
ORE
OML4R available on ADB
Oracle Machine Learning for R (OML4R) is available on Oracle Autonomous Database. Finally. After waiting for way, way too long we can now run R code in the Autonomous Database (in the Cloud). It’s based on using Oracle R Distribution 4.0.5 (which is based on R 4.0.5). This product was previously called Oracle R Enterprise, which I was a fan of many few years ago, so much so I wrote a book about it.
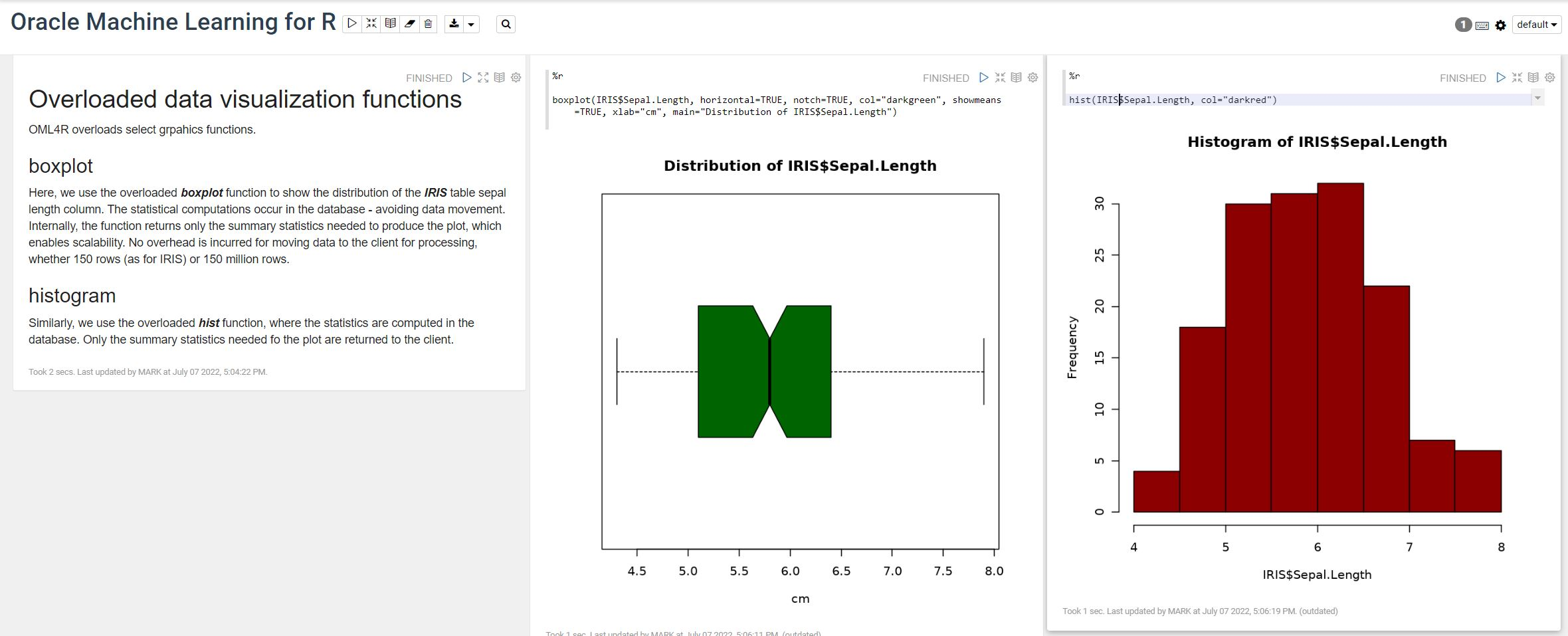
OML4R comes with all (or most) of the benefits of Oracle R Enterprise, whereby you can connect to, in this case an Oracle Autonomous Database (in the Cloud), allowing data scientists work with R code and manipulate data in the database instead of in their local environment. Embed R code in the database and enable other database users (and applications) to call this R code. Although with OML4R on ADB (in the Cloud) does come with some limitations and restrictions, which will put people/customers off from using it.
Waiting for OML4R reminds me of Eurovision Song Contest winning song by Johnny Logan titled,
I’ve been waiting such a long time
Looking out for you
But you’re not here
What’s another year
It has taken Oracle way, way too long to migrate OML4R to ADB. They’ve probably just made it available because one or two customers needed/asked it.
