
ethics
NATO AI Strategy
Over the past 18 months there has been wide spread push buy many countries and geographic regions, to examine how the creation and use of Artificial Intelligence (AI) can be regulated. I’ve written many blog posts about these. But it isn’t just government or political alliances that are doing this, other types of organisations are also doing so.
NATO, the political and (mainly) military alliance, has also joined the club. They have release a summary version of their AI Strategy. This might seem a little strange for this type of organisation to do something like this. But if you look a little closer NATA also says they work together in other areas such as Standardisation Agreements, Crisis Management, Disarmament, Energy Security, Clime/Environment Change, Gender and Human Security, Science and Technology.
In October/November 2021, NATO formally adopted their Artificial Intelligence (AI) Strategy (for defence). Their AI Strategy outlines how AI can be applied to defence and security in a protected and ethical way (interesting wording). Their aim is to position NATO as a leader of AI adoption, and it provides a common policy basis to support the adoption of AI System sin order to achieve the Alliances three core tasks of Collective Defence, Crisis Management and Cooperative Security. An important element of the AI Strategy is to ensure inter-operability and standardisation. This is a little bit more interesting and perhaps has a lessor focus on ethical use.
NATO’s AI Strategy contains the following principles of Responsible use of AI (in defence):
- Lawfulness: AI applications will be developed and used in accordance with national and international law, including international humanitarian law and human rights law, as applicable.
- Responsibility and Accountability: AI applications will be developed and used with appropriate levels of judgment and care; clear human responsibility shall apply in order to ensure accountability.
- Explainability and Traceability: AI applications will be appropriately understandable and transparent, including through the use of review methodologies, sources, and procedures. This includes verification, assessment and validation mechanisms at either a NATO and/or national level.
- Reliability: AI applications will have explicit, well-defined use cases. The safety, security, and robustness of such capabilities will be subject to testing and assurance within those use cases across their entire life cycle, including through established NATO and/or national certification procedures.
- Governability: AI applications will be developed and used according to their intended functions and will allow for: appropriate human-machine interaction; the ability to detect and avoid unintended consequences; and the ability to take steps, such as disengagement or deactivation of systems, when such systems demonstrate unintended behaviour.
- Bias Mitigation: Proactive steps will be taken to minimise any unintended bias in the development and use of AI applications and in data sets.
By acting collectively members of NATO will ensure a continued focus on interoperability and the development of common standards.
Some points of interest:
- Bias Mitigation efforts will be adopted with the aim of minimising discrimination against traits such as gender, ethnicity or personal attributes. However, the strategy does not say how bias will be tackled – which requires structural changes which go well beyond the use of appropriate training data.
- The strategy also recognises that in due course AI technologies are likely to become widely available, and may be put to malicious uses by both state and non-state actors. NATO’s strategy states that the alliance will aim to identify and safeguard against the threats from malicious use of AI, although again no detail is given on how this will be done.
- Running through the strategy is the idea of interoperability – the desire for different systems to be able to work with each other across NATO’s different forces and nations without any restrictions.
- What about Autonomous weapon systems? Some members do not support a ban on this technology.
- Has similar wording to the principles adopted by the US Department of Defense for the ethical use of AI.
- Wants to make defence and security a more attractive to private sector and academic AI developers/researchers.
- NATO principles have no coherent means of implementation or enforcement.
Truth, Fairness & Equality in AI – US Federal Trade Commission
Over the past few months we have seen a growing level of communication, guidelines, regulations and legislation for the use of Machine Learning (ML) and Artificial Intelligence (AI). Where Artificial Intelligence is a superset containing all possible machine or computer generated or apply intelligence consisting of any logic that makes a decision or calculation.
Although the EU has been leading the charge in this area, other countries have been following suit with similar guidelines and legislation.
There has been several examples of this in the USA over the past couple of years. Some of this has been prefaced by the debates and issues around the use of facial recognition. Some States in USA have introduced laws to control what can and cannot be done, but, at time of writing, where is no federal law governing the whole of USA.
In April 2021, the US Federal Trade Commission published and article on titled ‘Aiming for truth, fairness, and equity in Company’s use of AI‘.

