
PL/SQL
SelectAI – the APEX version
I’ve written a few blog posts about the new Select AI feature on the Oracle Database. In this post, I’ll explore how to use this within APEX, because you have to do things in a different way.
The previous posts on Select AI are:
- SelectAI – the beginning of a journey
- SelectAI – Doing something useful
- SelectAI – Can metadata help
- SelectAI – the APEX version
We have seen in my previous posts how the PL/SQL package called DBMS_CLOUD_AI was used to create a profile. This profile provided details of what provided to use (Cohere or OpenAI in my examples), and what metadata (schemas, tables, etc) to send to the LLM. When you look at the DBMS_CLOUD_AI PL/SQL package it only contains seven functions (at time of writing this post). Most of these functions are for managing the profile, such as creating, deleting, enabling, disabling and setting the profile attributes. But there is one other important function called GENERATE. This function can be used to send your request to the LLM.
Why is the DBMS_CLOUD_AI.GENERATE function needed? We have seen in my previous posts using Select AI using common SQL tools such as SQL Developer, SQLcl and SQL Developer extension for VSCode. When using these tools we need to enable the SQL session to use Select AI by setting the profile. When using APEX or creating your own PL/SQL functions, etc. You’ll still need to set the profile, using
EXEC DBMS_CLOUD_AI.set_profile('OPEN_AI');We can now use the DBMS_CLOUD_AI.GENERATE function to run our equivalent Select AI queries. We can use this to run most of the options for Select AI including showsql, narrate and chat. It’s important to note here that runsql is not supported. This was the default action when using Select AI. Instead, you obtain the necessary SQL using showsql, and you can then execute the returned SQL yourself in your PL/SQL code.
Here are a few examples from my previous posts:
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'what customer is the largest by sales',
profile_name => 'OPEN_AI',
action => 'showsql')
FROM dual;
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'how many customers in San Francisco are married',
profile_name => 'OPEN_AI',
action => 'narrate')
FROM dual;
SELECT DBMS_CLOUD_AI.GENERATE(prompt => 'who is the president of ireland',
profile_name => 'OPEN_AI',
action => 'chat')
FROM dual;If using Oracle 23c or higher you no longer need to include the FROM DUAL;
RandomForest Machine Learning – Oracle Machine Learning (OML)
Oracle Machine Learning has 30+ different machine learning algorithms built into the database. This means you can use SQL to create machine learning models and then use these models to score or label new data stored in the database or as the data is being created dynamically in the applications.
One of the most commonly used machine learning algorithms, over the past few years, is can RandomForest. This post will take a closer look at this algorithm and how you can build & use a RandomForest model.
Random Forest is known as an ensemble machine learning technique that involves the creation of hundreds of decision tree models. These hundreds of models are used to label or score new data by evaluating each of the decision trees and then determining the outcome based on the majority result from all the decision trees. Just like in the game show. The combining of a number of different ways of making a decision can result in a more accurate result or prediction.
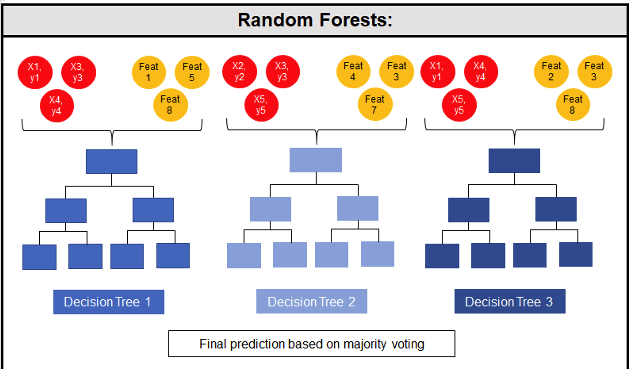
Random Forest models can be used for classification and regression types of problems, which form the majority of machine learning systems and solutions. For classification problems, this is where the target variable has either a binary value or a small number of defined values. For classification problems the Random Forest model will evaluate the predicted value for each of the decision trees in the model. The final predicted outcome will be the majority vote for all the decision trees. For regression problems the predicted value is numeric and on some range or scale. For example, we might want to predict a customer’s lifetime value (LTV), or the potential value of an insurance claim, etc. With Random Forest, each decision tree will make a prediction of this numeric value. The algorithm will then average these values for the final predicted outcome.
