
20c
Enhanced Window Clause functionality in Oracle 21c (20c)
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
The Oracle Database has had advanced analytical functions for some time now and with each release we get to have some new additions or some enhancements to existing functionality.
One new enhancement, available and documented in 21c (not yet released at time of writing this), is changing in the way the Window Clause can be defined for analytic functions. Oracle 21c is available on Oracle Cloud as a pre-release for evaluation purposes (but it won’t be available for much longer!). The examples shown below are based on using this 21c pre-release of the database.
NOTE: At this point, no one really knows when or if 20c will be released. I’m sure all the documented 20c new features will be rolled into 21c, whenever that will be released.
Before giving some examples of the new Window Clause functionality, lets have a quick recap on how we could use it up to now (up to 19c database). Here is a simple example of windowing the data by creating partitions based on the distinct values in DEPTNO column
select deptno,
ename,
job,
salary,
avg (salary) over (partition by DEPTNO) avg_sal
from employee
order by deptno;

Here we get to see the average salary being calculated for each window partition and being reset for the next windwo partition.
The SQL:2011 standard support the defining of the Window clause in the query block, after defining the list tables for the query. This allows us to define the window clause one and then reference this for analytic function that need it. The following example illustrate this. I’ve take the able query and altered it to have the newer syntax. I’ve highlighted the new or changed code in blue. In the analytic function, the w1 refers to the Window clause defined later, and is more in keeping with how a query is logically processed.
select deptno,
ename,
sal,
sum(sal) over (w1) sum_sal
from emp
window w1 as (partition by deptno);
As you would expect we get the same results returned.
This newer syntax is particularly useful when we have many more analytic function in our queries, and some of these are using slightly different windowing. To me it makes it easier to read and to make edits, allowing an edit to be preformed once instead of for each analytic function, and avoids any errors. But making it easier to read and understand is by far the greatest benefit. Here is another example which uses different window clauses using the previous syntax.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (PARTITION BY deptno ORDER BY sal) AS avg_dept_sal,
AVG(sal) OVER (PARTITION BY deptno ) AS avg_dept_sal2,
SUM(sal) OVER (PARTITION BY deptno ORDER BY sal desc) AS sum_dept_sal
FROM emp;
Using the newer syntax this gets transformed into the following.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (w1) AS avg_dept_sal,
AVG(sal) OVER (w2) AS avg_dept_sal2,
SUM(sal) OVER (w2) AS avg_dept_sal
FROM emp
window w1 as (PARTITION BY deptno ORDER BY sal),
w2 as (PARTITION BY deptno),
w3 as (PARTITION BY deptno ORDER BY sal desc);
Adam Solver for Neural Networks (OML) in Oracle 21c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
The ability to create and use Neural Networks on business data has been available in Oracle Database since Oracle 18c (18c and 19c are just slightly extended versions of Oracle 12c). With each minor database release we get some small improvements and minor features added. I’ve written other blog posts about other 21c new machine learning features (see here, here and here).
With Oracle 21c they have added a new neural network solver. This is called Adam Solver and the original research was conducted by Diederik Kingma from OpenAI and Jimmy Ba from the University of Toronto and they presented they work at ICLR 2015. The name Adam is derived from ‘adaptive moment estimation‘. This algorithm, research and paper has gathered some attention in the research community over the past few years. Most of this has been focused on the benefits of using it.

But care is needed. As with most machine learning (and deep learning) algorithms, they work up to a point. They may be good on certain problems and input data sets, and then for others they may not be as good or as efficient at producing an optimal outcome. Although using this solver may be beneficial to your problem, using the concept of ‘No Free Lunch’, you will need to prove the solver is beneficial for your problem.