They provide guidelines on how to build AI applications while avoiding potential issues such as bias and unfair outcomes, and at the same time incorporating transparency. In addition to the recommendations in the report, they point to three laws (which have been around for some time) which are important for developers of AI applications. These include:
- Section 5 of the FTC Act: The FTC Act prohibits unfair or deceptive practices. That would include the sale or use of – for example – racially biased algorithms.
- Fair Credit Reporting Act: The FCRA comes into play in certain circumstances where an algorithm is used to deny people employment, housing, credit, insurance, or other benefits.
- Equal Credit Opportunity Act: The ECOA makes it illegal for a company to use a biased algorithm that results in credit discrimination on the basis of race, color, religion, national origin, sex, marital status, age, or because a person receives public assistance.
These guidelines aims for truthfully, fairly and equitably. With these covering the technical and non-technical side of AI applications. The guidelines include:
- Start with the right direction: Get your data set right, what is missing, is it balanced, what’s missing, etc. Look at how to improve the data set and address any shortcomings, and this may limit you use model
- Watch out of discriminatory outcomes: Are the outcomes biased? If it works for you data set and scenario, will it work in others eg. Applying the model in a different hospital? Regular and detail testing is needed to ensure no discrimination gets included
- Embrace transparency and independence: Think about how to incorporate transparency from the beginning of the AI project. Use international best practice and standards, have independent audits and publish results, by opening the data and source code to outside inspection.
- Don’t exaggerate what you algorithm can do or whether it can deliver fair or unbiased results: That kind of says it all really. Under the FTC Act, your statements to business customers and consumers must be truthful, no-deceptive and backed up by evidence. Typically with the rush to introduce new technologies and products there can be a tendency to over exaggerate what it can do. Don’t do this
- Tell the truth about how you use data: Be careful about what data you used and how you got this data. For example, Facebook using facial recognition software on pictures default, when they asked for your permission but ignored what you said. Misrepresentation of what the customer/consumer was told.
- Do more good than harm: A practice is unfair if it causes more harm than good. Making decisions based on race, color, religion, sex, etc. If the model causes more harm than good, if it causes or is likely to cause substantial injury to consumers that I not reasonably avoidable by consumers and not outweighed by countervailing benefits to consumers or to competition, their model is unfair.
- Hold yourself accountable: If you use AI, in any form, you will be held accountable for the algorithm’s performance.
Some of these guidelines build upon does from April 2020, on Using Artificial Intelligence and Algorithms, where there is a focus on fair use of data, transparency of data usage, algorithms and models, ability to clearly explain how a decision was made, and ensure all decisions made are fair and unbiased
Working with AI products and applications can be challenging in many different ways. Most of the focus, information and examples is about building these. But that can be the easy part. With the growing number of legal aspects from different regions around the world the task of managing AI products and applications is becoming more and more complicated.
The EU AI Regulations supports the role of person to oversee these different aspects, and this is something we will see job adverts for very very soon, no matter what country or region you live in. The people in these roles will help steer and support companies through this difficult and evolving area, to ensure compliance with local as well and global compliance and legal requirements.
AutoML, what is it good for? It Depends!
Automated Machine Learning (AutoML) seems to be everywhere and every Analytics product and SaaS offering seems to have some element of AutoML built into them. Part of the reason for this is because most of the market analysts, such as Gartner etc., have been rating Machine Learning (ML) products and services based on them having an AutoML feature.

Some of the benefits of AutoML is it will automatically generate a ML model for you without you having to worry about any of the technical details and the various statistical tests to measure if the model is useful. This kind of message has resulted is lots and lots of articles talking about the death of the Data Scientist, as they are no longer needed. We must remember ML is only one of the tools and skills of the data scientist.
This can all sound great. No need to hire these expensive data scientists, I can just use this AutoML software to create a ML model, for my data, and life will be good with all these wonderful predictions. Just think of the money I’ll be making and saving!
Where the fun comes into all of this is when someone issues legal proceedings based on what one of these AutoML models has predicted. The AutoML has made an incorrect prediction. The problem you now face, probably in court, is trying to justify the prediction by saying the machine/computer/algorithm made it, and you have no idea how or what it is doing to make the prediction. Good luck in a court explaining that to a judge and/or jury. Be prepared to hand over lots of money
What is missing is the human in the loop, and in most cases this will be the data scientist or machine learning engineer (or someone else with a really cool job title). Part of their job is to evaluate lots of difference models for you data (remember they will create lots and lots of models and not just one!), determine (from experimentation) what algorithms work best with your data and problem, optimize these models and assess the impact of changing hyperparameters, look at how these ML models are behaving, are there any biases in the model or data, use a wide variety of statistic tests to assess the models, examine how the model works with different sub-parts of the data (customers), look at any potential legal and legislative issues not just in one geographic but across many disparate regions all of which have different legal requirements, etc.
As you can see there are many additional tasks beyond the ML steps needed to create, verify and select a ML to use. All of this is before you look at how it can be deployed in your production systems/architecture and building out you MLOps.
One importing characteristic of having the human in the loop is Explainability. Explainability of the process followed, what models were produced, the effect of tuning and opimizing, possible biases and mitigating steps, etc etc The list goes on and on. This the role of the data scientist and now it might look like a good idea to hire a good data scientist who understands all of this.

