
Data Science
Exploring Database trends using Python pytrends (Google Trends)
A little word of warning before you read the rest of this post. The examples shown below are just examples of what is possible. It isn’t very scientific or rigorous, so don’t come complaining if what is shown doesn’t match your knowledge and other insights. This is just a little fun to see what is possible. Yes a more rigorous scientific study is needed, and some attempts at this can be seen at DB-Engines.com. Less scientific are examples shown at TOPDB Top Database index and that isn’t meant to be very scientific.
After all of that, here we go 🙂
pytrends is a library providing an API to Google Trends using Python. The following examples show some ways you can use this library and the focus area I’ll be using is Databases. Many of you are already familiar with using Google Trends, and if this isn’t something you have looked at before then I’d encourage you to go have a look at their website and to give it a try. You don’t need to run Python to use it. For example, here is a quick example taken from the Google Trends website. Here are a couple of screen shots from Google Trends, comparing Relational Database to NoSQL Database. The information presented is based on what searches have been performed over the past 12 months. Some of the information is kind of interesting when you look at the related queries and also the distribution of countries.


To install pytrends use the pip command
pip3 install pytrends
As usual it will change the various pendent libraries and will update where necessary. In my particular case, the only library it updated was the version of pandas.
You do need to be careful of how many searches you perform as you may be limited due to Google rate limits. You can get around this by using a proxy and there is an example on the pytrends PyPi website on how to get around this.
The following code illustrates how to import and setup an initial request. The pandas library is also loaded as the data returned by pytrends API into a pandas dataframe. This will make it ease to format and explore the data.
import pandas as pd
from pytrends.request import TrendReq
pytrends = TrendReq()
The pytrends API has about nine methods. For my example I’ll be using the following:
- Interest Over Time: returns historical, indexed data for when the keyword was searched most as shown on Google Trends’ Interest Over Time section.
- Interest by Region: returns data for where the keyword is most searched as shown on Google Trends’ Interest by Region section.
- Related Queries: returns data for the related keywords to a provided keyword shown on Google Trends’ Related Queries section.
- Suggestions: returns a list of additional suggested keywords that can be used to refine a trend search.
Let’s now explore these APIs using the Databases as the main topic of investigation and examining some of the different products. I’ve used the db-engines.com website to select the top 5 databases (as per date of this blog post). These were:
- Oracle
- MySQL
- SQL Server
- PostgreSQL
- MongoDB
I will use this list to look for number of searches and other related information. First thing is to import the necessary libraries and create the connection to Google Trends.
import pandas as pd
from pytrends.request import TrendReq
pytrends = TrendReq()
Next setup the payload and keep the timeframe for searches to the past 12 months only.
search_list = ["Oracle", "MySQL", "SQL Server", "PostgreSQL", "MongoDB"] #max of 5 values allowed
pytrends.build_payload(search_list, timeframe='today 12-m')
We can now look at the the interest over time method to see the number of searches, based on a ranking where 100 is the most popular.
df_ot = pd.DataFrame(pytrends.interest_over_time()).drop(columns='isPartial')
df_ot

and to see a breakdown of these number on an hourly bases you can use the get_historical_interest method.
pytrends.get_historical_interest(search_list)
Let’s move on to exploring the level of interest/searches by country. The following retrieves this information, ordered by Oracle (in decending order) and then select the top 20 countries. Here we can see the relative number of searches per country. Note these doe not necessarily related to the countries with the largest number of searches
df_ibr = pytrends.interest_by_region(resolution='COUNTRY') # CITY, COUNTRY or REGION
df_ibr.sort_values('Oracle', ascending=False).head(20)

Visualizing data is always a good thing to do as we can see a patterns and differences in the data in a clearer way. The following takes the above query and creates a stacked bar chart.
import matplotlib
from matplotlib import pyplot as plt
df2 = df_ibr.sort_values('Oracle', ascending=False).head(20)
df2.reset_index().plot(x='geoName', y=['Oracle', 'MySQL', 'SQL Server', 'PostgreSQL', 'MongoDB'], kind ='bar', stacked=True, title="Searches by Country")
plt.rcParams["figure.figsize"] = [20, 8]
plt.xlabel("Country")
plt.ylabel("Ranking")

We can delve into the data more, by focusing on one particular country and examine the google searches by city or region. The following looks at the data from USA and gives the rankings for the various states.
