
database
Exploring Apache Iceberg – Part 4 – Parquet Files with Oracle Autonomous Database
In this post I’ll walk through the steps needed to setup and use Parquet files with an Oracle Autonomous Database and with the parquet files stored in Oracle Cloud. In my previous post, did something similar but for an on-premises Oracle Database.
Generally the setup is very similar except for two particular parts where we need to load the parquet files into a bucket on Oracle cloud (OCI) and the secondly we need some additional configuration in the Database to be able to access those files in an OCI bucket.
Create Bucket and Upload files
In OCI Storage section of OCI, create a new bucket (Parquet-files) and upload the parquet files. You can automate this step with a simple piece of Python code.
Create Credential
Log into the schema you are going to use to create the external table. You’ll need to generate an authentication token.
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( credential_name => 'PARQUET_FILES_CRED', username => '<your cloud username>', password => '<generated auth token>' );END;
Create the External table
We can now create the external table pointing to the parquet files in the OCI bucket.
BEGIN DBMS_CLOUD.CREATE_EXTERNAL_TABLE( table_name => 'PARQUET_FILES_EXT', credential_name => 'PARQUET_FILES_CRED', file_uri_list => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/<namespace>/b/Parquet-Files/o/*.parquet', format => JSON_OBJECT( 'type' VALUE 'parquet', 'schema' VALUE 'first', 'blankasnull' VALUE 'true', 'trimspaces' VALUE 'lrtrim' ) );END;/
Query the Parquet Files
We can now query the parquet files.
SELECT region, product, SUM(amount) AS total_salesFROM parquet_files_extGROUP BY regionORDER BY total_sales DESC;
What a difference a Bind Variable makes
To bind or not to bind, that is the question?
Over the years, I heard and read about using Bind variables and how important they are, particularly when it comes to the efficient execution of queries. By using bind variables, the optimizer will reuse the execution plan from the cache rather than generating it each time. Recently, I had conversations about this with a couple of different groups, and they didn’t really believe me and they asked me to put together a demonstration. One group said they never heard of ‘prepared statements’, ‘bind variables’, ‘parameterised query’, etc., which was a little surprising.
The following is a subset of what I demonstrated to them to illustrate the benefits and potential benefits.
Here is a basic example of a typical scenario where we have a SQL query being constructed using concatenation.
select * from order_demo where order_id = || 'i';That statement looks simple and harmless. When we try to check the EXPLAIN plan from the optimizer we will get an error, so let’s just replace it with a number, because that’s what the query will end up being like.
select * from order_demo where order_id = 1;When we check the Explain Plan, we get the following. It looks like a good execution plan as it is using the index and then doing a ROWID lookup on the table. The developers were happy, and that’s what those recent conversations were about and what they are missing.
-------------------------------------------------------------
| Id | Operation | Name | E-Rows |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | TABLE ACCESS BY INDEX ROWID| ORDER_DEMO | 1 |
|* 2 | INDEX UNIQUE SCAN | SYS_C0014610 | 1 |
-------------------------------------------------------------
The missing part in their understanding was what happens every time they run their query. The Explain Plan looks good, so what’s the problem? The problem lies with the Optimizer evaluating the execution plan every time the query is issued. But the developers came back with the idea that this won’t happen because the execution plan is cached and will be reused. The problem with this is how we can test this, and what is the alternative, in this case, using bind variables (which was my suggestion).
Let’s setup a simple test to see what happens. Here is a simple piece of PL/SQL code which will look 100K times to retrieve just one row. This is very similar to what they were running.
DECLARE
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF4'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = '||i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF4'));
END;
/When we run this test against a 23.7 Oracle Database running in a VM on my laptop, this completes in little over 2 minutes
Start time : 16:26:04:5527
End time : 16:28:13:4820
PL/SQL procedure successfully completed.
Elapsed: 00:02:09.158The developers seemed happy with that time! Ok, but let’s test it using bind variables and see if it’s any different. There are a few different ways of setting up bind variables. The PL/SQL code below is one example.
DECLARE
order_rec ORDER_DEMO%rowtype;
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF9'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = :1' using i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF9'));
END;
/
Start time : 16:31:39:162619000
End time : 16:31:40:479301000
PL/SQL procedure successfully completed.
Elapsed: 00:00:01.363This just took a little over one second to complete. Let me say that again, a little over one second to complete. We went from taking just over two minutes to run, down to just over one second to run.
The developers were a little surprised or more correctly, were a little shocked. But they then said the problem with that demonstration is that it is running directly in the Database. It will be different running it in Python across the network.
Ok, let me set up the same/similar demonstration using Python. The image below show some back Python code to connect to the database, list the tables in the schema and to create the test table for our demonstration

The first demonstration is to measure the timing for 100K records using the concatenation approach. I
# Demo - The SLOW way - concat values
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
# only loop 10,000 instead of 100,000 - impact of network latency
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = " + str(i))
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:45:29:523020
End time: 16:49:15:610094This took just under four minutes to complete. With PL/SQL it took approx two minutes. The extrat time is due to the back and forth nature of the client-server communications between the Python code and the Database. The developers were a little unhappen with this result.
The next step for the demonstrataion was to use bind variables. As with most languages there are a number of different ways to write and format these. Below is one example, but some of the others were also tried and give the same timing.
#Bind variables example - by name
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = :order_num", order_num=i )
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:53:00:479468
End time: 16:54:14:197552This took 1 minute 14 seconds. [Read that sentence again]. Compared to approx four minutes, and yes the other bind variable options has similar timing.
To answer the quote at the top of this post, “To bind or not to bind, that is the question?”, the answer is using Bind Variables, Prepared Statements, Parameterised Query, etc will make you queries and applications run a lot quicker. The optimizer will see the structure of the query, will see the parameterised parts of it, will see the execution plan already exists in the cache and will use it instead of generating the execution plan again. Thereby saving time for frequently executed queries which might just have a different value for one or two parts of a WHERE clause.
Select AI – OpenAI changes
A few weeks ago I wrote a few blog posts about using SelectAI. These illustrated integrating and using Cohere and OpenAI with SQL commands in your Oracle Cloud Database. See these links below.
- SelectAI – the beginning of a journey
- SelectAI – Doing something useful
- SelectAI – Can metadata help
- SelectAI – the APEX version
With the constantly changing world of APIs, has impacted the steps I outlined in those posts, particularly if you are using the OpenAI APIs. Two things have changed since writing those posts a few weeks ago. The first is with creating the OpenAI API keys. When creating a new key you need to define a project. For now, just select ‘Default Project’. This is a minor change, but it has caused some confusion for those following my steps in this blog post. I’ve updated that post to reflect the current setup in defining a new key in OpenAI. This is a minor change, oh and remember to put a few dollars into your OpenAI account for your key to work. I put an initial $10 into my account and a few minutes later API key for me from my Oracle (OCI) Database.
