
Oracle Machine Learning
OML4Py – AutoML – Step-by-Step Approach
Automated Machine Learning (AutoML) is or was a bit of a hot topic over the past couple of years. With various analysis companies like Gartner and others pushing for the need for AutoML, lots and lots of vendors have been creating different types of offerings to support this.
I’ve written some blog posts about AutoML already, from describing what it is and the different types, to showing how to do a black box approach using Oracle OML4Py, and also for using Oracle Machine Learning (OML) AutoML UI. Go check out those posts. In this post I will look at the more detailed step-by-step approach to AutoML using OML4Py. The same data set and cloud account/setup will be used. This will make it easier for you to compare the steps, the results and the AutoML experience across the different OML offerings.
Check out my previous post where I give details of the data set and some data preparation. I won’t repeat those here, but will move onto performing the step-by-step AutoML using OML4Py. The following diagram, from Oracle, outlines the steps involved

A little reminder/warning before you use AutoML in OML4Py. It only works for Classification (binary and multi-class) and Regression problems. The following code example illustrates a binary class problem, but in general there is no difference between the each type of Classification and Regression, except for the evaluation metrics, which I will list below.
Step 1 – Prepare the Data Set & Setup
See my previous blog post where I prepare the data set. I’m not going to repeat those steps here to save a little bit of space.
Also have a look at what libraries to load/import.
Step 2 – Automatic Algorithm Selection
The first step to configure and complete is select the “best model” from a selection of available Algorithms. Not all of the in-database algorithms are available to use in AutoML, which is a pity as there are some algorithms that can produce really accurate model. Hopefully with time these will be added.
The function to use is called AlgorithmSelection. This consists of two parts. The first is to define the parameters and the second part is to run it. This function accepts three parameters:
- mining function : ‘classification’ or ‘regression. Classification can be for binary and multi-class.
- score metric : the evaluation metric to evaluate the model performance. The following list gives the evaluation metric for each mining function
binary classification – accuracy (default), f1, precision, recall, roc_auc, f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
multiclass classification – accuracy (default), f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
regression – r2 (default), neg_mean_squared_error, neg_mean_absolute_error, neg_mean_squared_log_error, neg_median_absolute_error
- parallel : degree of parallelism to use. Default it system determined.
The second step uses this configuration and runs the code to find the “best models”. This takes the training data set (in typical Python format), and can also have a number of additional parameters. See my previous blog post for a full list of these, but ignore adaptive sampling. To keep life simple, you only really need to use ‘k’ and ‘cv’. ‘k’ specifies the number of models to include in the return list, default is 3. ‘cv’ tells how many levels of cross validation to perform. To keep things consistent across these blog posts and make comparison easier, I’m going to set ‘cv=5’
as_bank = automl.AlgorithmSelection(mining_function='classification',
score_metric='accuracy', parallel=4)
oml_bank_ms = as_bank.select(oml_bank_X, oml_bank_y, cv=5)
To display the results and select out the best algorithm:
print("Ranked algorithms with Evaluation score:\n", oml_bank_ms)
selected_oml_bank_ms = next(iter(dict(oml_bank_ms).keys()))
print("Best algorithm =", selected_oml_bank_ms)
Ranked algorithms with Evaluation score:
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377)]
Best algorithm = glm
This last bit of code is import, where the “best” algorithm is extracted from the list. This will be used in the next step.
“It Depends” is a phrase we hear/use a lot in IT, and the same applies to using AutoML. The model returned above does not mean it is the “best model”. It Depends on the parameters used, primarily the Evaluation Metric, but also the number set for CV (cross validation). Here are some examples of changing these and their results. As you can see we get a slightly different set of results or “best model” for each. My advice is to set ‘k’ large (eg current maximum values is 8), as this will ensure all algorithms are evaluated and not just a subset of them (potential hard coded ordered list of algorithms)
oml_bank_ms5 = as_bank.select(oml_bank_X, oml_bank_y, k=5)
oml_bank_ms5
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713)]
oml_bank_ms10 = as_bank.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms10
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713), ('nn', 0.8496405750798722), ('svm_gaussian', 0.8454472843450479), ('dt', 0.8386581469648562)]
Here are some examples when the Score Metric is changed, and the impact it can have.
as_bank2 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms2 = as_bank2.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms2
[('rf', 0.6163242642976126), ('glm', 0.6160046056419113), ('glm_ridge', 0.6160046056419113), ('svm_linear', 0.5996686913307566), ('nn', 0.5896457765667574), ('svm_gaussian', 0.5829741379310345), ('dt', 0.5747368421052631), ('nb', 0.5269709543568464)]
as_bank3 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms3 = as_bank3.select(oml_bank_X, oml_bank_y, k=10, cv=2)
oml_bank_ms3
[('glm', 0.60365647055431), ('glm_ridge', 0.6034077555816686), ('rf', 0.5990036646816308), ('svm_linear', 0.588201766334537), ('svm_gaussian', 0.5845019676714007), ('nn', 0.5842357537014313), ('dt', 0.5686862482989511), ('nb', 0.4981168003466766)]
as_bank4 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms4 = as_bank4.select(oml_bank_X, oml_bank_y, k=10, cv=5)
oml_bank_ms4
[('glm', 0.583504644833276), ('glm_ridge', 0.58343736244422), ('rf', 0.5815952044164737), ('svm_linear', 0.5668069231027809), ('nn', 0.5628153929281711), ('svm_gaussian', 0.5613976370223811), ('dt', 0.5602129668741175), ('nb', 0.49153999668083814)]
The problem we now have with AutoML, it is telling us different answers for “best model”. To most that might be confusing but for the more technical data scientist they will know why. In very very simple terms, you are doing different things with the data and because of this you can get a different answer.
It is because of these different possible answers answers for the “best model”, is the reason AutoML can really only be used as a guide (a pointer towards what might be the “best model”), and cannot be relied upon to give a “best model”. AutoML is still not suitable for the general data analyst despite what some companies are saying.
Lots more could be discussed here but let’s more onto the next step.
Step 3 – Automatic Feature Selection
In the previous steps we have identified a possible “best model”. Let’s pretend the “best model” is the “best model”. The next steps is to look at how this model can be refined and improved using a subset of the features/attributes/columns. FeatureSelection looks are examining the data when combined with the model to find the optimised set of features/attributes/columns, to improve the model performance i.e. make it more accurate or have a better outcome based on the evaluation or score metric. For simplicity I’m going to use the result from the first example produced in the previous step. In a similar way to Step 2, there are two parts to setup and run the Feature Selection (Reduction). Each part is setup in a similar way to Step 2, with the parameters for FeatureSelection being the same values as those used for AlgorithmSelection. For the ‘reduce’ function, pass in the name of the “best model” or “best algorithm” from Step 2. This was extracted to a variable called ‘selected_oml_bank_ms’. Most of the other parameters the ‘reduce’ function takes are similar to the ‘select’ function. Again keeping things consistent, pass in the training data set and set the number of cross validations to 5.
fs_oml_bank = automl.FeatureSelection(mining_function = 'classification',
score_metric = 'accuracy', parallel=4)
oml_bank_fsR = fs_oml_bank.reduce(selected_oml_bank_ms, oml_bank_X, oml_bank_y, cv=5)
We can now look at the results from this listing the reduced set of features/columns and comparing the number of features/columns in the original data set to the reduced set.
#print(oml_bank_fsR)
oml_bank_fsR_l = oml_bank_X[:,oml_bank_fsR]
print("Selected columns:", oml_bank_fsR_l.columns)
print("Number of columns:")
"{} reduced to {}".format(len(oml_bank_X.columns), len(oml_bank_fsR_l.columns))
Selected columns: ['DURATION', 'PDAYS', 'EMP_VAR_RATE', 'CONS_PRICE_IDX', 'CONS_CONF_IDX', 'EURIBOR3M', 'NR_EMPLOYED']
Number of columns:
'20 reduced to 7'
In this example the data set gets reduced from having 20 features/columns in the original data set, down to having 7 features/columns.
Step 4 – Automatic Model Tuning
Up to now, we have identified the “best model” / “best algorithm” and the optimised reduced set of features to use. The final step is to take the details generated from the previous steps and use this to generate a Tuned Model. In a similar way to the previous steps, this involve two parts. The first sets up some parameters and the second runs the Model Tuning function called ‘tune’. Make sure to include the data frame containing the reduced set of features/attributes.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4) oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5) print(oml_bank_mt)
The output is very long and contains the name of the Algorithm, the hyperparameters used for the final model, the features used, and (at the end) lists the various combinations of hyperparameters used and the evaluation metric score for each combination. Partial output shown below.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4)
oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5)
print(oml_bank_mt)
{'best_model':
Algorithm Name: Generalized Linear Model
Mining Function: CLASSIFICATION
Target: TARGET_Y
Settings:
setting name setting value
0 ALGO_NAME ALGO_GENERALIZED_LINEAR_MODEL
1 CLAS_WEIGHTS_BALANCED OFF
...
