
cloud
Using NotebookLM to help with understanding Oracle Analytics Cloud or any other product
Over the past few months, we’ve seen a plethora of new LLM related products/agents being released. One such one is NotebookLM from Google. The offical description say “NotebookLM is an AI-powered research and note-taking tool from Google Labs that allows users to ground a large language model (like Gemini) in their own documents, such as PDFs, Google Docs, website URLs, or audio, acting as a personal, intelligent research assistant. It facilitates summarizing, analyzing, and querying information within these specific sources to create study guides, outlines, and, notably, “Audio Overviews” (podcast-style summaries)”
Let’s have a look at using NotebookLM to help with answering questions and how it can help with understanding Oracle Analytics Cloud (OAC).

Yes, you’ll need a Google account, and Yes you need to be OK with uploading your documents to NotebookLM. Make sure you are not breaking any laws (IP, GDPR, etc). It’s really easy to create your first notebook. Simply click on ‘Create new notebook’.
When the notebook opens, you can add your documents and webpages to the notebook. These can be documents in PDF, audio, text, etc to the notebook repository. Currently, there seems to be a limit of 50 documents and webpages that can be added.
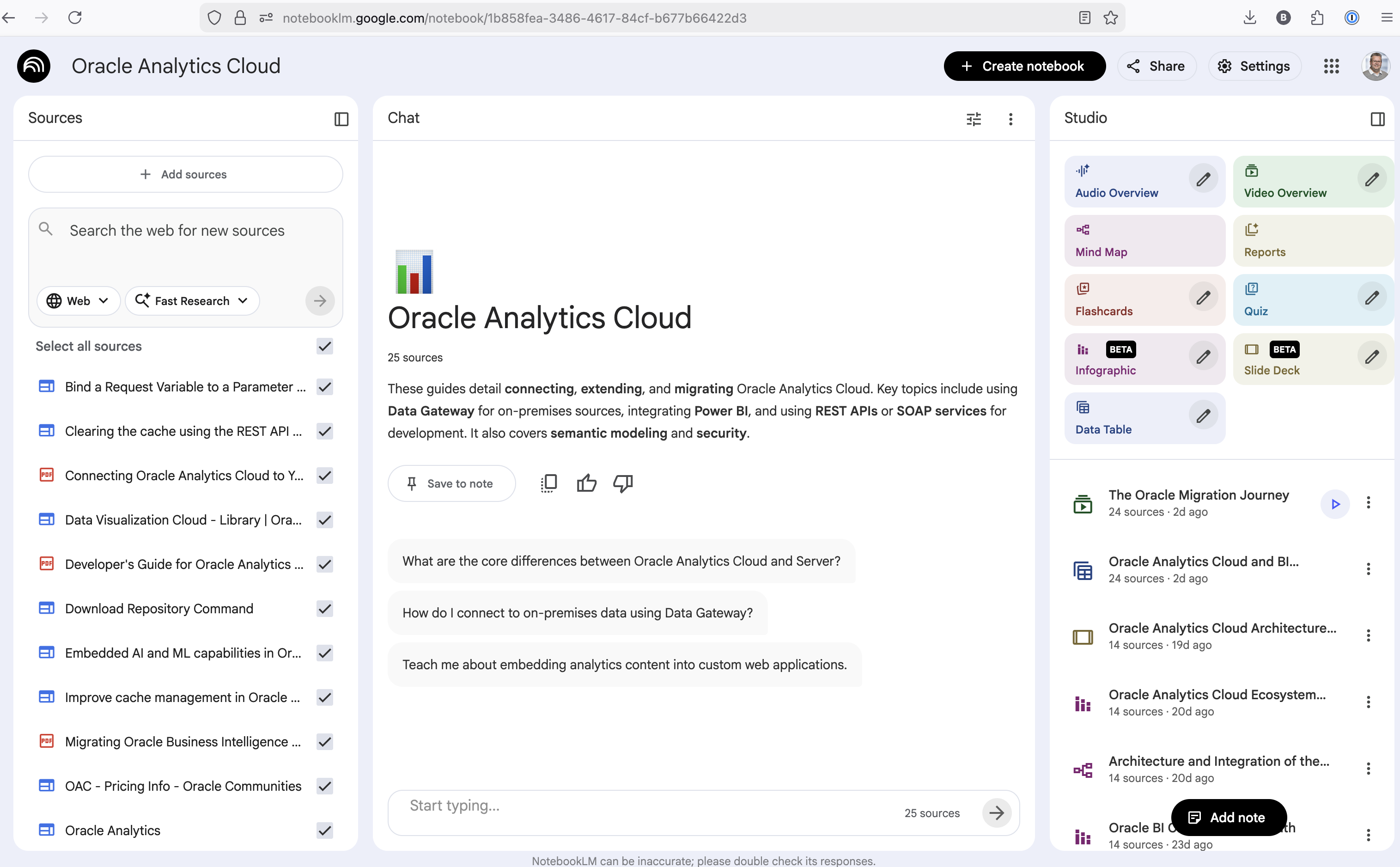
The main part of the NotebookLM provides a chatbot where you can ask questions, and the NotebookLM will search through the documents and webpages to formulate an answer. In addition to this, there are features that allow you to generate Audio Overview, Video Overview, Mind Map, Reports, Flashcards, Quiz, Infographic, Slide Deck and a Data Table.
Before we look at some of these and what they have created for Oracle Analytics Cloud, there is a small warning. Some of these can take a long time to complete, that is, if they complete. I’ve had to run some of these features multiple times to get them to create. I’ve run all of the features, and the output from these can be seen on the right-hand side of the above image.
It created a 15-slide presentation on Oracle Analytics Cloud and its various features, and a five minute video on migrating OAC.


