
ADW
oracledb Python Library – Connect to DB & a few other changes
Oracle have released a new Python library for connecting to Oracle Databases on-premises and on the Cloud. It’s called (very imaginatively, yet very clearly) oracledb. This new Python library replaces the previous library called cx_Oracle. Just consider cx_oracle as obsolete, and use oracledb going forward, as all development work on new features and enhancements will be done to oracledb.
cx_oracle has been around a long time, and it’s about time we have a new and enhanced library that is more flexible and will suit many different deployment scenarios. The previous library (cx_Oracle) was great, but it did require additional software installation with Oracle Client, and some OS environment settings, which at times took a bit of debugging. This makes it difficult/challenging to deploy in different environments, for example IOTs, CI/CD, containers, etc. Deployment environments have changed and the new oracledb library makes it simpler.
To check out the following links for a full list of new features and other details.
Home page: oracle.github.io/python-oracledb
Installation instructions: python-oracledb.readthedocs.io/en/latest/installation.html
Documentation: python-oracledb.readthedocs.io
One of the main differences between the two libraries is how you connect to the Database. With oracledb you need to use named the parameters, and the new library uses a thin connection. If you need the thick connection you can switch to that easily enough.
The following examples will illustrate how to connect to Oracle Database (local and cloud ADW/ATP) and how these are different to using the cx_Oracle library (which needed Oracle Client software installed). Remember the new oracledb library does not need Oracle Client.
To get started, install oracledb.
pip3 install oracledbLocal Database (running in Docker)
To test connection to a local Database I’m using a Docker image of 21c (hence localhost in this example, replace with IP address for your database). Using the previous library (cx_Oracle) you could concatenate the connection details to form a string and pass that to the connection. With oracledb, you need to use named parameters and specify each part of the connection separately.
This example illustrates this simple connection and prints out some useful information about the connection, do we have a healthy connection, are we using thing database connection and what version is the connection library.
p_username = "..."
p_password = "..."
p_dns = "localhost/XEPDB1"
p_port = "1521"
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
print(con.is_healthy())
print(con.thin)
print(con.version)
---
True
True
21.3.0.0.0
Having created the connection we can now query the Database and close the connection.
cur = con.cursor()
cur.execute('select table_name from user_tables')
for row in cur:
print(row)
---
('WHISKIES_DATASET',)
('HOLIDAY',)
('STAGE',)
('DIRECTIONS',)
---
cur.close()
con.close()The code I’ve given above is simple and straight forward. And if you are converting from cx_Oracle, you will probably have minimal changes as you probably had your parameter keywords defined in your code. If not, some simple editing is needed.
To simplify the above code even more, the following does all the same steps without the explicit open and close statements, as these are implicit in this example.
import oracledb
con = oracledb.connect(user=p_username, password=p_password, dsn=p_dns, port=p_port)
with con.cursor() as cursor:
for row in cursor.execute('select table_name from user_tables'):
print(row)(Basic) Oracle Cloud – Autonomous Database, ATP/ADW
Everyone is using the Cloud, Right? If you believe the marketing they are, but in reality most will be working in some hybrid world using a mixture of on-premises and cloud storage. The example given in the previous section illustrated connecting to a local/on-premises database. Let’s now look at connecting to a database on Oracle Cloud (Autonomous Database, ATP/ADW).
With the oracledb library things have been simplified a little. In this section I’ll illustrate a simple connection to a ATP/ADW using a thin connection.
What you need is the location of the directory containing the unzipped wallet file. No Oracle client is needed. If you haven’t downloaded a Wallet file in a while, you should go download a new version of it. The Wallet will contain a pem file which is needed to securely connect to the DB. You’ll also need the password for the Wallet, so talk nicely with your DBA. When setting up the connection you need to provide the directory for the tnsnames.ora file and the ewallet.pem file. If you have downloaded and unzipped the Wallet, these will be in the same directory
import oracledb
p_username = "..."
p_password = "..."
p_walletpass = '...'
#This time we specify the location of the wallet
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high",
config_dir="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_location="/Users/brendan.tierney/Dropbox/5-Database-Wallets/Wallet_student-Full",
wallet_password=p_walletpass)
print(con)
con.close()This method allows you to easily connect to any Oracle Cloud Database.
(Thick Connection) Oracle Cloud – Autonomous Database, ATP/ADW
If you have Oracle Client already installed and set up, and you want to use a thick connection, you will need to initialize the function init_oracle_client.
import oracledb
p_username = "..."
p_password = "..."
#point to directory containing tnsnames.ora
oracledb.init_oracle_client(config_dir="/Applications/instantclient_19_8/network/admin")
con = oracledb.connect(user=p_username, password=p_password, dsn="student_high")
print(con)
con.close()Warning: Some care is needed with using init_oracle_client. If you use it once in your Python code or App then all connections will use it. You might need to do a code review to look at when this is needed and if not remove all occurrences of it from your Python code.
(Additional Security) Oracle Cloud – Autonomous Database, ATP/ADW
There are a few other additional ways of connecting to a database, but one of my favorite ways to connect involves some additional security, particularly when working with IOT devices, or in scenarios that additional security is needed. Two of these involve using One-way TLS and Mututal TLS connections. The following gives an example of setting up One-Way TLS. This involves setting up the Database to only received data and connections from one particular device via an IP address. This requires you to know the IP address of the device you are using and running the code to connect to the ATP/ADW Database.
To set this up, go to the ATP/ADW details in Oracle Cloud, edit the Access Control List, add the IP address of the client device, disable mutual TLS and download the DB Connection. The following code gives and example of setting up a connection
import oracledb
p_username = "..."
p_password = "..."
adw_dsn = '''(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)
(host=adb.us-ashburn-1.oraclecloud.com))(connect_data=(service_name=a8rk428ojzuffy_student_high.adb.oraclecloud.com))
(security=(ssl_server_cert_dn="CN=adwc.uscom-east-1.oraclecloud.com,OU=Oracle BMCS US,O=Oracle Corporation,L=Redwood City,ST=California,C=US")))'''
con4 = oracledb.connect(user=p_username, password=p_password, dsn=adw_dsn)This sets up a secure connection between the client device and the Database.
From my initial testing of existing code/applications (although no formal test cases) it does appear the new oracledb library is processing the queries and data quicker than cx_Oracle. This is good and hopefully we will see more improvements with speed in later releases.
Also don’t forget the impact of changing the buffer size for your database connection. This can have a dramatic effect on speeding up your database interactions. Check out this post which illustrates this.
OML4Py – AutoML – Step-by-Step Approach
Automated Machine Learning (AutoML) is or was a bit of a hot topic over the past couple of years. With various analysis companies like Gartner and others pushing for the need for AutoML, lots and lots of vendors have been creating different types of offerings to support this.
I’ve written some blog posts about AutoML already, from describing what it is and the different types, to showing how to do a black box approach using Oracle OML4Py, and also for using Oracle Machine Learning (OML) AutoML UI. Go check out those posts. In this post I will look at the more detailed step-by-step approach to AutoML using OML4Py. The same data set and cloud account/setup will be used. This will make it easier for you to compare the steps, the results and the AutoML experience across the different OML offerings.
Check out my previous post where I give details of the data set and some data preparation. I won’t repeat those here, but will move onto performing the step-by-step AutoML using OML4Py. The following diagram, from Oracle, outlines the steps involved