...
, 'all_evals': [(0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 31, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.4211156437080018, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'})]}
The list of parameter settings and the evaluation score is an ordered list in decending order, starting with the best model.
We can extract the different parts of this dictionary object by using the following:
#display the main model details print(oml_bank_mt['best_model'])
Now extract the evaluation metric score and the parameter settings used for the best model, (position 0 of the dictionary)
score, params = oml_bank_mt['all_evals'][0]
And that’s it, job done with using OML4Py AutoML to generate an optimised model.
The example above is for a Classification problem. If you had a Regression problem all you need to do is replace ‘classification’ with ‘regression’, and change the score_metric parameter to ‘r2’, or one of the other Regression metric values (see above for list of these.
Adding Text Processing to Classification Machine Learning in Oracle Machine Learning
One of the typical machine learning functions is Classification. This is in widespread use across most domains and geographic regions. I’ve written several blog posts on this topic over many years (and going back many, many year) on how to do this using Oracle Machine Learning (OML) (formally known as Oracle Advanced Analytic and in the Oracle Data Miner tool in SQL Developer). Just do a quick search of my blog to find some of these posts.
When it comes to Classification problems, typically the data set will be contain your typical categorical and numerical variables/features. The Automatic Data Preparation (ADP) feature of OML where it automatically pre-processes and transforms these variable for input to the machine learning algorithm. This greatly reduces the boring work of the data scientist and increases their productivity.
But sometimes data sets come with text descriptions. These will contain production descriptions, free format text, and other descriptive data, for example product reviews. But how can this information be included as part of the input data set to the machine learning algorithms. Oracle allows this kind of input data, and a letting bit of setup is needed to tell Oracle how to process the data set. This uses the in-database feature of Oracle Text.
The following example walks through an example of the steps needed to pre-process and include the text processing as part of the machine learning algorithm.
The data set: The data used to illustrate this and to show the steps needed, is a data set from Kaggle webiste. This data set contains 130K Wine Reviews. This data set contain descriptive information of the wine with attributes about each wine including country, region, number of points, price, etc as well as a text description contain a review of the wine.
The following are 2 files containing the DDL (to create the table) and then Import the data set (using sql script with insert statements). These can be run in your schema (in order listed below).
I’ll leave the Data Exploration to you to do and to discover some early insights.
The ML Question
I want to be able to predict if a wine is a good quality wine, based on the prices and different characteristics of the wine?
Data Preparation
To be able to answer this question the first thing needed is to define a target variable to identify good and bad wines. To do this create a new attribute/feature called POINTS_BIN and populate it based on the number of points a wine has. If it has >90 points it is a good wine, if <90 points it is a bad wine.
ALTER TABLE WineReviews130K_bin ADD POINTS_BIN VARCHAR2(15);
UPDATE WineReviews130K_bin
SET POINTS_BIN = 'GT_90_Points'
WHERE winereviews130k_bin.POINTS >= 90;
UPDATE WineReviews130K_bin
SET POINTS_BIN = 'LT_90_Points'
WHERE winereviews130k_bin.POINTS < 90;
alter table WineReviews130K_bin DROP COLUMN POINTS;
The DESCRIPTION column data type needs to be changed to CLOB. This is to allow the Text Mining feature to work correctly.
-- add a new column of data type CLOB
ALTER TABLE WineReviews130K_bin ADD (DESCRIPTION_NEW CLOB);
-- update new column with data from the DESCRIPTION attribute
UPDATE WineReviews130K_bin SET DESCRIPTION_NEW = DESCRIPTION;
-- drop the DESCRIPTION attribute from table
ALTER TABLE WineReviews130K_bin DROP COLUMN DESCRIPTION;
-- rename the new attribute to replace DESCRIPTION
ALTER TABLE WineReviews130K_bin RENAME COLUMN DESCRIPTION_NEW TO DESCRIPTION;
Text Mining Configuration
There are a number of things we need to define for the Text Mining to work, these include a Lexer, Stop Word list and preferences.
First define the Lexer to use. In this case we will use a basic one and basic settings
BEGIN ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); ctx_ddl.set_attribute ( 'mylex', 'index_themes', 'NO'); ctx_ddl.set_attribute ( 'mylex', 'index_text', 'YES'); END;
Next we can define a Stop Word List. Oracle Text comes with a predefined set of Stop Word lists for most of the common languages. You can add to one of those list or create your own. Depending on the domain you are working in it might be easier to create your own and it is very straight forward to do. For example:
DECLARE v_stoplist_name varchar2(100); BEGIN v_stoplist_name := 'mystop'; ctx_ddl.create_stoplist(v_stoplist_name, 'BASIC_STOPLIST'); ctx_ddl.add_stopword(v_stoplist_name, 'nonetheless'); ctx_ddl.add_stopword(v_stoplist_name, 'Mr'); ctx_ddl.add_stopword(v_stoplist_name, 'Mrs'); ctx_ddl.add_stopword(v_stoplist_name, 'Ms'); ctx_ddl.add_stopword(v_stoplist_name, 'a'); ctx_ddl.add_stopword(v_stoplist_name, 'all'); ctx_ddl.add_stopword(v_stoplist_name, 'almost'); ctx_ddl.add_stopword(v_stoplist_name, 'also'); ctx_ddl.add_stopword(v_stoplist_name, 'although'); ctx_ddl.add_stopword(v_stoplist_name, 'an'); ctx_ddl.add_stopword(v_stoplist_name, 'and'); ctx_ddl.add_stopword(v_stoplist_name, 'any'); ctx_ddl.add_stopword(v_stoplist_name, 'are'); ctx_ddl.add_stopword(v_stoplist_name, 'as'); ctx_ddl.add_stopword(v_stoplist_name, 'at'); ctx_ddl.add_stopword(v_stoplist_name, 'be'); ctx_ddl.add_stopword(v_stoplist_name, 'because'); ctx_ddl.add_stopword(v_stoplist_name, 'been'); ctx_ddl.add_stopword(v_stoplist_name, 'both'); ctx_ddl.add_stopword(v_stoplist_name, 'but'); ctx_ddl.add_stopword(v_stoplist_name, 'by'); ctx_ddl.add_stopword(v_stoplist_name, 'can'); ctx_ddl.add_stopword(v_stoplist_name, 'could'); ctx_ddl.add_stopword(v_stoplist_name, 'd'); ctx_ddl.add_stopword(v_stoplist_name, 'did'); ctx_ddl.add_stopword(v_stoplist_name, 'do'); ctx_ddl.add_stopword(v_stoplist_name, 'does'); ctx_ddl.add_stopword(v_stoplist_name, 'either'); ctx_ddl.add_stopword(v_stoplist_name, 'for'); ctx_ddl.add_stopword(v_stoplist_name, 'from'); ctx_ddl.add_stopword(v_stoplist_name, 'had'); ctx_ddl.add_stopword(v_stoplist_name, 'has'); ctx_ddl.add_stopword(v_stoplist_name, 'have'); ctx_ddl.add_stopword(v_stoplist_name, 'having'); ctx_ddl.add_stopword(v_stoplist_name, 'he'); ctx_ddl.add_stopword(v_stoplist_name, 'her'); ctx_ddl.add_stopword(v_stoplist_name, 'here'); ctx_ddl.add_stopword(v_stoplist_name, 'hers'); ctx_ddl.add_stopword(v_stoplist_name, 'him'); ctx_ddl.add_stopword(v_stoplist_name, 'his'); ctx_ddl.add_stopword(v_stoplist_name, 'how'); ctx_ddl.add_stopword(v_stoplist_name, 'however'); ctx_ddl.add_stopword(v_stoplist_name, 'i'); ctx_ddl.add_stopword(v_stoplist_name, 'if'); ctx_ddl.add_stopword(v_stoplist_name, 'in'); ctx_ddl.add_stopword(v_stoplist_name, 'into'); ctx_ddl.add_stopword(v_stoplist_name, 'is'); ctx_ddl.add_stopword(v_stoplist_name, 'it'); ctx_ddl.add_stopword(v_stoplist_name, 'its'); ctx_ddl.add_stopword(v_stoplist_name, 'just'); ctx_ddl.add_stopword(v_stoplist_name, 'll'); ctx_ddl.add_stopword(v_stoplist_name, 'me'); ctx_ddl.add_stopword(v_stoplist_name, 'might'); ctx_ddl.add_stopword(v_stoplist_name, 'my'); ctx_ddl.add_stopword(v_stoplist_name, 'no'); ctx_ddl.add_stopword(v_stoplist_name, 'non'); ctx_ddl.add_stopword(v_stoplist_name, 'nor'); ctx_ddl.add_stopword(v_stoplist_name, 'not'); ctx_ddl.add_stopword(v_stoplist_name, 