
Data Science
Managing imbalanced Data Sets with SMOTE in Python
When working with data sets for machine learning, lots of these data sets and examples we see have approximately the same number of case records for each of the possible predicted values. In this kind of scenario we are trying to perform some kind of classification, where the machine learning model looks to build a model based on the input data set against a target variable. It is this target variable that contains the value to be predicted. In most cases this target variable (or feature) will contain binary values or equivalent in categorical form such as Yes and No, or A and B, etc or may contain a small number of other possible values (e.g. A, B, C, D).
For the classification algorithm to perform optimally and be able to predict the possible value for a new case record, it will need to see enough case records for each of the possible values. What this means, it would be good to have approximately the same number of records for each value (there are many ways to overcome this and these are outside the score of this post). But most data sets, and those that you will encounter in real life work scenarios, are never balanced, as in having a 50-50 split. What we typically encounter might be a 90-10, 98-2, etc type of split. These data sets are said to be imbalanced.

The image above gives examples of two approaches for creating a balanced data set. The first is under-sampling. This involves reducing the class that contains the majority of the case records and reducing it to match the number of case records in the minor class. The problems with this include, the resulting data set is too small to be meaningful, the case records removed could contain important records and scenarios that the model will need to know about.
The second example is creating a balanced data set by increasing the number of records in the minority class. There are a few approaches to creating this. The first approach is to create duplicate records, from the minor class, until such time as the number of case records are approximately the same for each class. This is the simplest approach. The second approach is to create synthetic records that are statistically equivalent of the original data set. A commonly technique used for this is called SMOTE, Synthetic Minority Oversampling Technique. SMOTE uses a nearest neighbors algorithm to generate new and synthetic data we can use for training our model. But one of the issues with SMOTE is that it will not create sample records outside the bounds of the original data set. As you can image this would be very difficult to do.
The following examples will illustrate how to perform Under-Sampling and Over-Sampling (duplication and using SMOTE) in Python using functions from Pandas, Imbalanced-Learn and Sci-Kit Learn libraries.
NOTE: The Imbalanced-Learn library (e.g. SMOTE)requires the data to be in numeric format, as it statistical calculations are performed on these. The python function get_dummies was used as a quick and simple to generate the numeric values. Although this is perhaps not the best method to use in a real project. With the other sampling functions can process data sets with a sting and numeric.
Data Set: Is the Portuaguese Banking data set and is available on the UCI Data Set Repository, and many other sites. Here are some basics with that data set.
import warnings
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
get_ipython().magic('matplotlib inline')
bank_file = ".../bank-additional-full.csv"
# import dataset
df = pd.read_csv(bank_file, sep=';',)
# get basic details of df (num records, num features)
df.shape
df['y'].value_counts() # dataset is imbalanced with majority of class label as "no".
no 36548 yes 4640 Name: y, dtype: int64
#print bar chart df.y.value_counts().plot(kind='bar', title='Count (target)');

