
Measuring Kurtosis of Data in Oracle (21c)
Kurtosis is a new analytics function in Oracle 21c (20c) and is one of a set of commonly used statistical functions used to evaluate data to see and understand the behavior of the data.
[See my previous post where I give examples of the new Skewness functions]
Kurtosis is the measurement of the tails of the data distribution and its comparison with that of normal distribution. The Kurtosis of the normal distribution is said to be 3. To make interpenetrating results easier (a Zero) kurtosis measure for gaussian/normal distribution by subtracting 3 from its value, this is called Excess Kurtosis. Kurtosis can be used to describe the height or the breath of the distributions, when compared to a normal distributions, although this is not theoretically correct, it gives a simpler explanation and visualization of it. The following diagram gives an example of a normal distribution, a plot of Positive Kurtosis and Negative Kurtosis.
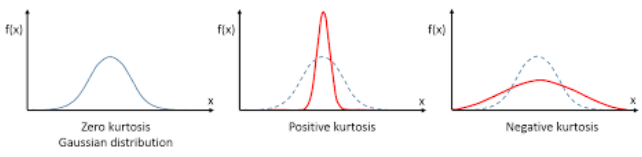
Prior to the new Kurtosis SQL functions (KURTOSIS_POP and KURTOSIS_SAMP), you had to calculate the Kurtosis value manually using something like the following SQL. These use the same data and attributes set used for the Skewness examples.
select avg(KV) K_value
from (select power((age - avg(age) over ())/stddev(age) over (), 4) KV
from cust_data)
union all
select avg(KV) K_value
from (select power((duration - avg(duration) over ())/stddev(duration) over (), 4) KV
from cust_data);
K_value
------------------------------------------
3.79088571963003808388287765230733611415
23.24420570926391173498028369605428048285
These don’t include the subtraction of 3 to give a zero kurtosis, and these values can be compared to the data distribution charts shown in the Skewness post.
Now with the new Kurtosis functions it simplifies the tasks of getting these values.
SELECT kurtosis_pop(age), kurtosis_samp(age) FROM bank_additional union all SELECT kurtosis_pop(duration), kurtosis_samp(duration) FROM bank_additional; KURTOSIS_POP KURTOSIS_SAMP ------------------ ----------------------------------------- 0.791069803527387 0.79131153115443467194451597661213420763 20.245334438614832 20.24793801497878942299945619307526969226
As you can see the Kurtosis function have the subtraction include.
As with the Skewness functions, the SAMP version works on a sample of the data values and as the number inputs increases, and differences between the POP and SAMP will reduce.
