
Vector Databases – Part 4 – Vector Indexes
In this post on Vector Databases, I’ll explore some of the commonly used indexing techniques available in Databases. I’ll also explore the Vector Indexes available in Oracle 23c. Be sure to check that section towards the end of the post, where I’ll also include links to other articles in this series.
As with most data in a Databases, indexes are used for fast access to data. They create an organised structure (typically B+ tree) for storing the location of certain values within a table. When searching for data, if an index exists on that data, the index will be used for matching and the location of the records is used to quickly retrieve the data.
Similarly, for Vector searches, we need some way to search through thousands or millions of vectors to find those that best match our search criteria (vector search). For vector search, there are many more calculations to perform. We want to avoid a MxN search space.

Given the nature of Vectors and the the type of search performed on these, databases need to have different types of indexes. Common Vector Index types include Hash-base, Tree-based, Graph-base and Inverted-file. Let’s have a look at each of these.

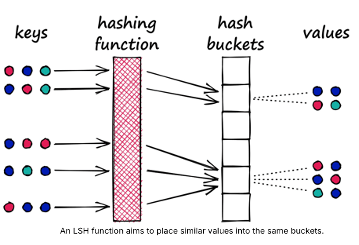
Hash-based Vector Indexes
Locality-Sensitive Hashing (LSH) uses hash functions to bucket similar vectors into a hash table. The query vectors are also hashed using the same hash function and it is compared with the other vectors already present in the table. This method is much faster than doing an exhaustive search across the entire dataset because there are fewer vectors in each hash table than in the whole vector space. While this technique is quite fast, the downside is that it is not very accurate. LSH is an approximate method, so a better hash function will result in a better approximation, but the result will not be the exact answer.
Tree-based Vector Indexes
Tree-based indexing allows for fast searches by using a data structure such as a binary tree. The tree gets created in a way that similar vectors are grouped in the same subtree. Approximate Nearest Neighbour (ANN) uses a forest of binary trees to perform approximate nearest neighbors search. ANN performs well with high-dimension data where doing an exact nearest neighbors search can be expensive. The downside of using this method is that it can take a significant amount of time to build the index. Whenever a new data point is received, the indices cannot be restructured on the fly. The entire index has to be rebuilt from scratch.
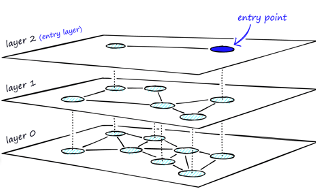
Graph-based Vector Indexes
Similar to tree-based indexing, graph-based indexing groups similar data points by connecting them with an edge. Graph-based indexing is useful when trying to search for vectors in a high-dimensional space. Hierarchical Navigable Small Worlds (HNSW) creates a layered graph with the topmost layer containing the fewest points and the bottom layer containing the most points. When an input query comes in, the topmost layer is searched via ANN. The graph is traversed downward layer by layer. At each layer, the ANN algorithm is run to find the closest point to the input query. Once the bottom layer is hit, the nearest point to the input query is returned. Graph-based indexing is very efficient because it allows one to search through a high-dimensional space by narrowing down the location at each layer. However, re-indexing can be challenging because the entire graph may need to be recreated
Inverted-FIle Vector Indexes
IVF (InVerted File) narrows the search space by partitioning the dataset and creating a centroid(random point) for each partition. The centroids get updated via the K-Means algorithm. Once the index is populated, the ANN algorithm finds the nearest centroid to the input query and only searches through that partition. Although IVF is efficient at searching for similar points once the index is created, the process of creating the partitions and centroids can be quite slow.

Oracle 23ai comes with two main types of indexes for Vectors. These are:
In-Memory – Neighbor Graph Vector Index
Hierarchical Navigable Small World (HNSW) is the only type of In-Memory Neighbor Graph vector index supported. With Navigable Small World (NSW), the idea is to build a proximity graph where each vector in the graph connects to several others based on three characteristics:
- The distance between vectors
- The maximum number of closest vector candidates considered at each step of the search during insertion (EFCONSTRUCTION)
- Within the maximum number of connections (NEIGHBORS) permitted per vector
Navigable Small World (NSW) graph traversal for vector search begins with a predefined entry point in the graph, accessing a cluster of closely related vectors. The search algorithm employs two key lists:
- Candidates, a dynamically updated list of vectors that we encounter while traversing the graph,
- and Results, which contains the vectors closest to the query vector found thus far.
As the search progresses, the algorithm navigates through the graph, continually refining the Candidates by exploring and evaluating vectors that might be closer than those in the Results. The process concludes once there are no vectors in the Candidates closer than the farthest in the Results, indicating

Neighbor Partition Vector Index
Inverted File Flat (IVF) index is the only type of Neighbor Partition vector index supported.
Inverted File Flat Index (IVF Flat or simply IVF) is a partitioned-based index which balance high search quality with reasonable speed.
The IVF index is a technique designed to enhance search efficiency by narrowing the search area through the use of neighbor partitions or clusters.

Here is an example of creating such an index in Oracle 23ai.
CREATE VECTOR INDEX galaxies_ivf_idx ON galaxies (embedding)
ORGANIZATION NEIGHBOR
PARTITIONS DISTANCE COSINE
WITH TARGET ACCURACY 95;
Check out my other posts in this series on Vector Databases.
Vector Databases – Part 3 – Vector Search
Searching semantic similarity in a data set is now equivalent to searching for nearest neighbors in a vector space instead of using traditional keyword searches using query predicates. The distance between “dog” and “wolf” in this vector space is shorter than the distance between “dog” and “kitten”. A “dog” is more similar to a “wolf” than it is to a “kitten”.

Vector data tends to be unevenly distributed and clustered into groups that are semantically related. Doing a similarity search based on a given query vector is equivalent to retrieving the K-nearest vectors to your query vector in your vector space.
Typically, you want to find an ordered list of vectors by ranking them, where the first row in the list is the closest or most similar vector to the query vector, the second row in the list is the second closest vector to the query vector, and so on. When doing a similarity search, the relative order of distances is what really matters rather than the actual distance.

Semantic search where the initial vector is the word “Puppy” and you want to identify the four closest words. Similarity searches tend to get data from one or more clusters depending on the value of the query vector, distance and the fetch size. Approximate searches using vector indexes can limit the searches to specific clusters, whereas exact searches visit vectors across all clusters.
Measuring distances in a vector space is the core of identifying the most relevant results for a given query vector. That process is very different from the well-known keyword filtering in the relational database world, which is very quick, simple and very very efficient. Vector distance functions involve more complicated computations.
There are several ways you can calculate distances to determine how similar, or dissimilar, two vectors are. Each distance metric is computed using different mathematical formulas. The time taken to calculate the distance between two vectors depends on many factors, including the distance metric used as well as the format of the vectors themselves, such as the number of vector dimensions and the vector dimension formats.
Generally, it’s best to match the distance metric you use to the one that was used to train the vector embedding model that generated the vectors. Common Distance metric functions include:
- Euclidean Distance
- Euclidean Distance Squared
- Cosine Similarity [most commonly used]
- Dot Product Similarity
- Manhattan Distance Hamming Similarity
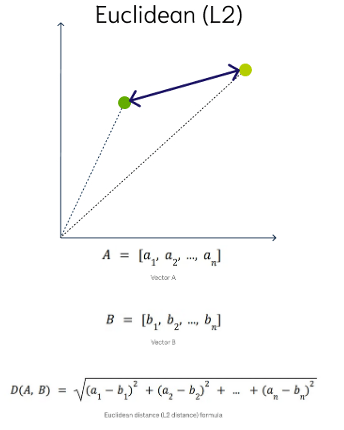
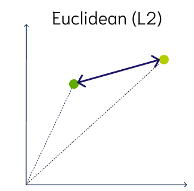
Euclidean Distance
This is a measure of the straight line distance between two points in the vector space. It ranges from 0 to infinity, where 0 represents identical vectors, and larger values represent increasingly dissimilar vectors. This is calculated using the Pythagorean theorem applied to the vector’s coordinates.
This metric is sensitive to both the vector’s size and it’s direction.