Example 1a – Down/Under sampling the majority class y=1 (using random sampling)
count_class_0, count_class_1 = df.y.value_counts()
# Divide by class
df_class_0 = df[df['y'] == 0] #majority class
df_class_1 = df[df['y'] == 1] #minority class
# Sample Majority class (y=0, to have same number of records as minority calls (y=1)
df_class_0_under = df_class_0.sample(count_class_1)
# join the dataframes containing y=1 and y=0
df_test_under = pd.concat([df_class_0_under, df_class_1])
print('Random under-sampling:')
print(df_test_under.y.value_counts())
print("Num records = ", df_test_under.shape[0])
df_test_under.y.value_counts().plot(kind='bar', title='Count (target)');
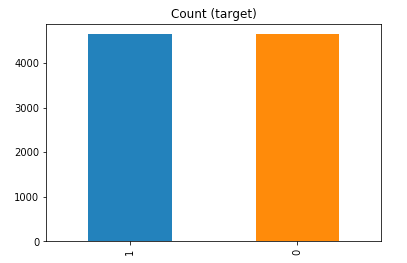
Example 1b – Down/Under sampling the majority class y=1 using imblearn
from imblearn.under_sampling import RandomUnderSampler
X = df_new.drop('y', axis=1)
Y = df_new['y']
rus = RandomUnderSampler(random_state=42, replacement=True)
X_rus, Y_rus = rus.fit_resample(X, Y)
df_rus = pd.concat([pd.DataFrame(X_rus), pd.DataFrame(Y_rus, columns=['y'])], axis=1)
print('imblearn over-sampling:')
print(df_rus.y.value_counts())
print("Num records = ", df_rus.shape[0])
df_rus.y.value_counts().plot(kind='bar', title='Count (target)');
[same results as Example 1a]
Example 1c – Down/Under sampling the majority class y=1 using Sci-Kit Learn
from sklearn.utils import resample
print("Original Data distribution")
print(df['y'].value_counts())
# Down Sample Majority class
down_sample = resample(df[df['y']==0],
replace = True, # sample with replacement
n_samples = df[df['y']==1].shape[0], # to match minority class
random_state=42) # reproducible results
# Combine majority class with upsampled minority class
train_downsample = pd.concat([df[df['y']==1], down_sample])
# Display new class counts
print('Sci-Kit Learn : resample : Down Sampled data set')
print(train_downsample['y'].value_counts())
print("Num records = ", train_downsample.shape[0])
train_downsample.y.value_counts().plot(kind='bar', title='Count (target)');
[same results as Example 1a]
Example 2 a – Over sampling the minority call y=0 (using random sampling)
df_class_1_over = df_class_1.sample(count_class_0, replace=True)
df_test_over = pd.concat([df_class_0, df_class_1_over], axis=0)
print('Random over-sampling:')
print(df_test_over.y.value_counts())
df_test_over.y.value_counts().plot(kind='bar', title='Count (target)');
Random over-sampling: 1 36548 0 36548 Name: y, dtype: int64
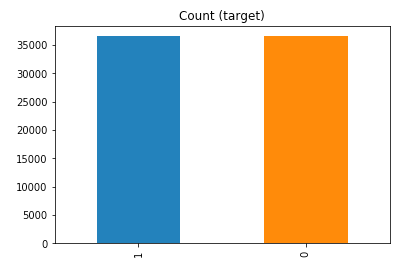
Example 2b – Over sampling the minority call y=0 using SMOTE
from imblearn.over_sampling import SMOTE
print(df_new.y.value_counts())
X = df_new.drop('y', axis=1)
Y = df_new['y']
sm = SMOTE(random_state=42)
X_res, Y_res = sm.fit_resample(X, Y)
df_smote_over = pd.concat([pd.DataFrame(X_res), pd.DataFrame(Y_res, columns=['y'])], axis=1)
print('SMOTE over-sampling:')
print(df_smote_over.y.value_counts())
df_smote_over.y.value_counts().plot(kind='bar', title='Count (target)');
[same results as Example 2a]
Example 2c – Over sampling the minority call y=0 using Sci-Kit Learn
from sklearn.utils import resample
print("Original Data distribution")
print(df['y'].value_counts())
# Upsample minority class
train_positive_upsample = resample(df[df['y']==1],
replace = True, # sample with replacement
n_samples = train_zero.shape[0], # to match majority class
random_state=42) # reproducible results
# Combine majority class with upsampled minority class
train_upsample = pd.concat([train_negative, train_positive_upsample])
# Display new class counts
print('Sci-Kit Learn : resample : Up Sampled data set')
print(train_upsample['y'].value_counts())
train_upsample.y.value_counts().plot(kind='bar', title='Count (target)');
[same results as Example 2a]
Examples of using Machine Learning on Video and Photo in Public
Over the past 18 months or so most of the examples of using machine learning have been on looking at images and identifying objects in them. There are the typical examples of examining pictures looking for a Cat or a Dog, or some famous person, etc. Most of these examples are very noddy, although they do illustrate important examples.
But what if this same technology was used to monitor people going about their daily lives. What if pictures and/or video was captured of you as you walked down the street or on your way to work or to a meeting. These pictures and videos are being taken of you without you knowing.
And this raises a wide range of Ethical concerns. There are the ethics of deploying such solutions in the public domain, but there are also ethical concerns for the data scientists, machine learner, and other people working on these projects. “Just because we can, doesn’t mean we should”. People need to decide, if they are working on one of these projects, if they should be working on it and if not what they can do.
Ethics are the principals of behavior based on ideas of right and wrong. Ethical principles often focus on ideas such as fairness, respect, responsibility, integrity, quality, transparency and trust. There is a lot in that statement on Ethics, but we all need to consider that is right and what is wrong. But instead of wrong, what is grey-ish, borderline scenarios.
Here are some examples that might fall into the grey-ish space between right and wrong. Why they might fall more towards the wrong is because most people are not aware their image is being captured and used, not just for a particular purpose at capture time, but longer term to allow for better machine learning models to be built.
Can you imagine walking down the street with a digital display in front of you. That display is monitoring you, and others, and then presents personalized adverts on the digital display aim specifically at you. A classify example of this is in the film Minority Report. This is no longer science fiction.

This is happening at the Westfield shopping center in London and in other cities across UK and Europe. These digital advertisement screens are monitoring people, identifying their personal characteristics and then customizing the adverts to match in with the profile of the people walking past. This solutions has been developed and rolled out by Ocean Out Door. They are using machine learning to profile the individual people based on gender, age, facial hair, eye wear, mood, engagement, attention time, group size, etc. They then use this information to:
- Optimisation – delivering the appropriate creative to the right audience at the right time.
- Visualise – Gaze recognition to trigger creative or an interactive experience
- AR Enabled – Using the HD cameras to create an augmented reality mirror or window effect, creating deep consumer engagement via the latest technology
- Analytics – Understanding your brand’s audience, post campaign analysis and creative testing

Face Plus Plus can monitor people walking down the street and do similar profiling, and can bring it to another level where by they can identify what clothing you are wearing and what the brand is. Image if you combine this with location based services. An example of this, imagine you are walking down the high street or a major retail district. People approach you trying to entice you into going into a particular store, and they offer certain discounts. But you are with a friend and the store is not interested in them.
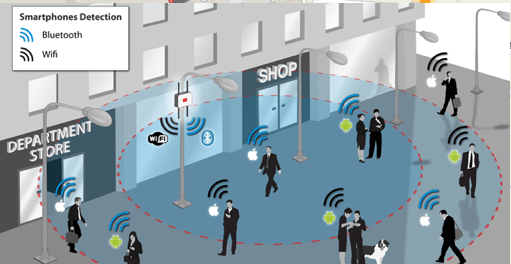
The store is using video monitoring, capturing details of every person walking down the street and are about to pass the store. The video is using machine/deep learning to analyze you profile and what brands you are wearing. The store as a team of people who are deployed to stop and engage with certain individuals, just because they make the brands or interests of the store and depending on what brands you are wearing can offer customized discounts and offers to you.
How comfortable would you be with this? How comfortable would you be about going shopping now?
For me, I would not like this at all, but I can understand why store and retail outlets are interested, as they are all working in a very competitive market trying to maximize every dollar or euro they can get.
Along side the ethical concerns, we also have some legal aspects to consider. Some of these are a bit in the grey-ish area, as some aspects of these kind of scenarios are slightly addresses by EU GDPR and the EU Artificial Intelligence guidelines. But what about other countries around the World. Then it comes to training and deploying these facial models, they are dependent on having a good training data set. This means they needs lots and lots of pictures of people and these pictures need to be labelled with descriptive information about the person. For these public deployments of facial recognition systems, then will need more and more training samples/pictures. This will allow the models to improve and evolve over time. But how will these applications get these new pictures? They claim they don’t keep any of the images of people. They only take the picture, use the model on it, and then perform some action. They claim they do not keep the images! But how can they improve and evolve their solution?
I’ll have another blog post giving more examples of how machine/deep learning, video and image captures are being used to monitor people going about their daily lives.
Machine Learning Tools and Workbenches
The following is a list of the most commonly used tools and workbenches for machine learning. These are specific to machine learning only. This list does not include any library or frameworks. These are tools and workbenches only. Most offering machine learning tools will include the following features:
- Easy drag and drop capabilities
- Data collection
- Data preparation and cleaning
- Model building
- Data Visualization
- Model Deployment
- Integration with other tools and languages
As more and more organizations implement machine learning, there are two core aims they want to achieve.
- Employee Productivity: Who wants to spend days or weeks writing mundane code to load data, clean data, etc etc etc. No one wants to do this and especially employers don’t want their staff wasting time on this. Instead they are happy to invest in tools and workbenches where a lot or most or all of these mundane tasks are automated for you. You can not concentrate on the important tasks of adding value to your organisation. This saves money, improves employee productivity and employee value.
- Integration with Technical Architecture: Many of these tools and workbenches allow for easy integration with the technical architecture and thereby allowing easy and quick integration of machine learning withe the day to day activities of the organization. This saves money, improves employee productivity and employee value.
SAS
SAS software has been around for every and is the great grand-daddy of analytics and machine learning. They have built a large number of machine learning tools and solutions built upon these for various industries. Their core machine learning tools include SAS Enterprise Miner and SAS Visual Data Mining and Machine Learning.


