
AutoML – using TPOT
Another popular AutoML library is TPOT, which stands for Tree-Based Pipeline Optimization Tool. The goal of TPOT is to automate the building of ML pipelines by combining a flexible expression tree representation of pipelines with stochastic search algorithms such as genetic programming. TPOT makes use of the Python-based scikit-learn library
Install the TPOT library using
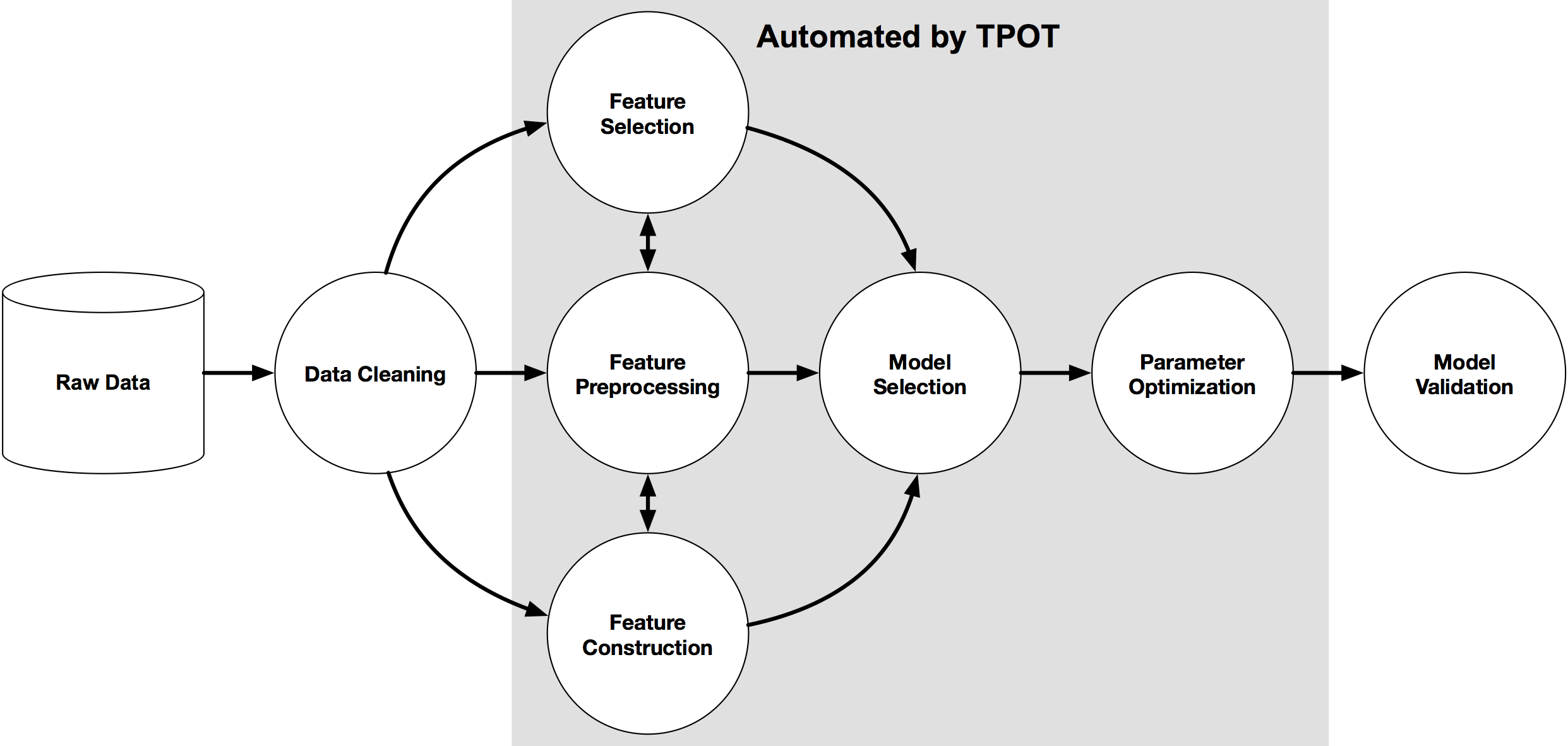
pip3 install tpotHere is an example tree-based pipeline from TPOT. Each circle corresponds to a machine learning operator, and the arrows indicate the direction of the data flow

Let’s build upon my previous blog post on AutomML, by using the same data set, with no modifications, and using the training (X_train, y_train) and test (X_test, y_test) data sets (dataframes), based on the Bank data sets. Check the previous post for the detailed steps on getting to this point.
In a similar way as the autosklean library example, I’m just going to demonstrate using TPOT for a classification problem using TPOTClassifier class. For regression problems, there is the corresponding TPOTRegressor class (not demonstrated in this post).
TPOTClassifier has the following main parameters (there are others):
- generations: Number of iterations to the run pipeline optimization process. The default is 100.
- population_size: Number of individuals to retain in the genetic programming population every generation. The default is 100.
- offspring_size: Number of offspring to produce in each genetic programming generation. The default is 100.
- mutation_rate: Mutation rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the GP algorithm how many pipelines to apply random changes to every generation. Default is 0.9
- crossover_rate: Crossover rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the genetic programming algorithm how many pipelines to “breed” every generation.
- scoring: Function used to evaluate the quality of a given pipeline for the classification problem like
accuracy,average_precision,roc_auc,recall, etc. The default isaccuracy. - cv: Cross-validation strategy used when evaluating pipelines. The default is 5.