Euclidean Distance Squared
This is very similar to Euclidean Distance. When ordering is more important than the distance values themselves, the Squared Euclidean distance is very useful as it is faster to calculate than the Euclidean distance (avoiding the square-root calculation)
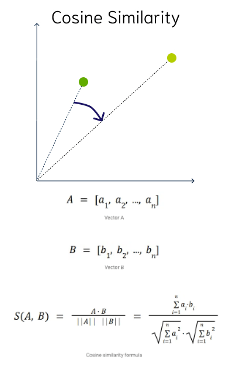
Cosine Similarity
This is the most commonly used distance measure. The cosine of the angle between two vectors – the larger the cosine, the closer the vectors. The smaller the angle, the bigger is its cosine. Cosine similarity measures the similarity in the direction or angle of the vectors, ignoring differences in their size (also called magnitude). The smaller the angle, the more similar are the two vectors. It ranges from -1 to 1, where 1 represents identical vectors, 0 represents orthogonal vectors, and -1 represents vectors that are diametrically opposed
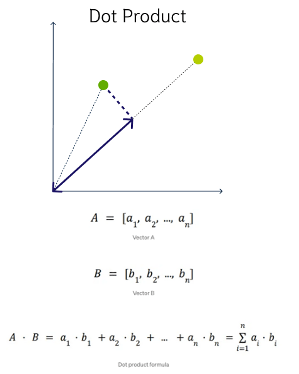
DOT Product Similarity
DOT product similarity of two vectors can be viewed as multiplying the size of each vector by the cosine of their angle. The larger the dot product, the closer the vectors. You project one vector on the other and multiply the resulting vector sizes. Larger DOT product values imply that the vectors are more similar, while smaller values imply that they are less similar. It ranges from -∞ to ∞, where a positive value represents vectors that point in the same direction, 0 represents orthogonal vectors, and a negative value represents vectors that point in opposite directions
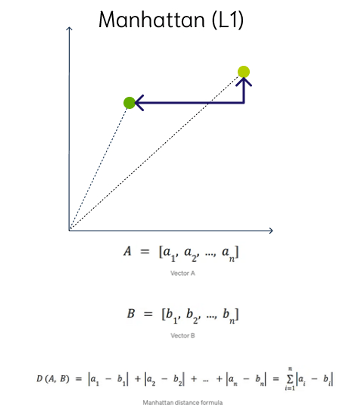
Manhattan Distance
This is calculated by summing the distance between the dimensions of the two vectors that you want to compare.
Imagine yourself in the streets of Manhattan trying to go from point A to point B. A straight line is not possible.
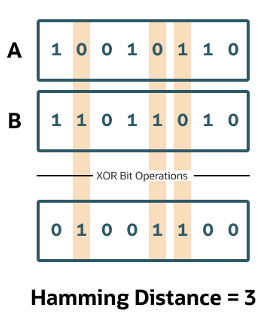
Hamming Similarity
This is the distance between two vectors represented by the number of dimensions where they differ. When using binary vectors, the Hamming distance between two vectors is the number of bits you must change to change one vector into the other. To compute the Hamming distance between two vectors, you need to compare the position of each bit in the sequence.
Check out my other posts in this series on Vector Databases.
Vector Databases – Part 2
In this post on Vector Databases, I’ll look at the main components:
- Vector Embedding Models. What they do and what they create.
- Vectors. What they represent, and why they have different sizes.
- Vector Search. An overview of what a Vector Search will do. A more detailed version of this is in a separate post.
- Vector Search Process. It’s a multi-step process and some care is needed.

Vector Embedding Models
A vector embedding model is a type of machine learning model that transforms data into vectors (embeddings) in a high-dimensional space. These embeddings capture the semantic or contextual relationships between the data points, making them useful for tasks such as similarity search, clustering, and classification.
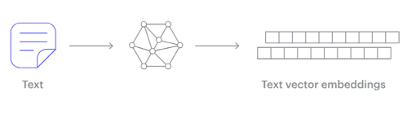
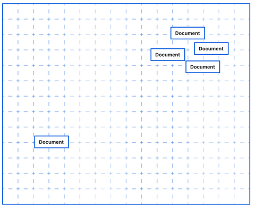
Embedding models are trained to convert the input data point (text, video, image, etc) into a vector (a series of numeric values). The model aims to identify semantic similarity with the input and map these to N-dimensional space. For example, the words “car” and “vehicle” have very different spelling but are semantically similar. The embedding model should map this to have similar vectors. Similarly with documents. The embedding model will map the documents to be able to group similar documents together (in N-dimensional space).
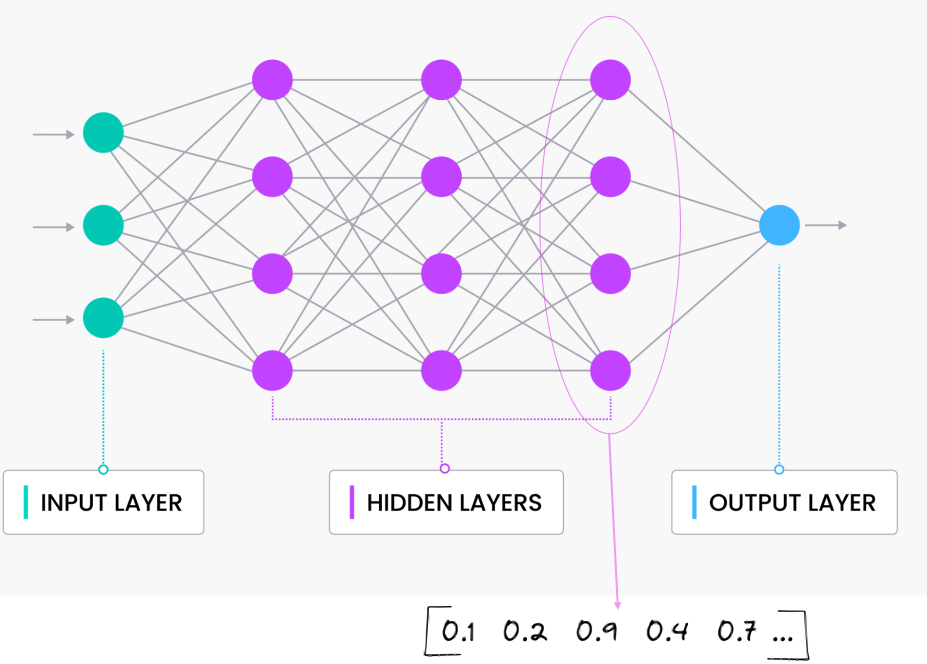
An embedding model is typically a Neural Network (NN) model. There are many different embedding models available from various vendor such as OpenAI, Cohere, etc., or you can build your own. Some models are open source and some are available for a fee. Typically, the output from the embedding model (the Vector) come from the last layer of the neural network
Vectors
A Vector is a sequence of numbers, called dimensions, used to capture the important “features” or “characteristics” of a piece of data. A vector is a mathematical object that has both magnitude (length) and direction. In the context of mathematics and physics, a vector is typically represented as an arrow pointing from one point to another in space, or as a list of numbers (coordinates) that define its position in a particular space.
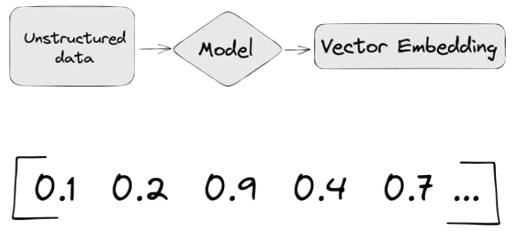
Different Embedding Models create different numbers of Dimensions. Size is important with vectors as the greater the number number of dimensions the larger the Vector. The larger the number of dimensions the better the semantic similarity matches will be. As Vector size increases, so does space required to store them (not really a problem for Databases, but at Big Data scale it can be a challenge)
As vector size increases so does the Index space, and correspondingly search time can increase as the number of calculations for Distance Measure increases. There are various Vector indexes available to help with this (see my post covering this topic)
Basically, a vector is an array of numbers, where each number represents a dimension. It is easy for us to comprehend and visualise 2 dimensions. Here is an example of using 2 dimensions to represent different types of vehicles. The vectors give us a way to map or chart the data.