Microsoft
Microsoft have been improving their Machine Learning offering over the years and most of this is based on the Azure cloud platform with Microsoft Azure Machine Learning Studio and Azure Databricks.


SAP
SAP Leonardo is a cloud based platform for machine learning and supports tight integration with other SAP software.


Oracle
Oracle have a number of machine learning tools and supports for the main machine learning languages. They have built a large number of applications (both cloud and on-premises) with in-built machine learning. Their main tools for machine learning include Oracle Data Miner, Oracle Machine Learning and Oracle Analytics (OAC or DVD versions)



Cloudera
If you work with hadoop and big data then you are probably using Cloudera in some way. Cloudera have hired Hilary Mason as their GM of ML. By taking an “AI factory” approach to turning data into decisions, you can make the process of building, scaling, and deploying enterprise ML and AI solutions automated, repeatable, and predictable—boring even. Cloudera Data Science Workbench is their solution.
IBM
IBM have a number of machine learning tools, one of them being a long standing member of the machine learning community, SPSS Modeler. Other machine learning tools include Watson Studio, IBM Machine Learning for z/OS, and IBM Watson Explorer.




Google have a large number of machine learning solutions including everything from traditional machine learning, into NLP, in Image processing, Video processing, etc. It’s a long list. Many of these come with various APIs to access these features. Most of these revolve around their Google AI Cloud offering. But sticking with the tools and workbenches we have AI Platform Notebooks, Kubeflow, and BigQuery ML.



TensorBoard
TensorBoard is a suite of tools for graphical representation of different aspects and stages of machine learning in TensorFlow.


Amazon
A bit like Goolge, Amazon has a large number of solutions for machine learning and AI, and most of these are available via an API or some cloud service. Amazon SageMaker is their main service.


Looker
Looker connects directly with Google BQML reduces additional complexity for data scientists by eliminating the need to move outputs of predictive models back into the database for use, while also increases the time-to-value for business users, allowing them to operationalize the outputs of predictive metrics to make better decisions every day.


Weka
Weka has been around for a long time and still popular in some research groups. Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization.



RapidMiner
RapidMiner Studio has been around for a long time and is one of the few more visual workflow tools (that everyone else should be doing).



Databricks
From the people who created Spark, we have another notebook solution for your machine learning projects called Databricks Workbench.


KNIME
KNIME Analytics Platform is the open source software for creating data science applications and services.


Dataiku
Dataiki Data Science (DSS) is a collaborative data science software workflow platform enabling data exploration, prototyping and delivery of analytical and machine learning solutions.

")
I’ve not included the tools like R Studio and Notebooks in this list as they don’t really address the aims listed above. But you will notice a lot of the above solutions are really Jupyter Notebooks. Most of these vendors have a long way to go to make the tasks of machine learning boring.
This list does not cover all available tools and workbenches, but it does list the most common one you will come across.
Data Sets for Analytics
When working with analytics, in whatever flavor, one of the key things you need is some data. But data comes in many different shapes and sizes, but where can you get some useful data, be it transactional, time-series, meta-data, analytical, master, categorical, numeric, regression, clustering, etc.
Many of the popular analytics languages have some data sets built into them. For example the R language comes pre-loaded with data sets and these can be accessed using
data()
but many of the R packages also come with data sets.
Similarly if you are using Python, it comes with some pre-loaded data sets and similarly many of the Python libraries have data sets build into them. For example scikit learn.
from sklearn import datasetsBut where else can you get data sets. There are lots and lots of website available with data sets and the list could be very long. The following is a list of, what I consider, the websites with the best data sets.
Microsoft Research Data Set: https://lnkd.in/eic-WUbQ
Azure Open Data: https://lnkd.in/g6J-zXxb
Amazon Data Set: https://lnkd.in/eRdduaaV
Google DataSet search: https://lnkd.in/egyh_MtM
Pew Research Center posts lots of survey data and other research data: https://lnkd.in/gUVS-8kS
Paperswithcode- the research papers are shared with code repo, often with datasets too: https://lnkd.in/ghpgxEbH
UCI Machine Learning Repository
Awesome Public Datasets Collection
Northern Ireland Public Open Data
Carnegie Mellon University Data Sets
Github List of Public Data Sets
Boston Housing Data Set and from here
ODSC – 25 picks of open data sets
NHS Open Data Sets – including prescriptions issued in England

Time Series Forecasting in Oracle – Part 1
Time-series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. In this blog post I’ll introduce what time-series analysis is, the different types of time-series analysis and introduce how you can do this using SQL and PL/SQL in Oracle Database. I’ll have additional blog posts giving more detailed examples of Oracle functions and how they can be used for different time-series data problems.
Time-series forecasting is the use of a model to predict future values based on previously observed/historical values. It is a form of regression analysis with additions to facilitate trends, seasonal effects and various other combinations.