pytrends.build_payload(search_list, geo='US')
df_ibr = pytrends.interest_by_region(resolution='COUNTRY', inc_low_vol=True)
df_ibr.sort_values('Oracle', ascending=False).head(20)
df2.reset_index().plot(x='geoName', y=['Oracle', 'MySQL', 'SQL Server', 'PostgreSQL', 'MongoDB'], kind ='bar', stacked=True, title="test")
plt.rcParams["figure.figsize"] = [20, 8]
plt.title("Searches for USA")
plt.xlabel("State")
plt.ylabel("Ranking")


We can find the top related queries and and top queries including the names of each database.
search_list = ["Oracle", "MySQL", "SQL Server", "PostgreSQL", "MongoDB"] #max of 5 values allowed
pytrends.build_payload(search_list, timeframe='today 12-m')
rq = pytrends.related_queries()
rq.values()
#display rising terms
rq.get('Oracle').get('rising')
We can see the top related rising queries for Oracle are about tik tok. No real surprise there!

and the top queries for Oracle included:
rq.get('Oracle').get('top')

This was an interesting exercise to do. I didn’t show all the results, but when you explore the other databases in the list and see the results from those, and then compare them across the five databases you get to see some interesting patterns.
Pre-build Machine Learning Models
Machine learning has seen widespread adoption over the past few years. In more recent times we have seem examples of how the models, created by the machine learning algorithms, can be shared. There have been various approaches to sharing these models using different model interchange languages. Some of these have become more or less popular over time, for example a few years ago PMML was very popular, and in more recent times ONNX seems to popular. Who knows what it will be next year or in a couple of years time.
With the increased use of machine learning models and the ability to share them, we are now seeing other uses of them. Typically the sharing of models involved a company transferring a model developed by the data scientists in their lab environment, to DevOps teams who then deploy the model into the production environment. This has developed a new are of expertise of MLOps or AIOps.
The languages and tools used by the data scientists in the lab environment are different to the languages used to deploy applications in production. The model interchange languages can be used take the model parameters, algorithm type and data transformations, etc and map these into the interchange language. The production environment would read this interchange object and apply it to the production language. In such situations the models will use the algorithms already coded in the production language. For example, the lab environment could be using Python. But the product environment could be using C, Java, Go, etc. Python is an interpretative language and in a lot of cases is not suitable for real-time use in a production environment, due to speed and scalability issues. In this case the underlying algorithm of the production language will be used and not algorithm used in the lab. In theory the algorithms should be the same. For example a decision tree algorithm using Gini Index in one language should function in the same way in another language. We all know there can be a small to a very large difference between what happens in theory and how it works in practice. Different language and different developers will do things slightly differently. This means there will be differences between the accuracy of the models developed in the lab versus the accuracy of the (same) model used in production. As long as everyone is aware of this, then everything will be ok. But it will be important task, for the data science team, to have some measurements of these differences.

Moving on a little this a little, we are now seeing some other developments with the development and sharing of machine learning models, and the use of these open model interchange languages, like ONNX, makes this possible.
We are now seeing people making their machine learning models available to the wider community, instead of keeping them within their own team or organization.
Why would some one do this? why would they share their machine learning model? It’s a bit like the picture to the left which comes from a very popular kids programme on the BBC called Blue Peter. They would regularly show some craft projects for kids to work on at home. They would never show all the steps needed to finish the project and would end up showing us “one I made earlier”. It always looked perfect and nothing like what they tried to make in the studio and nothing like my attempt.
But having pre-made machine learning models is now a thing. There ware lots of examples of these and for example the ONNX website has several pre-trained models ready for you to use. These cover various examples for image classification, object detection, machine translation and comprehension, language modeling, speech and audio processing, etc. More are being added over time.
Most of these pre-trained models are based on defined data sets and problems and allows others to see what they have done, and start building upon their work without the need to go through the training and validating phase.
Could we have something like this in the commercial world? Could we have pre-trained machine learning models being standardized and shared across different organizations? Again the in-theory versus in-practical terms apply. Many organizations within a domain use the same or similar applications for capturing, storing, processing and analyzing their data. In this case could the sharing of machine learning models help everyone be more competitive or have better insights and discoveries from their data? Again the difference between in-theory versus in-practice applies.
Some might remember in the early days of Data Warehousing we used to have some industry (dimensional) models, and vendors and consulting companies would offer their custom developed industry models and how to populate these. In theory these were supposed to help companies to speed up their time to data insights and save money. We have seem similar attempts at doing similar things over the decades. But the reality was most projects ended up being way more expensive and took way too long to deploy due to lots of technical difficulties and lots of differences in the business understand, interpretation and deployment of the underlying applications. The pre-built DW model was generic and didn’t really fit in with the business needs.
