
Oracle Database
What a difference a Bind Variable makes
To bind or not to bind, that is the question?
Over the years, I heard and read about using Bind variables and how important they are, particularly when it comes to the efficient execution of queries. By using bind variables, the optimizer will reuse the execution plan from the cache rather than generating it each time. Recently, I had conversations about this with a couple of different groups, and they didn’t really believe me and they asked me to put together a demonstration. One group said they never heard of ‘prepared statements’, ‘bind variables’, ‘parameterised query’, etc., which was a little surprising.
The following is a subset of what I demonstrated to them to illustrate the benefits and potential benefits.
Here is a basic example of a typical scenario where we have a SQL query being constructed using concatenation.
select * from order_demo where order_id = || 'i';That statement looks simple and harmless. When we try to check the EXPLAIN plan from the optimizer we will get an error, so let’s just replace it with a number, because that’s what the query will end up being like.
select * from order_demo where order_id = 1;When we check the Explain Plan, we get the following. It looks like a good execution plan as it is using the index and then doing a ROWID lookup on the table. The developers were happy, and that’s what those recent conversations were about and what they are missing.
-------------------------------------------------------------
| Id | Operation | Name | E-Rows |
-------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | TABLE ACCESS BY INDEX ROWID| ORDER_DEMO | 1 |
|* 2 | INDEX UNIQUE SCAN | SYS_C0014610 | 1 |
-------------------------------------------------------------
The missing part in their understanding was what happens every time they run their query. The Explain Plan looks good, so what’s the problem? The problem lies with the Optimizer evaluating the execution plan every time the query is issued. But the developers came back with the idea that this won’t happen because the execution plan is cached and will be reused. The problem with this is how we can test this, and what is the alternative, in this case, using bind variables (which was my suggestion).
Let’s setup a simple test to see what happens. Here is a simple piece of PL/SQL code which will look 100K times to retrieve just one row. This is very similar to what they were running.
DECLARE
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF4'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = '||i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF4'));
END;
/When we run this test against a 23.7 Oracle Database running in a VM on my laptop, this completes in little over 2 minutes
Start time : 16:26:04:5527
End time : 16:28:13:4820
PL/SQL procedure successfully completed.
Elapsed: 00:02:09.158The developers seemed happy with that time! Ok, but let’s test it using bind variables and see if it’s any different. There are a few different ways of setting up bind variables. The PL/SQL code below is one example.
DECLARE
order_rec ORDER_DEMO%rowtype;
start_time TIMESTAMP;
end_time TIMESTAMP;
BEGIN
start_time := systimestamp;
dbms_output.put_line('Start time : ' || to_char(start_time,'HH24:MI:SS:FF9'));
--
for i in 1 .. 100000 loop
execute immediate 'select * from order_demo where order_id = :1' using i;
end loop;
--
end_time := systimestamp;
dbms_output.put_line('End time : ' || to_char(end_time,'HH24:MI:SS:FF9'));
END;
/
Start time : 16:31:39:162619000
End time : 16:31:40:479301000
PL/SQL procedure successfully completed.
Elapsed: 00:00:01.363This just took a little over one second to complete. Let me say that again, a little over one second to complete. We went from taking just over two minutes to run, down to just over one second to run.
The developers were a little surprised or more correctly, were a little shocked. But they then said the problem with that demonstration is that it is running directly in the Database. It will be different running it in Python across the network.
Ok, let me set up the same/similar demonstration using Python. The image below show some back Python code to connect to the database, list the tables in the schema and to create the test table for our demonstration

The first demonstration is to measure the timing for 100K records using the concatenation approach. I
# Demo - The SLOW way - concat values
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
# only loop 10,000 instead of 100,000 - impact of network latency
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = " + str(i))
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:45:29:523020
End time: 16:49:15:610094This took just under four minutes to complete. With PL/SQL it took approx two minutes. The extrat time is due to the back and forth nature of the client-server communications between the Python code and the Database. The developers were a little unhappen with this result.
The next step for the demonstrataion was to use bind variables. As with most languages there are a number of different ways to write and format these. Below is one example, but some of the others were also tried and give the same timing.
#Bind variables example - by name
#print start-time
print('Start time: ' + datetime.now().strftime("%H:%M:%S:%f"))
for i in range(1, 100000):
cursor.execute("select * from order_demo where order_id = :order_num", order_num=i )
#print end-time
print('End time: ' + datetime.now().strftime("%H:%M:%S:%f"))
----------
Start time: 16:53:00:479468
End time: 16:54:14:197552This took 1 minute 14 seconds. [Read that sentence again]. Compared to approx four minutes, and yes the other bind variable options has similar timing.
To answer the quote at the top of this post, “To bind or not to bind, that is the question?”, the answer is using Bind Variables, Prepared Statements, Parameterised Query, etc will make you queries and applications run a lot quicker. The optimizer will see the structure of the query, will see the parameterised parts of it, will see the execution plan already exists in the cache and will use it instead of generating the execution plan again. Thereby saving time for frequently executed queries which might just have a different value for one or two parts of a WHERE clause.
Comparing Text using Soundex, PHONIC_ENCODE and FUZZY_MATCH
When comparing text strings we have a number of functions on Oracle Database to help us. These include SOUNDEX, PHONIC_ENCODE and FUZZY_MATCH. Let’s have a look at what each of these can do.
The SOUNDEX function returns a character string containing the phonetic representation of a string. SOUNDEX lets you compare words that are spelled differently, but sound alike in English. To illustrate this, let’s compare some commonly spelled words and their variations, for example McDonald, MacDonald, and Smith and Smyth.
select soundex('MCDONALD') from dual;
SOUNDEX('MCDONALD')
___________________
M235
SQL> select soundex('MACDONALD') from dual;
SOUNDEX('MACDONALD')
____________________
M235
SQL> pause next_smith_smyth
next_smith_smyth
SQL>
SQL> select soundex('SMITH') from dual;
SOUNDEX('SMITH')
________________
S530
SQL> select soundex('SMYTH') from dual;
SOUNDEX('SMYTH')
________________
S530
Here we get to see SOUNDEX function returns the same code for each of the spelling variations. This function can be easily used to search for and to compare text in our tables.
Now let’s have a look at some of the different ways to spell Brendan.
select soundex('Brendan'),
2 soundex('BRENDAN'),
3 soundex('Breandan'),
4 soundex('Brenden'),
5 soundex('Brandon'),
6 soundex('Brendawn'),
7 soundex('Bhenden'),
8 soundex('Brendin'),
9 soundex('Brendon'),
10 soundex('Beenden'),
11 soundex('Breenden'),
12 soundex('Brendin'),
13 soundex('Brendyn'),
14 soundex('Brandon'),
15 soundex('Brenainn'),
16 soundex('Bréanainn')
17 from dual;
SOUNDEX('BRENDAN') SOUNDEX('BRENDAN') SOUNDEX('BREANDAN') SOUNDEX('BRENDEN') SOUNDEX('BRANDON') SOUNDEX('BRENDAWN') SOUNDEX('BHENDEN') SOUNDEX('BRENDIN') SOUNDEX('BRENDON') SOUNDEX('BEENDEN') SOUNDEX('BREENDEN') SOUNDEX('BRENDIN') SOUNDEX('BRENDYN') SOUNDEX('BRANDON') SOUNDEX('BRENAINN') SOUNDEX('BRÉANAINN')
__________________ __________________ ___________________ __________________ __________________ ___________________ __________________ __________________ __________________ __________________ ___________________ __________________ __________________ __________________ ___________________ ____________________
B653 B653 B653 B653 B653 B653 B535 B653 B653 B535 B653 B653 B653 B653 B655 B655 We can see which variations of my name can be labeled as being similar in sound.