The second change is related to how the OpenAI API is called from Oracle (OCI) Databases. The API is now expecting a model name. From talking to the Oracle PMs, they will be implementing a fix in their Cloud Databases where the default model will be ‘gpt-3.5-turbo’, but in the meantime, you have to explicitly define the model when creating your OpenAI profile.
BEGIN
--DBMS_CLOUD_AI.drop_profile(profile_name => 'COHERE_AI');
DBMS_CLOUD_AI.create_profile(
profile_name => 'COHERE_AI',
attributes => '{"provider": "cohere",
"credential_name": "COHERE_CRED",
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "channels"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "times"}],
"model":"gpt-3.5-turbo"
}');
END;Other model names you could use include gpt-4 or gpt-4o.
Annual Look at Database Trends (Jan 2024)
Each January I take a little time to look back on the Database market over the previous calendar year. This year I’ll have a look at 2023 (obviously!) and how things have changed and evolved.
In my post from last year (click here) I mentioned the behaviour of some vendors and how they like to be-little other vendors. That kind of behaviour is not really acceptable, but they kept on doing it during 2023 up to a point. That point occurred during the Autumn of 2023. It was during this period there was some degree of consolidation in the IT industry with staff reductions through redundancies, contracts not being renewed, and so on. These changes seemed to have an impact on the messages these companies were putting out and everything seemed to calm down. These staff reductions have continued into 2024.
The first half of the year was generally quiet until we reached the Summer. We then experienced a flurry of activity. The first was the release of the new SQL standard (SQL:2023). There were some discussions about the changes included (for example Property Graph Queries), but the news quickly fizzled out as SQL:2023 was primarily a maintenance release, where the standard was catching up on what many of the database vendors had already implemented over the preceding years. Two new topics seemed to take over the marketing space over the summer months and early autumn. These included LLMs and Vector Databases. Over the Autumn we have seen some releases across vendors incorporating various elements of these and we’ll see more during 2024. Although there have been a lot of marketing on these topics, it still remains to be seen what the real impact of these will be on your average, everyday type of enterprise application. In a similar manner to previous “new killer features” specialised database vendors, we are seeing all the mainstream database vendors incorporating these new features. Just like what has happened over the last 30 years, these specialised vendors will slowly or quickly disappear, as the multi-model database vendors incorporate the features and allow organisations to work with their database rather than having to maintain several different vendors. Another database topic that seemed to attract a lot of attention over the past few years was Distributed SQL (or previously called NewSQL). Again some of the activity around this topic and suppliers seemed to drop off in the second half of 2023. Time will tell what is happening here, maybe it is going through a similar time the NewSQL era had (the previous incarnation). The survivors of that era now call themselves Distributed SQL (Databases), which I think is a better name as it describes what they are doing more clearly. The size of this market is still relatively small. Again time will tell.
There was been some consolidation in the open source vendor market, with some mergers, buyouts, financial difficulties and some shutting down. There have been some high-profile cases not just from the software/support supplier side of things but also from the cloud hosting side of things. Not everyone and not every application can be hosted in the cloud, as Microsoft CEO reported in early 2023 that 90+% of IT spending is still for on-premises. We have also seen several reports and articles of companies reporting their exit from the Cloud (due to costs) and how much they have saved moving back to on-premises data centres.
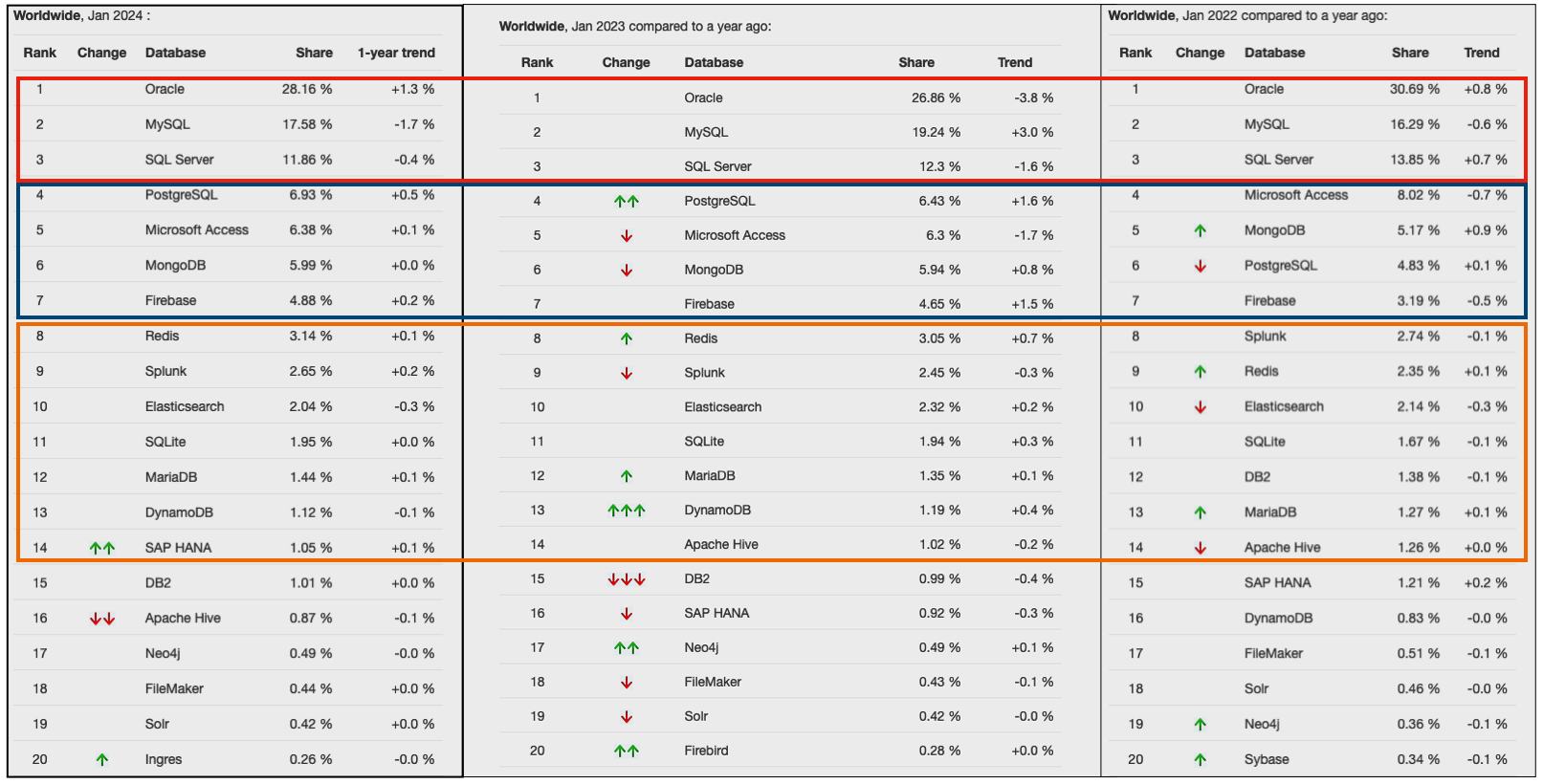
Two popular sites that constantly monitor the wider internet and judge how popular Databases are globally. These sites are DB-Engines and TOPDB Top Database index. These are well-known and are frequently cited. The image below, based on DB-Engines, shows the position of each Database in the top 20 and compares their position changes to 12 months previously. Here we have a comparison for 2023 and 2022 and the changes in positions. You’ll see there have been no changes in the positions of the top six Databases and minor positional changes for the next five Databases.

