
21c
Oracle on AWS costs
In a previous post I walked through the steps of setting up an Oracle Database on AWS RDS. It was a very simple and straight forward process. The only thing to watch out for was to open the network to allow traffic in and out. I also showed how to connect SQL Developer to that database.
I’ve been using it for a few days and needed to move onto other things for a few days. I could leave the Database up and running during this period or I could shut down the Database to save a few dollars/euro. It also gave me a chance to see how much this database cloud instance is costing me. In my previous post, it was estimated to cost about 0.89c per day.
Before we look at the Actual/Real costs, let’s walk through the steps of shutting down the database.
To stop the database, click on the Actions button on the top right hand side of the screen, just above the database summary details. You will get a confirmation window/box appearing, see image below, asking you to confirm by clicking ‘Yes, Stop Now’.
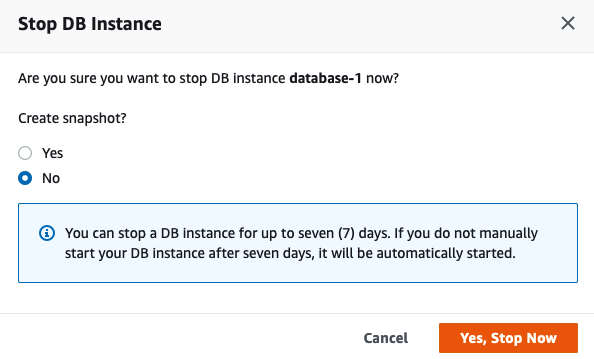
It will take a few minutes for this shutdown to complete and in my case it took approx. 8 minutes, which was a little surprising as no one was using it at the time. You might need to refresh the webpage to see this change.

That’s all very simple, but it does give you a warning about the stopped database instance. It will be restarted in 7 days time! So if this is a database you will occasionally use, then you will need to carefully manage this particular feature, otherwise you will end up with the database automatically starting and you will be paying for this.
What about the Costs?
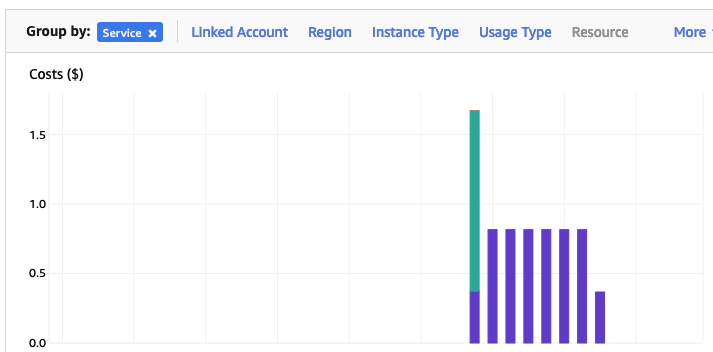
The costs for running this service can be found in the AWS Cost Management page. Here we can see the database was running for 7 and a bit days before I shut it down, and we can see the daily cost was 0.82c. Two things note about these costs. There was larger cost for the first day. Most of this cost was associated with the setup and configuration of the database service. The second thing to note is the costs listed in this console do not include taxes.
A got the bill for this usage, and it came to $6.94, consisting of $5.64 for usage (approx. 75c per day) and $1.30 in taxes/vat. Not a lot considering some cloud services, but comes out at approx 92.5c per day, which is a little more than the estimated cost when the service was being created. A small example of what can happen between the “in theory” cost of cloud versus the actual costs.
AWS RDS Oracle setup
There are lots of options available to you for creating and using an Oracle Database.
One of these options is to use AWS RDS services to create and host a Database.
Warning: Using AWS is a paid service and the RDS options are available based on the size of the server you pick. The example show in below will cost approx 89c per day or $27 per month. For this the database will be running 24×7. You could reduce this cost significantly by only starting/stopping the Database when you need it, or alternatively create an AWS lamda function service to start/stop.
First thing you need to do is go create an AWS account, and yes you will need to hand over your credit card number.
After creating your account and you have logged in, search for RDS and you will get the following display. Click on the orange button at the top of the page to Create Database.