A little reminder/warning before you use AutoML in OML4Py. It only works for Classification (binary and multi-class) and Regression problems. The following code example illustrates a binary class problem, but in general there is no difference between the each type of Classification and Regression, except for the evaluation metrics, which I will list below.
Step 1 – Prepare the Data Set & Setup
See my previous blog post where I prepare the data set. I’m not going to repeat those steps here to save a little bit of space.
Also have a look at what libraries to load/import.
Step 2 – Automatic Algorithm Selection
The first step to configure and complete is select the “best model” from a selection of available Algorithms. Not all of the in-database algorithms are available to use in AutoML, which is a pity as there are some algorithms that can produce really accurate model. Hopefully with time these will be added.
The function to use is called AlgorithmSelection. This consists of two parts. The first is to define the parameters and the second part is to run it. This function accepts three parameters:
- mining function : ‘classification’ or ‘regression. Classification can be for binary and multi-class.
- score metric : the evaluation metric to evaluate the model performance. The following list gives the evaluation metric for each mining function
binary classification – accuracy (default), f1, precision, recall, roc_auc, f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
multiclass classification – accuracy (default), f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
regression – r2 (default), neg_mean_squared_error, neg_mean_absolute_error, neg_mean_squared_log_error, neg_median_absolute_error
- parallel : degree of parallelism to use. Default it system determined.
The second step uses this configuration and runs the code to find the “best models”. This takes the training data set (in typical Python format), and can also have a number of additional parameters. See my previous blog post for a full list of these, but ignore adaptive sampling. To keep life simple, you only really need to use ‘k’ and ‘cv’. ‘k’ specifies the number of models to include in the return list, default is 3. ‘cv’ tells how many levels of cross validation to perform. To keep things consistent across these blog posts and make comparison easier, I’m going to set ‘cv=5’
as_bank = automl.AlgorithmSelection(mining_function='classification',
score_metric='accuracy', parallel=4)
oml_bank_ms = as_bank.select(oml_bank_X, oml_bank_y, cv=5)
To display the results and select out the best algorithm:
print("Ranked algorithms with Evaluation score:\n", oml_bank_ms)
selected_oml_bank_ms = next(iter(dict(oml_bank_ms).keys()))
print("Best algorithm =", selected_oml_bank_ms)
Ranked algorithms with Evaluation score:
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377)]
Best algorithm = glm
This last bit of code is import, where the “best” algorithm is extracted from the list. This will be used in the next step.
“It Depends” is a phrase we hear/use a lot in IT, and the same applies to using AutoML. The model returned above does not mean it is the “best model”. It Depends on the parameters used, primarily the Evaluation Metric, but also the number set for CV (cross validation). Here are some examples of changing these and their results. As you can see we get a slightly different set of results or “best model” for each. My advice is to set ‘k’ large (eg current maximum values is 8), as this will ensure all algorithms are evaluated and not just a subset of them (potential hard coded ordered list of algorithms)
oml_bank_ms5 = as_bank.select(oml_bank_X, oml_bank_y, k=5)
oml_bank_ms5
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713)]
oml_bank_ms10 = as_bank.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms10
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713), ('nn', 0.8496405750798722), ('svm_gaussian', 0.8454472843450479), ('dt', 0.8386581469648562)]
Here are some examples when the Score Metric is changed, and the impact it can have.
as_bank2 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms2 = as_bank2.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms2
[('rf', 0.6163242642976126), ('glm', 0.6160046056419113), ('glm_ridge', 0.6160046056419113), ('svm_linear', 0.5996686913307566), ('nn', 0.5896457765667574), ('svm_gaussian', 0.5829741379310345), ('dt', 0.5747368421052631), ('nb', 0.5269709543568464)]
as_bank3 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms3 = as_bank3.select(oml_bank_X, oml_bank_y, k=10, cv=2)
oml_bank_ms3
[('glm', 0.60365647055431), ('glm_ridge', 0.6034077555816686), ('rf', 0.5990036646816308), ('svm_linear', 0.588201766334537), ('svm_gaussian', 0.5845019676714007), ('nn', 0.5842357537014313), ('dt', 0.5686862482989511), ('nb', 0.4981168003466766)]
as_bank4 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms4 = as_bank4.select(oml_bank_X, oml_bank_y, k=10, cv=5)
oml_bank_ms4
[('glm', 0.583504644833276), ('glm_ridge', 0.58343736244422), ('rf', 0.5815952044164737), ('svm_linear', 0.5668069231027809), ('nn', 0.5628153929281711), ('svm_gaussian', 0.5613976370223811), ('dt', 0.5602129668741175), ('nb', 0.49153999668083814)]
The problem we now have with AutoML, it is telling us different answers for “best model”. To most that might be confusing but for the more technical data scientist they will know why. In very very simple terms, you are doing different things with the data and because of this you can get a different answer.
It is because of these different possible answers answers for the “best model”, is the reason AutoML can really only be used as a guide (a pointer towards what might be the “best model”), and cannot be relied upon to give a “best model”. AutoML is still not suitable for the general data analyst despite what some companies are saying.
Lots more could be discussed here but let’s more onto the next step.
Step 3 – Automatic Feature Selection
In the previous steps we have identified a possible “best model”. Let’s pretend the “best model” is the “best model”. The next steps is to look at how this model can be refined and improved using a subset of the features/attributes/columns. FeatureSelection looks are examining the data when combined with the model to find the optimised set of features/attributes/columns, to improve the model performance i.e. make it more accurate or have a better outcome based on the evaluation or score metric. For simplicity I’m going to use the result from the first example produced in the previous step. In a similar way to Step 2, there are two parts to setup and run the Feature Selection (Reduction). Each part is setup in a similar way to Step 2, with the parameters for FeatureSelection being the same values as those used for AlgorithmSelection. For the ‘reduce’ function, pass in the name of the “best model” or “best algorithm” from Step 2. This was extracted to a variable called ‘selected_oml_bank_ms’. Most of the other parameters the ‘reduce’ function takes are similar to the ‘select’ function. Again keeping things consistent, pass in the training data set and set the number of cross validations to 5.
fs_oml_bank = automl.FeatureSelection(mining_function = 'classification',
score_metric = 'accuracy', parallel=4)
oml_bank_fsR = fs_oml_bank.reduce(selected_oml_bank_ms, oml_bank_X, oml_bank_y, cv=5)
We can now look at the results from this listing the reduced set of features/columns and comparing the number of features/columns in the original data set to the reduced set.
#print(oml_bank_fsR)
oml_bank_fsR_l = oml_bank_X[:,oml_bank_fsR]
print("Selected columns:", oml_bank_fsR_l.columns)
print("Number of columns:")
"{} reduced to {}".format(len(oml_bank_X.columns), len(oml_bank_fsR_l.columns))
Selected columns: ['DURATION', 'PDAYS', 'EMP_VAR_RATE', 'CONS_PRICE_IDX', 'CONS_CONF_IDX', 'EURIBOR3M', 'NR_EMPLOYED']
Number of columns:
'20 reduced to 7'
In this example the data set gets reduced from having 20 features/columns in the original data set, down to having 7 features/columns.
Step 4 – Automatic Model Tuning
Up to now, we have identified the “best model” / “best algorithm” and the optimised reduced set of features to use. The final step is to take the details generated from the previous steps and use this to generate a Tuned Model. In a similar way to the previous steps, this involve two parts. The first sets up some parameters and the second runs the Model Tuning function called ‘tune’. Make sure to include the data frame containing the reduced set of features/attributes.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4) oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5) print(oml_bank_mt)
The output is very long and contains the name of the Algorithm, the hyperparameters used for the final model, the features used, and (at the end) lists the various combinations of hyperparameters used and the evaluation metric score for each combination. Partial output shown below.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4)
oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5)
print(oml_bank_mt)
{'best_model':
Algorithm Name: Generalized Linear Model
Mining Function: CLASSIFICATION
Target: TARGET_Y
Settings:
setting name setting value
0 ALGO_NAME ALGO_GENERALIZED_LINEAR_MODEL
1 CLAS_WEIGHTS_BALANCED OFF
...
...
, 'all_evals': [(0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 31, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.4211156437080018, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'})]}
The list of parameter settings and the evaluation score is an ordered list in decending order, starting with the best model.
We can extract the different parts of this dictionary object by using the following:
#display the main model details print(oml_bank_mt['best_model'])
Now extract the evaluation metric score and the parameter settings used for the best model, (position 0 of the dictionary)
score, params = oml_bank_mt['all_evals'][0]
And that’s it, job done with using OML4Py AutoML to generate an optimised model.
The example above is for a Classification problem. If you had a Regression problem all you need to do is replace ‘classification’ with ‘regression’, and change the score_metric parameter to ‘r2’, or one of the other Regression metric values (see above for list of these.
OML4Py – AutoML – An Example
OML4Py (Oracle Machine Learning for Python) is Oracle’s offering where you can use Python commands to process and analyse data in an Oracle Database without having to write any SQL. OML4Py, via it’s transparency layer, translates Python code into SQL, executes it in the Database and then presents the results back to you in your Python environment. The examples shown in this post used the OML Notebooks available with Autonomous Databases on Oracle Cloud.
[Warning: the functionality available with initial release of OML4Py is very limited and may not suit most Python developers. Hopefully this will be addressed in later releases]
One of the features of OML4Py is Automated Machine Leaning (AutoML). At some point in the near future Oracle will have a GUI interface for AutoML, which will save you from having to write any code, such as the example in this post. See my previous blog post about AutoML. It is a general discussion on AutoML and some things you need to be careful with. Also, be careful of the marketing around AutoML from all vendors. The reality doesn’t necessarily live up to marketing

