
Oracle Advanced Analytics
Embedding Transformation Data Pipeline into ML Model using Oracle Data Mining
I’ve written several blog posts about how to use the DBMS_DATA_MINING.TRANSFORM function to create various data transformations and how to apply these to your data. All of these steps can be simple enough to following and re-run in a lab environment. But the real value with data science and machine learning comes when you deploy the models into production and have the ML models scoring data as it is being produced, and your applications acting upon these predictions immediately, and not some hours or days later when the data finally arrives in the lab environment.
It would be useful to be able to bundle all the transformations into the same process the create the model. The transformations and model become one, together. If this is possible, then that greatly simplifies how the ML model can be deployed into production. It then becomes a simple function or REST call. We need to keep this simple (KISS).
Using the examples from my previous blog posts performing various data transformations, the following example shows how you can bundle these up into one defined set of transformations and then embed these transformations as part of the ML model. To do this we need to define a list of transformations. We can do this using:
xform_list IN TRANSFORM_LIST DEFAULT NULL
Where TRANSFORM_LIST has the following structure:
TRANFORM_REC IS RECORD ( attribute_name VARCHAR2(4000), attribute_subname VARCHAR2(4000), expression EXPRESSION_REC, reverse_expression EXPRESSION_REC, attribute_spec VARCHAR2(4000));
You can use the DBMS_DATA_MINING.SET_TRANSFORM function to defined the transformations. The following example illustrates the transformation of converting the BOOKKEEPING_APPLICATION attribute from a number data type to a character data type.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN dbms_data_mining_transform.SET_TRANSFORM(transform_stack, 'BOOKKEEPING_APPLICATION', NULL, 'to_char(BOOKKEEPING_APPLICATION)', 'to_number(BOOKKEEPING_APPLICATION)', NULL); END;
Alternatively you can use the SET_EXPRESSION function and then create the transformation using it.
You can Stack the transforms together. Using the above example you could express a number of transformations and have these stored in the TRANSFORM_STACK variable. You can then pass this variable into your CREATE_MODEL procedure and have these transformations embedded in your ML model.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN -- Define the transformation list dbms_data_mining_transform.SET_TRANSFORM(transform_stack, 'BOOKKEEPING_APPLICATION', NULL, 'to_char(BOOKKEEPING_APPLICATION)', 'to_number(BOOKKEEPING_APPLICATION)', NULL); -- Create the data mining model DBMS_DATA_MINING.CREATE_MODEL( model_name => 'DEMO_TRANSFORM_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MINING_DATA_BUILD_V', case_id_column_name => 'cust_id', target_column_name => 'affinity_card', settings_table_name => 'demo_class_dt_settings', xform_list => transform_stack); END;
My previous blog posts showed how to create various types of transformations. These transformations were then used to create a view of the data set that included these transformations. To embed these transformations in the ML Model we need to use the STACK function. The following examples illustrate the stacking of the transformations created in the previous blog posts. These transformations are added (or stacked) to a transformation list and then added to the CREATE_MODEL function, embedding these transformations in the model.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN -- Stack the missing numeric transformations dbms_data_mining_transform.STACK_MISS_NUM ( miss_table_name => 'TRANSFORM_MISSING_NUMERIC', xform_list => transform_stack); -- Stack the missing categorical transformations dbms_data_mining_transform.STACK_MISS_CAT ( miss_table_name => 'TRANSFORM_MISSING_CATEGORICAL', xform_list => transform_stack); -- Stack the outlier treatment for AGE dbms_data_mining_transform.STACK_CLIP ( clip_table_name => 'TRANSFORM_OUTLIER', xform_list => transform_stack); -- Stack the normalization transformation dbms_data_mining_transform.STACK_NORM_LIN ( norm_table_name => 'MINING_DATA_NORMALIZE', xform_list => transform_stack); -- Create the data mining model DBMS_DATA_MINING.CREATE_MODEL( model_name => 'DEMO_STACKED_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MINING_DATA_BUILD_V', case_id_column_name => 'cust_id', target_column_name => 'affinity_card', settings_table_name => 'demo_class_dt_settings', xform_list => transform_stack); END;
To view the embedded transformations in your data mining model you can use the GET_MODEL_TRANSFORMATIONS function.
SELECT TO_CHAR(expression)
FROM TABLE (dbms_data_mining.GET_MODEL_TRANSFORMATIONS('DEMO_STACKED_MODEL'));
TO_CHAR(EXPRESSION)
--------------------------------------------------------------------------------
(CASE WHEN (NVL("AGE",38.892)<18) THEN 18 WHEN (NVL("AGE",38.892)>70) THEN 70 E
LSE NVL("AGE",38.892) END -18)/52
NVL("BOOKKEEPING_APPLICATION",.880667)
NVL("BULK_PACK_DISKETTES",.628)
NVL("FLAT_PANEL_MONITOR",.582)
NVL("HOME_THEATER_PACKAGE",.575333)
NVL("OS_DOC_SET_KANJI",.002)
NVL("PRINTER_SUPPLIES",1)
(CASE WHEN (NVL("YRS_RESIDENCE",4.08867)<1) THEN 1 WHEN (NVL("YRS_RESIDENCE",4.