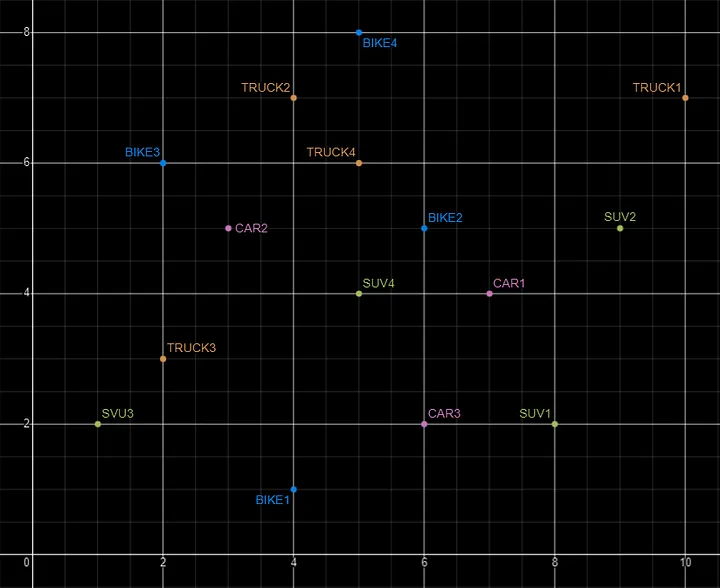
Here is SQL code for this data. I’ll come back to this data in the section on Vector Search.
INSERT INTO PARKING_LOT VALUES('CAR1','[7,4]');
INSERT INTO PARKING_LOT VALUES('CAR2','[3,5]');
INSERT INTO PARKING_LOT VALUES('CAR3','[6,2]');
INSERT INTO PARKING_LOT VALUES('TRUCK1','[10,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK2','[4,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK3','[2,3]');
INSERT INTO PARKING_LOT VALUES('TRUCK4','[5,6]');
INSERT INTO PARKING_LOT VALUES('BIKE1','[4,1]');
INSERT INTO PARKING_LOT VALUES('BIKE2','[6,5]');
INSERT INTO PARKING_LOT VALUES('BIKE3','[2,6]');
INSERT INTO PARKING_LOT VALUES('BIKE4','[5,8]');
INSERT INTO PARKING_LOT VALUES('SUV1','[8,2]');
INSERT INTO PARKING_LOT VALUES('SUV2','[9,5]');
INSERT INTO PARKING_LOT VALUES('SUV3','[1,2]');
INSERT INTO PARKING_LOT VALUES('SUV4','[5,4]');The vectors created by the embedding models can have a different number of dimensions. Common Dimension Sizes are:
- 100-Dimensional: Often used in older or simpler models like some configurations of Word2Vec and GloVe. Suitable for tasks where computational efficiency is a priority and the context isn’t highly complex.
- 300-Dimensional: A common choice for many word embeddings (e.g., Word2Vec, GloVe). Strikes a balance between capturing sufficient detail and computational feasibility.
- 512-Dimensional: Used in some transformer models and sentence embeddings. Offers a richer representation than 300-dimensional embeddings.
- 768-Dimensional: Standard for BERT base models and many other transformer-based models. Provides detailed and contextual embeddings suitable for complex tasks.
- 1024-Dimensional: Used in larger transformer models (e.g., GPT-2 large). Provides even more detail but requires more computational resources.
Many of the newer embedding models have >3000 dimensions!
- Cohere’s embedding model embed-english-v3.0 has 1024 dimensions.
- OpenAI’s embedding model text-embedding-3-large has 3072 dimensions.
- Hugging Face’s embedding model all-MiniLM-L6-v2 has 384 dimensions
Here is a blog post listing some of the embedding models supported by Oracle Vector Search.
Vector Search
Vector search is a method of retrieving data by comparing high-dimensional vector representations (embeddings) of items rather than using traditional keyword or exact-match queries. This technique is commonly used in applications that involve similarity search, where the goal is to find items that are most similar to a given query based on their vector representations.
For example, using the vehicle data given above, we can easily visualise the search for similar vehicles. If we took “CAR1” as our initiating data point and wanted to know what other vehicles are similar to it. Vector Search looks at the distance between “CAR1” and all other vehicles in the 2-dimensional space.
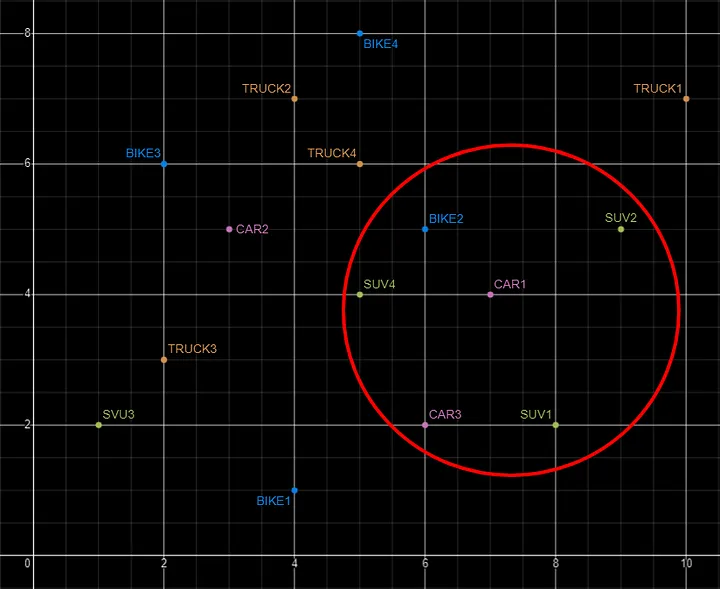
Vector Search becomes a bit more of a challenge when we have 1000+ dimensions, requiring advanced distance algorithms. I’ll have more on these in the next post.
Vector Search Process
The Vector Search process is divided into two parts.
The first part involved creating Vectors for your existing data and for any new data generated and needs to be stored. This data can be used for Semantic Similarity searches (part two of the process). The first part of the process takes your data, applies a vector embedding model to it, generates the vectors and stores them in your Database. When the vectors are stored, Vector Indexes can be created.
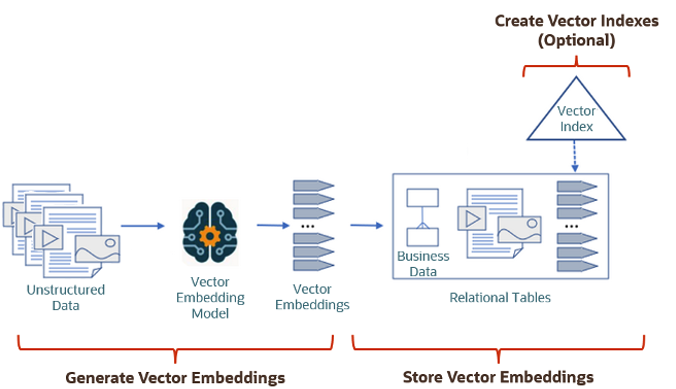
The second part if the process involves Vector Search. This involves having some data you want to search on (e.g. “CARS1” in the previous example). This data will need to be passed to the Vector Embedding model. A Vector for this data is generated. The Vector Search will use this vector to compare to all other vectors in the Database. The results returned will be those vectors (and their corresponding data) that closely match the vector being searched.