OML4Py has a couple of approaches you can follow to Automatically generate a Machine Learning Model (see previous blog post). The first of these can be considered the Black Box approach for AutoML, and the example below illustrates an example of this. The more detailed version of AutoML will be covered in a later post.
[Info: I’m using Oracle Free Tier Database. At time of writing this post OML4Py is only available with Oracle Autonomous 19c]
But before look at these, the first step we need to do is setup the data set to use for AutoML. I’ll be using the popular Portuguese Bank data set. Each code snippets shown below are for a one cell in my OML Notebooks. The data set exists as a table in my schema called BANK_ADDITIONAL_FULL. The sync command creates a proxy object in the notebook session pointing to the table in the DB. No data is copied into the notebook.
%python import oml from oml import automl import pandas as pd
%python oml_bank = oml.sync(table = 'BANK_ADDITIONAL_FULL') type(oml_bank)
Let’s explore the data. Remember the data lives in a table in the DB and only the results are displayed
%python oml_bank.head()

%python oml_bank.describe()

Now remove one attribute from data set and at the sample time setup the dataframes for input to the ML. This is highly correlated to the the target variable.
%python
oml_bank_X, oml_bank_y = oml_bank.drop('TARGET_Y'), oml_bank['TARGET_Y']
Finally, we can now look at the first of the AutoML options, the black box option. This uses the AutoML ModelSelection function. Using this you can define the type of machine learning to perform (‘classification) and set some additional parameters. The parallel parameter will probably not have too much of an effect when using the Oracle Free Tier, but will certainly improved performance when using additional compute resources.
The example below is very simple and the setup of it is very simple. The ModelSelection function sets up the parameters for the AutoML to function. The ‘select’ function runs the AutoML based on those parameters along with some additional ones. These parameters and the additional ones available are explained below, after this first example.
%python ms_bank = automl.ModelSelection(mining_function='classification', parallel=4)
ModelSelection can have the following parameters. The possible values for each are listed with the value in bold being the default value:
- mining_function : the type of ML to preform, only two option available for this, classification or regression
- score_metric: what metric to use for evaluating the models. Defaults for binary and multi classification balanced_accuracy is used and default for regression is neg_mean_squared_error. Other options for regression include r2, neg_mean_absolute_error and neg_median_absolute_error. For classification other options include, accuracy, f1, precision, recall, roc_auc, f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
- parallel: degree of parallelism to use, None or a number.
Having defined ModelSelection settings, we can move onto using it to preform (black box) AutoML, using the ‘select’ function. Oracle doesn’t tell us what it does inside this black box except that it uses ML and meta-learning techniques to work out which algorithms to use, what subsets of the original data set to use to give use a optimal outcome. It’s there secret recipe!
The ‘select’ function elevates all the available algorithms, creating models for each or a subset of them based on the meta-learning, and returns the “best” one. The function returns just one model, which is the “best”. The value set for ‘k’ tells the function how many of the “best” or top models created, how many of these to tune before returning the “best” one.
Now, let’s run an example of the ‘select’ function and what parameters is can have
- X: input data set consisting of the columns to use for Training.
- y: the column containing the Target variable.
- case_id: columns name of case_id, default is None. If supplied can be used for data sampling
- k: the number of (best) models to tune. Default is 3, but can be set to any number between one and eight, as setting it higher than that has no effect as there aren’t any more than that number of algorithms in the database!
- solver: allowed values are fast (default) and exhaustive. fast uses internal ML and meta-learning thereby reducing the search space. exhaustive will be slower as it will evaluate all algorithms and options for creating a model.
- cv: cross validation. Default is auto, but can be set to a number or set to None uses inputs defined in X_valid and y_valid defined below. auto will determine the number based on size of input data set, and when a number is provided will perform that number cross validation.
- adaptive_sampling: use adaptive sampling to reduce data set size to speed up runtime of ‘select’ function. Default is True, otherwise use False.
- X_valid: validation data set, default is None.
- y_valid: validation target column, default is None.
- time_budget: defines a time constraint on how how long, in seconds, to spend working out the solution. Default is None, or number for number of seconds. Useful for large data sets or for when you need a quicker results, and can be increased based on experimentation.
Here is a basic example of using the ‘select’ function, using the data frames created above as input, ‘k’ is set to five telling the function to tune the top five models created based on doing five fold cross-validation ‘cv’.
best_model = ms_bank.select(oml_bank_X, oml_bank_y, k=5, cv=5) best_model
This returns the following model information. We are told the algorithm used (RandomForest), the tuned algorithm settings, and what attributes from the input data frame are used in the tuned model.
( Algorithm Name: Random Forest Mining Function: CLASSIFICATION Target: TARGET_Y Settings: setting name setting value 0 ALGO_NAME ALGO_RANDOM_FOREST 1 CLAS_MAX_SUP_BINS 32 2 CLAS_WEIGHTS_BALANCED OFF 3 ODMS_DETAILS ODMS_DISABLE 4 ODMS_MISSING_VALUE_TREATMENT ODMS_MISSING_VALUE_AUTO 5 ODMS_RANDOM_SEED 0 6 ODMS_SAMPLING ODMS_SAMPLING_DISABLE 7 PREP_AUTO ON 8 RFOR_MTRY 10 9 RFOR_NUM_TREES 20 10 RFOR_SAMPLING_RATIO 0.5 11 TREE_IMPURITY_METRIC TREE_IMPURITY_ENTROPY 12 TREE_TERM_MAX_DEPTH 16 13 TREE_TERM_MINPCT_NODE 0.05 14 TREE_TERM_MINPCT_SPLIT 0.1 15 TREE_TERM_MINREC_NODE 10 16 TREE_TERM_MINREC_SPLIT 20 Attributes: AGE CAMPAIGN CONS_CONF_IDX CONS_PRICE_IDX CONTACT DEFAULT_VALUE DURATION EDUCATION EMP_VAR_RATE EURIBOR3M JOB MARITAL MONTH NR_EMPLOYED PDAYS POUTCOME PREVIOUS Partition: NO , 'rf')