08867)>8) THEN 8 ELSE NVL("YRS_RESIDENCE",4.08867) END -1)/7
NVL("Y_BOX_GAMES",.286667)
NVL("COUNTRY_NAME",'United States of America')
NVL("CUST_GENDER",'M')
NVL("CUST_INCOME_LEVEL",'J: 190,000 - 249,999')
NVL("CUST_MARITAL_STATUS",'Married')
NVL("EDUCATION",'HS-grad')
NVL("HOUSEHOLD_SIZE",'3')
NVL("OCCUPATION",'Exec.')
Transforming Outliers in Oracle Data Mining
In previous posts I’ve shown how to use the DBMS_DATA_MINING.TRANSFORM function to transform data is various ways including, normalization and missing data. In this post I’ll build upon these to show how to outliers can be handled.
The following example will show you how you can transform data to identify outliers and transform them. In the example, Winsorsizing transformation is performed where the outlier values are replaced by the nearest value that is not an outlier.
The transformation process takes place in three stages. For the first stage a table is created to contain the outlier transformation data. The second stage calculates the outlier transformation data and store these in the table created in stage 1. One of the parameters to the outlier procedure requires you to list the attributes you do not the transformation procedure applied to (this is instead of listing the attributes you do want it applied to). The third stage is to create a view (MINING_DATA_V_2) that contains the data set with the outlier transformation rules applied. The input data set to this stage can be the output from a previous transformation process (e.g. DATA_MINING_V).
BEGIN -- Clean-up : Drop the previously created tables BEGIN execute immediate 'drop table TRANSFORM_OUTLIER'; EXCEPTION WHEN others THEN null; END; -- Stage 1 : Create the table for the transformations -- Perform outlier treatment for: AGE and YRS_RESIDENCE -- DBMS_DATA_MINING_TRANSFORM.CREATE_CLIP ( clip_table_name => 'TRANSFORM_OUTLIER'); -- Stage 2 : Transform the categorical attributes -- Exclude the number attributes you do not want transformed DBMS_DATA_MINING_TRANSFORM.INSERT_CLIP_WINSOR_TAIL ( clip_table_name => 'TRANSFORM_OUTLIER', data_table_name => 'MINING_DATA_V', tail_frac => 0.025, exclude_list => DBMS_DATA_MINING_TRANSFORM.COLUMN_LIST ( 'affinity_card', 'bookkeeping_application', 'bulk_pack_diskettes', 'cust_id', 'flat_panel_monitor', 'home_theater_package', 'os_doc_set_kanji', 'printer_supplies', 'y_box_games')); -- Stage 3 : Create the view with the transformed data DBMS_DATA_MINING_TRANSFORM.XFORM_CLIP( clip_table_name => 'TRANSFORM_OUTLIER', data_table_name => 'MINING_DATA_V', xform_view_name => 'MINING_DATA_V_2'); END;
The view MINING_DATA_V_2 will now contain the data from the original data set transformed to process missing data for numeric and categorical data (from previous blog post), and also has outlier treatment for the AGE attribute.
Transforming Missing Data using Oracle Data Mining
In a previous post I showed how you can normalize data using the in-database machine learning feature using the DBMS_DATA_MINING.TRANSFORM function. This same function can be used to perform many more data transformations with standardized routines. When it comes to missing data, where you have some case records where the value for an attribute is missing you have a number of options open to you. The first is to evaluate the degree of missing values for the attribute for the data set as a whole. If it is very high, you may want to remove that attribute from the data set. But in scenarios when you have a small number or percentage of missing values you will want to find an appropriate or an approximate value. Such calculations can involve the use of calculating the mean or mode.
To build this up using DBMS_DATA_MINING.TRANSFORM function, we need to follow a simple three stage process. The first stage creates a table that will contain the details of the transformations. The second stage defines and runs the transformation function to calculate the replacement values and finally, the third stage, to create the necessary records in the table created in the previous stage. These final two stages need to be followed for both numerical and categorical attributes. For the final stage you can create a new view that contains the data from the original table and has the missing data rules generated in the second stage applied to it. The following example illustrates these two stages for numerical and categorical attributes in the MINING_DATA_BUILD_V data set.
-- Transform missing data for numeric attributes -- Stage 1 : Clean up, if previous run -- transformed missing data for numeric and categorical -- attributes. BEGIN -- -- Clean-up : Drop the previously created tables -- BEGIN execute immediate 'drop table TRANSFORM_MISSING_NUMERIC'; EXCEPTION WHEN others THEN null; END; BEGIN execute immediate 'drop table TRANSFORM_MISSING_CATEGORICAL'; EXCEPTION WHEN others THEN null; END;
Now for stage 2 to define the functions to calculate the missing values for Numerical and Categorical variables.