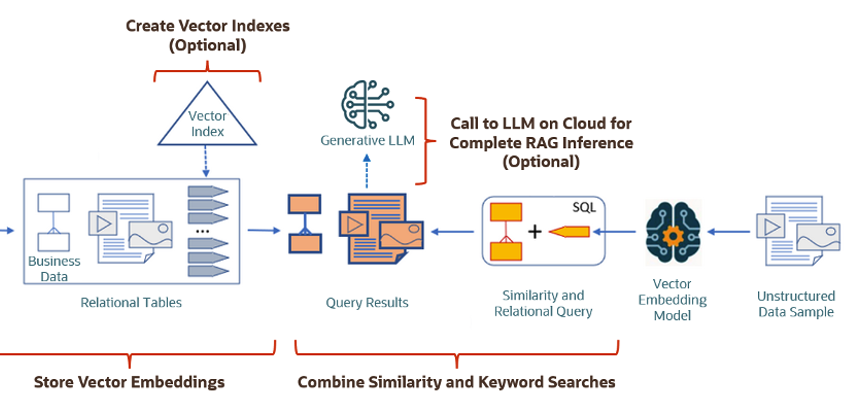
Check out my other posts in this series on Vector Databases.
Using OpenAI to Generate Vector Embeddings
In a recent post, I demonstrated how you could use Cohere to generate Vector Embeddings. Despite having upgraded to a Production API (i.e. a paid one), the experience and time taken to process a relatively small dataset was underwhelming. The result was Cohere wasn’t up to the job of generating Vector Embeddings for the dataset, never mind a few hundred records of that dataset.
This post explores using OpenAI to perform the same task.
First thing is to install the OpenAI python library
pip install openaiNext, you need to create an account with OpenAI. This will allow you to get an API key. OpenAI gives you greater access to and usage of their algorithms than Cohere. Their response times are quicker and you have to lots before any rate limiting might kick in.
Using the same Wine Reviews dataset, the following code processes the data in the same/similar using the OpenAI embedding models. OpenAI has three text embedding models and these create vector embeddings with up to 1536 dimensions, or if you use the large model it will have 3072 dimensions. However, with these OpenAI Embedding models, you can specify a small number of dimensions, which gives you flexibility based on your datasets and the problems being addressed. It also allows you to be more careful with the space allocation for the vector embeddings and the vector indexes created on these.
One other setup you need to do to use the OpenAI API is to create a local environment variable. You can do this at the terminal level, or set/define it in your Python code, as shown below.
import openai
import os
import numpy as np
import os
import time
import pandas as pd
print_every = 200
num_records = 10000
#define your OpenAI API Key
os.environ["OPENAI_API_KEY"] = "... Your OpenAI API Key ..."
client = openai.OpenAI()
#load file into pandas DF
data_file = '.../winemag-data-130k-v2.csv'
df = pd.read_csv(data_file)
#define the outfile name
print("Input file :", data_file)
v_file = os.path.splitext(data_file)[0]+'.openai'
print(v_file)
#Open file with write (over-writes previous file)
f=open(v_file,"w")
f.write("delete from WINE_REVIEWS_130K;\n")
for index,row in df.head(num_records).iterrows():
response = client.embeddings.create(
model = "text-embedding-3-large",
input = row['description'],
dimensions = 100
)
v_embedding = str(response.data[0].embedding)
tab_insert="INSERT into WINE_REVIEWS_130K VALUES ("+str(row["Seq"])+"," \
+"'"+str(row["country"])+"'," \
+"'"+str(row["description"])+"'," \
+"'"+str(row["designation"])+"'," \
+str(row["points"])+"," \
+str(row["price"])+"," \
+"'"+str(row["province"])+"'," \
+"'"+str(row["region_1"])+"'," \
+"'"+str(row["region_2"])+"'," \
+"'"+str(row["taster_name"])+"'," \
+"'"+str(row["taster_twitter_handle"])+"'," \
+"'"+str(row["title"])+"'," \
+"'"+str(row["variety"])+"'," \
+"'"+str(row["winery"])+"'," \
+"'"+v_embedding+"'"+");\n"
# print(tab_insert)
f.write(tab_insert)
if (index%print_every == 0):
print(f'Processed {index} vectors ', time.strftime("%H:%M:%S", time.localtime()))
#Close vector file
f.write("commit;\n")
f.close()
print(f"Finished writing file with Vector data [{index+1} vectors]", time.strftime("%H:%M:%S", time.localtime()))
That’s it. You can now run the script file to populate the table in your Database.
I mentioned above in in my previous post about using Cohere for this task. Yes there were some issues when using Cohere but for OpenAI everything ran very smoothly and was much. quicker too. I did encounter some rate limiting with OpenAI when I tried to processs more than ten thousand records. But the code did eventually complete.
Here is an example of the output from one of my tests.

Vector Databases – Part 1
A Vector Database is a specialized database designed to efficiently store, search, and retrieve high-dimensional vectors, which are often used to represent complex data like images, text, or audio. Vector Databases handle the growing need for managing unstructured and semi-structured data generated by AI models, particularly in applications such as recommendation systems, similarity search, and natural language processing. By enabling fast and scalable operations on vector embeddings, vector databases play a crucial role in unlocking the power of modern AI and machine learning applications.

While traditional Databases are very efficient with storing, processing and searching structured data, but over the past 10+ years they have expanded to include many of the typical NoSQL Database features. This allows ‘modern’ multi-model Databases to be capable of processing structured, semi-structured and unstructured data all within a single Database. Such NoSQL capabilities now available in ‘modern’ multi-model Databases include unstructured data, dynamic models, columnar data, in-memory data, distributed data, big data volumes, high performance, graph data processing, spatial data, documents, streaming, machine learning, artificial intelligence, etc. That is a long list of features and I haven’t listed everything. As new data processing paradigms emerge, they are evaluated and businesses identify the usefulness or not of each. If the new data processing paradigms are determined to be useful, apart from some niche use cases, these capabilities are integrated by the vendors of these ‘modern’ multi-model Database vendors. We have seen similar happen with Vector Databases over the past year or so. Yes Vector Databases have existed for many years but we now have the likes of Oracle, PostgreSQL, MySQL, SQL Server and even DB2 including Vector Embedding and Search.

Vector databases are specifically designed to store and search high-dimensional vector embeddings, which are generated by machine learning models. Here are some key use cases for vector databases:
1. Similarity Search:
- Image Search: Vector databases can be used to perform image similarity searches. For example, e-commerce platforms can allow users to search for products by uploading an image, and the system finds visually similar items using image embeddings.
- Document Search: In NLP (Natural Language Processing) tasks, vector databases help find semantically similar documents or text snippets by comparing their embeddings.
2. Recommendation Systems:
- Product Recommendations: Vector databases enable personalized product recommendations by comparing user and item embeddings to suggest items that are similar to a user’s past interactions or preferences.
- Content Recommendation: For media platforms (e.g., video streaming or news), vector databases power recommendation engines by finding content that matches the user’s interests based on embeddings of past behavior and content characteristics.
3. Natural Language Processing (NLP):
- Semantic Search: Vector databases are used in semantic search engines that understand the meaning behind a query, rather than just matching keywords. This is useful for applications like customer support or knowledge bases, where users may phrase questions in various ways.
- Question-Answering Systems: Vector databases can be employed to match user queries with relevant answers by comparing their vector representations, improving the accuracy and relevance of responses.
4. Anomaly Detection:
- Fraud Detection: In financial services, vector databases help detect anomalies or potential fraud by comparing transaction embeddings with a normal behavior profile.
- Security: Vector databases can be used to identify unusual patterns in network traffic or user behavior by comparing embeddings of normal activity to detect security threats.
5. Audio and Video Processing:
- Audio Search: Vector databases allow users to search for similar audio files or songs by comparing audio embeddings, which capture the characteristics of sound.
- Video Recommendation and Search: Embeddings of video content can be stored and queried in a vector database, enabling more accurate content discovery and recommendation in streaming platforms.
6. Geospatial Applications:
- Location-Based Services: Vector databases can store embeddings of geographical locations, enabling applications like nearest-neighbor search for finding the closest points of interest or users in a given area.
- Spatial Queries: Vector databases can be used in applications where spatial relationships matter, such as in logistics and supply chain management, where efficient searching of locations is crucial.
7. Biometric Identification:
- Face Recognition: Vector databases store face embeddings, allowing systems to compare and identify faces for authentication or security purposes.
- Fingerprint and Iris Matching: Similar to face recognition, vector databases can store and search biometric data like fingerprints or iris scans by comparing vector representations.
