
AI
SelectAI – Doing something useful
In a previous post, I introduced Select AI and gave examples of how to do some simple things. These included asking it using some natural language questions, to query some data in the Database. That post used both Cohere and OpenAI to process the requests. There were mixed results and some gave a different, somewhat disappointing, outcome. But with using OpenAI the overall outcome was a bit more positive. To build upon the previous post, this post will explore some of the additional features of Select AI, which can give more options for incorporating Select AI into your applications/solutions.
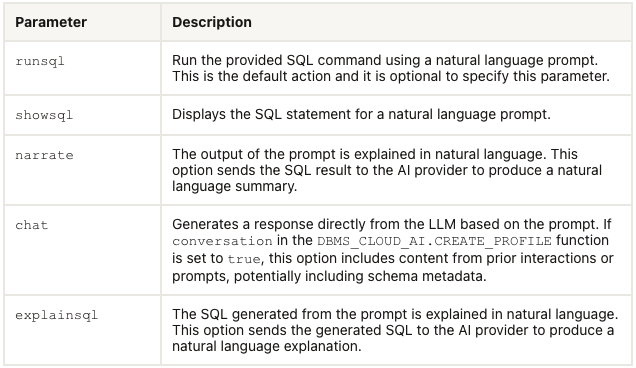
Select AI has five parameters, as shown in the table below. In the previous post, the examples focused on using the first parameter. Although those examples didn’t include the parameter name ‘runsql‘. It is the default parameter and can be excluded from the Select AI statement. Although there were mixed results from using this default parameter ‘runsql’, it is the other parameters that make things a little bit more interesting and gives you opportunities to include these in your applications. In particular, the ‘narrate‘ and ‘explainsql‘ parameters and to a lesser extent the ‘chat‘ parameter. Although for the ‘chat’ parameter there are perhaps slightly easier and more efficient ways of doing this.
Let’s start by looking at the ‘chat‘ parameter. This allows you to ‘chat’ LLM just like you would with ChatGPT and other similar. A useful parameter to set in the CREATE_PROFILE is to set the conversation to TRUE, as that can give more useful results as the conversation develops.
BEGIN
DBMS_CLOUD_AI.drop_profile(profile_name => 'OPEN_AI');
DBMS_CLOUD_AI.create_profile(
profile_name => 'OPEN_AI',
attributes => '{"provider": "openai",
"credential_name": "OPENAI_CRED",
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "channels"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "times"}],
"conversation": "true", "model":"gpt-3.5-turbo" }');
END;There are a few statements I’ve used.
select AI chat who is the president of ireland;
select AI chat what role does NAMA have in ireland;
select AI chat what are the annual revenues of Oracle;
select AI chat who is the largest cloud computing provider;
select AI chat can you rank the cloud providers by income over the last 5 years;
select AI chat what are the benefits of using Oracle Cloud;As you’d expect the results can be ‘kind of correct’, with varying levels of information given. I’ve tried these using Cohere and OpenAI, and their responses illustrate the need for careful testing and evaluation of the various LLMs to see which one suits your needs.
In my previous post, I gave some examples of using Select AI to query data in the Database based on a natural language request. Select AI takes that request and sends it, along with details of the objects listed in the create_profile, to the LLM. The LLM then sends back the SQL statement, which is then executed in the Database and the results are displayed. But what if you want to see the SQL generated by the LLM. To see the SQL you can use the ‘showsql‘ parameter. Here are a couple of examples:
SQL> select AI showsql how many customers in San Francisco are married;
RESPONSE
_____________________________________________________________________________SELECT COUNT(*) AS total_married_customers
FROM SH.CUSTOMERS c
WHERE c.CUST_CITY = 'San Francisco'
AND c.CUST_MARITAL_STATUS = 'Married'
SQL> select AI what customer is the largest by sales;
CUST_ID CUST_FIRST_NAME CUST_LAST_NAME TOTAL_SALES
__________ __________________ _________________ ______________
11407 Dora Rice 103412.66
SQL> select AI showsql what customer is the largest by sales;
RESPONSE
_____________________________________________________________________________SELECT C.CUST_ID, C.CUST_FIRST_NAME, C.CUST_LAST_NAME, SUM(S.AMOUNT_SOLD) AS TOTAL_SALES
FROM SH.CUSTOMERS C
JOIN SH.SALES S ON C.CUST_ID = S.CUST_ID
GROUP BY C.CUST_ID, C.CUST_FIRST_NAME, C.CUST_LAST_NAME
ORDER BY TOTAL_SALES DESC
FETCH FIRST 1 ROW ONLY The examples above that illustrate the ‘showsql‘ is kind of interesting. Careful consideration of how and where to use this is needed.
Where things get a little bit more interesting with the ‘narrate‘ parameter, which attempts to narrate or explain the output from the query. There are many use cases where this can be used to supplement existing dashboards, etc. The following are examples of using ‘narrate‘ for the same two queries used above.
SQL> select AI narrate how many customers in San Francisco are married;
RESPONSE
________________________________________________________________
The total number of married customers in San Francisco is 18.
SQL> select AI narrate what customer is the largest by sales;
RESPONSE
_____________________________________________________________________________To find the customer with the largest sales, you can use the following SQL query:
```sql
SELECT c.CUST_FIRST_NAME || ' ' || c.CUST_LAST_NAME AS CUSTOMER_NAME, SUM(s.AMOUNT_SOLD) AS TOTAL_SALES
FROM "SH"."CUSTOMERS" c
JOIN "SH"."SALES" s ON c.CUST_ID = s.CUST_ID
GROUP BY c.CUST_FIRST_NAME, c.CUST_LAST_NAME
ORDER BY TOTAL_SALES DESC
FETCH FIRST 1 ROW ONLY;
```
This query joins the "CUSTOMERS" and "SALES" tables on the customer ID and calculates the total sales for each customer. It then sorts the results in descending order of total sales and fetches only the first row, which represents the customer with the largest sales.
The result will be in the following format:
| CUSTOMER_NAME | TOTAL_SALES |
|---------------|-------------|
| Tess Drumm | 161882.79 |
In this example, the customer with the largest sales is "Tess Drumm" with a total sales amount of 161,882.79.
Looking at the outputs from using the ‘narrate‘ parameter, we can see the level of detail given and see the potential of including this kind of information in our applications, dashboards, etc. But to use this output some additional filtering and subsetting will need to be performed.
The final parameter is called ‘explainsql‘. While it may not be as useful as the ‘narrate‘ parameter, it does have some potential uses. The ‘explainsql‘ attempts to explain in natural language what a SQL query is attempting to do, based on a natural language statement. Again using the same two examples, we get the following.
SQL> select AI explainsql what customer is the largest by sales;
RESPONSE
_____________________________________________________________________________SELECT C.CUST_ID, C.CUST_FIRST_NAME, C.CUST_LAST_NAME, SUM(S.AMOUNT_SOLD) AS TOTAL_SALES
FROM SH.CUSTOMERS C
JOIN SH.SALES S ON C.CUST_ID = S.CUST_ID
GROUP BY C.CUST_ID, C.CUST_FIRST_NAME, C.CUST_LAST_NAME
ORDER BY TOTAL_SALES DESC
FETCH FIRST 1 ROW ONLY;
Explanation:
- The query selects the customer ID, first name, last name, and the sum of the amount sold from the CUSTOMERS and SALES tables.
- The CUSTOMERS and SALES tables are joined on the CUST_ID column.
- The results are grouped by customer ID, first name, and last name.
- The results are then ordered in descending order by the total sales.
- The FETCH FIRST 1 ROW ONLY clause is used to retrieve only the top row with the highest total sales.
SQL> select AI explainsql how many customers in San Francisco are married;
RESPONSE
_____________________________________________________________________________
SELECT COUNT(*) AS total_married_customers
FROM SH.CUSTOMERS c
WHERE c.CUST_CITY = 'San Francisco'
AND c.CUST_MARITAL_STATUS = 'Married';
This query selects the count of customers who are married and live in San Francisco. The table alias "c" is used for the CUSTOMERS table. The condition "c.CUST_CITY = 'San Francisco'" filters the customers who live in San Francisco, and the condition "c.CUST_MARITAL_STATUS = 'Married'" filters the customers who are married. The result is the total number of married customers in San Francisco. Check out the other posts about Select AI.
EU AI Act has been passed by EU parliament
It feels like we’ve been hearing about and talking about the EU AI Act for a very long time now. But on Wednesday 13th March 2024, the EU Parliament finally voted to approve the Act. While this is a major milestone, we haven’t crossed the finish line. There are a few steps to complete, although these are minor steps and are part of the process.
The remaining timeline is:
- The EU AI Act will undergo final linguistic approval by lawyer-linguists in April. This is considered a formality step.
- It will then be published in the Official EU Journal
- 21 days after being published it will come into effect (probably in May)
- The Prohibited Systems provisions will come into force six months later (probably by end of 2024)
- All other provisions in the Act will come into force over the next 2-3 years
If you haven’t already started looking at and evaluating the various elements of AI deployed in your organisation, now is the time to start. It’s time to prepare and explore what changes, if any, you need to make. If you don’t the penalties for non-compliance are hefty, with fines of up to €35 million or 7% of global turnover.
The first thing you need to address is the Prohibited AI Systems and the EU AI Act outlines the following and will need to be addressed before the end of 2024:
- Manipulative and Deceptive Practices: systems that use subliminal techniques to materially distort a person’s decision-making capacity, leading to significant harm. This includes systems that manipulate behaviour or decisions in a way that the individual would not have otherwise made.
- Exploitation of Vulnerabilities: systems that target individuals or groups based on age, disability, or socio-economic status to distort behaviour in harmful ways.
- Biometric Categorisation: systems that categorise individuals based on biometric data to infer sensitive information like race, political opinions, or sexual orientation. This prohibition does not cover any labelling or filtering of lawfully acquired biometric datasets, such as images. There are also exceptions for law enforcement.
- Social Scoring: systems designed to evaluate individuals or groups over time based on their social behaviour or predicted personal characteristics, leading to detrimental treatment.
- Real-time Biometric Identification: The use of real-time remote biometric identification systems in publicly accessible spaces for law enforcement is heavily restricted, with allowances only under narrowly defined circumstances that require judicial or independent administrative approval.
