
Month: October 2022
Number of rows in each Table – Various Databases
A possible common task developers perform is to find out how many records exists in every table in a schema. In the examples below I’ll show examples for the current schema of the developer, but these can be expanded easily to include tables in other schemas or for all schemas across a database.
These example include the different ways of determining this information across the main databases including Oracle, MySQL, Postgres, SQL Server and Snowflake.
A little warning before using these queries. They may or may not give the true accurate number of records in the tables. These examples illustrate extracting the number of records from the data dictionaries of the databases. This is dependent on background processes being run to gather this information. These background processes run from time to time, anything from a few minutes to many tens of minutes. So, these results are good indication of the number of records in each table.
Oracle
SELECT table_name, num_rows
FROM user_tables
ORDER BY num_rows DESC;or
SELECT table_name,
to_number(
extractvalue(xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name))
,'/ROWSET/ROW/C')) tab_count
FROM user_tables
ORDER BY tab_count desc;Using PL/SQL we can do something like the following.
DECLARE
val NUMBER;
BEGIN
FOR i IN (SELECT table_name FROM user_tables ORDER BY table_name desc) LOOP
EXECUTE IMMEDIATE 'SELECT count(*) FROM '|| i.table_name INTO val;
DBMS_OUTPUT.PUT_LINE(i.table_name||' -> '|| val );
END LOOP;
END;MySQL
SELECT table_name, table_rows
FROM INFORMATION_SCHEMA.TABLES
WHERE table_type = 'BASE TABLE'
AND TABLE_SCHEMA = current_user();
Using Common Table Expressions (CTE), using WITH clause
WITH table_list AS (
SELECT
table_name
FROM information_schema.tables
WHERE table_schema = current_user()
AND
table_type = 'BASE TABLE'
)
SELECT CONCAT(
GROUP_CONCAT(CONCAT("SELECT '",table_name,"' table_name,COUNT(*) rows FROM ",table_name) SEPARATOR " UNION "),
' ORDER BY table_name'
)
INTO @sql
FROM table_list;
Postgres
select relname as table_name, n_live_tup as num_rows from pg_stat_user_tables;
An alternative is
select n.nspname as table_schema,
c.relname as table_name,
c.reltuples as rows
from pg_class c
join pg_namespace n on n.oid = c.relnamespace
where c.relkind = 'r'
and n.nspname = current_user
order by c.reltuples desc;
SQL Server
SELECT tab.name,
sum(par.rows)
FROM sys.tables tab INNER JOIN sys.partitions par
ON tab.object_id = par.object_id
WHERE schema_name(tab.schema_id) = current_user
Snowflake
SELECT t.table_schema, t.table_name, t.row_count
FROM information_schema.tables t
WHERE t.table_type = 'BASE TABLE'
AND t.table_schema = current_user
order by t.row_count desc;
The examples give above are some of the ways to obtain this information. As with most things, there can be multiple ways of doing it, and most people will have their preferred one which is based on their background and preferences.
As you can see from the code given above they are all very similar, with similar syntax, etc. The only thing different is the name of the data dictionary table/view containing the information needed. Yes, knowing what data dictionary views to query can be a little challenging as you switch between databases.
AUTO_PARTITION – Inspecting & Implementing Recommendations
In a previous blog post I gave an overview of the DBMS_AUTO_PARTITION package in Oracle Autonomous Database. This looked at how you can get started and to setup Auto Partitioning and to allow it to automatically implement partitioning.
This might not be something the DBAs will want to happen for lots of different reasons. An alternative is to use DBMS_AUTO_PARTITION to make recommendations for tables where partitioning will have a performance improvement. The DBA can inspect these recommendations and decide which of these to implement.
In the previous post we set the CONFIGURE function to be ‘IMPLEMENT’. We need to change that to report the recommendations.