Then select
- Standard create
- Oracle
- Architecture settings -> Use multitenant architecture
- Oracle Enterprise Edition
- Version -> use the drop down and select latest version (in my case 21)
- Templates -> Dev/Test
- Instance Identifier -> database-1
- Master Username -> admin
- Master password -> <set password> and confirm it
- DB Instance Class – as we only want a DB for playing with, go with the cheapest -> db.t3.small (Hint: Scroll to bottom of page to see the estimated monthly costs)
- Storage type -> General Purpose SSD. If you change this to Magnetic, you will see the cost drop by approx $2 per month. I selected General Purpose SSD
- Allocated Storage -> I set this to 20G (it’s just a small play DB)
- Disable/un-tick – Entable Storage Autoscaling
- Select defaults for VPC (Virtual Private Cloud) – see notes later on opening this to allow connection from your computer.
- Public Access – Set to Yes
- Defaults for remaining options.
[Note: You might be prompted to enter a DB Name. Keep this short, with no special characters.]
Click on ‘Create Database’ button at bottom of screen to create the database. It can take anything from a couple of minutes to 30 minutes to create the Database.
When everything is create, and you try to connect to the Database using SQL Developer, you will not be able to connect. The VPC needs to be opened to outside traffic. Click on the VPC Security Groups link, then click on the Security Group link on the next page
Then click on the ‘Edit Inbound rules’ button, and then on the ‘Add Rule’ button (bottom left) to add a new rule. Then select ‘All Traffic’ from drop down, and 0.0.0.0/0 in the Source field. Then save the rules.

You are now ready to create a connection using SQL Developer. To do this you will need database Endpoint from the RDS dashboard. You will also need the DB Name. This can be found by clicking on the ‘Configuration’ tab, and is listed on left-hand side under DB Name
Now in SQL Developer enter those details and click Test button to see if the connection works. It should! but if it doesn’t then double check the username and password, the other details entered, and the network changes made above are correct.

You can now connect and start using the Database.
Warning: You will be connecting as the ADMIN for the Database. You should never use this account for any development work. So go create a new database user/schema and use it for all your work.
Collection of Oracle 21c posts on new Machine Learning and Statistical functions
Oracle 21c was officially released a few days about and this post contains links to some blog posts I’ve written on new machine learning and statistical functions in the new Oracle 21c.
- Adam Optimization Solver for Neural Network Algorithm
- MSET-SPRT Algorithm
- XGBoost Algorithm
- Measuring SKEWNESS Function
- Measuring tailedness of data with KURTOSIS Function
I also have posts on new OML4Py and AutoML too, and I’ll have a different set of posts for those, so look out them.
Also check out my previous blog post that covers new machine learning feature introduced in Oracle 19c.
Measuring Kurtosis of Data in Oracle (21c)
Kurtosis is a new analytics function in Oracle 21c (20c) and is one of a set of commonly used statistical functions used to evaluate data to see and understand the behavior of the data.
[See my previous post where I give examples of the new Skewness functions]
Kurtosis is the measurement of the tails of the data distribution and its comparison with that of normal distribution. The Kurtosis of the normal distribution is said to be 3. To make interpenetrating results easier (a Zero) kurtosis measure for gaussian/normal distribution by subtracting 3 from its value, this is called Excess Kurtosis. Kurtosis can be used to describe the height or the breath of the distributions, when compared to a normal distributions, although this is not theoretically correct, it gives a simpler explanation and visualization of it. The following diagram gives an example of a normal distribution, a plot of Positive Kurtosis and Negative Kurtosis.

Prior to the new Kurtosis SQL functions (KURTOSIS_POP and KURTOSIS_SAMP), you had to calculate the Kurtosis value manually using something like the following SQL. These use the same data and attributes set used for the Skewness examples.
select avg(KV) K_value
from (select power((age - avg(age) over ())/stddev(age) over (), 4) KV
from cust_data)
union all
select avg(KV) K_value
from (select power((duration - avg(duration) over ())/stddev(duration) over (), 4) KV
from cust_data);
K_value
------------------------------------------
3.79088571963003808388287765230733611415
23.24420570926391173498028369605428048285
These don’t include the subtraction of 3 to give a zero kurtosis, and these values can be compared to the data distribution charts shown in the Skewness post.
Now with the new Kurtosis functions it simplifies the tasks of getting these values.
SELECT kurtosis_pop(age), kurtosis_samp(age) FROM bank_additional union all SELECT kurtosis_pop(duration), kurtosis_samp(duration) FROM bank_additional; KURTOSIS_POP KURTOSIS_SAMP ------------------ ----------------------------------------- 0.791069803527387 0.79131153115443467194451597661213420763 20.245334438614832 20.24793801497878942299945619307526969226
As you can see the Kurtosis function have the subtraction include.
As with the Skewness functions, the SAMP version works on a sample of the data values and as the number inputs increases, and differences between the POP and SAMP will reduce.
Enhanced Window Clause functionality in Oracle 21c (20c)
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
The Oracle Database has had advanced analytical functions for some time now and with each release we get to have some new additions or some enhancements to existing functionality.
One new enhancement, available and documented in 21c (not yet released at time of writing this), is changing in the way the Window Clause can be defined for analytic functions. Oracle 21c is available on Oracle Cloud as a pre-release for evaluation purposes (but it won’t be available for much longer!). The examples shown below are based on using this 21c pre-release of the database.
NOTE: At this point, no one really knows when or if 20c will be released. I’m sure all the documented 20c new features will be rolled into 21c, whenever that will be released.
Before giving some examples of the new Window Clause functionality, lets have a quick recap on how we could use it up to now (up to 19c database). Here is a simple example of windowing the data by creating partitions based on the distinct values in DEPTNO column
select deptno,
ename,
job,
salary,
avg (salary) over (partition by DEPTNO) avg_sal
from employee
order by deptno;