- Risk Assessment in Criminal Offences: systems that assess the risk of individuals committing criminal offences based solely on profiling, except when supporting human assessment already based on factual evidence.
- Facial Recognition Databases: systems that create or expand facial recognition databases through untargeted scraping of images are prohibited.
- Emotion Inference in Workplaces and Educational Institutions: The use of AI to infer emotions in sensitive environments like workplaces and schools is banned, barring exceptions for medical or safety reasons.
In addition to the timeline given above we also have:
- 12 months after entry into force: Obligations on providers of general purpose AI models go into effect. Appointment of member state competent authorities. Annual Commission review of and possible amendments to the list of prohibited AI.
- after 18 months: Commission implementing act on post-market monitoring
- after 24 months: Obligations on high-risk AI systems specifically listed in Annex III, which includes AI systems in biometrics, critical infrastructure, education, employment, access to essential public services, law enforcement, immigration and administration of justice. Member states to have implemented rules on penalties, including administrative fines. Member state authorities to have established at least one operational AI regulatory sandbox. Commission review and possible amendment of the last of high-risk AI systems.
- after 36 months: Obligations for high-rish AI systems that are not prescribed in Annex III but are intended to be used as a safety component of a product, or the AI is itself a product, and the product is required to undergo a third-party conformity assessment under existing specific laws, for example, toys, radio equipment, in vitro diagnostic medical devices, civil aviation security and agricultural vehicles.
The EU has provided an official compliance check that helps identify which parts of the EU AI Act apply in a given use case.
OCI:Vision – AI for image processing – the Basics
Every cloud service provides some form of AI offering. Some of these can range from very basic features right up to a mediocre level. Only a few are delivering advanced AI services in a useful way.
Oracle AI Services have been around for about a year now, and with all new products or cloud services, a little time is needed to let it develop from an MVP (minimum viable produce) to something that’s more mature, feature-rich, stable and reliable. Oracle’s OCI AI Services come with some pre-training models and to create your own custom models based on your own training datasets.
Oracle’s OCI AI Services include:
- Digital Assistant
- Language
- Speech