Although we are seeing more and more pre-trained machine learning models appearing on the market. Many vendors are offering pre-trained solutions. But can these really work. Some of these pre-trained models are based on certain data preparation, using one particular machine learning model and using only one particular evaluation matric. As with the custom DW models of twenty years ago, pre-trained ML models are of limited use.
Everyone is different, data is different, behavior is different, etc. the list goes on. Using the principle of the “No Free Lunch” theorem, although we might be using the same or similar applications for capturing, storing, processing and analysing their data, the underlying behavior of the data (and the transactions, customers etc that influence that), will be different, the marketing campaigns will be different, business semantics may be different, general operating models will be different, etc. Based on “No Free Lunch” we need to explore the data using a variety of different algorithms, to determine what works for our data at this point in time. The behavior of the data (and business influences on it) keep on changing and evolving on a daily, weekly, monthly, etc basis. A great example of this but in a more extreme and rapid rate of change happened during the COVID pandemic. Most of the machine learning models developed over the preceding period no longer worked, the models developed during the pandemic have a very short life span, and it will take some time before “normal” will return and newer models can be built to represent the “new normal”
Principal Component Analysis (PCA) in Oracle
Principal Component Analysis (PCA), is a statistical process used for feature or dimensionality reduction in data science and machine learning projects. It summarizes the features of a large data set into a smaller set of features by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data’s variation as possible. There are lots of resources that goes into the mathematics behind this approach. I’m not going to go into that detail here and a quick internet search will get you what you need.
PCA can be used to discover important features from large data sets (large as in having a large number of features), while preserving as much information as possible.
Oracle has implemented PCA using Sigular Value Decomposition (SVD) on the covariance and correlations between variables, for feature extraction/reduction. PCA is closely related to SVD. PCA computes a set of orthonormal bases (principal components) that are ranked by their corresponding explained variance. The main difference between SVD and PCA is that the PCA projection is not scaled by the singular values. The extracted features are transformed features consisting of linear combinations of the original features.
When machine learning is performed on this reduced set of transformed features, it can completed with less resources and time, while still maintaining accuracy.
Algorithm Name in Oracle using
Mining Model Function = FEATURE_EXTRACTION
Algorithm = ALGO_SINGULAR_VALUE_DECOMP
(Hyper)-Parameters for algorithms
- SVDS_U_MATRIX_OUTPUT : SVDS_U_MATRIX_ENABLE or SVDS_U_MATRIX_DISABLE
- SVDS_SCORING_MODE : SVDS_SCORING_SVD or SVDS_SCORING_PCA
- SVDS_SOLVER : possible values include SVDS_SOLVER_TSSVD, SVDS_SOLVER_TSEIGEN, SVDS_SOLVER_SSVD, SVDS_SOLVER_STEIGEN
- SVDS_TOLERANCE : range of 0…1
- SVDS_RANDOM_SEED : range of 0…4294967296 (!)
- SVDS_OVER_SAMPLING : range of 1…5000
- SVDS_POWER_ITERATIONS : Default value 2, with possible range of 0…20
Let’s work through an example using the MINING_DATA_BUILD_V data set that comes with Oracle Data Miner.
First step is to define the parameter settings for the algorithm. No data preparation is needed as the algorithm takes care of this. This means you can disable the Automatic Data Preparation (ADP).
-- create the parameter table CREATE TABLE svd_settings ( setting_name VARCHAR2(30), setting_value VARCHAR2(4000)); -- define the settings for SVD algorithm BEGIN INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_singular_value_decomp); -- turn OFF ADP INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_off); -- set PCA scoring mode INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.svds_scoring_mode, dbms_data_mining.svds_scoring_pca); INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_shift_2dnum, dbms_data_mining.prep_shift_mean); INSERT INTO svd_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_scale_2dnum, dbms_data_mining.prep_scale_stddev); END; /
You are now ready to create the model.
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'SVD_MODEL',
mining_function => dbms_data_mining.feature_extraction,
data_table_name => 'mining_data_build_v',
case_id_column_name => 'CUST_ID',
settings_table_name => 'svd_settings');
END;
When created you can use the mining model data dictionary views to explore the model and to explore the specifics of the model and the various MxN matrix created using the model specific views. These include:
- DM$VESVD_Model : Singular Value Decomposition S Matrix
- DM$VGSVD_Model : Global Name-Value Pairs
- DM$VNSVD_Model : Normalization and Missing Value Handling
- DM$VSSVD_Model : Computed Settings
- DM$VUSVD_Model : Singular Value Decomposition U Matrix
- DM$VVSVD_Model : Singular Value Decomposition V Matrix
- DM$VWSVD_Model : Model Build Alerts
Where the S, V and U matrix contain:
- U matrix : consists of a set of ‘left’ orthonormal bases
- S matrix : is a diagonal matrix
- V matrix : consists of set of ‘right’ orthonormal bases
These can be explored using the following
-- S matrix select feature_id, VALUE, variance, pct_cum_variance from DM$VESVD_MODEL; -- V matrix select feature_id, attribute_name, value from DM$VVSVD_MODEL order by feature_id, attribute_name; -- U matrix select feature_id, attribute_name, value from DM$VVSVD_MODEL order by feature_id, attribute_name;
To determine the projections to be used for visualizations we can use the FEATURE_VALUES function.