'of'); ctx_ddl.add_stopword(v_stoplist_name, 'on'); ctx_ddl.add_stopword(v_stoplist_name, 'one'); ctx_ddl.add_stopword(v_stoplist_name, 'only'); ctx_ddl.add_stopword(v_stoplist_name, 'onto'); ctx_ddl.add_stopword(v_stoplist_name, 'or'); ctx_ddl.add_stopword(v_stoplist_name, 'our'); ctx_ddl.add_stopword(v_stoplist_name, 'ours'); ctx_ddl.add_stopword(v_stoplist_name, 's'); ctx_ddl.add_stopword(v_stoplist_name, 'shall'); ctx_ddl.add_stopword(v_stoplist_name, 'she'); ctx_ddl.add_stopword(v_stoplist_name, 'should'); ctx_ddl.add_stopword(v_stoplist_name, 'since'); ctx_ddl.add_stopword(v_stoplist_name, 'so'); ctx_ddl.add_stopword(v_stoplist_name, 'some'); ctx_ddl.add_stopword(v_stoplist_name, 'still'); ctx_ddl.add_stopword(v_stoplist_name, 'such'); ctx_ddl.add_stopword(v_stoplist_name, 't'); ctx_ddl.add_stopword(v_stoplist_name, 'than'); ctx_ddl.add_stopword(v_stoplist_name, 'that'); ctx_ddl.add_stopword(v_stoplist_name, 'the'); ctx_ddl.add_stopword(v_stoplist_name, 'their'); ctx_ddl.add_stopword(v_stoplist_name, 'them'); ctx_ddl.add_stopword(v_stoplist_name, 'then'); ctx_ddl.add_stopword(v_stoplist_name, 'there'); ctx_ddl.add_stopword(v_stoplist_name, 'therefore'); ctx_ddl.add_stopword(v_stoplist_name, 'these'); ctx_ddl.add_stopword(v_stoplist_name, 'they'); ctx_ddl.add_stopword(v_stoplist_name, 'this'); ctx_ddl.add_stopword(v_stoplist_name, 'those'); ctx_ddl.add_stopword(v_stoplist_name, 'though'); ctx_ddl.add_stopword(v_stoplist_name, 'through'); ctx_ddl.add_stopword(v_stoplist_name, 'thus'); ctx_ddl.add_stopword(v_stoplist_name, 'to'); ctx_ddl.add_stopword(v_stoplist_name, 'too'); ctx_ddl.add_stopword(v_stoplist_name, 'until'); ctx_ddl.add_stopword(v_stoplist_name, 've'); ctx_ddl.add_stopword(v_stoplist_name, 'very'); ctx_ddl.add_stopword(v_stoplist_name, 'was'); ctx_ddl.add_stopword(v_stoplist_name, 'we'); ctx_ddl.add_stopword(v_stoplist_name, 'were'); ctx_ddl.add_stopword(v_stoplist_name, 'what'); ctx_ddl.add_stopword(v_stoplist_name, 'when'); ctx_ddl.add_stopword(v_stoplist_name, 'where'); ctx_ddl.add_stopword(v_stoplist_name, 'whether'); ctx_ddl.add_stopword(v_stoplist_name, 'which'); ctx_ddl.add_stopword(v_stoplist_name, 'while'); ctx_ddl.add_stopword(v_stoplist_name, 'who'); ctx_ddl.add_stopword(v_stoplist_name, 'whose'); ctx_ddl.add_stopword(v_stoplist_name, 'why'); ctx_ddl.add_stopword(v_stoplist_name, 'will'); ctx_ddl.add_stopword(v_stoplist_name, 'with'); ctx_ddl.add_stopword(v_stoplist_name, 'would'); ctx_ddl.add_stopword(v_stoplist_name, 'yet'); ctx_ddl.add_stopword(v_stoplist_name, 'you'); ctx_ddl.add_stopword(v_stoplist_name, 'your'); ctx_ddl.add_stopword(v_stoplist_name, 'yours'); ctx_ddl.add_stopword(v_stoplist_name, 'drink'); ctx_ddl.add_stopword(v_stoplist_name, 'flavors'); ctx_ddl.add_stopword(v_stoplist_name, '2020'); ctx_ddl.add_stopword(v_stoplist_name, 'now'); END;
Next define the preferences for processing the Text, for example what Stop Word list to use, if Fuzzy match is to be used and what language to use for this, number of tokens/words to process and if stemming is to be used.
BEGIN ctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('mywordlist','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('mywordlist','FUZZY_SCORE','1'); ctx_ddl.set_attribute('mywordlist','FUZZY_NUMRESULTS','5000'); ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX','TRUE'); ctx_ddl.set_attribute('mywordlist','STEMMER','ENGLISH'); END;
And the final step is to piece it all together by defining a new Text policy
BEGIN ctx_ddl.create_policy('my_policy', NULL, NULL, 'mylex', 'mystop', 'mywordlist'); END;
Define Settings for OML Model
We will create two models. An Attribute Importance model and a Classification model. The following defines the model parameters for each of these.
CREATE TABLE att_import_model_settings (setting_name varchar2(30), setting_value varchar2(30)); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ALGO_NAME'', ''ALGO_AI_MDL''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''PREP_AUTO'', ''ON''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_POLICY_NAME'', ''my_policy''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_MAX_FEATURES'', ''3000'')';
CREATE TABLE wine_model_settings (setting_name varchar2(30), setting_value varchar2(30)); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ALGO_NAME'', ''ALGO_RANDOM_FOREST''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''PREP_AUTO'', ''ON''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_POLICY_NAME'', ''my_policy''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_MAX_FEATURES'', ''3000'')';
Create the Training and Test data sets.
CREATE TABLE wine_train_data AS SELECT id, country, description, designation, points_bin, price, province, region_1, region_2, taster_name, variety, title FROM winereviews130k_bin SAMPLE (60) SEED (1);
CREATE TABLE wine_test_data AS SELECT id, country, description, designation, points_bin, price, province, region_1, region_2, taster_name, variety, title FROM winereviews130k_bin WHERE id NOT IN (SELECT id FROM wine_train_data);
All the set up is done, we can move onto the creating the machine learning models.
Create the OML Model (Attribute Importance & Classification)
We are going to create two models. The first is an Attribute Important model. This will look at the data set and will determine what attributes contribute most towards determining the target variable. As we are incorporting Texting Mining we will see what words/tokens from the DESCRIPTION attribute also contribute towards the target variable.
BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'GOOD_WINE_AI', mining_function => DBMS_DATA_MINING.ATTRIBUTE_IMPORTANCE, data_table_name => 'winereviews130k_bin', case_id_column_name => 'ID', target_column_name => 'POINTS_BIN', settings_table_name => 'att_import_mode_settings'); END;
We can query the system views for Oracle ML to find out what are the important variables.
SELECT * FROM dm$vagood_wine_ai ORDER BY attribute_rank;
Here is the listing of the top 15 most important attributes. We can see from the first 15 rows and looking under column ATTRIBUTE_SUBNAME, the words from the DESCRIPTION attribute that seem to be important and contribute towards determining the value in the target attribute.

At this point you might determine, based on domain knowledge, some of these words should be excluded as they are generic for the domain. In this case, go back to the Stop Word List and recreate it with any additional words. This can be repeated until you are happy with the list. In this example, WINE could be excluded by including it in the Stop Word List.
Run the following to create the Classification model. It is very similar to what we ran above with minor changes to the name of the model, the data mining function and the name of the settings table.
BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'GOOD_WINE_MODEL', mining_function => DBMS_DATA_MINING.CLASSIFICATION, data_table_name => 'winereviews130k_bin', case_id_column_name => 'ID', target_column_name => 'POINTS_BIN', settings_table_name => 'wine_model_settings'); END;
Apply OML Model
The model can be applied in similar ways to any other ML model created using OML. For example the following displays the wine details along with the predicted points bin values (good or bad) and the probability score (<=1) of the prediction.
SELECT id, price, country, designation, province, variety, points_bin, PREDICTION(good_wine_mode USING *) pred_points_bin, PREDICTION_PROBABILITY(good_wine_mode USING *) prob_points_bin FROM wine_test_data;
Principal Component Analysis (PCA) in Oracle
Principal Component Analysis (PCA), is a statistical process used for feature or dimensionality reduction in data science and machine learning projects. It summarizes the features of a large data set into a smaller set of features by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data’s variation as possible. There are lots of resources that goes into the mathematics behind this approach. I’m not going to go into that detail here and a quick internet search will get you what you need.