Under the hood, Random Forest is a collection of decision trees. Although decision trees are a popular algorithm for machine learning, they can have a tendency to over fit the model. This can lead higher than expected errors when predicting unseen data. It also gives just one possible way of representing the data and being able to derive a possible predicted outcome.
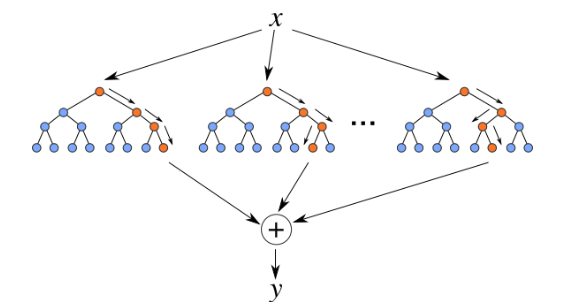 Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
The Random Forest algorithm has three main features:
- It uses a method called bagging to create different subsets of the original training data
- It will randomly section different subsets of the features/attributes and build the decision tree based on this subset
- By creating many different decision trees, based on different subsets of the training data and different subsets of the features, it will increase the probability of capturing all possible ways of modeling the data
For each decision tree produced, the algorithm will use a measure, such as the Gini Index, to select the attributes to split on at each node of the decision tree.
To create a RandomForest model using Oracle Data Mining, you will follow the same process as with any of the other algorithms, the core of these are:
- define the parameter settings
- create the model
- score/label new data
Let’s start with the first step, defining the parameters. As with all the classification algorithms the same or similar parameters are set. With RandomForest we can set an additional parameter which tells the algorithm how many decision trees to create as part of the model. By default, 20 decision trees will be created. But if you want to change this number you can use the RFOR_NUM_TREES parameter. Remember the larger the value the longer it will take to create the model. But will have better accuracy. On the other hand with a small number of trees the quicker the model build will be, but might night be as accurate. This is something you will need to explore and determine. In the following example I change the number of trees to created to ten.
CREATE TABLE BANKING_RF_SETTINGS ( SETTING_NAME VARCHAR2(50), SETTING_VALUE VARCHAR2(50) ); BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.RFOR_NUM_TREES, 10); COMMIT; END;
Other default parameters used include, for creating each decision tree, use random 50% selection of columns and 50% sample of training data.
Now for step 2, create the model.
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
The above code measures how long it takes to create the model.
I’ve run this same parameters and create models for different training data set sizes. I’ve also changed the number of decision trees to create. The following table shows the timings.
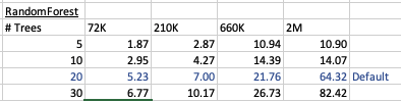
You can see it took 5.23 seconds to create a RandomForest model using the default settings for a data set of 72K records. This increase to just over one minute for a data set of 2 million records. Yo can also see the effect of reducing the number of decision trees on how long it takes the create model to run.
For step 3, on using the model on new data, this is just the same as with any of the classification models. Here is an example:
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
That’s it. That’s all there is to creating a RandomForest machine learning model using Oracle Machine Learning.
It’s quick and easy 🙂
Explicit Semantic Analysis setup using SQL and PL/SQL
In my previous blog post I introduced the new Explicit Semantic Analysis (ESA) algorithm and gave an example of how you can build an ESA model and use it. Check out this link for that blog post.
In this blog post I will show you how you can manually create an ESA model. The reason that I’m showing you this way is that the workflow (in ODMr and it’s scheduler) may not be for everyone. You may want to automate the creation or recreation of the ESA model from time to time based on certain business requirements.
In my previous blog post I showed how you can setup a training data set. This comes with ODMr 4.2 but you may need to expand this data set or to use an alternative data set that is more in keeping with your domain.
Setup the ODM Settings table
As with all ODM algorithms we need to create a settings table. This settings table allows us to store the various parameters and their values, that will be used by the algorithm.
-- Create the settings table
CREATE TABLE ESA_settings (
setting_name VARCHAR2(30),
setting_value VARCHAR2(30));
-- Populate the settings table
-- Specify ESA. By default, Naive Bayes is used for classification.
-- Specify ADP. By default, ADP is not used. Need to turn this on.