exec dbms_auto_partition.configure('AUTO_PARTITION_MODE','REPORT ONLY');Just remember, tables will only be considered by AUTO_PARTITION as outlined in my previous post.
Next we can ask for recommendations using the RECOMMEND_PARTITION_METHOD function.
exec dbms_auto_partition.recommend_partition_method(
table_owner => 'WHISKEY',
table_name => 'DIRECTIONS',
report_type => 'TEXT',
report_section => 'ALL',
report_level => 'ALL');The results from this are stored in DBA_AUTO_PARTITION_RECOMMENDATIONS, which you can query to view the recommendations.
select recommendation_id, partition_method, partition_key
from dba_auto_partition_recommendations;RECOMMENDATION_ID PARTITION_METHOD PARTITION_KEY
-------------------------------- ------------------------------------------------------------------------------------------------------------- --------------
D28FC3CF09DF1E1DE053D010000ABEA6 Method: LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL '2' MONTH, TIMESTAMP '2019-08-10 00:00:00')) AUTOMATIC D
To apply the recommendation pass the RECOMMENDATION_KEY value to the APPLY_RECOMMENDATION function.
exec dbms_auto_partition.apply_recommendation('D28FC3CF09DF1E1DE053D010000ABEA6');It might takes some minutes for the partitioned table to become available. During this time the original table will remain available as the change will be implemented using a ALTER TABLE MODIFY PARTITION ONLINE command.
Two other functions include REPORT_ACTIVITY and REPORT_LAST_ACTIVITY. These can be used to export a detailed report on the recommendations in text or HTML form. It is probably a good idea to create and download these for your change records.
spool autoPartitionFinding.html
select dbms_auto_partition.report_last_activity(type=>'HTML') from dual;
exit;AUTO_PARTITION – Basic setup
Partitioning is an effective way to improve performance of SQL queries on large volumes of data in a database table. But only so, if a bit of care and attention is taken by both the DBA and Developer (or someone with both of these roles). Care is needed on the database side to ensure the correct partitioning method is deployed and the management of these partitions, as some partitioning methods can create a significantly large number of partitions, which in turn can affect the management of these and possibly performance too, which is not what you want. Care is also needed from the developer side to ensure their code is written in a way that utilises the partitioning method deployed. If doesn’t then you may not see much improvement in performance of your queries, and somethings things can run slower. Which not one wants!
With the Oracle Autonomous Database we have the expectation it will ‘manage’ a lot of the performance features behind the scenes without the need for the DBA and Developing getting involved (‘Autonomous’). This is kind of true up to a point, as the serverless approach can work up to a point. Sometimes a little human input is needed to give a guiding hand to the Autonomous engine to help/guide it towards what data needs particular focus.
In this (blog post) case we will have a look at DBMS_AUTO_PARTITION and how you can do a basic setup, config and enablement. I’ll have another post that will look at the recommendation feature of DBMS_AUTO_PARTITION. Just a quick reminder, DBMS_AUTO_PARTITION is for the Oracle Autonomous Database (ADB) (on the Cloud). You’ll need to run the following as ADMIN user.
The first step is to enable auto partitioning on the ADB using the CONFIGURE function. This function can have three parameters:
- IMPLEMENT : generates a report and implements the recommended partitioning method. (Autonomous!)
- REPORT_ONLY : {default} reports recommendations for partitioning on tables
- OFF : Turns off auto partitioning (reporting and implementing)
For example, to enable auto partitioning and to automatically implement the recommended partitioning method.
exec DBMS_AUTO_PARTITION.CONFIGURE('AUTO_PARTITION_MODE', 'IMPLEMENT');The changes can be inspected in the DBA_AUTO_PARTITION_CONFIG view.
SELECT * FROM DBA_AUTO_PARTITION_CONFIG;When you look at the listed from the above select we can see IMPLEMENT is enabled