An alternative function is to use the PHONIC_ENCODE. The PHONIC_ENCODE function converts text into language-specific codes based on the pronunciation of the text. It implements the Double Metaphone algorithm and an alternative algorithm. DOUBLE_METAPHONE returns the primary code. DOUBLE_METAPHONE_ALT returns the alternative code if present. If the alternative code is not present, it returns the primary code.
select col, phonic_encode(double_metaphone,col) double_met
2 from ( values
3 ('Brendan'), ('BRENDAN'), ('Breandan'), ('Brenden'), ('Brandon'),
4 ('Brendawn'), ('Bhenden'), ('Brendin'), ('Brendon'), ('Beenden'),
5 ('Breenden'), ('Brendin'), ('Brendyn'), ('Brandon'), ('Brenainn'),
6 ('Bréanainn')
7 ) names (col);
COL DOUBLE_MET
_________ __________
Brendan PRNT
BRENDAN PRNT
Breandan PRNT
Brenden PRNT
Brandon PRNT
Brendawn PRNT
Bhenden PNTN
Brendin PRNT
Brendon PRNT
Beenden PNTN
Breenden PRNT
Brendin PRNT
Brendyn PRNT
Brandon PRNT
Brenainn PRNN
Bréanainn PRNN The final function we’ll look at is FUZZY_MATCH. The FUZZY_MATCH function is language-neutral. It determines the similarity between two strings and supports several algorithms. Here is a simple example, again using variations of Brendan
with names (col) as (
2 values
3 ('Brendan'), ('BRENDAN'), ('Breandan'), ('Brenden'), ('Brandon'),
4 ('Brendawn'), ('Bhenden'), ('Brendin'), ('Brendon'), ('Beenden'),
5 ('Breenden'), ('Brendin'), ('Brendyn'), ('Brandon'), ('Brenainn'),
6 ('Bréanainn') )
7 select a.col, b.col, fuzzy_match(levenshtein, a.col, b.col) as lev
8 from names a, names b
9 where a.col != b.col;
COL COL LEV
________ _________ ___
Brendan BRENDAN 15
Brendan Breandan 88
Brendan Brenden 86
Brendan Brandon 72
Brendan Brendawn 88
Brendan Bhenden 72
Brendan Brendin 86
Brendan Brendon 86
Brendan Beenden 72
Brendan Breenden 75
Brendan Brendin 86
Brendan Brendyn 86
Brendan Brandon 72
Brendan Brenainn 63
Brendan Bréanainn 45
...Only a portion of the output is shown above. Similar solution would be the following and additionally we can compare the outputs from a number of the algorithms.
with names (col) as (
values
('Brendan'), ('BRENDAN'), ('Breandan'), ('Brenden'), ('Brandon'),
('Brendawn'), ('Bhenden'), ('Brendin'), ('Brendon'), ('Beenden'),
('Breenden'), ('Brendin'), ('Brendyn'), ('Brandon'), ('Brenainn'),
('Bréanainn') )
select a.col as col1, b.col as col2,
fuzzy_match(levenshtein, a.col, b.col) as lev,
fuzzy_match(jaro_winkler, a.col, b.col) as jaro_winkler,
fuzzy_match(bigram, a.col, b.col) as bigram,
fuzzy_match(trigram, a.col, b.col) as trigram,
fuzzy_match(whole_word_match, a.col, b.col) as jwhole_word,
fuzzy_match(longest_common_substring, a.col, b.col) as lcs
from names a, names b
where a.col != b.col
and ROWNUM <= 10;
COL1 COL2 LEV JARO_WINKLER BIGRAM TRIGRAM JWHOLE_WORD LCS
_______ ________ ___ ____________ ______ _______ ___________ ___
Brendan BRENDAN 15 48 0 0 0 14
Brendan Breandan 88 93 71 50 0 50
Brendan Brenden 86 94 66 60 0 71
Brendan Brandon 72 84 50 0 0 28
Brendan Brendawn 88 97 71 66 0 75
Brendan Bhenden 72 82 33 20 0 42
Brendan Brendin 86 94 66 60 0 71
Brendan Brendon 86 94 66 60 0 71
Brendan Beenden 72 82 33 20 0 42
Brendan Breenden 75 90 57 33 0 37 By default, the output is a percentage similarity, but the UNSCALED keyword can be added to return the raw value.
with names (col) as (
values
('Brendan'), ('BRENDAN'), ('Breandan'), ('Brenden'), ('Brandon'),
('Brendawn'), ('Bhenden'), ('Brendin'), ('Brendon'), ('Beenden'),
('Breenden'), ('Brendin'), ('Brendyn'), ('Brandon'), ('Brenainn'),
('Bréanainn') )
select a.col as col1, b.col as col2,
fuzzy_match(levenshtein, a.col, b.col, unscaled) as lev,
fuzzy_match(jaro_winkler, a.col, b.col, unscaled) as jaro_winkler,
fuzzy_match(bigram, a.col, b.col, unscaled) as bigram,
fuzzy_match(trigram, a.col, b.col, unscaled) as trigram,
fuzzy_match(whole_word_match, a.col, b.col, unscaled) as jwhole_word,
fuzzy_match(longest_common_substring, a.col, b.col, unscaled) as lcs
from names a, names b
where a.col != b.col
and ROWNUM <= 10;
COL1 COL2 LEV JARO_WINKLER BIGRAM TRIGRAM JWHOLE_WORD LCS
_______ ________ ___ ____________ ______ _______ ___________ ___
Brendan BRENDAN 6 0.48 0 0 0 1
Brendan Breandan 1 0.93 5 3 0 4
Brendan Brenden 1 0.94 4 3 0 5
Brendan Brandon 2 0.84 3 0 0 2
Brendan Brendawn 1 0.97 5 4 0 6
Brendan Bhenden 2 0.82 2 1 0 3
Brendan Brendin 1 0.94 4 3 0 5
Brendan Brendon 1 0.94 4 3 0 5
Brendan Beenden 2 0.82 2 1 0 3
Brendan Breenden 2 0.9 4 2 0 3This was another post in the ‘Back to Basics’ series of posts. Make sure to check out the other posts in the series.
Vector Databases – Part 2
In this post on Vector Databases, I’ll look at the main components:
- Vector Embedding Models. What they do and what they create.
- Vectors. What they represent, and why they have different sizes.
- Vector Search. An overview of what a Vector Search will do. A more detailed version of this is in a separate post.
- Vector Search Process. It’s a multi-step process and some care is needed.

Vector Embedding Models
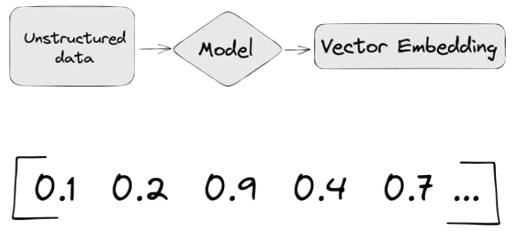
A vector embedding model is a type of machine learning model that transforms data into vectors (embeddings) in a high-dimensional space. These embeddings capture the semantic or contextual relationships between the data points, making them useful for tasks such as similarity search, clustering, and classification.