Taking a little step back, AutoML is kind of good cool feature/tool. A lot of the main steps of creating all those ML models, tuning them and evaluating them, etc can be very boring work. You do same steps for each model and do it all over again for the next, and so on for the tens or hundreds of models you will be creating. Most data scientists will have scripts in their toolbox (based from their experience) to automatically perform all of these steps and output the results. I mentioned the word experience in the last sentence. It can take a bit of time to build up to this. The AutoML products will do all of this automatically for you hence you don’t have to hire a data scientist to do it (see what I said above about this).
I mentioned above some of the challenges and the need to keep a human in the loop. AutoML can be seen as another tool to assist the data scientist and not to replace them. AutoML can be used to to help the data scientist work towards identifying what ML models to use. But this can be a bit of a challenge to do. It depends on what product or library you use. Some AutoML solutions act as a black box. Kind of like the image at the top of this post. These are simple to use but the draw back is there is not explainability or ability of the data scientist to really assess what is happening at each step. There are AutoML products/solutions that allow you to inspect and monitor what is happening at each step within AutoML. The diagram given able is one example of this. This allows for the human in the loop and allows for explainability. If the data scientist sees some unusual direction being taken by AutoML they can see where and why this is happening and can take corrective action. AutoML isn’t a black box in this scenario.
I mentioned above, AutoML can be another tool for the data scientist to use. Look on AutoML as quick way to see what might be possible. Using the information from each step of AutoML, the data scientist can use this information to guide them towards creating a more suitable and usable ML model, and do so in perhaps a slightly shorter space of time.
Going back to the title of the post ‘AutoML, what is it good for?’, the answer really is ‘It Depends!’, but if you do use it, be careful how you use the models and results beyond doing some simple investigation. And be careful of product offerings saying you don’t need anything else.
Responsible AI: Principles & Standards around the World
During 2019 there was been a increase awareness of AI and the need for Responsible AI. During 2020 (and beyond) we will see more and more on this topic. To get you started on some of the details and some background reading, here are links to various Principles and Standards for Responsible AI from around the World.
| Standard/Principles | Description |
|---|---|
| EU AI Ethics Guidelines | The Ethics Guidelines for Trustworthy Artificial Intelligence developed by EU High-Level Expert Group on AI highlights that trustworthy AI should be lawful, ethical and robust. Puts forward seven key requirements for AI systems should meet in order to be deemed trustworthy, including among others diversity, non-discrimination, societal and environmental well-being, transparency and accountability. |
| OECD principles on Artificial Intelligence | OECD’s member countries along with partner countries adopted the first ever set of intergovernmental policy guidelines on AI, agreeing to uphold international standards that aim to ensure AI systems are designed in a way that respects the rule of law, human rights, democratic values and diversity. They emphasize that AI should benefit people and the planet by driving inclusive growth, sustainable development and well-being. |
| CoE: Human Rights impacts of Algorithms | Council of Europe draft recommendation on the human rights impacts of algorithmic AI systems, released for consultation in August 2019 and to be adopted in early 2020. The document explicitly refers to the UN Guiding Principles on Business and Human Rights as a guidance for due diligence process and Human Rights Impact Assessments. |
| IEEE Global Initiative: Ethically Aligned Design | Ethically Aligned Design (EAD) Document is created to educate a broader public and to inspire academics, engineers, policy makers and manufacturers of autonomous and intelligent systems to take action on prioritizing ethical considerations. The general principles for AI design, manufacturing and use include: human rights, wellbeing, data agency, effectiveness, transparency, accountability, awareness of misuse, competence. The unique IEEE P7000 Standards series address specific issues at the intersection of technology and ethics and aimed to empower innovation across borders and enable societal benefit. |
| UN Sustainable Development Goals | The UN Sustainable Goals include the annual AI for Good Global Summit is the leading UN platform for global and inclusive dialogue on how artificial intelligence could help accelerate progress towards the Global Goals. |
| UN Business and Human Rights | The UN Guiding Principles on Business and Human Rights (UNGPs)gives a framework offering a roadmap to navigate responsibility-related challenges, rapid technological disruption and rising inequality, business has a unique opportunity to implement human-centered innovation by taking into account social, ethical and human rights implications of AI. |
| EU Collaborative Platforms and Social Learning | Several EU countries have articulated their ambitions related to artificial intelligence, it is of paramount importance to find your unique voice, track and join essential conversations, strategically engage in collective efforts and leave meaningful digital footprint. |
Always watching, always listening. Be careful with your data
The saying ‘Big Brother is Watching’ has been around a long time and typically gets associated with government organisations. But over the past few years we have a few new Big Brothers appearing. These are in the form of Google and Facebook and a few others.