It also created a Mind-map, and an Infographic.
Moving Out of the Cloud – or something hybrid – The Key is Managing your Costs Carefully
Over the past decade, we have been hearing the call of the Cloud, from various vendors. The Cloud has provided a wonderful technology shift in the wider IT industry and accelerated the introduction of new technologies and more efficient ways of doing things. There were a lot of promises made or implied in migrating to the Cloud, and these are still being made.
In February 2023, Andy Jassy (CEO of AWS) highlighted: “I think it’s also useful to remember that 90% to 95% of the global IT spend remains on-premises.”. Despite all the talk, pushing customers and customers deciding for themselves to go to the Cloud, there is still a very significant percentage of IT spending remaining on-premises. If you look at the revenue growth of these Cloud providers (Microsoft, Google, AWS and yes even Oracle), if all that revenue equates to just 5-10% of IT spend, just think of the potential revenues if they can convert 1-2% of that spend. It would be Huge!
We have seen lots of competition between the Cloud vendors with multiple price reductions over the last few years. Get the customers to sign up for their Cloud services. They will sign up when things look cheap, but will it remain that way.
In more recent years, say from 2022 onwards, we have seen some questioning the value of going to the Cloud. It seems to get more expensive as time progresses and in some cases receiving surprisingly large Bills. What at first appears to be cheap and quick to spin up new services, turns out to hit the credit card hard at a later time. We have seen many articles by some well-known companies that were early adopters of the Cloud, and have migrated back to being fully on-premises.
The following are some related articles and documentary about the Cloud and exit from the Cloud.
Why companies are leaving the cloud
90-95% of Global IT spend remains on-premises – says Amazon CEO
And check out this documentary from clouded.tv.
OCI Object Storage Buckets
We can upload and store data in Object Storage on OCI. This allows us to load and store data in a variety of different formats and sizes. With this data/files in object storage, it can be easily accessed from an Oracle Database (e.g. Autonomous Database) and any other service on OCI. This allows building more complete business solutions in a more integrated way.
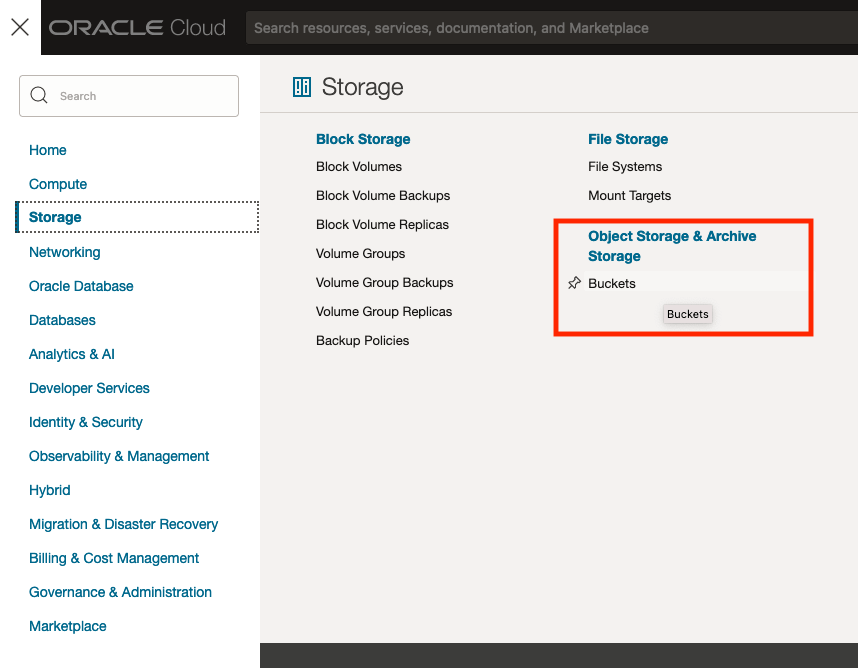
The Buckets feature can be found under the Storage option in the main Menu. From the popup screen look under Object Storage & Archive Storage and click on Buckets.
In the Objects Storage screen click on Create Bucket button.
In the Create Bucket screen, change the name of the Bucket. In this example, I’ve called it ‘Cats-and-Dogs-Small-Dataset’. No spaces are allowed. You can leave the defaults for the other settings. Then click the Create button.
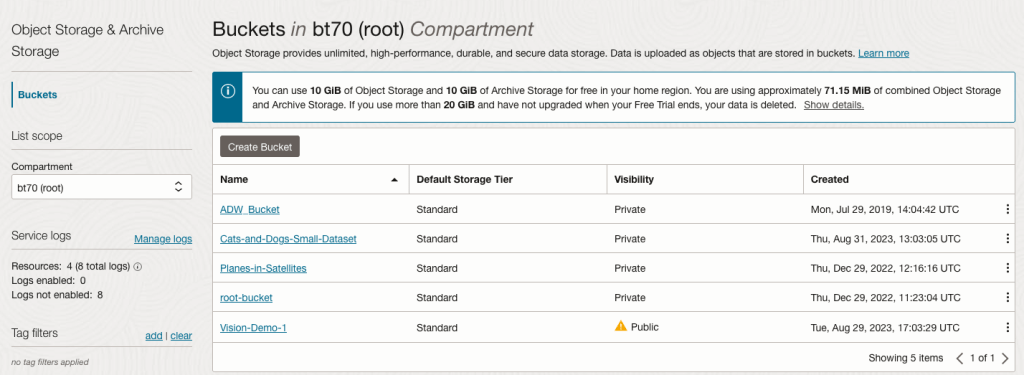
It will then be displayed along with any other buckets you have. I’ve a few other buckets.
Click on the Bucket name to open the bucket and add files to it.
Click on the Upload button. Locate the files on your computer, select the files you want to upload.
The files will be listed in the Upload Object window. Click the Upload button to start transferring them to OCI.
If you wish you can set a prefix for all the files being uploaded.
When the files have been uploaded, click the Close button.
Note: The larger the dateset, in files and file size, it can take some time (depending on interest connection speed) for all the files to load into the Bucket.
To view the details of an image, click on the three dots to the right of the image files. This will open a menu for the image, where you can select to view image Details, download, copy, rename, delete, etc. the image.
Click on View Object Details to get the details of the image.
This will display details about the object and the URI for the image.
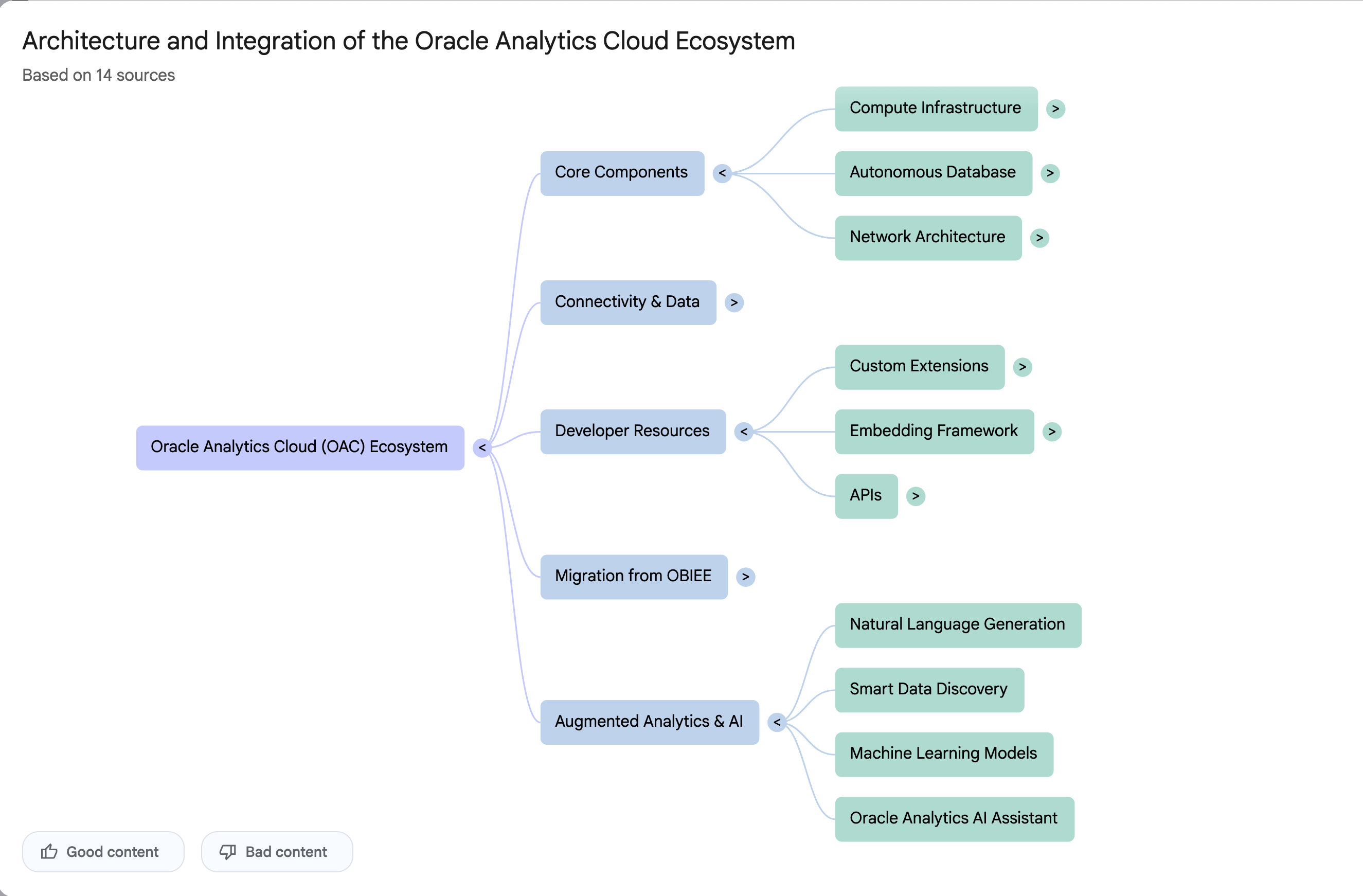
How many Data Center Regions by Vendor?
There has been some discussions over the past weeks, months, years on which Cloud provider is the best, or the biggest, or provides the most services, or [insert some other topic]? The old answer to everything related to IT is ‘It Depends’. A recent article by CloudWars (and updated numbers by them) and some of the comments to it, and elsewhere prompted me to have a look at ‘How Many Data Center Regions do each Cloud Vendor have?’ I didn’t go looking at all possible cloud vendors, but instead kept to the main vendors consisting of Microsoft Azure, Google Cloud Platform (GCP), Oracle Cloud and Amazon Web Services (AWS). We know AWS has been around for a long long time, and seems to gather most of the attention and focus within the developer community, etc, you’d expect them to be the biggest. Well, the results from my investigation does not support this.
Now, it is important to remember when reading the results presented below that these are from a particular point in time, and that is the date of this blog post. If you are reading this some time later, the actual number of data centers will be different and will be larger.
When looking at the data, as presented on each vendors website (see link to each vendor below), most list some locations coming in the future. It’s really impressive to see the number of “coming soon” locations. These “coming soon” locations are not included below (as of blog post date).
Before showing a breakdown for each vendor the following table gives the total number of data center regions for each vendor.
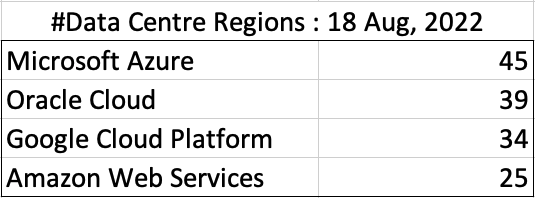
The numbers presented in the above table are different to does presented in the original CloudWars article or their updated numbers. If you look at the comments on that article and the comments on LinkedIn, you will see there was some disagreement of on their numbers. The problem is a data quality one, and vendors presenting their list of data centers in different parts of their website and documentation. Data quality and consistency is always a challenge, and particularly so when publishing data on vendor blogs, documentation and various websites. Indeed, the data I present in this post will be out of date within a few days/weeks. I’ve also excluded locations marked as ‘coming soon’ (see Azure listing).
Looking at the numbers in the above table can be a little surprising, particularly if you look at AWS, and then look at the difference in numbers between AWS and Azure and even Oracle. Very soon Azure will have double the number of data center regions when compared to AWS.
What do these numbers tell you? Based on just these numbers it would appear that Azure and Oracle Cloud are BIG cloud providers, and are much bigger than AWS. But maybe AWS has data centers that are way way bigger than those two vendors. It can be a little challenging to know the size and scale of each data center. Maybe they are going after different types of customers? With the roll out of Cloud over the past few years, there has been numerous challenges from legal and sovereign related issues requiring data to be geographically located within a country or geographic region. Most of these restrictions apply to larger organizations in the financial, insurance, and government related, etc. Given the historical customer base of Microsoft and Oracle, maybe this is driving their number of data center regions.
In more recent times there has been a growing interest, and in some sectors a growing need for organizations to be multi-cloud. Given the number of data center regions, for Azure and Oracle, and commonality in their geographic locations, it isn’t surprising to see the recent announcement from Azure and Oracle of their interconnect agreement and making the Oracle Database Service available (via interconnect) from Azure. I’m sure we will see more services being shared between these two vendors, and other might join in doing something similar.
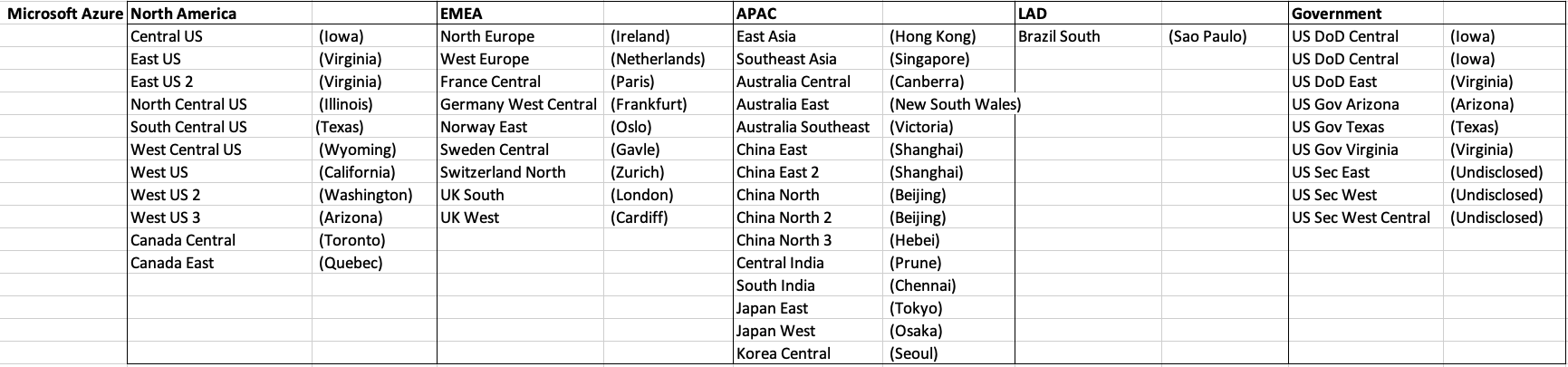
Let’s get back to the numbers and data for each Vendor. I’ve also included a link to the Vendor website where these data was obtained. (just remember these are based on date of blog post)
When you look at the Azure website listing the location, at first look it might appear they have many more locations. When you look closer at these, some/many of them are listed as ‘coming soon’. These ‘coming soon’ locations are not included in the above and below tables.
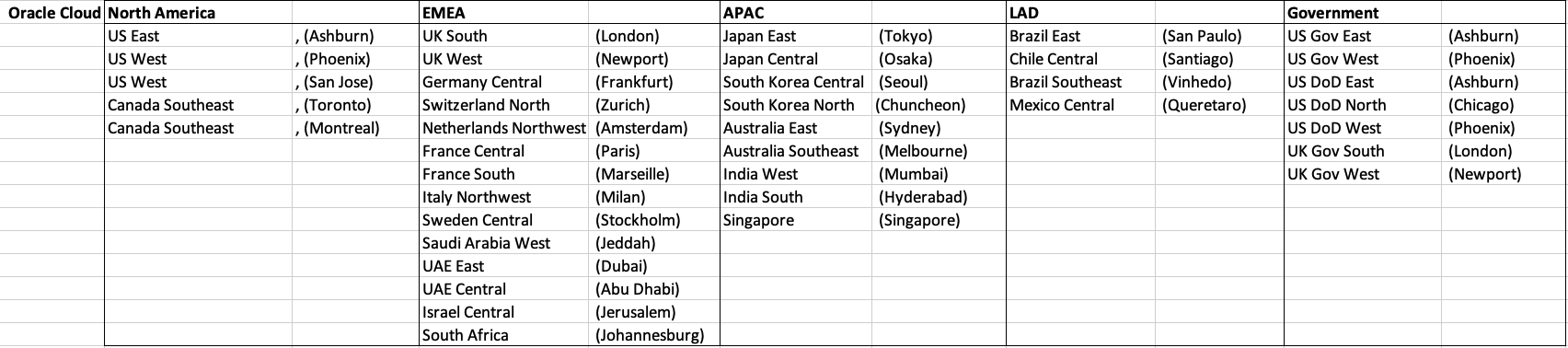
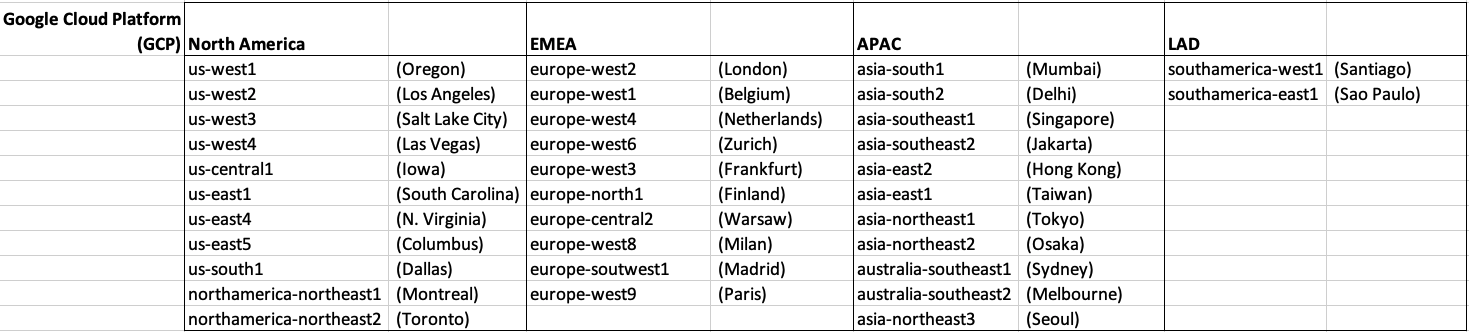
GCP doesn’t list and Government data center regions.

