you need to use named the parameters, and the new library uses a thin connection. If you need the thick connection you can switch to that easily enough.
The following examples will illustrate how to connect to Oracle Database (local and cloud ADW/ATP) and how these are different to using the cx_Oracle library (which needed Oracle Client software installed). Remember the new oracledb library does not need Oracle Client.
To get started, install oracledb.
pip3 install oracledbLocal Database (running in Docker)
To test connection to a local Database I’m using a Docker image of 21c (hence localhost in this example, replace with IP address for your database). Using the previous library (cx_Oracle) you could concatenate the connection details to form a string and pass that to the connection. With oracledb, you need to use named parameters and specify each part of the connection separately.
This example illustrates this simple connection and prints out some useful information about the connection, do we have a healthy connection, are we using thing database connection and what version is the connection library.
p_username = "..."
p_password = "..."
p_dns = "localhost/XEPDB1"
p_port = "1521"
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
print(con.is_healthy())
print(con.thin)
print(con.version)
---
True
True
21.3.0.0.0
Having created the connection we can now query the Database and close the connection.
cur = con.cursor()
cur.execute('select table_name from user_tables')
for row in cur:
print(row)
---
('WHISKIES_DATASET',)
('HOLIDAY',)
('STAGE',)
('DIRECTIONS',)
---
cur.close()
con.close()The code I’ve given above is simple and straight forward. And if you are converting from cx_Oracle, you will probably have minimal changes as you probably had your parameter keywords defined in your code. If not, some simple editing is needed.
To simplify the above code even more, the following does all the same steps without the explicit open and close statements, as these are implicit in this example.
import oracledb
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
with con.cursor() as cursor:
for row in cursor.execute('select table_name from user_tables'):
print(row)(Basic) Oracle Cloud – Autonomous Database, ATP/ADW
Everyone is using the Cloud, Right? If you believe the marketing they are, but in reality most will be working in some hybrid world using a mixture of on-premises and cloud storage. The example given in the previous section illustrated connecting to a local/on-premises database. Let’s now look at connecting to a database on Oracle Cloud (Autonomous Database, ATP/ADW).
With the oracledb library things have been simplified a little. In this section I’ll illustrate a simple connection to a ATP/ADW using a thin connection.
What you need is the location of the directory containing the unzipped wallet file. No Oracle client is needed. If you haven’t downloaded a Wallet file in a while, you should go download a new version of it. The Wallet will contain a pem file which is needed to securely connect to the DB. You’ll also need the password for the Wallet, so talk nicely with your DBA. When setting up the connection you need to provide the directory for the tnsnames.ora file and the ewallet.pem file. If you have downloaded and unzipped the Wallet, these will be in the same directory
import oracledb
p_username = "..."
p_password = "..."
p_walletpass = '...'
#This time we specify the location of the wallet
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high",
config_dir="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_location="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_password=p_walletpass)
print(con)
con.close()This method allows you to easily connect to any Oracle Cloud Database.
(Thick Connection) Oracle Cloud – Autonomous Database, ATP/ADW
If you have Oracle Client already installed and set up, and you want to use a thick connection, you will need to initialize the function init_oracle_client.
import oracledb
p_username = "..."
p_password = "..."
#point to directory containing tnsnames.ora
oracledb.init_oracle_client(config_dir="/Applications/instantclient_19_8/network/admin")
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high")
print(con)
con.close()Warning: Some care is needed with using init_oracle_client. If you use it once in your Python code or App then all connections will use it. You might need to do a code review to look at when this is needed and if not remove all occurrences of it from your Python code.
(Additional Security) Oracle Cloud – Autonomous Database, ATP/ADW
There are a few other additional ways of connecting to a database, but one of my favorite ways to connect involves some additional security, particularly when working with IOT devices, or in scenarios that additional security is needed. Two of these involve using One-way TLS and Mututal TLS connections. The following gives an example of setting up One-Way TLS. This involves setting up the Database to only received data and connections from one particular device via an IP address. This requires you to know the IP address of the device you are using and running the code to connect to the ATP/ADW Database.
To set this up, go to the ATP/ADW details in Oracle Cloud, edit the Access Control List, add the IP address of the client device, disable mutual TLS and download the DB Connection. The following code gives and example of setting up a connection
import oracledb
p_username = "..."
p_password = "..."
adw_dsn = '''(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)
(host=adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=a8rk428ojzuffy_student_high.adb.oraclecloud.com))
(security=(ssl_server_cert_dn="CN=adwc.uscom-east-1.oraclecloud.com,OU=Oracle BMCS US,O=Oracle Corporation,L=Redwood City,ST=California,C=US")))'''
con4 = oracledb.connect(user=p_username, password=p_password, dsn=adw_dsn)This sets up a secure connection between the client device and the Database.
From my initial testing of existing code/applications (although no formal test cases) it does appear the new oracledb library is processing the queries and data quicker than cx_Oracle. This is good and hopefully we will see more improvements with speed in later releases.
Also don’t forget the impact of changing the buffer size for your database connection. This can have a dramatic effect on speeding up your database interactions. Check out this post which illustrates this.
Python-Connecting to multiple Oracle Autonomous DBs in one program
More and more people are using the FREE Oracle Autonomous Database for building new new applications, or are migrating to it.
I’ve previously written about connecting to an Oracle Database using Python. Check out that post for details of how to setup Oracle Client and the Oracle Python library cx_Oracle.
In thatblog post I gave examples of connecting to an Oracle Database using the HostName (or IP address), the Service Name or the SID.
But with the Autonomous Oracle Database things are a little bit different. With the Autonomous Oracle Database (ADW or ATP) you will need to use an Oracle Wallet file. This file contains some of the connection details, but you don’t have access to ServiceName/SID, HostName, etc. Instead you have the name of the Autonomous Database. The Wallet is used to create a secure connection to the Autonomous Database.
You can download the Wallet file from the Database console on Oracle Cloud.