Time-series forecasting is not an exact science but instead consists of a set of statistical tools and techniques that support human judgment and intuition, and only forms part of a solution. It can be used to automate the monitoring and control of data flows and can then indicate certain trends, alerts, rescheduling, etc., as in most business scenarios it is used for predict some future customer demand and/or products or services needs.
Typical application areas of Time-series forecasting include:
- Operations management: forecast of product sales; demand for services
- Marketing: forecast of sales response to advertisement procedures, new promotions etc.
- Finance & Risk management: forecast returns from investments
- Economics: forecast of major economic variables, e.g. GDP, population growth, unemployment rates, inflation; useful for monetary & fiscal policy; budgeting plans & decisions
- Industrial Process Control: forecasts of the quality characteristics of a production process
- Demography: forecast of population; of demographic events (deaths, births, migration); useful for policy planning
When working with time-series data we are looking for a pattern or trend in the data. What we want to achieve is the find a way to model this pattern/trend and to then project this onto our data and into the future. The graphs in the following image illustrate examples of the different kinds of scenarios we want to model.



Most time-series data sets will have one or more of the following components:
- Seasonal: Regularly occurring, systematic variation in a time series according to the time of year.
- Trend: The tendency of a variable to grow over time, either positively or negatively.
- Cycle: Cyclical patterns in a time series which are generally irregular in depth and duration. Such cycles often correspond to periods of economic expansion or contraction. Also know as the business cycle.
- Irregular: The Unexplained variation in a time series.
When approaching time-series problems you will use a combination of visualizations and time-series forecasting methods to examine the data and to build a suitable model. This is where the skills and experience of the data scientist becomes very important.
Oracle provided a algorithm to support time-series analysis in Oracle 18c. This function is called Exponential Smoothing. This algorithm allows for a number of different types of time-series data and patterns, and provides a wide range of statistical measures to support the analysis and predictions, in a similar way to Holt-Winters.

The first parameter for the Exponential Smoothing function is the name of the model to use. Oracle provides a comprehensive list of models and these are listed in the following table.
Check out my other blog posts on performing time-series analysis using the Exponential Smoothing function in Oracle Database. These will give more detailed examples of how the Oracle time-series functions, using the Exponential Smoothing algorithm, can be used for different time-series data problems. I’ll also look at example of the different configurations.
HiveML : Using SQL for ML on Big Data
It is widely recognised that SQL is one of the core languages that every data scientist needs to know. Not just know but know really well. If you are going to be working with data (big or small) you are going to use SQL to access the data. You may use some other tools and languages as part of your data science role, but for processing data SQL is king.
During the era of big data and hadoop it was all about moving the code to where the data was located. Over time we have seem a number of different languages and approaches being put forward to allow us to process the data in these big environments. One of the most common one is Spark. As with all languages there can be a large learning curve, and as newer languages become popular, the need to change and learn new languages is becoming a lot more frequent.
We have seen many of the main stream database vendors including machine learning in their databases, thereby allowing users to use machine learning using SQL. In the big data world there has been many attempts to do this, to building some SQL interfaces for machine learning in a big data environment.
One such (newer) SQL machine learning engine is called HiveMall. This will allow anyone with a basic level knowledge of SQL to quickly learn machine learning. Apache Hivemall is built to be a scalable machine learning library that runs on Apache Hive, Apache Spark, and Apache Pig.