These companies gather lots and lots. Some companies gather enormous amounts of data. This data will include details of your interactions with the companies through various websites, applications, etc. But some are gathering data in ways that you might not be aware. For example, take this following video. Data is being gathered about what you do and where you go even if you have disconnected your phone.
Did you know this kind of data was being gathered about you?
Just think of what they could be doing with that data, that data you didn’t know they were gathering about you. Companies like these generate huge amounts of income from selling advertisements and the more data they have about individuals the more the can understand what they might be interested. The generate customer profiles and sell expensive advertising based on having these very detailed customer profiles.
But it doesn’t stop there. Recently Google bought Fitbit. Just think about what they can do now. Combining their existing profiles of you as a person with you activities throughout every day, week and month. Just think about how various health and insurance companies would love to have this data. Yes they would and companies like Google would be able to charge these companies even more money for this level of detail on individuals/customers.
But it doesn’t stop there. There have been lots of reports of various apps sharing health and other related data with various companies, without their customers being aware this is happening.
What about Google Assistant? In a recent article by MIT Technology Review title Inside Amazon’s plan for Alexa to run your entire life, they discuss how Alexa can be used to control virtually everything. In this article Alexa’s cheif scientist say “plan is for the voice assistant to move from passive to proactive interactions. Rather than wait for and respond to requests, Alexa will anticipate what the user might want. The idea is to turn Alexa into an omnipresent companion that actively shapes and orchestrates your life. This will require Alexa to get to know you better than ever before.” When combined with other products this will allow “these new products let Alexa listen to and log data about a dramatically larger portion of your life“.
Just imagine if Google did the same with their Google Assistant! Big Brother isn’t just Watching, they are also Listening!
There has been some recent report of Google looking to get into Banking by offering checking accounts. The project, code-named Cache, is due to launch in 2020. Google has partnered with Citigroup and a credit union at Stanford University, which will administer the accounts. Users will be able to access their accounts through Google’s digital payment platform, Google Pay.
And there are the reports of Google having access to the health records of over 50 million people. In addition to this, Google has signed a deal with Ascension, the second-largest hospital system in the US, to collect and analyze millions of Americans’ personal health data. Ascension operates in 150 hospitals in 21 states.
What if they also had access to your banking details and spending habits? Google is looking at different options to extend financial products from the google pay into more main stream banking. There has been some recent report of them looking at offering current accounts.
I won’t go discussing their attempts at Ethics and their various (failed) attempts at establishing and Ethics Advisory Board. This has been well documented elsewhere.
Things are getting a bit scary and the saying ‘Big Brother is Watching You’, is very, very true.
In the ever increasing connected world, all of us have a responsibility to know what data companies are gathering on us. We need to decide how comfortable we are with this and if you aren’t then you need to take steps to ensure you protect yourself. Maybe part of this protection requires us to become less connected, stop using some apps, turn off more notification, turn off updates, turn off tracking, etc
While taking each product or offering individually, it may seem ok to us for Google and other companies to offer such services and to analyze our data to provide a better service. But for most people the issues arise when each of these products start to be combined. By doing this they get to have greater access and understanding our our data and our behaviors. What role does (digital) ethics play in all of this? This is something for the company and the employees to decide where things should stop. But when/how do you decide this? when do you/they know things have gone too far? how can you undo some of this work to go back to an acceptable level? what is an acceptable level and how do you define this?
As yo can see there are lots of things to consider and a vital component is the role of (digital) ethics. All organizations who process and analyze data need to have an ethics board and ethics needs to be a core part of every project. To support this everyone needs more training and awareness of ethics and what is acceptable or not.
Examples of Machine Learning with Facial Recognition
In a previous blog post I gave some examples of how facial images recognition and videos are being used in our daily lives. In this post I want to extend this with some additional examples. There are ethical issues around this and in some of these examples their usage has stopped. What is also interesting is the reaction on various social media channels about this. People don’t like it and and happen that some of these have stopped.
But how widespread is this technology? Based on these known examples, and this list is by no means anywhere near complete, but gives an indication of the degree of it’s deployment and how widespread it is.
Dubai is using facial recognition to measure customer satisfaction at four of the Roads and Transport Authority Customer Happiness Centers. They analyze the faces of their customers and rank their level of happiness. They can use this to generate alerts when the happiness levels falls below certain levels.