Most people end up working with multiple database. Sometimes these can be combined into one TNSNAMES file. This can make things simple and easy. To use the download TNSNAME file you will need to set the TNS_ADMIN environment variable. This will allow Python and cx_Oracle library to automatically pick up this file and you can connect to the ATP/ADW Database.
But most people don’t work with just a single database or use a single TNSNAMES file. In most cases you need to switch between different database connections and hence need to use multiple TNSNAMES files.
The question is how can you switch between ATP/ADW Database using different TNSNAMES files while inside one Python program?
Use the os.environ setting in Python. This allows you to reassign the TNS_ADMIN environment variable to point to a new directory containing the TNSNAMES file. This is a temporary assignment and over rides the TNS_ADMIN environment variable.
For example,
import cx_Oracle import os os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ATP" p_username = ''p_password = ''p_service = 'atp_high' con = cx_Oracle.connect(p_username, p_password, p_service) print(con) print(con.version) con.close()
I can now easily switch to another ATP/ADW Database, in the same Python program, by changing the value of os.environ and opening a new connection.
import cx_Oracle import os os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ATP" p_username = '' p_password = '' p_service = 'atp_high' con1 = cx_Oracle.connect(p_username, p_password, p_service) ... con1.close() ... os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ADW2" p_username = '' p_password = '' p_service = 'ADW2_high' con2 = cx_Oracle.connect(p_username, p_password, p_service) ... con2.close()
As mentioned previously the setting and resetting of TNS_ADMIN using os.environ, is only temporary, and when your Python program exists or completes the original value for this environment variable will remain.
Machine Learning Models in Python – How long does it take
We keep hearing from people about all the computing resources needed for machine learning. Sometimes it can put people off from trying it as they will think I don’t have those kind of resources.
This is another blog post in my series on ‘How long does it take to create a machine learning model?‘
Check out my previous blog post that used data sets containing 72K, 210K, 660K, 2M and 10M records.
- Creating Machine Learning Models in Oracle Cloud Database service
- Creating Machine Learning Models using Oracle Autonomous Data Warehouse (ADW)
There was some surprising results in those these.
In this test, I’ll be using Python and SciKitLearn package to create models using the same algorithms. There are a few things to keep in mind. Firstly, although they maybe based on the same algorithms, the actual implementation of them will be different in each environment (SQL vs Python).
With using Python for machine learning, one of the challenges we have is getting access to the data. Assuming the data lives in a Database then time is needed to extract that data to the local Python environment. Secondly, when using Python you will be using a computer with significantly less computing resources than a Database server. In this test I used my laptop (MacBook Pro). Thirdly, when extracting the data from the database, what method should be used.
I’ve addressed these below and the Oracle Database I used was the DBaaS I used in my first experiment. This is a Database hosted on Oracle Cloud.
Extracting Data to CSV File
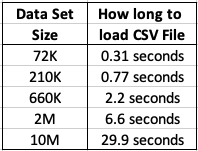
This kind of depends on how you do this. There are hundreds of possibilities available to you, but if you are working with an Oracle Database you will probably be using SQL Developer. I used the ‘export’ option to create a CSV file for each of the data sets. The following table shows how long it took for each data set.

As you can see this is an incredibly slow way of exporting this data. Like I said, there are quicker ways of doing this.
After downloading the data sets, the next step is to see how load it takes to load these CSV files into a pandas data frame in Python. The following table show the timings in seconds.
Extracting Data using cx_Oracle Python package
As I’ll be using Python to create the models and the data exists in an Oracle Database (on Oracle Cloud), I can use the cx_Oracle package to download the data sets into my Python environment. After using the cx_Oracle package to download the data I then converted it into a pandas data frame.
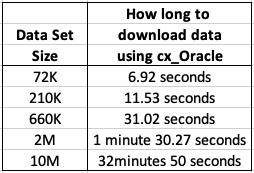
I had the array fetch size set to 10,000. I also experimented with smaller and larger numbers for the array fetch size, but 10,000 seemed to give a quickest results.
How long to create Machine Learning Models in Python
Now we get onto checking out the timings of how long it takes to create a number of machine learning models using different algorithms and using the default settings. The algorithms include Naive Bayes, Decision Tree, GLM, SVM and Neural Networks.
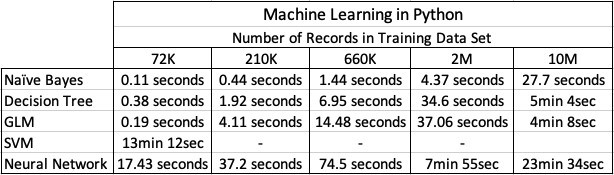
I had to stop including SVM in the tests as it was taking way too long to run. For example I killed the SVM model build on the 210K data set after it was running for 5 hours.
The Neural Network models created had 3 hidden layers.
In addition to creating the models, there was some minor data preparation steps performed including factorizing, normalization and one-hot-coding. This data preparation would be comparable to the automatic data preparation steps performed by Oracle, although Oracle Automatic Data Preparation does a bit of extra work.
At the point I would encourage you to look back at my previous blog posts on timings using Oracle DBaaS and ADW. You will see that Python, in these test cases, was quicker at creating the machine learning models. But with Python the data needed to be extracted from the database and that can take time!
A separate consideration is being able to deploy the models. The time it takes to build models is perhaps not the main consideration. You need to consider ease of deployment and use of the models.

You must be logged in to post a comment.