Hivemall is currently at incubator stage under Apache and version 0.6 was released in December 2018.
I’ve a number of big data/hadoop environments in my home lab and build on a couple of cloud vendors (Oracle and AWS). I’ve completed the installation of Hivemall easily on my Oracle BigDataLite VM and my own custom build Hadoop environment on Oracle cloud. A few simple commands you will have Hivemall up and running. Initially installed for just Hive and then updated to use Spark.
Hivemall expands the analytical functions available in Hive, as well as providing data preparation and the typical range of machine learning functions that are necessary for 97+% of all machine learning use cases.
Download the hivemall-core-xxx-with-dependencies.jar file
# Setup Your Environment $HOME/.hiverc add jar /home/myui/tmp/hivemall-core-xxx-with-dependencies.jar; source /home/myui/tmp/define-all.hive;
This automatically loads all Hivemall functions every time you start a Hive session
# Create a directory in HDFS for the JAR hadoop fs -mkdir -p /apps/hivemall hdfs dfs -chmod -R 777 /apps/hivemall cp hivemall-core-0.4.2-rc.2-with-dependencies.jar hivemall-with-dependencies.jar hdfs dfs -put hivemall-with-dependencies.jar /apps/hivemall/ hdfs dfs -put hivemall-with-dependencies.jar /apps/hive/warehouse
You might want to create a new DB in Hive for your Hivemall work.
CREATE DATABASE IF NOT EXISTS hivemall;
USE hivemall;Then list all the Hivemall functions
show functions "hivemall.*"; +-----------------------------------------+--+ | tab_name | +-----------------------------------------+--+ | hivemall.add_bias | | hivemall.add_feature_index | | hivemall.amplify | | hivemall.angular_distance | | hivemall.angular_similarity | ...
Hivemall for ML using SQL is now up and running. Next step is to do try out the various analytical and ML functions.
Why Data Science projects fail
Over the past few weeks or months (maybe even years) I’ve had several conversations with various people about why Data Science (or whatever you want to call it) projects fail or never really get started.
Before we go any further perhaps we need to define what ‘fail’ means in these conversations. Typically fail means that the project doesn’t deliver what was hoped for, it got bogged down is some technical or political issues, it did not deliver useful results, and more typically it is run once (or a couple of times) and never run again. You get the idea.
The following points outline some of the most typical reasons why Data Science projects fail, but this is not an exhaustive list. This list is just some of the most typical reason.
- We need Big Data: It seems like everything that you read says you need Big Data for your data science project. Firstly what big data means to one person or company can be very different to what it means for another person/company. One possible definition is that it might include all the various social media and log type of data. If you don’t have all of this data then no big deal. You can still do data science projects. You have lots and lots of other data. The data that you generate every day for the general running of your business. You can use that. If you have some history of this data going back over a few months or a couple of years then even better (and most of you will say Yes I have that data). Work with the data that you already have, that you already understand, that you are already using, etc and use that data to see if you can gain extra insights that will have some value to your business (it needs to have value otherwise whats the point). Some people call this everyday type of data you have, ‘Small Data’. Big Data or Small Data are really bad terms. It is just Data. Let us work with data we already have and incrementally add in newer data (from your typical ‘Big Data’ sources) with each iteration of the data science project.
- We need Big Technology: This kind of follows on from the mistake of believing we need Big Data to do our data science projects. As most companies will be working with the data that they already have, and you will have various technology solutions in place to manage this data. Then do we really need Big Data Technology solutions for our Data Science projects? Technologies like Hadoop and everything that goes along with it. The simple answer is ‘No You Don’t’. Now don’t get me wrong. These technologies are important with it comes to managing Big Data, but you don’t needs these to perform your data science projects. Many, many companies both large and small are performing data science projects using their existing technology solutions and have perhaps just added some analytics tools to support their project using the data that they are already managing. Most companies have databases to store and manage their data. You can use your analytics software to work with the data in these database to analyse, model and predict. Any results that are produced can be easily integrated back into these databases and the results can then be used by various groups within your organisation. Use the technologies you have, that you understand, that you can use to the max, supplemented with some newer analytics software that works with all of these for your data science projects. (An example: one project I’ve worked on included a retail organisation for one of the largest countries in the work. I was working with 3 years of sales data. Is this big data? I was able to use my laptop to perform advanced analytics on all their data)
- Old School Data Science: Give me all your data, I’ll analyse it and tell you what is happening. Unfortunately this kind of phrases are still very common. They are common and considered out of date 20 years ago when I worked on my first data science project (it wasn’t called data science back then). If you do come across someone saying this to you, I would question their ability to deliver anything. If it was me, I would just say ‘No thank you’, and move onto someone else. You as a company will already know a lot of what is happening in your business, what data is currently being used for and any potential areas where you know advanced analytics and data science can help. You will know that the focus areas should be and how good or not your data is. You need someone who can help you to identify the key areas and what data science techniques can be used to help you to gain (a possible) greater insight into what is happening.
- No clear objective or business question/problem and no measurable outcomes: In a way this is very similar to the previous point. You don’t get into your car each morning and start driving, with the eventual hope that you arrive at work on time. No, you plan what you want to do (get to work), how you are going to get then (using your car) and when you want to get there by (your work start time). Using these you then plan out what is the best route you need to take to get to work, in the most efficient way you can, using your knowledge and experience of the road network, supplemented by traffic reports and making adjustments as necessary, to ensure that you get to work on time. This is exactly the same for data science projects. You need a good clear objective, that can be broken down into distinct problems, that will each require a specific set of advanced analytics to generate a measurable outcome. The measurable outcomes should allow you to measure if the advanced analytics actually gives you a valuable return. For example if you predict that you can increase sales by 3%, this sound good. But if the cost of implementing the solution is treating any the profit generated then you might decide that this solution is not worth continuing with.
- Not productionalising the outcomes: This point follows on from the previous two points. A lot of what you read and a lot of what I’ve seen is that Data Science looks are discovering some new (and actionable) insights. But that is where the discussion ends. As if a report is produced that makes a recommendation or a list of customers to target, and that is it. What happens to your data science project then. It really gets canned or you might be told that we will come back to it in a few months (and possibly a year) from now. This is not what you really want. Why? because when you finally remember to come back to review the project and to do another run, the people who where involved in the original project have moved on or are not available. It then become too difficult to start over again and that is when the data science project fails. I’ve used the word ‘productionalising’ (is that a real word?) What I mean by that is that we need to take our data science project and build it into our every day applications and processes. For example if we build a customer risk model for loans in a bank. This should be built into the application that captures the loan application by the customer. That way when the bank employee is entering the loan application they can be given live feedback. They can then use this live feedback to address any issues with the customer. What can be typical is that this is discovered some weeks later when the loan has already been approved. We need to automate the use of our data science work. Another example is fraud detection. I know of several companies who have fraud detection measures in place. It can take them 4-6 weeks to identify a potential fraud case that needs investigation. Using data science and building this into their transaction monitoring systems they can now detect potential fraud cases in near real time )no big data architectures being used). By automating it we get quicker response and take actions at the right time. The quicker we can react the more money we can make or save. This is an area that a lot of companies are now focusing on when they are looking at data science project as this is they way that they can get a quicker return on their investment in their data science projects.