BEGIN
INSERT INTO ESA_settings (setting_name, setting_value)
VALUES (dbms_data_mining.algo_name,
dbms_data_mining.algo_explicit_semantic_analys);
INSERT INTO ESA_settings (setting_name, setting_value)
VALUES (dbms_data_mining.prep_auto,dbms_data_mining.prep_auto_on);
INSERT INTO ESA_settings (setting_name, setting_value)
VALUES (odms_sampling,odms_sampling_disable);
commit;
END;
These are the minimum number of parameter setting needed to run the ESA algorithm. The other ESA algorithm setting include:

Setup the Oracle Text Policy
You also need to setup an Oracle Text Policy and a lexer for the Stopwords.
DECLARE
v_policy_name varchar2(30);
v_lexer_name varchar2(3)
BEGIN
v_policy_name := 'ESA_TEXT_POLICY';
v_lexer_name := 'ESA_LEXER';
ctx_ddl.create_preference(v_lexer_name, 'BASIC_LEXER');
v_stoplist_name := 'CTXSYS.DEFAULT_STOPLIST'; -- default stop list
ctx_ddl.create_policy(policy_name => v_policy_name, lexer => v_lexer_name, stoplist => v_stoplist_name);
END;
Create the ESA model
Once we have the settings table created with the parameter values set for the algorithm and the Oracle Text policy created, we can now create the model.
To ensure that the Oracle Text Policy is applied to the text we want to analyse we need to create a transformation list and add the Text Policy to it.
We can then pass the text transformation list as a parameter to the CREATE_MODEL, procedure.
DECLARE
v_xlst dbms_data_mining_transform.TRANSFORM_LIST;
v_policy_name VARCHAR2(130) := 'ESA_TEXT_POLICY';
v_model_name varchar2(50) := 'ESA_MODEL_DEMO_2';
BEGIN
v_xlst := dbms_data_mining_transform.TRANSFORM_LIST();
DBMS_DATA_MINING_TRANSFORM.SET_TRANSFORM(v_xlst, '"TEXT"', NULL, '"TEXT"', '"TEXT"', 'TEXT(POLICY_NAME:'||v_policy_name||')(MAX_FEATURES:3000)(MIN_DOCUMENTS:1)(TOKEN_TYPE:NORMAL)');
DBMS_DATA_MINING.DROP_MODEL(v_model_name, TRUE);
DBMS_DATA_MINING.CREATE_MODEL(
model_name => v_model_name,
mining_function => DBMS_DATA_MINING.FEATURE_EXTRACTION,
data_table_name => 'WIKISAMPLE',
case_id_column_name => 'TITLE',
target_column_name => NULL,
settings_table_name => 'ESA_SETTINGS',
xform_list => v_xlst);
END;
NOTE: Yes we could have merged all of the above code into one PL/SQL block.
Use the ESA model
We can now use the FEATURE_COMPARE function to use the model we just created, just like I did in my previous blog post.
SELECT FEATURE_COMPARE(ESA_MODEL_DEMO_2
USING 'Oracle Database is the best available for managing your data' text
AND USING 'The SQL language is the one language that all databases have in common' text) similarity
FROM DUAL;
Go give the ESA algorithm a go and see where you could apply it within your applications.
My 2nd Book: is now available: Real World SQL and PL/SQL
It has been a busy 12 month. In addition to the day jobs, I’ve also been busy writing. (More news on this in a couple of weeks!)
Today is a major milestone as my second book is officially released and available in print and ebook formats.
The tile of the book is ‘Real Word SQL and PL/SQL: Advice from the Experts’. Check it out on Amazon.
Now that sounds like a very fancy title, but it isn’t meant to be. This book is written by 5 people (including me), who are all Oracle ACE Directors, who all have 20+ years of experience, each, of working with the Oracle Database, and we all love sharing our knowledge. My co-authors are Arup Nanda, Heli Helskyaho, Martin Widlake and Alex Nuitjen. It was a pleasure working with you.
I haven’t seen a physical copy of the book yet !!! Yes the book is released and I haven’t held it in my hands. Although I have seen pictures of it that other people have taken. There was a delay in sending out the author copies of the book, but as of this morning my books are sitting in Stansted Airport and should be making their way to Ireland today. So fingers crossed I’ll have them tomorrow. I’ll update this blog post with a picture when I have them. UPDATE: They finally arrived at 13:25 on the 22nd August.

In addition to the 5 authors we also had Chet Justice (Oraclenerd), and Oracle ACE Director, as the technical editor. We also had Tim Hall, Oracle ACE Director, wrote a foreword for us.