- random_state: The seed of the pseudo-random number generator used in TPOT. Use this parameter to make sure that TPOT will give you the same results each time you run it against the same data set with that seed.
- verbosity: How much information TPOT communicates while it is running. Default is 0 (zero) TPOT will display nothing. 1=display minimal information, 2=display more information and progress bar, 3=print everything and progress bar.
- n_jobs: Number of processes to use. Default is 1. Use -1 to use all available cores.
Care is needed with some of these settings, for example generations should be set small to begin with, for example set to 5 initially. Also, population_size should also be kept small, for example 5 initially. These initial settings will evaluate 25 piplelines (5×5) configurations before finishing, and for some these settings may need to be adjusted smaller for initial work/investigations. Another parameter to adjust is the ‘verbosity’ setting. The default is 0 which means no details will be displayed. I like to set this to 3, as it gives more details of the outcomes from each pipeline. Adjust higher for more details or lower to fewer details. Another parameter to consider adjusting is ‘max_time_min’ and ‘max_eval_time_min’, but setting these too low can result in no or minimum results.
Load the library, setup the configuration and run. This is very simple to setup
from tpot import TPOTClassifier
#configure settings
tpot = TPOTClassifier(generations=5, population_size=5, verbosity=3, n_jobs=4, scoring='accuracy')
#run TPOT
tpot.fit(X_train, y_train)
As verbosity is set to 3 we get a lot of detail being displayed for each generation. The final output is shown below. What is missing from this is the progress bars which are displayed while TPOT is running
32 operators have been imported by TPOT.
Generation 1 - Current Pareto front scores:
-1 0.8963961891371728 RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=5, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
-2 0.8978183008194085 RandomForestClassifier(ZeroCount(input_matrix), RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=5, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
Pipeline encountered that has previously been evaluated during the optimization process. Using the score from the previous evaluation.
Generation 2 - Current Pareto front scores:
-1 0.8974020496851336 RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=8, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
-2 0.8978183008194085 RandomForestClassifier(ZeroCount(input_matrix), RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=5, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
_pre_test decorator: _random_mutation_operator: num_test=0 '(slice(None, None, None), 0)' is an invalid key.
Pipeline encountered that has previously been evaluated during the optimization process. Using the score from the previous evaluation.
Generation 3 - Current Pareto front scores:
-1 0.8974020496851336 RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=8, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
-2 0.8978183008194085 RandomForestClassifier(ZeroCount(input_matrix), RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=5, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
Skipped pipeline #21 due to time out. Continuing to the next pipeline.
Skipped pipeline #23 due to time out. Continuing to the next pipeline.
Generation 4 - Current Pareto front scores:
-1 0.8974020496851336 RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=8, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
-2 0.8978183008194085 RandomForestClassifier(ZeroCount(input_matrix), RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.7000000000000001, RandomForestClassifier__min_samples_leaf=5, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
Generation 5 - Current Pareto front scores:
-1 0.8983385200075953 RandomForestClassifier(input_matrix, RandomForestClassifier__bootstrap=True, RandomForestClassifier__criterion=gini, RandomForestClassifier__max_features=0.55, RandomForestClassifier__min_samples_leaf=8, RandomForestClassifier__min_samples_split=7, RandomForestClassifier__n_estimators=100)
TPOTClassifier(generations=5, n_jobs=4, population_size=5, scoring='accuracy',
verbosity=3)We can now display the ‘best’ model configuration discovered by TPOT.
tpot.fitted_pipeline_
Pipeline(steps=[('normalizer', Normalizer(norm='l1')),
('xgbclassifier',
XGBClassifier(base_score=0.5, booster='gbtree',
colsample_bylevel=1, colsample_bynode=1,
colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain',
interaction_constraints='', learning_rate=0.01,
max_delta_step=0, max_depth=8,
min_child_weight=7, missing=nan,
monotone_constraints='()', n_estimators=100,
n_jobs=1, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
subsample=0.8, tree_method='exact',
validate_parameters=1, verbosity=0))])In this run of TPOT, on this data set, XGBoost algorithm gave the best results using the parameters and settings listed above. What is interesting, everytime I’ve run TPOT for the same data set, using the same configuration parameters, I get a slightly different outcome.
Next step is to evaluate the ‘best’ model on the holdout data set.
tpot.score(X_test, y_test)
0.9037792344420167The results achieved are good and are better than some of the other models created by other AutoML libraries.
The final step we can perform is to export the model template. This creates a file containing the template code to create and use the model. This does require some modifications to specify the data set, and the pipeline of data modifications and transformations.
#export the model
tpot.export('.../tpot_Bank_pipeline.py')The output file contains the following.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
from xgboost import XGBClassifier
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=None)
# Average CV score on the training set was: 0.8986507248984001
exported_pipeline = make_pipeline(
Normalizer(norm="l1"),
XGBClassifier(learning_rate=0.01, max_depth=8, min_child_weight=7, n_estimators=100, n_jobs=1, subsample=0.8, verbosity=0)
)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)TPOT does have some issues and limitations. Well it is slow, and part of this is due to the nature of genetic algorithms, every time you run TPOT you may get different results, etc. Some of these issues can be addressed by adjusting some of the parameters, but even still, it doesn’t eliminate all of them. Running on GPU helps a little with timing of each run. TPOT doesn’t remove the need for data cleaning, feature engineering etc, but that is the case with most solutions.
