
ADW
OML Workspace Permissions
When working with Oracle Machine Learning (OML) you are creating notebooks which focus on a particular data exploration and possibly some machine learning. Despite it’s name, OML is used extensively for data discovery and data exploration.
One of the aims of using OML, or notebooks in general, is that these can be easily shared with other people either within the same team or beyond. Something to consider when sharing notebooks is what you are allowing other people do with your notebook. Without any permissions you are allowing people to inspect, run and modify the notebooks. This can be a problem because those people you are sharing with may or may not be allowed to make modification. Some people should be able to just view the notebook, and others should be able to more advanced tasks.
With OML Notebooks there are four primary types of people who can access Notebooks and these can have different privileges. These are defined as
- Developer : Can create new notebooks withing a project and workspace but cannot create a workspace or a project. Can create and run a notebook as a scheduled job.
- Viewer : They can just view projects, Workspaces and notebooks. They are not allowed to create or run anything.
- Manager : can create new notebooks and projects. But only view Workspaces. Additionally they can schedule notebook jobs.
- Administrators : Administrators of the OML environment do not have any edit capabilities on notebooks. But they can view them.


OML Notebooks Interpreter Bindings
When using Oracle Machine Learning notebooks, you can export and import these between different projects and different environments (from ADW to ATP).
But something to watch out for when you import a notebook into your ADW or ATP environment is to reset the Interpreter Bindings.
When you create a new OML Notebook and build it up, the various Interpreter Bindings are automatically set or turned on. But for Imported OML Notebooks they are not turned on.
I’m assuming this will be fixed at some future point.
If you import an OML Notebook and turn on the Interpreter Bindings you may find the code in your notebook cells running very slowly
To turn on these binding, click on the options icon as indicated by the red box in the following image.

You will get something like the following being displayed. None of the bindings are highlighted.
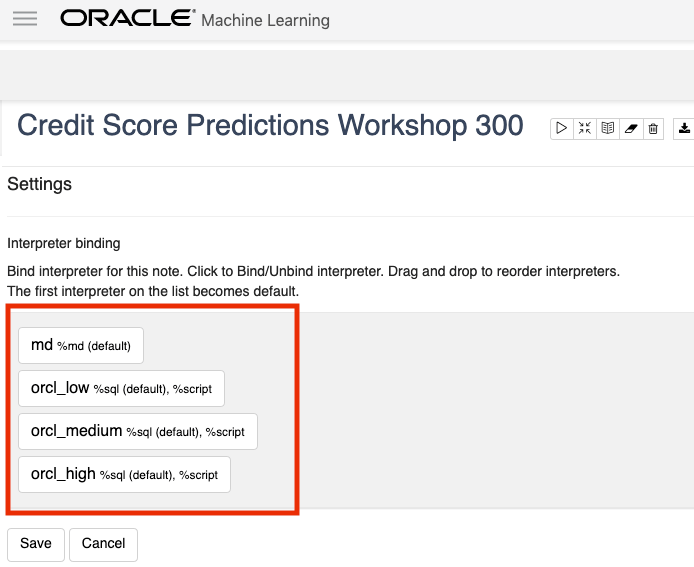
To enable the Interpreter Bindings just click on each of these boxes. When you do this each one will be highlighted and will turn a blue color.

All done! You can now run your OML Notebooks without any problems or delays.
ADW – Loading data using Object Storage
There are a number of different ways to load data into your Autonomous Data Warehouse (ADW) environment. I’ll have posts about these alternatives.
In this blog post I’ll go through the steps needed to load data using Object Storage. This might appear to have a large-ish number of steps, but once you have gone through it and have some of the parts already setup and configuration from your first time, then the second and subsequent times will be easier.
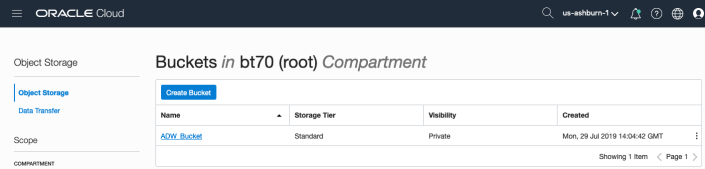
After logging into your Oracle Cloud dashboard, select Object Storage from the side menu.

Then click on the Create Bucket button.

Enter a name for the Object Storage bucket, take the defaults for the for the rest, and click on the Create Bucket button at the bottom. In my example, I’ve called the bucket ‘ADW_Bucket’.

Click on the name of the bucket in the list.
And then click Upload Objects button.

In the Upload Objects window, browse for the file(s) you want to upload.