[I’ve found the Oracle Documentation for (initial release of) OML4Py lacking with information. Hopefully the documentation will be updated]
I’ve mentioned before you need to exercise some caution with using AutoML due to various potential legal and moral issues. Can they be used as a quick way get an idea if ML will produce useful insights for your data. But the results from it should never be used for making business decisions and never deployed in production. Use it as a starting point, from which to build out an ML solutions with humans making the decisions on what to use and why to use them.
For a more detailed, step-by-step approach to AutoML check out this next post for more.
[Warning: Based on the functionality currently available in this early release of OML4Py, you will be limited in what you can do, not just with AutoML but with other features of OML4Py. Maybe check back at a later time when it has matured and has way more functionality, allowing you to do something useful with it!]
Loading and Reading Binary files in Oracle Database using Python
Most Python example show how to load data into a database table. In this blog post I’ll show you how to load a binary file, for example a picture, into a table in an Oracle Autonomous Database (ATP or ADW) and how to read that same image back using Python.
Before we can do this, we need to setup a few things. These include,
Let’s use the following table
CREATE TABLE demo_blob ( id NUMBER PRIMARY KEY, image_txt VARCHAR2(100), image BLOB);
Now let’s get onto the fun bit of loading a image file into this table. The image I’m going to use is the cover of my Data Science book published by MIT Press.

I have this file saved in ‘…/MyBooks/DataScience/BookCover.jpg’.
#Read the binary file
with open (".../MyBooks/DataScience/BookCover.jpg", 'rb') as file:
blob_file = file.read()
#Display some details of file
print('Length =', len(blob_file))
print('Printing first part of file')
print(blob_file[:50])
Now define the insert statement and setup a cursor to process the insert statement;
#define prepared statement inst_blob = 'insert into demo_blob (id, image_txt, image) values (:1, :2, :3)' #connection created using cx_Oracle - see links earlier in post cur = con.cursor()
Now insert the data and the binary file.
#setup values for attributes idNum = 1 imageText = 'Demo inserting Blob file' #insert data into table cur.execute(inst_blob, (idNum, imageText, blob_file)) #close and finish cur.close() #close the cursor con.close() #close the database connection
The image is now saved in the database table. You can use Python to retrieve it or use other tools to view the image.
For example using SQL Developer, query the table and in the results window double click on the blob value. A window pops open and you can view on the image from there by clicking on the check box.
Now that we have the image loads into an Oracle Database the next step is the Python code to read and display the image.
#define prepared statement qry_blog = 'select id, image_txt, image from demo_blob where id = :1' #connection created using cx_Oracle - see links earlier in post cur = con.cursor()
#setup values for attributes idNum = 1 #execute the query
#query the data and blob data connection.outputtypehandler = OutputTypeHandler cur.execute(qry_blob, (idNum)) id, desc, blob_data = cur.fetchone() #write the blob data to file newFileName = '.../MyBooks/DataScience/DummyImage.jpg' with open(newFileName, 'wb') as file: file.write(blob_data)
#close and finish cur.close() #close the cursor con.close() #close the database connection
Partitioned Models – Oracle Machine Learning (OML)
Building machine learning models can be a relatively trivial task. But getting to that point and understanding what to do next can be challenging. Yes the task of creating a model is simple and usually takes a few line of code. This is what is shown in most examples. But when you try to apply to real world problems we are faced with other challenges. Some of which include volume of data is larger, building efficient ML pipelines is challenging, time to create models gets longer, applying models to new data in real-time takes longer (not possible in real-time), etc. Yes these are typically challenges and most of these can be easily overcome.
When building ML solutions for real-world problem you will be faced with building (and deploying) many 10s or 100s of ML models. Why are so many models needed? Almost every example we see for ML takes the entire data set and build a model on that data. When you think about it, not everyone in the data set can be considered in the same grouping (similar characteristics). If we were to build a model on the data set and apply it to new data, we will get a generic prediction. A prediction comparing the new data item (new customer, purchase, etc) with everyone else in the data population. Maybe this is why so many ML project fail as they are building generic solution that performs badly when run on new (and evolving) data.
To overcome this we start to look at the different groups of data in the data set. Can the data set be divided into a number of different parts based on some characteristics. If we could do this and build a separate model on each group (or cluster), then we would have ML models that would be more accurate with their predictions. This is where we will end up creating 10s or 100s of models. As you can imagine the work involved in doing this with be LOTs. Then think about all the coding needed to manage all of this. What about the complexity of all the code needed for making the predictions on new data.
Yes all of this gets complex very, very quickly!
Ideally we want a separate model for each group
But how can you do that efficiently? is it possible?
When working with Oracle Machine Learning, you can use a feature called partitioned models. Partitioned Models are designed to handle this type of problem. They are designed to:
- make the building of models simple
- scales as the data and number of partitions increase
- includes all the steps part of the ML pipeline (all the data prep, transformations, etc)
- make predicting new data using the ML model simple
- make the deployment of the ML model easy
- make the MLOps process simple
- make the use of ML model easy to use by all developers no matter the programming language
- make the ML model build and ML model scoring quick and with better, more accurate predictions.