-- Stage 2 : Perform the transformations -- Exclude any attributes you don't want transformed -- e.g. the case id and the target attribute -- -- Transform the numeric attributes -- dbms_data_mining_transform.CREATE_MISS_NUM ( miss_table_name => 'TRANSFORM_MISSING_NUMERIC'); dbms_data_mining_transform.INSERT_MISS_NUM_MEAN ( miss_table_name => 'TRANSFORM_MISSING_NUMERIC', data_table_name => 'MINING_DATA_BUILD_V', exclude_list => DBMS_DATA_MINING_TRANSFORM.COLUMN_LIST ( 'affinity_card', 'cust_id')); -- -- Transform the categorical attributes -- dbms_data_mining_transform.CREATE_MISS_CAT ( miss_table_name => 'TRANSFORM_MISSING_CATEGORICAL'); dbms_data_mining_transform.INSERT_MISS_CAT_MODE ( miss_table_name => 'TRANSFORM_MISSING_CATEGORICAL', data_table_name => 'MINING_DATA_BUILD_V', exclude_list => DBMS_DATA_MINING_TRANSFORM.COLUMN_LIST ( 'affinity_card', 'cust_id')); END;
When the above code completes the two transformation tables, TRANSFORM_MISSING_NUMERIC and TRANSFORM_MISSING_CATEGORICAL, will exist in your schema.
Querying these two tables shows the table attributes along with the value to be used to relate the missing value. For example the following illustrates the missing data transformations for the categorical data.
SELECT col, val FROM transform_missing_categorical;
For the sample data set used in these examples we get.
COL VAL ------------------------- ------------------------- CUST_GENDER M CUST_MARITAL_STATUS Married COUNTRY_NAME United States of America CUST_INCOME_LEVEL J: 190,000 - 249,999 EDUCATION HS-grad OCCUPATION Exec. HOUSEHOLD_SIZE 3
For stage three you will need to create a new view (MINING_DATA_V). This combines the data from original table and the missing data rules generated in the second stage applied to it. This is built in stages with an initial view (MINING_DATA_MISS_V) created that merges the data source and the transformations for the missing numeric attributes. This view (MINING_DATA_MISS_V) will then have the transformations for the missing categorical attributes applied to create the a new view called MINING_DATA_V that contains all the missing data transformations.
BEGIN
-- xform input data to replace missing values
-- The data source is MINING_DATA_BUILD_V
-- The output is MINING_DATA_MISS_V
DBMS_DATA_MINING_TRANSFORM.XFORM_MISS_NUM(
miss_table_name => 'TRANSFORM_MISSING_NUMERIC',
data_table_name => 'MINING_DATA_BUILD_V',
xform_view_name => 'MINING_DATA_MISS_V');
-- xform input data to replace missing values
-- The data source is MINING_DATA_MISS_V
-- The output is MINING_DATA_V
DBMS_DATA_MINING_TRANSFORM.XFORM_MISS_CAT(
miss_table_name => 'TRANSFORM_MISSING_CATEGORICAL',
data_table_name => 'MINING_DATA_MISS_V',
xform_view_name => 'MINING_DATA_V');
END;
You can now query the MINING_DATA_V view and see that the data displayed will not contain any null values for any of the attributes.
Time Series Forecasting in Oracle – Part 2
This is the second part about time-series data modeling using Oracle. Check out the first part here.
In this post I will take a time-series data set and using the in-database time-series functions model the data, that in turn can be used for predicting future values and trends.
The data set used in these examples is the Rossmann Store Sales data set. It is available on Kaggle and was used in one of their competitions.
Let’s start by aggregating the data to monthly level. We get.
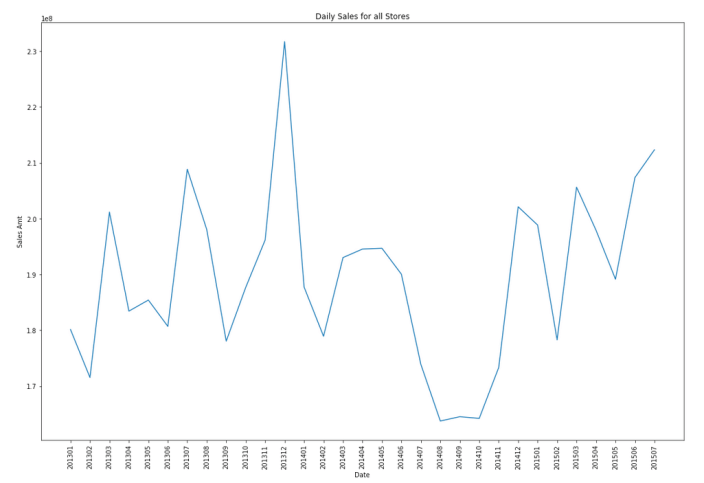
Data Set-up
Although not strictly necessary, but it can be useful to create a subset of your time-series data to only contain the time related attribute and the attribute containing the data to model. When working with time-series data, the exponential smoothing function expects the time attribute to be of DATE data type. In most cases it does. When it is a DATE, the function will know how to process this and all you need to do is to tell the function the interval.
A view is created to contain the monthly aggregated data.
-- Create input time series create or replace view demo_ts_data as select to_date(to_char(sales_date, 'MON-RRRR'),'MON-RRRR') sales_date, sum(sales_amt) sales_amt from demo_time_series group by to_char(sales_date, 'MON-RRRR') order by 1 asc;
Next a table is needed to contain the various settings for the exponential smoothing function.
CREATE TABLE demo_ts_settings(setting_name VARCHAR2(30),
setting_value VARCHAR2(128));
Some care is needed with selecting the parameters and their settings as not all combinations can be used.