Oracle OCI AI Services
Oracle Cloud have been introducing new AI Services over the past few months, and we see a few more appearing over the coming few months. When you look at the list you might be a little surprised that these are newly available cloud services from Oracle. You might be surprised for two main reasons. Firstly, AWS and Google have similar cloud services available for some time (many years) now, and secondly, Oracle started talking about having these cloud services many years ago. It has taken some time for these to become publicly available. Although some of these have been included in other applications and offerings from Oracle, so probably they were busy with those before making them available as stand alone services.

These can be located in your Oracle Cloud account from the hamburger menu, as shown below

As you can see most of these AI Services are listed, except for the OCI Forecasting, which is due to be added “soon”. We can also expect to have an OCI Translation services and possibly some additional ones.
- OCI Language: This services can work with over 75 languages and allows you to detect and perform knowledge extraction from the text to include entity identification and labelling, classification of text into more than 600 categories, sentiment analysis and key phrase extraction. This can be used automate knolwedge extraction from customer feedback, product reviews, discussion forums, legal documents, etc
- OCI Speech: Performs Speech to Text, from live streaming of speech, audio and video recordings, etc creating a transcription. It works across English, Spanish and Portuguese, with other languages to be added. A nice little feature includes Profanity filtering, allowing you to tag, remove or mask certain words
- OCI Vision: This has two parts. The first is for processing documents, and is slightly different to OCI Language Service, in that this service looks at processing text documents in jpeg, pdf, png and tiff formats. Text information extraction is performed identifying keep terms, tables, meta-data extraction, table extraction etc. The second part of OCI Vision deals with image analysis and extracting key information from the image such as objects, people, text, image classification, scene detection, etc. You can use either the pretrained models or include your own models.
- OCI Anomaly Detection: Although anomaly detection is available via algorithms in the Database and OCI Data Science offerings, this new services allow for someone with little programming experience to utilise an ensemble of models, including the MSET algorithm, to provide greater accuracy with identifying unusual patterns in the data.
Note: I’ve excluded some services from the above list as these have been available for some time now or have limited AI features included in them. These include OCI Data Labelling, OCI Digital Assistant.
Some of these AI Services, based on the initial release, have limited functionality and resources, but this will change over time.
Oracle on AWS costs
In a previous post I walked through the steps of setting up an Oracle Database on AWS RDS. It was a very simple and straight forward process. The only thing to watch out for was to open the network to allow traffic in and out. I also showed how to connect SQL Developer to that database.
I’ve been using it for a few days and needed to move onto other things for a few days. I could leave the Database up and running during this period or I could shut down the Database to save a few dollars/euro. It also gave me a chance to see how much this database cloud instance is costing me. In my previous post, it was estimated to cost about 0.89c per day.
Before we look at the Actual/Real costs, let’s walk through the steps of shutting down the database.
To stop the database, click on the Actions button on the top right hand side of the screen, just above the database summary details. You will get a confirmation window/box appearing, see image below, asking you to confirm by clicking ‘Yes, Stop Now’.
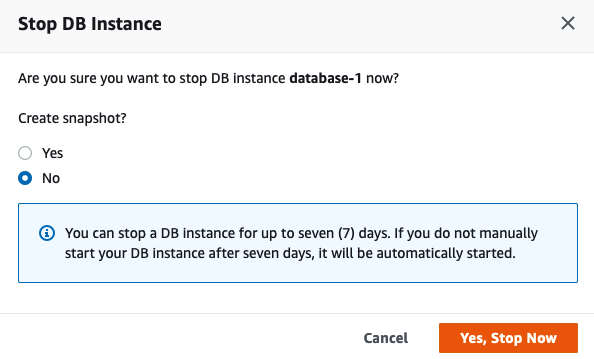
It will take a few minutes for this shutdown to complete and in my case it took approx. 8 minutes, which was a little surprising as no one was using it at the time. You might need to refresh the webpage to see this change.