Here we get to see the average salary being calculated for each window partition and being reset for the next windwo partition.
The SQL:2011 standard support the defining of the Window clause in the query block, after defining the list tables for the query. This allows us to define the window clause one and then reference this for analytic function that need it. The following example illustrate this. I’ve take the able query and altered it to have the newer syntax. I’ve highlighted the new or changed code in blue. In the analytic function, the w1 refers to the Window clause defined later, and is more in keeping with how a query is logically processed.
select deptno,
ename,
sal,
sum(sal) over (w1) sum_sal
from emp
window w1 as (partition by deptno);
As you would expect we get the same results returned.
This newer syntax is particularly useful when we have many more analytic function in our queries, and some of these are using slightly different windowing. To me it makes it easier to read and to make edits, allowing an edit to be preformed once instead of for each analytic function, and avoids any errors. But making it easier to read and understand is by far the greatest benefit. Here is another example which uses different window clauses using the previous syntax.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (PARTITION BY deptno ORDER BY sal) AS avg_dept_sal,
AVG(sal) OVER (PARTITION BY deptno ) AS avg_dept_sal2,
SUM(sal) OVER (PARTITION BY deptno ORDER BY sal desc) AS sum_dept_sal
FROM emp;
Using the newer syntax this gets transformed into the following.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (w1) AS avg_dept_sal,
AVG(sal) OVER (w2) AS avg_dept_sal2,
SUM(sal) OVER (w2) AS avg_dept_sal
FROM emp
window w1 as (PARTITION BY deptno ORDER BY sal),
w2 as (PARTITION BY deptno),
w3 as (PARTITION BY deptno ORDER BY sal desc);
MSET (Multivariate State Estimation Technique) in Oracle 20c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Oracle 21c Database comes with some new in-database Machine Learning algorithms.

The short name for one of these is called MSET or Multivariate State Estimation Technique. That’s the simple short name. The more complete name is Multivariate State Estimation Technique – Sequential Probability Ratio Test. That is a long name, and the reason is it consists of two algorithms. The first part looks at creating a model of the training data, and the second part looks at how new data is statistical different to the training data.
What are the use cases for this algorithm? This algorithm can be used for anomaly detection.