Example 1 – Holt-Winters
The first example is to create a Holt-Winters time-series model for hour data set. For this we need to set the parameter to include defining the algorithm name, the specific time-series model to use (exsm_holt), the type/size of interval (monthly) and the number of predictions to make into the future, pass the last data point.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- set ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_holt);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
commit;
END;
Now we can call the function, generate the model and produce the predicted values.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
When the model is created a number of data dictionary views are populated with model details and some addition views are created specific to the model. One such view commences with DM$VP. Views commencing with this contain the predicted values for our time-series model. You need to append the name of the model created, in our example DEMO_TS_MODEL.
-- get predictions select case_id, value, prediction, lower, upper from DM$VPDEMO_TS_MODEL order by case_id;
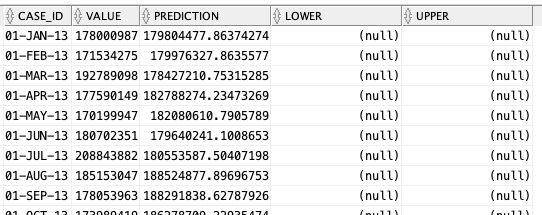
When we plot this data we get.
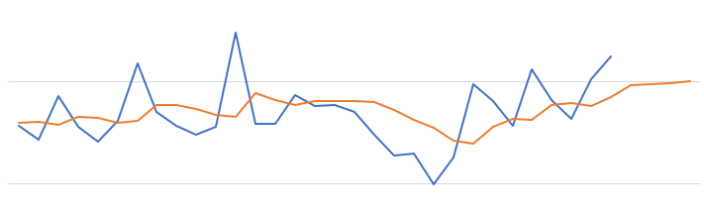
The blue line contains the original data values and the red line contains the predicted values. The predictions are very similar to those produced using Holt-Winters in Python.

Example 2 – Holt-Winters including Seasonality
The previous example didn’t really include seasonality into the model and predictions. In this example we introduce seasonality to allow the model to pick up any trends in the data based on a defined period.
For this example we will change the model name to HW_ADDSEA, and the season size to 5 units. A data set with a longer time period would illustrate the different seasons better but this gives you an idea.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- select ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters Seasonal Adjusted
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_HW_ADDSEA);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
-- set seasonal cycle to be 5 quarters
insert into demo_ts_settings
values (dbms_data_mining.exsm_seasonality,
'5');
commit;
END;
We need to re-run the creation of the model and produce the predicted values. This code is unchanged from the previous example.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
When we re-query the DM$VPDEMO_TS_MODEL we get the new values. When plotted we get.
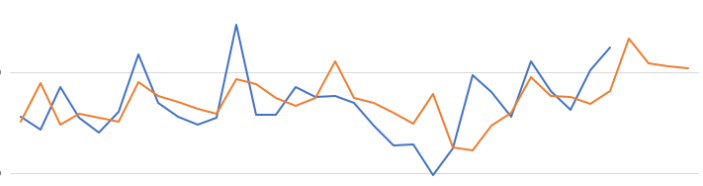
The blue line contains the original data values and the red line contains the predicted values.
Comparing this chart to the chart from the first example we can see there are some important differences between them. These differences are particularly evident in the second half of the chart, on the right hand side. We get to see there is a clearer dip in the predicted data. This mirrors the real data values better. We also see better predictions as the time line moves to the end.
When performing time-series analysis you really need to spend some time exploring the data, to understand what is happening, visualizing the data, seeing if you can identify any patterns, before moving onto using the different models. Similarly you will need to explore the various time-series models available and the parameters, to see what works for your data and follow the patterns in your data. There is no magic solution in this case.
Time Series Forecasting in Oracle – Part 1
Time-series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. In this blog post I’ll introduce what time-series analysis is, the different types of time-series analysis and introduce how you can do this using SQL and PL/SQL in Oracle Database. I’ll have additional blog posts giving more detailed examples of Oracle functions and how they can be used for different time-series data problems.
Time-series forecasting is the use of a model to predict future values based on previously observed/historical values. It is a form of regression analysis with additions to facilitate trends, seasonal effects and various other combinations.

Time-series forecasting is not an exact science but instead consists of a set of statistical tools and techniques that support human judgment and intuition, and only forms part of a solution. It can be used to automate the monitoring and control of data flows and can then indicate certain trends, alerts, rescheduling, etc., as in most business scenarios it is used for predict some future customer demand and/or products or services needs.
Typical application areas of Time-series forecasting include:
- Operations management: forecast of product sales; demand for services
- Marketing: forecast of sales response to advertisement procedures, new promotions etc.
- Finance & Risk management: forecast returns from investments
- Economics: forecast of major economic variables, e.g. GDP, population growth, unemployment rates, inflation; useful for monetary & fiscal policy; budgeting plans & decisions
- Industrial Process Control: forecasts of the quality characteristics of a production process
- Demography: forecast of population; of demographic events (deaths, births, migration); useful for policy planning
When working with time-series data we are looking for a pattern or trend in the data. What we want to achieve is the find a way to model this pattern/trend and to then project this onto our data and into the future. The graphs in the following image illustrate examples of the different kinds of scenarios we want to model.