PCA can be used to discover important features from large data sets (large as in having a large number of features), while preserving as much information as possible.
Oracle has implemented PCA using Sigular Value Decomposition (SVD) on the covariance and correlations between variables, for feature extraction/reduction. PCA is closely related to SVD. PCA computes a set of orthonormal bases (principal components) that are ranked by their corresponding explained variance. The main difference between SVD and PCA is that the PCA projection is not scaled by the singular values. The extracted features are transformed features consisting of linear combinations of the original features.
When machine learning is performed on this reduced set of transformed features, it can completed with less resources and time, while still maintaining accuracy.
Algorithm Name in Oracle using
Mining Model Function = FEATURE_EXTRACTION
Algorithm = ALGO_SINGULAR_VALUE_DECOMP
(Hyper)-Parameters for algorithms
- SVDS_U_MATRIX_OUTPUT : SVDS_U_MATRIX_ENABLE or SVDS_U_MATRIX_DISABLE
- SVDS_SCORING_MODE : SVDS_SCORING_SVD or SVDS_SCORING_PCA
- SVDS_SOLVER : possible values include SVDS_SOLVER_TSSVD, SVDS_SOLVER_TSEIGEN, SVDS_SOLVER_SSVD, SVDS_SOLVER_STEIGEN
- SVDS_TOLERANCE : range of 0…1
- SVDS_RANDOM_SEED : range of 0…4294967296 (!)
- SVDS_OVER_SAMPLING : range of 1…5000
- SVDS_POWER_ITERATIONS : Default value 2, with possible range of 0…20
Let’s work through an example using the MINING_DATA_BUILD_V data set that comes with Oracle Data Miner.
First step is to define the parameter settings for the algorithm. No data preparation is needed as the algorithm takes care of this. This means you can disable the Automatic Data Preparation (ADP).
-- create the parameter table CREATE TABLE svd_settings ( setting_name VARCHAR2(30), setting_value VARCHAR2(4000)); -- define the settings for SVD algorithm BEGIN INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_singular_value_decomp); -- turn OFF ADP INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_off); -- set PCA scoring mode INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.svds_scoring_mode, dbms_data_mining.svds_scoring_pca); INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_shift_2dnum, dbms_data_mining.prep_shift_mean); INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_scale_2dnum, dbms_data_mining.prep_scale_stddev); END; /
You are now ready to create the model.
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'SVD_MODEL',
mining_function => dbms_data_mining.feature_extraction,
data_table_name => 'mining_data_build_v',
case_id_column_name => 'CUST_ID',
settings_table_name => 'svd_settings');
END;
When created you can use the mining model data dictionary views to explore the model and to explore the specifics of the model and the various MxN matrix created using the model specific views. These include:
- DM$VESVD_Model : Singular Value Decomposition S Matrix
- DM$VGSVD_Model : Global Name-Value Pairs
- DM$VNSVD_Model : Normalization and Missing Value Handling
- DM$VSSVD_Model : Computed Settings
- DM$VUSVD_Model : Singular Value Decomposition U Matrix
- DM$VVSVD_Model : Singular Value Decomposition V Matrix
- DM$VWSVD_Model : Model Build Alerts
Where the S, V and U matrix contain:
- U matrix : consists of a set of ‘left’ orthonormal bases
- S matrix : is a diagonal matrix
- V matrix : consists of set of ‘right’ orthonormal bases
These can be explored using the following
-- S matrix select feature_id, VALUE, variance, pct_cum_variance from DM$VESVD_MODEL; -- V matrix select feature_id, attribute_name, value from DM$VVSVD_MODEL order by feature_id, attribute_name; -- U matrix select feature_id, attribute_name, value from DM$VVSVD_MODEL order by feature_id, attribute_name;
To determine the projections to be used for visualizations we can use the FEATURE_VALUES function.
select FEATURE_VALUE(svd_sh_sample, 1 USING *) proj1,
FEATURE_VALUE(svd_sh_sample, 2 USING *) proj2
from mining_data_build_v
where cust_id <= 101510
order by 1, 2;
Other algorithms available in Oracle for feature extraction and reduction include:
- Non-Negative Matrix Factorization (NMF)
- Explicit Semantic Analysis (ESA)
- Minimum Description Length (MDL) – this is really feature selection rather than feature extraction
Adam Solver for Neural Networks (OML) in Oracle 21c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
The ability to create and use Neural Networks on business data has been available in Oracle Database since Oracle 18c (18c and 19c are just slightly extended versions of Oracle 12c). With each minor database release we get some small improvements and minor features added. I’ve written other blog posts about other 21c new machine learning features (see here, here and here).
With Oracle 21c they have added a new neural network solver. This is called Adam Solver and the original research was conducted by Diederik Kingma from OpenAI and Jimmy Ba from the University of Toronto and they presented they work at ICLR 2015. The name Adam is derived from ‘adaptive moment estimation‘. This algorithm, research and paper has gathered some attention in the research community over the past few years. Most of this has been focused on the benefits of using it.

But care is needed. As with most machine learning (and deep learning) algorithms, they work up to a point. They may be good on certain problems and input data sets, and then for others they may not be as good or as efficient at producing an optimal outcome. Although using this solver may be beneficial to your problem, using the concept of ‘No Free Lunch’, you will need to prove the solver is beneficial for your problem.
With Oracle Machine Learning there are two Optimization Solver available for the Neural Network algorithm. The default solver is call L-BFGS (Limited memory Broyden-Fletch-Goldfarb-Shanno). This is one of the most popular solvers in use in most algorithms. The is a limited version of BFGS, using less memory (hence the L in the name) This solver finds the descent direction and line search is used to find the appropriate step size. The solver searches for the optimal solution of the loss function to find the extreme value (maximum or minimum) of the loss (cost) function
The Adam Solver uses an extension to stochastic gradient descent. It uses the squared gradients to scale the learning rate and it takes advantage of momentum by using moving average of the gradient instead of gradient. This allows the solver to work quickly by seeing less data and can work well with larger data sets.
With Oracle Data Mining the Adam Solver has the following parameters.
- ADAM_ALPHA : Learning rate for solver. Default value is 0.001.
- ADAM_BATCH_ROWS : Number of rows per batch. Default value is 10,000
- ADAM_BETA1 : Exponential decay rate for 1st moment estimates. Default value is 0.9.
- ADAM_BETA2 : Exponential decay rate for the 2nd moment estimates. Default value is 0.99.
- ADAM_GRADIENT_TOLERANCE : Gradient infinity norm tolerance. Default value is 1E-9.
The parameters ADAM_ALPHA and ADAM_BATCH_ROWS can have an effect on the timing for the neural network algorithm to produce the model. Some exploration is needed to determine the optimal values for this parameters based on the size of the data set. For example having a larger value for ADAM_ALPHA results in a faster initial learning before the rates is updated. Small values than the default slows learning down during training.
To tell Oracle Machine Learning to use the Adam Solver the DMSSET_NN_SOLVER parameter needs to be set. The default setting for a neural network is DMSSET_NN_SOLVER_LGFGS. But to use the Adam solver set it to DMSSET_NN_SOLVER_ADAM.
The following is an example of setting the parameters for the Adam solver and creating a neural network.
BEGIN DELETE FROM BANKING_NNET_SETTINGS; INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_neural_network); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.nnet_nodes_per_layer, '20,10,6'); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.nnet_iterations, 10); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.NNET_SOLVER, 'NNET_SOLVER_ADAM'); END; The addition of the last parameter overrides the default solver for building a neural network model.
To build the model we can use the following.
DECLARE
v_start_time TIMESTAMP;
BEGIN
begin DBMS_DATA_MINING.DROP_MODEL('BANKING_NNET_72K_1'); exception when others then null; end;
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name. => 'BANKING_NNET_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_NNET_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
For me on my Oracle 20c Preview Database, this takes 1.8 seconds to run and create the neural network model ob a data set of 72,000 records.
Using the default solver, the model is created in 5.2 seconds. With using a small data set of 72,000 records, we can see the impact of using an Adam Solver for creating a neural network model.
These timings and the timings shown below (in seconds) are based on the Oracle 20c Preview Database, using a minimum VM sizing and specification available.
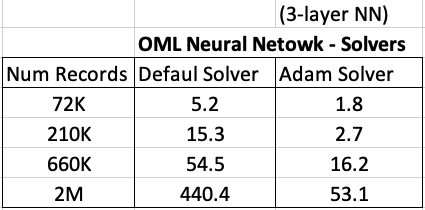
Creating OML Models in Parallel
In a previous post I showed how to use the partition option in Oracle Data Mining to create many sub-models. This gives one overall driving model with each sub-model created on a different subset or partition of the training data set.