select FEATURE_VALUE(svd_sh_sample, 1 USING *) proj1,
FEATURE_VALUE(svd_sh_sample, 2 USING *) proj2
from mining_data_build_v
where cust_id <= 101510
order by 1, 2;
Other algorithms available in Oracle for feature extraction and reduction include:
- Non-Negative Matrix Factorization (NMF)
- Explicit Semantic Analysis (ESA)
- Minimum Description Length (MDL) – this is really feature selection rather than feature extraction
k-Fold and Repeated k-Fold Cross Validation in Python
When it comes to evaluation the performance of a machine learning model there are a number of different approaches. Plus there are as many different view points on what is the best or better evaluation metric to use.
One of the common approaches is to use k-Fold cross validation. This divides the data in to ‘k‘ non-overlapping parts (or Folds). One of these part/Folds is used for hold out testing and the remaining part/Folds (k-1) are used to train and create a model. This model is then used to applied or fitted to the hold-out ‘k‘ part/Fold. This process is repeated across all the ‘k‘ parts/Folds until all the data has been used. The results from applying or fitting the model are aggregated and the mean performance is report.
Traditionally, ‘k‘ is set to 10 and will be the default value in most/all languages, libraries, packages and application. This number can be changed to anything you want. Most reports indicated a value of between 5 and 10, as these seem to indicate results that don’t suffer from bias or variance.
Let’s take a look at an example of using k-Fold Cross Validation using Scikit-Learning library. First step is to prepare the data.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
bank_file = "/.../4-Datasets/bank-additional-full.csv"
# import dataset
df = pd.read_csv(bank_file, sep=';',)
# get basic details of df (num records, num features)
df.shape
print('Percentage per target class ')
df['y'].value_counts()/len(df) #calculate percentages
#Data Clean up
df = df.drop('duration', axis=1) #this is highly correlated to target variable
df_new = pd.get_dummies(df) #simple and easy approach for categorical variables
df_new.describe()
df['y'] = df['y'].map({'no':0, 'yes':1}) # binary encoding of class label
#split data set into input variables and target variables
## create separate dataframes for Input features (X) and for Target feature (Y)
X_train = df_new.drop('y', axis=1)
Y_train = df_new['y']
Now we can perform k-fold cross valuation.
#load scikit-learn k-fold cross-validation
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
#setup for k-Fold Cross Validation
cv = KFold(n_splits=10, shuffle=True, random_state=1)
#n_splits = number of k-folds
#shuffle = shuffles data set prior to split
#radnom_state = seed for (pseydo)random number generator
#define model
model = LogisticRegression()
#create model, perform cross validation and evaluate model
scores = cross_val_score(model, X_train, Y_train, scoring='accuracy', cv=cv, n_jobs=-1)
#performance result
print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
We can see from the above example the model is evaluated across 10 folds, giving the accuracy score for each of these. The mean of these 10 accuracy scores is calculated along with the standard deviation, which in this example is very small. You may have slightly different results and this will vary from data set to data set.
The results from k-fold can be nosy, as in each time the code is run a slightly different result may be achieved. This is due to having differing splits of the data set into the k-folds. The model accuracy can vary between each execution and it can be difficult to determine which iteration of the model should be used.
One way to address this possible noise is to estimate the model accurary/performance based on running k-fold a number of times and calculating the performance across all the repeats. This approach is called Repeated k-Fold Cross-Validation. Yes there is a computation cost for performing this approach, and it therefore suited to datasets of smaller scale. In most scenarios having data sets up to 1M records/cases is possible, and depending on the hardware and memory, it can scale to many times that and still be relatively quick to run.
[a small data set for one person could be another persons Big Data set!]
How many repeats should be performed? It kind of depends on how noisy the data is, but in a similar way of having ten as a default value for k, the number of repeats default is ten. Although the typical default is ten, but can be adjusted to say 5, but some testing/experimentation is needed to determine a suitable value.