Most time-series data sets will have one or more of the following components:
- Seasonal: Regularly occurring, systematic variation in a time series according to the time of year.
- Trend: The tendency of a variable to grow over time, either positively or negatively.
- Cycle: Cyclical patterns in a time series which are generally irregular in depth and duration. Such cycles often correspond to periods of economic expansion or contraction. Also know as the business cycle.
- Irregular: The Unexplained variation in a time series.
When approaching time-series problems you will use a combination of visualizations and time-series forecasting methods to examine the data and to build a suitable model. This is where the skills and experience of the data scientist becomes very important.
Oracle provided a algorithm to support time-series analysis in Oracle 18c. This function is called Exponential Smoothing. This algorithm allows for a number of different types of time-series data and patterns, and provides a wide range of statistical measures to support the analysis and predictions, in a similar way to Holt-Winters.
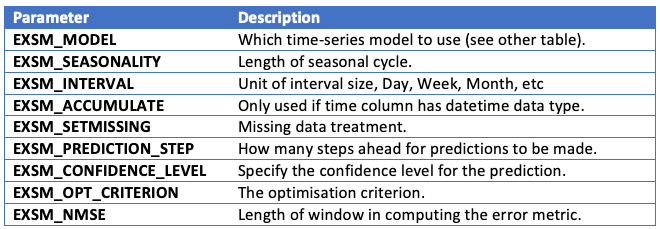
The first parameter for the Exponential Smoothing function is the name of the model to use. Oracle provides a comprehensive list of models and these are listed in the following table.
Check out my other blog posts on performing time-series analysis using the Exponential Smoothing function in Oracle Database. These will give more detailed examples of how the Oracle time-series functions, using the Exponential Smoothing algorithm, can be used for different time-series data problems. I’ll also look at example of the different configurations.
How long does it take to build a Machine Learning model using Oracle Cloud
Everyday someone talks about the the processing power needed for Machine Learning, and the vast computing needed for these tasks. It has become evident that most of these people have never created a machine learning model. Never. But like to make up stuff and try to make themselves look like an expert, or as I and others like to call them a “fake expert”.
When you question these “fake experts” about this topic, they huff and puff about lots of things and never answer the question or try to claim it is so difficult, you simply don’t understand.
Having worked in the area of machine learning for a very very long time, I’ve never really had performance issues with creating models. Yes most of the time I’ve been able to use my laptop. Yes my laptop to build models large models. In a couple of these my laptop couldn’t cope and I moved onto a server.
But over the past few years we keep hearing about using cloud services for machine learning. If you are doing machine learning you need to computing capabilities that are available with cloud services.
So, the results below show the results of building machine learning models, using different algorithms, with different sizes of data sets.
For this test, I used a basic cloud service. Well maybe it isn’t basic, but for others they will consider it very basic with very little compute involved.
I used an Oracle Cloud DBaaS for this experiment. I selected an Oracle 18c Extreme edition cloud service. This comes with the in-database machine learning option. This comes with 1 OCPUs, 7.5G Memory and 170GB storage. This is the basic configuration.
Next I created data sets with different sizes. These were based on one particular data set, as this ensures that as the data set size increases, the same kind of data and processing required remained consistent, instead of using completely different data sets.
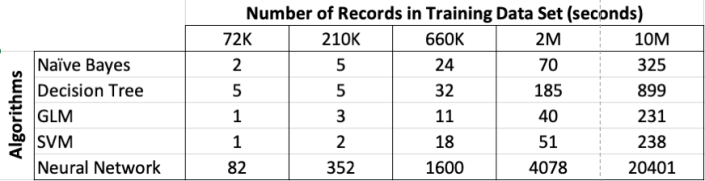
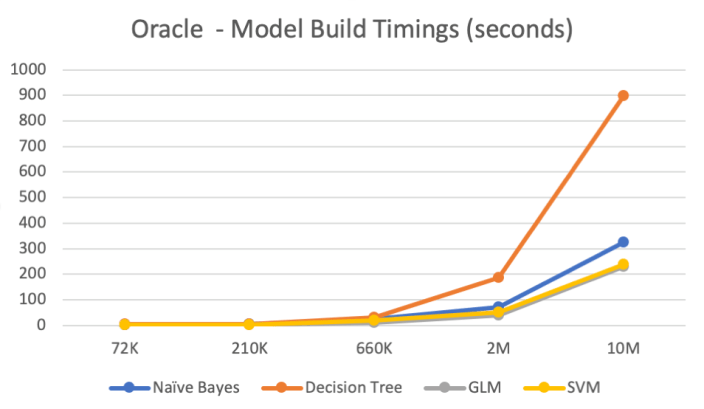
The data set consisted of the following number of records, 72K, 660K, 210K, 2M, 10M and 50M.
I then created machine learning models using Decisions Tree, Naive Bayes, Support Vector Machine, Generaliszd Linear Models (GLM) and Neural Networks. Yes it was a typical classification problem.
The following table below shows the length of time in seconds to build the models. All data preparations etc was done prior to this.
Note: It should be noted that Automatic Data Preparation was turned on for these algorithms. This performed additional algorithm specific data preparation for each model. That means the times given in the following tables is for some data preparation time and for building the models.