With Oracle Machine Learning there are two Optimization Solver available for the Neural Network algorithm. The default solver is call L-BFGS (Limited memory Broyden-Fletch-Goldfarb-Shanno). This is one of the most popular solvers in use in most algorithms. The is a limited version of BFGS, using less memory (hence the L in the name) This solver finds the descent direction and line search is used to find the appropriate step size. The solver searches for the optimal solution of the loss function to find the extreme value (maximum or minimum) of the loss (cost) function
The Adam Solver uses an extension to stochastic gradient descent. It uses the squared gradients to scale the learning rate and it takes advantage of momentum by using moving average of the gradient instead of gradient. This allows the solver to work quickly by seeing less data and can work well with larger data sets.
With Oracle Data Mining the Adam Solver has the following parameters.
- ADAM_ALPHA : Learning rate for solver. Default value is 0.001.
- ADAM_BATCH_ROWS : Number of rows per batch. Default value is 10,000
- ADAM_BETA1 : Exponential decay rate for 1st moment estimates. Default value is 0.9.
- ADAM_BETA2 : Exponential decay rate for the 2nd moment estimates. Default value is 0.99.
- ADAM_GRADIENT_TOLERANCE : Gradient infinity norm tolerance. Default value is 1E-9.
The parameters ADAM_ALPHA and ADAM_BATCH_ROWS can have an effect on the timing for the neural network algorithm to produce the model. Some exploration is needed to determine the optimal values for this parameters based on the size of the data set. For example having a larger value for ADAM_ALPHA results in a faster initial learning before the rates is updated. Small values than the default slows learning down during training.
To tell Oracle Machine Learning to use the Adam Solver the DMSSET_NN_SOLVER parameter needs to be set. The default setting for a neural network is DMSSET_NN_SOLVER_LGFGS. But to use the Adam solver set it to DMSSET_NN_SOLVER_ADAM.
The following is an example of setting the parameters for the Adam solver and creating a neural network.
BEGIN DELETE FROM BANKING_NNET_SETTINGS; INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_neural_network); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.nnet_nodes_per_layer, '20,10,6'); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.nnet_iterations, 10); INSERT INTO BANKING_NNET_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.NNET_SOLVER, 'NNET_SOLVER_ADAM'); END; The addition of the last parameter overrides the default solver for building a neural network model.
To build the model we can use the following.
DECLARE
v_start_time TIMESTAMP;
BEGIN
begin DBMS_DATA_MINING.DROP_MODEL('BANKING_NNET_72K_1'); exception when others then null; end;
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name. => 'BANKING_NNET_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_NNET_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
For me on my Oracle 20c Preview Database, this takes 1.8 seconds to run and create the neural network model ob a data set of 72,000 records.
Using the default solver, the model is created in 5.2 seconds. With using a small data set of 72,000 records, we can see the impact of using an Adam Solver for creating a neural network model.
These timings and the timings shown below (in seconds) are based on the Oracle 20c Preview Database, using a minimum VM sizing and specification available.
XGBoost in Oracle 20c
 Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Another of the new machine learning algorithms in Oracle 21c Database is called XGBoost. Most people will have come across this algorithm due to its recent popularity with winners of Kaggle competitions and other similar events.
XGBoost is an open source software library providing a gradient boosting framework in most of the commonly used data science, machine learning and software development languages. It has it’s origins back in 2014, but the first official academic publication on the algorithm was published in 2016 by Tianqi Chen and Carlos Guestrin, from the University of Washington.
The algorithm builds upon the previous work on Decision Trees, Bagging, Random Forest, Boosting and Gradient Boosting. The benefits of using these various approaches are well know, researched, developed and proven over many years. XGBoost can be used for the typical use cases of Classification including classification, regression and ranking problems. Check out the original research paper for more details of the inner workings of the algorithm.