8. Drug Discovery and Genomics:
- Molecular Similarity Search: In the pharmaceutical industry, vector databases can help in searching for chemical compounds that are structurally similar to known drugs, aiding in drug discovery processes.
- Genomic Data Analysis: Vector databases can store and search genomic sequences, enabling fast comparison and clustering for research and personalized medicine.
9. Customer Support and Chatbots:
- Intelligent Response Systems: Vector databases can be used to store and retrieve relevant answers from a knowledge base by comparing user queries with stored embeddings, enabling more intelligent and context-aware responses in chatbots.
10. Social Media and Networking:
- User Matching: Social networking platforms can use vector databases to match users with similar interests, friends, or content, enhancing the user experience through better connections and content discovery.
- Content Moderation: Vector databases help in identifying and filtering out inappropriate content by comparing content embeddings with known examples of undesirable content.
These use cases highlight the versatility of vector databases in handling various applications that rely on similarity search, pattern recognition, and large-scale data processing in AI and machine learning environments.
This post is the first in a series on Vector Databases. Some will be background details and some will be technical examples using Oracle Database. I’ll post links to the following posts below as they are published.
2024 Leaving Certificate Results – Inline
The 2024 Leaving Certificate results are out. Up, down and across the country there have been tears of joy and some muted celebrations. But there have been some disappointments too. Although the government has been talking about how the marks have been increased, with post mark adjustments, this doesn’t help students come to terms with their results.
In previous years, I’ve looked at the profile of marks across some (not all) of the Leaving Certificate tools (the tools I used included an Oracle Database, and used Oracle Analytics Cloud to do some of the analysis along with other tools). Check out these previous posts
- Leaving Certificate 2023 – Inline or more adjustments
- CAO Points 2023
- Leaving Certificate 2022 – Inflation, deflation or in-line
- CAO Points 2022
From analysing the results for 2024, both numerically and graphically, we can see the results this year are broadly inline with last year. That news might bring some joy to some students but will be slightly disappointing for others. You can see this for yourself from the graphics below. However, in some subjects, there appears to be some minor (yes very minor) changes in the profiles, with a slight shift to the left, indicating a slight decrease in the higher grades and a corresponding increase in lower grades. But across many subjects, we have seen a slight increase in those achieving a H1 grade. The impact of these slight changes will be seen in the CAO points needed for the courses in the 550+ courses. But for the courses below 500 points, we might not see much of a change in CAO points. Although there might be some minor fluctuations based on demand for certain courses, which is typical most years.
I’ll have another post looking at the CAO points after they are released, so look out for that post.
The charts below give the profile of marks for each year between 2019 (pre-Covid) and 2024. The chart on the left includes all years, and the chart on the right is for the last four years. This allows us to see if there have been any adjustments in the profiles over those years. For most subjects, we can see a marked reduction of marks for certain subjects since the 2021 exceptionally high marks. While some subjects are almost back to matching the 2019 profile (science subjects, Irish), for others the stepback needed is small. Based on the messaging from the government, the stepping back will commence in 2025
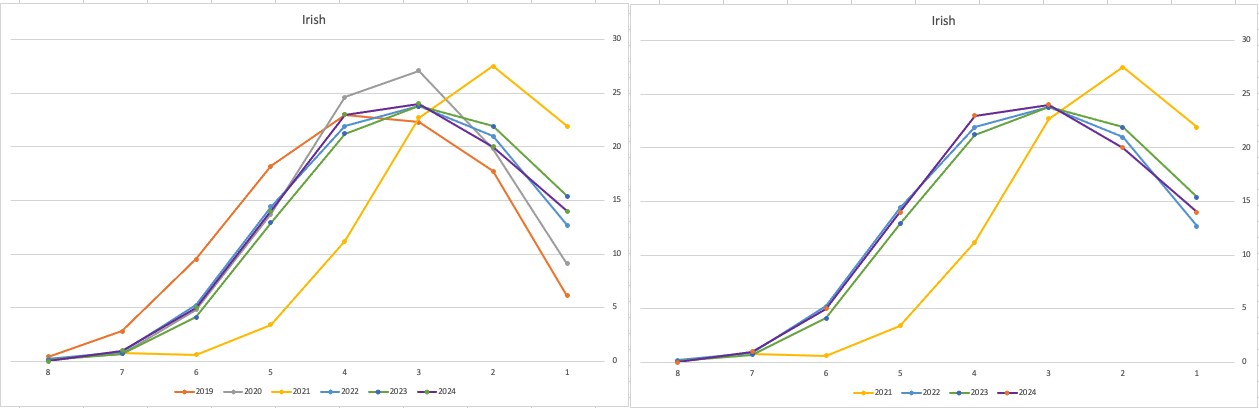
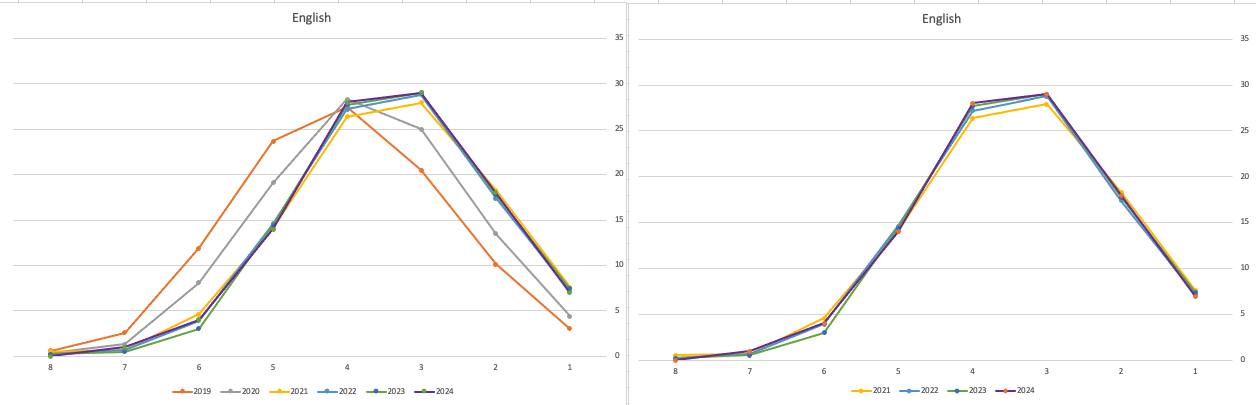
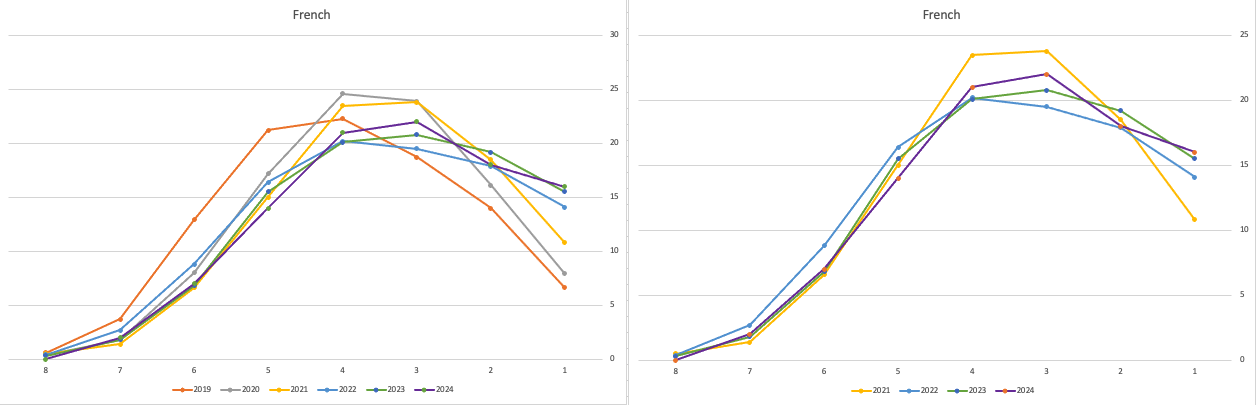