- Very little senior management support: I think most of the data science projects are supported by senior management to some extent. The more successful the data science project the more involved the senior managers are and the more they understand of what these projects can potentially deliver. But with the ever changing and evolving world of IT most of the senior managers are very focused on the here and now, keeping the lights on, making sure their day-to-day applications are up and running, the backups and recovery processes are in place (and tested), and future proofing their application. It is well known that very little time and resources (human and money) are available for adding new functionality. Most of what I’ve mentioned is very IT related and perhaps the IT managers are not the most suitable people to sponsor data science projects. I’ve already some of the reasons but sometimes IT can get a bit caught up with the technology and trying to use the newest thing. Some of the most successful projects I’ve worked on have had senior managers from a business function. They will not be focused on the technology but on the processes around the data science project and how the outputs of the data science project can be used. The more focused they are on this the more successful the project will be. They will then act as the key to informing (and selling) the rest of the business on the success of the project. This in turn create more and more data scicene projects and will keep you busy for a long time to come
- Ticking the box: Unfortunately I’ve seen this in way too many companies. Board level or the senior management team have hear about data science and all the magic that is can produce. The message is then passed down through the organisation that we need to be doing more and more of this. A business unit is chosen as for the pilot project. The pilot is completed, successfully, and the good news message is fed back up the ladder. But that is when enthusiasm ends. We have done a data science project, it was successful and now lets move on to the next thing. I’ve seen pilot or POC project that have proven to potentially save $10+M a year with a cost of $100K per year, being canned. Yes I’ve been told this is fantastic, this is beyond our wildest dreams. Only for nothing else to happen.
- The data is no good: You need data, you need historical data. The more you have more more useful it will be for the data science project. But what if the data is of poor quality? How can this happen? Well it can happen very frequently. You may have applications that are poorly designed, that have a very poor data model, the staff are not trained correctly to ensure that good data gets entered, etc. etc. The list could go on and on. It is one thing for an application to capture data but if that data cannot be used for any meaningful purposes then it has very little value. Some companies have people hired that constantly inspect the data, assess the quality of the data and are then feeding back ideas on how to improve the quality of the data captured by the applications and also by the people inputting the data. Without good quality data then there is very little a data science project can do to magically convert it into good quality data. I’ve been in the situation where >90% of the data was unusable. We give them a list what improvements they needed to make and only come back to use then they have completed these and have at least 6 months of good quality data. We might be able to do something then. We never heard from them again. Also I get to talk to a lot of start ups who want to have data science build in from day one. These have very little ‘real’ data. Again I get to tell them come back to me when you have 6 months of data.
- Too much focus on descriptive analytics: Although descriptive analytics is an important step in the early stages of all data science projects, they is still a huge number of consulting and product companies who are promoting this as a data science project. Like I said descriptive analytics is an important step, but it doesn’t end there. It is just the beginning. When selecting a consulting or product company to partner with on your data science projects you need to ensure that they are offering more than just descriptive analytics. In a similar way to what I’ve mentioned in the points above, you need to look at how you can make use of these descriptive analytics and share them with the wider community in your company. But you also need to have some control over the proliferation of various visualisation tools. Descriptive analytics and visualisations is not data science or a major output of data science. It is only one part of a data science project and far more value outputs from a data science project can be achieved by using one or more of the advanced analytics methods that are available to you.
- Ignoring your BI/DW: Unfortunately when it comes to a lot of data science projects your have two very different approaches to working with the data. One approach seems to be that we will look at your data that is available in the transactional databases (and other data sources), we will then look at how to integrate and clean this data before getting onto the fund stuff of exploring and then performing the advanced analytics. This approach completely ignores the BI team and any data warehouse that might exist. If a data warehouse already exists then it probably contains all or most of the data you are going to use. Therefore you can avoid all that them spent integrating and cleaning the data. The data warehouse will have this done for you. Plus the data warehouse will have a lot more data than what the current transactional databases will contain. Please, Please, Please use the data in the data warehouse and you will find that you will save a lot of time on your data science project. In addition to the time saved you will have a lot more (possibly years of) data to work with. I always try to work with data warehouse data. When I do I can go back 5 years and build predictive models from back then. I can then roll these through various time periods and can easily measure how good the level of predictive I’m getting. I also get to see if there are any changes in the data and how they affect the models. Plus I also get to see how the various algorithms and their associated models change and evolve over time. This allows me to demonstrate to the customer how the use of data science and predictive models works with their data over the past 5 years. This build up confidence with the customer on what is being done and what can be achieved. In one case I was able to demonstrate that if they implemented my solution 5 years ago, they would have save $40+M in that time period. If I didn’t use the data warehouse I wouldn’t have been able to prove this. Needless to say the customer was very happy.
- Make up of team is wrong: You don’t need a team of PhDs: There has been lots written about what the make up of skills what your data science team should be. Back a few years ago all the talk was that you need to have people with PhDs maths, stats or related states. Plus all you needed to do was to hire one of these. We all know that this is not true but was part of the rubbish that people were talking about. We all know that you really need a team of people and perhaps you already have some of these people already employed in your company already. You have database people, you have ETL people, you have data integration people, you have data analysts, you have project managers, you have business analysts, you have domain experts, etc. How many of those people have PhDs or require a PhD to do their job. But perhaps you don’t have people with the skills of applying advanced analytic techniques to your data and business problems. Perhaps it is these people who you really need the most. Do these people really need to have a PhD? No they don’t. You need someone who knows and understands the various techniques and most importantly how to use these to solve business problems. All too often people try to show off about using a particular technique or parameter setting, or a particular formula, or graphic technique, or using a certain language over another, or what library or package is the best. Don’t engage in this. Look for people that can apply the correct technique or combination of techniques to your business problems. But despite what I said in the first two point, as your data management requirements grow you are going to need some addition people with some big data technologies.
- Communication: being able to explain what data science can do, what it is producing and relating that back to the business. Being able to work with the management team, end users and all involved to show and explain what and how the data science project can do to support their work. Most technical people are not good at this. Bus some people are and these are a very valuable resource as part of your data science team or are keen supporter of what data science can do and how it can be used to help the business developed new and interesting actionable insights.
- The output is not a report => You need to operationise/productionalise the data science project: See the point above on productionalising your data science work. The outputs should not be a report or a list of some form. With proper planning data science can become a central to all the operational systems in your company. They can help you make better and quicker decisions on how you interact with your customers, improve the efficiencies of your processes, etc. The list goes on and on. All data science projects are cyclical in nature. For example you developer a churn prediction system. You use this to interact with your customers. You are trying to change or alter their behaviour and this in turn changes them as a customer. This in turn affect the churn prediction system. It will no longer be as effective. So you will need to update it on a semi-regular basis. This could be every 3, 4, 6, or 12 months. It all depends. You can build in checks into your productionalised data science projects to detect when the predictive models need updating. This in turn helps your data science team to be more productive, with quicker turn around times of each iteration. Also with each iteration you can look to see if new data is available for you to include and use. Maybe at this point some of your big data sources are coming online with some useful data.
So when looking to start a Data Science project it is important to know a few things before you start. The following attempts to use the 5 W’s to try explains these.