Although there has been some positive change for Postgres, given the numbers are based on log scale, this small change is small. The one notable mover in this table is Snowflake, which isn’t surprising really given what they offer and how they’ve been increasing their market share gradually over the years.
The TOPDB Top Database Index is another popular website and measures the popularity of Databases. It does this in a different way to DB-Engines. It can be an interesting exercise to cross-compare the results between the two websites. The image below compares the results from the past three years from TOPDB Top Database Index. We can see there is very little difference in the positions of most Databases. The point of interest here is the percentage Share of the top ten Databases. Have a look at the Databases that changed by more than one percentage point, and for those Databases (which had a lot of Marketing dollars) which moved very little, despite what some of their associated vendors try to get you to believe.
Dictionary Health Check in 23ai Oracle Database
There’s a new PL/SQL package in Oracle 23ai Database that allows you to check for any inconsistencies or problems that might occur in the data dictionary of the database. Previously there was an external SQL script available to perform similar action (hcheck.sql).
Inconsistencies can occur from time to time and can be caused by various reasons. It’s good to perform regular checks, and having the necessary functionality in a PL/SQL package allows for easier use and automation.
Warning: There are slightly different names for this PL/SQL package and it depends on which version of 23ai Database you are running. If you are running an early release of 23c this package is called DBMS_HCHECK. If you are running against a newer version (say 23.3ai) the package is called DBMS_DICTIONARY_CHECK.
This PL/SQL package assists you in identifying such inconsistencies and in some cases provides guided remediation to resolve the problem and avoid such database failures.
The following illustrates how to use the main functions in the package and these are being run on a 23ai (Free) Database running in Docker. The main functions include FULL and CRITICAL. There are an additional 66 functions which allow you to examine each of the report elements returned in the FULL report.
To run the FULL report
exec dbms_dictionary_check.full
dbms_hcheck on 02-OCT-2023 13:56:39
----------------------------------------------
Catalog Version 23.0.0.0.0 (2300000000)
db_name: FREE
Is CDB?: YES CON_ID: 3 Container: FREEPDB1
Trace File: /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_335_HCHECK.trc
Catalog Fixed
Procedure Name Version Vs Release Timestamp Result
------------------------------ ... ---------- -- ---------- -------------- ------
.- OIDOnObjCol ... 2300000000 <= *All Rel* 10/02 13:56:39 PASS
.- LobNotInObj ... 2300000000 <= *All Rel* 10/02 13:56:40 PASS
.- SourceNotInObj ... 2300000000 <= *All Rel* 10/02 13:56:40 PASS
.- OversizedFiles ... 2300000000 <= *All Rel* 10/02 13:56:40 PASS
.- PoorDefaultStorage ... 2300000000 <= *All Rel* 10/02 13:56:40 PASS
.- PoorStorage ... 2300000000 <= *All Rel* 10/02 13:56:40 PASS
.- TabPartCountMismatch ... 2300000000 <= *All Rel* 10/02 13:56:41 PASS
.- TabComPartObj ... 2300000000 <= *All Rel* 10/02 13:56:41 PASS
.- Mview ... 2300000000 <= *All Rel* 10/02 13:56:41 PASS
.- ValidDir ... 2300000000 <= *All Rel* 10/02 13:56:41 PASS
.- DuplicateDataobj ... 2300000000 <= *All Rel* 10/02 13:56:41 PASS
.- ObjSyn ... 2300000000 <= *All Rel* 10/02 13:56:43 PASS
.- ObjSeq ... 2300000000 <= *All Rel* 10/02 13:56:43 PASS
.- UndoSeg ... 2300000000 <= *All Rel* 10/02 13:56:43 PASS
.- IndexSeg ... 2300000000 <= *All Rel* 10/02 13:56:43 PASS
.- IndexPartitionSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- IndexSubPartitionSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- TableSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- TablePartitionSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- TableSubPartitionSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- PartCol ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- ValidSeg ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- IndPartObj ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- DuplicateBlockUse ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- FetUet ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- Uet0Check ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- SeglessUET ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- ValidInd ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- ValidTab ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- IcolDepCnt ... 2300000000 <= *All Rel* 10/02 13:56:44 PASS
.- ObjIndDobj ... 2300000000 <= *All Rel* 10/02 13:56:45 PASS
.- TrgAfterUpgrade ... 2300000000 <= *All Rel* 10/02 13:56:45 PASS
.- ObjType0 ... 2300000000 <= *All Rel* 10/02 13:56:45 PASS
.- ValidOwner ... 2300000000 <= *All Rel* 10/02 13:56:45 PASS
.- StmtAuditOnCommit ... 2300000000 <= *All Rel* 10/02 13:56:45 PASS
.- PublicObjects ... 2300000000 <= *All Rel* 10/02 13:56:46 PASS
.- SegFreelist ... 2300000000 <= *All Rel* 10/02 13:56:46 PASS
.- ValidDepends ... 2300000000 <= *All Rel* 10/02 13:56:46 PASS
.- CheckDual ... 2300000000 <= *All Rel* 10/02 13:56:47 PASS
.- ObjectNames ... 2300000000 <= *All Rel* 10/02 13:56:47 PASS
.- ChkIotTs ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- NoSegmentIndex ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- NextObject ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- DroppedROTS ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- FilBlkZero ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- DbmsSchemaCopy ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- IdnseqObj ... 2300000000 > 1201000000 10/02 13:56:51 PASS
.- IdnseqSeq ... 2300000000 > 1201000000 10/02 13:56:51 PASS
.- ObjError ... 2300000000 > 1102000000 10/02 13:56:51 PASS
.- ObjNotLob ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- MaxControlfSeq ... 2300000000 <= *All Rel* 10/02 13:56:51 PASS
.- SegNotInDeferredStg ... 2300000000 > 1102000000 10/02 13:56:52 PASS
.- SystemNotRfile1 ... 2300000000 <= *All Rel* 10/02 13:56:52 PASS
.- DictOwnNonDefaultSYSTEM ... 2300000000 <= *All Rel* 10/02 13:56:53 PASS
.- ValidateTrigger ... 2300000000 <= *All Rel* 10/02 13:56:53 PASS
.- ObjNotTrigger ... 2300000000 <= *All Rel* 10/02 13:56:54 PASS
.- InvalidTSMaxSCN ... 2300000000 > 1202000000 10/02 13:56:54 PASS
.- OBJRecycleBin ... 2300000000 <= *All Rel* 10/02 13:56:54 PASS
---------------------------------------
02-OCT-2023 13:56:54 Elapsed: 15 secs
---------------------------------------
Found 0 potential problem(s) and 0 warning(s)
Trace File: /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_335_HCHECK.trcIf you just want to examine the CRITICAL issues you can run
execute dbms_dictionary_check..critical
dbms_hcheck on 02-OCT-2023 14:17:23
----------------------------------------------
Catalog Version 23.0.0.0.0 (2300000000)
db_name: FREE
Is CDB?: YES CON_ID: 3 Container: FREEPDB1
Trace File: /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_335_HCHECK.trc
Catalog Fixed
Procedure Name Version Vs Release Timestamp Result
------------------------------ ... ---------- -- ---------- -------------- ------
.- UndoSeg ... 2300000000 <= *All Rel* 10/02 14:17:23 PASS
.- MaxControlfSeq ... 2300000000 <= *All Rel* 10/02 14:17:23 PASS
.- InvalidTSMaxSCN ... 2300000000 > 1202000000 10/02 14:17:23 PASS
---------------------------------------
02-OCT-2023 14:17:23 Elapsed: 0 secs
---------------------------------------
Found 0 potential problem(s) and 0 warning(s)
Trace File: /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_335_HCHECK.trc
You will notice from the last line of output, in the above examples, the output is also saved on the Database Server in the directory indicated.