As the lyrics from Johnny Logan says (changing I’ve to We’ve), We’ve been waiting such a long time, most customers have moved to other languages, tools and other cloud data science platforms for their data science work. The market has moved on, many years ago.
Hopefully over the next few months, and with Oracle 23c Database, we might see some innovation, or maybe their data science and AI focus lies elsewhere within Oracle development teams.
Managing memory allocation for Oracle R Enterprise Embedded Execution
When working with Oracle R Enterprise and particularly when you are using the ORE functions that can spawn multiple R processes, on the DB Server, you need to be very aware of the amount of memory that will be consumed for each call of the ORE function.
ORE has two sets of parallel functions for running your user defined R scripts stored in the database, as part of the Embedded R Execution feature of ORE. The R functions are called ore.groupApply, ore.rowApply and ore.indexApply. When using SQL there are “rqGroupApply” and rqRowApply. (There is no SQL function equivalent of the R function ore.indexApply)
For each parallel R process that is spawned on the DB server a certain amount of memory (RAM) will be allocated to this R process. The default size of memory to be allocated can be found by using the following query.
select name, value from sys.rq_config; NAME VALUE ----------------------------------- ----------------------------------- VERSION 1.5 MIN_VSIZE 32M MAX_VSIZE 4G MIN_NSIZE 2M MAX_NSIZE 20M
The memory allocation is broken out into the amount of memory allocated for Cells and NCells for each R process.
If your parallel ORE function create a large number of parallel R processes then you can see that the amount of overall memory consumed can be significant. I’ve seen a few customers who very quickly run out of memory on their DB servers. Now that is something you do not want to happen.
How can you prevent this from happening ?
There are a few things you need to keep in mind when using the parallel enabled ORE functions. The first one is, how many R processes will be spawned. For most cases this can be estimated or calculated to a high degree of accuracy. Secondly, how much memory will be used to process each of the R processes. Thirdly, how memory do you have available on the DB server. Fourthly, how many other people will be running parallel R processes at the same time?
Examining and answering each of these may look to be a relatively trivial task, but the complexity behind these can increase dramatically depending on the answer to the fourth point/question above.
To calculate the amount of memory used during the ORE user defined R script, you can use the R garbage function to calculate the memory usage at the start and at the end of the R script, and then return the calculated amount. Yes you need to add this extra code to your R script and then remove it when you have calculated the memory usage.
gc.start <- gc(reset=TRUE) ... gc.end <- gc() gc.used <- gc.end[,7] - gc.start[,7] # amount consumed by the processing
Using this information and the answers to the points/questions I listed above you can now look at calculating how much memory you need to allocated to the R processes. You can set this to be static for all R processes or you can use some code to allocate the amount of memory that is needed for each R process. But this starts to become messy. The following gives some examples (using R) of changing the R memory allocations in the Oracle Database. Similar commands can be issued using SQL.
> sys.rqconfigset('MIN_VSIZE', '10M') -- min heap 10MB, default 32MB
> sys.rqconfigset('MAX_VSIZE', '100M') -- max heap 100MB, default 4GB
> sys.rqconfigset('MIN_NSIZE', '500K') -- min number cons cells 500x1024, default 1M
> sys.rqconfigset('MAX_NSIZE', '2M') -- max number cons cells 2M, default 20M
Some guidelines – as with all guidelines you have to consider all the other requirements for the Database, and in reality you will have to try to find a balance between what is listed here and what is actually possible.
- Set parallel_degree_policy to MANUAL.
- Set parallel_min_servers to the number of parallel slave processes to be started when the database instances start, this avoids start up time for the R processes. This is not a problem for long running processes. But can save time with processes running for 10s seconds
- To avoid overloading the CPUs if the parallel_max_servers limit is reached, set the hidden parameter _parallel_statement_queuing to TRUE. Avoids overloading and lets processes wait.
- Set application tables and their indexes to DOP 1 to reinforce the ability of ORE to determine when to use parallelism.
Understanding the memory requirements for your ORE processes can be tricky business and can take some time to work out the right balance between what is needed by the spawned parallel R processes and everything else that is going on in the Database. There will be a lot of trial and error in working this out and it is always good to reach out for some help. If you have a similar scenario and need some help or guidance let me know.
Formatting results from ORE script in a SELECT statement
This blog post looks at how to format the output or the returned returns from an Oracle R Enterprise (ORE), user defined R function, that is run using a SELECT statement in SQL.
Sometimes this can be a bit of a challenge to work out, but it can be relatively easy once you have figured out how to do it. The following examples works through some scenarios of different results sets from a user defined R function that is stored in the Oracle Database.