- Vision
- Document Understand
- Anomaly Detection
- Forecasting
In this post, we’ll explore OCI Vision, and what the capabilities are available with their pre-trained models. To demonstrate this their online/webpage application will be used to demonstrate what it does and what it creates and identifies. You can access the Vision AI Services from the menu as shown in the following image.
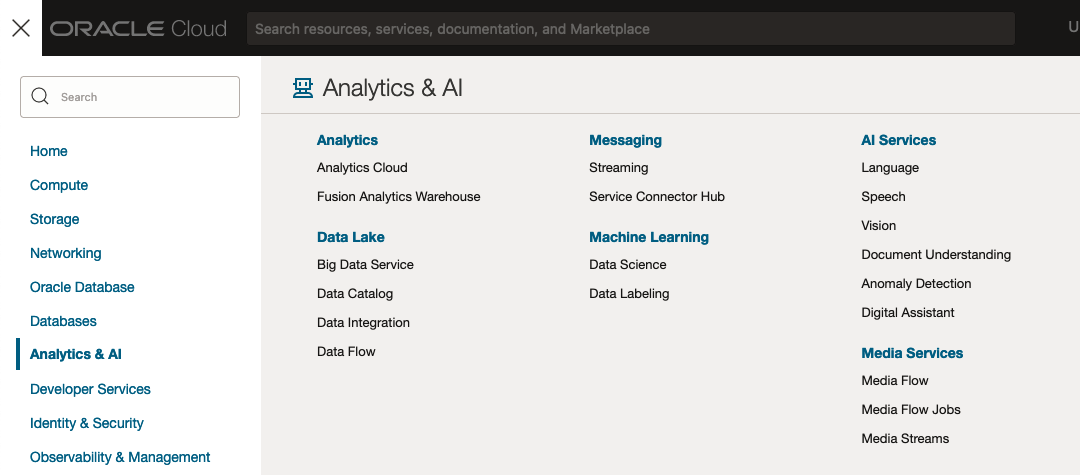
From the main AI Vision webpage, we can see on the menu (on left-hand side of the page), we have three main Vision related options. These are Image Classification, Object Detection and Document AI. These are pre-trained models that perform slightly different tasks.
Let’s start with Image Classification and explore what is possible. Just Click on the link.
Note: The Document AI feature will be moving to its own cloud Service in 2024, so it will disappear from them many but will appear as a new service on the main Analytics & AI webpage (shown above).
The webpage for each Vision feature comes with a couple of images for you to examine to see how it works. But a better way to explore the capabilities of each feature is to use your own images or images you have downloaded. Here are examples.
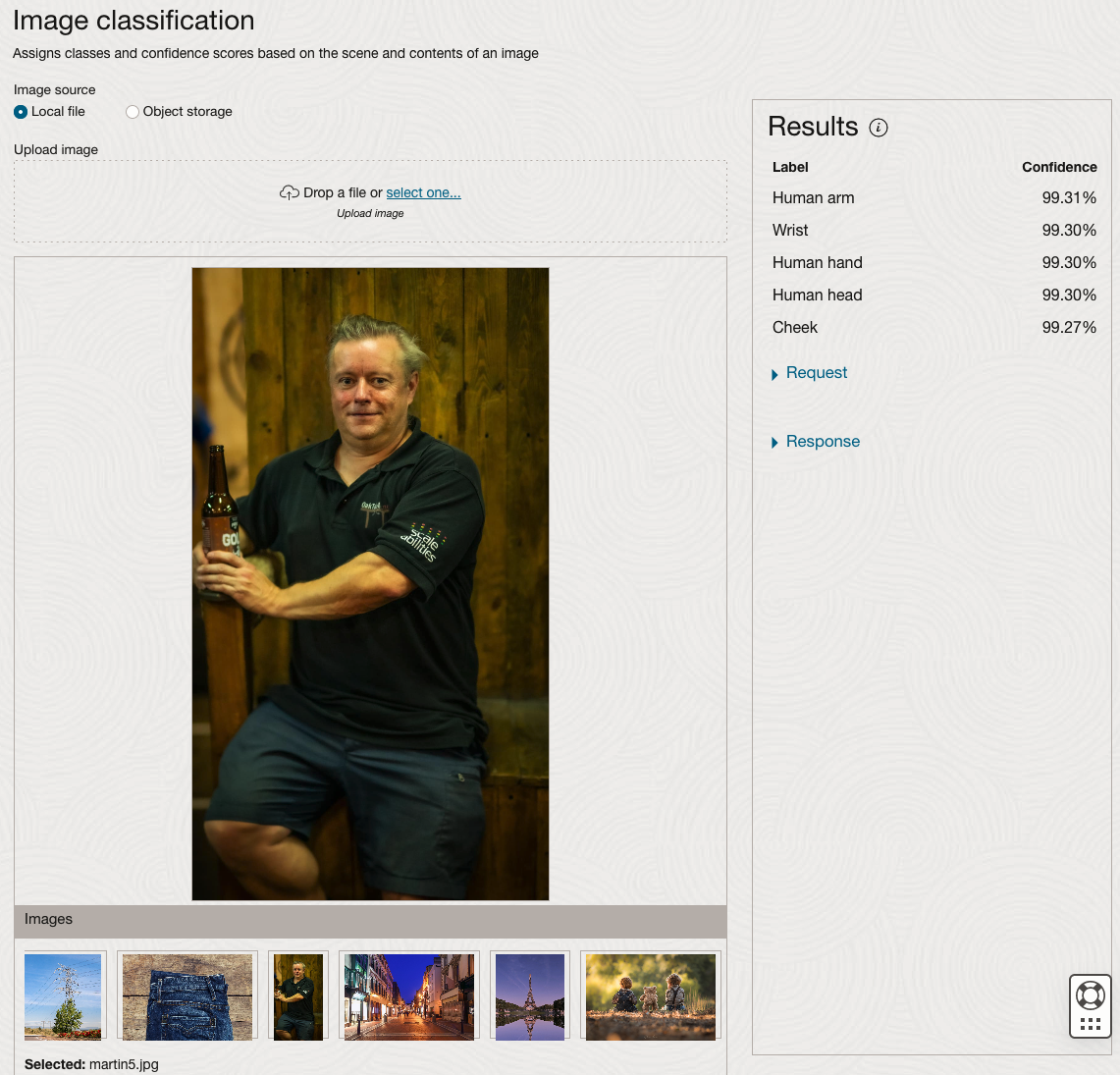
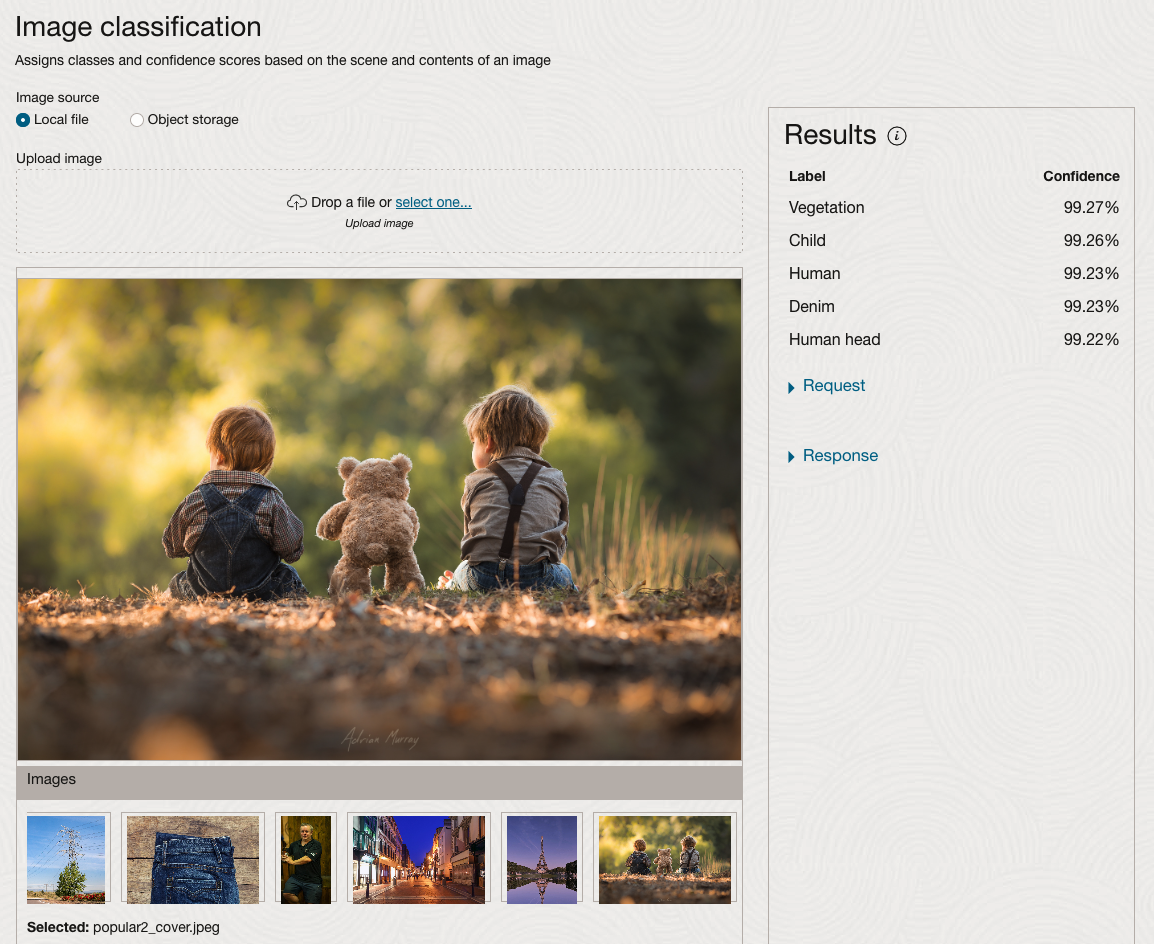
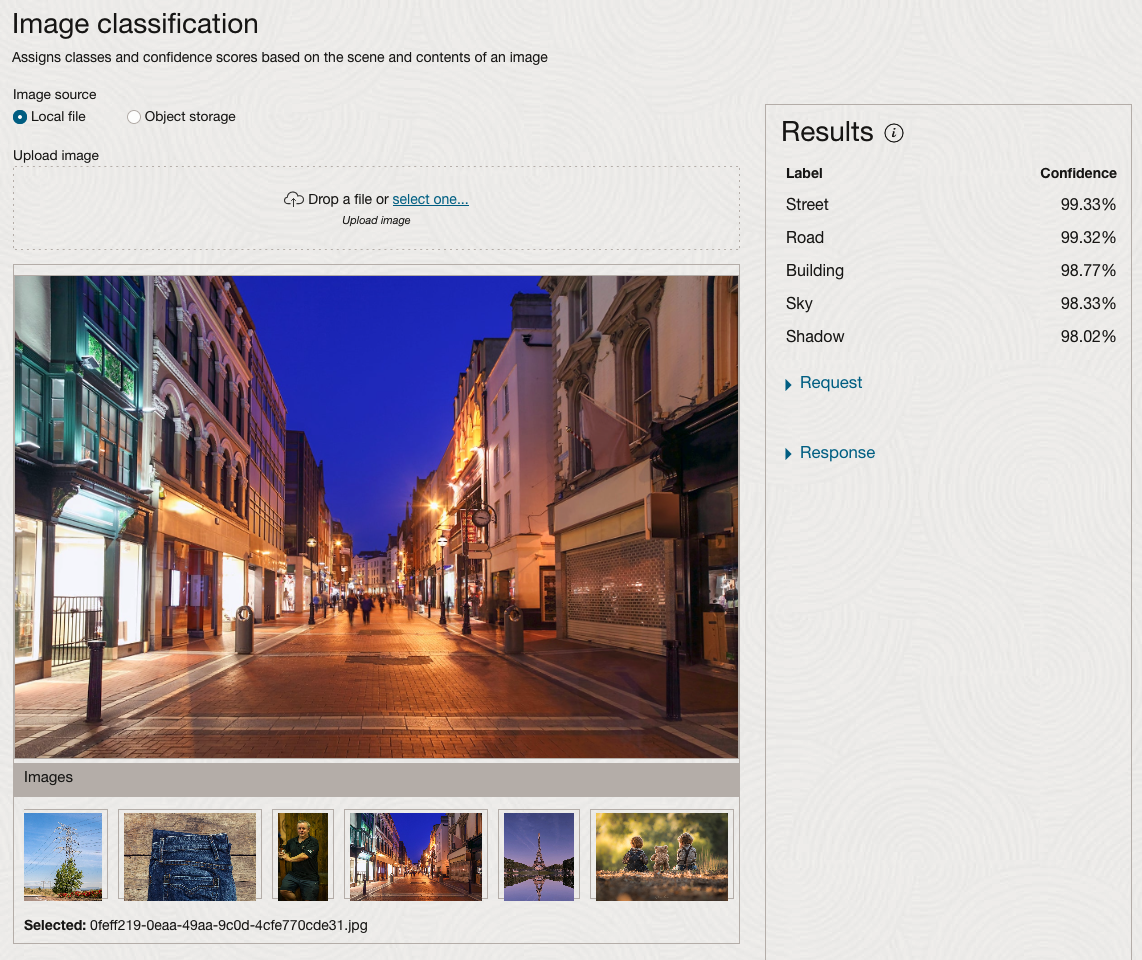
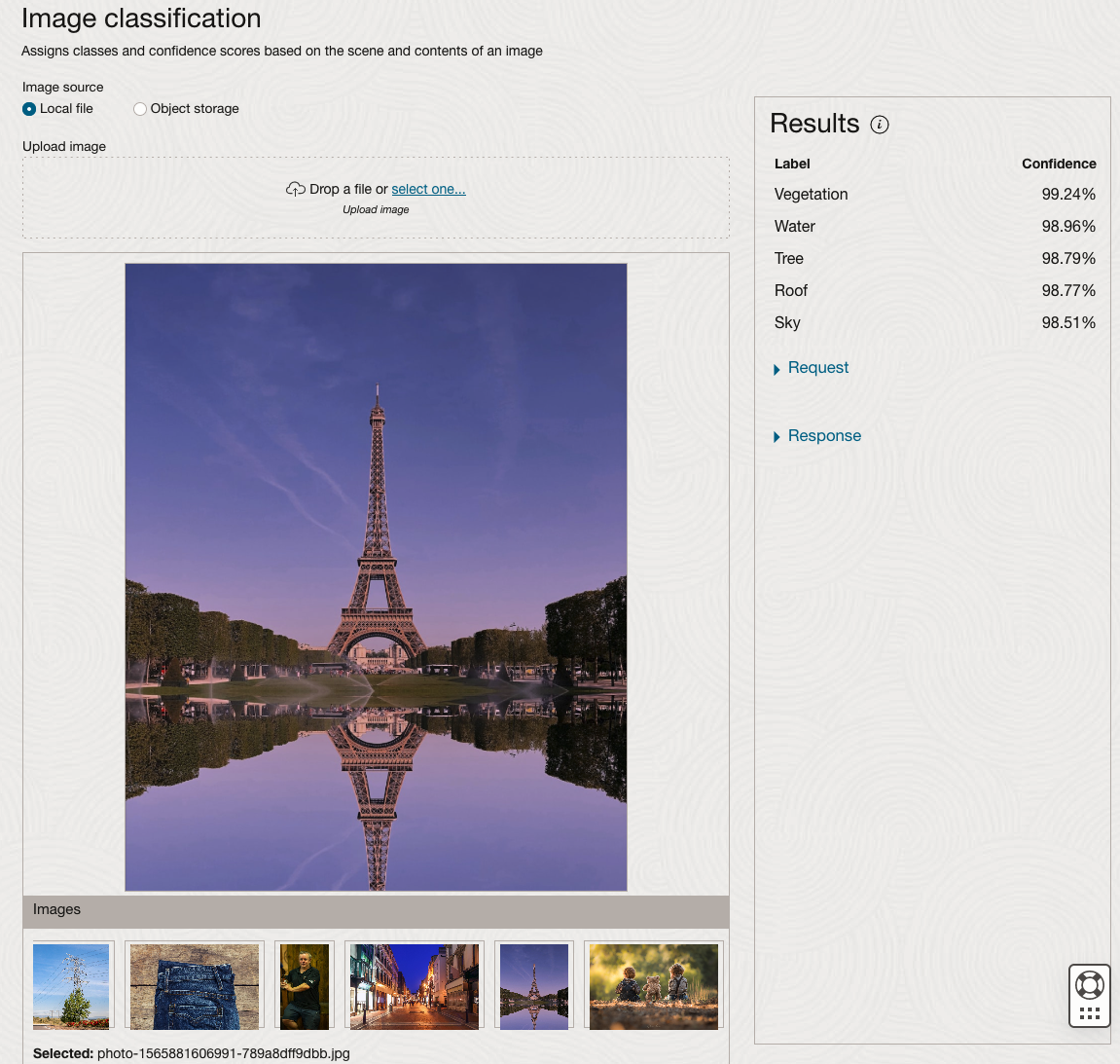
We can see the pre-trained model assigns classes and confidence for each image based on the main components it has identified in the image. For example with the Eiffel Tower image, the model has identified Water, Trees, Sky, Vegetation and Roof (of build). But it didn’t do so well with identifying the main object in the image as being a tower, or building of some form. Where with the streetscape image it was able to identify Street, Road, Building, Sky and Shadow.
Just under the Result section, we see two labels that can be expanded. One of these is the Response which contains JSON structure containing the labels, and confidences it has identified. This is what the pre-trained model returns and if you were to use Python to call this pre-trained model, it is this JSON object that you will get returned. You can then use the information contained in the JSON object to perform additional tasks for the image.
As you can see the webpage for OCI Vision and other AI services gives you a very simple introduction to what is possible, but it over simplifies the task and a lot of work is needed outside of this page to make the use of these pre-trained models useful.
Moving onto the Object Detection feature (left-hand menu) and using the pre-trained model on the same images, we get slightly different results.