Just remember the Warning given earlier in this post, depending on the versions of the database you are using the PL/SQL package can be called DBMS_DICTIONARY_CHECK or DBMS_HCHECK.
SQL:2023 Standard
As of June 2023 the new standard for SQL had been released, by the International Organization for Standards. Although SQL language has been around since the 1970s, this is the 11th release or update to the SQL standard. The first version of the standard was back in 1986 and the base-level standard for all databases was released in 1992 and referred to as SQL-92. That’s more than 30 years ago, and some databases still don’t contain all the base features in that standard, although they aim to achieve this sometime in the future.
| Year | Name | Alias | New Features or Enhancements |
|---|---|---|---|
| 1996 | SQL-86 | SQL-87 | This is the first version of the SQL standard by ANSI. Transactions, CREATE, Read, Update and Delete |
| 1989 | SQL-89 | This version includes minor revisions that added integrity constraints. | |
| 1992 | SQL-92 | SQL2 | This version includes major revisions on the SQL Language. Considered the base version of SQL. Many database systems, including NoSQL databases, use this standard for the base specification language, with varying degrees of implementation. |
| 1999 | SQL:1999 | SQL3 | This version introduces many new features such as regex matching, triggers, object-oriented features, OLAP capabilities and User Defined Types. The BOOLEAN data type was introduced but it took some time for all the major databases to support it. |
| 2003 | SQL:2003 | This version contained minor modifications to SQL:1999. SQL:2003 introduces new features such as window functions, columns with auto-generated values, identity specification and the addition of XML. | |
| 2006 | SQL:2006 | This version defines ways of importing, storing and manipulating XML data. Use of XQuery to query data in XML format. | |
| 2008 | SQL:2008 | This version includes major revisions to the SQL Language. Considered the base version of SQL. Many database systems, including NoSQL databases, use this standard for the base specification language, with varying degrees of implementation. | |
| 2011 | SQL:2011 | This version adds enhancements for window functions and FETCH clause, and Temporal data | |
| 2016 | SQL:2016 | This version adds various functions to work with JSON data and Polymorphic Table functions. | |
| 2019 | SQL:2019 | This version specifies muti-dimensional arrays data type. | |
| 2023 | SQL:2023 | This version contains minor updates to SQL functions to bring them in-line with how databases have implemented them. New JSON updates to include a new JSON data type with simpler dot notation processing. The main new addition to the standard is Property Graph Query (PDQ) which defines ways for the SQL language to represent property graphs and to interact with them. |
The Property Graph Query (PGQ) new features have been added as a new section or part of the standard and can be found labelled as Part-16: Property Graph Queries (SQL/PGQ). You can purchase the document for €191. Or you can read and scroll through the preview here.
For the other SQL updates, these updates were to reflect how the various (mainstream) database vendors (PostgreSQL, MySQL, Oracle, SQL Server, have implemented various functions. The standard is catching up with what is happening across the industry. This can be seen in some of the earlier releases
The following blog posts give a good overview of the SQL changes in the SQL:2023 standard.
Although SQL:2023 has been released there are some discussions about the next release of the standard. Although SQL:PGQ has been introduced, it also looks like (from various reports), some parts of SQL:PGQ were dropped and not included. More work is needed on these elements and will be included in the next release.
Also for the next release, there will be more JSON functionality included, with a particular focus on JSON Schemas. Yes, you read that correctly. There is a realisation that a schema is a good thing and when JSON objects can consist of up to 80% meta-data, a schema will have significant benefits for storage, retrieval and processing.
They are also looking at how to incorporate Streaming data. We can see some examples of this kind of processing in other languages and tools (Spark SQL, etc)
The SQL Standard is still being actively developed and we should see another update in a few years time.
Oracle 23c Free – Developer Release
Oracle 23c if finally available, in the form of Oracle 23c FREE – Developer Release. There was lots of excitement in some parts of the IT community about this release, some of which is to do with people having to wait a while for this release, given 22c was never released due to Covid!
But some caution is needed and reining back on the excitement is needed.

Why? This release isn’t the full bells and whistles full release of 23c Database. There has been several people from Oracle emphasizing the name of this release is Oracle 23c Free – Developer Release. There are a few things to consider with this release. It isn’t a GA (General Available) Release which is due later this year (maybe). Oracle 23c Free – Developer Release is an early release to allow developers to start playing with various developer focused new features. Some people have referred to this as the 23c Beta version 2 release, and this can be seen in the DB header information. It could be viewed in a similar way as the XE releases we had previously. XE was always Free, so we now we have a rename and emphasis of this. These have been many, many organizations using the XE release to build applications. Also the the XE releases were a no cost option, or what most people would like to say, the FREE version.
For the full 23c Database release we will get even more features, but most of these will probably be larger enterprise scale scenarios.