The next step with using DBMS_AUTO_PARTITION is to tell the ADB what schemas and/or tables to include for auto partitioning. This first example shows how to turn on auto partitioning for a particular schema, and to allow the auto partitioning (engine) to determine what is needed and to just go and implement that it thinks is the best partitioning methods.
exec DBMS_AUTO_PARTITION.CONFIGURE(
parameter_name => 'AUTO_PARTITION_SCHEMA',
parameter_value => 'WHISKEY',
ALLOW => TRUE);If you query the DBA view again we now get.

We have not enabled a schema (called WHISKEY) to be included as part of the auto partitioning engine.
Auto Partitioning may not do anything for a little while, with some reports suggesting to wait for 15 minutes for the database to pick up any changes and to make suggestions. But there are some conditions for a table needs to meet before it can be considered, this is referred to as being a ‘Candidate’. These conditions include:
- Table passes inclusion and exclusion tests specified by AUTO_PARTITION_SCHEMA and AUTO_PARTITION_TABLE configuration parameters.
- Table exists and has up-to-date statistics.
- Table is at least 64 GB.
- Table has 5 or more queries in the SQL tuning set that scanned the table.
- Table does not contain a LONG data type column.
- Table is not manually partitioned.
- Table is not an external table, an internal/external hybrid table, a temporary table, an index-organized table, or a clustered table.
- Table does not have a domain index or bitmap join index.
- Table is not an advance queuing, materialized view, or flashback archive storage table.
- Table does not have nested tables, or certain other object features.
If you find Auto Partitioning isn’t partitioning your tables (i.e. not a valid Candidate) it could be because the table isn’t meeting the above list of conditions.
This can be verified using the VALIDATE_CANDIDATE_TABLE function.
select DBMS_AUTO_PARTITION.VALIDATE_CANDIDATE_TABLE(
table_owner => 'WHISKEY',
table_name => 'DIRECTIONS')
from dual;If the table has met the above list of conditions, the above query will return ‘VALID’, otherwise one or more of the above conditions have not been met, and the query will return ‘INVALID:’ followed by one or more reasons
Check out my other blog post on using the AUTO_PARTITION to explore it’s recommendations and how to implement.
Postgres on Docker
Prostgres is one of the most popular databases out there, being used in Universities, open source projects and also widely used in the corporate marketplace. I’ve written a previous post on running Oracle Database on Docker. This post is similar, as it will show you the few simple steps to have a persistent Postgres Database running on Docker.
The first step is go to Docker Hub and locate the page for Postgres. You should see something like the following. Click through to the Postgres page.

There are lots and lots of possible Postgres images to download and use. The simplest option is to download the latest image using the following command in a command/terminal window. Make sure Docker is running on your machine before running this command.
docker pull postgresAlthough, if you needed to install a previous release, you can do that.

After the docker image has been downloaded, you can now import into Docker and create a container.
docker run --name postgres -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=pgPassword -e POSTGRES_DB=postgres -d postgresImportant: I’m using Docker on a Mac. If you are using Windows, the format of the parameter list is slightly different. For example, remove the = symbol after POSTGRES_DB
If you now check with Docker you’ll see Postgres is now running on post 5432.

Next you will need pgAdmin to connect to the Postgres Database and start working with it. You can download and install it, or run another Docker container with pgAdmin running in it.
First, let’s have a look at installing pgAdmin. Download the image and run, accepting the initial requirements. Just let it run and finish installing.


When pgAdmin starts it looks for you to enter a password. This can be anything really, but one that you want to remember. For example, I set mine to pgPassword.
Then create (or Register) a connection to your Postgres Database. Enter the details you used when creating the docker image including username=postgres, password=pgPassword and IP address=0.0.0.0.
The IP address on your machine might be a little different, and to check what it is, run the following
docker ps -a