To run that user defined R function using a SELECT statement I can use one of the following ORE SQL functions.
- rqEval
- rqTableEval
- “rqGroupEval“
- rqRowEval
For simplicity we will just use the first of these ORE SQL functions to illustrate the problem and how to go about solving it. The rqEval ORE SQL function is a generate purpose function to call a user defined R script stored in the database. The function does not require any input data set and but it will return some data. You could use this to generate some dummy/test data or to find some information in the database. Here is noddy example that returns my name.
BEGIN
--sys.rqScriptDrop('GET_NAME');
sys.rqScriptCreate('GET_NAME',
'function() {
res<-data.frame("Brendan")
res
} ');
END;
To call this user defined R function I can use the following SQL.
select *
from table(rqEval(null,
'select cast(''a'' as varchar2(50)) from dual',
'GET_NAME') );
For text strings returned you need to cast the returned value giving a size.
If we have a numeric value being returned we can don’t have to use the cast and instead use ‘1’ as shown in the following example. This second example extends our user defined R function to return my name and a number.
BEGIN
sys.rqScriptDrop('GET_NAME');
sys.rqScriptCreate('GET_NAME',
'function() {
res<-data.frame(NAME="Brendan", YEAR=2017)
res
} ');
END;
To call the updated GET_NAME function we now have to process two returned columns. The first is the character string and the second is a numeric.
select *
from table(rqEval(null,
'select cast(''a'' as varchar2(50)) as "NAME", 1 AS YEAR from dual',
'GET_NAME') );
These example illustrate how you can process character strings and numerics being returned by the user defined R script.
The key to setting up the format of the returned values is knowing the structure of the data frame being returned by the user defined R script. Once you know that the rest is (in theory) easy.
How to get ORE to work with APEX
This blog post will bring you through the steps of how to get Oracle R Enterprise (ORE) to work with APEX.
The reason for this blog posts is that since ORE 1.4+ the security model has changed for how you access and run in-database user defined R scripts using the ORE SQL API functions.
I have a series of blog posts going out on using Oracle Text, Oracle R Enterprise and Oracle Data Mining. It was during one of these posts I wanted to show how easy it was to display an R chart using ORE in APEX. Up to now my APEX environment consisted of APEX 4 and ORE 1.3. Everything worked, nice and easy. But in my new APEX environment (APEX 5 and ORE 1.5), it didn’t work. This is the calling of an in-database user defined R script using the SQL API functions didn’t work. Here is the error message that is displayed.

So something extra was needed with using ORE 1.5. The security model around the use of in-database user defined R scripts has changed. Extra functions are now available to allow you who can run these scripts. For example we have an ore.grant function where you can grant another user the privilege to run the script.
But the problem was, when I was in APEX, the application was defined on the same schema that the r script was created in (this was the RQUSER schema). When I connect to the RQUSER schema using ORE and SQL, I was able to see and run this R script (see my previous blog post for these details). But when I was in APEX I wasn’t able to see the R script. For example, when using the SQL Workshop in APEX, I just couldn’t see the R script.

Something strange is going on. It turns out that the view definitions for the in-database ORE scripts are defined with
owner=SYS_CONTEXT('USERENV', 'SESSION_USER');
(Thanks to the Oracle ORE team and the Oracle APEX team for their help in working out what needed to be done)
This means when I’m connected to APEX, using my schema (RQUSER), I’m not able to see any of my ORE objects.
How do you overcome this problem ?
To fix this problem, I needed to grant the APEX_PUBLIC_USER access to my ORE script.
ore.grant(name = "prepare_tm_data_2", type = "rqscript", user = "APEX_PUBLIC_USER")
Now when I query the ALL_RQ_SCRIPTS view again, using the APEX SQL Workshop, I now get the following.

Great. Now I can see the ORE script in my schema.
Now when I run my APEX application I now get graphic produced by R, running on my DB server, and delivered to my APEX application using SQL (via a BLOB object), displayed on my screen.

Change the size of ORE PNG graphics using in-database R functions
In a previous blog post I showed you how create and display a ggplot2 R graphic using SQL. Make sure to check it out before reading the rest of this blog post.
In my previous blog post, I showed and mentioned that the PNG graphic returned by the embedded R execution SQL statement was not the same as what was produced if you created the graphic in an R session.
Here is the same ggplot2 graphic. The first one is what is produced in an R session and the section is what is produced by SQL query and the embedded R execution in Oracle.