Now it’s time you to go play with 23c Free – Developer Release. Here are some useful links
- Product Release Official Announcement
- Post by Gerald Venzi
- See link for Docker installation below
- VirtualBox Virtual Machine
- You want to do it old school – Download RPM files
- New Features Guide
I’ll be writing posts on some of the more interesting new features and I’ll add the links to those below. I’ll also add some links to post by other people:
- Docker Installation (Intel and Apple Chip)
- 23 Free Virtual Machine
- 23 Free – A Few (New Features) A few Quickies
- JSON Relational Duality – see post by Tim Hall
- more coming soon (see maintained list at https://oralytics.com/23c/)
Annual Look at Database Trends (Jan 2023)
Monitoring trends in the popularity and usage of different Database vendors can be a interesting exercise. The marketing teams from each vendor do an excellent job of promoting their Database, along with the sales teams, developer advocates, and the user communities. Some of these are more active than others and it varies across the Database market on what their choice is for promoting their products. One of the problems with these various types of marketing, is how can be believe what they are saying about how “awesome” their Database is, and then there are some who actively talk about how “rubbish” (or saying something similar) other Databases area. I do wonder how this really works for these people and vendors when to go negative about their competitors. A few months ago I wrote about “What does Legacy Really Mean?“. That post was prompted by someone from one Database Vendor calling their main competitor Database a legacy product. They are just name calling withing providing any proof or evidence to support what they are saying.
Getting back to the topic of this post, I’ve gathered some data and obtained some league tables from some sites. These will help to have a closer look at what is really happening in the Database market throughout 2022. Two popular sites who constantly monitor the wider internet and judge how popular Databases area globally. These sites are DB-Engines and TOPDB Top Database index. These are well know and are frequently cited. Both of these sites give some details of how they calculate their scores, with one focused mainly on how common the Database appears in searches across different search engines, while the other one, in addition to search engine results/searches, also looks across different websites, discussion forms, social media, job vacancies, etc.
The first image below is a comparison of the league tables from DB-Engines taken in January 2022 and January 2023. I’ve divided this image into three sections/boxes. Overall for the first 10 places, not a lot has changed. The ranking scores have moved slightly in most cases but not enough to change their position in the rank. Even with a change of score by 30+ points is a very small change and doesn’t really indicate any great change in the score as these scores are ranked in a manner where, “when system A has twice as large a value in the DB-Engines Ranking as system B, then it is twice as popular when averaged over the individual evaluation criteria“. Using this explanation, Oracle would be twice as popular when compared to PostgreSQL. This is similar across 2022 and 2023.

Next we’ll look a ranking from TOPDB Top Database index. The image below compares January 2022 and January 2023. TOPDB uses a different search space and calculation for its calculation. The rankings from TOPDB do show some changes in the ranks and these are different to those from DB-Engines. Here we see the top three ranks remain the same with some small percentage changes, and nothing to get excited about. In the second box covering ranks 4-7 we do some changes with PostgreSQL improving by two position and MongoDB. These changes do seem to reflect what I’ve been seeing in the marketplace with MongoDB being replaced by PostgreSQL and MySQL, with this multi-model architecture where you can have relational, document, and other data models in the one Database. It’s important to note Oracle and SQL Server also support this. Over the past couple of years there has been a growing awareness of and benefits of having relation and document (and others) data models in the one database. This approach makes sense both for developer productivity, and for data storage and management.

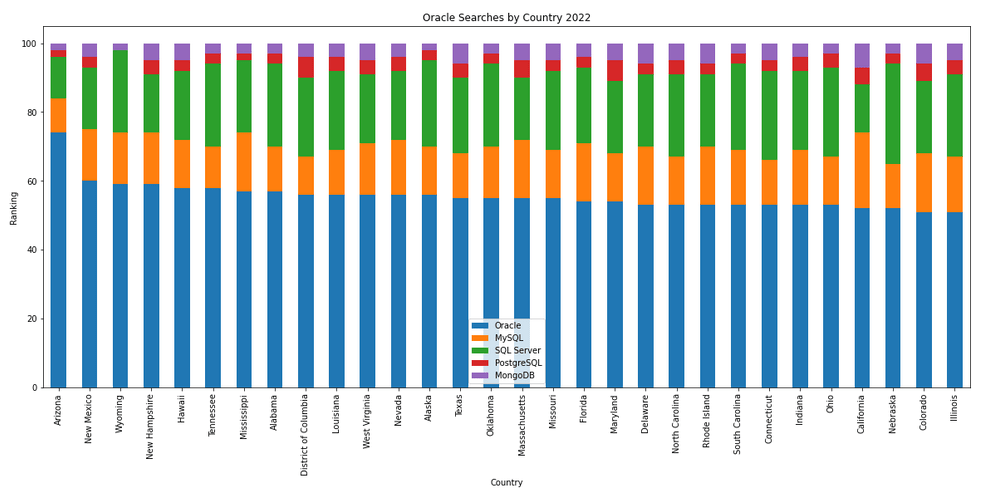
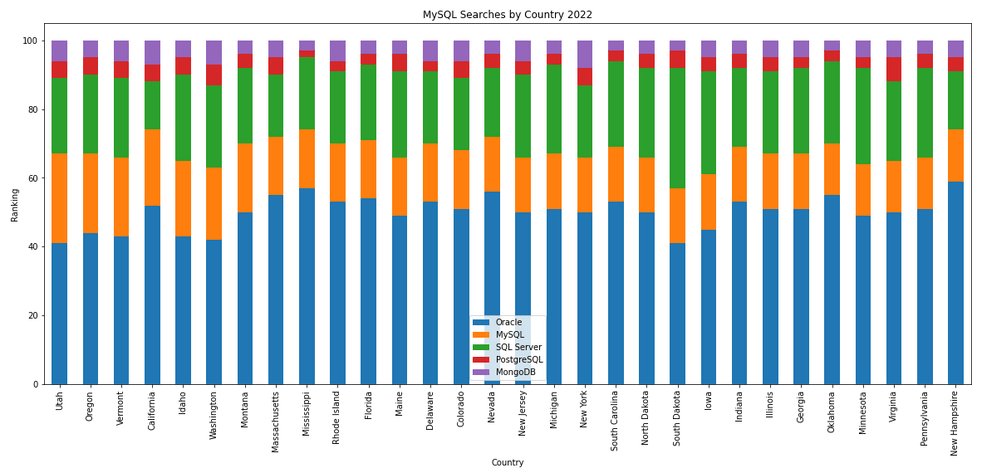
The next gallery of images is based on some Python code I’ve written to look a little bit closer at the top five Databases. In this case these are Oracle, MySQL, SQL Server, PostgreSQL and MongoDB. This gallery plots a bar chart for each Database for their top 15 Counties, and compares them with the other four Databases. The results are interesting and we can see some geographic aspects to the popularity of the Databases.