Building upon the k-fold example code given previously, the following shows can example of using the Repeated k-Fold Cross Validation.
#Repeated k-Fold Cross Validation
#load the necessary libraries
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import RepeatedKFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
#using the same data set created for k-Fold => X_train, Y_train
#Setup and configure settings for Repeated k-Fold CV (k-folds=10, repeats=10)
rcv = RepeatedKFold(n_splits=10, n_repeats=10, random_state=1)
#define model
model = LogisticRegression()
#create model, perform Repeated CV and evaluate model
scores = cross_val_score(model, X_train, Y_train, scoring='accuracy', cv=rcv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
[New Book] 97 Things about Data Ethics in Data Science – Collective Wisdom from the Experts
 Some months ago I was approached about being part and contributing to a new book on Data Ethics for Data Science. It is now available to purchase on Amazon (and elsewhere), and this book now becomes the Sixth book that I’ve either solely or co-written. Check out my all my books here.
Some months ago I was approached about being part and contributing to a new book on Data Ethics for Data Science. It is now available to purchase on Amazon (and elsewhere), and this book now becomes the Sixth book that I’ve either solely or co-written. Check out my all my books here.
This has been an area I’ve been working in for some time now, in both research and assisting companies. I was able to make a couple of contributions to this book, and there has been great contributions from (other) global experts in Data Science and Data Ethics, and has been edited by Bill Franks.
Most of the high-profile cases of real or perceived unethical activity in data science aren’t matters of bad intent. Rather, they occur because the ethics simply aren’t thought through well enough. Being ethical takes constant diligence, and in many situations identifying the right choice can be difficult.
In this in-depth book, contributors from top companies in technology, finance, and other industries share experiences and lessons learned from collecting, managing, and analyzing data ethically. Data science professionals, managers, and tech leaders will gain a better understanding of ethics through powerful, real-world best practices.
The book is available in paper back and kindle formats and is published by O’Reilly Press.
You might be interested in my previous book on Data Science, part of the MIT Press Essentials Series. This book has been a Best Seller in 2018 and 2019 on Amazon.

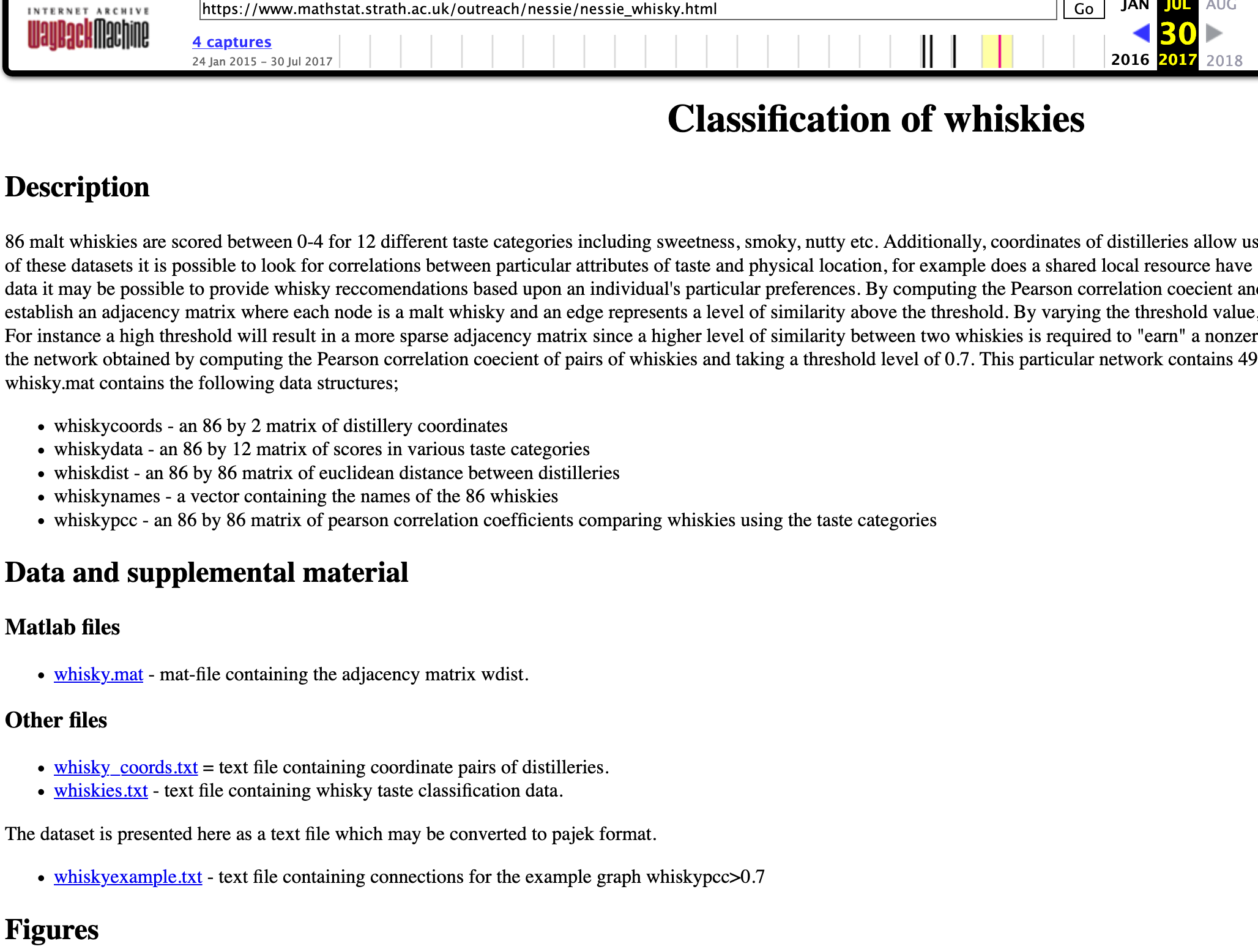
Irish Whiskey Distilleries Data Set
I’ve been building some Irish Whiskey data sets, and the first of these data sets contains details of all the Whiskey Distilleries in Ireland. This page contains the following:
- Table describing the attributes/features of the data set
- Data set, in a scroll able region
- Download data set in different formats
- Map of the Distilleries