- what you are doing
- why you are doing it
- who it is for and what they will gain from it
- where will it be used within your applications/processes
- when you are going to commence the project and how it will fit into strategic goals of your organisation
There has been plenty written about what magic Data Science projects will produce and bring to your organisation. You need to be careful of people who only talk about the magic. You also need to understand that it may not work or deliver what you are lead to believe. In all the projects I’ve worked on we have had some amazing results. But in one or two projects we have had results that where only a percentage or two better than what they are already doing.
Perhaps I need to write another blog post on ‘Why Data Science projects succeed’, and this will only be based on what I’ve experienced (in the real-world).
Like I said at the beginning, this is not an exhaustive list. There are many more and I’m sure you will have a few of your own. These are the typical reasons that I’ve come across in my 20 years of doing these kind of projects and long before the term data science existed.
PMML in Oracle Data Mining
PMML (Predictive Model Markup Langauge) is an XML formatted output that defines the core elements and settings for your Predictive Models. This XML formatted output can be used to migrate your models from one data mining or predictive modelling tool to another data mining or predictive modelling tool, such as Oracle.
Using PMML to migrate your models from one tool to another allows for you to use the most appropriate tools for developing your models and then allows them to be imported into another tool that will be used for deploying your predictive models in batch or real-time mode. In particular the ability to use your Predictive Model within your everyday applications enables you to work in the area of Automatic or Prescriptive Analytics. Oracle Data Mining and the Oracle Database are ideal or even the best possible tools to allow for Automatic and Prescriptive Analytics for your transa
PMML is an XML based standard specified by the Data Mining Group
Oracle Data Mining supports the importing of PMML models that are compliant with version 3.1 of the standard and for Regression Models only. The regression models can be for linear regression or binary logistic regression.
The Data Mining Group Archive webpage have a number of sample PMML files for you to download and then to load into your Oracle database.
To Load the PMML file into your Oracle Database you can use the DBMS_DATA_MINING.IMPORT_MODEL function. I’ve given examples of how you can use this function to import an Oracle Data Mining model that was exported using the EXPORT_MODEL function.
The syntax of the IMPORT_MODEL function when importing a PMML file is the following
DBMS_DATA_MINING.IMPORT_MODEL (
model_name IN VARCHAR2,
pmmldoc IN XMLTYPE
strict_check IN BOOLEAN DEFAULT FALSE);
The following example shows how you can load the version 3.1 Logistic Regression PMML file from the Data Mining Group archive webpage
![]()
BEGIN
dbms_data_mining.IMPORT_MODEL (‘PMML_MODEL',
XMLType (bfilename (‘IMPORT_DIR', 'sas_3.1_iris_logistic_reg.xml'),
nls_charset_id ('AL32UTF8')
));
END;
This example uses the default value for STRICT_CHECK as FALASE. In this case if there are any errors in the PMML structure then these will be ignored and the imported model may contain “features” that may make it perform in a slightly odd manner.
PMML in Oracle Data Mining
PMML (Predictive Model Markup Langauge) is an XML formatted output that defines the core elements and settings for your Predictive Models. This XML formatted output can be used to migrate your models from one data mining or predictive modelling tool to another data mining or predictive modelling tool, such as Oracle.
Using PMML to migrate your models from one tool to another allows for you to use the most appropriate tools for developing your models and then allows them to be imported into another tool that will be used for deploying your predictive models in batch or real-time mode. In particular the ability to use your Predictive Model within your everyday applications enables you to work in the area of Automatic or Prescriptive Analytics. Oracle Data Mining and the Oracle Database are ideal or even the best possible tools to allow for Automatic and Prescriptive Analytics for your transa
PMML is an XML based standard specified by the Data Mining Group
Oracle Data Mining supports the importing of PMML models that are compliant with version 3.1 of the standard and for Regression Models only. The regression models can be for linear regression or binary logistic regression.
The Data Mining Group Archive webpage have a number of sample PMML files for you to download and then to load into your Oracle database.
To Load the PMML file into your Oracle Database you can use the DBMS_DATA_MINING.IMPORT_MODEL function. I’ve given examples of how you can use this function to import an Oracle Data Mining model that was exported using the EXPORT_MODEL function.
The syntax of the IMPORT_MODEL function when importing a PMML file is the following
DBMS_DATA_MINING.IMPORT_MODEL (
model_name IN VARCHAR2,
pmmldoc IN XMLTYPE
strict_check IN BOOLEAN DEFAULT FALSE);
The following example shows how you can load the version 3.1 Logistic Regression PMML file from the Data Mining Group archive webpage
BEGIN
dbms_data_mining.IMPORT_MODEL (‘PMML_MODEL',
XMLType (bfilename (‘IMPORT_DIR', 'sas_3.1_iris_logistic_reg.xml'),
nls_charset_id ('AL32UTF8')
));
END;
This example uses the default value for STRICT_CHECK as FALASE. In this case if there are any errors in the PMML structure then these will be ignored and the imported model may contain “features” that may make it perform in a slightly odd manner.
Viewing Models Details for Decision Trees using SQL
When you are working with and developing Decision Trees by far the easiest way to visualise these is by using the Oracle Data Miner (ODMr) tool that is part of SQL Developer.
Developing your Decision Tree models using the ODMr allows you to explore the decision tree produced, to drill in on each of the nodes of the tree and to see all the statistics etc that relate to each node and branch of the tree.
But when you are working with the DBMS_DATA_MINING PL/SQL package and with the SQL commands for Oracle Data Mining you don’t have the same luxury of the graphical tool that we have in ODMr. For example here is an image of part of a Decision Tree I have and was developed using ODMr.
What if we are not using the ODMr tool? In that case you will be using SQL and PL/SQL. When using these you do not have luxury of viewing the Decision Tree.
So what can you see of the Decision Tree? Most of the model details can be used by a variety of functions that can apply the model to your data. I’ve covered many of these over the years on this blog.
For most of the data mining algorithms there is a PL/SQL function available in the DBMS_DATA_MINING package that allows you to see inside the models to find out the settings, rules, etc. Most of these packages have a name something like GET_MODEL_DETAILS_XXXX, where XXXX is the name of the algorithm. For example GET_MODEL_DETAILS_NB will get the details of a Naive Bayes model. But when you look through the list there doesn’t seem to be one for Decision Trees.
Actually there is and it is called GET_MODEL_DETAILS_XML. This function takes one parameter, the name of the Decision Tree model and produces an XML formatted output that contains the attributes used by the model, the overall model settings, then for each node and branch the attributes and the values used and the other statistical measures required for each node/branch.
The following SQL uses this PL/SQL function to get the Decision Tree details for model called CLAS_DT_1_59.
SELECT dbms_data_mining.get_model_details_xml(‘CLAS_DT_1_59’)
FROM dual;
If you are using SQL Developer you will need to double click on the output column and click on the pencil icon to view the full listing.
Nothing too fancy like what we get in ODMr, but it is something that we can work with.
If you examine the XML output you will see references to PMML. This refers to the Predictive Model Markup Language (PMML) and this is defined by the Data Mining Group (www.dmg.org). I will discuss the PMML in another blog post and how you can use it with Oracle Data Mining.
Changing REVERSE Transformations in Oracle Data Miner
In my previous blog post I showed you how you can have a look at the transformations that the Automatic Data Preparation (ADP) feature of Oracle Data Mining produces. I also gave some example of the different types of ADF that are performed for different algorithms.
One of the features of the transformations produced is that it will generate a REVERSE_EXPRESSION. This will take the scored results and apply the inverse of the transformation that was performed when the data was being prepared for input to the algorithm.
Somethings you may want to have the scored data returned in a slightly different ways or labeled in a slightly different way.
In this blog post I will show you how to define an alternative REVERSE_EXPRESSION for an attribute.
The function we need to use for this is the ALTER_REVERSE_EXPRESSION procedure that is part of the DBMS_DATA_MINING package.
When we score data for a typical classification problem we typically use 0 (zero) and 1 to be the target variable values. But what if we wanted the output from our classification model to label the scored data slighted differently.
In this case we can use the ALTER_REVERSE_EXPRESSION procedure to define the new values. What if we wanted the zero to be labeled as NO and the 1 as YES. In this case we can use the following.
BEGIN
dbms_data_mining.alter_reverse_expression(
model_name => ‘CLAS_NB_1_59’,
expression => ‘decode(affinity_card, ”1”, ”YES”, ”NO”)’,
attribute_name => ‘AFFINITY_CARD’);
END;
When we view the transformations for our data mining model we can now see the transformation.
![]()
Now when we score our data the predicted target variable will now have our newly defined values.
SELECT cust_id,
PREDICTION(CLAS_NB_1_59 USING *) PRED
FROM mining_data_apply_v
FETHC FIRST 5 ROWS ONLY;