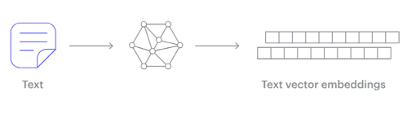
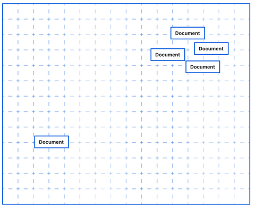
Embedding models are trained to convert the input data point (text, video, image, etc) into a vector (a series of numeric values). The model aims to identify semantic similarity with the input and map these to N-dimensional space. For example, the words “car” and “vehicle” have very different spelling but are semantically similar. The embedding model should map this to have similar vectors. Similarly with documents. The embedding model will map the documents to be able to group similar documents together (in N-dimensional space).
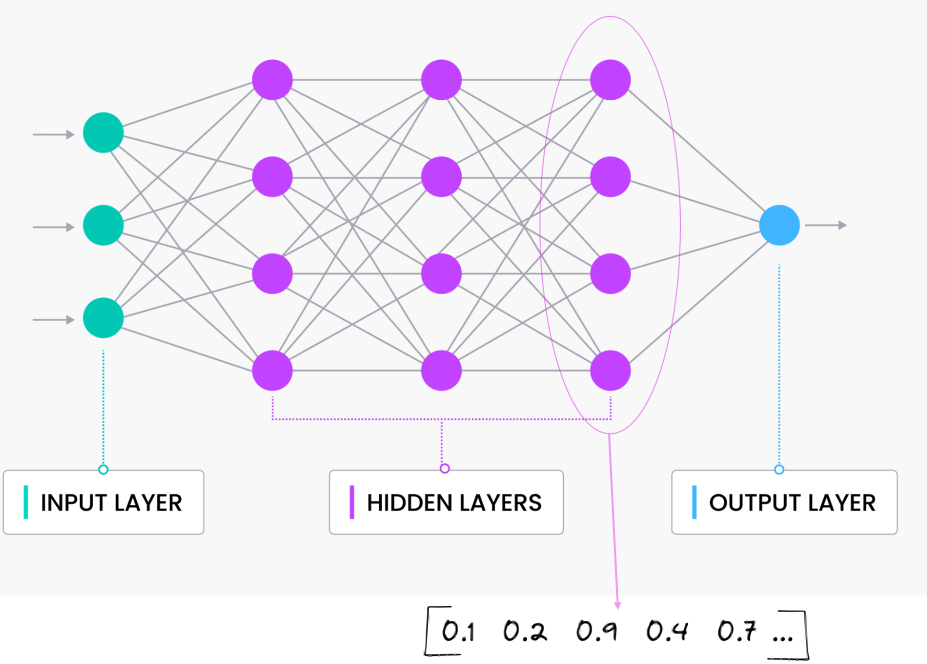
An embedding model is typically a Neural Network (NN) model. There are many different embedding models available from various vendor such as OpenAI, Cohere, etc., or you can build your own. Some models are open source and some are available for a fee. Typically, the output from the embedding model (the Vector) come from the last layer of the neural network
Vectors
A Vector is a sequence of numbers, called dimensions, used to capture the important “features” or “characteristics” of a piece of data. A vector is a mathematical object that has both magnitude (length) and direction. In the context of mathematics and physics, a vector is typically represented as an arrow pointing from one point to another in space, or as a list of numbers (coordinates) that define its position in a particular space.
Different Embedding Models create different numbers of Dimensions. Size is important with vectors as the greater the number number of dimensions the larger the Vector. The larger the number of dimensions the better the semantic similarity matches will be. As Vector size increases, so does space required to store them (not really a problem for Databases, but at Big Data scale it can be a challenge)
As vector size increases so does the Index space, and correspondingly search time can increase as the number of calculations for Distance Measure increases. There are various Vector indexes available to help with this (see my post covering this topic)
Basically, a vector is an array of numbers, where each number represents a dimension. It is easy for us to comprehend and visualise 2 dimensions. Here is an example of using 2 dimensions to represent different types of vehicles. The vectors give us a way to map or chart the data.
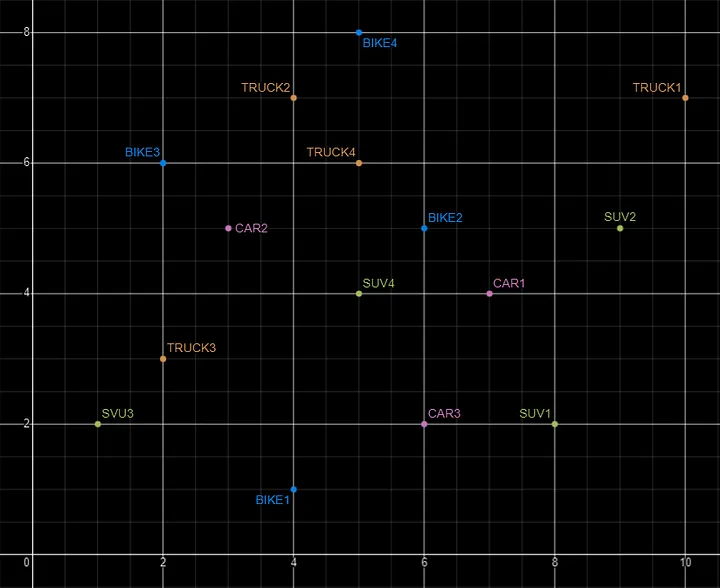
Here is SQL code for this data. I’ll come back to this data in the section on Vector Search.
INSERT INTO PARKING_LOT VALUES('CAR1','[7,4]');
INSERT INTO PARKING_LOT VALUES('CAR2','[3,5]');
INSERT INTO PARKING_LOT VALUES('CAR3','[6,2]');
INSERT INTO PARKING_LOT VALUES('TRUCK1','[10,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK2','[4,7]');
INSERT INTO PARKING_LOT VALUES('TRUCK3','[2,3]');
INSERT INTO PARKING_LOT VALUES('TRUCK4','[5,6]');
INSERT INTO PARKING_LOT VALUES('BIKE1','[4,1]');
INSERT INTO PARKING_LOT VALUES('BIKE2','[6,5]');
INSERT INTO PARKING_LOT VALUES('BIKE3','[2,6]');
INSERT INTO PARKING_LOT VALUES('BIKE4','[5,8]');
INSERT INTO PARKING_LOT VALUES('SUV1','[8,2]');
INSERT INTO PARKING_LOT VALUES('SUV2','[9,5]');
INSERT INTO PARKING_LOT VALUES('SUV3','[1,2]');
INSERT INTO PARKING_LOT VALUES('SUV4','[5,4]');The vectors created by the embedding models can have a different number of dimensions. Common Dimension Sizes are:
- 100-Dimensional: Often used in older or simpler models like some configurations of Word2Vec and GloVe. Suitable for tasks where computational efficiency is a priority and the context isn’t highly complex.
- 300-Dimensional: A common choice for many word embeddings (e.g., Word2Vec, GloVe). Strikes a balance between capturing sufficient detail and computational feasibility.
- 512-Dimensional: Used in some transformer models and sentence embeddings. Offers a richer representation than 300-dimensional embeddings.
- 768-Dimensional: Standard for BERT base models and many other transformer-based models. Provides detailed and contextual embeddings suitable for complex tasks.
- 1024-Dimensional: Used in larger transformer models (e.g., GPT-2 large). Provides even more detail but requires more computational resources.
Many of the newer embedding models have >3000 dimensions!