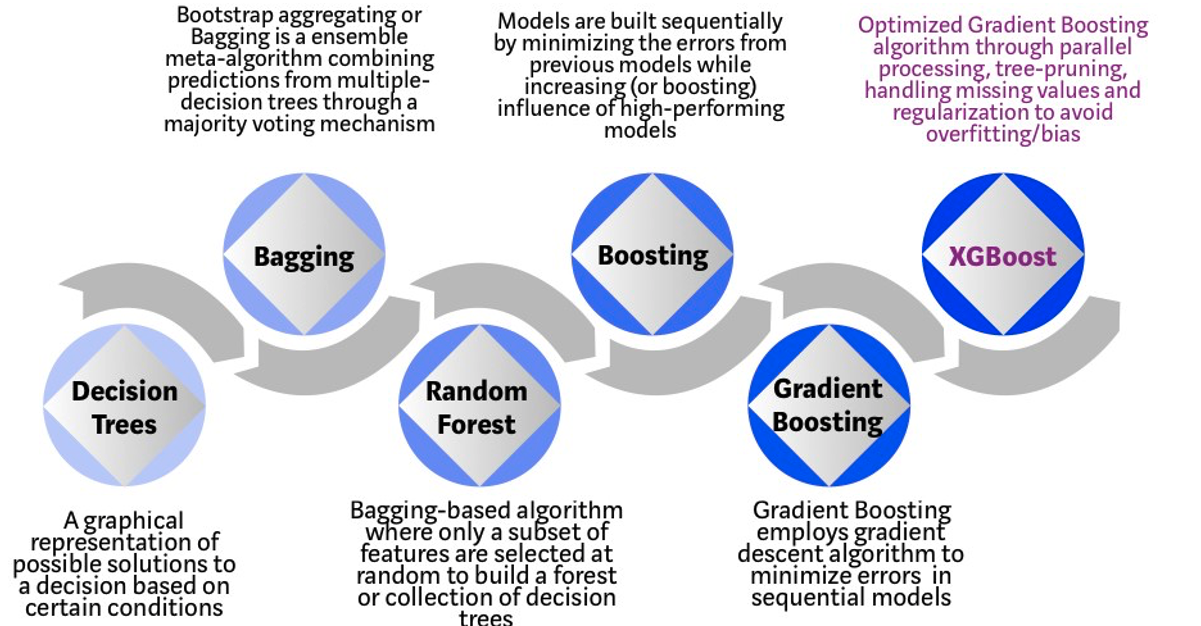
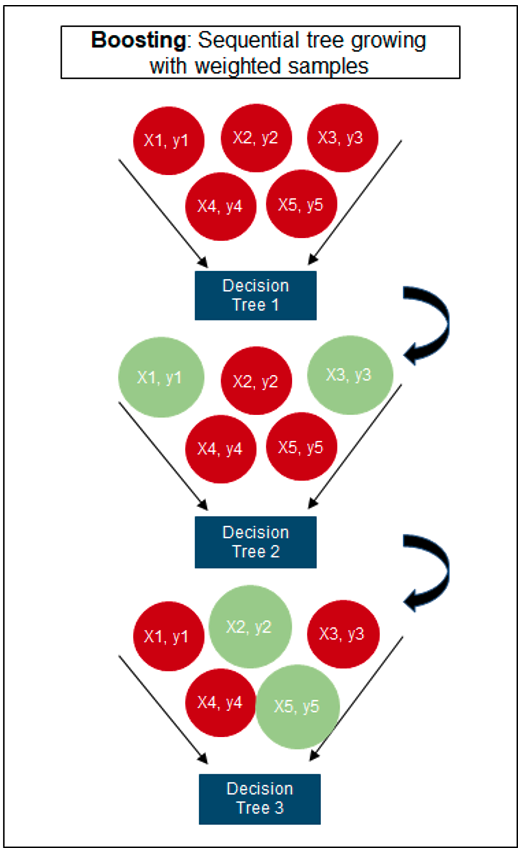
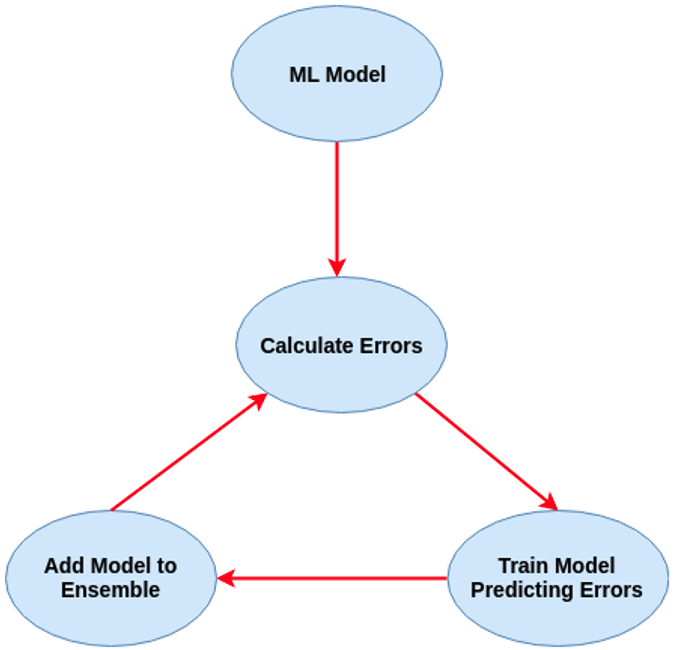 Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
The following three images illustrates the differences between Decision Trees, Random Forest and XGBoost.