Various department stores are using facial recognition throughout the stores and at checkout. These are being used to delivery personalized adverts to users on either in-store screen or on personalized screens on the shopping trolley. And can be used to verify a person’s age if they are buying alcohol or other products. Tesco’s have previously used face-scanning cameras at tills in petrol stations to target advertisements at customers depending on their age and approximate age.

Some retail stores are using ML to monitor you, monitor what items you pick up and what you pay for at the checkout, identifying any differences and what steps to take next.
In a slight variation of facial recognition, some stores are using similar technology to monitor stock levels, monitor how people interact with different products (e.g pick up one product and then relate it with a similar product), and optimized location of products. Walmart has been a learner in the are of AI and Machine Learning in the retail section for some time now.
The New York Metropolitan Transport Authority has been using facial capture and recognition at several site across the city. Their proof of concept location was at the Robert F Kennedy Bridge. The company supplying the technology claimed 80% accuracy at predicting the person, through a widescreen while the car was traveling at low speed. These images can then be matched against government databases, such as driver license authorities, police databases and terrorist databases. The problem with this project was that it did not achieve one single positive match (within acceptable parameters) during the initial period of the project.
There are some reports that similar technology is being use on the New York Subway system in Time Square to help with identifying fare dodgers.
How about using facial recognition at boarding gates for your new flight instead of showing your passport or other official photo id. JetBlue and other airlines are now using this technology. Some airports have been using this for many many years.

San Francisco City government took steps in May 2019 to ban the use of facial recognition across all city functions. Other cities like Oakland and Sommerville in Massachusetts have implemented similar bans with other cities likely to follow. But it doesn’t ban the use by private companies.

What about using this technology to automatically monitor and manage staff. Manage staff, as in to decide who should be fired and who should be reallocated elsewhere. It is reported that Amazon is using facial and other recognition systems to monitor staff productivity in their warehouses.