- Cohere’s embedding model embed-english-v3.0 has 1024 dimensions.
- OpenAI’s embedding model text-embedding-3-large has 3072 dimensions.
- Hugging Face’s embedding model all-MiniLM-L6-v2 has 384 dimensions
Here is a blog post listing some of the embedding models supported by Oracle Vector Search.
Vector Search
Vector search is a method of retrieving data by comparing high-dimensional vector representations (embeddings) of items rather than using traditional keyword or exact-match queries. This technique is commonly used in applications that involve similarity search, where the goal is to find items that are most similar to a given query based on their vector representations.
For example, using the vehicle data given above, we can easily visualise the search for similar vehicles. If we took “CAR1” as our initiating data point and wanted to know what other vehicles are similar to it. Vector Search looks at the distance between “CAR1” and all other vehicles in the 2-dimensional space.
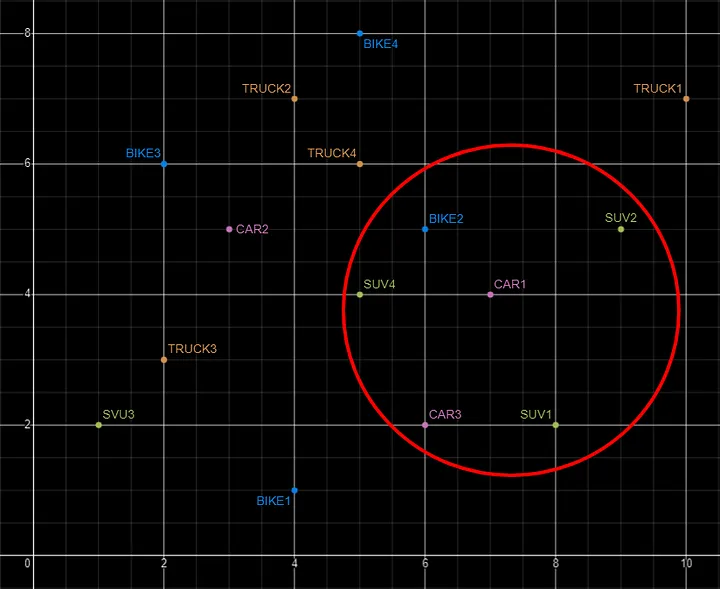
Vector Search becomes a bit more of a challenge when we have 1000+ dimensions, requiring advanced distance algorithms. I’ll have more on these in the next post.
Vector Search Process
The Vector Search process is divided into two parts.
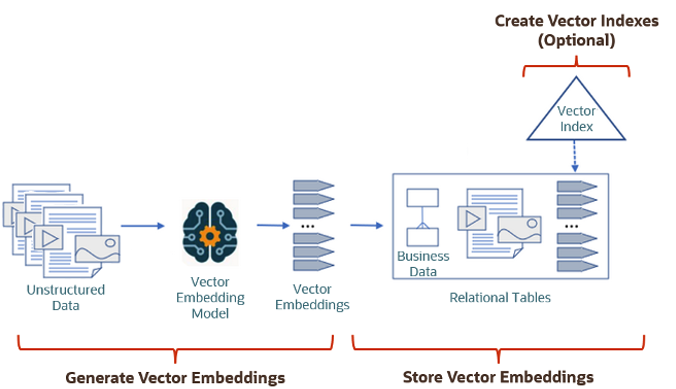
The first part involved creating Vectors for your existing data and for any new data generated and needs to be stored. This data can be used for Semantic Similarity searches (part two of the process). The first part of the process takes your data, applies a vector embedding model to it, generates the vectors and stores them in your Database. When the vectors are stored, Vector Indexes can be created.
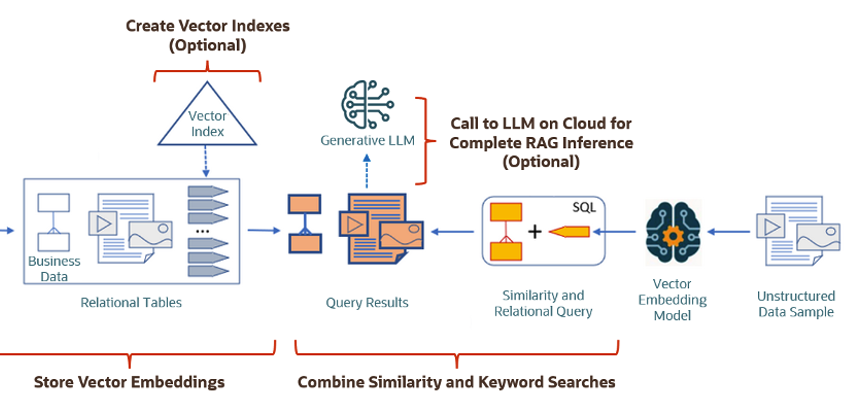
The second part if the process involves Vector Search. This involves having some data you want to search on (e.g. “CARS1” in the previous example). This data will need to be passed to the Vector Embedding model. A Vector for this data is generated. The Vector Search will use this vector to compare to all other vectors in the Database. The results returned will be those vectors (and their corresponding data) that closely match the vector being searched.
Check out my other posts in this series on Vector Databases.
Vector Databases – Part 1
A Vector Database is a specialized database designed to efficiently store, search, and retrieve high-dimensional vectors, which are often used to represent complex data like images, text, or audio. Vector Databases handle the growing need for managing unstructured and semi-structured data generated by AI models, particularly in applications such as recommendation systems, similarity search, and natural language processing. By enabling fast and scalable operations on vector embeddings, vector databases play a crucial role in unlocking the power of modern AI and machine learning applications.

While traditional Databases are very efficient with storing, processing and searching structured data, but over the past 10+ years they have expanded to include many of the typical NoSQL Database features. This allows ‘modern’ multi-model Databases to be capable of processing structured, semi-structured and unstructured data all within a single Database. Such NoSQL capabilities now available in ‘modern’ multi-model Databases include unstructured data, dynamic models, columnar data, in-memory data, distributed data, big data volumes, high performance, graph data processing, spatial data, documents, streaming, machine learning, artificial intelligence, etc. That is a long list of features and I haven’t listed everything. As new data processing paradigms emerge, they are evaluated and businesses identify the usefulness or not of each. If the new data processing paradigms are determined to be useful, apart from some niche use cases, these capabilities are integrated by the vendors of these ‘modern’ multi-model Database vendors. We have seen similar happen with Vector Databases over the past year or so. Yes Vector Databases have existed for many years but we now have the likes of Oracle, PostgreSQL, MySQL, SQL Server and even DB2 including Vector Embedding and Search.

Vector databases are specifically designed to store and search high-dimensional vector embeddings, which are generated by machine learning models. Here are some key use cases for vector databases:
1. Similarity Search:
- Image Search: Vector databases can be used to perform image similarity searches. For example, e-commerce platforms can allow users to search for products by uploading an image, and the system finds visually similar items using image embeddings.
- Document Search: In NLP (Natural Language Processing) tasks, vector databases help find semantically similar documents or text snippets by comparing their embeddings.
2. Recommendation Systems:
- Product Recommendations: Vector databases enable personalized product recommendations by comparing user and item embeddings to suggest items that are similar to a user’s past interactions or preferences.
- Content Recommendation: For media platforms (e.g., video streaming or news), vector databases power recommendation engines by finding content that matches the user’s interests based on embeddings of past behavior and content characteristics.
