
RandomForest Machine Learning – Oracle Machine Learning (OML)
Oracle Machine Learning has 30+ different machine learning algorithms built into the database. This means you can use SQL to create machine learning models and then use these models to score or label new data stored in the database or as the data is being created dynamically in the applications.
One of the most commonly used machine learning algorithms, over the past few years, is can RandomForest. This post will take a closer look at this algorithm and how you can build & use a RandomForest model.
Random Forest is known as an ensemble machine learning technique that involves the creation of hundreds of decision tree models. These hundreds of models are used to label or score new data by evaluating each of the decision trees and then determining the outcome based on the majority result from all the decision trees. Just like in the game show. The combining of a number of different ways of making a decision can result in a more accurate result or prediction.
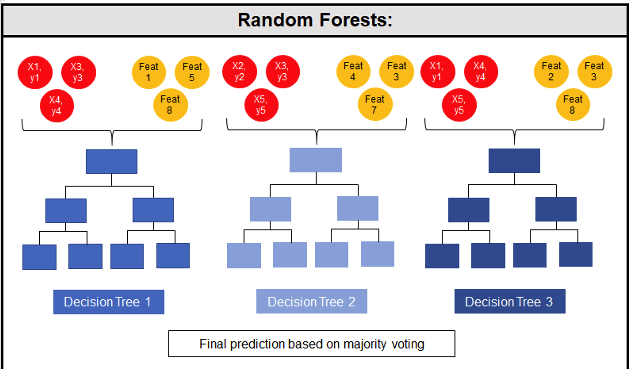
Random Forest models can be used for classification and regression types of problems, which form the majority of machine learning systems and solutions. For classification problems, this is where the target variable has either a binary value or a small number of defined values. For classification problems the Random Forest model will evaluate the predicted value for each of the decision trees in the model. The final predicted outcome will be the majority vote for all the decision trees. For regression problems the predicted value is numeric and on some range or scale. For example, we might want to predict a customer’s lifetime value (LTV), or the potential value of an insurance claim, etc. With Random Forest, each decision tree will make a prediction of this numeric value. The algorithm will then average these values for the final predicted outcome.
Under the hood, Random Forest is a collection of decision trees. Although decision trees are a popular algorithm for machine learning, they can have a tendency to over fit the model. This can lead higher than expected errors when predicting unseen data. It also gives just one possible way of representing the data and being able to derive a possible predicted outcome.
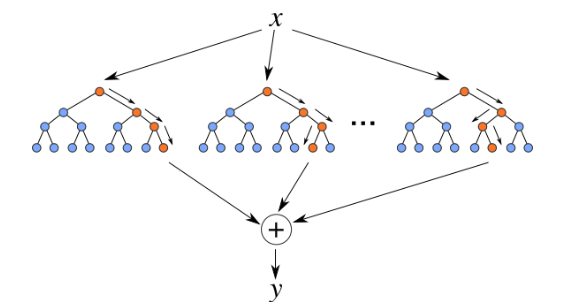 Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
The Random Forest algorithm has three main features:
- It uses a method called bagging to create different subsets of the original training data
- It will randomly section different subsets of the features/attributes and build the decision tree based on this subset
- By creating many different decision trees, based on different subsets of the training data and different subsets of the features, it will increase the probability of capturing all possible ways of modeling the data
For each decision tree produced, the algorithm will use a measure, such as the Gini Index, to select the attributes to split on at each node of the decision tree.
To create a RandomForest model using Oracle Data Mining, you will follow the same process as with any of the other algorithms, the core of these are:
- define the parameter settings
- create the model
- score/label new data
Let’s start with the first step, defining the parameters. As with all the classification algorithms the same or similar parameters are set. With RandomForest we can set an additional parameter which tells the algorithm how many decision trees to create as part of the model. By default, 20 decision trees will be created. But if you want to change this number you can use the RFOR_NUM_TREES parameter. Remember the larger the value the longer it will take to create the model. But will have better accuracy. On the other hand with a small number of trees the quicker the model build will be, but might night be as accurate. This is something you will need to explore and determine. In the following example I change the number of trees to created to ten.
CREATE TABLE BANKING_RF_SETTINGS ( SETTING_NAME VARCHAR2(50), SETTING_VALUE VARCHAR2(50) ); BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.RFOR_NUM_TREES, 10); COMMIT; END;
Other default parameters used include, for creating each decision tree, use random 50% selection of columns and 50% sample of training data.
Now for step 2, create the model.
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
The above code measures how long it takes to create the model.
I’ve run this same parameters and create models for different training data set sizes. I’ve also changed the number of decision trees to create. The following table shows the timings.
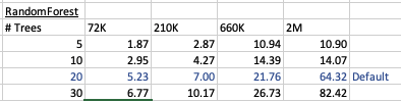
You can see it took 5.23 seconds to create a RandomForest model using the default settings for a data set of 72K records. This increase to just over one minute for a data set of 2 million records. Yo can also see the effect of reducing the number of decision trees on how long it takes the create model to run.
For step 3, on using the model on new data, this is just the same as with any of the classification models. Here is an example:
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
That’s it. That’s all there is to creating a RandomForest machine learning model using Oracle Machine Learning.
It’s quick and easy 🙂