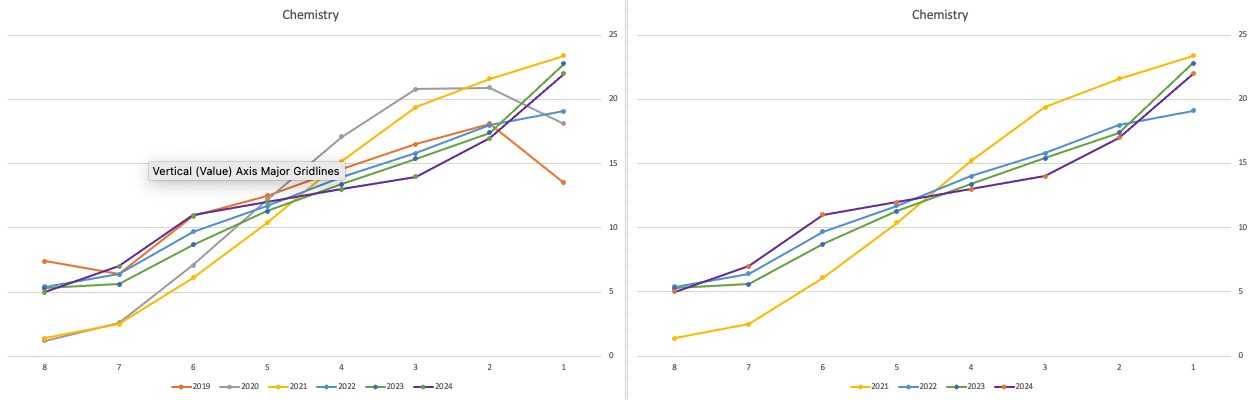
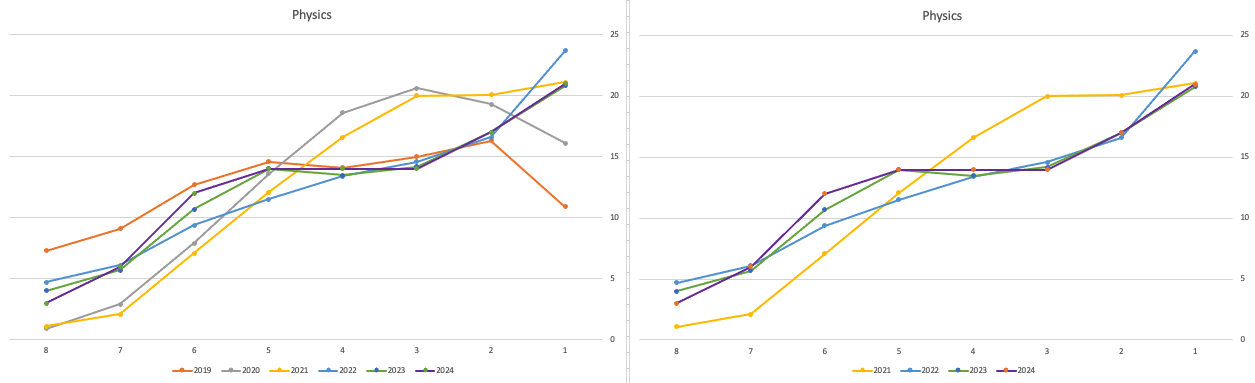
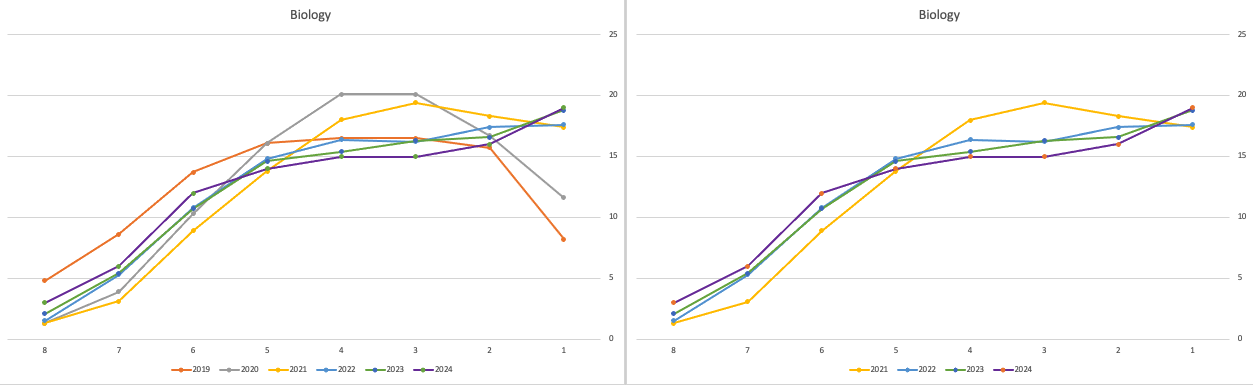
Back in April, an Irish Times article discussed the changes coming from 2025, where there will be a gradual return to “normal” (pre-Covid) profile of marks. Looking at the profile of marks over the past couple of years we can clearly see there has been some stepping back in the profile of marks. Some subjects are back to pre-Covid 2019 profiles. In some subjects, this is more evident than in others. They’ve used the phrase “on aggregate” to hide the stepping back in some subjects and less so in others.
Using Cohere to Generate Vector Embeddings
When using Vector Databases or Vector Embedding features in most (modern, multi-model) Databases, you can gain additional insights. The Vector Embeddings can be utilised for semantic searches, where you can find related data or information based on the values of the Vectors. One of the challenges is generating suitable vectors. There are a lot of options available for generating these Vector Embeddings. In this post, I’ll illustrate how to generate these using Cohere, and in a future post, I’ll illustrate using OpenAI. There are advantages and disadvantages to using these solutions. I’ll point out some of these for each solution (Cohere and OpenAI), using their Python API library.
The first step is to install the Cohere Python library
pip install cohereNext, you need to create an account with Cohere. This will allow you to get an API key. You can get a Trial API key, but you will be restricted to the number of calls you are allowed. As with most free or trial keys these allow you to do a limited number of calls. This is commonly referred to as Rate Limiting. The trial key for the embedding models allows you to have up to 40 calls per minute. This is very very limited and each call is very slow. (I’ll discuss related issues about OpenAI rate limiting in another post)
The dataset I’ll be using is the Wine Reviews 130K (dropbox link). This is widely available on many sites. I want to create Vector Embeddings for the ‘Description’ field in this dataset which contains a review of each wine. There are some columns with no values, and these need to be handled. For each wine review, I’ll create a SQL INSERT statement and print this out to a file. This file will contain an INSERT statement for each wine review, including the vector embedding.
Here’s the code, (you’ll need to enter an API key and change the directory for the data file)
import numpy as np
import os
import time
import pandas as pd
import cohere
co = cohere.Client(api_key="...")
data_file = ".../VectorDatabase/winemag-data-130k-v2.csv"
df = pd.read_csv(data_file)
print_every = 200
rate_limit = 1000 #Cohere limits to 40 API calls per minute
print("Input file :", data_file)
v_file = os.path.splitext(data_file)[0]+'.cohere'
print(v_file)
#Open file with write (over-writes previous file)
f=open(v_file,"w")
for index,row in df.head(rate_limit).iterrows():
phrases=list(row['description'])
model="embed-english-v3.0"
input_type="search_query"
#####
res = co.embed(texts=phrases,
model=model,
input_type=input_type) #,
# embedding_types=['float'])
v_embedding = str(res.embeddings[0])
tab_insert="INSERT into WINE_REVIEWS_130K VALUES ("+str(row["Seq"])+"," \
+'"'+str(row["description"])+'",' \
+'"'+str(row["designation"])+'",' \
+str(row["points"])+"," \
+'"'+str(row["province"])+'",' \
+str(row["price"])+"," \
+'"'+str(row["region_1"])+'",' \
+'"'+str(row["region_2"])+'",' \
+'"'+str(row["taster_name"])+'",' \
+'"'+str(row["taster_twitter_handle"])+'",' \
+'"'+str(row["title"])+'",' \
+'"'+str(row["variety"])+'",' \
+'"'+str(row["winery"])+'",' \
+"'"+v_embedding+"'"+");\n"
f.write(tab_insert)
if (index%print_every == 0):
print(f'Processed {index} vectors ', time.strftime("%H:%M:%S", time.localtime()))
#Close vector file
f.close()
print(f"Finished writing file with Vector data [{index+1} vectors]", time.strftime("%H:%M:%S", time.localtime()))The vector generated has 1024 dimensions. At this time there isn’t a parameter to change/reduce the number of dimensions.