Let us work through an example. In this example lets start by creating a Random Forest ML model using the entire data set. The following code shows setting up the Parameters settings table. The second code segment creates the Random Forest ML model. The training data set being used in this example contains 72,000 records.
BEGIN
DELETE FROM BANKING_RF_SETTINGS;
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on);
COMMIT;
END;
/
-- Create the ML model
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
/
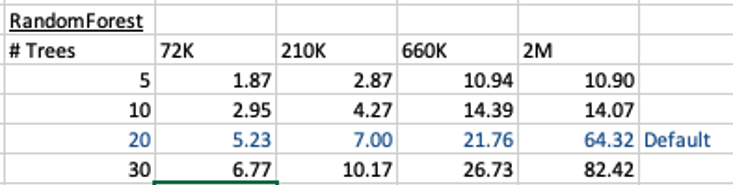
This is the basic setup and the following table illustrates how long the CREATE_MODEL function takes to run for different sizes of training datasets and with different number of trees per model. The default number of trees is 20.
To run this model against new data we could use something like the following SQL query.
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
This is simple and straight forward to use.
For the 72,000 records it takes just approx 5.23 seconds to create the model, which includes creating 20 Decision Trees. As mentioned earlier, this will be a generic model covering the entire data set.
To create a partitioned model, we can add new parameter which lists the attributes to use to partition the data set. For example, if the partition attribute is MARITAL, we see it has four different values. This means when this attribute is used as the partition attribute, Oracle Machine Learning will create four separate sub Random Forest models all until the one umbrella model. This means the above SQL query to run the model, does not change and the correct sub model will be selected to run on the data based on the value of MARITAL attribute.
To create this partitioned model you need to add the following to the settings table.
BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL’); COMMIT; END; /
The code to create the model remains the same!
The code to call and use the model remains the same!
This keeps everything very simple and very easy to use.
When I ran the CREATE_MODEL code for the partitioned model, it took approx 8.3 seconds to run. Yes it took slightly longer than the previous example, but this time it is creating four models instead of one. This is still very quick!
What if I wanted to add more attributes to the partition key? Yes you can do that. The more attributes you add, the more sub-models will be be created.
For example, if I was to add JOB attribute to the partition key list. I will now get 48 sub-models (with 20 Decision Trees each) being created. The JOB attribute has 12 distinct values, multiplied by the 4 values for MARITAL, gives us 48 models.
INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL,JOB');
How long does this take the CREATE_MODEL code to run? approx 37 seconds!
Again that is quick!
Again remember the code to create the model and to run the model to predict on new data does not change. This means our applications using this ML model does not change. This shows us we can very easily increase the predictive accuracy of our models with only adding one additional model, and by improving this accuracy by adding more attributes to the partition key.
But you do need to be careful with what attributes to include in the partition key. If the attributes have a very high number of distinct values, will result in 100s, or 1000s of sub models being created.
An important benefit of using partitioned models is when a new distinct value occurs in one of the partition key attributes. You code to create the parameters and models does not change. OML will automatically will pick this up and do all the work under the hood.
Benchmarking calling Oracle Machine Learning using REST
Over the past year I’ve been presenting, blogging and sharing my experiences of using REST to expose Oracle Machine Learning models to developers in other languages, for example Python.
One of the questions I’ve been asked is, Does it scale?
Although I’ve used it in several projects to great success, there are no figures I can report publicly on how many REST API calls can be serviced 😦
But this can be easily done, and the results below are based on using and Oracle Autonomous Data Warehouse (ADW) on the Oracle Always Free.
The machine learning model is built on a Wine reviews data set, using Oracle Machine Learning Notebook as my tool to write some SQL and PL/SQL to build out a model to predict Good or Bad wines, based on the Prices and other characteristics of the wine. A REST API was built using this model to allow for a developer to pass in wine descriptors and returns two values to indicate if it would be a Good or Bad wine and the probability of this prediction.
No data is stored in the database. I only use the machine learning model to make the prediction
I built out the REST API using APEX, and here is a screenshot of the GET API setup.

Here is an example of some Python code to call the machine learning model to make a prediction.
import json
import requests
country = 'Portugal'
province = 'Douro'
variety = 'Portuguese Red'
price = '30'
resp = requests.get('https://jggnlb6iptk8gum-adw2.adb.us-ashburn-1.oraclecloudapps.com/ords/oml_user/wine/wine_pred/'+country+'/'+province+'/'+'variety'+'/'+price)
json_data = resp.json()
print (json.dumps(json_data, indent=2))
—–
{
"pred_wine": "LT_90_POINTS",
"prob_wine": 0.6844716987704507
}
But does this scale, as in how many concurrent users and REST API calls can it handle at the same time.
To test this I multi-threaded processes in Python to call a Python function to call the API, while ensuring a range of values are used for the input parameters. Some additional information for my tests.
- Each function call included two REST API calls
- Test effect of creating X processes, at same time
- Test effect of creating X processes in batches of Y agents
- Then, the above, with function having one REST API call and also having two REST API calls, to compare timings
- Test in range of parallel process from 10 to 1,000 (generating up to 2,000 REST API calls at a time)
Some of the results. The table shows the time(*) in seconds to complete the number of processes grouped into batches (agents). My laptop was the limiting factor in these tests. It wasn’t able to test when the number of parallel processes when above 500. That is why I broke them into batches consisting of X agents

* this is the total time to run all the Python code, including the time taken to create each process.
Some observations:
- Time taken to complete each function/process was between 0.45 seconds and 1.65 seconds, for two API calls.
- When only one API call, time to complete each function/process was between 0.32 seconds and 1.21 seconds
- Average time for each function/process was 0.64 seconds for one API functions/processes, and 0.86 for two API calls in function/process
- Table above illustrates the overhead associated with setting up, calling, and managing these processes
As you can see, even with the limitations of my laptop, using an Oracle Database, in-database machine learning and REST can be used to create a Micro-Service type machine learning scoring engine. Based on these numbers, this machine learning micro-service would be able to handle and process a large number of machine learning scoring in Real-Time, and these numbers would be well within the maximum number of such calls in most applications. I’m sure I could process more parallel processes if I deployed on a different machine to my laptop and maybe used a number of different machines at the same time
How many applications within you enterprise needs to process move than 6,000 real-time machine learning scoring per minute? This shows us the Oracle Always Free offering is capable and suitable for most applications.
Now, if you are processing more than those numbers per minutes then perhaps you need to move onto the paid options.
What next? I’ll spin up two VMs on Oracle Always Free, install Python, copy code into these VMs and have then run in parallel 🙂
Python-Connecting to multiple Oracle Autonomous DBs in one program
More and more people are using the FREE Oracle Autonomous Database for building new new applications, or are migrating to it.
I’ve previously written about connecting to an Oracle Database using Python. Check out that post for details of how to setup Oracle Client and the Oracle Python library cx_Oracle.
In thatblog post I gave examples of connecting to an Oracle Database using the HostName (or IP address), the Service Name or the SID.
But with the Autonomous Oracle Database things are a little bit different. With the Autonomous Oracle Database (ADW or ATP) you will need to use an Oracle Wallet file. This file contains some of the connection details, but you don’t have access to ServiceName/SID, HostName, etc. Instead you have the name of the Autonomous Database. The Wallet is used to create a secure connection to the Autonomous Database.
You can download the Wallet file from the Database console on Oracle Cloud.