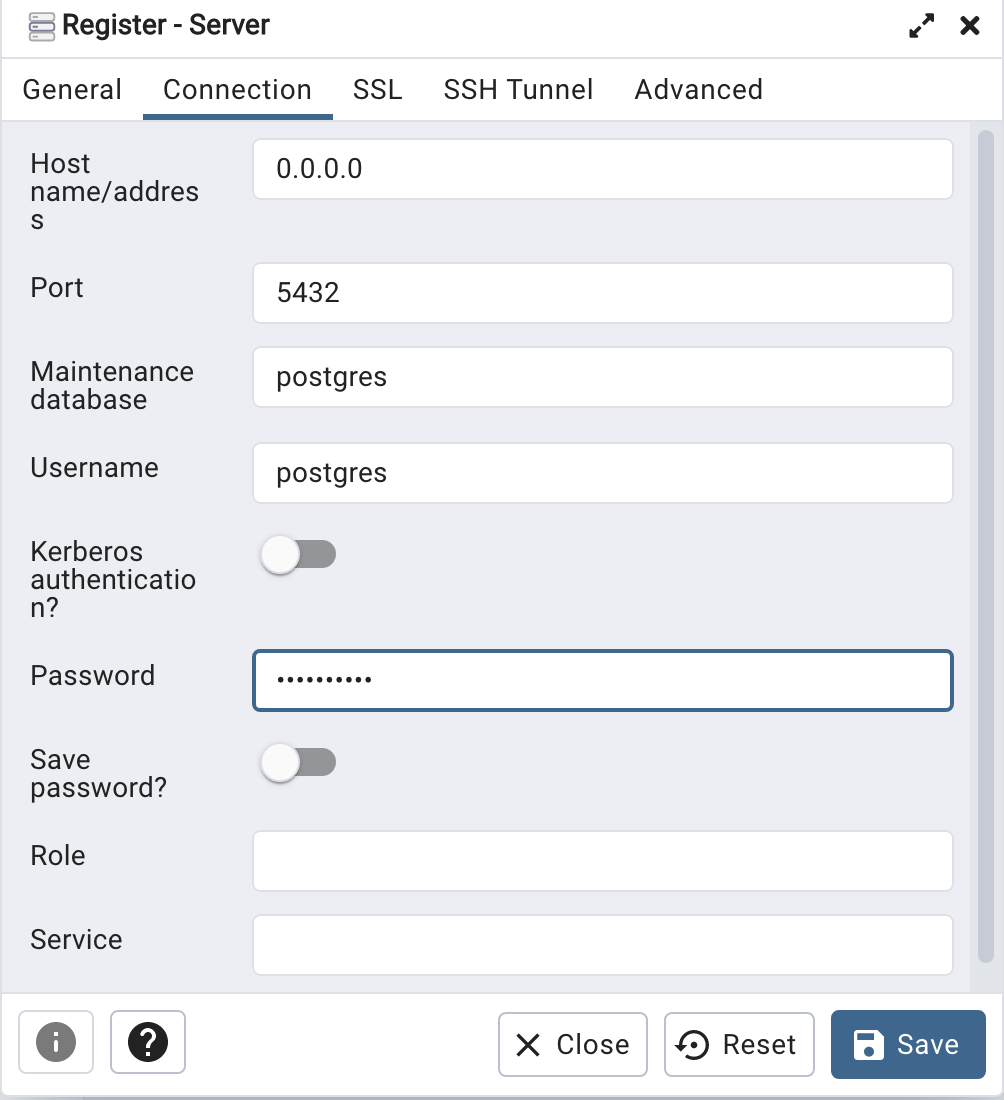
When your (above) connection works, the next step is to create another schema/user in the database. The reason we need to do this is because the user we connected to above (postgres) is an admin user. This user/schema should never be used for database development work.
Let’s setup a user we can use for our development work called ‘student’. To do this, right click on the ‘postgres’ user connection and open the query tool.
Then run the following.

After these two commands have been run successfully we can now create a connection to the postgres database, open the query tool and you’re now all set to write some SQL.

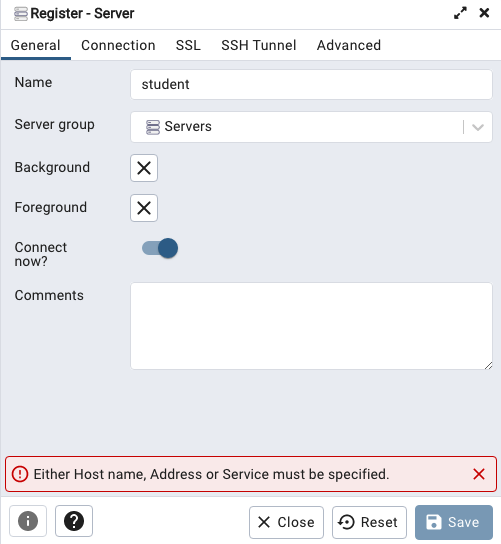
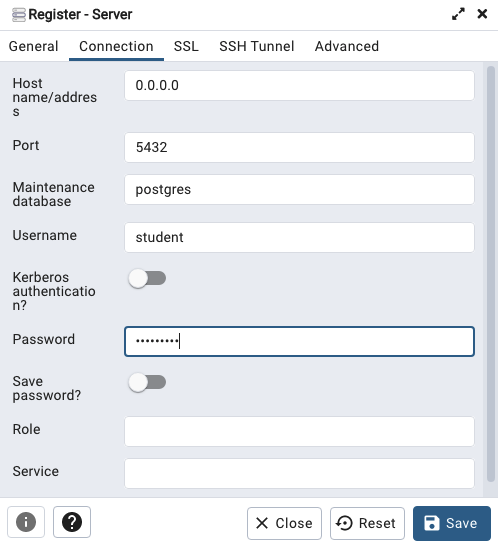

You must be logged in to post a comment.