Anomaly Detection, using algorithms, is able identifying unexpected items or events in data that differ to the norm. It can be easy to perform some simple calculations and graphics to examine and present data to see if there are any patterns in the data set. When the data sets grow it is difficult for humans to identify anomalies and we need the help of algorithms.
The images shown here are easy to analyze to spot the anomalies and it can be relatively easy to build some automated processing to identify these. Most of these solutions can be considered AI (Artificial Intelligence) solutions as they mimic human behaviors to identify the anomalies, and these example don’t need deep learning, neural networks or anything like that.
Other types of anomalies can be easily spotted in charts or graphics, such as the chart below.
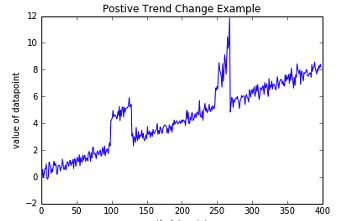
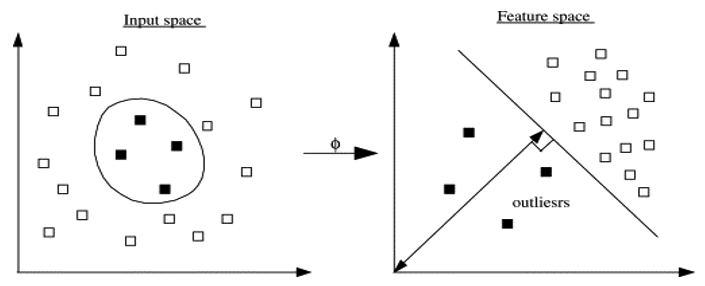 There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
Getting back to the MSET algorithm. Remember it is a 2-part algorithm abbreviated to MSET. The first part is a non-linear, nonparametric anomaly detection algorithm that calibrates the expected behavior of a system based on historical data from the normal sequence of monitored signals. Using data in time series format (DATE, Value) the training data set contains data consisting of “normal” behavior of the data. The algorithm creates a model to represent this “normal”/stationary data/behavior. The second part of the algorithm compares new or live data and calculates the differences between the estimated and actual signal values (residuals). It uses Sequential Probability Ratio Test (SPRT) calculations to determine whether any of the signals have become degraded. As you can imagine the creation of the training data set is vital and may consist of many iterations before determining the optimal training data set to use.
MSET has its origins in computer hardware failures monitoring. Sun Microsystems have been were using it back in the late 1990’s-early 2000’s to monitor and detect for component failures in their servers. Since then MSET has been widely used in power generation plants, airplanes, space travel, Disney uses it for equipment failures, and in more recent times has been extensively used in IOT environments with the anomaly detection focused on signal anomalies.
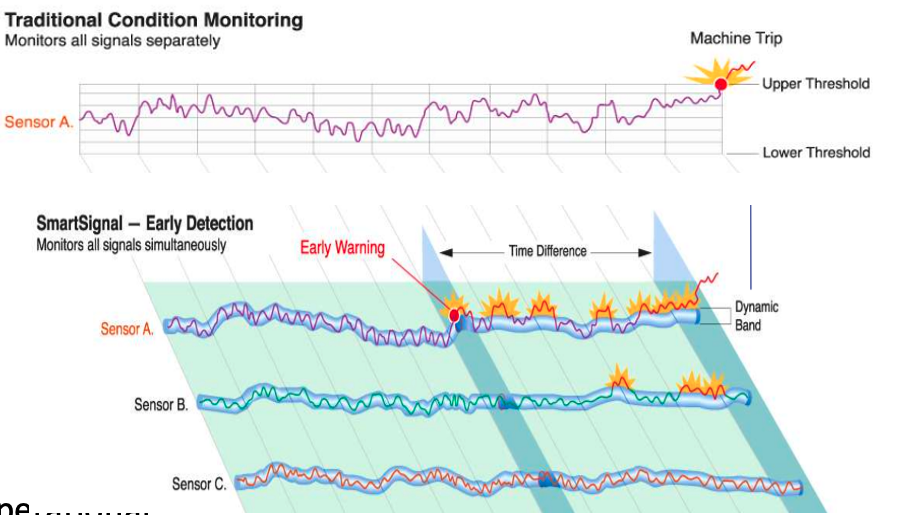
How does MSET work in Oracle 21c?
An important point to note before we start is, you can use MSET on your typical business data and other data stored in the database. It isn’t just for sensor, IOT, etc data mentioned above and can be used in many different business scenarios.
The first step you need to do is to create the time series data. This can be easily done using a view, but a Very important component is the Time attribute needs to be a DATE format. Additional attributes can be numeric data and these will be used as input to the algorithm for model creation.
-- Create training data set for MSET CREATE OR REPLACE VIEW mset_train_data AS SELECT time_id, sum(quantity_sold) quantity, sum(amount_sold) amount FROM (SELECT * FROM sh.sales WHERE time_id <= '30-DEC-99’) GROUP BY time_id ORDER BY time_id;
The example code above uses the SH schema data, and aggregates the data based on the TIME_ID attribute. This attribute is a DATE data type. The second import part of preparing and formatting the data is Ordering of the data. The ORDER BY is necessary to ensure the data is fed into or processed by the algorithm in the correct time series order.
The next step involves defining the parameters/hyper-parameters for the algorithm. All algorithms come with a set of default values, and in most cases these are suffice for your needs. In that case, you only need to define the Algorithm Name and to turn on Automatic Data Preparation. The following example illustrates this and also includes examples of setting some of the typical parameters for the algorithm.
BEGIN DELETE FROM mset_settings; -- Select MSET-SPRT as the algorithm INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.algo_name, dbms_data_mining.algo_mset_sprt); -- Turn on automatic data preparation INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); -- Set alert count INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_COUNT, 3); -- Set alert window INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_WINDOW, 5); -- Set alpha INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALPHA_PROB, 0.1); COMMIT; END;
To create the MSET model using the MST_TRAIN_DATA view created above, we can run:
BEGIN -- DBMS_DATA_MINING.DROP_MODEL(MSET_MODEL'); DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'MSET_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MSET_TRAIN_DATA', case_id_column_name => 'TIME_ID', target_column_name => '', settings_table_name => 'MSET_SETTINGS'); END;
The SELECT statement below is an example of how to call and run the MSET model to label the data to find anomalies. The PREDICTION function will return a values of 0 (zero) or 1 (one) to indicate the predicted values. If the predicted values is 0 (zero) the MSET model has predicted the input record to be anomalous, where as a predicted values of 1 (one) indicates the value is typical. This can be used to filter out the records/data you will want to investigate in more detail.
-- display all dates with Anomalies SELECT time_id, pred FROM (SELECT time_id, prediction(mset_sh_model using *) over (ORDER BY time_id) pred FROM mset_test_data) WHERE pred = 0;

You must be logged in to post a comment.