- Subscribe to Twitter List containing these Distilleries, and some Twitter Hash Tags
- How to send me updates, corrections and details of Distilleries I’ve missed
If you use this data set (and my other data sets) make sure to add a reference back to data set webpage. Let me know if you use the data set is an interesting way, share the details with me and I’ll share it on my blog and social media for you.
This data set will have it’s own Irish Distilleries webpage and all updates to the data set and other information will be made there. Check out that webpage for the latest version of things.
Data Set Description
Data set contains 45 Distilleries.
| ATTRIBUTE NAME | DESCRIPTION |
| Distillery | Name of the Distillery |
| County | County / Area where distillery is located |
| Address | Full address of the distillery |
| EIRCODE | EirCode for distillery in Ireland. Distilleries in Northern Ireland will not have an EIRCODE |
| NI_Postcode | Post code of distilleries located in Northern Ireland |
| Tours | Does the distillery offer tours to visitors (Yes/No) |
| Web_Site | Web site address |
| The twitter name of the distillery | |
| Lat | Latitude for the distillery |
| Long | Longitude for the distillery |
| Notes_Parent_Company | Contains other descriptive information about the distillery, founded by, parent company, etc. |
Data Set (scroll able region)
Data set contains 45 Distilleries.
| DISTILLERY | COUNTY | ADDRESS | EIRCODE | NI_POSTCODE | TOURS | WEB_SITE | LAT | LONG | NOTES_PARENT_COMPANY | |
| Ballykeefe Distillery | Kilkenny | Kyle, Ballykeefe, Cuffsgrange, County Kilkenny, R95 NR50, Ireland | R95 NR50 | Yes | https://ballykeefedistillery.ie | @BallykeefeD | 52.602034 | -7.375774 | Ging Family | |
| Belfast Distillery | Antrim | Crumlin Road Goal, Crumlin Road, Belfast, BT14 6ST, United Kingdom | BT14 6ST | No | http://www.belfastdistillery.com | @BDCIreland | 54.609718 | -5.941994 | J&J McConnell | |
| Blacks Distillery | Cork | Farm Lane, Kinsale, Co. Cork | P17 XW70 | No | https://www.blacksbrewery.com | @BlacksBrewery | 51.710969 | -8.515579 | ||
| Blackwater | Waterford | Church Road, Ballinlevane East, Ballyduff, Co. Waterford, P51 C5C6 | P51 C5C6 | No | https://blackwaterdistillery.ie/ | @BlackDistillery | 52.147581 | -8.052973 | ||
| Boann | Louth | Lagavooren, Platin Rd., Drogheda, Co. Louth, A92 X593 | A92 X593 | Yes | http://boanndistillery.ie/ | @Boanndistillery | 53.69459 | -6.366558 | Cooney Family | |
| Bow Street | Dublin | Bow St, Smithfield Village, Dublin 7 | D07 N9VH | Yes | https://www.jamesonwhiskey.com/en-IE/visit-us/jameson-distillery-bow-st | @jamesonireland | 53.348415 | -6.277266 | Pernod Ricard | |
| Bushmills Distillery | Antrim | 2 Distillery Rd, Bushmills BT57 8XH, United Kingdom | BT57 8XH | Yes | https://bushmills.com | @BushmillsGlobal | 55.202936 | -6.517221 | ||
| Cape Clear | Cork | Cape Clear Island, Knockannamaurnagh, Skibbereen, Co. Cork | P81 RX70 | No | https://www.capecleardistillery.com/ | @capedistillery | 51.4509 | -9.483047 | ||