As you can see the second image (produced using the embedded R execution) gives a very square image.
The reason for this is that Oracle R Enterprise (ORE) creates the graphic image in PNG format. The default setting from this is 480 x 480. You will find this information when you go digging in the R documentation and not in the Oracle documentation.
So, how can I get my ORE produced graphic to appear like what is produced in R?
What you need to do is to change the height and width of the PNG image produced by ORE. You can do this by passing parameters in the SQL statement used to call the user defined R function, that in turn produces the ggplot2 image.
In my previous post, I gave the SQL statement to call and produce the graphic (shown above). One of the parameters to the rqTableEval function was set to null. This was because we didn’t have any parameters to pass, apart from the data set.
We can replace this null with any parameters we want to pass to the user defined R function (demo_ggpplot). To pass the parameters we need to define them using a SELECT statement.
cursor(select 500 as "ore.png.height", 850 as "ore.png.width" from dual),
The full SELECT statement now becomes
select *
from table(rqTableEval( cursor(select * from claims),
cursor(select 500 as "ore.png.height", 850 as "ore.png.width" from dual),
'PNG',
'demo_ggpplot'));
When you view the graphic in SQL Developer, you will get something that looks a bit more like what you would expect or want to see.

For each graphic image you want to produce using ORE you will need to figure out that are the best PNG height and width settings to use. Plus it also depends on what tool or application you are going to use to display the images (eg. APEX etc)
Oracle Text, Oracle R Enterprise and Oracle Data Mining – Part 1
A project that I’ve been working on for a while now involves the use of Oracle Text, Oracle R Enterprise and Oracle Data Mining. Oracle Text comes with your Oracle Database licence. Oracle R Enterprise and Oracle Data Mining are part of the Oracle Advanced Analytics (extra cost) option.
What I will be doing over the course of 4 or maybe 5 blog posts is how these products can work together to help you gain a grater insight into your data, and part of your data being large text items like free format text, documents (in various forms e.g. html, xml, pdf, ms word), etc.
Unfortunately I cannot show you examples from the actual project I’ve been working on (and still am, from time to time). But what I can do is to show you how products and components can work together.
In this blog post I will just do some data setup. As with all project scenarios there can be many ways of performing the same tasks. Some might be better than others. But what I will be showing you is for demonstration purposes.
The scenario: The scenario for this blog post is that I want to extract text from some webpages and store them in a table in my schema. I then want to use Oracle Text to search the text from these webpages.
Schema setup: We need to create a table that will store the text from the webpages. We also want to create an Oracle Text index so that this text is searchable.
drop sequence my_doc_seq; create sequence my_doc_seq; drop table my_documents; create table my_documents ( doc_pk number(10) primary key, doc_title varchar2(100), doc_extracted date, data_source varchar2(200), doc_text clob); create index my_documents_ot_idx on my_documents(doc_text) indextype is CTXSYS.CONTEXT;
In the table we have a number of descriptive attributes and then a club for storing the website text. We will only be storing the website text and not the html document (More on that later). In order to make the website text searchable in the DOC_TEXT attribute we need to create an Oracle Text index of type CONTEXT.
There are a few challenges with using this type of index. For example when you insert a new record or update the DOC_TEXT attribute, the new values/text will not be reflected instantly, just like we are use to with traditional indexes. Instead you have to decide when you want to index to be updated. For example, if you would like the index to be updated after each commit then you can create the index using the following.
create index my_documents_ot_idx on my_documents(doc_text)
indextype is CTXSYS.CONTEXT
parameters ('sync (on commit)');
Depending on the number of documents you have being committed to the DB, this might not be for you. You need to find the balance. Alternatively you could schedule the index to be updated by passing an interval to the ‘sync’ in the above command. Alternatively you might want to use DBMS_JOB to schedule the update.
To manually sync (or via DBMS_JOB) the index, assuming we used the first ‘create index’ statement, we would need to run the following.
EXEC CTX_DDL.SYNC_INDEX('my_documents_ot_idx');
This function just adds the new documents to the index. This can, over time, lead to some fragmentation of the index, and will require it to the re-organised on a semi-regular basis. Perhaps you can schedule this to happen every night, or once a week, or whatever makes sense to you.
BEGIN
CTX_DDL.OPTIMIZE_INDEX('my_documents_ot_idx','FULL');
END;
(I could talk a lot more about setting up some basics of Oracle Text, the indexes, etc. But I’ll leave that for another day or you can read some of the many blog posts that already exist on the topic.)