That blog post also showed the timing for creating the models and how this compares to creating one overall model for your data set, while achieving greater accuracy with model predictions.
This is all good. But can it scale more. What if I have significantly more data! How does this scale and how?
My previous blog post showed how the you can quickly partition the data into different subsets and some care is needed on choosing the attributes carefully for the partition key.
What if I want to run these different sub-models on the different data partitions in parallel on different slaves.
This is simple to do and can be achieved by adding one additional parameter to the Model Settings table. This parameter is called ODMS_PARTITION_BUILD_TYPE. This parameter has three possible values:
ODMS_PARTITION_BUILD_INTRA — Each partition is built in parallel using all slaves.
ODMS_PARTITION_BUILD_INTER — Each partition is built entirely in a single slave, but multiple partitions may be built at the same time since multiple slaves are active.
ODMS_PARTITION_BUILD_HYBRID — It is a combination of the other two types and is recommended for most situations to adapt to dynamic environments.
The default mode is ODMS_PARTITION_BUILD_HYBRID.
Although by default the model will try to run in parallel, I’ve found this is not necessarily the case. In my previous post I showed the timing to create a model on 72K records using different models. These timings are
One over all Model = 5.23 seconds
Partitioned Model (4 partitions/models) = 8.3 seconds
Partitioned Model (48 partitions/models) = 37 seconds
Now let’s change/set the ODMS_PARTITION_BUILD_TYPE parameter. The following code is the complete code to set the parameters and build upon those shown in the previous blog post.
BEGIN
DELETE FROM BANKING_RF_SETTINGS;
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL, JOB’);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.odms_partition_build_type, 'ODMS_PARTITION_BUILD_INTER');
COMMIT;
END;
The code to create the Model using CREATE_MODEL does not change.
So, how long this this take to run? In my DBaaS preview 20c database (basic setup) it too 6.6 seconds.
Remember that was for an input data set consisting of 72K records and the partition key creates 48 partitions and in-turn creates 48 different machine learning models.
This 6.6 seconds compares to 37 seconds when this parameter was not set or using the default.
No that is fast and available to everyone to use 🙂
Partitioned Models – Oracle Machine Learning (OML)
Building machine learning models can be a relatively trivial task. But getting to that point and understanding what to do next can be challenging. Yes the task of creating a model is simple and usually takes a few line of code. This is what is shown in most examples. But when you try to apply to real world problems we are faced with other challenges. Some of which include volume of data is larger, building efficient ML pipelines is challenging, time to create models gets longer, applying models to new data in real-time takes longer (not possible in real-time), etc. Yes these are typically challenges and most of these can be easily overcome.
When building ML solutions for real-world problem you will be faced with building (and deploying) many 10s or 100s of ML models. Why are so many models needed? Almost every example we see for ML takes the entire data set and build a model on that data. When you think about it, not everyone in the data set can be considered in the same grouping (similar characteristics). If we were to build a model on the data set and apply it to new data, we will get a generic prediction. A prediction comparing the new data item (new customer, purchase, etc) with everyone else in the data population. Maybe this is why so many ML project fail as they are building generic solution that performs badly when run on new (and evolving) data.
To overcome this we start to look at the different groups of data in the data set. Can the data set be divided into a number of different parts based on some characteristics. If we could do this and build a separate model on each group (or cluster), then we would have ML models that would be more accurate with their predictions. This is where we will end up creating 10s or 100s of models. As you can imagine the work involved in doing this with be LOTs. Then think about all the coding needed to manage all of this. What about the complexity of all the code needed for making the predictions on new data.
Yes all of this gets complex very, very quickly!
Ideally we want a separate model for each group
But how can you do that efficiently? is it possible?
When working with Oracle Machine Learning, you can use a feature called partitioned models. Partitioned Models are designed to handle this type of problem. They are designed to:
- make the building of models simple
- scales as the data and number of partitions increase
- includes all the steps part of the ML pipeline (all the data prep, transformations, etc)
- make predicting new data using the ML model simple
- make the deployment of the ML model easy
- make the MLOps process simple
- make the use of ML model easy to use by all developers no matter the programming language
- make the ML model build and ML model scoring quick and with better, more accurate predictions.

Let us work through an example. In this example lets start by creating a Random Forest ML model using the entire data set. The following code shows setting up the Parameters settings table. The second code segment creates the Random Forest ML model. The training data set being used in this example contains 72,000 records.
BEGIN
DELETE FROM BANKING_RF_SETTINGS;
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on);
COMMIT;
END;
/
-- Create the ML model
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
/
This is the basic setup and the following table illustrates how long the CREATE_MODEL function takes to run for different sizes of training datasets and with different number of trees per model. The default number of trees is 20.
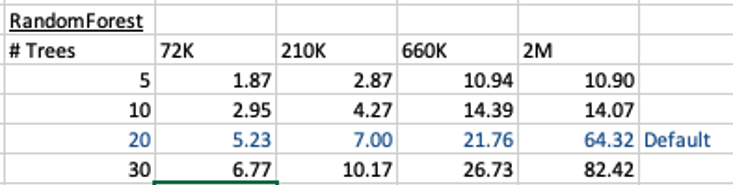
To run this model against new data we could use something like the following SQL query.
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
This is simple and straight forward to use.
For the 72,000 records it takes just approx 5.23 seconds to create the model, which includes creating 20 Decision Trees. As mentioned earlier, this will be a generic model covering the entire data set.
To create a partitioned model, we can add new parameter which lists the attributes to use to partition the data set. For example, if the partition attribute is MARITAL, we see it has four different values. This means when this attribute is used as the partition attribute, Oracle Machine Learning will create four separate sub Random Forest models all until the one umbrella model. This means the above SQL query to run the model, does not change and the correct sub model will be selected to run on the data based on the value of MARITAL attribute.
To create this partitioned model you need to add the following to the settings table.
BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL’); COMMIT; END; /
The code to create the model remains the same!
The code to call and use the model remains the same!
This keeps everything very simple and very easy to use.
When I ran the CREATE_MODEL code for the partitioned model, it took approx 8.3 seconds to run. Yes it took slightly longer than the previous example, but this time it is creating four models instead of one. This is still very quick!
What if I wanted to add more attributes to the partition key? Yes you can do that. The more attributes you add, the more sub-models will be be created.
For example, if I was to add JOB attribute to the partition key list. I will now get 48 sub-models (with 20 Decision Trees each) being created. The JOB attribute has 12 distinct values, multiplied by the 4 values for MARITAL, gives us 48 models.
INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL,JOB');
How long does this take the CREATE_MODEL code to run? approx 37 seconds!
Again that is quick!
Again remember the code to create the model and to run the model to predict on new data does not change. This means our applications using this ML model does not change. This shows us we can very easily increase the predictive accuracy of our models with only adding one additional model, and by improving this accuracy by adding more attributes to the partition key.
But you do need to be careful with what attributes to include in the partition key. If the attributes have a very high number of distinct values, will result in 100s, or 1000s of sub models being created.
An important benefit of using partitioned models is when a new distinct value occurs in one of the partition key attributes. You code to create the parameters and models does not change. OML will automatically will pick this up and do all the work under the hood.
RandomForest Machine Learning – Oracle Machine Learning (OML)
Oracle Machine Learning has 30+ different machine learning algorithms built into the database. This means you can use SQL to create machine learning models and then use these models to score or label new data stored in the database or as the data is being created dynamically in the applications.
One of the most commonly used machine learning algorithms, over the past few years, is can RandomForest. This post will take a closer look at this algorithm and how you can build & use a RandomForest model.
Random Forest is known as an ensemble machine learning technique that involves the creation of hundreds of decision tree models. These hundreds of models are used to label or score new data by evaluating each of the decision trees and then determining the outcome based on the majority result from all the decision trees. Just like in the game show. The combining of a number of different ways of making a decision can result in a more accurate result or prediction.