3. Natural Language Processing (NLP):
- Semantic Search: Vector databases are used in semantic search engines that understand the meaning behind a query, rather than just matching keywords. This is useful for applications like customer support or knowledge bases, where users may phrase questions in various ways.
- Question-Answering Systems: Vector databases can be employed to match user queries with relevant answers by comparing their vector representations, improving the accuracy and relevance of responses.
4. Anomaly Detection:
- Fraud Detection: In financial services, vector databases help detect anomalies or potential fraud by comparing transaction embeddings with a normal behavior profile.
- Security: Vector databases can be used to identify unusual patterns in network traffic or user behavior by comparing embeddings of normal activity to detect security threats.
5. Audio and Video Processing:
- Audio Search: Vector databases allow users to search for similar audio files or songs by comparing audio embeddings, which capture the characteristics of sound.
- Video Recommendation and Search: Embeddings of video content can be stored and queried in a vector database, enabling more accurate content discovery and recommendation in streaming platforms.
6. Geospatial Applications:
- Location-Based Services: Vector databases can store embeddings of geographical locations, enabling applications like nearest-neighbor search for finding the closest points of interest or users in a given area.
- Spatial Queries: Vector databases can be used in applications where spatial relationships matter, such as in logistics and supply chain management, where efficient searching of locations is crucial.
7. Biometric Identification:
- Face Recognition: Vector databases store face embeddings, allowing systems to compare and identify faces for authentication or security purposes.
- Fingerprint and Iris Matching: Similar to face recognition, vector databases can store and search biometric data like fingerprints or iris scans by comparing vector representations.
8. Drug Discovery and Genomics:
- Molecular Similarity Search: In the pharmaceutical industry, vector databases can help in searching for chemical compounds that are structurally similar to known drugs, aiding in drug discovery processes.
- Genomic Data Analysis: Vector databases can store and search genomic sequences, enabling fast comparison and clustering for research and personalized medicine.
9. Customer Support and Chatbots:
- Intelligent Response Systems: Vector databases can be used to store and retrieve relevant answers from a knowledge base by comparing user queries with stored embeddings, enabling more intelligent and context-aware responses in chatbots.
10. Social Media and Networking:
- User Matching: Social networking platforms can use vector databases to match users with similar interests, friends, or content, enhancing the user experience through better connections and content discovery.
- Content Moderation: Vector databases help in identifying and filtering out inappropriate content by comparing content embeddings with known examples of undesirable content.
These use cases highlight the versatility of vector databases in handling various applications that rely on similarity search, pattern recognition, and large-scale data processing in AI and machine learning environments.
This post is the first in a series on Vector Databases. Some will be background details and some will be technical examples using Oracle Database. I’ll post links to the following posts below as they are published.
Select AI – OpenAI changes
A few weeks ago I wrote a few blog posts about using SelectAI. These illustrated integrating and using Cohere and OpenAI with SQL commands in your Oracle Cloud Database. See these links below.
- SelectAI – the beginning of a journey
- SelectAI – Doing something useful
- SelectAI – Can metadata help
- SelectAI – the APEX version
With the constantly changing world of APIs, has impacted the steps I outlined in those posts, particularly if you are using the OpenAI APIs. Two things have changed since writing those posts a few weeks ago. The first is with creating the OpenAI API keys. When creating a new key you need to define a project. For now, just select ‘Default Project’. This is a minor change, but it has caused some confusion for those following my steps in this blog post. I’ve updated that post to reflect the current setup in defining a new key in OpenAI. This is a minor change, oh and remember to put a few dollars into your OpenAI account for your key to work. I put an initial $10 into my account and a few minutes later API key for me from my Oracle (OCI) Database.
The second change is related to how the OpenAI API is called from Oracle (OCI) Databases. The API is now expecting a model name. From talking to the Oracle PMs, they will be implementing a fix in their Cloud Databases where the default model will be ‘gpt-3.5-turbo’, but in the meantime, you have to explicitly define the model when creating your OpenAI profile.
BEGIN
--DBMS_CLOUD_AI.drop_profile(profile_name => 'COHERE_AI');
DBMS_CLOUD_AI.create_profile(
profile_name => 'COHERE_AI',
attributes => '{"provider": "cohere",
"credential_name": "COHERE_CRED",
"object_list": [{"owner": "SH", "name": "customers"},
{"owner": "SH", "name": "sales"},
{"owner": "SH", "name": "products"},
{"owner": "SH", "name": "countries"},
{"owner": "SH", "name": "channels"},
{"owner": "SH", "name": "promotions"},
{"owner": "SH", "name": "times"}],
"model":"gpt-3.5-turbo"
}');
END;Other model names you could use include gpt-4 or gpt-4o.
SQL:2023 Standard
As of June 2023 the new standard for SQL had been released, by the International Organization for Standards. Although SQL language has been around since the 1970s, this is the 11th release or update to the SQL standard. The first version of the standard was back in 1986 and the base-level standard for all databases was released in 1992 and referred to as SQL-92. That’s more than 30 years ago, and some databases still don’t contain all the base features in that standard, although they aim to achieve this sometime in the future.
| Year | Name | Alias | New Features or Enhancements |
|---|---|---|---|
| 1996 | SQL-86 | SQL-87 | This is the first version of the SQL standard by ANSI. Transactions, CREATE, Read, Update and Delete |
| 1989 | SQL-89 | This version includes minor revisions that added integrity constraints. | |
| 1992 | SQL-92 | SQL2 | This version includes major revisions on the SQL Language. Considered the base version of SQL. Many database systems, including NoSQL databases, use this standard for the base specification language, with varying degrees of implementation. |
| 1999 | SQL:1999 | SQL3 | This version introduces many new features such as regex matching, triggers, object-oriented features, OLAP capabilities and User Defined Types. The BOOLEAN data type was introduced but it took some time for all the major databases to support it. |
| 2003 | SQL:2003 | This version contained minor modifications to SQL:1999. SQL:2003 introduces new features such as window functions, columns with auto-generated values, identity specification and the addition of XML. | |
| 2006 | SQL:2006 | This version defines ways of importing, storing and manipulating XML data. Use of XQuery to query data in XML format. | |
| 2008 | SQL:2008 | This version includes major revisions to the SQL Language. Considered the base version of SQL. Many database systems, including NoSQL databases, use this standard for the base specification language, with varying degrees of implementation. | |
| 2011 | SQL:2011 | This version adds enhancements for window functions and FETCH clause, and Temporal data | |
| 2016 | SQL:2016 | This version adds various functions to work with JSON data and Polymorphic Table functions. | |
| 2019 | SQL:2019 | This version specifies muti-dimensional arrays data type. | |
| 2023 | SQL:2023 | This version contains minor updates to SQL functions to bring them in-line with how databases have implemented them. New JSON updates to include a new JSON data type with simpler dot notation processing. The main new addition to the standard is Property Graph Query (PDQ) which defines ways for the SQL language to represent property graphs and to interact with them. |
The Property Graph Query (PGQ) new features have been added as a new section or part of the standard and can be found labelled as Part-16: Property Graph Queries (SQL/PGQ). You can purchase the document for €191. Or you can read and scroll through the preview here.
For the other SQL updates, these updates were to reflect how the various (mainstream) database vendors (PostgreSQL, MySQL, Oracle, SQL Server, have implemented various functions. The standard is catching up with what is happening across the industry. This can be seen in some of the earlier releases
The following blog posts give a good overview of the SQL changes in the SQL:2023 standard.