Then click on the Upload Objects button on the Upload Objects window. After a few moments you will see a message saying the file(s) have been uploaded. Click on the Close window.
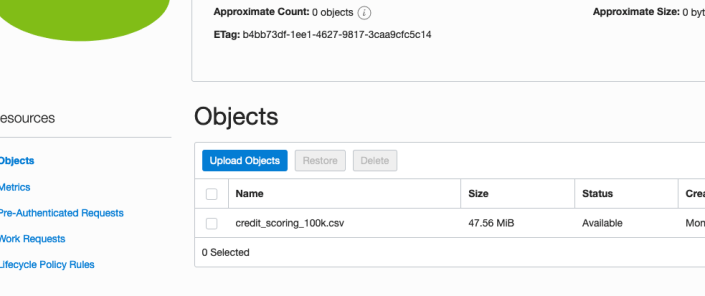
Click into the Object details and take a note/copy of the URL Path. You will need this later
To load data from the Oracle Cloud Infrastructure(OCI) Object Storage you will need an OCI user with the appropriate privileges to read data (or upload) data to the Object Store. The communication between the database and the object store relies on the Swift protocol and the OCI user Auth Token. Go back to the menu in the upper left and select users.


Then click on the user name to view the details. This is probably your OCI username.
On the left hand side of the page click Auth Tokens, and then click on Generate Token button. Give a name for the token e.g ADW_TOKEN, and then generate token.
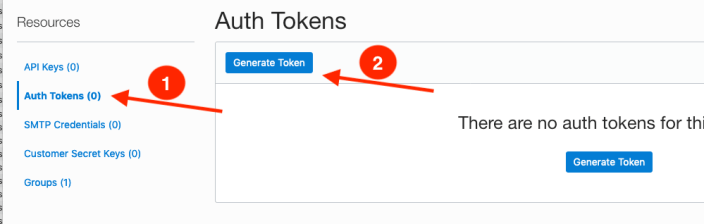
Save the generated token to use later.
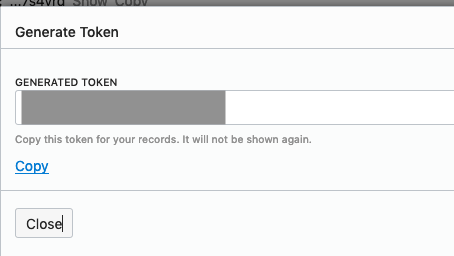
Open SQL Developer and setup a connection to your OML User/schema. When connected the next steps is to authenticate with the Object storage using your OCI username and the Auth Token, generated above.
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'ADW_TOKEN',
username => '<your cloud username>',
password => '<generated auth token>'
);
END;If successful you should get the following message. If not then you probably entered something incorrectly. Go back and review the previous steps
PL/SQL procedure successfully completed.
Next, create a table to store the data you want to import. For my table the create table is the following. [It is one of the sample data sets for OML, and I’ve made the create table statement compact to save space in this post]
create table credit_scoring_100k ( customer_id number(38,0), age number(4,0), income number(38,0), marital_status varchar2(26 byte), number_of_liables number(3,0), wealth varchar2(4000 byte), education_level varchar2(26 byte), tenure number(4,0), loan_type varchar2(26 byte), loan_amount number(38,0), loan_length number(5,0), gender varchar2(26 byte), region varchar2(26 byte), current_address_duration number(5,0), residental_status varchar2(26 byte), number_of_prior_loans number(3,0), number_of_current_accounts number(3,0), number_of_saving_accounts number(3,0), occupation varchar2(26 byte), has_checking_account varchar2(26 byte), credit_history varchar2(26 byte), present_employment_since varchar2(26 byte), fixed_income_rate number(4,1), debtor_guarantors varchar2(26 byte), has_own_phone_no varchar2(26 byte), has_same_phone_no_since number(4,0), is_foreign_worker varchar2(26 byte), number_of_open_accounts number(3,0), number_of_closed_accounts number(3,0), number_of_inactive_accounts number(3,0), number_of_inquiries number(3,0), highest_credit_card_limit number(7,0), credit_card_utilization_rate number(4,1), delinquency_status varchar2(26 byte), new_bankruptcy varchar2(26 byte), number_of_collections number(3,0), max_cc_spent_amount number(7,0), max_cc_spent_amount_prev number(7,0), has_collateral varchar2(26 byte), family_size number(3,0), city_size varchar2(26 byte), fathers_job varchar2(26 byte), mothers_job varchar2(26 byte), most_spending_type varchar2(26 byte), second_most_spending_type varchar2(26 byte), third_most_spending_type varchar2(26 byte), school_friends_percentage number(3,1), job_friends_percentage number(3,1), number_of_protestor_likes number(4,0), no_of_protestor_comments number(3,0), no_of_linkedin_contacts number(5,0), average_job_changing_period number(4,0), no_of_debtors_on_fb number(3,0), no_of_recruiters_on_linkedin number(4,0), no_of_total_endorsements number(4,0), no_of_followers_on_twitter number(5,0), mode_job_of_contacts varchar2(26 byte), average_no_of_retweets number(4,0), facebook_influence_score number(3,1), percentage_phd_on_linkedin number(4,0), percentage_masters number(4,0), percentage_ug number(4,0), percentage_high_school number(4,0), percentage_other number(4,0), is_posted_sth_within_a_month varchar2(26 byte), most_popular_post_category varchar2(26 byte), interest_rate number(4,1), earnings number(4,1), unemployment_index number(5,1), production_index number(6,1), housing_index number(7,2), consumer_confidence_index number(4,2), inflation_rate number(5,2), customer_value_segment varchar2(26 byte), customer_dmg_segment varchar2(26 byte), customer_lifetime_value number(8,0), churn_rate_of_cc1 number(4,1), churn_rate_of_cc2 number(4,1), churn_rate_of_ccn number(5,2), churn_rate_of_account_no1 number(4,1), churn_rate__of_account_no2 number(4,1), churn_rate_of_account_non number(4,2), health_score number(3,0), customer_depth number(3,0), lifecycle_stage number(38,0), credit_score_bin varchar2(100 byte));
After creating the table, you are ready to import the data from Object storage. To do this you will need to use the DBMS_COULD PL/SQL package.
begin
dbms_cloud.copy_data(
table_name =>'credit_scoring_100k',
credential_name =>'ADW_TOKEN',
file_uri_list => '<url of file in your Object Store bucket, see comment earlier in post>',
format => json_object('ignoremissingcolumns' value 'true', 'removequotes' value 'true', 'dateformat' value 'YYYY-MM-DD HH24:MI:SS', 'blankasnull' value 'true', 'delimiter' value ',', 'skipheaders' value '1')
);
end;
All done.
You can now query the data and use with Oracle Machine Learning, etc.
[I said at the top of the post there are other methods available. More on this in other posts]
Oracle ADW how to load new OML notebooks
Oracle Autonomous Database (ADW) has been out a while now and have had several, behind the scenes, improvements and new/additional features added.
If you have used the Oracle Machine Learning (OML) component of ADW you will have seen the various sample OML Notebooks that come pre-loaded. These are easy to open, use and to try out the various OML features.
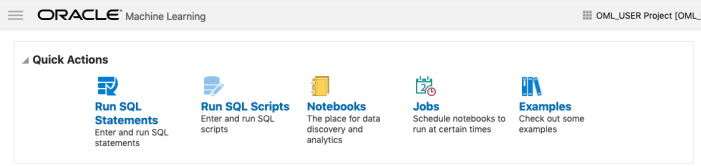
The above image shows the top part of the login screen for OML. To see the available sample notebooks click on the Examples icon. When you do, you will get the following sample OML Notebooks.
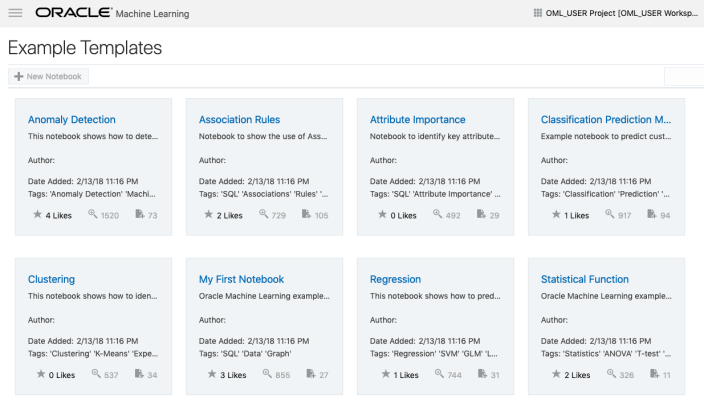
But what if you have a notebook you have used elsewhere. These can be exported in json format and loaded as a new notebook in OML.
To load a new notebook into OML, select the icon (three horizontal line) on the top left hand corner of the screen. Then select Notebooks from the menu.