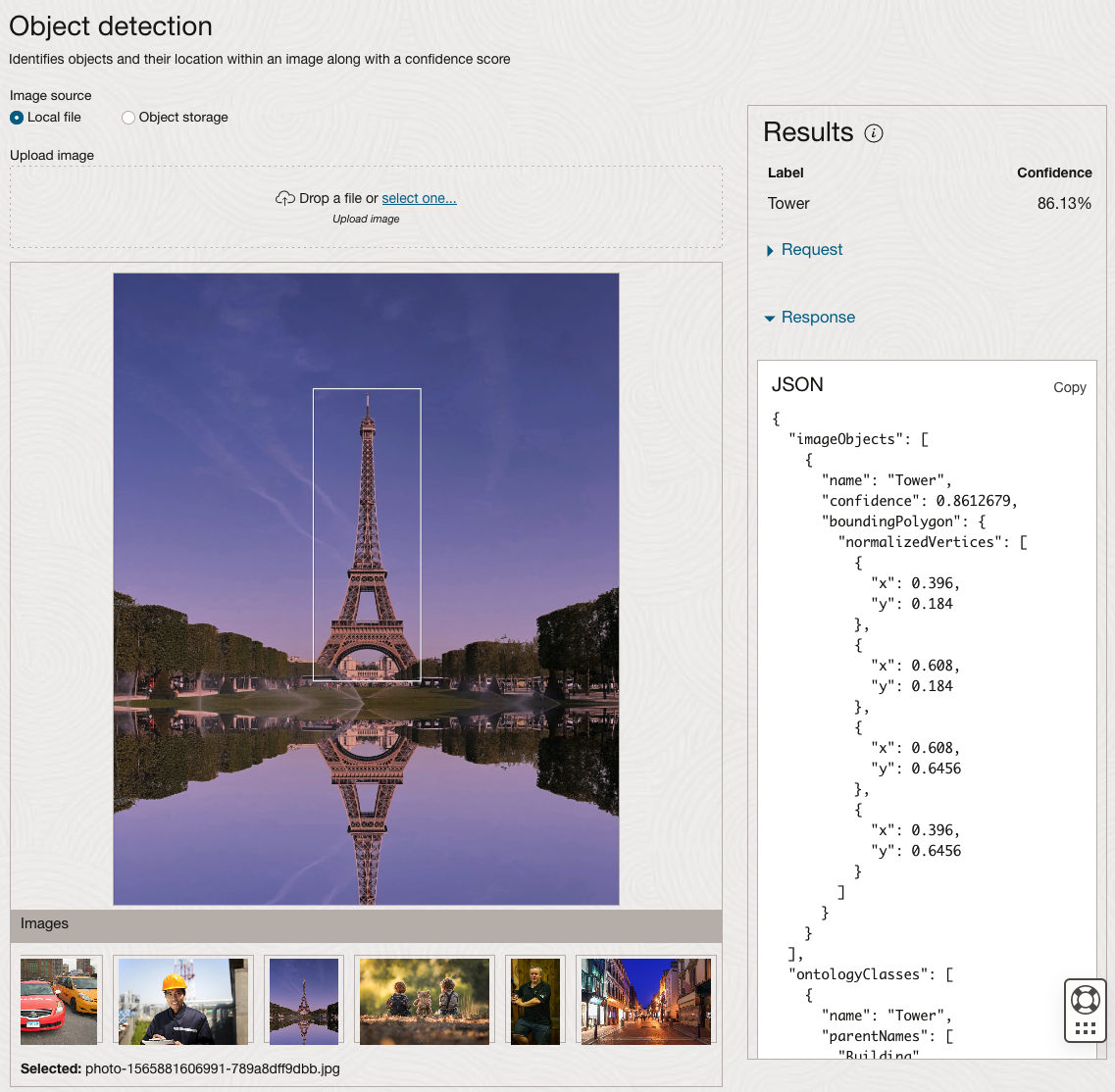
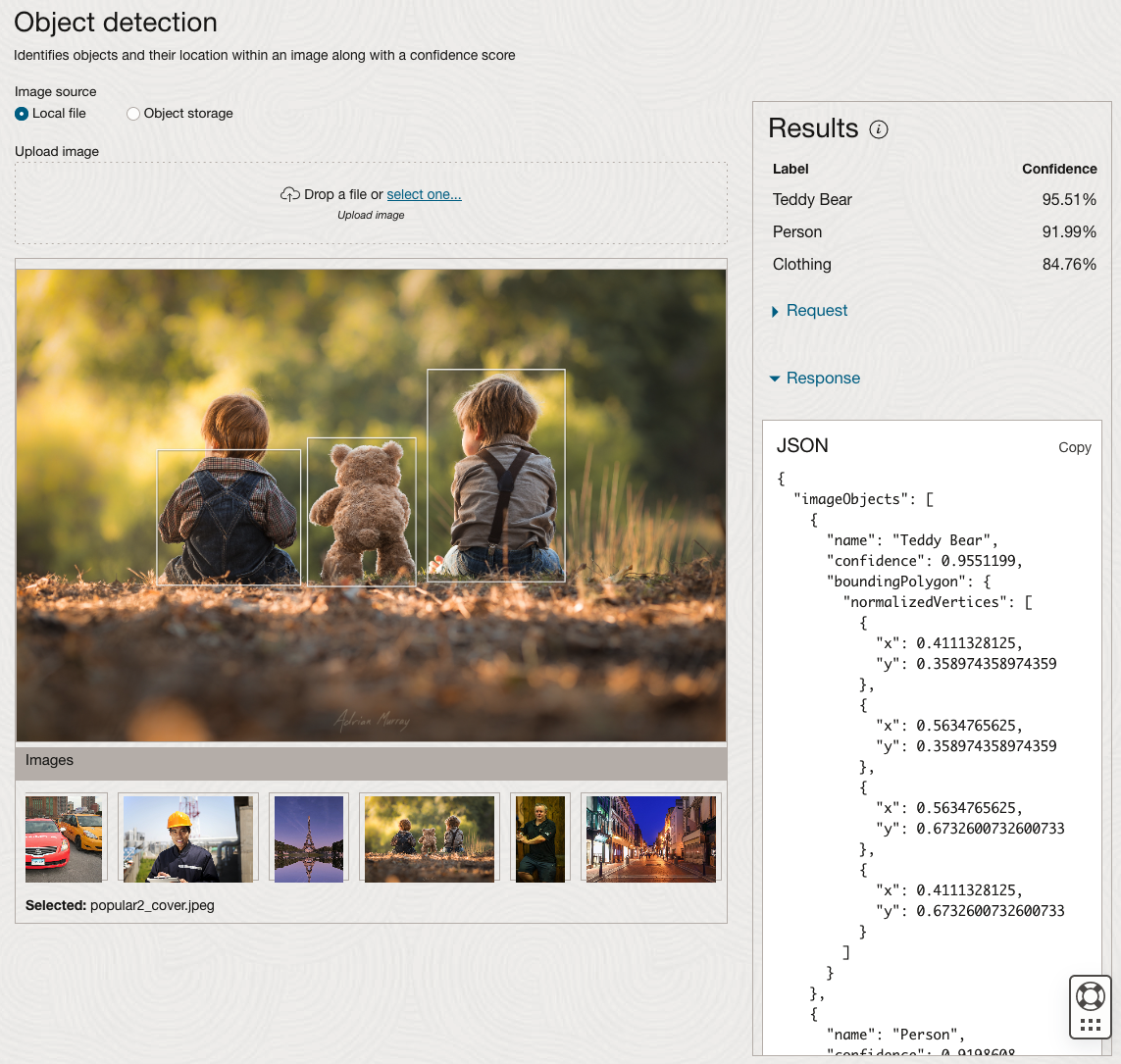
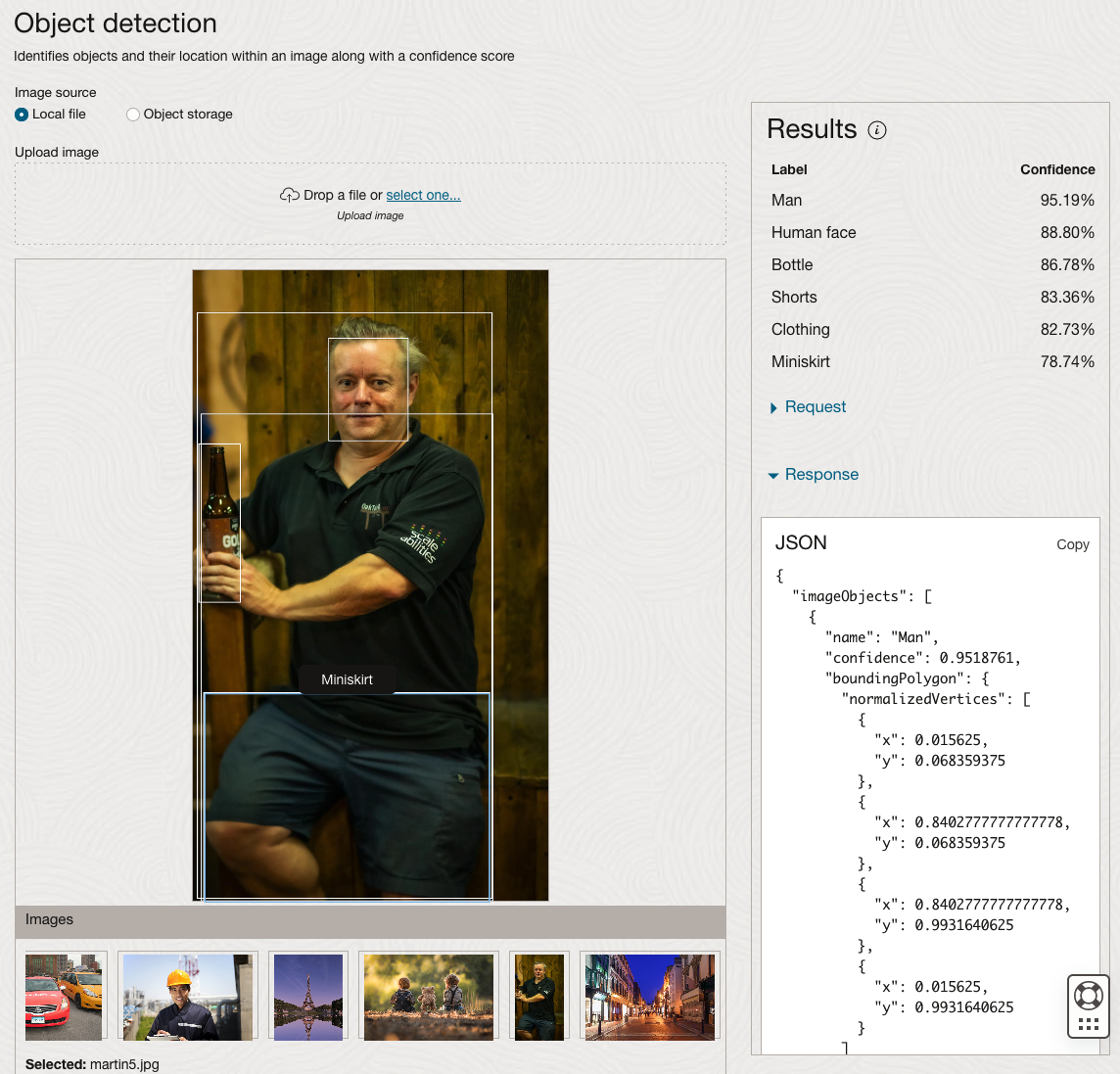
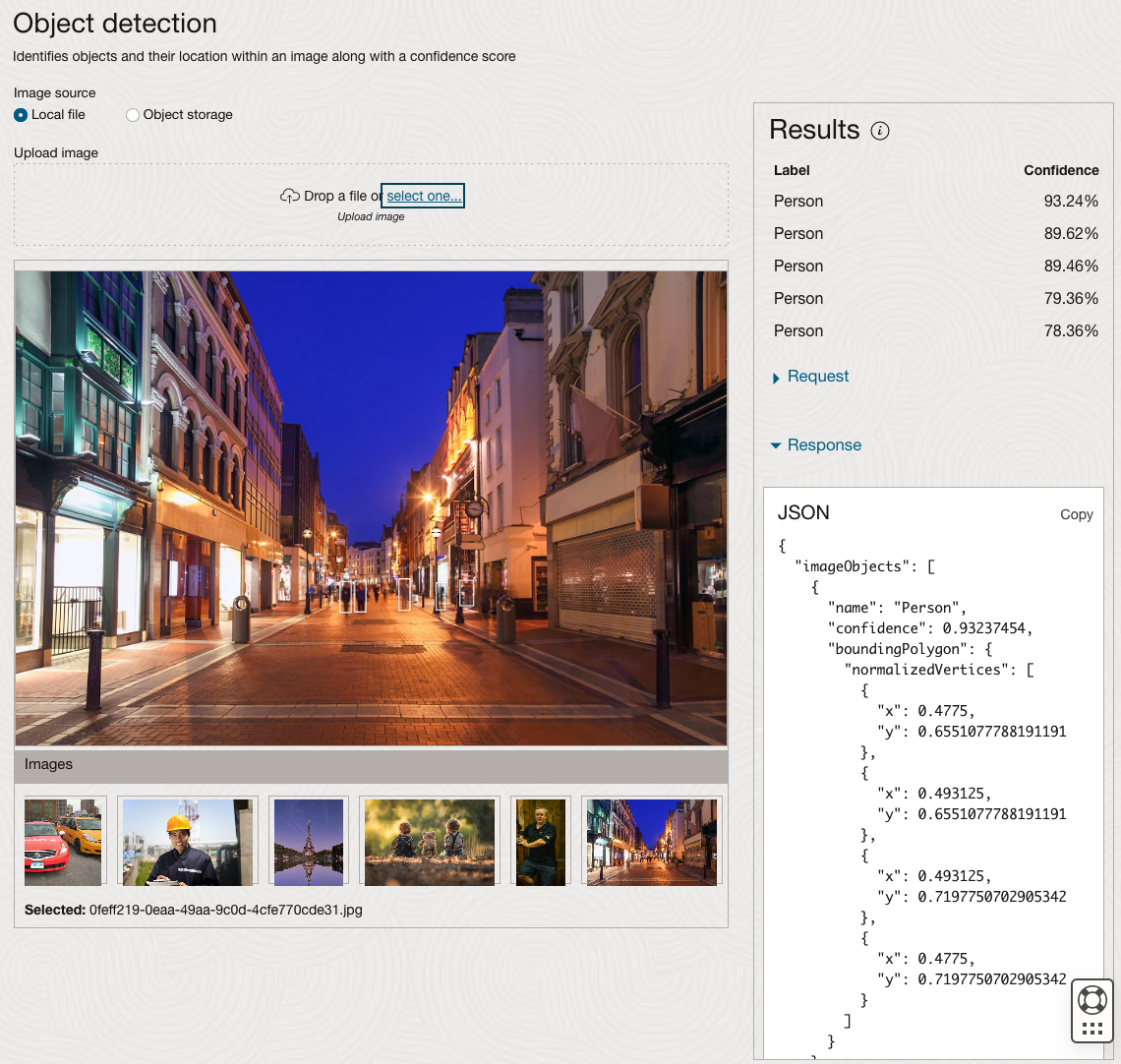
The object detection pre-trained model works differently as it can identify different things in the image. For example, with the Eiffel Tower image, it identifies a Tower in the image. In a similar way to the previous example, the model returns a JSON object with the label and also provides the coordinates for a bounding box for the objects detected. In the street scape image, it has identified five people. You’ll probably identify many more but the model identified five. Have a look at the other images and see what it has identified for each.
As I mentioned above, using these pre-trained models are kind of interesting, but are of limited use and do not really demonstrate the full capabilities of what is possible. Look out of additional post which will demonstrate this and steps needed to create and use your own custom model.
EU AI Act adopts OECD Definition of AI
Over the recent months, the EU AI Act has been making progress through the various hoop in the EU. Various committees and working groups have examined different parts of the AI Act and how it will impact the wider population. Their recommendations have been added to the EU Act and it has now progressed to the next stage for ratification in the EU Parliament which should happen in a few months time.
There are lots of terms within the EU AI Act which needed defining, with the most crucial one being the definition of AI, and this definition underpins the entire act, and all the other definitions of terms throughout the EU AI Act. Back in March of this year, the various political groups working on the EU AI Act reached an agreement on the definition of AI (Artificial Intelligence). The EI AI Act adopts, or is based on, the OECD definition of AI.
“Artificial intelligence system’ (AI system) means a machine-based system that is designed to operate with varying levels of autonomy and that can, for explicit or implicit objectives, generate output such as predictions, recommendations, or decisions influencing physical or virtual environments”

The working groups wanted the AI definition to be closely aligned with the work of international organisations working on artificial intelligence to ensure legal certainty, harmonisation and wide acceptance. The wording includes reference to predictions includes content, this is to ensure generative AI models like ChatGPT are included in the regulation.
Other definitions included are, significant risk, biometric authentication and identification.
“‘Significant risk’ means a risk that is significant in terms of its severity, intensity, probability of occurrence, duration of its effects, and its ability to affect an individual, a plurality of persons or to affect a particular group of persons,” the document specifies.