To give you some background to the book and why we wrote it, here is an extract from the start of the book, where I describe how the idea for this book came about and the aim of the book.
“While attempting to give you an idea into our original thinking behind the need for this book and why we wanted to write it, . the words of Rod Stewart’s song ‘Sailing’ keeps popping into my mind. These are ‘We are sailing, we are sailing, home again ‘cross the sea’. This is because the idea for this book was born on a boat. Some call it a ship. Some call it a cruise ship. Whatever you want to call it, this book was born at the OUG Norway conference in March 2015. What makes the OUG Norway conference special is that it is held on a cruise ship that goes between Oslo in Norway to Kiel in Germany and back again. This means as a speaker and conference attendee you are ‘trapped’ on the cruise ship for 2 days filled with presentations, workshops, discussions and idea sharing for the Oracle community.
It was during this conference that Heli and Brendan got talking about their books. Heli had just published her Oracle SQL Developer Data Modeler book and Brendan had published his book on Oracle Data Miner the previous year. Whilst they were discussing their experiences of writing and sharing their knowledge and how much they enjoyed this,they both recognized that there are a lot of books for the people starting out in their Oracle career and then there are lots of books on specialized topics. What was missing were books that covered the middle group. A question they kept on asking but struggled to answer was, ‘after reading the introductory books, what book would they read next before getting onto the specialized books?’ This was particularly true of SQL and PL/SQL.
They also felt that something that was missing from many books, especially introductory ones, was the “Why and How” of doing things in certain ways that comes from experience. It is all well and good knowing the syntax of commands and the options, but what takes people from understanding a language to being productive in using it is that real-world derived knowledge that comes from using it for real tasks. It would be great to share some of that experience.
Then over breakfast on the final day of the OUG Norway conference, as the cruise ship was sailing through the fjorrd and around the islands that lead back to Oslo, Heli and Brendan finally agreed that this book should happen. They then listed the type of content they thought would be in such a book and who are the recognized experts (or super heroes) for these topics. This list of experts was very easy to come up with and the writing team of Oracle ACE Directors was formed, consisting of Arup Nanda, Martin Widlake and Alex Nuijten, along with Heli Helskyaho and Brendan Tierney. The author team then got to work defining the chapters and their contents. Using their combined 120+ years of SQL and PL/SQL experience they finally came up with scope and content for the book at Oracle Open World.
…”
As you can see, this book was 17 months in the making. This consisted of 4 months of proposal writing, research and refinement, 8 months of writing, 3 months of editing and 2 months for production of book.
Yes it takes a lot of time and commitment. We all finished our last tasks and final edits on the book back in early June. Since then the book has been sent for printing, converted into an ebook, books shipped to Oracle Press warehouse, then shipped to Amazon and other book sellers. Today it is finally available officially.
(when I say officially, it seems that Amazon has shipped some pre-ordered books a week ago)
If you are at Oracle Open World (OOW) in September make sure to check out the book in the Oracle Book Store, and if you buy a copy try to track us down to get us to sign it. The best way to do this is to contact us on Twitter, leave a message at the Oracle Press stand, or you will find us hanging out at the OTN Lounge.
Checking out the Oracle Reserved Words using V$RESERVED_WORDS
When working with SQL or PL/SQL we all know there are some words we cannot use in our code or to label various parts of it. These languages have a number of reserved words that form the language.
Somethings it can be a challenge to know what is or isn’t a reserved word. Yes we can check the Oracle documentation for the SQL reserved words and the PL/SQL reserved words. There are other references and list in the Oracle documentation listing the reserved and key words.
But we also have the concept of Key Words (as opposed to reserved words). In the SQL documentation these are are not listed. In the PL/SQL documentation most are listed.
What is a Key Word in Oracle ?
Oracle SQL keywords are not reserved. BUT Oracle uses them internally in specific ways. If you use these words as names for objects and object parts, then your SQL statements may be more difficult to read and may lead to unpredictable results.
But if we didn’t have access to the documentation (or google) how can we find out what the key words are. You can use the data dictionary view called V$RESERVED_WORDS.

But this view isn’t available to version. So if you want to get your hands on it you will need the SYS user. Alternatively if you are a DBA you could share this with all your developers.
When we query this view we get 2,175 entries (for 12.1.0.2 Oracle Database).


You must be logged in to post a comment.