| Clonakilty | Cork | The Waterfront, Clonakilty, Co. Cork | P85 EW82 | Yes | https://www.clonakiltydistillery.ie/ | @clondistillery | 51.62165 | -8.8855 | Scully Family | |
| Connacht Whiskey Distillery | Mayo | Belleek, Ballina, Co Mayo, F26 P932 | F26 P932 | Yes | https://connachtwhiskey.com | @connachtwhiskey | 54.122131 | -9.143779 | ||
| Cooley Distillery | Louth | Dundalk Rd, Maddox Garden, Carlingford, Dundalk, Co. Louth | A91 FX98 | Yes | 53.996544 | -6.221563 | Beam Suntory | |||
| Copeland Distillery | Down | 43 Manor Street, Donaghadee, Co Down, Northern Ireland, BT21 0HG | BT21 0HG | Yes | https://copelanddistillery.com | @CopelandDistill | 54.642699 | -5.532739 | ||
| Dingle Distillery | Kerry | Farranredmond, DIngle, Co. Kerry | V92 E7YD | Yes | https://dingledistillery.ie/ | @DingleWhiskey | 52.141928 | -10.289287 | ||
| Dublin Liberties | Dublin | 33 Mill Street, Dublin 8, D08 V221 | D08 V221 | Yes | https://thedld.com | @WeAreTheDLD | 53.337343 | -6.276367 | ||
| Echlinville Distillery | Down | 62 Gransha Rd, Kircubbin, Newtownards BT22 1AJ, United Kingdom | BT22 1AJ | Yes | https://echlinville.com/ | @Echlinville | 54.46909 | -5.509397 | ||
| Glendalough | Wicklow | Unit 9 Newtown Business And Enterprise Centre, Newtown Mount Kennedy, Co. Wicklow, A63 A439 | A63 A439 | No | https://www.glendaloughdistillery.com/ | @GlendaloughDist | 53.085011 | -6.1074016 | Mark Anthony Brands International | |
| Great Northern Distillery | Louth | Carrickmacross Road, Dundalk, Co. Louth, Ireland, A91 P8W9 | A91 P8W9 | No | https://gndireland.com/ | @GNDistillery | 54.001574 | -6.40964 | Teeling Family, formally of Cooley Distillery | |
| Hinch Distillery | Down | 19 Carryduff Road, Boardmills, Ballynahinch, Down, United Kingdom | BT27 6TZ | No | https://hinchdistillery.com/ | @hinchdistillery | 54.461021 | -5.903713 | ||
| Kilbeggan Distillery | Westmeath | Lower Main St, Aghamore, Kilbeggan, Co. Westmeath, Ireland | N91 W67N | Yes | https://www.kilbegganwhiskey.com | @Kilbeggan | 53.369369 | -7.502809 | Beam Suntory | |
| Kinahan’s Distillery | Dublin | 44 Fitzwilliam Place, Dublin | D02 P027 | No | https://kinahanswhiskey.com | @KinahansLL | Sources Whiskey from around ireland | |||
| Lough Gill | Sligo | Hazelwood Avenue, Cams, Co. Sligo F91 Y820 | F91 Y820 | Yes | https://www.athru.com/ | @athruwhiskey | 54.255318 | -8.433156 | ||
| Lough Mask | Mayo | Drioglann Loch Measc Teo, Killateeaun, Tourmakeady, Co. Mayo | F12 PK75 | Yes | https://www.loughmaskdistillery.com/ | @lough_mask | 53.611819 | -9.444077 | David Raethorne | |
| Lough Ree | Longford | Main Street, Lanesborough, Co. Longford | N39 P229 | No | https://www.lrd.ie | @LoughReeDistill | 53.673328 | -7.99043 | ||
| Matt D’Arcy | Down | 27 St Marys St, Newry BT34 2AA, United Kingdom | BT34 2AA | No | http://www.mattdarcys.com | @mattdarcys | 54.172817 | -6.339367 | ||
| Midleton Distillery | Cork | Old Midleton Distillery, Distillery Walk, Midleton, Co. Cork. P25 Y394 | P25 Y394 | Yes | https://www.jamesonwhiskey.com/en-IE/visit-us/jameson-distillery-midleton | @jamesonireland | 51.916344 | -8.165174 | Pernod Ricard | |