Extracting text from a webpage using R: Some time ago I wrote a blog post on using some of the text mining features and packages in R to produce a word cloud based on some of the Oracle Advanced Analytics webpages.
I’m going to use the same webpages and some of the same code/functions/packages here.
The first task you need to do is to get your hands on the ‘htmlToText function. You can download the htmlToText function on github. This function requires the ‘Curl’ and ‘XML’ R packages. So you may need to install these.
I also use the str_replace_all function (“stringer’ R package) to remove some of the html that remains, to remove some special quotes and to replace and occurrences of ‘&’ with ‘and’.
# Load the function and required R packages
source(“c:/app/htmltotext.R”)
library(stringr)
data1 <- str_replace_all(htmlToText("http://www.oracle.com/technetwork/database/options/advanced-analytics/overview/index.html"), "[\r\n\t\"\'\u201C\u201D]" , "")
data1 <- str_replace_all(data1, "&", "and")
data2 <- str_replace_all(str_replace_all(htmlToText("http://www.oracle.com/technetwork/database/options/advanced-analytics/odm/index.html"), "[\r\n\t\"\'\u201C\u201D]" , ""), "&", "and")
data2 <- str_replace_all(data2, "&", "and")
data3 <- str_replace_all(str_replace_all(htmlToText("http://www.oracle.com/technetwork/database/database-technologies/r/r-technologies/overview/index.html"), "[\r\n\t\"\'\u201C\u201D]" , ""), "&", "and")
data3 <- str_replace_all(data3, "&", "and")
data4 <- str_replace_all(str_replace_all(htmlToText("http://www.oracle.com/technetwork/database/database-technologies/r/r-enterprise/overview/index.html"), "[\r\n\t\"\'\u201C\u201D]" , ""), "&", "and")
data4 <- str_replace_all(data4, "&", "and")
We now have the text extracted and cleaned up.
Create a data frame to contain all our data: Now that we have the text extracted, we can prepare the other data items we need to insert the data into our table (‘my_documents’). The first stept is to construct a data frame to contain all the data.
data_source = c("http://www.oracle.com/technetwork/database/options/advanced-analytics/overview/index.html",
"http://www.oracle.com/technetwork/database/options/advanced-analytics/odm/index.html",
"http://www.oracle.com/technetwork/database/database-technologies/r/r-technologies/overview/index.html",
"http://www.oracle.com/technetwork/database/database-technologies/r/r-enterprise/overview/index.html")
doc_title = c("OAA_OVERVIEW", "OAA_ODM", "R_TECHNOLOGIES", "OAA_ORE")
doc_extracted = Sys.Date()
data_text <- c(data1, data2, data3, data4)
my_docs <- data.frame(doc_title, doc_extracted, data_source, data_text)
Insert the data into our database table: With the data in our data fram (my_docs) we can now use this data to insert into our database table. There are a number of ways of doing this in R. What I’m going to show you here is how to do it using Oracle R Enterprise (ORE). The thing with ORE is that there is no explicit functionality for inserting and updating records in a database table. What you need to do is to construct, in my case, the insert statement and then use ore.exec to execute this statement in the database.
Accessing the R datasets in ORE and SQL
When you install R you also get a set of pre-compiled datasets. These are great for trying out many of the features that are available with R and all the new packages that are being produced on an almost daily basis.
The exact list of data sets available will depend on the version of R that you are using.
To get the list of available data sets in R you can run the following.
> library(help="datasets")
This command will list all the data sets that you can reference and start using immediately.
I’m currently running the latest version of Oracle R Distribution version 3.2. See the listing at the end of this blog post for the available data sets.
But are these data sets available to you if you are using Oracle R Enterprise (ORE)? The answer is Yes of course they are.
But are these accessible on the Oracle Database server? Yes they are, as you have R installed there and you can use ORE to access and use the data sets.
But how? how can I list what is on the Oracle Database server using R? Simple use the following ORE code to run an embedded R execution function using the ORE R API.
What? What does that mean? Using the R on your client machine, you can use ORE to send some R code to the Oracle Database server. The R code will be run on the Oracle Database server and the results will be returned to the client. The results contain the results from the server. Try the following code.
ore.doEval(function() library(help="datasets"))
# let us create a functions for this code
myFn <- function() {library(help="datasets")}
# Now send this function to the DB server and run it there.
ore.doEval(myFn)
# create an R script in the Oracle Database that contains our R code
ore.scriptDrop("inDB_R_DemoData")
ore.scriptCreate("inDB_R_DemoData", myFn)
# Now run the R script, stored in the Oracle Database, on the Database server
# and return the results to my client
ore.doEval(FUN.NAME="inDB_R_DemoData")
Simple, Right!