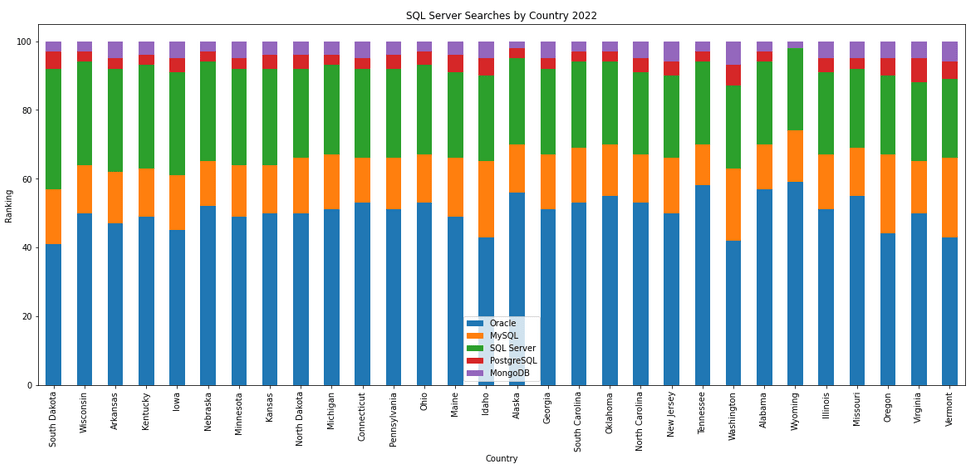
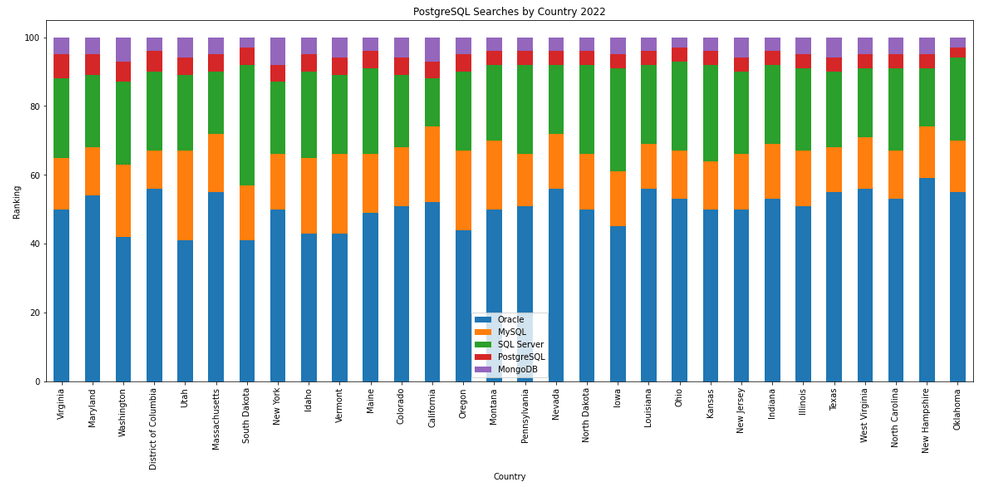
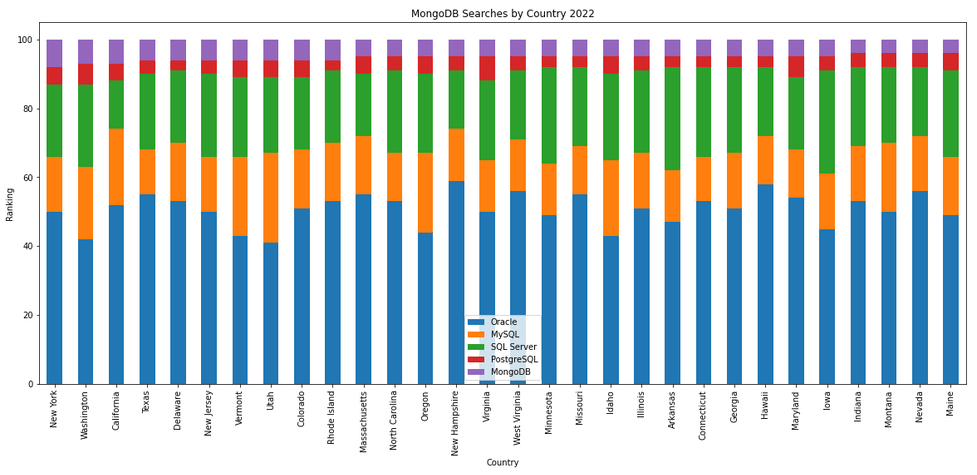
What does Legacy really mean?
In the IT industry we hear the term “legacy” being using, but that does it mean? It can mean a lot of different things and it really depends on the person who is saying it, their context, what they want to portray and their intended meaning. In a lot of cases people seem to use it without knowing the meaning or the impact it can have. This can result in negative impact and not in the way the person intended.
Before looking at some (and there can be lots) possible meanings, lets have a look at what one person said recently.
“Migrating away from legacy databases like Oracle can seem like a daunting undertaking for businesses. But it doesn’t have to be.”
To give context to this quote, the person works for a company selling products, services, support, etc for PostgreSQL and wants everyone to move to ProtgreSQL (Postgres), which is understandable given their role. There’s nothing wrong with trying to convince people/companies to use software that you sell lots of services and additional software to support it. What is interesting is they used the work “legacy”.
Legacy can mean lots of different things to different people. Here are some examples of how legacy is used within the IT industry.
- The product is old and out of date
- The product has no relevancy in software industry today
- Software or hardware that has been superseded
- Any software that has just been released (yes I’ve come across this use)
- Outdated computing software and/or hardware that is still in use. The system still meets the needs it was originally designed for, but doesn’t allow for growth
- Anything in production
- Software that has come to an end of life with no updates, patching and/or no product roadmap
- …
Going back to the quote given above, let’s look a little closer at their intended use. As we can see from the list above the use of the word “legacy” can be used in derogatory way and can try to make one software appear better then it’s old, out of date, not current, hard to use, etc competitor.
If you were to do a side-by-side comparison of PostgreSQL and Oracle, there would be a lot of the same or very similar features. But there are differences too and this, in PostgreSQL case, we see various vendors offering add-on software you can pay for. This is kind of similar with Oracle where you need to license various add-ons, or if you are using a Cloud offering it may come as part of the package. On a features comparison level when these are similar, saying one is “legacy” doesn’t seem right. Maybe its about how old the software is, as in legacy being old software. The first release of Oracle was 1979 and we now get yearly update releases (previously it could be every 2-4 years). PostgresSQL, or its previous names date back to 1974 with the first release of Ingres, which later evolved to Postgres in early 1980s, and took on the new name of PostgreSQL in 1996. Are both products today still the same as what they had in the 1970s, 1980s, 1990s, etc. The simple answer is No, they have both evolved and matured since then. Based on this can we say PostgreSQL is legacy or is more of a Legacy product than Oracle Database which was released in 1979 (5 years after Ingres)? Yes we can.