Remote biometric verification systems were defined as AI systems used to verify the identity of persons by comparing their biometric data against a reference database with their prior consent. That is distinguished by an authentication system, where the persons themselves ask to be authenticated.
On biometric categorisation, a practice recently added to the list of prohibited use cases, a reference was added to inferring personal characteristics and attributes like gender or health.
Machine Learning App Migration to Oracle Cloud VM
Over the past few years, I’ve been developing a Stock Market prediction algorithm and made some critical refinements to it earlier this year. As with all analytics, data science, machine learning and AI projects, testing is vital to ensure its performance, accuracy and sustainability. Taking such a project out of a lab environment and putting it into a production setting introduces all sorts of different challenges. Some of these challenges include being able to self-manage its own process, logging, traceability, error and event management, etc. Automation is key and implementing all of these extra requirements tasks way more code and time than developing the actual algorithm. Typically, the machine learning and algorithms code only accounts for less than five percent of the actual code, and in some cases, it can be less than one percent!
I’ve come to the stage of deploying my App to a production-type environment, as I’ve been running it from my laptop and then a desktop for over a year now. It’s now 100% self-managing so it’s time to deploy. The environment I’ve chosen is using one of the Virtual Machines (VM) available on the Oracle Free Tier. This means it won’t cost me a cent (dollar or more) to run my App 24×7.
My App has three different components which use a core underlying machine learning predictions engine. Each is focused on a different set of stock markets. These marks operate in the different timezone of US markets, European Markets and Asian Markets. Each will run on a slightly different schedule than the rest.
The steps outlined below take you through what I had to do to get my App up and running the VM (Oracle Free Tier). It took about 20 minutes to complete everything
The first thing you need to do is create a ssh key file. There are a number of ways of doing this and the following is an example.
ssh-keygen -t rsa -N "" -b 2048 -C "myOracleCloudkey" -f myOracleCloudkey
This key file will be used during the creation of the VM and for logging into the VM.
Log into your Oracle Cloud account and you’ll find the Create Instances Compute i.e. create a virtual machine/

Complete the Create Instance form and upload the ssh file you created earlier. Then click the Create button. This assumes you have networking already created.

It will take a minute or two for the VM to be created and you can monitor the progress.