Most people end up working with multiple database. Sometimes these can be combined into one TNSNAMES file. This can make things simple and easy. To use the download TNSNAME file you will need to set the TNS_ADMIN environment variable. This will allow Python and cx_Oracle library to automatically pick up this file and you can connect to the ATP/ADW Database.
But most people don’t work with just a single database or use a single TNSNAMES file. In most cases you need to switch between different database connections and hence need to use multiple TNSNAMES files.
The question is how can you switch between ATP/ADW Database using different TNSNAMES files while inside one Python program?
Use the os.environ setting in Python. This allows you to reassign the TNS_ADMIN environment variable to point to a new directory containing the TNSNAMES file. This is a temporary assignment and over rides the TNS_ADMIN environment variable.
For example,
import cx_Oracle import os os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ATP" p_username = ''p_password = ''p_service = 'atp_high' con = cx_Oracle.connect(p_username, p_password, p_service) print(con) print(con.version) con.close()
I can now easily switch to another ATP/ADW Database, in the same Python program, by changing the value of os.environ and opening a new connection.
import cx_Oracle import os os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ATP" p_username = '' p_password = '' p_service = 'atp_high' con1 = cx_Oracle.connect(p_username, p_password, p_service) ... con1.close() ... os.environ['TNS_ADMIN'] = "/Users/brendan.tierney/Dropbox/wallet_ADW2" p_username = '' p_password = '' p_service = 'ADW2_high' con2 = cx_Oracle.connect(p_username, p_password, p_service) ... con2.close()
As mentioned previously the setting and resetting of TNS_ADMIN using os.environ, is only temporary, and when your Python program exists or completes the original value for this environment variable will remain.
OML Workspace Permissions
When working with Oracle Machine Learning (OML) you are creating notebooks which focus on a particular data exploration and possibly some machine learning. Despite it’s name, OML is used extensively for data discovery and data exploration.
One of the aims of using OML, or notebooks in general, is that these can be easily shared with other people either within the same team or beyond. Something to consider when sharing notebooks is what you are allowing other people do with your notebook. Without any permissions you are allowing people to inspect, run and modify the notebooks. This can be a problem because those people you are sharing with may or may not be allowed to make modification. Some people should be able to just view the notebook, and others should be able to more advanced tasks.
With OML Notebooks there are four primary types of people who can access Notebooks and these can have different privileges. These are defined as
- Developer : Can create new notebooks withing a project and workspace but cannot create a workspace or a project. Can create and run a notebook as a scheduled job.
- Viewer : They can just view projects, Workspaces and notebooks. They are not allowed to create or run anything.
- Manager : can create new notebooks and projects. But only view Workspaces. Additionally they can schedule notebook jobs.
- Administrators : Administrators of the OML environment do not have any edit capabilities on notebooks. But they can view them.

OML Notebooks Interpreter Bindings
When using Oracle Machine Learning notebooks, you can export and import these between different projects and different environments (from ADW to ATP).
But something to watch out for when you import a notebook into your ADW or ATP environment is to reset the Interpreter Bindings.
When you create a new OML Notebook and build it up, the various Interpreter Bindings are automatically set or turned on. But for Imported OML Notebooks they are not turned on.
I’m assuming this will be fixed at some future point.
If you import an OML Notebook and turn on the Interpreter Bindings you may find the code in your notebook cells running very slowly
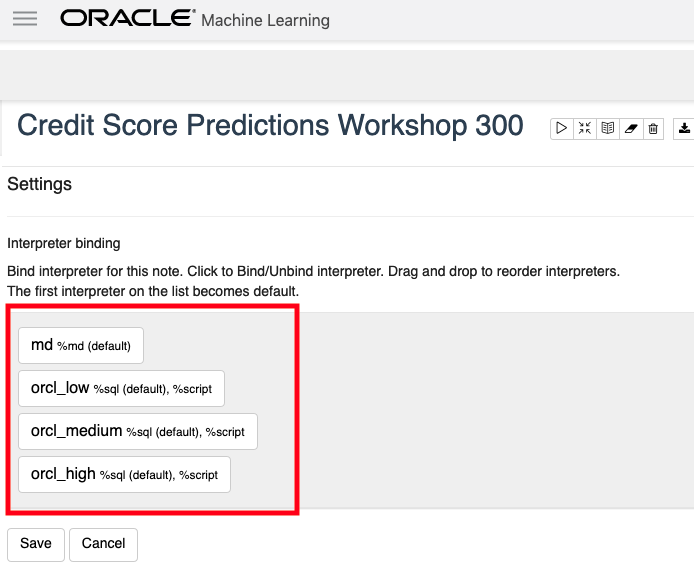
To turn on these binding, click on the options icon as indicated by the red box in the following image.

You will get something like the following being displayed. None of the bindings are highlighted.
To enable the Interpreter Bindings just click on each of these boxes. When you do this each one will be highlighted and will turn a blue color.
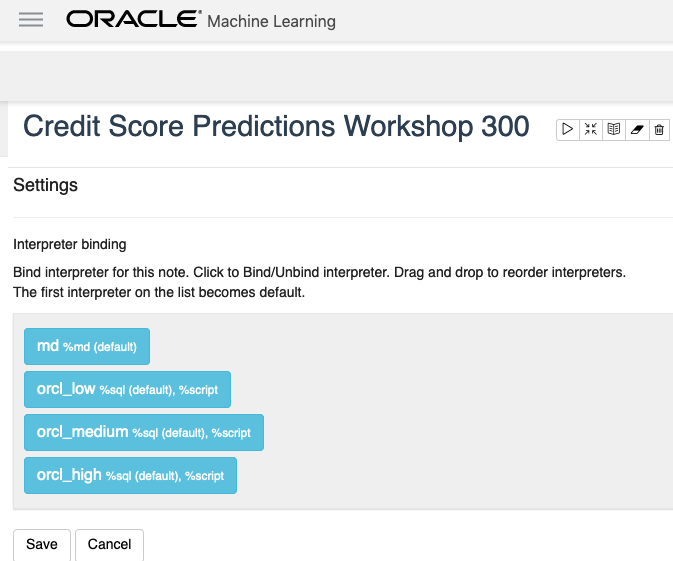
All done! You can now run your OML Notebooks without any problems or delays.
ADW – Loading data using Object Storage
There are a number of different ways to load data into your Autonomous Data Warehouse (ADW) environment. I’ll have posts about these alternatives.
In this blog post I’ll go through the steps needed to load data using Object Storage. This might appear to have a large-ish number of steps, but once you have gone through it and have some of the parts already setup and configuration from your first time, then the second and subsequent times will be easier.
After logging into your Oracle Cloud dashboard, select Object Storage from the side menu.