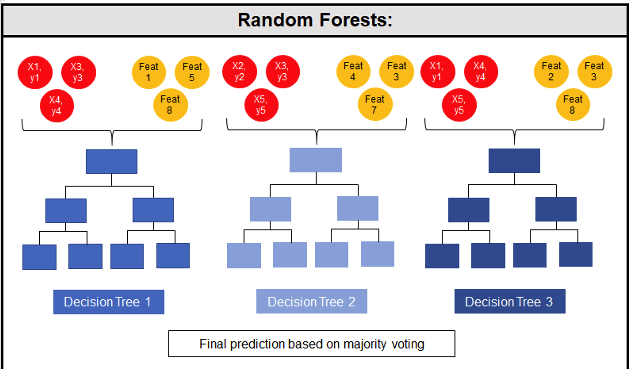
Random Forest models can be used for classification and regression types of problems, which form the majority of machine learning systems and solutions. For classification problems, this is where the target variable has either a binary value or a small number of defined values. For classification problems the Random Forest model will evaluate the predicted value for each of the decision trees in the model. The final predicted outcome will be the majority vote for all the decision trees. For regression problems the predicted value is numeric and on some range or scale. For example, we might want to predict a customer’s lifetime value (LTV), or the potential value of an insurance claim, etc. With Random Forest, each decision tree will make a prediction of this numeric value. The algorithm will then average these values for the final predicted outcome.
Under the hood, Random Forest is a collection of decision trees. Although decision trees are a popular algorithm for machine learning, they can have a tendency to over fit the model. This can lead higher than expected errors when predicting unseen data. It also gives just one possible way of representing the data and being able to derive a possible predicted outcome.
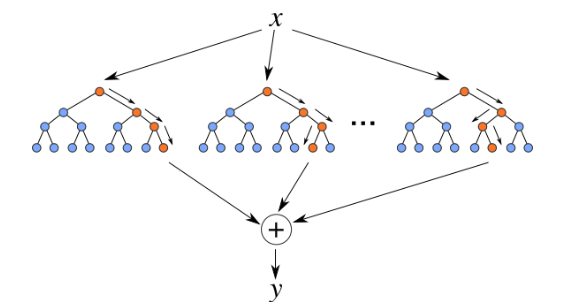 Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
Random Forest on the other hand relies of the predicted outcomes from many different decision trees, each of which is built in a slightly different way. It is an ensemble technique that combines the predicted outcomes from each decision tree to give one answer. Typically, the number of trees created by the Random Forest algorithm is defined by a parameter setting, and in most languages this can default to 100+ or 200+ trees.
The Random Forest algorithm has three main features:
- It uses a method called bagging to create different subsets of the original training data
- It will randomly section different subsets of the features/attributes and build the decision tree based on this subset
- By creating many different decision trees, based on different subsets of the training data and different subsets of the features, it will increase the probability of capturing all possible ways of modeling the data
For each decision tree produced, the algorithm will use a measure, such as the Gini Index, to select the attributes to split on at each node of the decision tree.
To create a RandomForest model using Oracle Data Mining, you will follow the same process as with any of the other algorithms, the core of these are:
- define the parameter settings
- create the model
- score/label new data
Let’s start with the first step, defining the parameters. As with all the classification algorithms the same or similar parameters are set. With RandomForest we can set an additional parameter which tells the algorithm how many decision trees to create as part of the model. By default, 20 decision trees will be created. But if you want to change this number you can use the RFOR_NUM_TREES parameter. Remember the larger the value the longer it will take to create the model. But will have better accuracy. On the other hand with a small number of trees the quicker the model build will be, but might night be as accurate. This is something you will need to explore and determine. In the following example I change the number of trees to created to ten.
CREATE TABLE BANKING_RF_SETTINGS ( SETTING_NAME VARCHAR2(50), SETTING_VALUE VARCHAR2(50) ); BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.RFOR_NUM_TREES, 10); COMMIT; END;
Other default parameters used include, for creating each decision tree, use random 50% selection of columns and 50% sample of training data.
Now for step 2, create the model.
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
The above code measures how long it takes to create the model.
I’ve run this same parameters and create models for different training data set sizes. I’ve also changed the number of decision trees to create. The following table shows the timings.
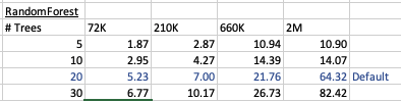
You can see it took 5.23 seconds to create a RandomForest model using the default settings for a data set of 72K records. This increase to just over one minute for a data set of 2 million records. Yo can also see the effect of reducing the number of decision trees on how long it takes the create model to run.
For step 3, on using the model on new data, this is just the same as with any of the classification models. Here is an example:
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
That’s it. That’s all there is to creating a RandomForest machine learning model using Oracle Machine Learning.
It’s quick and easy 🙂
MSET (Multivariate State Estimation Technique) in Oracle 20c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Oracle 21c Database comes with some new in-database Machine Learning algorithms.

The short name for one of these is called MSET or Multivariate State Estimation Technique. That’s the simple short name. The more complete name is Multivariate State Estimation Technique – Sequential Probability Ratio Test. That is a long name, and the reason is it consists of two algorithms. The first part looks at creating a model of the training data, and the second part looks at how new data is statistical different to the training data.
What are the use cases for this algorithm? This algorithm can be used for anomaly detection.

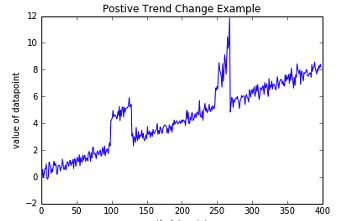
Anomaly Detection, using algorithms, is able identifying unexpected items or events in data that differ to the norm. It can be easy to perform some simple calculations and graphics to examine and present data to see if there are any patterns in the data set. When the data sets grow it is difficult for humans to identify anomalies and we need the help of algorithms.
The images shown here are easy to analyze to spot the anomalies and it can be relatively easy to build some automated processing to identify these. Most of these solutions can be considered AI (Artificial Intelligence) solutions as they mimic human behaviors to identify the anomalies, and these example don’t need deep learning, neural networks or anything like that.
Other types of anomalies can be easily spotted in charts or graphics, such as the chart below.
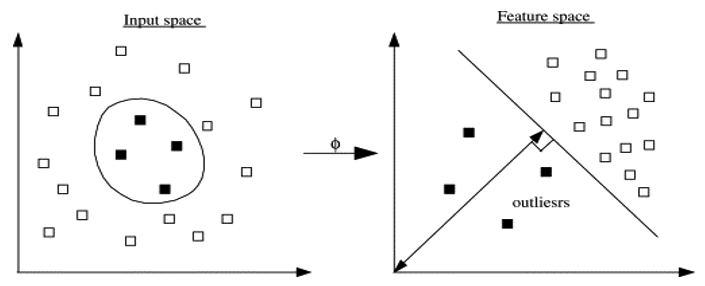 There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
Getting back to the MSET algorithm. Remember it is a 2-part algorithm abbreviated to MSET. The first part is a non-linear, nonparametric anomaly detection algorithm that calibrates the expected behavior of a system based on historical data from the normal sequence of monitored signals. Using data in time series format (DATE, Value) the training data set contains data consisting of “normal” behavior of the data. The algorithm creates a model to represent this “normal”/stationary data/behavior. The second part of the algorithm compares new or live data and calculates the differences between the estimated and actual signal values (residuals). It uses Sequential Probability Ratio Test (SPRT) calculations to determine whether any of the signals have become degraded. As you can imagine the creation of the training data set is vital and may consist of many iterations before determining the optimal training data set to use.
MSET has its origins in computer hardware failures monitoring. Sun Microsystems have been were using it back in the late 1990’s-early 2000’s to monitor and detect for component failures in their servers. Since then MSET has been widely used in power generation plants, airplanes, space travel, Disney uses it for equipment failures, and in more recent times has been extensively used in IOT environments with the anomaly detection focused on signal anomalies.
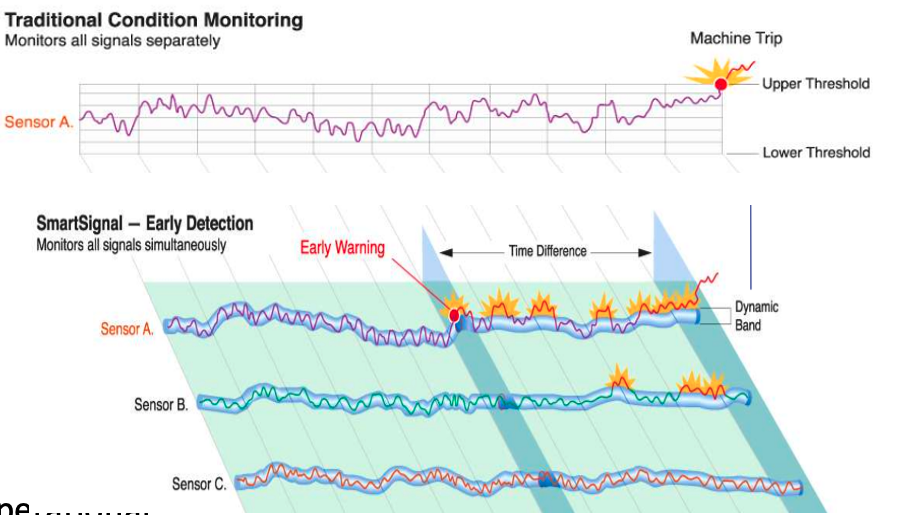
How does MSET work in Oracle 21c?