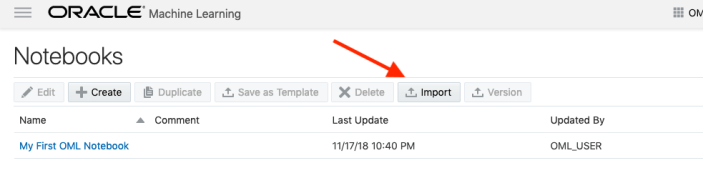
Then select the Import button located at the top of the Notebooks screen. This will open a File window, where you can select the json file from your file system.
A couple of seconds later the notebook will be available and listed along side any other notebooks you may have created.
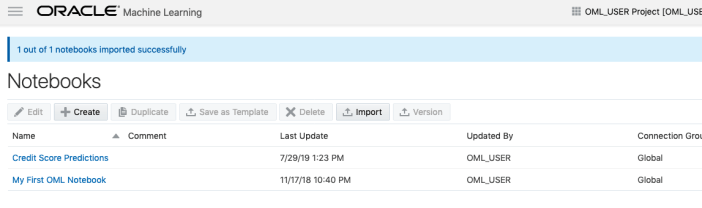
All done!
You have now imported a new notebook into OML and can now use it to process your data and perform machine learning using the in-database features.

You must be logged in to post a comment.