That’s all very simple, but it does give you a warning about the stopped database instance. It will be restarted in 7 days time! So if this is a database you will occasionally use, then you will need to carefully manage this particular feature, otherwise you will end up with the database automatically starting and you will be paying for this.
What about the Costs?
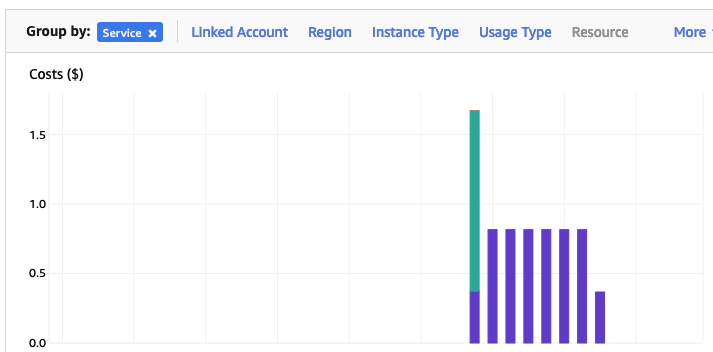
The costs for running this service can be found in the AWS Cost Management page. Here we can see the database was running for 7 and a bit days before I shut it down, and we can see the daily cost was 0.82c. Two things note about these costs. There was larger cost for the first day. Most of this cost was associated with the setup and configuration of the database service. The second thing to note is the costs listed in this console do not include taxes.
A got the bill for this usage, and it came to $6.94, consisting of $5.64 for usage (approx. 75c per day) and $1.30 in taxes/vat. Not a lot considering some cloud services, but comes out at approx 92.5c per day, which is a little more than the estimated cost when the service was being created. A small example of what can happen between the “in theory” cost of cloud versus the actual costs.
OCI Data Science – Initial Setup and Configuration
After a very, very, very long wait (18+ months) Oracle OCI Data Science platform is now available.
But before you jump straight into using OCI Data Science, there is a little bit of setup required for your Cloud Tenancy. There is the easy simple approach and then there is the slightly more involved approach. These are
- Simple approach. Assuming you are just going to use the root tenancy and compartment, you just need to setup a new policy to enable the use of the OCI Data Science services. This assuming you have your VNC configuration complete with NAT etc. This can be done by creating a policy with the following policy statement. After creating this you can proceed with creating your first notebook in OCI Data Science.
allow service datascience to use virtual-network-family in tenancy
- Slightly more complicated approach. When you get into having a team based approach you will need to create some additional Oracle Cloud components to manage them and what resources are allocated to them. This involved creating Compartments, allocating users, VNCs, Policies etc. The following instructions brings you through these steps
IMPORTANT: After creating a Compartment or some of the other things listed below, and they are not displayed in the expected drop-down lists etc, then either refresh your screen or log-out and log back in again!
1. Create a Group for your Data Science Team & Add Users
The first step involves creating a Group to ‘group’ the various users who will be using the OCI Data Science services.
Go to Governance and Administration ->Identity and click on Groups.
Enter some basic descriptive information. I called my Group, ‘my-data-scientists’.



Now click on your Group in the list of Groups and add the users to the group.
You may need to create the accounts for the various users.
2. Create a Compartment for your Data Science work
Now create a new Compartment to own the network resources and the Data Science resources.
Go to Governance and Administration ->Identity and click on Compartments.
Enter some basic descriptive information. I’ve called my compartment, ‘My-DS-Compartment’.


3. Create Network for your Data Science work
Creating and setting up the VNC can be a little bit of fun. You can do it the manual way whereby you setup and configure everything. Or you can use the wizard to do this. I;m going to show the wizard approach below.
But the first thing you need to do is to select the Compartment the VNC will belong to. Select this from the drop-down list on the left hand side of the Virtual Cloud Network page. If your compartment is not listed, then log-out and log-in!


To use the wizard approach click the Networking QuickStart button.
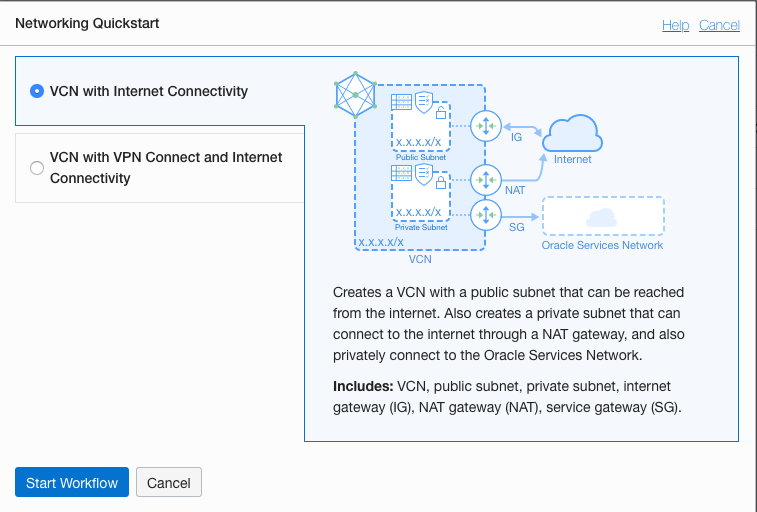
Select the option ‘VCN with Internet Connectivity and click Start Workflow, as you will want to connect to it and to allow the service to connect to other cloud services.
I called my VNC ‘My-DS-vnc’ and took the default settings. Then click the Next button.