Then click on the Create Bucket button.
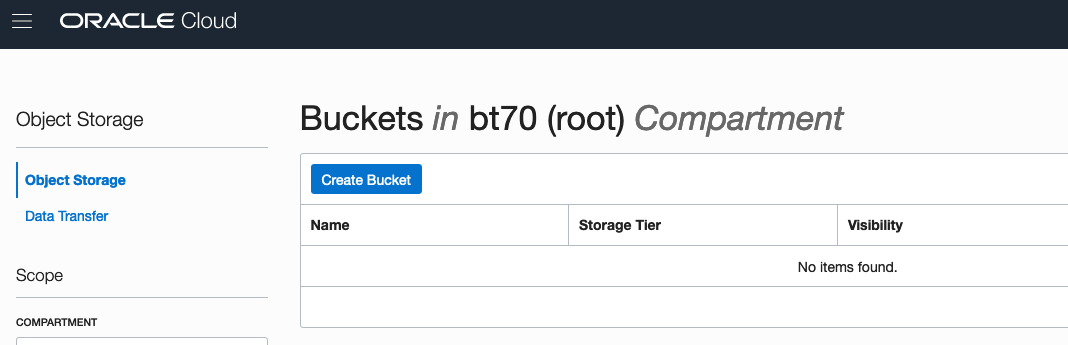
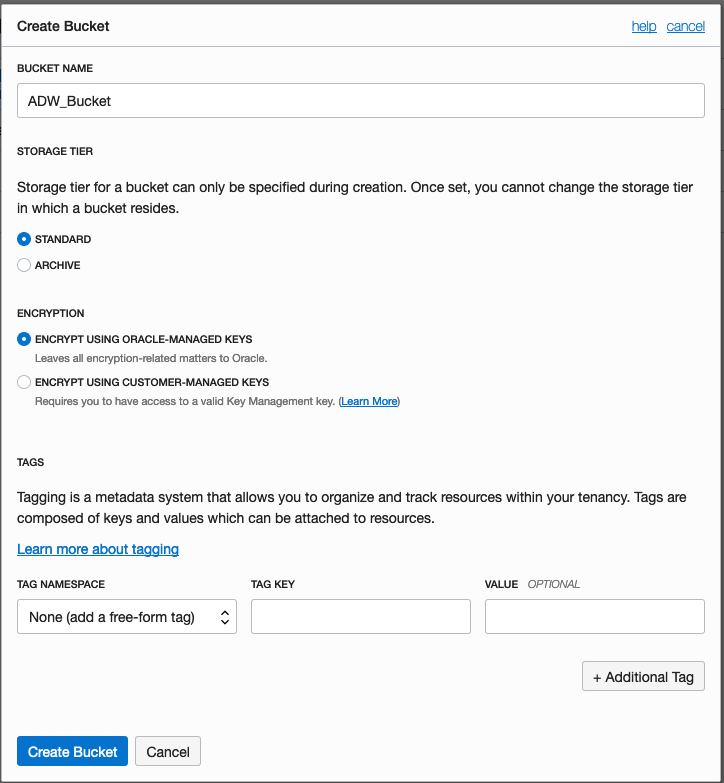
Enter a name for the Object Storage bucket, take the defaults for the for the rest, and click on the Create Bucket button at the bottom. In my example, I’ve called the bucket ‘ADW_Bucket’.
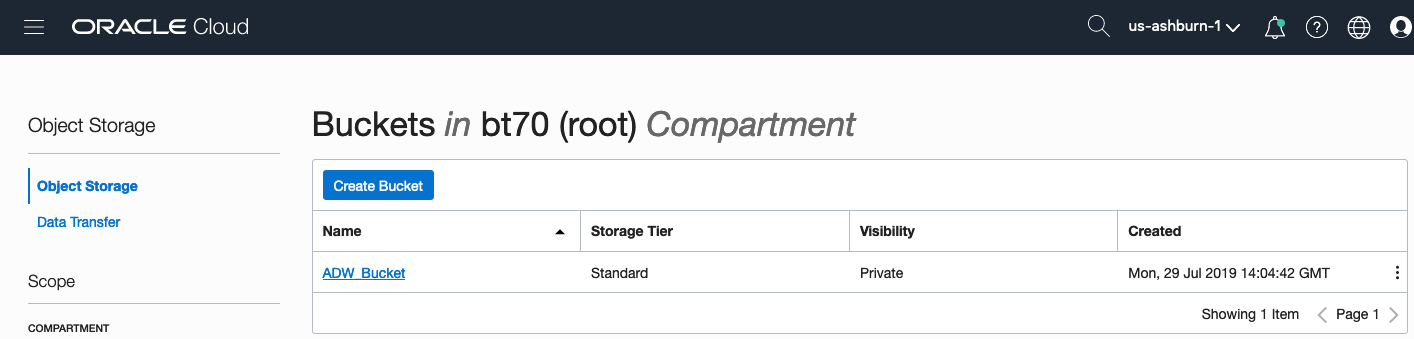
Click on the name of the bucket in the list.
And then click Upload Objects button.

In the Upload Objects window, browse for the file(s) you want to upload.


Then click on the Upload Objects button on the Upload Objects window. After a few moments you will see a message saying the file(s) have been uploaded. Click on the Close window.

Click into the Object details and take a note/copy of the URL Path. You will need this later
To load data from the Oracle Cloud Infrastructure(OCI) Object Storage you will need an OCI user with the appropriate privileges to read data (or upload) data to the Object Store. The communication between the database and the object store relies on the Swift protocol and the OCI user Auth Token. Go back to the menu in the upper left and select users.


Then click on the user name to view the details. This is probably your OCI username.
On the left hand side of the page click Auth Tokens, and then click on Generate Token button. Give a name for the token e.g ADW_TOKEN, and then generate token.

Save the generated token to use later.