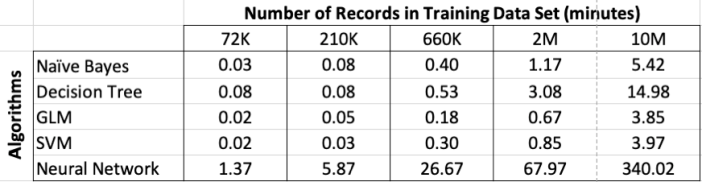
Converting the above table into minutes.
Oracle 18c New Oracle Advanced Analytics (Machine Learning) features
With each release of the Oracle Database we get new Machine Learning features, under the umbrella term of Oracle Advanced Analytics option (OAA).
With Oracle 18c we get the following new features, that include new machine learning algorithms, improvements to machine learning algorithms, and meta-data improvements for registering new R based algorithms.
These new OAA features include:
New Time-Series function : This new function forecasts target value based solely on a known history of target values and uses the popular auto-regressive modelling method.
New Model Detail Views : Previously you could inspect the details of a model using a function. This is being phased out and replaced by model view, with the format DM$VA
New Neural Networks Algorithm : With the growing interest in deep learning, Oracle have now included a neural network algorithm into the database, thus providing SQL and PL/SQL interfaces to all for easy of use and easy of integration into applications.
New Random Forest Algorithm : Random Forests has been proven over the past few years to be very accurate for certain types of classification problems. This algorithm has now been included in the database, with SQL and PL/SQL interfaces.
Improved Sampling for Association Rules : A new specialised sampling approach is introduced for Association Rules. This is to improve performance, while maintaining accuracy, for large/big data sets.
Algorithm Meta Data Registration : Simplifies the integration of new algorithms in the R extensibility framework. This feature allows a uniform consistent approach of registering new algorithm functions and their settings.
New Exponential Smoothing Algorithm : This allows for users to make predictions from time series data, and includes 14 models, including the popular Holt (trend) and Holt-Winters (trend and seasonality) models, and the ability to handle irregular time series intervals.
New CUR Decomposition-based Algorithm for Attribute and Row Importance : Most algorithms focus on identifying columns or rows that are important within their data sets. This algorithm has the added feature of also identifying important rows.
As you can see there are a lot of machine learning new features in Oracle 18c. Each one of these new features will be explored in more detail in separate blog posts.
How to speed up your Oracle Data Mining with in-memory and parallel
Have you have found running a workflow in Oracle Data Miner slow or running the scripts in the database slow ?
No. Good, because I haven’t found it slow.
But (there is always a but) it really depends on the volume of data your are dealing with. For the vast majority of us who aren’t of the size of google, amazon, etc have data volumes that are not that large really and a basic server can process many millions of records extremely quickly using Oracle Data Mining.
But what if we have a large volume of data. In one recent project I had a data set containing over 3.5 billion records. Now that is big data. All of this data sitting in an Oracle Database.
So how can we process over 3.5 billion records in a couple of seconds, building 4 machine learning models in that time? Is that really possible with just using an Oracle Database? Yes is the answer and very easily. (Surely I needed Hadoop and Spark to process this data? Nope!)
The Oracle Data Miner (ODMr) tool comes with a new feature in SQL Developer 4 (and higer) that allows you to manage using Parallel execution and the in-memory DB features. These can be accessed on the ODMr Worksheet tool bar.

The best time to look at these setting is when you have created your workflow and are ready to run it for the first time. When you click on the ‘Performance Options’ link, you will get the following window. It will display the list of nodes you have in the workflow and will then indicate if the Degree of Parallel and the In-Memory options can be set for each of the nodes.

The default values are shown and you can changes these. For example, in a lot of scenarios you might prefer to leave the Degree of Parallel as System Determined. This will then use whatever the the default is for the database and controlled by the DBA, but if you want to specify a particular value then you can, for example setting the degree of parallel to 4 for the ‘Class Build’ node, in the above image. Similarly for the in-memory option, this will only be available for nodes where the in-memory option would be applicable. This will be where there is a lot of data processing (preparing data, transforming data, performing specific statistics, etc) and for storing any data that is generated by Oracle Data Mining.
But what if you want to change the default values. You can change these at a global level within the SQL Developer Preferences. Here you can set the default to be used for each of the different types of Oracle Data Mining nodes.

I mentioned at the start that I’ve been able to build 4 machine learning models using Oracle Data Mining on a data set of over 3.5 billion records, all in a couple of seconds. In my scenario Parallel was set to 16 and we didn’t use in-memory as we didn’t have the licence for it. You can see that machine learning at lighting speed (ish) is possible. This timing is only for building the models, which is the step that consumes the most about of resources and time. When it comes to scoring the data, that is lighting fast. In may scenario, scoring over 300,000 was less than a second, and I didn’t use parallel or anything else to speed things up. Because we didn’t need to.
Go give it a try!
Scheduling ODMr Workflows in SQL Developer 4.2+
A new feature for Oracle Data Mining (ODM) (part of SQL Developer 4.2) is the ability to schedule an ODM workflow to run a defined time or frequency.