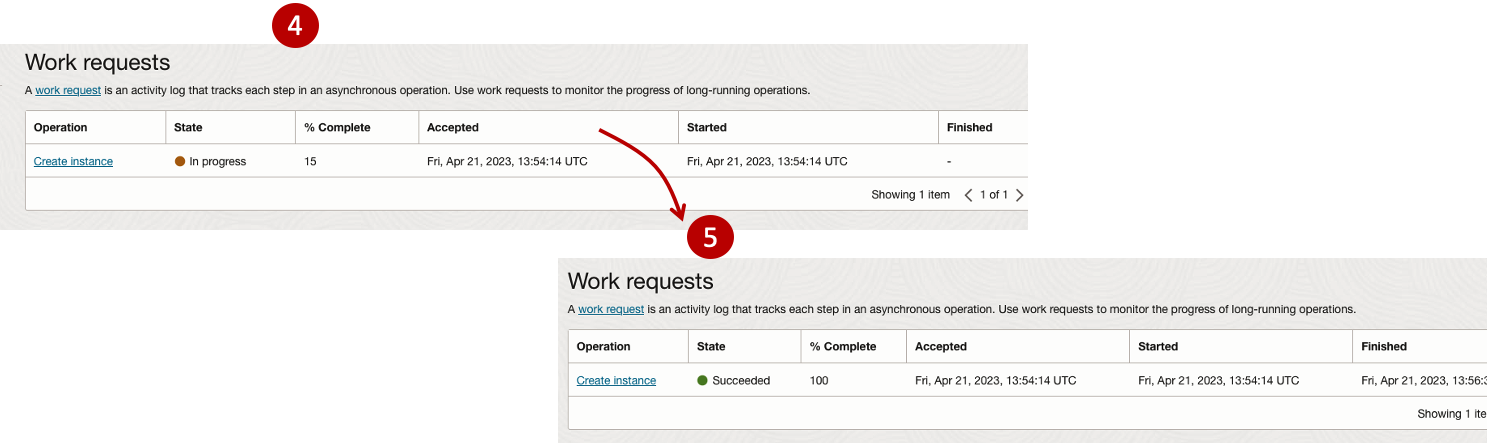
After it has been created you need to click on the start button to start the VM.
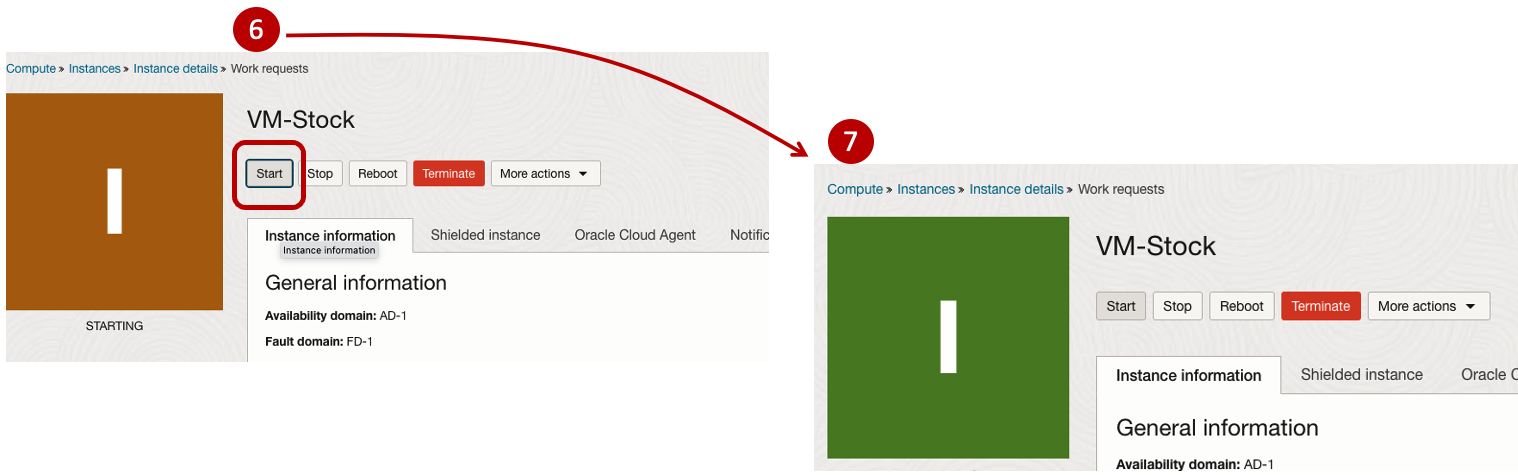
After it has started you can now log into the VM from a terminal window, using the public IP address
ssh -i myOracleCloudKey opc@xxx.xxx.xxx.xxxAfter you’ve logged into the VM it’s a good idea to run an update.
[opc@vm-stocks ~]$ sudo yum -y update
Last metadata expiration check: 0:13:53 ago on Fri 21 Apr 2023 14:39:59 GMT.
Dependencies resolved.
========================================================================================================================
Package Arch Version Repository Size
========================================================================================================================
Installing:
kernel-uek aarch64 5.15.0-100.96.32.el8uek ol8_UEKR7 1.4 M
kernel-uek-core aarch64 5.15.0-100.96.32.el8uek ol8_UEKR7 47 M
kernel-uek-devel aarch64 5.15.0-100.96.32.el8uek ol8_UEKR7 19 M
kernel-uek-modules aarch64 5.15.0-100.96.32.el8uek ol8_UEKR7 59 M
Upgrading:
NetworkManager aarch64 1:1.40.0-6.0.1.el8_7 ol8_baseos_latest 2.1 M
NetworkManager-config-server noarch 1:1.40.0-6.0.1.el8_7 ol8_baseos_latest 141 k
NetworkManager-libnm aarch64 1:1.40.0-6.0.1.el8_7 ol8_baseos_latest 1.9 M
NetworkManager-team aarch64 1:1.40.0-6.0.1.el8_7 ol8_baseos_latest 156 k
NetworkManager-tui aarch64 1:1.40.0-6.0.1.el8_7 ol8_baseos_latest 339 k
...
...
The VM is now ready to setup and install my App. The first step is to install Python, as all my code is written in Python.
[opc@vm-stocks ~]$ sudo yum install -y python39
Last metadata expiration check: 0:20:35 ago on Fri 21 Apr 2023 14:39:59 GMT.
Dependencies resolved.
========================================================================================================================
Package Architecture Version Repository Size
========================================================================================================================
Installing:
python39 aarch64 3.9.13-2.module+el8.7.0+20879+a85b87b0 ol8_appstream 33 k
Installing dependencies:
python39-libs aarch64 3.9.13-2.module+el8.7.0+20879+a85b87b0 ol8_appstream 8.1 M
python39-pip-wheel noarch 20.2.4-7.module+el8.6.0+20625+ee813db2 ol8_appstream 1.1 M
python39-setuptools-wheel noarch 50.3.2-4.module+el8.5.0+20364+c7fe1181 ol8_appstream 497 k
Installing weak dependencies:
python39-pip noarch 20.2.4-7.module+el8.6.0+20625+ee813db2 ol8_appstream 1.9 M
python39-setuptools noarch 50.3.2-4.module+el8.5.0+20364+c7fe1181 ol8_appstream 871 k
Enabling module streams:
python39 3.9
Transaction Summary
========================================================================================================================
Install 6 Packages
Total download size: 12 M
Installed size: 47 M
Downloading Packages:
(1/6): python39-pip-20.2.4-7.module+el8.6.0+20625+ee813db2.noarch.rpm 23 MB/s | 1.9 MB 00:00
(2/6): python39-pip-wheel-20.2.4-7.module+el8.6.0+20625+ee813db2.noarch.rpm 5.5 MB/s | 1.1 MB 00:00
...
...Next copy the code to the VM, setup the environment variables and create any necessary directories required for logging. The final part of this is to download the connection Wallett for the Database. I’m using the Python library oracledb, as this requires no additional setup.
Then install all the necessary Python libraries used in the code, for example, pandas, matplotlib, tabulate, seaborn, telegram, etc (this is just a subset of what I needed). For example here is the command to install pandas.
pip3.9 install pandasAfter all of that, it’s time to test the setup to make sure everything runs correctly.
The final step is to schedule the App/Code to run. Before setting the schedule just do a quick test to see what timezone the VM is running with. Run the date command and you can see what it is. In my case, the VM is running GMT which based on the current time locally, the VM was showing to be one hour off. Allowing for this adjustment and for day-light saving time, the time +/- markets openings can be set. The following example illustrates setting up crontab to run the App, Monday-Friday, between 13:00-22:00 and at 5-minute intervals. Open crontab and edit the schedule and command. The following is an example
> contab -e
*/5 13-22 * * 1-5 python3.9 /home/opc/Stocks.py >Stocks.txtFor some stock market trading apps, you might want it to run more frequently (than every 5 minutes) or less frequently depending on your strategy.
After scheduling the components for each of the Geographic Stock Market areas, the instant messaging of trades started to appear within a couple of minutes. After a little monitoring and validation checking, it was clear everything was running as expected. It was time to sit back and relax and see how this adventure unfolds.
For anyone interested, the App does automated trading with different brokers across the markets, while logging all events and trades to an Oracle Autonomous Database (Free Tier = no cost), and sends instant messages to me notifying me of the automated trades. All I have to do is Nothing, yes Nothing, only to monitor the trade notifications. I mentioned earlier the importance of testing, and with back-testing of the recent changes/improvements (as of the date of post), the App has given a minimum of 84% annual return each year for the past 15 years. Most years the return has been a lot more!
AI Liability Act
Over the past few weeks we have seem a number of new Artificial Intelligence (AI) Acts or Laws, either being proposed or are at an advanced stage of enactment. One of these is the EU AI Liability Act (also), and is supposed be be enacted and work hand-in-hand with the EU AI Act.
There are different view or focus perspectives between these two EU AI acts. For the EU AI Act, the focus is from the technical perspective and those who develop AI solutions. On the other side of things is the EU AI Liability Act whose perspective is from the end-user/consumer point.
The aim of the EU AI Liability Act is to create a framework for trust in AI technology, and when a person has been harmed by the use of the AI, provides a structure to claim compensation. Just like other EU laws to protect the consumers from defective or harmful products, the AI Liability Act looks to do similar for when a person is harmed in some way by the use or application of AI.
Most of the examples given for how AI might harm a person includes the use of robotics, drones, and when AI is used in the recruitment process, where is automatically selects a candidate based on the AI algorithms. Some other examples include data loss from tech products or caused by tech products, smart-home systems, cyber security, products where people are selected or excluded based on algorithms.
Harm can be difficult to define, and although some attempt has been done to define this in the Act, additional work is needed to by the good people refining the Act, to provide clarifications on this and how its definition can evolve post enactment to ensure additional scenarios can be included without the need for updates to the Act, which can be a lengthy process. A similar task is being performed on the list of high-risk AI in the EU AI Act, where they are proposing to maintain a webpages listing such.