An important point to note before we start is, you can use MSET on your typical business data and other data stored in the database. It isn’t just for sensor, IOT, etc data mentioned above and can be used in many different business scenarios.
The first step you need to do is to create the time series data. This can be easily done using a view, but a Very important component is the Time attribute needs to be a DATE format. Additional attributes can be numeric data and these will be used as input to the algorithm for model creation.
-- Create training data set for MSET CREATE OR REPLACE VIEW mset_train_data AS SELECT time_id, sum(quantity_sold) quantity, sum(amount_sold) amount FROM (SELECT * FROM sh.sales WHERE time_id <= '30-DEC-99’) GROUP BY time_id ORDER BY time_id;
The example code above uses the SH schema data, and aggregates the data based on the TIME_ID attribute. This attribute is a DATE data type. The second import part of preparing and formatting the data is Ordering of the data. The ORDER BY is necessary to ensure the data is fed into or processed by the algorithm in the correct time series order.
The next step involves defining the parameters/hyper-parameters for the algorithm. All algorithms come with a set of default values, and in most cases these are suffice for your needs. In that case, you only need to define the Algorithm Name and to turn on Automatic Data Preparation. The following example illustrates this and also includes examples of setting some of the typical parameters for the algorithm.
BEGIN DELETE FROM mset_settings; -- Select MSET-SPRT as the algorithm INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.algo_name, dbms_data_mining.algo_mset_sprt); -- Turn on automatic data preparation INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); -- Set alert count INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_COUNT, 3); -- Set alert window INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_WINDOW, 5); -- Set alpha INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALPHA_PROB, 0.1); COMMIT; END;
To create the MSET model using the MST_TRAIN_DATA view created above, we can run:
BEGIN -- DBMS_DATA_MINING.DROP_MODEL(MSET_MODEL'); DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'MSET_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MSET_TRAIN_DATA', case_id_column_name => 'TIME_ID', target_column_name => '', settings_table_name => 'MSET_SETTINGS'); END;
The SELECT statement below is an example of how to call and run the MSET model to label the data to find anomalies. The PREDICTION function will return a values of 0 (zero) or 1 (one) to indicate the predicted values. If the predicted values is 0 (zero) the MSET model has predicted the input record to be anomalous, where as a predicted values of 1 (one) indicates the value is typical. This can be used to filter out the records/data you will want to investigate in more detail.
-- display all dates with Anomalies SELECT time_id, pred FROM (SELECT time_id, prediction(mset_sh_model using *) over (ORDER BY time_id) pred FROM mset_test_data) WHERE pred = 0;
Benchmarking calling Oracle Machine Learning using REST
Over the past year I’ve been presenting, blogging and sharing my experiences of using REST to expose Oracle Machine Learning models to developers in other languages, for example Python.
One of the questions I’ve been asked is, Does it scale?
Although I’ve used it in several projects to great success, there are no figures I can report publicly on how many REST API calls can be serviced 😦
But this can be easily done, and the results below are based on using and Oracle Autonomous Data Warehouse (ADW) on the Oracle Always Free.
The machine learning model is built on a Wine reviews data set, using Oracle Machine Learning Notebook as my tool to write some SQL and PL/SQL to build out a model to predict Good or Bad wines, based on the Prices and other characteristics of the wine. A REST API was built using this model to allow for a developer to pass in wine descriptors and returns two values to indicate if it would be a Good or Bad wine and the probability of this prediction.
No data is stored in the database. I only use the machine learning model to make the prediction
I built out the REST API using APEX, and here is a screenshot of the GET API setup.

Here is an example of some Python code to call the machine learning model to make a prediction.
import json
import requests
country = 'Portugal'
province = 'Douro'
variety = 'Portuguese Red'
price = '30'
resp = requests.get('https://jggnlb6iptk8gum-adw2.adb.us-ashburn-1.oraclecloudapps.com/ords/oml_user/wine/wine_pred/'+country+'/'+province+'/'+'variety'+'/'+price)
json_data = resp.json()
print (json.dumps(json_data, indent=2))
—–
{
"pred_wine": "LT_90_POINTS",
"prob_wine": 0.6844716987704507
}
But does this scale, as in how many concurrent users and REST API calls can it handle at the same time.
To test this I multi-threaded processes in Python to call a Python function to call the API, while ensuring a range of values are used for the input parameters. Some additional information for my tests.
- Each function call included two REST API calls
- Test effect of creating X processes, at same time
- Test effect of creating X processes in batches of Y agents
- Then, the above, with function having one REST API call and also having two REST API calls, to compare timings
- Test in range of parallel process from 10 to 1,000 (generating up to 2,000 REST API calls at a time)
Some of the results. The table shows the time(*) in seconds to complete the number of processes grouped into batches (agents). My laptop was the limiting factor in these tests. It wasn’t able to test when the number of parallel processes when above 500. That is why I broke them into batches consisting of X agents

* this is the total time to run all the Python code, including the time taken to create each process.
Some observations:
- Time taken to complete each function/process was between 0.45 seconds and 1.65 seconds, for two API calls.
- When only one API call, time to complete each function/process was between 0.32 seconds and 1.21 seconds
- Average time for each function/process was 0.64 seconds for one API functions/processes, and 0.86 for two API calls in function/process
- Table above illustrates the overhead associated with setting up, calling, and managing these processes
As you can see, even with the limitations of my laptop, using an Oracle Database, in-database machine learning and REST can be used to create a Micro-Service type machine learning scoring engine. Based on these numbers, this machine learning micro-service would be able to handle and process a large number of machine learning scoring in Real-Time, and these numbers would be well within the maximum number of such calls in most applications. I’m sure I could process more parallel processes if I deployed on a different machine to my laptop and maybe used a number of different machines at the same time
How many applications within you enterprise needs to process move than 6,000 real-time machine learning scoring per minute? This shows us the Oracle Always Free offering is capable and suitable for most applications.
Now, if you are processing more than those numbers per minutes then perhaps you need to move onto the paid options.
What next? I’ll spin up two VMs on Oracle Always Free, install Python, copy code into these VMs and have then run in parallel 🙂
OML Workspace Permissions
When working with Oracle Machine Learning (OML) you are creating notebooks which focus on a particular data exploration and possibly some machine learning. Despite it’s name, OML is used extensively for data discovery and data exploration.
One of the aims of using OML, or notebooks in general, is that these can be easily shared with other people either within the same team or beyond. Something to consider when sharing notebooks is what you are allowing other people do with your notebook. Without any permissions you are allowing people to inspect, run and modify the notebooks. This can be a problem because those people you are sharing with may or may not be allowed to make modification. Some people should be able to just view the notebook, and others should be able to more advanced tasks.