Yes it is. You have shown us how to do this in R using the ORE package. But what if I’m a SQL developer. Can I do this in SQL? Yes you can. Connect you your schema using SQL Developer/SQL*Plus/SQLcl or whatever tool you will be using to run SQL. Then run the following SQL.
select * from table(rqEval(null, 'XML', 'inDB_R_DemoData'));
This SQL code will return the results in XML format. You can parse this to extract and display the results and when you do you will get something like the following listing, which is exactly the same that is produced when you run the R code that I gave above.
So what this means is that evening if you have an empty schema with no data in it, and as long as you have the privileges to run embedded R execution, you actually have access to all these different data sets. You can use these to try our R using the ORE SQL APIs too.
Information on package ‘datasets’
Description:
Package: datasets
Version: 3.2.0
Priority: base
Title: The R Datasets Package
Author: R Core Team and contributors worldwide
Maintainer: R Core Team
Description: Base R datasets.
License: Part of R 3.2.0
Built: R 3.2.0; ; 2015-08-07 02:20:26 UTC; windows
Index:
AirPassengers Monthly Airline Passenger Numbers 1949-1960
BJsales Sales Data with Leading Indicator
BOD Biochemical Oxygen Demand
CO2 Carbon Dioxide Uptake in Grass Plants
ChickWeight Weight versus age of chicks on different diets
DNase Elisa assay of DNase
EuStockMarkets Daily Closing Prices of Major European Stock
Indices, 1991-1998
Formaldehyde Determination of Formaldehyde
HairEyeColor Hair and Eye Color of Statistics Students
Harman23.cor Harman Example 2.3
Harman74.cor Harman Example 7.4
Indometh Pharmacokinetics of Indomethacin
InsectSprays Effectiveness of Insect Sprays
JohnsonJohnson Quarterly Earnings per Johnson & Johnson Share
LakeHuron Level of Lake Huron 1875-1972
LifeCycleSavings Intercountry Life-Cycle Savings Data
Loblolly Growth of Loblolly pine trees
Nile Flow of the River Nile
Orange Growth of Orange Trees
OrchardSprays Potency of Orchard Sprays
PlantGrowth Results from an Experiment on Plant Growth
Puromycin Reaction Velocity of an Enzymatic Reaction
Theoph Pharmacokinetics of Theophylline
Titanic Survival of passengers on the Titanic
ToothGrowth The Effect of Vitamin C on Tooth Growth in
Guinea Pigs
UCBAdmissions Student Admissions at UC Berkeley
UKDriverDeaths Road Casualties in Great Britain 1969-84
UKLungDeaths Monthly Deaths from Lung Diseases in the UK
UKgas UK Quarterly Gas Consumption
USAccDeaths Accidental Deaths in the US 1973-1978
USArrests Violent Crime Rates by US State
USJudgeRatings Lawyers' Ratings of State Judges in the US
Superior Court
USPersonalExpenditure Personal Expenditure Data
VADeaths Death Rates in Virginia (1940)
WWWusage Internet Usage per Minute
WorldPhones The World's Telephones
ability.cov Ability and Intelligence Tests
airmiles Passenger Miles on Commercial US Airlines,
1937-1960
airquality New York Air Quality Measurements
anscombe Anscombe's Quartet of 'Identical' Simple Linear
Regressions
attenu The Joyner-Boore Attenuation Data
attitude The Chatterjee-Price Attitude Data
austres Quarterly Time Series of the Number of
Australian Residents
beavers Body Temperature Series of Two Beavers
cars Speed and Stopping Distances of Cars
chickwts Chicken Weights by Feed Type
co2 Mauna Loa Atmospheric CO2 Concentration
crimtab Student's 3000 Criminals Data
datasets-package The R Datasets Package
discoveries Yearly Numbers of Important Discoveries
esoph Smoking, Alcohol and (O)esophageal Cancer
euro Conversion Rates of Euro Currencies
eurodist Distances Between European Cities and Between
US Cities
faithful Old Faithful Geyser Data
freeny Freeny's Revenue Data
infert Infertility after Spontaneous and Induced
Abortion
iris Edgar Anderson's Iris Data
islands Areas of the World's Major Landmasses
lh Luteinizing Hormone in Blood Samples
longley Longley's Economic Regression Data
lynx Annual Canadian Lynx trappings 1821-1934
morley Michelson Speed of Light Data
mtcars Motor Trend Car Road Tests
nhtemp Average Yearly Temperatures in New Haven
nottem Average Monthly Temperatures at Nottingham,
1920-1939
npk Classical N, P, K Factorial Experiment
occupationalStatus Occupational Status of Fathers and their Sons
precip Annual Precipitation in US Cities