Vice-president for values and transparency, Věra Jourová, said that for AI tech to thrive in the EU, it is important for people to trust digital innovation. She added that the new proposals would give customers “tools for remedies in case of damage caused by AI so that they have the same level of protection as with traditional technologies”

Didier Reynders, the EU’s justice commissioner says, “The new rules apply when a product that functions thanks to AI technology causes damage and that this damage is the result of an error made by manufacturers, developers or users of this technology.
The EU defines “an error” in this case to include not just mistakes in how the A.I. is crafted, trained, deployed, or functions, but also if the “error” is the company failing to comply with a lot of the process and governance requirements stipulated in the bloc’s new A.I. Act. The new liability rules say that if an organization has not complied with their “duty of care” under the new A.I. Act—such as failing to conduct appropriate risk assessments, testing, and monitoring—and a liability claim later arises, there will be a presumption that the A.I. was at fault. This creates an additional way of forcing compliance with the EU AI Act.
The EU Liability Act says that a court can now order a company using a high-risk A.I. system to turn over evidence of how the software works. A balancing test will be applied to ensure that trade secrets and other confidential information is not needlessly disclosed. The EU warns that if a company or organization fails to comply with a court-ordered disclosure, the courts will be free to presume the entity using the A.I. software is liable.
The EU Liability Act will go through some changes and refinement with the aim for it to be enacted at the same time as the EU AI Act. How long will this process that is a little up in the air, considering the EU AI Act should have been adopted by now and we could be in the 2 year process for enactment. But the EU AI Act is still working its way through the different groups in the EU. There has been some indications these might conclude in 2023, but lets wait and see. If the EU Liability Act is only starting the process now, there could be some additional details if the EU wants both Acts to be effective at the same time.
Oracle OCI AI Services
Oracle Cloud have been introducing new AI Services over the past few months, and we see a few more appearing over the coming few months. When you look at the list you might be a little surprised that these are newly available cloud services from Oracle. You might be surprised for two main reasons. Firstly, AWS and Google have similar cloud services available for some time (many years) now, and secondly, Oracle started talking about having these cloud services many years ago. It has taken some time for these to become publicly available. Although some of these have been included in other applications and offerings from Oracle, so probably they were busy with those before making them available as stand alone services.

These can be located in your Oracle Cloud account from the hamburger menu, as shown below

As you can see most of these AI Services are listed, except for the OCI Forecasting, which is due to be added “soon”. We can also expect to have an OCI Translation services and possibly some additional ones.
- OCI Language: This services can work with over 75 languages and allows you to detect and perform knowledge extraction from the text to include entity identification and labelling, classification of text into more than 600 categories, sentiment analysis and key phrase extraction. This can be used automate knolwedge extraction from customer feedback, product reviews, discussion forums, legal documents, etc
- OCI Speech: Performs Speech to Text, from live streaming of speech, audio and video recordings, etc creating a transcription. It works across English, Spanish and Portuguese, with other languages to be added. A nice little feature includes Profanity filtering, allowing you to tag, remove or mask certain words
- OCI Vision: This has two parts. The first is for processing documents, and is slightly different to OCI Language Service, in that this service looks at processing text documents in jpeg, pdf, png and tiff formats. Text information extraction is performed identifying keep terms, tables, meta-data extraction, table extraction etc. The second part of OCI Vision deals with image analysis and extracting key information from the image such as objects, people, text, image classification, scene detection, etc. You can use either the pretrained models or include your own models.
- OCI Anomaly Detection: Although anomaly detection is available via algorithms in the Database and OCI Data Science offerings, this new services allow for someone with little programming experience to utilise an ensemble of models, including the MSET algorithm, to provide greater accuracy with identifying unusual patterns in the data.
Note: I’ve excluded some services from the above list as these have been available for some time now or have limited AI features included in them. These include OCI Data Labelling, OCI Digital Assistant.
Some of these AI Services, based on the initial release, have limited functionality and resources, but this will change over time.
NATO AI Strategy
Over the past 18 months there has been wide spread push buy many countries and geographic regions, to examine how the creation and use of Artificial Intelligence (AI) can be regulated. I’ve written many blog posts about these. But it isn’t just government or political alliances that are doing this, other types of organisations are also doing so.
NATO, the political and (mainly) military alliance, has also joined the club. They have release a summary version of their AI Strategy. This might seem a little strange for this type of organisation to do something like this. But if you look a little closer NATA also says they work together in other areas such as Standardisation Agreements, Crisis Management, Disarmament, Energy Security, Clime/Environment Change, Gender and Human Security, Science and Technology.
In October/November 2021, NATO formally adopted their Artificial Intelligence (AI) Strategy (for defence). Their AI Strategy outlines how AI can be applied to defence and security in a protected and ethical way (interesting wording). Their aim is to position NATO as a leader of AI adoption, and it provides a common policy basis to support the adoption of AI System sin order to achieve the Alliances three core tasks of Collective Defence, Crisis Management and Cooperative Security. An important element of the AI Strategy is to ensure inter-operability and standardisation. This is a little bit more interesting and perhaps has a lessor focus on ethical use.
NATO’s AI Strategy contains the following principles of Responsible use of AI (in defence):
- Lawfulness: AI applications will be developed and used in accordance with national and international law, including international humanitarian law and human rights law, as applicable.
- Responsibility and Accountability: AI applications will be developed and used with appropriate levels of judgment and care; clear human responsibility shall apply in order to ensure accountability.
- Explainability and Traceability: AI applications will be appropriately understandable and transparent, including through the use of review methodologies, sources, and procedures. This includes verification, assessment and validation mechanisms at either a NATO and/or national level.
- Reliability: AI applications will have explicit, well-defined use cases. The safety, security, and robustness of such capabilities will be subject to testing and assurance within those use cases across their entire life cycle, including through established NATO and/or national certification procedures.
- Governability: AI applications will be developed and used according to their intended functions and will allow for: appropriate human-machine interaction; the ability to detect and avoid unintended consequences; and the ability to take steps, such as disengagement or deactivation of systems, when such systems demonstrate unintended behaviour.
- Bias Mitigation: Proactive steps will be taken to minimise any unintended bias in the development and use of AI applications and in data sets.
By acting collectively members of NATO will ensure a continued focus on interoperability and the development of common standards.
Some points of interest:
- Bias Mitigation efforts will be adopted with the aim of minimising discrimination against traits such as gender, ethnicity or personal attributes. However, the strategy does not say how bias will be tackled – which requires structural changes which go well beyond the use of appropriate training data.
- The strategy also recognises that in due course AI technologies are likely to become widely available, and may be put to malicious uses by both state and non-state actors. NATO’s strategy states that the alliance will aim to identify and safeguard against the threats from malicious use of AI, although again no detail is given on how this will be done.
- Running through the strategy is the idea of interoperability – the desire for different systems to be able to work with each other across NATO’s different forces and nations without any restrictions.
- What about Autonomous weapon systems? Some members do not support a ban on this technology.
- Has similar wording to the principles adopted by the US Department of Defense for the ethical use of AI.
- Wants to make defence and security a more attractive to private sector and academic AI developers/researchers.
- NATO principles have no coherent means of implementation or enforcement.
AI Sandboxes – EU AI Regulations
The EU AI Regulations provides a framework for placing on the market and putting into service AI system in the EU. One of the biggest challenges most organisations will face will be how they can innovate and develop new AI systems while at the same time ensuring they are compliant with the regulations. But a what point do you know you are compliant with these new AI Systems? This can be challenging and could limit or slow down the development and deployment of such systems.
The EU does not want to limit or slow down such innovations and want organisations to continually research, develop and deploy new AI. To facilitate this the EU AI Regulations contains a structure under which this can be achieved.
Section or Title of EU AI Regulations contains Articles 53, 54, and 55 to support the development of new AI systems by the use of Sandboxes. We have already seen examples of these being introduced by the UK and Norwegian Data Protection Commissioners.
A Sandbox “provides a controlled environment that facilitates the development, testing and validation of innovative AI systems for a limited time before their placement on the market or putting into
service pursuant to a specific plan.“

Sandboxes are stand alone environments to allow the exploration and development of new AI solutions, which may or may not include some risky use of customer data or other potential AI outcomes which may not be allowed under the regulations. It becomes a controlled experiment lab for the AI team who are developing and testing a potential AI System and can do so under real world conditions. The Sandbox gives a “safe” environment for this experimental work.
The Sandbox are to be established by the Competent Authorities in each EU country. In Ireland the Competent Authority seems to be the Data Protection Commissioner, and this may be similar in other countries. As you can imagine, under the current wording of the EU AI Regulations this might present some challenges for the both the Competent Authority and also for the company looking to develop an AI solution. Firstly, does the Competent Authority need to provide sandboxes for all companies looking to develop AI, and each one of these companies may have several AI projects. This is a massive overhead for the Competent Authority to provide and resource. Secondly, will companies be willing to setup a self-contained environment, containing customer data, data insights, solutions with potential competitive advantage, etc in a Sandbox provided by the Competent Authority. The technical infrastructure used could be hosting many Sandboxes, with many competing companies using the same infrastructure at the same time. This is a big ask for the companies and the Competent Authority.
Let’s see what really happens regarding the implementation of the Sandboxes over the coming years, and how this will be defined in the final draft of the Regulations.
Article 54 defines additional requirements for the processing of personal data within the Sandbox.
- Personal Data being used is required, and can be fulfilled by processing anonymized, synthetic or other non-personal data. Even if it has been collected for other purposes.
- Continuous monitoring needed to identify any high risk to fundamental rights of the data subject, and response mechanism to mitigate those risks.
- Any personal data to be processed is in a functionally separate, isolated and protected data processing environment under the control of the participants and only authorised persons have access to that data.
- Any personal data processed are not be transmitted, transferred or otherwise accessed by other parties.
- Any processing of personal data does not lead to measures or decisions affecting the data subjects.
- All personal data is deleted once the participation in the sandbox is terminated or the personal data has reached the end of its retention period.