Although SQL:2023 has been released there are some discussions about the next release of the standard. Although SQL:PGQ has been introduced, it also looks like (from various reports), some parts of SQL:PGQ were dropped and not included. More work is needed on these elements and will be included in the next release.
Also for the next release, there will be more JSON functionality included, with a particular focus on JSON Schemas. Yes, you read that correctly. There is a realisation that a schema is a good thing and when JSON objects can consist of up to 80% meta-data, a schema will have significant benefits for storage, retrieval and processing.
They are also looking at how to incorporate Streaming data. We can see some examples of this kind of processing in other languages and tools (Spark SQL, etc)
The SQL Standard is still being actively developed and we should see another update in a few years time.
Oracle 23c DBMS_SEARCH – Ubiquitous Search
One of the new PL/SQL packages with Oracle 23c is DBMS_SEARCH. This can be used for indexing (and searching) multiple schema objects in a single index.
Check out the documentation for DBMS_SEARCH.
This type of index is a little different to your traditional index. With DBMS_SEARCH we can create an index across multiple schema objects using just a single index. This gives us greater indexing capabilities for scenarios where we need to search data across multiple objects. You can create a ubiquitous search index on multiple columns of a table or multiple columns from different tables in a given schema. All done using one index, rather than having to use multiples. Because of this wider search capability, you will see this (DBMS_SEARCH) being referred to as a Ubiquitous Search Index. A ubiquitous search index is a JSON search index and can be used for full-text and range-based searches.
To create the index, you will first define the name of the index, and then add the different schema objects (tables, views) to it. The main commands for creating the index are:
- DBMS_SEARCH.CREATE_INDEX
- DBMS_SEARCH.ADD_SOURCE
Note: Each table used in the ADD_SOURCE must have a primary key.
The following is an example of using this type of index using the HR schema/data set.
exec dbms_search.create_index('HR_INDEX');This just creates the index header.
Important: For each index created using this method it will create a table with the Index name in your schemas. It will also create fourteen DR$ tables in your schema. SQL Developer filtering will help to hide these and minimise the clutter.
select table_name from user_tables;
...
HR_INDEX
DR$HR_INDEX$I
DR$HR_INDEX$K
DR$HR_INDEX$N
DR$HR_INDEX$U
DR$HR_INDEX$Q
DR$HR_INDEX$C
DR$HR_INDEX$B
DR$HR_INDEX$SN
DR$HR_INDEX$SV
DR$HR_INDEX$ST
DR$HR_INDEX$G
DR$HR_INDEX$DG
DR$HR_INDEX$KG To add the contents and search space to the index we need to use ADD_SOURCE. In the following, I’m adding two tables to the index.
exec DBMS_SEARCH.ADD_SOURCE('HR_INDEX', 'EMPLOYEES');NOTE: At the time of writing this post some of the client tools and libraries do not support the JSON datatype fully. If they did, you could just query the index metadata, but until such time all tools and libraries fully support the data type, you will need to use the JSON_SERIALIZE function to translate the metadata. If you query the metadata and get no data returned, then try using this function to get the data.
Running a simple select from the index might give you an error due to the JSON type not being fully implemented in the client software. (This will change with time)
select * from HR_INDEX;But if we do a count from the index, we could get the number of objects it contains.
select count(*) from HR_INDEX;
COUNT(*)
___________
107 We can view what data is indexed by viewing the virtual document.
select json_serialize(DBMS_SEARCH.GET_DOCUMENT('HR_INDEX',METADATA))
from HR_INDEX;
JSON_SERIALIZE(DBMS_SEARCH.GET_DOCUMENT('HR_INDEX',METADATA))
___________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
{"HR":{"EMPLOYEES":{"PHONE_NUMBER":"515.123.4567","JOB_ID":"AD_PRES","SALARY":24000,"COMMISSION_PCT":null,"FIRST_NAME":"Steven","EMPLOYEE_ID":100,"EMAIL":"SKING","LAST_NAME":"King","MANAGER_ID":null,"DEPARTMENT_ID":90,"HIRE_DATE":"2003-06-17T00:00:00"}}}
{"HR":{"EMPLOYEES":{"PHONE_NUMBER":"515.123.4568","JOB_ID":"AD_VP","SALARY":17000,"COMMISSION_PCT":null,"FIRST_NAME":"Neena","EMPLOYEE_ID":101,"EMAIL":"NKOCHHAR","LAST_NAME":"Kochhar","MANAGER_ID":100,"DEPARTMENT_ID":90,"HIRE_DATE":"2005-09-21T00:00:00"}}}
{"HR":{"EMPLOYEES":{"PHONE_NUMBER":"515.123.4569","JOB_ID":"AD_VP","SALARY":17000,"COMMISSION_PCT":null,"FIRST_NAME":"Lex","EMPLOYEE_ID":102,"EMAIL":"LDEHAAN","LAST_NAME":"De Haan","MANAGER_ID":100,"DEPARTMENT_ID":90,"HIRE_DATE":"2001-01-13T00:00:00"}}}
{"HR":{"EMPLOYEES":{"PHONE_NUMBER":"590.423.4567","JOB_ID":"IT_PROG","SALARY":9000,"COMMISSION_PCT":null,"FIRST_NAME":"Alexander","EMPLOYEE_ID":103,"EMAIL":"AHUNOLD","LAST_NAME":"Hunold","MANAGER_ID":102,"DEPARTMENT_ID":60,"HIRE_DATE":"2006-01-03T00:00:00"}}}
{"HR":{"EMPLOYEES":{"PHONE_NUMBER":"590.423.4568","JOB_ID":"IT_PROG","SALARY":6000,"COMMISSION_PCT":null,"FIRST_NAME":"Bruce","EMPLOYEE_ID":104,"EMAIL":"BERNST","LAST_NAME":"Ernst","MANAGER_ID":103,"DEPARTMENT_ID":60,"HIRE_DATE":"2007-05-21T00:00:00"}}} We can search the metadata for certain data using the CONTAINS or JSON_TEXTCONTAINS functions.
select json_serialize(metadata)
from DEMO_IDX
where contains(data, 'winston')>0;select json_serialize(metadata)
from DEMO_IDX
where json_textcontains(data, '$.HR.EMPLOYEES.FIRST_NAME', 'Winston');When the index is no longer required it can be dropped by running the following. Don’t run a DROP INDEX command as that removes some objects and leaves others behind! (leaves a bit of mess) and you won’t be able to recreate the index, unless you give it a different name.
exec dbms_search.drop_index('SH_INDEX');Number of rows in each Table – Various Databases
A possible common task developers perform is to find out how many records exists in every table in a schema. In the examples below I’ll show examples for the current schema of the developer, but these can be expanded easily to include tables in other schemas or for all schemas across a database.
These example include the different ways of determining this information across the main databases including Oracle, MySQL, Postgres, SQL Server and Snowflake.
A little warning before using these queries. They may or may not give the true accurate number of records in the tables. These examples illustrate extracting the number of records from the data dictionaries of the databases. This is dependent on background processes being run to gather this information. These background processes run from time to time, anything from a few minutes to many tens of minutes. So, these results are good indication of the number of records in each table.
Oracle
SELECT table_name, num_rows
FROM user_tables
ORDER BY num_rows DESC;or
SELECT table_name,
to_number(
extractvalue(xmltype(
dbms_xmlgen.getxml('select count(*) c from '||table_name))
,'/ROWSET/ROW/C')) tab_count
FROM user_tables
ORDER BY tab_count desc;Using PL/SQL we can do something like the following.