The next screen shows a summary of what will be done. Click the Create button, and all of these networking components will be created.
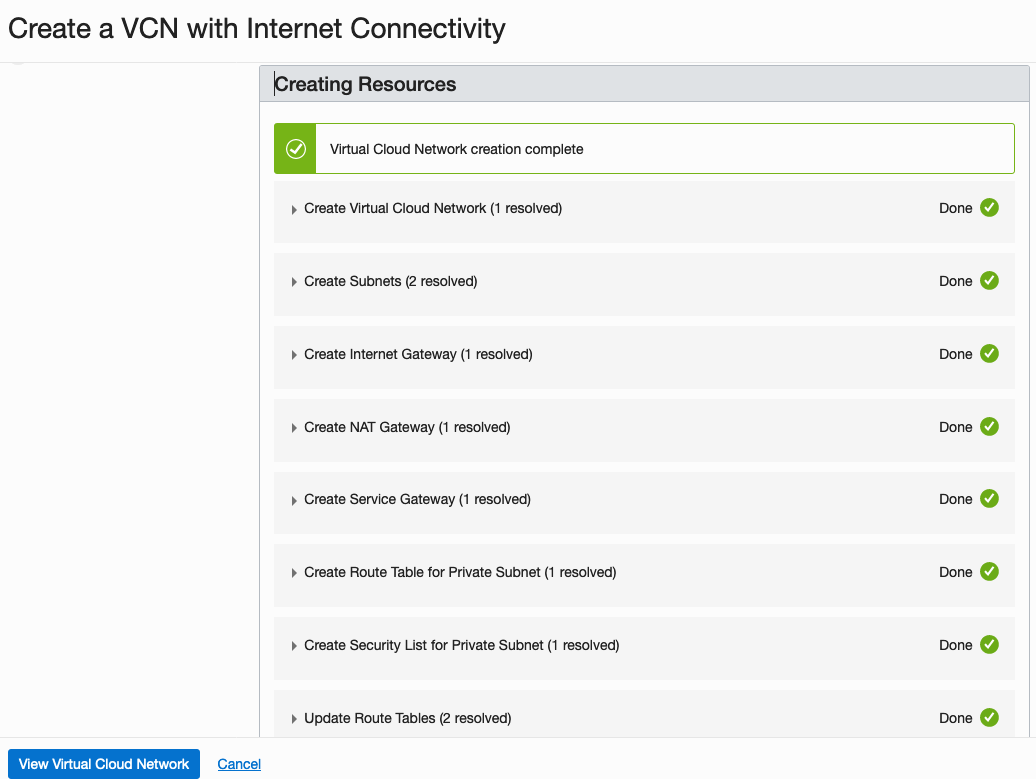
All done with creating the VNC.
4. Create required Policies enable OCI Data Science for your Compartment
There are three policies needed to allocated the necessary resources to the various components we have just created. To create these go to Governance and Administration ->Identity and click on Policies.
Select your Compartment from the drop-down list. This should be ‘My-DS-Compartment’, then click on Create Policy.
The first policy allocates a group to a compartment for the Data Science services. I called this policy, ‘DS-Manage-Access’.
allow group My-data-scientists to manage data-science-family in compartment My-DS-Compartment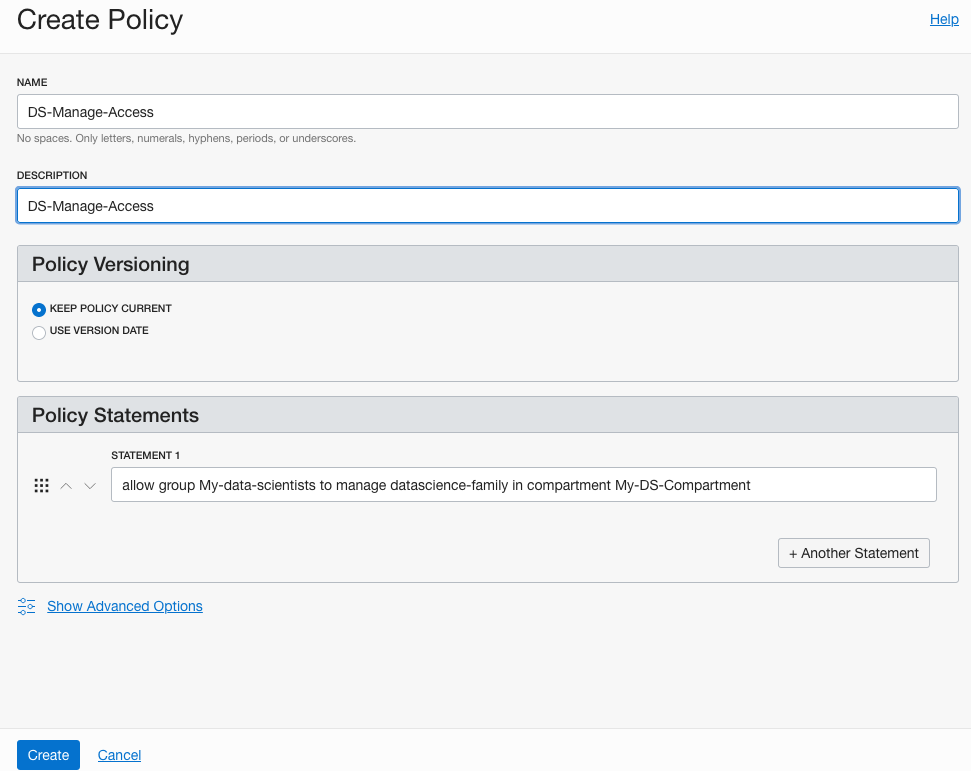
The next policy is to give the Data Science users access to the network resources. I called this policy, ‘DS-Manage-Network’.
allow group My-data-scientists to use virtual-network-family in compartment My-DS-Compartment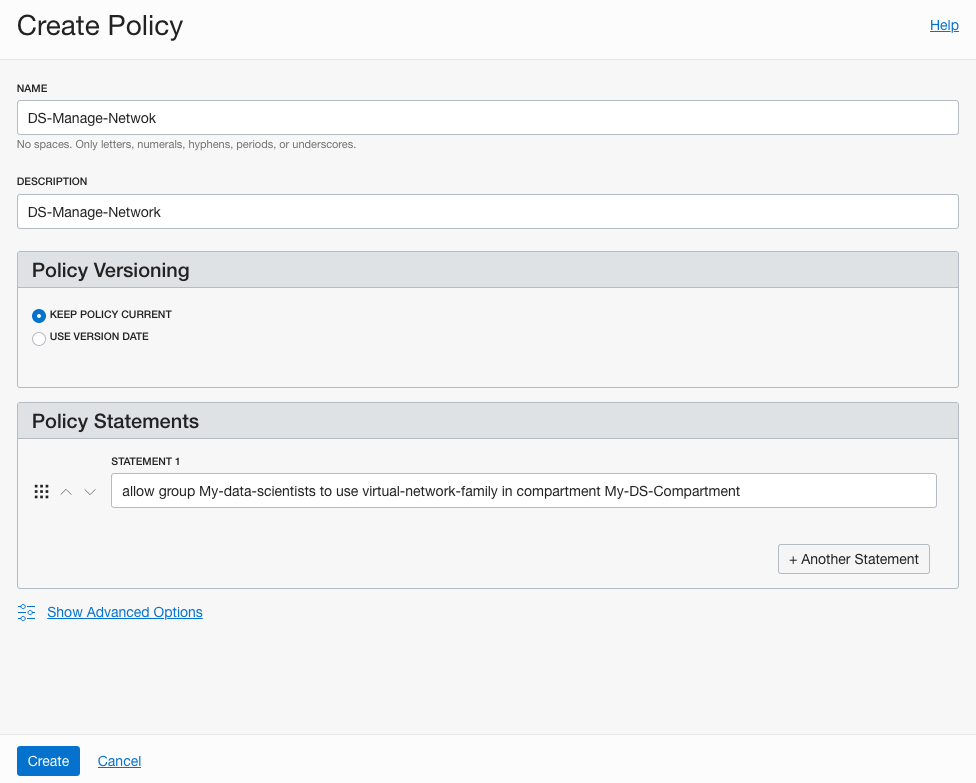
And the third policy is to give Data Science service access to the network resources. I called this policy, ‘DS-Network-Access’.
allow service datascience to use virtual-network-family in compartment My-DS-Compartment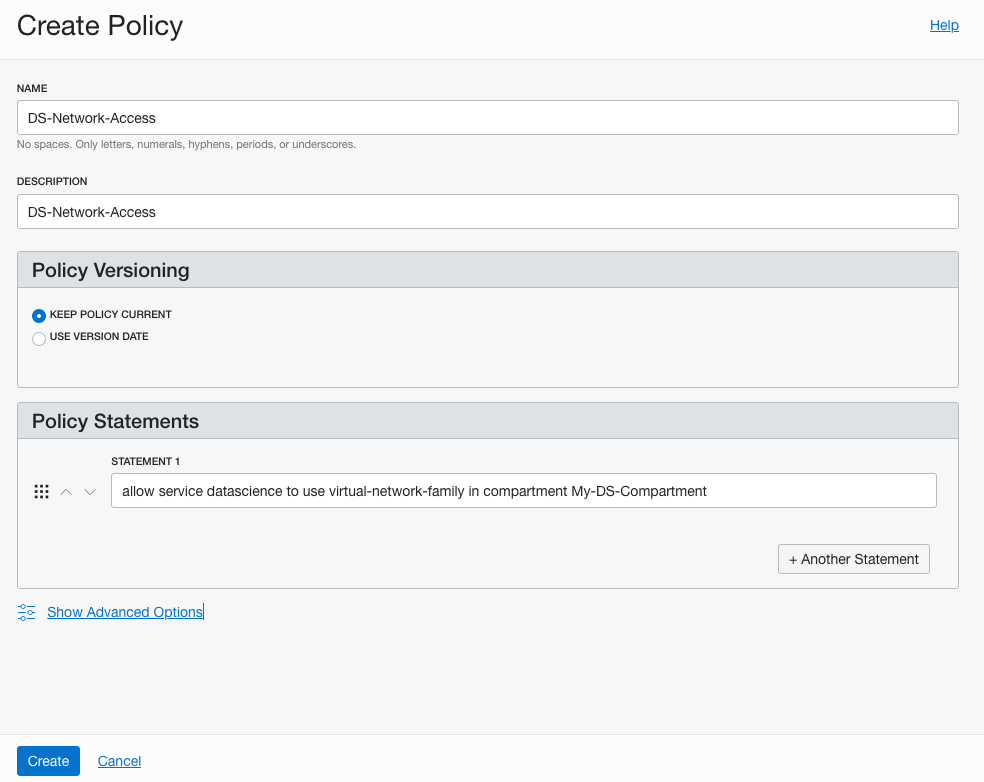
Job Done 🙂
You are now setup to run the OCI Data Science service. Check out my Blog Post on creating your first OCI Data Science Notebook and exploring what is available in this Notebook.
Creating a VM on Oracle Always Free
I’m going to create a new Cloud VM to host some of my machine learning work. The first step is to create the VM before installing the machine learning software.
That’s what I’m going to do in this blog post and the next blog post. In this blog post I’ll step through how to setup the VM using the Oracle Always Free cloud offering. In the next I’ll go through the machine learning software install and setup.
Step 1 – Create a ssh key/file
Whatever your preferred platform for your day to day computer there will be software available for you to generate a ssh key file. You will need this when creating the VM and for when you want to login in to VM on the command line. My day-to-day workhorse is a Mac, and I used the following command to create the ssh key file.
ssh-keygen -t rsa -N "" -b 2048 -C "myOracleCloudkey" -f myOracleCloudkey
Step 2 – Login and Select create VM
Log into your Oracle Cloud Always Free account.

Select Create a VM Instance.