I’m still very confused by the quote (given above) as to what “legacy” might mean, in their scenario. Apart from and (trying) to ignore the derogatory aspect of “they” are old and out of date, and look at us we are new and better, it is difficult to see what they are trying to achieve.
In a similar example on a LinkedIn discussion where one person said MongoDB was legacy, was a little surprising. MongoDB is very good at what it does and has a small number of use cases. The problem with MongoDB is it is used in scenarios when it shouldn’t be used and just causes too many data architecture problems. For me, the main problem driving these issues is how software engineering and programming is taught in Universities (and other third level institutions). They are focused on JavaScript which makes using MongoDB so so easy. And its’ Agile, and the data model can constantly change. This is great, up until you need to use that data. Then it becomes a nightmare.
Getting back to saying MongoDB is legacy, again comes back to the person saying it. They work at a company who is selling cloud based data engineering and analytic services. Is using cloud services the only thing people should be using? For me it is No but a hybrid cloud and on-premises approach will work based for most. Some of the industry analysts are now promoting this, saying vendors offering both will succeed into the future, where does only offering cloud based services will have limited growth, unless the adapt now.
What about other types legacy software applications. Here is an example Stew Ashton posted on Twitter. “I once had a colleague who argued, in writing, that changing the dev stack had the advantage of forcing a rewrite of “legacy applications” – which he had coded the previous year! Either he thought he had greatly improved, or he wanted guaranteed job security”
There are lots and lots of more examples out there and perhaps you will encounter some when you are attending presentations or sales pitches from various vendors. If you hear, then saying one product is “legacy” get them to define their meaning of it and to give specific examples to illustrate it. Does their meaning match with one from the list given above, or something else. Are they just using the word to make another product appear inferior without knowing the meaning or the differences in the product? Their intended meaning within their context is what defines their meaning, which may be different to yours.
Postgres on Docker
Prostgres is one of the most popular databases out there, being used in Universities, open source projects and also widely used in the corporate marketplace. I’ve written a previous post on running Oracle Database on Docker. This post is similar, as it will show you the few simple steps to have a persistent Postgres Database running on Docker.
The first step is go to Docker Hub and locate the page for Postgres. You should see something like the following. Click through to the Postgres page.

There are lots and lots of possible Postgres images to download and use. The simplest option is to download the latest image using the following command in a command/terminal window. Make sure Docker is running on your machine before running this command.
docker pull postgresAlthough, if you needed to install a previous release, you can do that.

After the docker image has been downloaded, you can now import into Docker and create a container.
docker run --name postgres -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=pgPassword -e POSTGRES_DB=postgres -d postgresImportant: I’m using Docker on a Mac. If you are using Windows, the format of the parameter list is slightly different. For example, remove the = symbol after POSTGRES_DB
If you now check with Docker you’ll see Postgres is now running on post 5432.

Next you will need pgAdmin to connect to the Postgres Database and start working with it. You can download and install it, or run another Docker container with pgAdmin running in it.
First, let’s have a look at installing pgAdmin. Download the image and run, accepting the initial requirements. Just let it run and finish installing.


When pgAdmin starts it looks for you to enter a password. This can be anything really, but one that you want to remember. For example, I set mine to pgPassword.
Then create (or Register) a connection to your Postgres Database. Enter the details you used when creating the docker image including username=postgres, password=pgPassword and IP address=0.0.0.0.
The IP address on your machine might be a little different, and to check what it is, run the following
docker ps -a


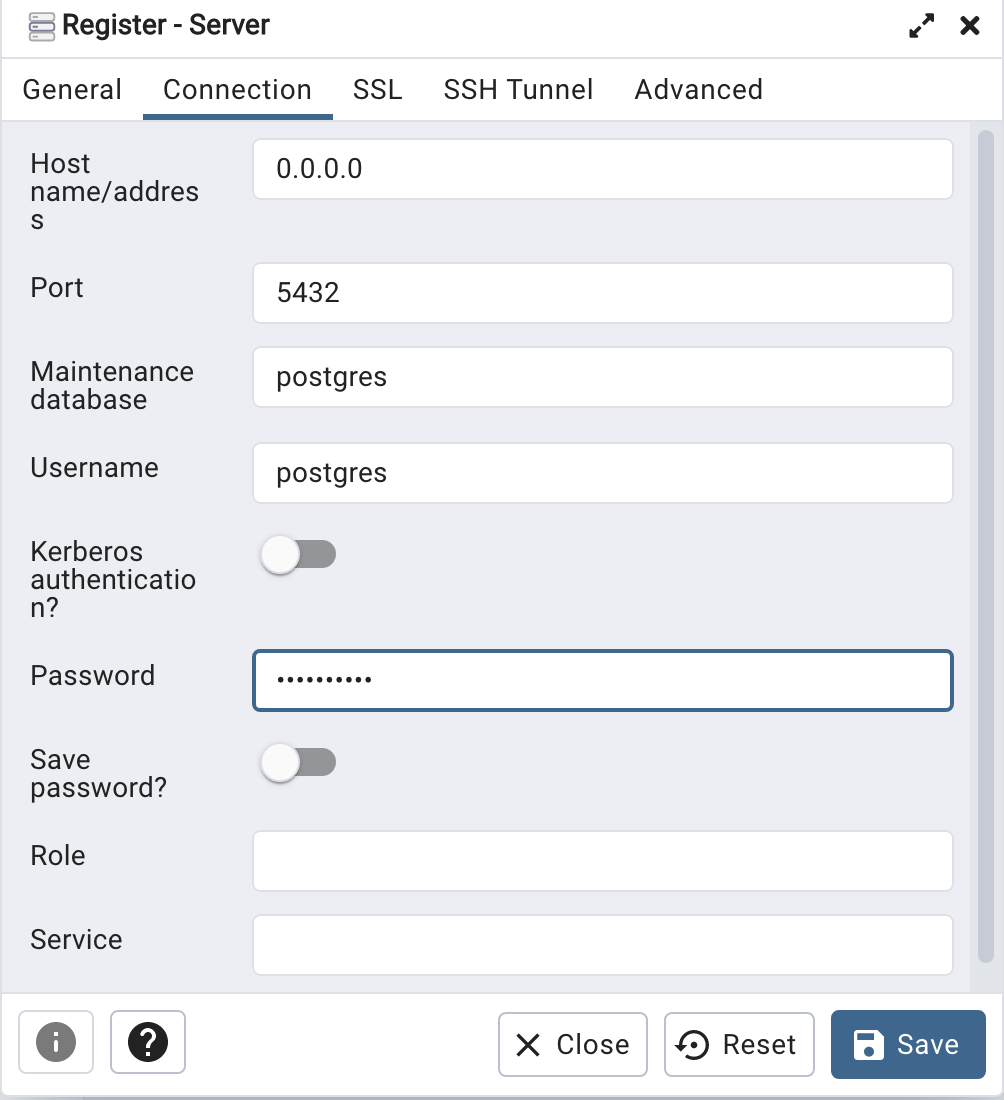
When your (above) connection works, the next step is to create another schema/user in the database. The reason we need to do this is because the user we connected to above (postgres) is an admin user. This user/schema should never be used for database development work.
