
AutoML using Pycaret
In this post we will have a look at using the AutoML feature in the Pycaret Python library. AutoML is a popular topic and allows Data Scientists and Machine Learning people to develop potentially optimized models based on their data. All requiring the minimum of input from the Data Scientist. As with all AutoML solutions, care is needed on the eventual use of these models. With various ML and AI Legal requirements around the World, it might not be possible to use the output from AutoML in production. But instead, gives the Data Scientists guidance on creating an optimized model, which can then be deployed in production. This facilitates requirements around model explainability, transparency, human oversight, fairness, risk mitigation and human in the loop.
Some useful links
Pycaret as all your typical Machine Learning algorithms and functions, including for classification, regression, clustering, anomaly detection, time series analysis, and so on.
To install Pycaret run the typical pip command
pip3 install pycaret
If you get any error messages when running any of the following example code, you might need to have a look at your certificates. Locate where Python is installed (for me on a Mac /Applications/Python 3.7) and you will find a command called ‘Install Certificates.command’. and run the following in the Python directory. This should fix what is causing the errors.
Pycaret comes with some datasets. Most of these are the typical introduction datasets you will find in other Python libraries and in various dataset repositories. For our example we are going to use the Customer Credit dataset. This contains data for a classification problem and the aim is to predict customers who are likely to default.
Let’s load the data and have a quick explore
#Don't forget to install Pycaret
#pip3 install pycaret
#Import dataset from Pycaret
from pycaret.datasets import get_data
#Credit defaulters dataset
df = get_data("credit")
The dataframe is displayed for the first five records

What’s the shape of the dataframe? The dataset/frame has 24,000 records and 24 columns.
#Check for the shape of the dataset df.shape (24000, 24)
The dataset has been formatted for a Classification problem with the column ‘default’ being the target or response variable. Let’s have a look at the distribution of records across each value in the ‘default’ column.
df['default'].value_counts() 0 18694 1 5306
And to get the percentage of these distributions,
df['default'].value_counts(normalize=True)*100 0 77.891667 1 22.108333
Before we can call the AutoML function, we need to create our Training and Test datasets.
#Initialize seed for random generators and reproducibility seed = 42 #Create the train set using pandas sampling - seen data set train = df.sample(frac=.8, random_state=seed) train.reset_index(inplace=True, drop=True) print(train.shape) train['default'].value_counts() (19200, 24) 0 14992 1 4208
Now the Test dataset.
#Using samples not available in train as future or unseen data set test = df.drop(train.index) test.reset_index(inplace=True, drop=True) print(test.shape) test['default'].value_counts() (4800, 24) 0 3798 1 1002
Next we need to setup and configure the AutoML experiment.
#Let's Do some magic! from pycaret.classification import * #Setup function initializes the environment and creates the transformation pipeline clf = setup(data=train, target="default", session_id=42)
When the above is run, it goes through a number of steps. The first looks at the dataset, the columns and determines the data types, displaying the following.

If everything is correct, press the enter key to confirm the datatypes, otherwise type ‘quit‘. If you press enter Pycaret will complete the setup of the experiments it will perform to identify a model. A subset of the 60 settings is shown below.

The next step runs the experiments to compare each of the models (AutoML), evaluates them and then prints out a league table of models with values for various model evaluation measures. 5.-Fold cross validation is used for each model. This league table is updated are each model is created and evaluated.
# Compares different models depending on their performance metrics. By default sorted by accuracy
best_model = compare_models(fold=5)For this dataset, this process of comparing the models (AutoML) only takes a few seconds. The constant updating of the league tables is a nice touch. The following shows the final league table created for our AutoML.