A point I highlighted in my previous post was how are these systems/applications able to get enough images as training samples for their models. This is considering that most of the able systems/applications say they don’t keep any of the images they capture.
How many of us take pictures and post them on Facebook, Instagram, Snapchat, Twitter, etc. By doing this, you are making those images available to these companies to training their machine learning model. To do this they scrap the images for these sites and then have to manually label them with descriptive information. It is a combination of the image and descriptive information that is used by the machine learning algorithms to learn and build a model that suits their needs. See the MIT Technology Review article for more details and example on this topic.
There are also reports of some mobile phone apps that turn on your mobile phone camera. The apps will detect if the phone is possibly mounted on the dashboard of a car, and then takes pictures of the inside of the car and also pictures of where you are driving. Similar reports exists about many apps and voice activated devices.
So be careful what you post on social media or anywhere else online, and be careful of what apps you have on your mobile phone!
There is a general backlash to the use of this technology, and with more people becoming aware of what is happening, we need to more aware of what when and where this technology is being used.
Examples of using Machine Learning on Video and Photo in Public
Over the past 18 months or so most of the examples of using machine learning have been on looking at images and identifying objects in them. There are the typical examples of examining pictures looking for a Cat or a Dog, or some famous person, etc. Most of these examples are very noddy, although they do illustrate important examples.
But what if this same technology was used to monitor people going about their daily lives. What if pictures and/or video was captured of you as you walked down the street or on your way to work or to a meeting. These pictures and videos are being taken of you without you knowing.
And this raises a wide range of Ethical concerns. There are the ethics of deploying such solutions in the public domain, but there are also ethical concerns for the data scientists, machine learner, and other people working on these projects. “Just because we can, doesn’t mean we should”. People need to decide, if they are working on one of these projects, if they should be working on it and if not what they can do.
Ethics are the principals of behavior based on ideas of right and wrong. Ethical principles often focus on ideas such as fairness, respect, responsibility, integrity, quality, transparency and trust. There is a lot in that statement on Ethics, but we all need to consider that is right and what is wrong. But instead of wrong, what is grey-ish, borderline scenarios.
Here are some examples that might fall into the grey-ish space between right and wrong. Why they might fall more towards the wrong is because most people are not aware their image is being captured and used, not just for a particular purpose at capture time, but longer term to allow for better machine learning models to be built.
Can you imagine walking down the street with a digital display in front of you. That display is monitoring you, and others, and then presents personalized adverts on the digital display aim specifically at you. A classify example of this is in the film Minority Report. This is no longer science fiction.

This is happening at the Westfield shopping center in London and in other cities across UK and Europe. These digital advertisement screens are monitoring people, identifying their personal characteristics and then customizing the adverts to match in with the profile of the people walking past. This solutions has been developed and rolled out by Ocean Out Door. They are using machine learning to profile the individual people based on gender, age, facial hair, eye wear, mood, engagement, attention time, group size, etc. They then use this information to:
- Optimisation – delivering the appropriate creative to the right audience at the right time.
- Visualise – Gaze recognition to trigger creative or an interactive experience
- AR Enabled – Using the HD cameras to create an augmented reality mirror or window effect, creating deep consumer engagement via the latest technology
- Analytics – Understanding your brand’s audience, post campaign analysis and creative testing

Face Plus Plus can monitor people walking down the street and do similar profiling, and can bring it to another level where by they can identify what clothing you are wearing and what the brand is. Image if you combine this with location based services. An example of this, imagine you are walking down the high street or a major retail district. People approach you trying to entice you into going into a particular store, and they offer certain discounts. But you are with a friend and the store is not interested in them.
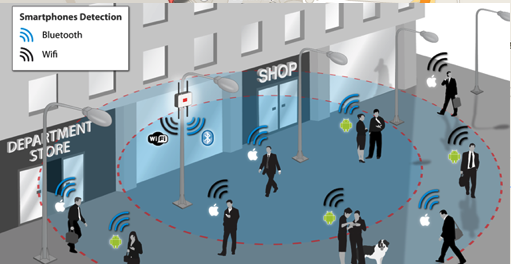
The store is using video monitoring, capturing details of every person walking down the street and are about to pass the store. The video is using machine/deep learning to analyze you profile and what brands you are wearing. The store as a team of people who are deployed to stop and engage with certain individuals, just because they make the brands or interests of the store and depending on what brands you are wearing can offer customized discounts and offers to you.
How comfortable would you be with this? How comfortable would you be about going shopping now?
For me, I would not like this at all, but I can understand why store and retail outlets are interested, as they are all working in a very competitive market trying to maximize every dollar or euro they can get.
Along side the ethical concerns, we also have some legal aspects to consider. Some of these are a bit in the grey-ish area, as some aspects of these kind of scenarios are slightly addresses by EU GDPR and the EU Artificial Intelligence guidelines. But what about other countries around the World. Then it comes to training and deploying these facial models, they are dependent on having a good training data set. This means they needs lots and lots of pictures of people and these pictures need to be labelled with descriptive information about the person. For these public deployments of facial recognition systems, then will need more and more training samples/pictures. This will allow the models to improve and evolve over time. But how will these applications get these new pictures? They claim they don’t keep any of the images of people. They only take the picture, use the model on it, and then perform some action. They claim they do not keep the images! But how can they improve and evolve their solution?
I’ll have another blog post giving more examples of how machine/deep learning, video and image captures are being used to monitor people going about their daily lives.

You must be logged in to post a comment.