Let’s setup a user we can use for our development work called ‘student’. To do this, right click on the ‘postgres’ user connection and open the query tool.
Then run the following.

After these two commands have been run successfully we can now create a connection to the postgres database, open the query tool and you’re now all set to write some SQL.

oracledb Python Library – Connect to DB & a few other changes
Oracle have released a new Python library for connecting to Oracle Databases on-premises and on the Cloud. It’s called (very imaginatively, yet very clearly) oracledb. This new Python library replaces the previous library called cx_Oracle. Just consider cx_oracle as obsolete, and use oracledb going forward, as all development work on new features and enhancements will be done to oracledb.
cx_oracle has been around a long time, and it’s about time we have a new and enhanced library that is more flexible and will suit many different deployment scenarios. The previous library (cx_Oracle) was great, but it did require additional software installation with Oracle Client, and some OS environment settings, which at times took a bit of debugging. This makes it difficult/challenging to deploy in different environments, for example IOTs, CI/CD, containers, etc. Deployment environments have changed and the new oracledb library makes it simpler.
To check out the following links for a full list of new features and other details.
Home page: oracle.github.io/python-oracledb
Installation instructions: python-oracledb.readthedocs.io/en/latest/installation.html
Documentation: python-oracledb.readthedocs.io
One of the main differences between the two libraries is how you connect to the Database. With oracledb you need to use named the parameters, and the new library uses a thin connection. If you need the thick connection you can switch to that easily enough.
The following examples will illustrate how to connect to Oracle Database (local and cloud ADW/ATP) and how these are different to using the cx_Oracle library (which needed Oracle Client software installed). Remember the new oracledb library does not need Oracle Client.
To get started, install oracledb.
pip3 install oracledbLocal Database (running in Docker)
To test connection to a local Database I’m using a Docker image of 21c (hence localhost in this example, replace with IP address for your database). Using the previous library (cx_Oracle) you could concatenate the connection details to form a string and pass that to the connection. With oracledb, you need to use named parameters and specify each part of the connection separately.
This example illustrates this simple connection and prints out some useful information about the connection, do we have a healthy connection, are we using thing database connection and what version is the connection library.
p_username = "..."
p_password = "..."
p_dns = "localhost/XEPDB1"
p_port = "1521"
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
print(con.is_healthy())
print(con.thin)
print(con.version)
---
True
True
21.3.0.0.0
Having created the connection we can now query the Database and close the connection.
cur = con.cursor()
cur.execute('select table_name from user_tables')
for row in cur:
print(row)
---
('WHISKIES_DATASET',)
('HOLIDAY',)
('STAGE',)
('DIRECTIONS',)
---
cur.close()
con.close()The code I’ve given above is simple and straight forward. And if you are converting from cx_Oracle, you will probably have minimal changes as you probably had your parameter keywords defined in your code. If not, some simple editing is needed.
To simplify the above code even more, the following does all the same steps without the explicit open and close statements, as these are implicit in this example.
import oracledb
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
with con.cursor() as cursor:
for row in cursor.execute('select table_name from user_tables'):
print(row)(Basic) Oracle Cloud – Autonomous Database, ATP/ADW
Everyone is using the Cloud, Right? If you believe the marketing they are, but in reality most will be working in some hybrid world using a mixture of on-premises and cloud storage. The example given in the previous section illustrated connecting to a local/on-premises database. Let’s now look at connecting to a database on Oracle Cloud (Autonomous Database, ATP/ADW).
With the oracledb library things have been simplified a little. In this section I’ll illustrate a simple connection to a ATP/ADW using a thin connection.
What you need is the location of the directory containing the unzipped wallet file. No Oracle client is needed. If you haven’t downloaded a Wallet file in a while, you should go download a new version of it. The Wallet will contain a pem file which is needed to securely connect to the DB. You’ll also need the password for the Wallet, so talk nicely with your DBA. When setting up the connection you need to provide the directory for the tnsnames.ora file and the ewallet.pem file. If you have downloaded and unzipped the Wallet, these will be in the same directory
import oracledb
p_username = "..."
p_password = "..."
p_walletpass = '...'
#This time we specify the location of the wallet
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high",
config_dir="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_location="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_password=p_walletpass)
print(con)
con.close()This method allows you to easily connect to any Oracle Cloud Database.
(Thick Connection) Oracle Cloud – Autonomous Database, ATP/ADW
If you have Oracle Client already installed and set up, and you want to use a thick connection, you will need to initialize the function init_oracle_client.
import oracledb
p_username = "..."
p_password = "..."
#point to directory containing tnsnames.ora
oracledb.init_oracle_client(config_dir="/Applications/instantclient_19_8/network/admin")
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high")
print(con)
con.close()Warning: Some care is needed with using init_oracle_client. If you use it once in your Python code or App then all connections will use it. You might need to do a code review to look at when this is needed and if not remove all occurrences of it from your Python code.
(Additional Security) Oracle Cloud – Autonomous Database, ATP/ADW
There are a few other additional ways of connecting to a database, but one of my favorite ways to connect involves some additional security, particularly when working with IOT devices, or in scenarios that additional security is needed. Two of these involve using One-way TLS and Mututal TLS connections. The following gives an example of setting up One-Way TLS. This involves setting up the Database to only received data and connections from one particular device via an IP address. This requires you to know the IP address of the device you are using and running the code to connect to the ATP/ADW Database.
To set this up, go to the ATP/ADW details in Oracle Cloud, edit the Access Control List, add the IP address of the client device, disable mutual TLS and download the DB Connection. The following code gives and example of setting up a connection
import oracledb
p_username = "..."
p_password = "..."
adw_dsn = '''(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)
(host=adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=a8rk428ojzuffy_student_high.adb.oraclecloud.com))
(security=(ssl_server_cert_dn="CN=adwc.uscom-east-1.oraclecloud.com,OU=Oracle BMCS US,O=Oracle Corporation,L=Redwood City,ST=California,C=US")))'''
con4 = oracledb.connect(user=p_username, password=p_password, dsn=adw_dsn)This sets up a secure connection between the client device and the Database.
From my initial testing of existing code/applications (although no formal test cases) it does appear the new oracledb library is processing the queries and data quicker than cx_Oracle. This is good and hopefully we will see more improvements with speed in later releases.
Also don’t forget the impact of changing the buffer size for your database connection. This can have a dramatic effect on speeding up your database interactions. Check out this post which illustrates this.

You must be logged in to post a comment.