The output file can now be run in your database, assuming you’ve created a table called WINE_REVIEWS_130K and has a column with the appropriate data type (e.g. VECTOR)
Warnings: When using the Cohere API you are limited to maximum of 40 calls per minute. I’ve found this to be incorrect and it was more like 38 calls (for me). I also found the ‘per minute’ to be incorrect. I had to wait several minutes and up to five minutes before I could attempt another run.
In an attempt to overcome this, I create a production API key. This involved giving some payment details, and this in theory should remove the ‘per minute’ rate limit, among other things. Unfortunately, for me this was not a good experience, as I had to make multiple attempts to run for 1000 records before I could have a successful outcome. I experienced multiple Server 500 errors and other errors that related to Cohere server problems.
I wasn’t able to process more that 600 records before the errors occurred and I wasn’t able to generate for a larger percentage of the dataset.
An additional issue is with the response time from Cohere. It was taking approx. 5 minutes to process 200 API calls.
So overall a rather poor experience. I then switched to OpenAI and had a slightly different experience. Check out that post for more details.
EU AI Act: Key Dates and Impact on AI Developers
The official text of the EU AI Act has been published in the EU Journal. This is another landmark point for the EU AI Act, as these regulations are set to enter into force on 1st August 2024. If you haven’t started your preparations for this, you really need to start now. See the timeline for the different stages of the EU AI Act below.
The EU AI Act is a landmark piece of legislation and similar legislation is being drafted/enacted in various geographic regions around the world. The EU AI Act is considered the most extensive legal framework for AI developers, deployers, importers, etc and aims to ensure AI systems introduced or currently being used in the EU internal market (even if they are developed and located outside of the EU) are secure, compliant with existing and new laws on fundamental rights and align with EU principles.
The key dates are:
- 2 February 2025: Prohibitions on Unacceptable Risk AI
- 2 August 2025: Obligations come into effect for providers of general purpose AI models. Appointment of member state competent authorities. Annual Commission review of and possible legislative amendments to the list of prohibited AI.
- 2 February 2026: Commission implements act on post market monitoring
- 2 August 2026: Obligations go into effect for high-risk AI systems specifically listed in Annex III, including systems in biometrics, critical infrastructure, education, employment, access to essential public services, law enforcement, immigration and administration of justice. Member states to have implemented rules on penalties, including administrative fines. Member state authorities to have established at least one operational AI regulatory sandbox. Commission review, and possible amendment of, the list of high-risk AI systems.
- 2 August 2027: Obligations go into effect for high-risk AI systems not prescribed in Annex III but intended to be used as a safety component of a product. Obligations go into effect for high-risk AI systems in which the AI itself is a product and the product is required to undergo a third-party conformity assessment under existing specific EU laws, for example, toys, radio equipment, in vitro diagnostic medical devices, civil aviation security and agricultural vehicles.
- By End of 2030: Obligations go into effect for certain AI systems that are components of the large-scale information technology systems established by EU law in the areas of freedom, security and justice, such as the Schengen Information System.
Here is the link to the official text in the EU Journal publication.

Select AI – OpenAI changes
A few weeks ago I wrote a few blog posts about using SelectAI. These illustrated integrating and using Cohere and OpenAI with SQL commands in your Oracle Cloud Database. See these links below.
- SelectAI – the beginning of a journey
- SelectAI – Doing something useful
- SelectAI – Can metadata help
- SelectAI – the APEX version
With the constantly changing world of APIs, has impacted the steps I outlined in those posts, particularly if you are using the OpenAI APIs. Two things have changed since writing those posts a few weeks ago. The first is with creating the OpenAI API keys. When creating a new key you need to define a project. For now, just select ‘Default Project’. This is a minor change, but it has caused some confusion for those following my steps in this blog post. I’ve updated that post to reflect the current setup in defining a new key in OpenAI. This is a minor change, oh and remember to put a few dollars into your OpenAI account for your key to work. I put an initial $10 into my account and a few minutes later API key for me from my Oracle (OCI) Database.
The second change is related to how the OpenAI API is called from Oracle (OCI) Databases. The API is now expecting a model name. From talking to the Oracle PMs, they will be implementing a fix in their Cloud Databases where the default model will be ‘gpt-3.5-turbo’, but in the meantime, you have to explicitly define the model when creating your OpenAI profile.
BEGIN
--DBMS_CLOUD_AI.drop_profile(profile_name => 'COHERE_AI');
DBMS_CLOUD_AI.create_profile(
profile_name => 'COHERE_AI',
attributes => '{"provider": "cohere",
"credential_name": "COHERE_CRED",
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "channels"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "times"}],
"model":"gpt-3.5-turbo"
}');
END;Other model names you could use include gpt-4 or gpt-4o.
Oracle Object Storage – Parallel Downloading
In previous posts, I’ve given example Python code (and functions) for processing files into and out of OCI Object and Bucket Storage. One of these previous posts includes code and a demonstration of uploading files to an OCI Bucket using the multiprocessing package in Python.
Building upon these previous examples, the code below will download a Bucket using parallel processing. Like my last example, this code is based on the example code I gave in an earlier post on functions within a Jupyter Notebook.
Here’s the code.
import oci
import os
import argparse
from multiprocessing import Process
from glob import glob
import time
####
def upload_file(config, NAMESPACE, b, f, num):
file_exists = os.path.isfile(f)
if file_exists == True:
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_storage_client.put_object(NAMESPACE, b, os.path.basename(f), open(f,'rb'))
print(f'. Finished {num} uploading {f} in {round(time.time()-start_time,2)} seconds')
except Exception as e:
print(f'Error uploading file {num}. Try again.')
print(e)
else:
print(f'... File {f} does not exist or cannot be found. Check file name and full path')
####
def check_bucket_exists(config, NAMESPACE, b_name):
#check if Bucket exists
is_there = False
object_storage_client = oci.object_storage.ObjectStorageClient(config)
l_b = object_storage_client.list_buckets(NAMESPACE, config.get("tenancy")).data
for bucket in l_b:
if bucket.name == b_name:
is_there = True
if is_there == True:
print(f'Bucket {b_name} exists.')
else:
print(f'Bucket {b_name} does not exist.')
return is_there
####
def download_bucket_file(config, NAMESPACE, b, d, f, num):
print(f'..Starting Download File ({num}):',f, ' from Bucket', b, ' at ', time.strftime("%H:%M:%S"))
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
get_obj = object_storage_client.get_object(NAMESPACE, b, f)
with open(os.path.join(d, f), 'wb') as f:
for chunk in get_obj.data.raw.stream(1024 * 1024, decode_content=False):
f.write(chunk)
print(f'..Finished Download ({num}) in ', round(time.time()-start_time,2), 'seconds.')
except:
print(f'Error trying to download file {f}. Check parameters and try again')
####
if __name__ == "__main__":
#setup for OCI
config = oci.config.from_file()
object_storage = oci.object_storage.ObjectStorageClient(config)
NAMESPACE = object_storage.get_namespace().data
####
description = "\n".join(["Upload files in parallel to OCI storage.",
"All files in <directory> will be uploaded. Include '/' at end.",
"",
"<bucket_name> must already exist."])
parser = argparse.ArgumentParser(description=description,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(dest='bucket_name',
help="Name of object storage bucket")
parser.add_argument(dest='directory',
help="Path to local directory containing files to upload.")
args = parser.parse_args()
####
bucket_name = args.bucket_name
directory = args.directory
if not os.path.isdir(directory):
parser.usage()
else:
dir = directory + os.path.sep + "*"
start_time = time.time()
print('Starting Downloading Bucket - Parallel:', bucket_name, ' at ', time.strftime("%H:%M:%S"))
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_list = object_storage_client.list_objects(NAMESPACE, bucket_name).data
count = 0
for i in object_list.objects:
count+=1
print(f'... {count} files to download')
proc_list = []
num=0
for o in object_list.objects:
p = Process(target=download_bucket_file, args=(config, NAMESPACE, bucket_name, directory, o.name, num))
p.start()
num+=1
proc_list.append(p)
for job in proc_list:
job.join()
print('---')
print(f'Download Finished in {round(time.time()-start_time,2)} seconds.({time.strftime("%H:%M:%S")})')
#### the end ####
I’ve saved the code to a file called bucket_parallel_download.py.