The cells colored/highlighted in Yellow tells you which model scored based for that particular evaluation matrix. Here we can see Ridge Classifier scored best using Accuracy and Precision. While the Linear Discriminant Analysis model was best using F1 score, Kappa and MCC.
print(best_model)
RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=42, solver='auto',
tol=0.001)
We can also print the ROC chart.
# Plots the AUC curve
import matplotlib.pyplot as plt
fig = plt.figure()
plt.figure(figsize = (14,10))
plot_model(best_model, plot="auc", scale=1)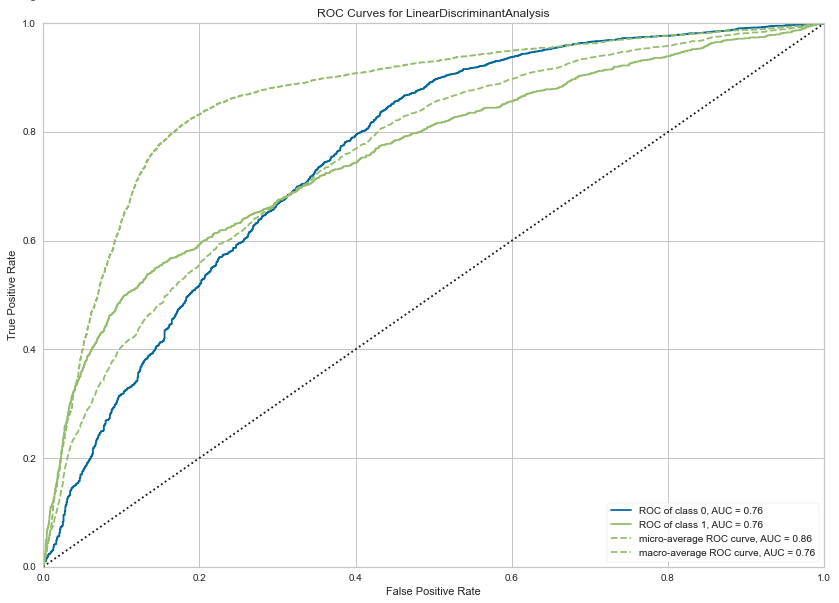
Also the confusion matrix.
plot_model(best_model, plot="confusion_matrix")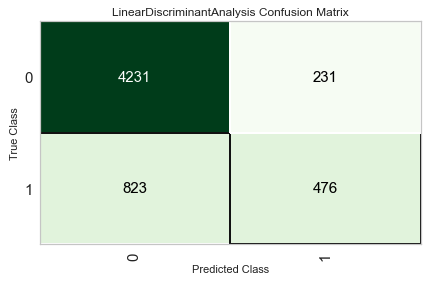
We can also see what the top features are that contribute to the model outcomes (the predictions). This is also referred to as feature importance.
plot_model(best_model, plot="feature")
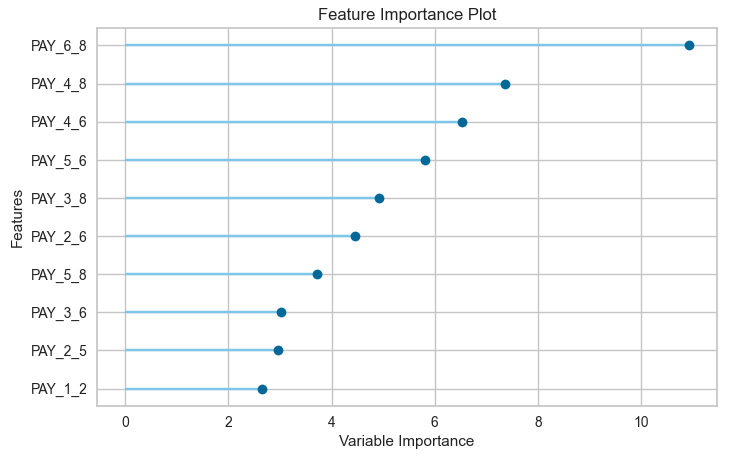
We could take one of these particular models and tune it for a better fit, or we could select the ‘best’ model and tune it.
# Tune model function performs a grid search to identify the best parameters
tuned = tune_model(best_model)
We can now use the tuned model to label the Test dataset and compare the results.
# Predict on holdout set
predict_model(tuned, data=test)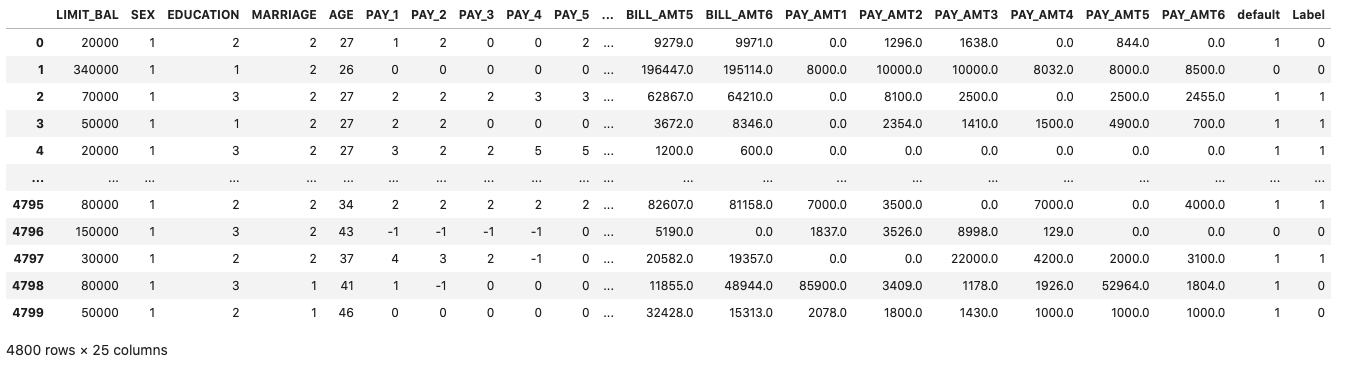
The final steps with all models is to save it for later use. Pycaret allows you to save the model in .pkl file format
# Model will be saved as .pkl and can be utilized for serving
save_model(tuned,'Tuned-Model-AutoML-Pycaret')
That’s it. All done.
One thought on “AutoML using Pycaret”
Comments are closed.

March 1, 2022 at 1:15 pm
[…] Brendan Tierney looks at the pycaret library: […]
LikeLike