You can see that this is a very powerful feature and allows use to turn the scored data values is a different way to make them more useful. This is particularly the case as we work towards a more Automatic type of Predictive Analytics.
ODM : View Transformations generated by Automatic Data Prepreparation
A very powerful feature of Oracle Data Mining and one that I think does not get enough notice is called Automatic Data Preparation.
Data Preparation is one of the most time consuming, repetitive and boring parts of the work that a Data Miner or Data Scientist performs as part of their daily tasks. Apart from gathering the data, integrating the data, getting the data into the required formation the most interesting part of the work is with feature engineering.
Then you have all the other boring data preparation tasks of how to handle missing data, type conversion, binning, normalization, outlier treatment etc.
With Automatic Data Preparation (ADP) in Oracle Data Mining you can let Oracle work all of these things out for you and to perform all the necessary coding and to store all of this coding as part of the in-database data mining model.
This is Fantastic. This ADP feature can same you hours and in some cases days of effort.
But (there is always a but 🙂 ) what if you are a bit unsure if the transformations that are being performed are exactly what you would wanted. Maybe you would like to see what Oracle is doing and depending on this you can do it a different way.
The first step is to examine the transformations that are generated by stored as part of the in-database data mining model. The DBMS_DATA_MINING package has a function called GET_MODEL_TRANSFORMATIONS. When you query this function, passing in the name of the data mining model, you will get returned the list of transformations that have been applied to each model.
In the following example a GLM model was created using the Oracle Data Miner tool (that is part of SQL Developer). When you use Oracle Data Miner, ADP is automatically turned on.
The following query calls the GET_MODEL_TRANSFORMATIONS function with the data mining model called CLAS_GLM_1_59/.
SELECT * FROM TABLE(DBMS_DATA_MINING.GET_MODEL_TRANSFORMATIONS(‘CLAS_GLM_1_59’));
The following image contains the output generated by this query.

When you look at the data under the EXPRESSION column we get to see what the ADP did to the data. In most of the cases there are just some simple data clean-up being performed and formatting for getting the data ready for input into the algorithm.
If we now look at the Naive Bayes model for the same data set we get a very different sent of transformations being listed under the EXPRESSION column.
SELECT * FROM TABLE(DBMS_DATA_MINING.GET_MODEL_TRANSFORMATIONS(‘CLAS_NB_1_59’));

Now we get to see some of the data binning that ADP performs and is required for input to the Naive Bayes algorithm. You will also notices that we also have some transformations in the REVERSE_EXPRESSION column. These are the inverse or reverse of the transformation that was generated in the EXPRESSION column.
I will let you explore the data transformations that are produced by ADP for the SVM and Decision Tree algorithms.
I will show you how you change the reverse expression in my next blog post, as there are times when you might want the data to be presented slightly differently after the model has been run to score your data.
To get more details of what Automatic Data Preparation is performed for each data mining algorithm you can check out this link in the 11g documentaion. This section seems to be missing from the online 12c documentation.
- ← Previous
- 1
- 2
- 3
- 4
- Next →

You must be logged in to post a comment.