This blog post will bring you through the steps need to schedule an ODM workflow using this new feature.
The first thing that you need is an ODMr workflow. The following image is a familiar looking one that I typically use to get a very quick demo of how easy it is to build a machine learning workflow.

Just above the workflow worksheet we have a row of icon buttons. In the above image one of these is highlighted by a red box. This is the workflow scheduler. So go ahead on click on it.

In most cases you will want to run the entire workflow. The default option presented to is ‘All Nodes’. If you would only like a subset of the nodes to run, you can click-on or select the node in the workflow and then click on the scheduler icon. In our example we are going to run the entire workflow, so select ‘All Nodes’ from the menu.

The main scheduler window will open. Here you can set the Start Date and time of the first run, what the Repeat frequency is (none, every day, every week or custom) and to End the Repeat (Never, After, On Date). To schedule a once off run of the workflow just set the Date and Time, set the Repeat to ‘None’ and End Repeat should disappear in this instance. If Repeat was set to another value then you can set a value for End Repeat.
Go ahead and run the scheduler by clicking on the OK button.

A Scheduled Jobs window should open that will display the details of the scheduled job. When this job is run in the database, this will be shown in the Workflow Jobs window. Here you can see and monitor the progress of the of the workflow.

and that’s it. Nice an simple.
But there is a something you needed to be WARNED about. When you schedule a workflow, Oracle Data Miner will lock the workflow. This is to ensure that no changes can be made to the scheduled workflow. This is indicated with the Locked button appearing on the icon menu. If you click on this button to unlock the workflow, it will also cancel your scheduled jobs associated with this workflow.

Also when the scheduled workflow is finished, the workflow will remain locked. So you will have to click on this Locked button to unlock the workflow.
There are a few additional advanced features. These can be found by clicking on the ‘Advanced…’ button in the main scheduler window. The first table displayed allows you to specify if you want an email sent for the different stages of the scheduled job. The second tab allows you to set the Job Priority, Max Failures, Max Run Duration and Schedule Limits.

ODM Model View Details Views in Oracle 12.2
A new feature for Oracle Data Mining in Oracle 12.2 is the new Model Details views.
In Oracle 11.2.0.3 and up to Oracle 12.1 you needed to use a range of PL/SQL functions (in DBMS_DATA_MINING package) to inspect the details of a data mining/machine learning model using SQL.
Check out these previous blog posts for some examples of how to use and extract model details in Oracle 12.1 and earlier versions of the database
Association Rules in ODM-Part 3
Extracting the rules from an ODM Decision Tree model
Instead of these functions there are now a lot of DB views available to inspect the details of a model. The following table summarises these various DB Views. Check out the DB views I’ve listed after the table, as these views might some some of the ones you might end up using most often.
I’ve now chance of remembering all of these and this table is a quick reference for me to find the DB views I need to use. The naming method used is very confusing but I’m sure in time I’ll get the hang of them.
NOTE: For the DB Views I’ve listed in the following table, you will need to append the name of the ODM model to the view prefix that is listed in the table.
table, th, td {
border: 1px solid black;
border-collapse: collapse;
text-align: left;
}
| Data Mining Type | Algorithm & Model Details | 12.2 DB View | Description |
|---|---|---|---|
| Association | Association Rules | DM$VR | generated rules for Association Rules |
| Frequent Itemsets | DM$VI | describes the frequent itemsets | |
| Transaction Itemsets | DM$VT | describes the transactional itemsets view | |
| Transactional Rules | DM$VA | describes the transactional rule view and transactional itemsets | |
| Classification | (General views for Classification models) | DM$VT
DM$VC |
describes the target distribution for Classification models
describes the scoring cost matrix for Classification models |
| Decision Tree | DM$VP
DM$VI DM$VO DM$VM |
describes the DT hierarchy & the split info for each level in DT
describes the statistics associated with individual tree nodes Higher level node description describes the cost matrix used by the Decision Tree build |
|
| Generalized Linear Model | DM$VD
DM$VA |
describes model info for Linear Regres & Logistic Regres
describes row level info for Linear Regres & Logistic Regres |
|
| Naive Bayes | DM$VP
DM$VV |
describes the priors of the targets for Naïve Bayes
describes the conditional probabilities of Naïve Bayes model |
|
| Support Vector Machine | DM$VL | describes the coefficients of a linear SVM algorithm | |
| Regression ??? | Doe | 80 | 50 |
| Clustering | (General views for Clustering models) | DM$VD
DM$VA DM$VH DM$VR |
Cluster model description
Cluster attribute statistics Cluster historgram statistics Cluster Rule statistics |
| k-Means | DM$VD
DM$VA DM$VH DM$VR |
k-Means model description
k-Means attribute statistics k-Means historgram statistics k-Means Rule statistics |
|
| O-Cluster | DM$VD
DM$VA DM$VH DM$VR |
O-Cluster model description
O-Cluster attribute statistics O-Cluster historgram statistics O-Cluster Rule statistics |
|
| Expectation Minimization | DM$VO
DM$VB DM$VI DM$VF DM$VM DM$VP |
describes the EM components
the pairwise Kullback–Leibler divergence attribute ranking similar to that of Attribute Importance parameters of multi-valued Bernoulli distributions mean & variance parameters for attributes by Gaussian distribution the coefficients used by random projections to map nested columns to a lower dimensional space |
|
| Feature Extraction | Non-negative Matrix Factorization | DM$VE
DM$VI |
Encoding (H) of a NNMF model
H inverse matrix for NNMF model |
| Singular Value Decomposition | DM$VE
DM$VV DM$VU |
Associated PCA information for both classes of models
describes the right-singular vectors of SVD model describes the left-singular vectors of a SVD model |
|
| Explicit Semantic Analysis | DM$VA
DM$VF |
ESA attribute statistics
ESA model features |
|
| Feature Section | Minimum Description Length | DM$VA | describes the Attribute Importance as well as the Attribute Importance rank |
Normalizing and Error Handling views created by ODM Automatic Data Processing (ADP)
- DM$VN : Normalization and Missing Value Handling
- DM$VB : Binning
Global Model Views
- DM$VG : Model global statistics
- DM$VS : Computed model settings
- DM$VW :Alerts issued during model creation
Each one of these new DB views needs their own blog post to explain what informations is being explained in each. I’m sure over time I will get round to most of these.