Step 3 – Configure the VM
Give the instance a name. I called mine ‘b01-vm-1‘
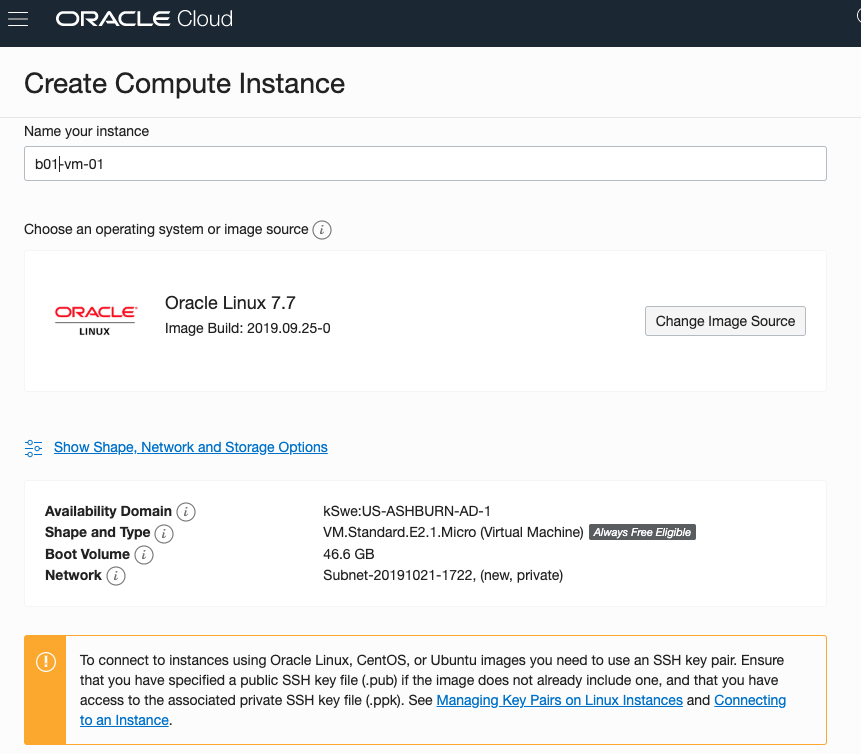
Expand the networks section by clicking on Show Shape, Network and Storage Options. Set the IP address to be public.
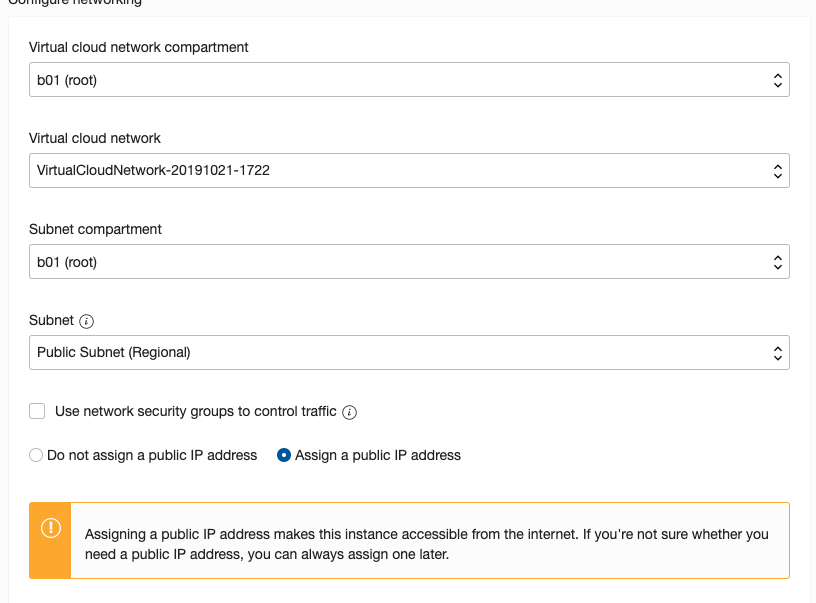
Scroll down to the ssh section. Select the ssh file you created earlier.
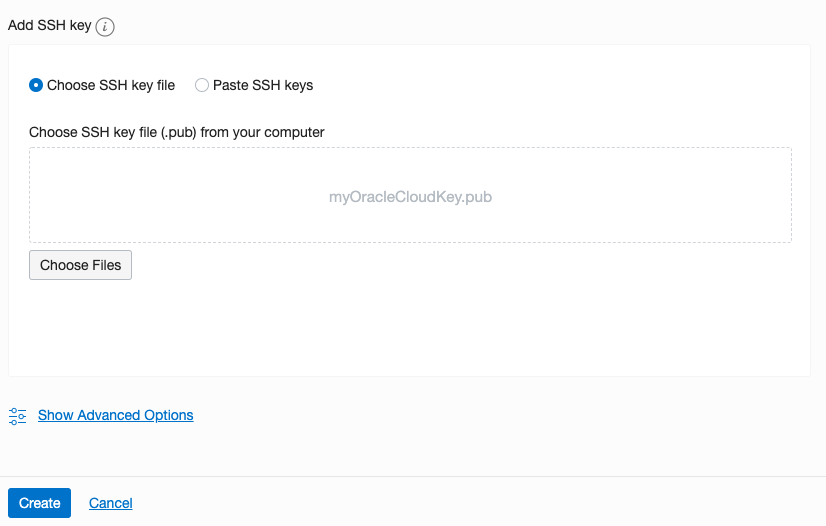
Click on the Create button.
That’s it, all done. Just wait for the VM to be created. This will takes a few seconds.
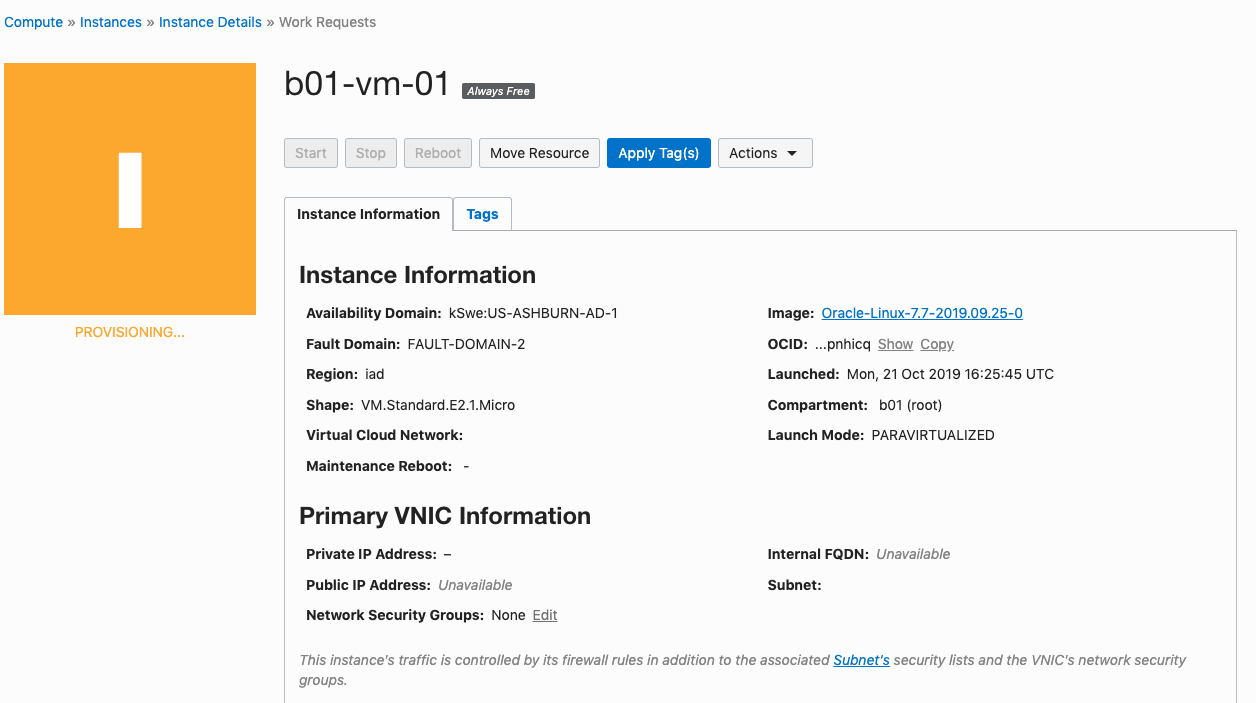
After the VM is created the IP address will be listed on this screen. Take note of it.
Step 4 – Connect and log into the VM
We can not log into the VM using ssh, to prove that it exists, using the command
ssh -i <name of ssh file> opc@<ip address of VM>
When I use this command I get the following:
ssh -i XXXXXXXXXX opc@XXX.XXX.XXX.XXX The authenticity of host 'XXX.XXX.XXX.XXX (XXX.XXX.XXX.XXX)' can't be established. ECDSA key fingerprint is SHA256:fX417Z1yFoQufm7SYfxNi/RnMH5BvpvlOb2gOgnlSCs. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'XXX.XXX.XXX.XXX' (ECDSA) to the list of known hosts. Enter passphrase for key 'XXXXXXXXXX': [opc@b1-vm-01 ~]$ pwd /home/opc [opc@b1-vm-01 ~]$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 469092 0 469092 0% /dev tmpfs 497256 0 497256 0% /dev/shm tmpfs 497256 6784 490472 2% /run tmpfs 497256 0 497256 0% /sys/fs/cgroup /dev/sda3 40223552 1959816 38263736 5% / /dev/sda1 204580 9864 194716 5% /boot/efi tmpfs 99452 0 99452 0% /run/user/1000
And there we have it. A VM setup on Oracle Always Free.
Next step is to install some Machine Learning software.
Oracle ADW how to load new OML notebooks
Oracle Autonomous Database (ADW) has been out a while now and have had several, behind the scenes, improvements and new/additional features added.
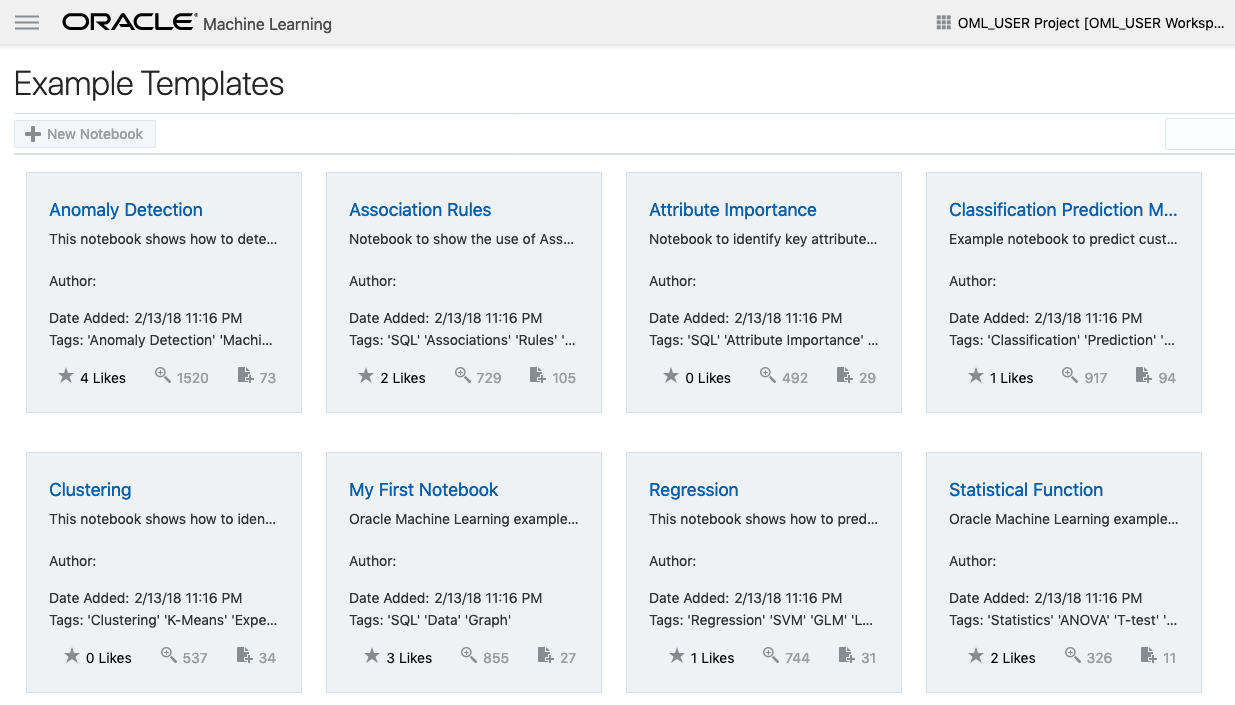
If you have used the Oracle Machine Learning (OML) component of ADW you will have seen the various sample OML Notebooks that come pre-loaded. These are easy to open, use and to try out the various OML features.