presidents Quarterly Approval Ratings of US Presidents
pressure Vapor Pressure of Mercury as a Function of
Temperature
quakes Locations of Earthquakes off Fiji
randu Random Numbers from Congruential Generator
RANDU
rivers Lengths of Major North American Rivers
rock Measurements on Petroleum Rock Samples
sleep Student's Sleep Data
stackloss Brownlee's Stack Loss Plant Data
state US State Facts and Figures
sunspot.month Monthly Sunspot Data, from 1749 to "Present"
sunspot.year Yearly Sunspot Data, 1700-1988
sunspots Monthly Sunspot Numbers, 1749-1983
swiss Swiss Fertility and Socioeconomic Indicators
(1888) Data
treering Yearly Treering Data, -6000-1979
trees Girth, Height and Volume for Black Cherry Trees
uspop Populations Recorded by the US Census
volcano Topographic Information on Auckland's Maunga
Whau Volcano
warpbreaks The Number of Breaks in Yarn during Weaving
women Average Heights and Weights for American Women
Oracle Advanced Analytics in the Oracle Cloud
You have heard about the cloud? Right? Even the Oracle Cloud?
If you haven’t, then maybe we need to look at how you can learn more about the Oracle Cloud.
Over the past while, and in the past few weeks in particular, Oracle has been advertising about how you can get a trail Oracle cloud service setup for FREE. Well it is free for one month when you set it up on the Oracle website (cloud.oracle.com).
As I like to talk about and use the Oracle Advanced Analytics (OAA) option (a lot), I thought I’d just give you some pointers on how to use OAA on the Oracle cloud.
To do this you need to set up an account on the Oracle cloud website (your Oracle single sign on should help with making that process a lot quicker). There are lots of websites and blog that will talk/show you through the process. Then you need to select what Database as a Service that you want to setup
OAA is not available on the Database Schema Service just yet (maybe one day they will)
Although Oracle Advanced Analytics comes pre-installed in the Oracle Enterprise Edition database (yes it is a separately priced option) when you install it on your own servers, but for the Enterprise Edition DaaS OAA is not part of it.
DaaS has the following versions
- Standard Edition Service
- Enterprise Edition Service
- High Performance Service
- Extreme Performance Service
OAA is only available for these last two versions of the DaaS.
High Performance DaaS: Multitenant, Partitioning, Real Application Testing, Advanced Compression, Advanced Security, Label Security, Database Vault, OLAP, Advanced Analytics, Spatial and Graph, Diagnostics Pack, Tuning Pack, Database Lifecycle Management Pack, Data Masking & Subsetting Pack and Cloud Management Pack for Oracle Database.
Extreme Performance DaaS: In-Memory Database, RAC (Real Application Clusters), Active Data Guard, Multitenant, Partitioning, Real Application Testing, Advanced Compression, Advanced Security, Label Security, Database Vault, OLAP, Advanced Analytics, Spatial and Graph, Diagnostics Pack, Tuning Pack, Database Lifecycle Management Pack, Data Masking & Subsetting Pack and Cloud Management Pack for Oracle Database.
Oracle Advanced Analytics has two main products or components. The first is the in-database Oracle Data Mining features. This are part of the High Performance and Extreme Performance DaaS offerings. But Oracle R Enterprise is not installed on these DaaS. Well if kind of is if you can get an 11g DaaS, but at time of writing this post ORE is not part of the 12c DaaS images. So you will need to factor in some time to go and install ORE, if you need to use it.
I’ve been lucky to have one of these DaaS with OAA trials and with thanks to Thomas Kurian he has extended these trials to 12 months for all Oracle ACE Directors. Thank you Thomas.
When you get your DaaS setup you just need to configure your connection privileges, ssh, etc and away you go. All you need to do is to move your data across the internet to your own Oracle DaaS, and once it is in the DaaS all your OAA and other analytics is performed on the Database Server. Only the results are returned to you and displayed in your tool. This significantly reduces the processing time for your data and removes the need to constantly extract your data (in whole or in parts) to feed into other advanced analytics tools.
