
postgres
Number of rows in each Table – Various Databases
A possible common task developers perform is to find out how many records exists in every table in a schema. In the examples below I’ll show examples for the current schema of the developer, but these can be expanded easily to include tables in other schemas or for all schemas across a database.
These example include the different ways of determining this information across the main databases including Oracle, MySQL, Postgres, SQL Server and Snowflake.
A little warning before using these queries. They may or may not give the true accurate number of records in the tables. These examples illustrate extracting the number of records from the data dictionaries of the databases. This is dependent on background processes being run to gather this information. These background processes run from time to time, anything from a few minutes to many tens of minutes. So, these results are good indication of the number of records in each table.
Oracle
SELECT table_name, num_rows
FROM user_tables
ORDER BY num_rows DESC;or
SELECT table_name,
to_number(
extractvalue(xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name))
,'/ROWSET/ROW/C')) tab_count
FROM user_tables
ORDER BY tab_count desc;Using PL/SQL we can do something like the following.
DECLARE
val NUMBER;
BEGIN
FOR i IN (SELECT table_name FROM user_tables ORDER BY table_name desc) LOOP
EXECUTE IMMEDIATE 'SELECT count(*) FROM '|| i.table_name INTO val;
DBMS_OUTPUT.PUT_LINE(i.table_name||' -> '|| val );
END LOOP;
END;MySQL
SELECT table_name, table_rows
FROM INFORMATION_SCHEMA.TABLES
WHERE table_type = 'BASE TABLE'
AND TABLE_SCHEMA = current_user();
Using Common Table Expressions (CTE), using WITH clause
WITH table_list AS (
SELECT
table_name
FROM information_schema.tables
WHERE table_schema = current_user()
AND
table_type = 'BASE TABLE'
)
SELECT CONCAT(
GROUP_CONCAT(CONCAT("SELECT '",table_name,"' table_name,COUNT(*) rows FROM ",table_name) SEPARATOR " UNION "),
' ORDER BY table_name'
)
INTO @sql
FROM table_list;
Postgres
select relname as table_name, n_live_tup as num_rows from pg_stat_user_tables;
An alternative is
select n.nspname as table_schema,
c.relname as table_name,
c.reltuples as rows
from pg_class c
join pg_namespace n on n.oid = c.relnamespace
where c.relkind = 'r'
and n.nspname = current_user
order by c.reltuples desc;
SQL Server
SELECT tab.name,
sum(par.rows)
FROM sys.tables tab INNER JOIN sys.partitions par
ON tab.object_id = par.object_id
WHERE schema_name(tab.schema_id) = current_user
Snowflake
SELECT t.table_schema, t.table_name, t.row_count
FROM information_schema.tables t
WHERE t.table_type = 'BASE TABLE'
AND t.table_schema = current_user
order by t.row_count desc;
The examples give above are some of the ways to obtain this information. As with most things, there can be multiple ways of doing it, and most people will have their preferred one which is based on their background and preferences.
As you can see from the code given above they are all very similar, with similar syntax, etc. The only thing different is the name of the data dictionary table/view containing the information needed. Yes, knowing what data dictionary views to query can be a little challenging as you switch between databases.
Postgres on Docker
Prostgres is one of the most popular databases out there, being used in Universities, open source projects and also widely used in the corporate marketplace. I’ve written a previous post on running Oracle Database on Docker. This post is similar, as it will show you the few simple steps to have a persistent Postgres Database running on Docker.
The first step is go to Docker Hub and locate the page for Postgres. You should see something like the following. Click through to the Postgres page.

There are lots and lots of possible Postgres images to download and use. The simplest option is to download the latest image using the following command in a command/terminal window. Make sure Docker is running on your machine before running this command.
docker pull postgresAlthough, if you needed to install a previous release, you can do that.

After the docker image has been downloaded, you can now import into Docker and create a container.
docker run --name postgres -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=pgPassword -e POSTGRES_DB=postgres -d postgresImportant: I’m using Docker on a Mac. If you are using Windows, the format of the parameter list is slightly different. For example, remove the = symbol after POSTGRES_DB
If you now check with Docker you’ll see Postgres is now running on post 5432.

Next you will need pgAdmin to connect to the Postgres Database and start working with it. You can download and install it, or run another Docker container with pgAdmin running in it.
First, let’s have a look at installing pgAdmin. Download the image and run, accepting the initial requirements. Just let it run and finish installing.


When pgAdmin starts it looks for you to enter a password. This can be anything really, but one that you want to remember. For example, I set mine to pgPassword.
Then create (or Register) a connection to your Postgres Database. Enter the details you used when creating the docker image including username=postgres, password=pgPassword and IP address=0.0.0.0.
The IP address on your machine might be a little different, and to check what it is, run the following
docker ps -a