- Full documentation of what was done to the data, must be kept for 1 year after termination of Sandbox, and only to be used for accountability and documentation obligations.
- Documentation of the complete process and rationale behind the training, testing and validation of AI, along with test results as part of technical documentation. (see Annex IV)
- Short Summary of AI project, its objectives and expected results published on website of Competent Authorities
Based on the last bullet point the Competent Authority is required to write am annual report and submit this report to the EU AI Board. The report is to include details on the results of their scheme, good and bad practices, lessons learnt and recommendations on the setup and application of the Regulations within the Sandboxes.
OCED Framework for Classifying of AI Systems
Over the past few months we have seen more and more countries looking at how they can support and regulate the use and development of AI within their geographic areas. For those in Europe, a lot of focus has been on the draft AI Regulations. At the time of writing this post there has been a lot of politics going on in relation to the EU AI Regulations. Some of this has been around the definition of AI, what will be included and excluded in their different categories, who will be policing and enforcing the regulations, among lots of other things. We could end up with a very different set of regulations to what was included in the draft (published April 2021). It also looks like the enactment of the EU AI Regulations will be delayed to the end of 2022, with some people suggesting it would be towards mid-2023 before something formal happens.
I mentioned above one of the things that may or may not change is the definition of AI within the EU AI Regulations. Although primarily focused on the inclusion/exclusion of biometic aspects, there are other refinements being proposed. When you look at what other geographic regions are doing, we start to see some common aspects on their definitions of AI, but we also see some differences. You can imagine the difficulties this will present in the global marketplace and how AI touches upon all/many aspects of most businesses, their customers and their data.
Most of you will have heard of OCED. In recent weeks they have been work across all member countries to work towards a Definition of AI and how different AI systems can be classified. They have called this their OCED Framework for Classifying of AI Systems.
The OCED Framework for Classifying AI System is a tool for policy-makers, regulators, legislators and others so that they can assess the opportunities and risks that different types of AI systems present and to inform their national AI strategies.
The Framework links the technical characteristics of AI with the policy implications set out in the OCED AI Principles which include:
- Inclusive growth, sustainable development and well-being
- Human-centred values and fairness
- Transparency and explainability
- Robustness, security and safety
- Accountability
The framework looks are different aspects depending on if the AI is still within the lab (sandbox) environment or is live in production or in use in the field.
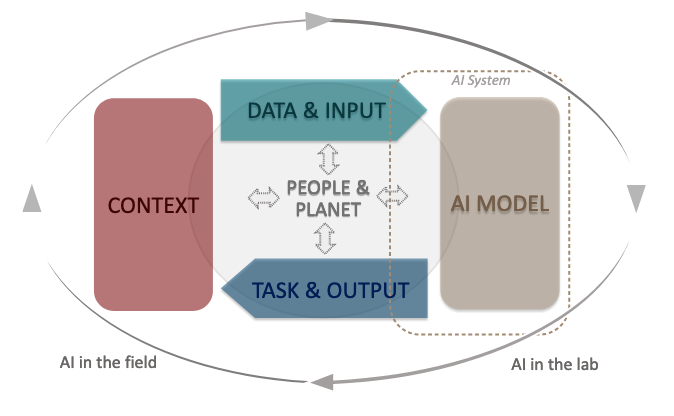
The framework goes into more detail on the various aspects that need to be considered for each of these. The working group have apply the frame work to a number of different AI systems to illustrate how it cab be used.

Check out the framework document where it goes into more detail of each of the criterion listed above for each dimension of the framework.
AI Categories in EU AI Regulations
The EU AI Regulations aims to provide a framework for addressing obligations for the use of AI applications in EU. These applications can be created, operated by or procured by companies both inside the EU and outside the EU, on data/people within the EU. In a previous post I get a fuller outline of the EU AI Regulations.
In this post I will look at proposed categorisation of AI applications, what type of applications fall into each category and what potential impact this may have on the operators of the AI application. The following diagram illustrates the categories detailed in the EU AI Regulations. These will be detailed below.
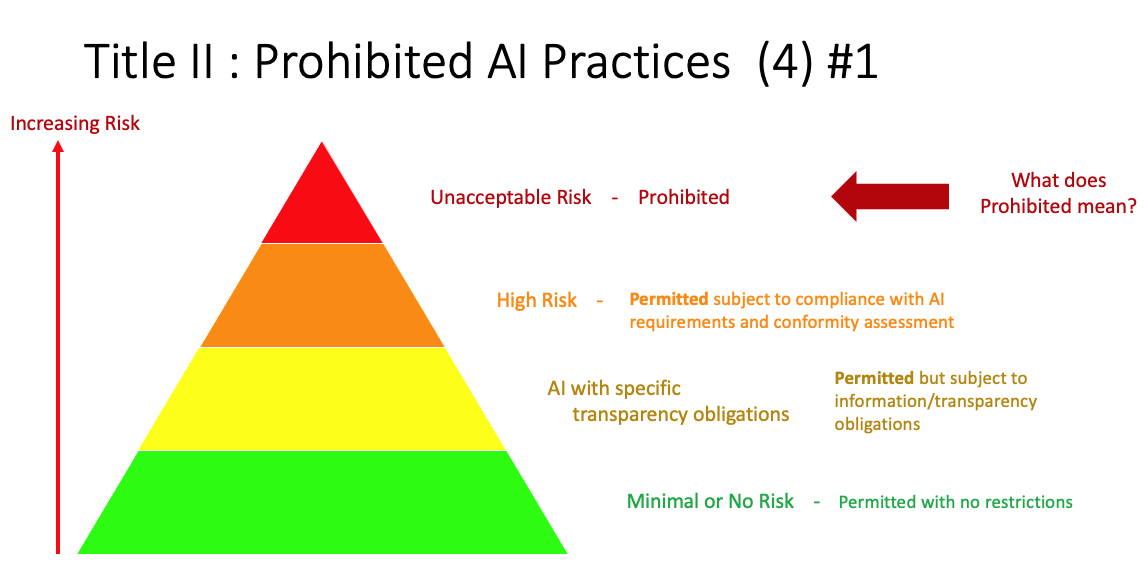
Let’s have a closer look at each of these categories
Unacceptable Risk (Red section)
The proposed legislation sets out a regulatory structure that bans some uses of AI, heavily regulates high-risk uses and lightly regulates less risky AI systems. The regulations intends to prohibit certain uses of AI which are deemed to be unacceptable because of the risks they pose. These would include deploying subliminal techniques or exploit vulnerabilities of specific groups of persons due to their age or disability, in order to materially distort a person’s behavior in a manner that causes physical or psychological harm; Lead to ‘social scoring’ by public authorities; Conduct ‘real time’ biometric identification in publicly available spaces. A more detailed version of this is:
- Designed or used in a manner that manipulates human behavior, opinions or decisions through choice architectures or other elements of user interfaces, causing a person to behave, form an opinion or take a decision to their detriment.
- Designed or used in a manner that exploits information or prediction about a person or group of persons in order to target their vulnerabilities or special circumstances, causing a person to behave, form an opinion or take a decision to their detriment.
- Indiscriminate surveillance applied in a generalised manner to all natural persons without differentiation. The methods of surveillance may include large scale use of AI systems for monitoring or tracking of natural persons through direct interception or gaining access to communication, location, meta data or other personal data collected in digital and/or physical environments or through automated aggregation and analysis of such data from various sources.
- General purpose social scoring of natural persons, including online. General purpose social scoring consists in the large scale evaluation or classification of the trustworthiness of natural persons [over certain period of time] based on their social behavior in multiple contexts and/or known or predicted personality characteristics, with the social score leading to detrimental treatment to natural person or groups.
There are some exemptions to these when such practices are authorised by law and are carried out [by public authorities or on behalf of public 25 authorities] in order to safeguard public security and are subject to appropriate safeguards for the rights and freedoms of third parties in compliance with Union law.
High Risk (Orange section)
AI systems identified as high-risk include AI technology used in:
- Critical infrastructures (e.g. transport), that could put the life and health of citizens at risk;
- Educational or vocational training, that may determine the access to education and professional course of someone’s life (e.g. scoring of exams);
- Safety components of products (e.g. AI application in robot-assisted surgery);
- Employment, workers management and access to self-employment (e.g. CV-sorting software for recruitment procedures);
- Essential private and public services (e.g. credit scoring denying citizens opportunity to obtain a loan);
- Law enforcement that may interfere with people’s fundamental rights (e.g. evaluation of the reliability of evidence);
- Migration, asylum and border control management (e.g. verification of authenticity of travel documents);
- Administration of justice and democratic processes (e.g. applying the law to a concrete set of facts).
All High risk AI applications will be subject to strict obligations before they can be put on the market:
- Adequate risk assessment and mitigation systems;
- High quality of the datasets feeding the system to minimise risks and discriminatory outcomes;
- Logging of activity to ensure traceability of results
- Detailed documentation providing all information necessary on the system and its purpose for authorities to assess its compliance;
- Clear and adequate information to the user;
- Appropriate human oversight measures to minimise risk;
- High level of robustness, security and accuracy.
These can also be categorised as (i) Risk management; (ii) Data governance; (iii) Technical documentation; (iv) Record keeping (traceability); (v) Transparency and provision of information to users; (vi) Human oversight; (vii) Accuracy; (viii) Cybersecurity robustness.
There will be some exceptions to this when the AI application is required by governmental and law enforcement agencies in certain circumstances.
Limited Risk (Yellow section)
“non-high-risk” AI systems should be encouraged to develop codes of conduct intended to foster the voluntary application of the mandatory requirements applicable to high-risk AI systems.
AI application within this Limited Risk category pose a limited risk, transparency requirements are imposed. For example, AI systems which are intended to interact with natural persons must be designed and developed in such a way that users are informed they are interacting with an AI system, unless it is “obvious from the circumstances and the context of use.”
Minimal Risk (Green section)
The Minimal Risk category a allows for all other AI systems can be developed and used in the EU without additional legal obligations than existing legislation For example, AI-enabled video games or spam filters. Some discussion suggest the vast majority of AI systems currently used in the EU fall into this category, where they represent minimal or no risk.
- ← Previous
- 1
- 2
- 3
- Next →

You must be logged in to post a comment.