So if you haven’t tried Oracle Advanced Analytics yet, then go ahead and setup your free trial of Oracle DaaS and try it out. You never know what you might discover by using Oracle Advanced Analytics (in the cloud)

Configuring RStudio Server for Oracle R Enterprise
In this blog post I will show you the configurations that are necessary for RStudio Server to work with Oracle R Enterprise on your Oracle Database server. In theory if you have just installed ORE and then RStudio Server, everything should work, but if you encounter any issues then check out the following.
Before I get started make sure to check out my previous blog posts on installing R Studio Server. The first blog post was installing and configuring RStudio Server on the Oracle BigDataLite VM. This is an automated install. The second blog post was a step by step guide to installing RStudio Server on your (Oracle) Linux Database Server and how to open the port on the VM using VirtualBox.
Right. Let’s get back to configuring to work with Oracle R Enterprise. The following assumes you have complete the second blog post mentioned above.
1. Edit the rserver.conf files
Add in the values and locations for RHOME and ORACLE_HOME
sudo vi /etc/rstudio/rserver.conf
rsession-ld-library-path=RHOME/lib:ORACLE_HOME/lib
2. Edit the .Renviron file.
Add in the values for ORACLE_HOME, ORACLE_HOSTNAME and ORACLE_SID
cd /home/oracle
sudo vi .Renviron
ORACLE_HOME=ORACLE_HOME
ORACLE_HOSTNAME=ORACLE_HOSTNAME
ORACLE_SID=ORACLE_SID
export ORACLE_HOME
export ORACLE_HOSTNAME
export ORACLE_SID
3. To access the Oracle R Distribution
Add the following to the usr/lib/rstudio-server/R/modules/SessionHelp.R file for the version of Oracle R Distribution you installed prior to installing Oracle R Enterprise.
.rs.addFunction( "httpdPortIsFunction", function() {
getRversion() >= "3.2"
})
You are all done now with all the installations and configurations.
Recoding variable values using ore.recode
Oracle R Enterprise comes with a vast array of features that not really documented anywhere. One of these features that I’ve recently found useful is the ore.recode() function.
The following code illustrates how you can records the values in an existing attributes or (more specifically in this example) how you can create a new attribute based on the values in another attribute.
The data set that I’m using is the White Wine data set that can be found on the UCI Machine Learning Repository Archive website. You can download this data set and load it into a table in your Oracle schema using just two commands.
> WhiteWine = read.table("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv",
sep=";", header=TRUE)
> ore.create(WhiteWine, table="WHITE_WINE")
This data set has an attribute called “quality”. This “quality” attribute contains values ranging from 2 to 8, and indicates the quality of the wine.
A typical task you may want to do is to relabel values into attributes to something a bit more meaningful or to group some values into a more standardised value.
To demonstrate this I want to create a new attribute that contains a description of the type of wine (and who I might share it with).
In this case, and to allow for other values in future versions of the data sets I’ve coded up the following:
quality grade ------- ---------------- 1 Paint Stripper 2 Vinegar 3 Barely Drinkable 4 For the in-laws 5 For my family 6 To share with friends 7 For cooking 8 To share with my wife 9 Mine all Mine
The next step we need to perform is to gather some information about the values in the “quality” attribute. We can use the table command to quickly perform the aggregations, and then use the marplot function to graph the distributions.
> WHITE_WINE2 table(WHITE_WINE2$quality) > barplot(table(WHITE_WINE2$quality), xlab="Wine Quality Ranking")

Now we are ready to perform the recoding of the values using the ore.recode() function.
> WHITE_WINE2$grade <- ore.recode(WHITE_WINE2$quality, old=c(1, 2, 3, 4, 5, 6, 7, 8, 9),
new=c("1-Paint Stripper", "2-Vinegar", "3-Barely Drinkable",
"4-For the in-laws", "5-For my family", "6-To share with friends",
"7-For cooking", "8-To share with my wife",
"9-Mine all Mine"))
You can now go and inspect the data, perform a frequency count and compare the values with what we had previously.
> head(WHITE_WINE2[,c("quality", "grade")])
> table(WHITE_WINE2$grade)
The final step is to write the newly modified data set back to your Oracle schema into a new table. This is to ensure that the original data is modified so that it can be used or reused later.
> ore.create(WHITE_WINE2, "WHITE_WINE2")

You must be logged in to post a comment.