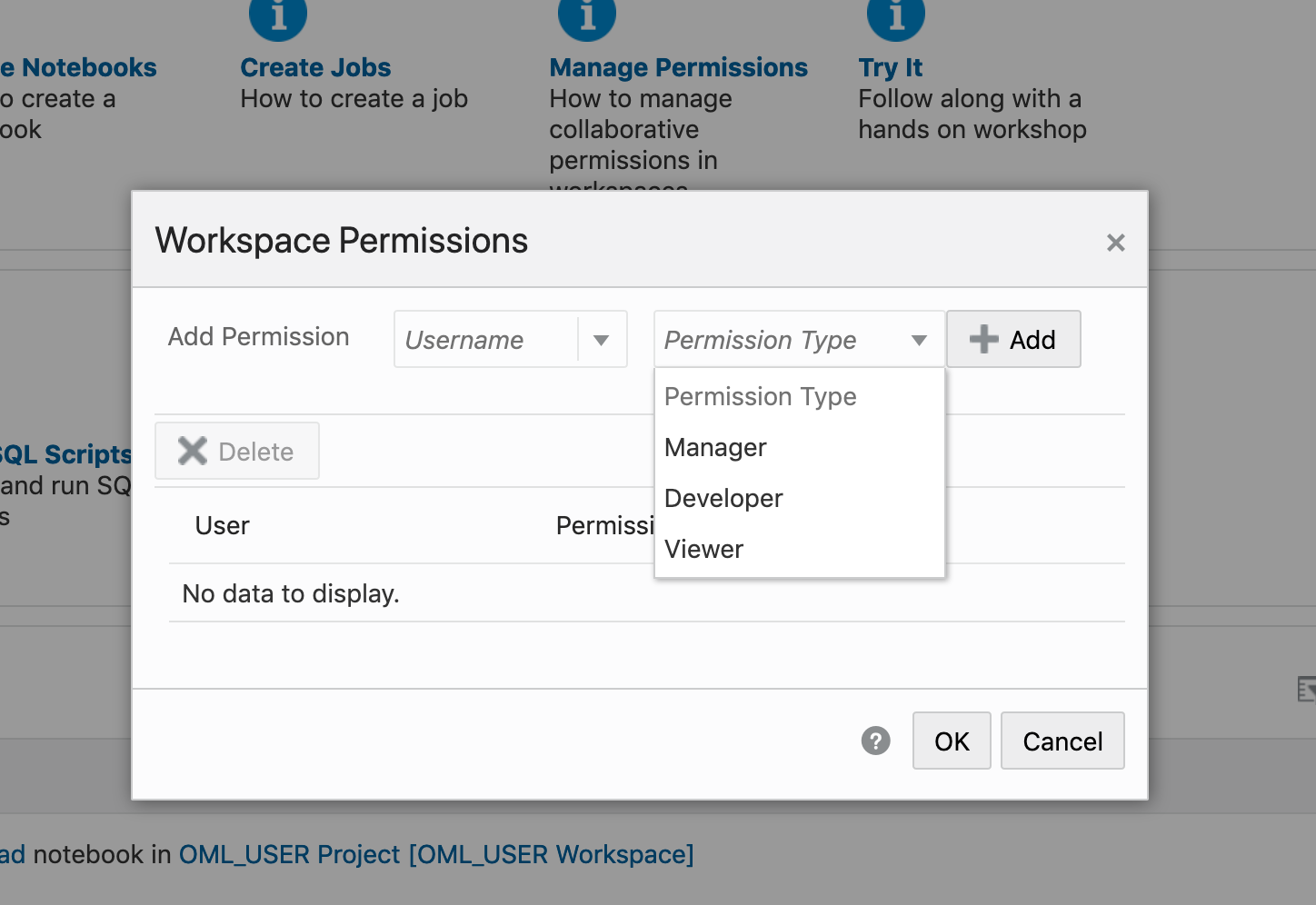
With OML Notebooks there are four primary types of people who can access Notebooks and these can have different privileges. These are defined as
- Developer : Can create new notebooks withing a project and workspace but cannot create a workspace or a project. Can create and run a notebook as a scheduled job.
- Viewer : They can just view projects, Workspaces and notebooks. They are not allowed to create or run anything.
- Manager : can create new notebooks and projects. But only view Workspaces. Additionally they can schedule notebook jobs.
- Administrators : Administrators of the OML environment do not have any edit capabilities on notebooks. But they can view them.

Oracle ADW how to load new OML notebooks
Oracle Autonomous Database (ADW) has been out a while now and have had several, behind the scenes, improvements and new/additional features added.
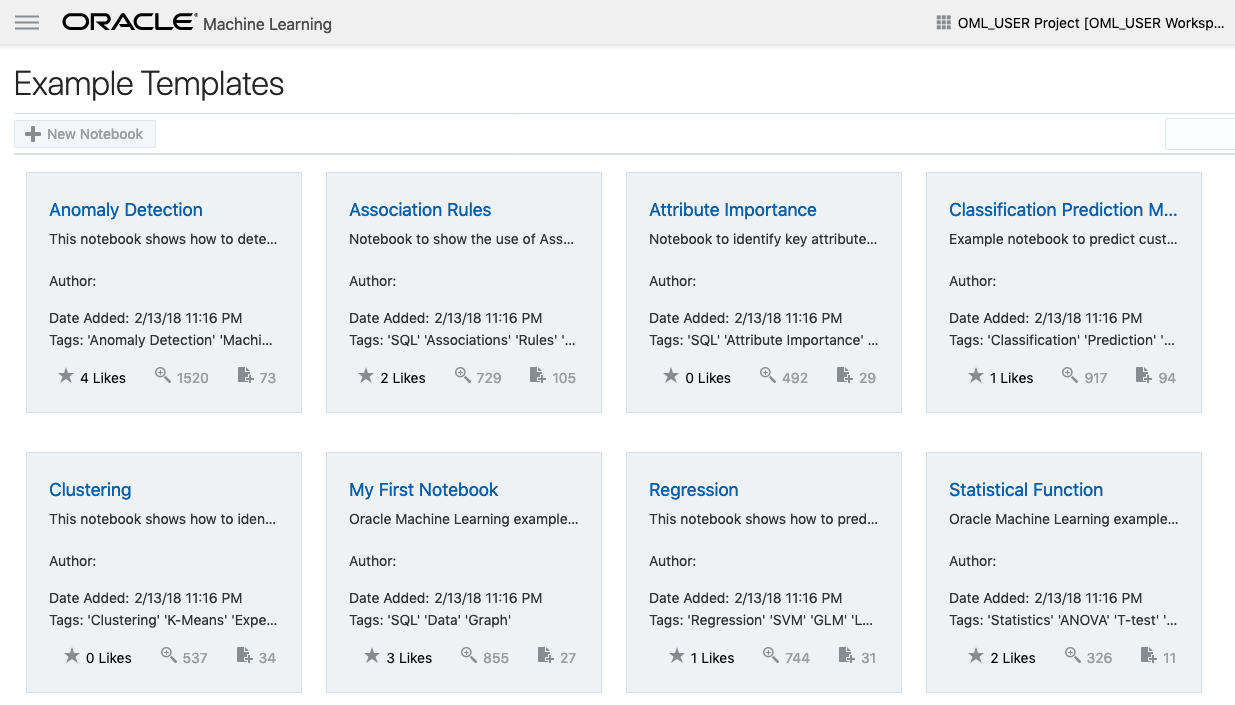
If you have used the Oracle Machine Learning (OML) component of ADW you will have seen the various sample OML Notebooks that come pre-loaded. These are easy to open, use and to try out the various OML features.

The above image shows the top part of the login screen for OML. To see the available sample notebooks click on the Examples icon. When you do, you will get the following sample OML Notebooks.
But what if you have a notebook you have used elsewhere. These can be exported in json format and loaded as a new notebook in OML.
To load a new notebook into OML, select the icon (three horizontal line) on the top left hand corner of the screen. Then select Notebooks from the menu.

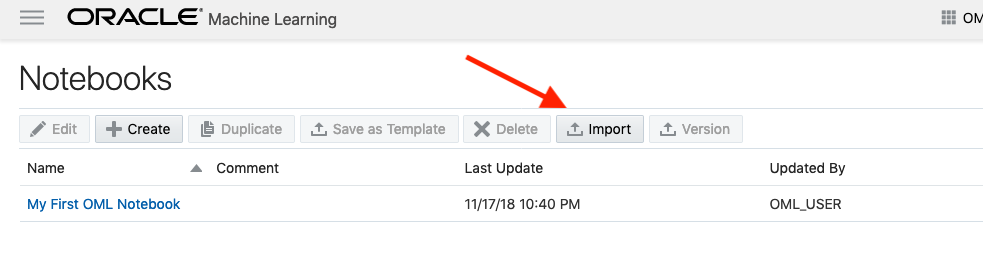
Then select the Import button located at the top of the Notebooks screen. This will open a File window, where you can select the json file from your file system.
A couple of seconds later the notebook will be available and listed along side any other notebooks you may have created.
All done!
You have now imported a new notebook into OML and can now use it to process your data and perform machine learning using the in-database features.
Understanding, Building and Using Neural Network Models using Oracle 18c
I recently had an article published on Oracle Developer Community website about Understanding, Building and Using Neural Network Machine Learning Models with Oracle 18c. I’ve also had a 2 Minute Tech Tip (2MTT) video about this topic and article. Oracle 18c Database brings prominent new machine learning algorithms, including Neural Networks and Random Forests. While many articles are available on machine learning, most of them concentrate on how to build a model. Very few talk about how to use these new algorithms in your applications to score or label new data. This article will explain how Neural Networks work, how to build a Neural Network in Oracle Database, and how to use the model to score or label new data. What are Neural Networks? Over the past couple of years, Neural Networks have attracted a lot of attention thanks to their ability to efficiently find patterns in data—traditional transactional data, as well as images, sound, streaming data, etc. But for some implementations, Neural Networks can require a lot of additional computing resources due to the complexity of the many hidden layers within the network. Figure 1 gives a very simple representation of a Neural Network with one hidden layer. All the inputs are connected to a neuron in the hidden layer (red circles). A neuron takes a set of numeric values as input and maps them to a single output value. (A neuron is a simple multi-input linear regression function, where the output is passed through an activation function.) Two common activation functions are logistic and tanh functions. There are many others, including logistic sigmoid function, arctan function, bipolar sigmoid function, etc. Continue reading the rest of the article here.

You must be logged in to post a comment.