DECLARE
val NUMBER;
BEGIN
FOR i IN (SELECT table_name FROM user_tables ORDER BY table_name desc) LOOP
EXECUTE IMMEDIATE 'SELECT count(*) FROM '|| i.table_name INTO val;
DBMS_OUTPUT.PUT_LINE(i.table_name||' -> '|| val );
END LOOP;
END;MySQL
SELECT table_name, table_rows
FROM INFORMATION_SCHEMA.TABLES
WHERE table_type = 'BASE TABLE'
AND TABLE_SCHEMA = current_user();
Using Common Table Expressions (CTE), using WITH clause
WITH table_list AS (
SELECT
table_name
FROM information_schema.tables
WHERE table_schema = current_user()
AND
table_type = 'BASE TABLE'
)
SELECT CONCAT(
GROUP_CONCAT(CONCAT("SELECT '",table_name,"' table_name,COUNT(*) rows FROM ",table_name) SEPARATOR " UNION "),
' ORDER BY table_name'
)
INTO @sql
FROM table_list;
Postgres
select relname as table_name, n_live_tup as num_rows from pg_stat_user_tables;
An alternative is
select n.nspname as table_schema,
c.relname as table_name,
c.reltuples as rows
from pg_class c
join pg_namespace n on n.oid = c.relnamespace
where c.relkind = 'r'
and n.nspname = current_user
order by c.reltuples desc;
SQL Server
SELECT tab.name,
sum(par.rows)
FROM sys.tables tab INNER JOIN sys.partitions par
ON tab.object_id = par.object_id
WHERE schema_name(tab.schema_id) = current_user
Snowflake
SELECT t.table_schema, t.table_name, t.row_count
FROM information_schema.tables t
WHERE t.table_type = 'BASE TABLE'
AND t.table_schema = current_user
order by t.row_count desc;
The examples give above are some of the ways to obtain this information. As with most things, there can be multiple ways of doing it, and most people will have their preferred one which is based on their background and preferences.
As you can see from the code given above they are all very similar, with similar syntax, etc. The only thing different is the name of the data dictionary table/view containing the information needed. Yes, knowing what data dictionary views to query can be a little challenging as you switch between databases.
AUTO_PARTITION – Inspecting & Implementing Recommendations
In a previous blog post I gave an overview of the DBMS_AUTO_PARTITION package in Oracle Autonomous Database. This looked at how you can get started and to setup Auto Partitioning and to allow it to automatically implement partitioning.
This might not be something the DBAs will want to happen for lots of different reasons. An alternative is to use DBMS_AUTO_PARTITION to make recommendations for tables where partitioning will have a performance improvement. The DBA can inspect these recommendations and decide which of these to implement.
In the previous post we set the CONFIGURE function to be ‘IMPLEMENT’. We need to change that to report the recommendations.
exec dbms_auto_partition.configure('AUTO_PARTITION_MODE','REPORT ONLY');Just remember, tables will only be considered by AUTO_PARTITION as outlined in my previous post.
Next we can ask for recommendations using the RECOMMEND_PARTITION_METHOD function.
exec dbms_auto_partition.recommend_partition_method(
table_owner => 'WHISKEY',
table_name => 'DIRECTIONS',
report_type => 'TEXT',
report_section => 'ALL',
report_level => 'ALL');The results from this are stored in DBA_AUTO_PARTITION_RECOMMENDATIONS, which you can query to view the recommendations.
select recommendation_id, partition_method, partition_key
from dba_auto_partition_recommendations;RECOMMENDATION_ID PARTITION_METHOD PARTITION_KEY
-------------------------------- ------------------------------------------------------------------------------------------------------------- --------------
D28FC3CF09DF1E1DE053D010000ABEA6 Method: LIST(SYS_OP_INTERVAL_HIGH_BOUND("D", INTERVAL '2' MONTH, TIMESTAMP '2019-08-10 00:00:00')) AUTOMATIC D
To apply the recommendation pass the RECOMMENDATION_KEY value to the APPLY_RECOMMENDATION function.
exec dbms_auto_partition.apply_recommendation('D28FC3CF09DF1E1DE053D010000ABEA6');It might takes some minutes for the partitioned table to become available. During this time the original table will remain available as the change will be implemented using a ALTER TABLE MODIFY PARTITION ONLINE command.
Two other functions include REPORT_ACTIVITY and REPORT_LAST_ACTIVITY. These can be used to export a detailed report on the recommendations in text or HTML form. It is probably a good idea to create and download these for your change records.
spool autoPartitionFinding.html
select dbms_auto_partition.report_last_activity(type=>'HTML') from dual;
exit;AUTO_PARTITION – Basic setup
Partitioning is an effective way to improve performance of SQL queries on large volumes of data in a database table. But only so, if a bit of care and attention is taken by both the DBA and Developer (or someone with both of these roles). Care is needed on the database side to ensure the correct partitioning method is deployed and the management of these partitions, as some partitioning methods can create a significantly large number of partitions, which in turn can affect the management of these and possibly performance too, which is not what you want. Care is also needed from the developer side to ensure their code is written in a way that utilises the partitioning method deployed. If doesn’t then you may not see much improvement in performance of your queries, and somethings things can run slower. Which not one wants!
With the Oracle Autonomous Database we have the expectation it will ‘manage’ a lot of the performance features behind the scenes without the need for the DBA and Developing getting involved (‘Autonomous’). This is kind of true up to a point, as the serverless approach can work up to a point. Sometimes a little human input is needed to give a guiding hand to the Autonomous engine to help/guide it towards what data needs particular focus.
In this (blog post) case we will have a look at DBMS_AUTO_PARTITION and how you can do a basic setup, config and enablement. I’ll have another post that will look at the recommendation feature of DBMS_AUTO_PARTITION. Just a quick reminder, DBMS_AUTO_PARTITION is for the Oracle Autonomous Database (ADB) (on the Cloud). You’ll need to run the following as ADMIN user.
The first step is to enable auto partitioning on the ADB using the CONFIGURE function. This function can have three parameters:
- IMPLEMENT : generates a report and implements the recommended partitioning method. (Autonomous!)
- REPORT_ONLY : {default} reports recommendations for partitioning on tables
- OFF : Turns off auto partitioning (reporting and implementing)
For example, to enable auto partitioning and to automatically implement the recommended partitioning method.
exec DBMS_AUTO_PARTITION.CONFIGURE('AUTO_PARTITION_MODE', 'IMPLEMENT');The changes can be inspected in the DBA_AUTO_PARTITION_CONFIG view.
SELECT * FROM DBA_AUTO_PARTITION_CONFIG;When you look at the listed from the above select we can see IMPLEMENT is enabled

The next step with using DBMS_AUTO_PARTITION is to tell the ADB what schemas and/or tables to include for auto partitioning. This first example shows how to turn on auto partitioning for a particular schema, and to allow the auto partitioning (engine) to determine what is needed and to just go and implement that it thinks is the best partitioning methods.
exec DBMS_AUTO_PARTITION.CONFIGURE(
parameter_name => 'AUTO_PARTITION_SCHEMA',
parameter_value => 'WHISKEY',
ALLOW => TRUE);If you query the DBA view again we now get.

We have not enabled a schema (called WHISKEY) to be included as part of the auto partitioning engine.