To call this, I run the following using the same DEMO_Bucket and directory of files I used in my previous posts.
python bucket_parallel_download.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
This creates the following output, and between 3.6 seconds to 4.4 seconds to download the 13 files, based on my connection.
[16:30~/Dropbox]> python bucket_parallel_download.py DEMO_Bucket /Users/brendan.tierney/DEMO_BUCKET
Starting Downloading Bucket - Parallel: DEMO_Bucket at 16:30:05
... 13 files to download
..Starting Download File (0): 2017-08-31 19.46.42.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (1): 2017-10-16 13.13.20.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (2): 2017-11-22 20.18.58.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (3): 2018-12-03 11.04.57.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (11): thumbnail_IMG_2333.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (5): IMG_2347.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (9): thumbnail_IMG_1711.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (4): 347397087_620984963239631_2131524631626484429_n.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (10): thumbnail_IMG_1712.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (8): thumbnail_IMG_1710.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (7): oug_ire18_1.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (6): IMG_6779.jpg from Bucket DEMO_Bucket at 16:30:08
..Starting Download File (12): thumbnail_IMG_2336.jpg from Bucket DEMO_Bucket at 16:30:08
..Finished Download (9) in 0.67 seconds.
..Finished Download (11) in 0.74 seconds.
..Finished Download (10) in 0.7 seconds.
..Finished Download (5) in 0.8 seconds.
..Finished Download (7) in 0.7 seconds.
..Finished Download (1) in 1.0 seconds.
..Finished Download (12) in 0.81 seconds.
..Finished Download (4) in 1.02 seconds.
..Finished Download (6) in 0.97 seconds.
..Finished Download (2) in 1.25 seconds.
..Finished Download (8) in 1.16 seconds.
..Finished Download (0) in 1.47 seconds.
..Finished Download (3) in 1.47 seconds.
---
Download Finished in 4.09 seconds.(16:30:09)Oracle Object Storage – Parallel Uploading
In my previous posts on using Python to work with OCI Object Storage, I gave code examples and illustrated how to create Buckets, explore Buckets, upload files, download files and delete files and buckets, all using Python and files on your computer.
- Oracle Object Storage – Setup and Explore
- Oracle Object Storage – Buckets & Loading files
- Oracle Object Storage – Downloading and Deleting
- Oracle Object Storage – Parallel Uploading
Building upon the code I’ve given for uploading files, which did so sequentially, in his post I’ve taken that code and expanded it to allow the files to be uploaded in parallel to an OCI Bucket. This is achieved using the Python multiprocessing library.
Here’s the code.
import oci
import os
import argparse
from multiprocessing import Process
from glob import glob
import time
####
def upload_file(config, NAMESPACE, b, f, num):
file_exists = os.path.isfile(f)
if file_exists == True:
try:
start_time = time.time()
object_storage_client = oci.object_storage.ObjectStorageClient(config)
object_storage_client.put_object(NAMESPACE, b, os.path.basename(f), open(f,'rb'))
print(f'. Finished {num} uploading {f} in {round(time.time()-start_time,2)} seconds')
except Exception as e:
print(f'Error uploading file {num}. Try again.')
print(e)
else:
print(f'... File {f} does not exist or cannot be found. Check file name and full path')
####
def check_bucket_exists(config, NAMESPACE, b_name):
#check if Bucket exists
is_there = False
object_storage_client = oci.object_storage.ObjectStorageClient(config)
l_b = object_storage_client.list_buckets(NAMESPACE, config.get("tenancy")).data
for bucket in l_b:
if bucket.name == b_name:
is_there = True
if is_there == True:
print(f'Bucket {b_name} exists.')
else:
print(f'Bucket {b_name} does not exist.')
return is_there
####
if __name__ == "__main__":
#setup for OCI
config = oci.config.from_file()
object_storage = oci.object_storage.ObjectStorageClient(config)
NAMESPACE = object_storage.get_namespace().data
####
description = "\n".join(["Upload files in parallel to OCI storage.",
"All files in <directory> will be uploaded. Include '/' at end.",
"",
"<bucket_name> must already exist."])
parser = argparse.ArgumentParser(description=description,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(dest='bucket_name',
help="Name of object storage bucket")
parser.add_argument(dest='directory',
help="Path to local directory containing files to upload.")
args = parser.parse_args()
####
bucket_name = args.bucket_name
directory = args.directory
if not os.path.isdir(directory):
parser.usage()
else:
dir = directory + os.path.sep + "*"
#### Check if Bucket Exists ####
b_exists = check_bucket_exists(config, NAMESPACE, bucket_name)
if b_exists == True:
try:
proc_list = []
num=0
start_time = time.time()
#### Start uploading files ####
for file_path in glob(dir):
print(f"Starting {num} upload for {file_path}")
p = Process(target=upload_file, args=(config, NAMESPACE, bucket_name, file_path, num))
p.start()
num+=1
proc_list.append(p)
except Exception as e:
print(f'Error uploading file ({num}). Try again.')
print(e)
else:
print('... Create Bucket before uploading Directory.')
for job in proc_list:
job.join()
print('---')
print(f'Finished uploading all files ({num}) in {round(time.time()-start_time,2)} seconds')
#### the end ####
I’ve saved the code to a file called bucket_parallel.py.
To call this, I run the following using the same DEMO_Bucket and directory of files I used in my previous posts.
python bucket_parallel.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
This creates the following output, and between 3.3 seconds to 4.6 seconds to upload the 13 files, based on my connection.
[15:29~/Dropbox]> python bucket_parallel.py DEMO_Bucket /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/
Bucket DEMO_Bucket exists.
Starting 0 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2336.jpg
Starting 1 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-08-31 19.46.42.jpg
Starting 2 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2333.jpg
Starting 3 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/347397087_620984963239631_2131524631626484429_n.jpg
Starting 4 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1712.jpg
Starting 5 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1711.jpg
Starting 6 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-11-22 20.18.58.jpg
Starting 7 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1710.jpg
Starting 8 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2018-12-03 11.04.57.jpg
Starting 9 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_6779.jpg
Starting 10 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/oug_ire18_1.jpg
Starting 11 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-10-16 13.13.20.jpg
Starting 12 upload for /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_2347.jpg
. Finished 2 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2333.jpg in 0.752561092376709 seconds
. Finished 5 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1711.jpg in 0.7750208377838135 seconds
. Finished 4 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1712.jpg in 0.7535321712493896 seconds
. Finished 0 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_2336.jpg in 0.8419861793518066 seconds
. Finished 7 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/thumbnail_IMG_1710.jpg in 0.7582859992980957 seconds
. Finished 10 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/oug_ire18_1.jpg in 0.8714470863342285 seconds
. Finished 12 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_2347.jpg in 0.8753311634063721 seconds
. Finished 1 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-08-31 19.46.42.jpg in 1.2201581001281738 seconds
. Finished 11 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-10-16 13.13.20.jpg in 1.2848408222198486 seconds
. Finished 3 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/347397087_620984963239631_2131524631626484429_n.jpg in 1.325110912322998 seconds
. Finished 9 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/IMG_6779.jpg in 1.6633048057556152 seconds
. Finished 8 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2018-12-03 11.04.57.jpg in 1.8549730777740479 seconds
. Finished 6 uploading /Users/brendan.tierney/Dropbox/OCI-Vision-Images/Blue-Peter/2017-11-22 20.18.58.jpg in 2.018144130706787 seconds
---
Finished uploading all files (13) in 3.9126579761505127 seconds
You must be logged in to post a comment.