The above image shows the top part of the login screen for OML. To see the available sample notebooks click on the Examples icon. When you do, you will get the following sample OML Notebooks.
But what if you have a notebook you have used elsewhere. These can be exported in json format and loaded as a new notebook in OML.
To load a new notebook into OML, select the icon (three horizontal line) on the top left hand corner of the screen. Then select Notebooks from the menu.

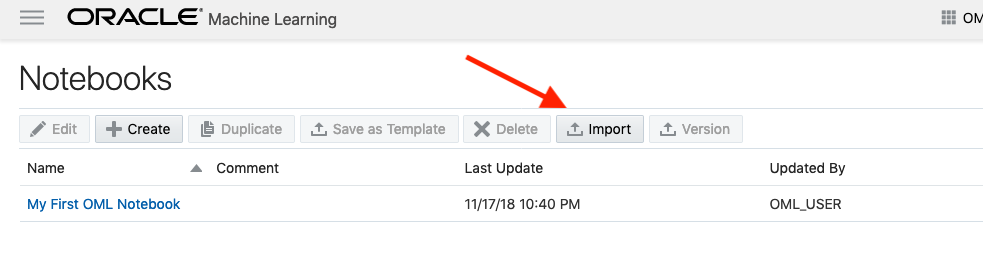
Then select the Import button located at the top of the Notebooks screen. This will open a File window, where you can select the json file from your file system.
A couple of seconds later the notebook will be available and listed along side any other notebooks you may have created.
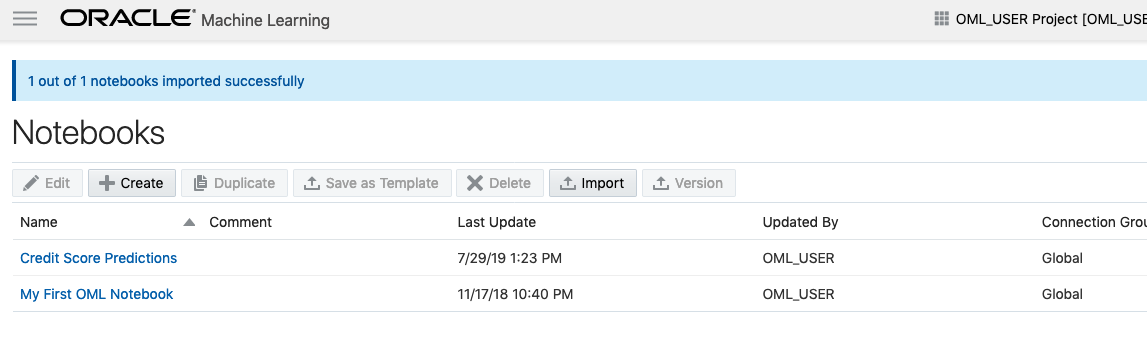
All done!
You have now imported a new notebook into OML and can now use it to process your data and perform machine learning using the in-database features.
Machine Learning Tools and Workbenches
The following is a list of the most commonly used tools and workbenches for machine learning. These are specific to machine learning only. This list does not include any library or frameworks. These are tools and workbenches only. Most offering machine learning tools will include the following features:
- Easy drag and drop capabilities
- Data collection
- Data preparation and cleaning
- Model building
- Data Visualization
- Model Deployment
- Integration with other tools and languages
As more and more organizations implement machine learning, there are two core aims they want to achieve.
- Employee Productivity: Who wants to spend days or weeks writing mundane code to load data, clean data, etc etc etc. No one wants to do this and especially employers don’t want their staff wasting time on this. Instead they are happy to invest in tools and workbenches where a lot or most or all of these mundane tasks are automated for you. You can not concentrate on the important tasks of adding value to your organisation. This saves money, improves employee productivity and employee value.
- Integration with Technical Architecture: Many of these tools and workbenches allow for easy integration with the technical architecture and thereby allowing easy and quick integration of machine learning withe the day to day activities of the organization. This saves money, improves employee productivity and employee value.
SAS
SAS software has been around for every and is the great grand-daddy of analytics and machine learning. They have built a large number of machine learning tools and solutions built upon these for various industries. Their core machine learning tools include SAS Enterprise Miner and SAS Visual Data Mining and Machine Learning.


Microsoft
Microsoft have been improving their Machine Learning offering over the years and most of this is based on the Azure cloud platform with Microsoft Azure Machine Learning Studio and Azure Databricks.


SAP
SAP Leonardo is a cloud based platform for machine learning and supports tight integration with other SAP software.


Oracle
Oracle have a number of machine learning tools and supports for the main machine learning languages. They have built a large number of applications (both cloud and on-premises) with in-built machine learning. Their main tools for machine learning include Oracle Data Miner, Oracle Machine Learning and Oracle Analytics (OAC or DVD versions)



Cloudera
If you work with hadoop and big data then you are probably using Cloudera in some way. Cloudera have hired Hilary Mason as their GM of ML. By taking an “AI factory” approach to turning data into decisions, you can make the process of building, scaling, and deploying enterprise ML and AI solutions automated, repeatable, and predictable—boring even. Cloudera Data Science Workbench is their solution.
IBM
IBM have a number of machine learning tools, one of them being a long standing member of the machine learning community, SPSS Modeler. Other machine learning tools include Watson Studio, IBM Machine Learning for z/OS, and IBM Watson Explorer.




Google have a large number of machine learning solutions including everything from traditional machine learning, into NLP, in Image processing, Video processing, etc. It’s a long list. Many of these come with various APIs to access these features. Most of these revolve around their Google AI Cloud offering. But sticking with the tools and workbenches we have AI Platform Notebooks, Kubeflow, and BigQuery ML.



TensorBoard
TensorBoard is a suite of tools for graphical representation of different aspects and stages of machine learning in TensorFlow.


Amazon
A bit like Goolge, Amazon has a large number of solutions for machine learning and AI, and most of these are available via an API or some cloud service. Amazon SageMaker is their main service.


Looker
Looker connects directly with Google BQML reduces additional complexity for data scientists by eliminating the need to move outputs of predictive models back into the database for use, while also increases the time-to-value for business users, allowing them to operationalize the outputs of predictive metrics to make better decisions every day.


Weka
Weka has been around for a long time and still popular in some research groups. Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization.



RapidMiner
RapidMiner Studio has been around for a long time and is one of the few more visual workflow tools (that everyone else should be doing).



Databricks
From the people who created Spark, we have another notebook solution for your machine learning projects called Databricks Workbench.


KNIME
KNIME Analytics Platform is the open source software for creating data science applications and services.


Dataiku
Dataiki Data Science (DSS) is a collaborative data science software workflow platform enabling data exploration, prototyping and delivery of analytical and machine learning solutions.