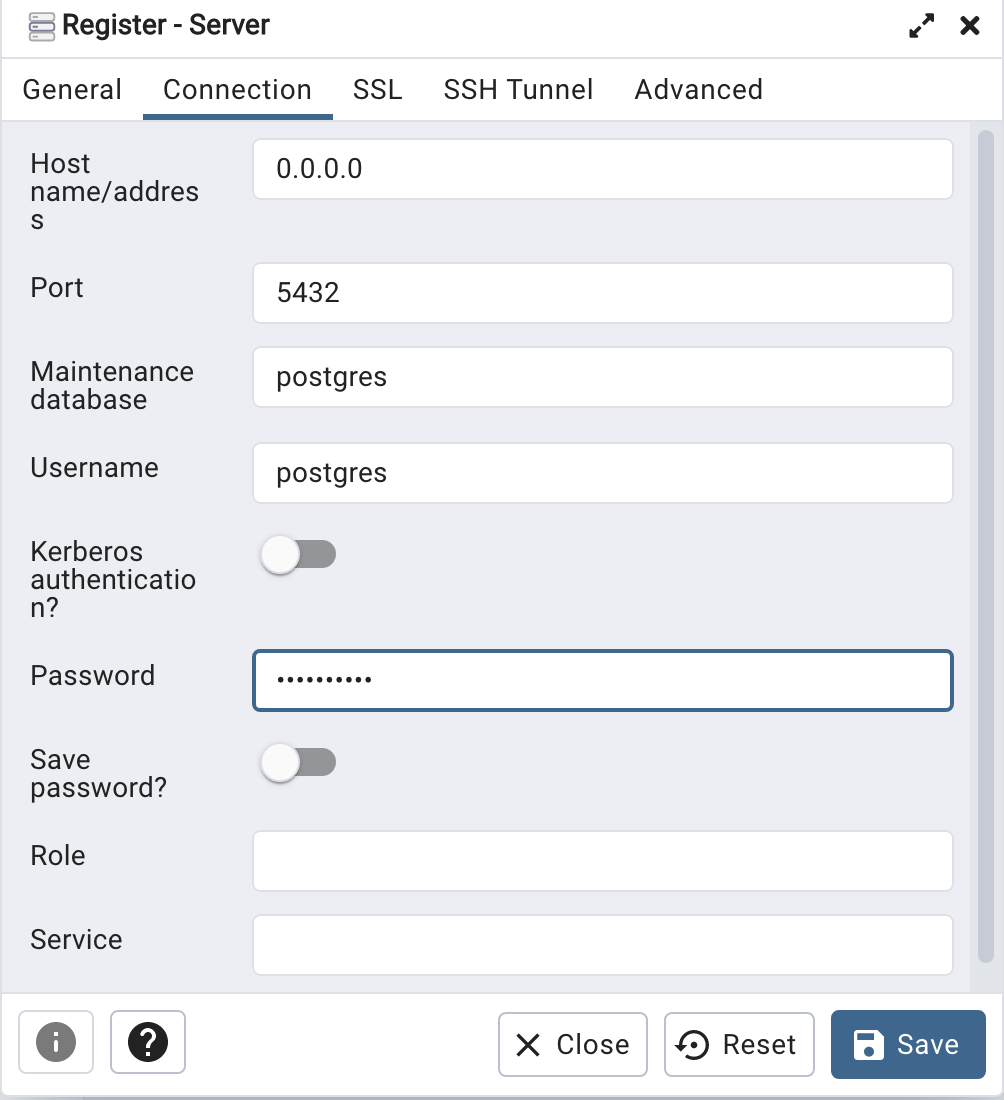
When your (above) connection works, the next step is to create another schema/user in the database. The reason we need to do this is because the user we connected to above (postgres) is an admin user. This user/schema should never be used for database development work.
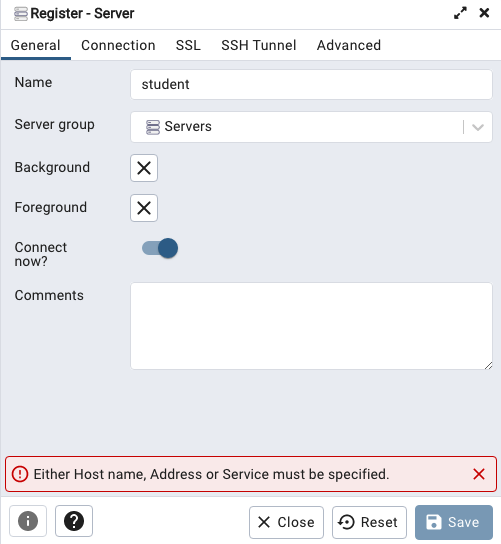
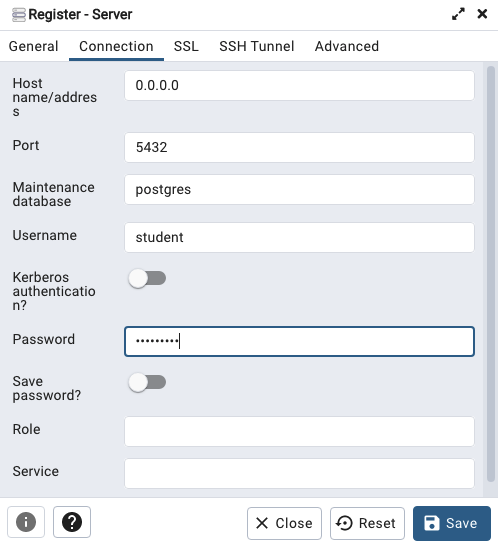
Let’s setup a user we can use for our development work called ‘student’. To do this, right click on the ‘postgres’ user connection and open the query tool.
Then run the following.

After these two commands have been run successfully we can now create a connection to the postgres database, open the query tool and you’re now all set to write some SQL.


You must be logged in to post a comment.