Auto Partitioning may not do anything for a little while, with some reports suggesting to wait for 15 minutes for the database to pick up any changes and to make suggestions. But there are some conditions for a table needs to meet before it can be considered, this is referred to as being a ‘Candidate’. These conditions include:
- Table passes inclusion and exclusion tests specified by AUTO_PARTITION_SCHEMA and AUTO_PARTITION_TABLE configuration parameters.
- Table exists and has up-to-date statistics.
- Table is at least 64 GB.
- Table has 5 or more queries in the SQL tuning set that scanned the table.
- Table does not contain a LONG data type column.
- Table is not manually partitioned.
- Table is not an external table, an internal/external hybrid table, a temporary table, an index-organized table, or a clustered table.
- Table does not have a domain index or bitmap join index.
- Table is not an advance queuing, materialized view, or flashback archive storage table.
- Table does not have nested tables, or certain other object features.
If you find Auto Partitioning isn’t partitioning your tables (i.e. not a valid Candidate) it could be because the table isn’t meeting the above list of conditions.
This can be verified using the VALIDATE_CANDIDATE_TABLE function.
select DBMS_AUTO_PARTITION.VALIDATE_CANDIDATE_TABLE(
table_owner => 'WHISKEY',
table_name => 'DIRECTIONS')
from dual;If the table has met the above list of conditions, the above query will return ‘VALID’, otherwise one or more of the above conditions have not been met, and the query will return ‘INVALID:’ followed by one or more reasons
Check out my other blog post on using the AUTO_PARTITION to explore it’s recommendations and how to implement.
Running Oracle Database on Docker on Apple M1 Chip
Click on this link to see the latest way to run Oracle 23ai Database on Docker. The instructions below are a bit obsolete, although they work for M1. To run Oracle 23ai Database on Docker on Apple Scilcon check out the instructions on this link.
This post is for you if you have an Apple M1 laptop and cannot get Oracle Database to run on Docker.
The reason Oracle Database, and lots of other software, doesn’t run on the new Apple Silicon is their new chip uses a different instruction set to what is used by Intel chips. Most of the Database vendors have come out to say they will not be porting their Databases to the M1 chip, as most/all servers out there run on x86 chips, and the cost of porting is just not worth it, as there is zero customers.
Are you using an x86 Chip computer (Windows or Macs with intel chips)? If so, follow these instructions (and ignore this post)
If you have been using Apple for your laptop for some time and have recently upgraded, you are now using the M1 chip, and you have probably found some of your software doesn’t run. In my scenario (and with many other people) you can no longer run an Oracle Database 😦
But there does seem to be a possible solution and this has been highlighted by Tom de Vroomen on his blog. A workaround is to spin up an x86 container using Colima. Tom has given some instructions on his blog, and what I list below is an extended set of instructions to get fully set up and running with Oracle on Docker on M1 chip.
1-Install Homebrew
You might have Homebrew installed, but if not run the following to install.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"2-Install colima
You can now install Colima using Homebrew. This might take a minute or two to run.
brew install colima3-Start colima x86 container
With Colima installed, we can now start an x86 container.
colima start --arch x86_64 --memory 4
The container will be based on x86, which is an important part of what we need. The memory is 4GB, but you can probably drop that a little.
The above command should start within a second or two.
4-Install Oracle Database for Docker
The following command will create an Oracle Database docker image using the image created by Gerald Venzi.
docker run -d -p 1521:1521 -e ORACLE_PASSWORD=<your password> -v oracle-volume:/opt/oracle/oradata gvenzl/oracle-xe
23c Database – If you want to use the 23c Database, Check out this post for the command to install
I changed <your password> to SysPassword1.
This will create the docker image and will allow for any changes to the database to be persisted after you shutdown docker. This is what you want to happen.
5-Log-in to Oracle as System
Open the docker client to see if the Oracle Database image is running. If not click on the run button.

When it finishes starting up, open the command line (see icon to the left of the run button), and log in as the SYSTEM user.
sqlplus system/SysPassword1@//localhost/XEPDB1
You are now running Oracle Database on Docker on an M1 chip laptop 🙂
6-Create new user
You shouldn’t use the System user, as that is like using root for everything. You’ll need to create a new user/schema in the database for you to use for your work. Run the following.
create user brendan identified by BTPassword1 default tablespace usersgrant connect, resource to brendan;If these run without any errors you now have your own schema in the Oracle Database on Docker (on M1 chip)
7-Connect using SQL*Plus & SQL Developer
Now let’s connect to the schema using sqlplus.
sqlplus brendan/BTPassword1@//localhost/XEPDB1That should work for you and you can now proceed using the command line tool.
If you refer to use a GUI tool then go install SQL Developer. Jeff Smith has a blog post about installing SQL Developer on M1 chip. Here is the connection screen with all the connection details entered (using the username and password given/used above)

You can now use the command line as well as SQL Developer to connect to your Oracle Database (on docker on M1).
8-Stop Docker and Colima
After you have finished using the Oracle Database on Docker you will want to shut it down until the next time you want to use it. There are two steps to follow. The first is to stop the Docker image. Just go to the Docker Desktop and click on the Stop button. It might take a few seconds for it to shutdown.
The second thing you need to do is to stop Colima.
colima stopThat’s it all done.
9-What you need to run the next time (and every time after that)
For the second and subsequent time you want to use the Oracle Docker image all you need to do is the following
(a) Start Colima
colima start --arch x86_64 --memory 4
(b) Start Oracle on Docker
Open Docker Desktop and click on the Run button [see Docker Desktop image above]
And to stop everything
(a) Stop the Oracle Database on Docker Desktop
(b) Stop Colima by running ‘colima stop’ in a terminal
Oracle Database In-Memory – simple example
In a previous post, I showed how to enable and increase the memory allocation for use by Oracle In-Memory. That example was based on using the Pre-built VM supplied by Oracle.
To use In-Memory on your objects, you have a few options.
Enabling the In-Memory attribute on the EXAMPLE tablespace by specifying the INMEMORY attribute
SQL> ALTER TABLESPACE example INMEMORY;Enabling the In-Memory attribute on the sales table but excluding the “prod_id” column
SQL> ALTER TABLE sales INMEMORY NO INMEMORY(prod_id);Disabling the In-Memory attribute on one partition of the sales table by specifying the NO INMEMORY clause
SQL> ALTER TABLE sales MODIFY PARTITION SALES_Q1_1998 NO INMEMORY;Enabling the In-Memory attribute on the customers table with a priority level of critical
SQL> ALTER TABLE customers INMEMORY PRIORITY CRITICAL;You can also specify the priority level, which helps to prioritise the order the objects are loaded into memory.

A simple example to illustrate the effect of using In-Memory versus not.
Create a table with, say, 11K records. It doesn’t really matter what columns and data are.
Now select all the records and display the explain plan
select count(*) from test_inmemory;
Now, move the table to In-Memory and rerun your query.
alter table test_inmemory inmemory PRIORITY critical;
select count(*) from test_inmemory; -- again
There you go!
We can check to see what object are In-Memory by
SELECT table_name, inmemory, inmemory_priority, inmemory_distribute,
inmemory_compression, inmemory_duplicate
FROM user_tables
WHERE inmemory = 'ENABLED’
ORDER BY table_name;
To remove the object from In-Memory
SQL > alter table test_inmemory no inmemory; -- remove the table from in-memory
This is just a simple test and lots of other things can be done to improve performance
But, you do need to be careful about using In-Memory. It does have some limitations and scenarios where it doesn’t work so well. So care is needed

You must be logged in to post a comment.