Open SQL Developer and setup a connection to your OML User/schema. When connected the next steps is to authenticate with the Object storage using your OCI username and the Auth Token, generated above.
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'ADW_TOKEN',
username => '<your cloud username>',
password => '<generated auth token>'
);
END;If successful you should get the following message. If not then you probably entered something incorrectly. Go back and review the previous steps
PL/SQL procedure successfully completed.
Next, create a table to store the data you want to import. For my table the create table is the following. [It is one of the sample data sets for OML, and I’ve made the create table statement compact to save space in this post]
create table credit_scoring_100k ( customer_id number(38,0), age number(4,0), income number(38,0), marital_status varchar2(26 byte), number_of_liables number(3,0), wealth varchar2(4000 byte), education_level varchar2(26 byte), tenure number(4,0), loan_type varchar2(26 byte), loan_amount number(38,0), loan_length number(5,0), gender varchar2(26 byte), region varchar2(26 byte), current_address_duration number(5,0), residental_status varchar2(26 byte), number_of_prior_loans number(3,0), number_of_current_accounts number(3,0), number_of_saving_accounts number(3,0), occupation varchar2(26 byte), has_checking_account varchar2(26 byte), credit_history varchar2(26 byte), present_employment_since varchar2(26 byte), fixed_income_rate number(4,1), debtor_guarantors varchar2(26 byte), has_own_phone_no varchar2(26 byte), has_same_phone_no_since number(4,0), is_foreign_worker varchar2(26 byte), number_of_open_accounts number(3,0), number_of_closed_accounts number(3,0), number_of_inactive_accounts number(3,0), number_of_inquiries number(3,0), highest_credit_card_limit number(7,0), credit_card_utilization_rate number(4,1), delinquency_status varchar2(26 byte), new_bankruptcy varchar2(26 byte), number_of_collections number(3,0), max_cc_spent_amount number(7,0), max_cc_spent_amount_prev number(7,0), has_collateral varchar2(26 byte), family_size number(3,0), city_size varchar2(26 byte), fathers_job varchar2(26 byte), mothers_job varchar2(26 byte), most_spending_type varchar2(26 byte), second_most_spending_type varchar2(26 byte), third_most_spending_type varchar2(26 byte), school_friends_percentage number(3,1), job_friends_percentage number(3,1), number_of_protestor_likes number(4,0), no_of_protestor_comments number(3,0), no_of_linkedin_contacts number(5,0), average_job_changing_period number(4,0), no_of_debtors_on_fb number(3,0), no_of_recruiters_on_linkedin number(4,0), no_of_total_endorsements number(4,0), no_of_followers_on_twitter number(5,0), mode_job_of_contacts varchar2(26 byte), average_no_of_retweets number(4,0), facebook_influence_score number(3,1), percentage_phd_on_linkedin number(4,0), percentage_masters number(4,0), percentage_ug number(4,0), percentage_high_school number(4,0), percentage_other number(4,0), is_posted_sth_within_a_month varchar2(26 byte), most_popular_post_category varchar2(26 byte), interest_rate number(4,1), earnings number(4,1), unemployment_index number(5,1), production_index number(6,1), housing_index number(7,2), consumer_confidence_index number(4,2), inflation_rate number(5,2), customer_value_segment varchar2(26 byte), customer_dmg_segment varchar2(26 byte), customer_lifetime_value number(8,0), churn_rate_of_cc1 number(4,1), churn_rate_of_cc2 number(4,1), churn_rate_of_ccn number(5,2), churn_rate_of_account_no1 number(4,1), churn_rate__of_account_no2 number(4,1), churn_rate_of_account_non number(4,2), health_score number(3,0), customer_depth number(3,0), lifecycle_stage number(38,0), credit_score_bin varchar2(100 byte));
After creating the table, you are ready to import the data from Object storage. To do this you will need to use the DBMS_COULD PL/SQL package.
begin
dbms_cloud.copy_data(
table_name =>'credit_scoring_100k',
credential_name =>'ADW_TOKEN',
file_uri_list => '<url of file in your Object Store bucket, see comment earlier in post>',
format => json_object('ignoremissingcolumns' value 'true', 'removequotes' value 'true', 'dateformat' value 'YYYY-MM-DD HH24:MI:SS', 'blankasnull' value 'true', 'delimiter' value ',', 'skipheaders' value '1')
);
end;
All done.
You can now query the data and use with Oracle Machine Learning, etc.
[I said at the top of the post there are other methods available. More on this in other posts]
Oracle ADW how to load new OML notebooks
Oracle Autonomous Database (ADW) has been out a while now and have had several, behind the scenes, improvements and new/additional features added.
If you have used the Oracle Machine Learning (OML) component of ADW you will have seen the various sample OML Notebooks that come pre-loaded. These are easy to open, use and to try out the various OML features.

The above image shows the top part of the login screen for OML. To see the available sample notebooks click on the Examples icon. When you do, you will get the following sample OML Notebooks.
But what if you have a notebook you have used elsewhere. These can be exported in json format and loaded as a new notebook in OML.
To load a new notebook into OML, select the icon (three horizontal line) on the top left hand corner of the screen. Then select Notebooks from the menu.

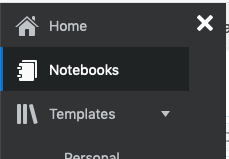
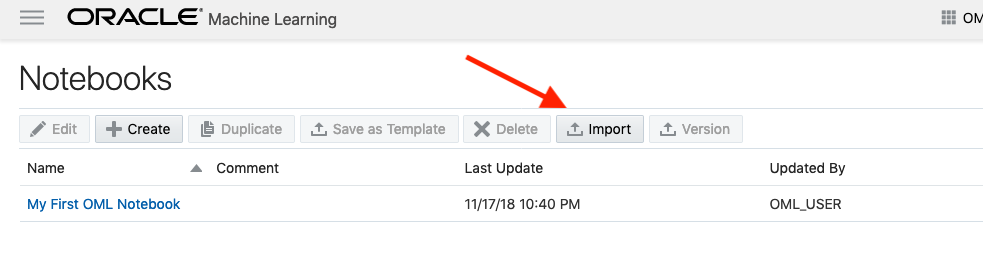
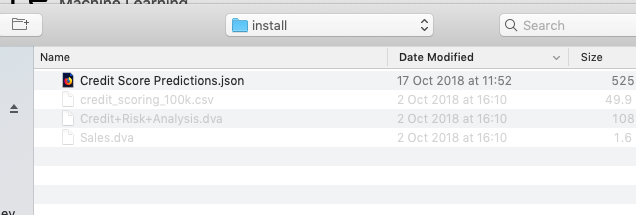
Then select the Import button located at the top of the Notebooks screen. This will open a File window, where you can select the json file from your file system.
A couple of seconds later the notebook will be available and listed along side any other notebooks you may have created.
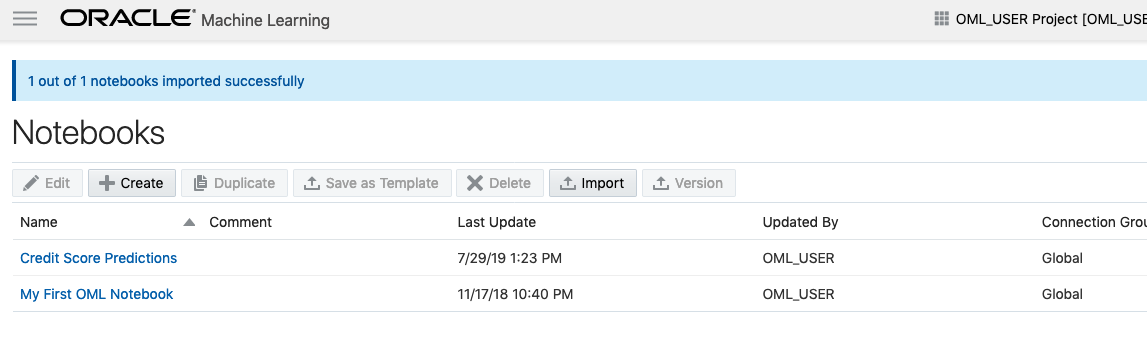
All done!
You have now imported a new notebook into OML and can now use it to process your data and perform machine learning using the in-database features.

You must be logged in to post a comment.