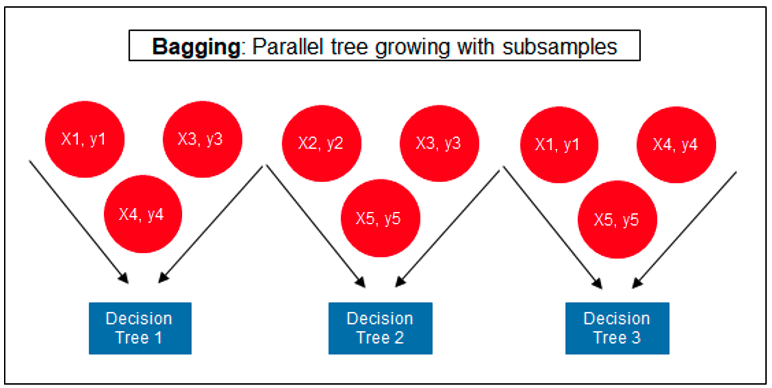
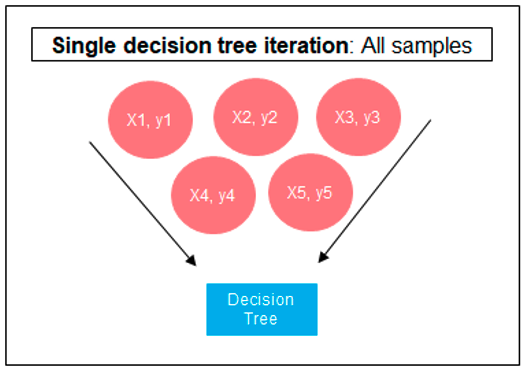
The XGBoost algorithm in Oracle 20c has over 40 different parameter settings, and with most scenarios the default settings with be fine for most scenarios. Only after creating a baseline model with the details will you look to explore making changes to these. Some of the typical settings include:
- Booster = gbtree
- #rounds for boosting = 10
- max_depth = 6
- num_parallel_tree = 1
- eval_metric = Classification error rate or RMSE for regression
As with most of the Oracle in-database machine learning algorithms, the setup and defining the parameters is really simple. Here is an example of minimum of parameter settings that needs to be defined.
BEGIN -- delete previous setttings DELETE FROM banking_xgb_settings; INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_xgboost); -- For 0/1 target, choose binary:logistic as the objective. INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_objective, 'binary:logistic’); commit; END;
To create an XGBoost model run the following. BEGIN DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'BANKING_XGB_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'BANKING_72K', case_id_column_name => 'ID', target_column_name => 'TARGET', settings_table_name => 'BANKING_XGB_SETTINGS'); END;
That’s all nice and simple, as it should be, and the new model can be called in the same manner as any of the other in-database machine learning models using functions like PREDICTION, PREDICTION_PROBABILITY, etc.