")
I’ve not included the tools like R Studio and Notebooks in this list as they don’t really address the aims listed above. But you will notice a lot of the above solutions are really Jupyter Notebooks. Most of these vendors have a long way to go to make the tasks of machine learning boring.
This list does not cover all available tools and workbenches, but it does list the most common one you will come across.
Time Series Forecasting in Oracle – Part 2
This is the second part about time-series data modeling using Oracle. Check out the first part here.
In this post I will take a time-series data set and using the in-database time-series functions model the data, that in turn can be used for predicting future values and trends.
The data set used in these examples is the Rossmann Store Sales data set. It is available on Kaggle and was used in one of their competitions.
Let’s start by aggregating the data to monthly level. We get.
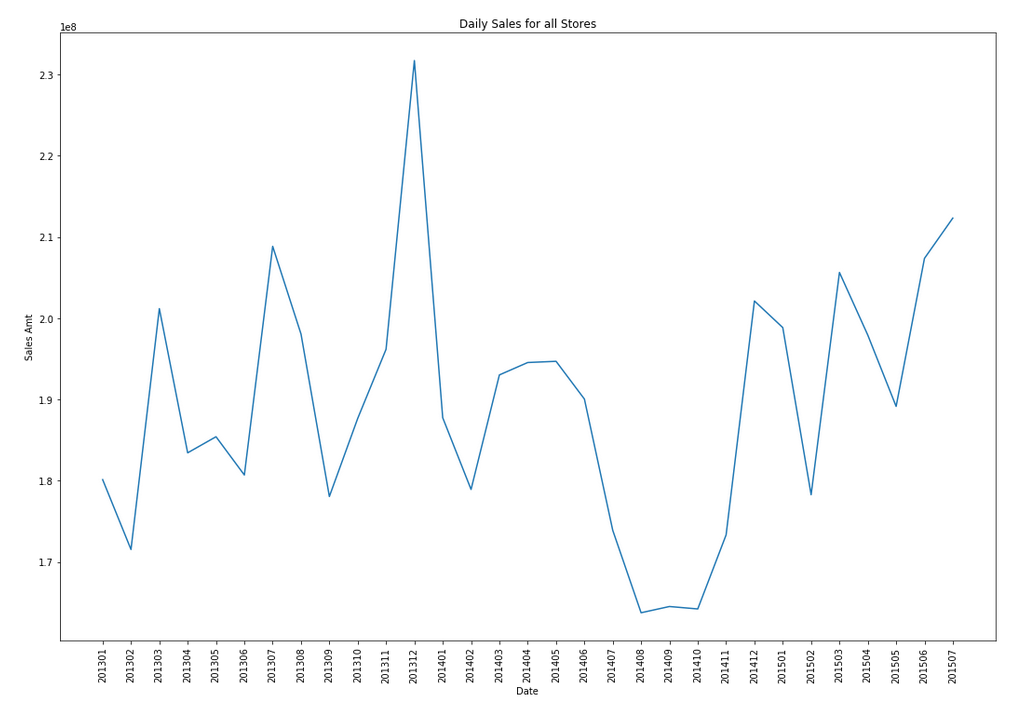
Data Set-up
Although not strictly necessary, but it can be useful to create a subset of your time-series data to only contain the time related attribute and the attribute containing the data to model. When working with time-series data, the exponential smoothing function expects the time attribute to be of DATE data type. In most cases it does. When it is a DATE, the function will know how to process this and all you need to do is to tell the function the interval.
A view is created to contain the monthly aggregated data.
-- Create input time series create or replace view demo_ts_data as select to_date(to_char(sales_date, 'MON-RRRR'),'MON-RRRR') sales_date, sum(sales_amt) sales_amt from demo_time_series group by to_char(sales_date, 'MON-RRRR') order by 1 asc;
Next a table is needed to contain the various settings for the exponential smoothing function.
CREATE TABLE demo_ts_settings(setting_name VARCHAR2(30),
setting_value VARCHAR2(128));
Some care is needed with selecting the parameters and their settings as not all combinations can be used.
Example 1 – Holt-Winters
The first example is to create a Holt-Winters time-series model for hour data set. For this we need to set the parameter to include defining the algorithm name, the specific time-series model to use (exsm_holt), the type/size of interval (monthly) and the number of predictions to make into the future, pass the last data point.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- set ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_holt);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
commit;
END;
Now we can call the function, generate the model and produce the predicted values.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
When the model is created a number of data dictionary views are populated with model details and some addition views are created specific to the model. One such view commences with DM$VP. Views commencing with this contain the predicted values for our time-series model. You need to append the name of the model created, in our example DEMO_TS_MODEL.
-- get predictions select case_id, value, prediction, lower, upper from DM$VPDEMO_TS_MODEL order by case_id;
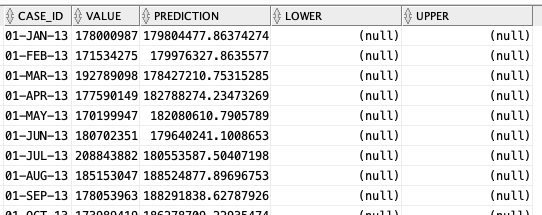
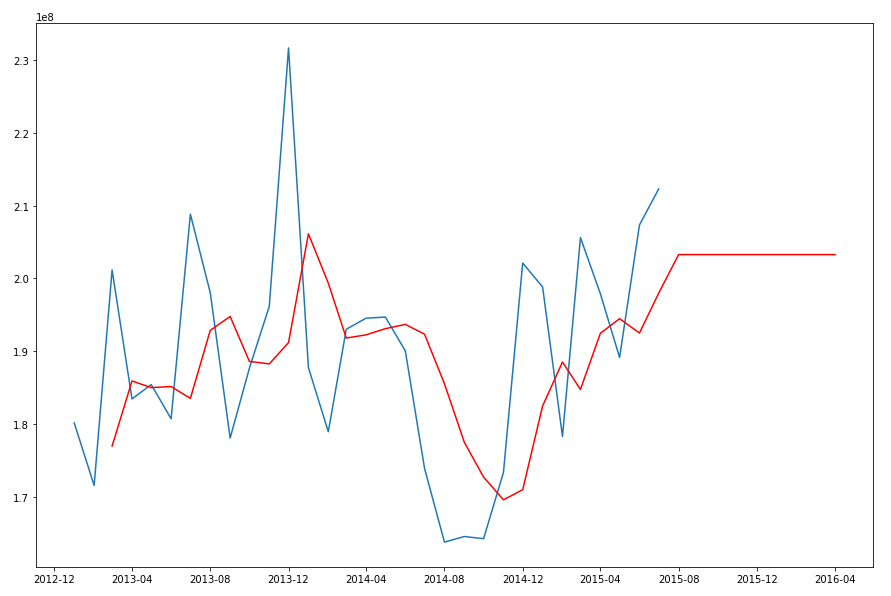
When we plot this data we get.
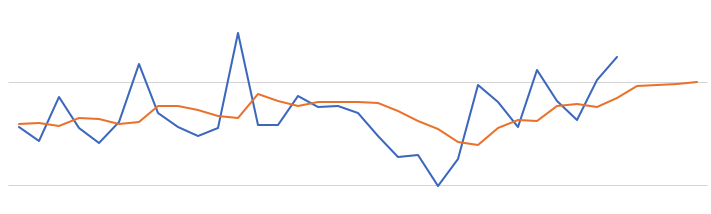
The blue line contains the original data values and the red line contains the predicted values. The predictions are very similar to those produced using Holt-Winters in Python.
Example 2 – Holt-Winters including Seasonality
The previous example didn’t really include seasonality into the model and predictions. In this example we introduce seasonality to allow the model to pick up any trends in the data based on a defined period.
For this example we will change the model name to HW_ADDSEA, and the season size to 5 units. A data set with a longer time period would illustrate the different seasons better but this gives you an idea.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- select ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters Seasonal Adjusted
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_HW_ADDSEA);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
-- set seasonal cycle to be 5 quarters
insert into demo_ts_settings
values (dbms_data_mining.exsm_seasonality,
'5');
commit;
END;
We need to re-run the creation of the model and produce the predicted values. This code is unchanged from the previous example.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
When we re-query the DM$VPDEMO_TS_MODEL we get the new values. When plotted we get.
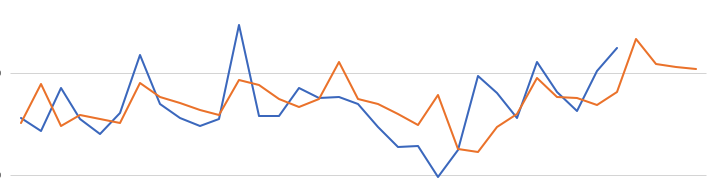
The blue line contains the original data values and the red line contains the predicted values.
Comparing this chart to the chart from the first example we can see there are some important differences between them. These differences are particularly evident in the second half of the chart, on the right hand side. We get to see there is a clearer dip in the predicted data. This mirrors the real data values better. We also see better predictions as the time line moves to the end.
When performing time-series analysis you really need to spend some time exploring the data, to understand what is happening, visualizing the data, seeing if you can identify any patterns, before moving onto using the different models. Similarly you will need to explore the various time-series models available and the parameters, to see what works for your data and follow the patterns in your data. There is no magic solution in this case.

You must be logged in to post a comment.