Managing memory allocation for Oracle R Enterprise Embedded Execution
When working with Oracle R Enterprise and particularly when you are using the ORE functions that can spawn multiple R processes, on the DB Server, you need to be very aware of the amount of memory that will be consumed for each call of the ORE function.
ORE has two sets of parallel functions for running your user defined R scripts stored in the database, as part of the Embedded R Execution feature of ORE. The R functions are called ore.groupApply, ore.rowApply and ore.indexApply. When using SQL there are “rqGroupApply” and rqRowApply. (There is no SQL function equivalent of the R function ore.indexApply)
For each parallel R process that is spawned on the DB server a certain amount of memory (RAM) will be allocated to this R process. The default size of memory to be allocated can be found by using the following query.
select name, value from sys.rq_config; NAME VALUE ----------------------------------- ----------------------------------- VERSION 1.5 MIN_VSIZE 32M MAX_VSIZE 4G MIN_NSIZE 2M MAX_NSIZE 20M
The memory allocation is broken out into the amount of memory allocated for Cells and NCells for each R process.
If your parallel ORE function create a large number of parallel R processes then you can see that the amount of overall memory consumed can be significant. I’ve seen a few customers who very quickly run out of memory on their DB servers. Now that is something you do not want to happen.
How can you prevent this from happening ?
There are a few things you need to keep in mind when using the parallel enabled ORE functions. The first one is, how many R processes will be spawned. For most cases this can be estimated or calculated to a high degree of accuracy. Secondly, how much memory will be used to process each of the R processes. Thirdly, how memory do you have available on the DB server. Fourthly, how many other people will be running parallel R processes at the same time?
Examining and answering each of these may look to be a relatively trivial task, but the complexity behind these can increase dramatically depending on the answer to the fourth point/question above.
To calculate the amount of memory used during the ORE user defined R script, you can use the R garbage function to calculate the memory usage at the start and at the end of the R script, and then return the calculated amount. Yes you need to add this extra code to your R script and then remove it when you have calculated the memory usage.
gc.start <- gc(reset=TRUE) ... gc.end <- gc() gc.used <- gc.end[,7] - gc.start[,7] # amount consumed by the processing
Using this information and the answers to the points/questions I listed above you can now look at calculating how much memory you need to allocated to the R processes. You can set this to be static for all R processes or you can use some code to allocate the amount of memory that is needed for each R process. But this starts to become messy. The following gives some examples (using R) of changing the R memory allocations in the Oracle Database. Similar commands can be issued using SQL.
> sys.rqconfigset('MIN_VSIZE', '10M') -- min heap 10MB, default 32MB
> sys.rqconfigset('MAX_VSIZE', '100M') -- max heap 100MB, default 4GB
> sys.rqconfigset('MIN_NSIZE', '500K') -- min number cons cells 500x1024, default 1M
> sys.rqconfigset('MAX_NSIZE', '2M') -- max number cons cells 2M, default 20M
Some guidelines – as with all guidelines you have to consider all the other requirements for the Database, and in reality you will have to try to find a balance between what is listed here and what is actually possible.
- Set parallel_degree_policy to MANUAL.
- Set parallel_min_servers to the number of parallel slave processes to be started when the database instances start, this avoids start up time for the R processes. This is not a problem for long running processes. But can save time with processes running for 10s seconds
- To avoid overloading the CPUs if the parallel_max_servers limit is reached, set the hidden parameter _parallel_statement_queuing to TRUE. Avoids overloading and lets processes wait.
- Set application tables and their indexes to DOP 1 to reinforce the ability of ORE to determine when to use parallelism.
Understanding the memory requirements for your ORE processes can be tricky business and can take some time to work out the right balance between what is needed by the spawned parallel R processes and everything else that is going on in the Database. There will be a lot of trial and error in working this out and it is always good to reach out for some help. If you have a similar scenario and need some help or guidance let me know.
OUG Ireland 2017 Presentation
Here are the slides from my presentation at OUG Ireland 2017. All about running R using SQL.

You must be logged in to post a comment.