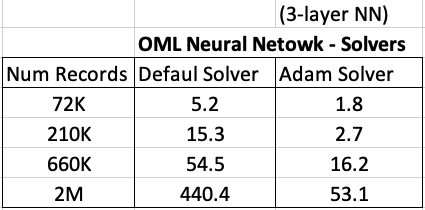
One of the interesting things I found when experimenting with XGBoost was the time it took to create the completed model. Using the default settings the following table gives the time taken, in seconds to create the model.

As you can see it is VERY quick even for large data sets and gives greater predictive accuracy.
MSET (Multivariate State Estimation Technique) in Oracle 20c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Oracle 21c Database comes with some new in-database Machine Learning algorithms.
The short name for one of these is called MSET or Multivariate State Estimation Technique. That’s the simple short name. The more complete name is Multivariate State Estimation Technique – Sequential Probability Ratio Test. That is a long name, and the reason is it consists of two algorithms. The first part looks at creating a model of the training data, and the second part looks at how new data is statistical different to the training data.
What are the use cases for this algorithm? This algorithm can be used for anomaly detection.

Anomaly Detection, using algorithms, is able identifying unexpected items or events in data that differ to the norm. It can be easy to perform some simple calculations and graphics to examine and present data to see if there are any patterns in the data set. When the data sets grow it is difficult for humans to identify anomalies and we need the help of algorithms.
The images shown here are easy to analyze to spot the anomalies and it can be relatively easy to build some automated processing to identify these. Most of these solutions can be considered AI (Artificial Intelligence) solutions as they mimic human behaviors to identify the anomalies, and these example don’t need deep learning, neural networks or anything like that.
Other types of anomalies can be easily spotted in charts or graphics, such as the chart below.
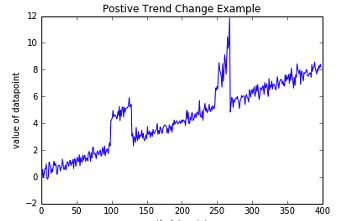
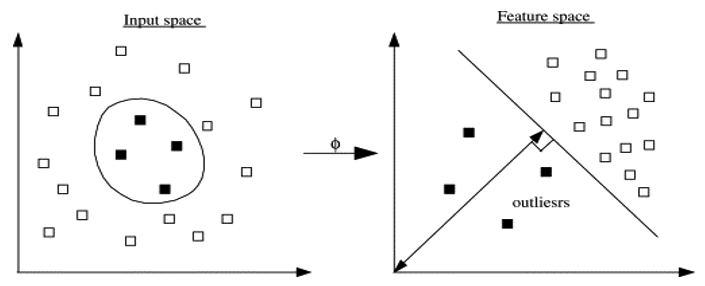 There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
Getting back to the MSET algorithm. Remember it is a 2-part algorithm abbreviated to MSET. The first part is a non-linear, nonparametric anomaly detection algorithm that calibrates the expected behavior of a system based on historical data from the normal sequence of monitored signals. Using data in time series format (DATE, Value) the training data set contains data consisting of “normal” behavior of the data. The algorithm creates a model to represent this “normal”/stationary data/behavior. The second part of the algorithm compares new or live data and calculates the differences between the estimated and actual signal values (residuals). It uses Sequential Probability Ratio Test (SPRT) calculations to determine whether any of the signals have become degraded. As you can imagine the creation of the training data set is vital and may consist of many iterations before determining the optimal training data set to use.
MSET has its origins in computer hardware failures monitoring. Sun Microsystems have been were using it back in the late 1990’s-early 2000’s to monitor and detect for component failures in their servers. Since then MSET has been widely used in power generation plants, airplanes, space travel, Disney uses it for equipment failures, and in more recent times has been extensively used in IOT environments with the anomaly detection focused on signal anomalies.
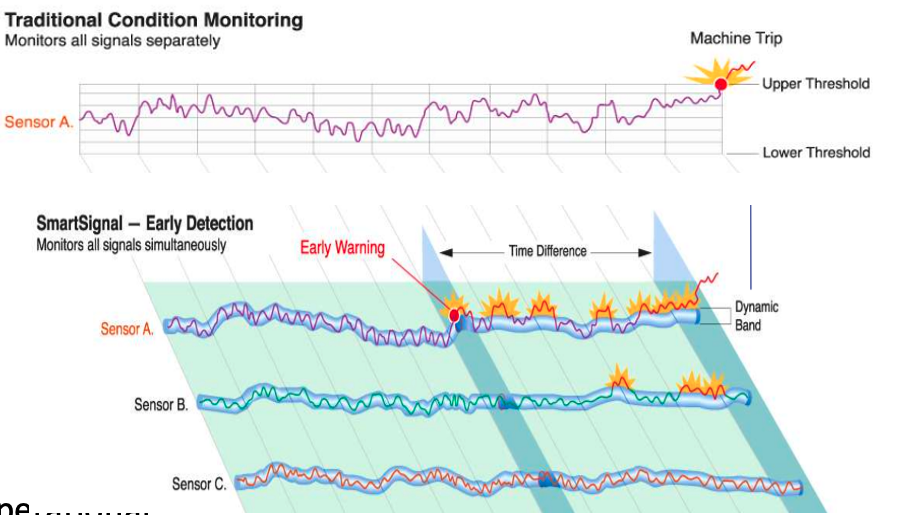
How does MSET work in Oracle 21c?
An important point to note before we start is, you can use MSET on your typical business data and other data stored in the database. It isn’t just for sensor, IOT, etc data mentioned above and can be used in many different business scenarios.
The first step you need to do is to create the time series data. This can be easily done using a view, but a Very important component is the Time attribute needs to be a DATE format. Additional attributes can be numeric data and these will be used as input to the algorithm for model creation.
-- Create training data set for MSET CREATE OR REPLACE VIEW mset_train_data AS SELECT time_id, sum(quantity_sold) quantity, sum(amount_sold) amount FROM (SELECT * FROM sh.sales WHERE time_id <= '30-DEC-99’) GROUP BY time_id ORDER BY time_id;
The example code above uses the SH schema data, and aggregates the data based on the TIME_ID attribute. This attribute is a DATE data type. The second import part of preparing and formatting the data is Ordering of the data. The ORDER BY is necessary to ensure the data is fed into or processed by the algorithm in the correct time series order.
The next step involves defining the parameters/hyper-parameters for the algorithm. All algorithms come with a set of default values, and in most cases these are suffice for your needs. In that case, you only need to define the Algorithm Name and to turn on Automatic Data Preparation. The following example illustrates this and also includes examples of setting some of the typical parameters for the algorithm.
BEGIN DELETE FROM mset_settings; -- Select MSET-SPRT as the algorithm INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.algo_name, dbms_data_mining.algo_mset_sprt); -- Turn on automatic data preparation INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); -- Set alert count INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_COUNT, 3); -- Set alert window INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_WINDOW, 5); -- Set alpha INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALPHA_PROB, 0.1); COMMIT; END;
To create the MSET model using the MST_TRAIN_DATA view created above, we can run:
BEGIN -- DBMS_DATA_MINING.DROP_MODEL(MSET_MODEL'); DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'MSET_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MSET_TRAIN_DATA', case_id_column_name => 'TIME_ID', target_column_name => '', settings_table_name => 'MSET_SETTINGS'); END;
The SELECT statement below is an example of how to call and run the MSET model to label the data to find anomalies. The PREDICTION function will return a values of 0 (zero) or 1 (one) to indicate the predicted values. If the predicted values is 0 (zero) the MSET model has predicted the input record to be anomalous, where as a predicted values of 1 (one) indicates the value is typical. This can be used to filter out the records/data you will want to investigate in more detail.
-- display all dates with Anomalies SELECT time_id, pred FROM (SELECT time_id, prediction(mset_sh_model using *) over (ORDER BY time_id) pred FROM mset_test_data) WHERE pred = 0;

You must be logged in to post a comment.