| Nephin | Mayo | Nephin Whiskey Company, Nephin Square, Lahardane, Co. Mayo | F26 W2H9 | No | http://nephinwhiskey.com/ | @NephinWhiskey | 54.029011 | -9.32211 | ||
| Pearse Lyons Distillery | Dublin | 121-122 James’s Street Dublin 8, D08 ET27 | D08 ET27 | Yes | https://www.pearselyonsdistillery.com | @PLDistillery | 53.343708 | -6.289351 | ||
| Powerscourt | Wicklow | Powerscourt Estate, Enniskerry, Co. Wicklow, A98 A9T7 | A98 A9T7 | Yes | https://powerscourtdistillery.com/ | @PowerscourtDist | 53.184167 | -6.190794 | ||
| Rademon Estate Distillery | Down | Rademon Estate Distillery, Downpatrick, County Down, United Kingdom | BT30 9HR | Yes | https://rademonestatedistillery.com | @RademonEstate | 54.396039 | -5.790968 | ||
| Roe & Co | Dublin | 92 James’s Street, Dublin 8 | D08 YYW9 | Yes | https://www.roeandcowhiskey.com | 53.343731 | -6.285673 | |||
| Royal Oak Distillery | Carlow | Clorusk Lower, Royaloak, Co. Carlow | R21 KR23 | Yes | https://royaloakdistillery.com/ | @royaloakwhiskey | 52.703341 | -6.978711 | Saronno | |
| Scotts Irish Distillery | Fermanagh | Main Street, Garrison, Co Fermanagh, BT93 4ER, United Kingdom | BT93 4ER | No | http://scottsirish.com | 54.417726 | -8.083534 | |||
| Skellig Six 18 Distillery | Kerry | Valentia Rd, Garranearagh, Cahersiveen, Co. Kerry, V23 YD89 | V23 YD89 | Yes | https://skelligsix18distillery.ie | @SkelligSix18 | 51.935701 | -10.239549 | ||
| Slane Castle Distillery | Meath | Slane Castle, Slane, Co. Meath | C15 F224 | Yes | https://www.slaneirishwhiskey.com/ | @slanewhiskey | 53.711065 | -6.562735 | Brown-Forman & Conyngham Family | |
| Sliabh Liag | Donegal | Line Road, Carrick, Co Donegal, F94 X9DX | F94 X9DX | Yes | https://www.sliabhliagdistillers.com/ | @sliabhliagdistl | 54.6545 | -8.633847 | ||
| Teeling Whiskey Distillery | Dublin | 13-17 Newmarket, The Liberties, Dublin 8, D08 KD91 | D08 KD91 | Yes | https://teelingwhiskey.com/ | @TeelingWhiskey | 53.337862 | -6.277123 | Teeling Family | |
| The Quiet Man | Derry | 10 Rossdowney Rd, Londonderry BT47 6NS, United Kingdom | BT47 6NS | No | http://www.thequietmanirishwhiskey.com/ | @quietmanwhiskey | 54.995344 | -7.301312 | Niche Drinks | |
| The Shed Distillery | Leitrim | Carrick on shannon Road, Drumshanbo, Co. Leitrim | N41 R6D7 | No | http://thesheddistillery.com/ | @SHEDDISTILLERY | 54.047145 | -8.04358 | ||
| Thomond Gate Distillery | Limerick | No | https://thomondgatewhiskey.com/ | @ThomondW | Nicholas Ryan | |||||
| Tipperary | Tipperary | Newtownadam, Cahir, Co. Tipperary | No | http://tipperarydistillery.ie/ | @TippDistillery | 52.358622 | -7.881875 | |||
| Tullamore Distillery | Offaly | Bury Quay, Tullamore, Co. Offaly | R35 XW13 | Yes | https://www.tullamoredew.com | @TullamoreDEW | 53.377774 | -7.492944 | ||
| Walsh Whiskey Distillery | Carlow | Equity House, Deerpark Business Park, Dublin Rd, Carlow | R93 K7W4 | No | http://walshwhiskey.com/ | @walshwhiskey | 52.853417 | -6.883916 | Walsh Family | |
| Waterford Distillery | Waterford | 9 Mary Street, Grattan Quay, Waterford City, Co. Waterford | X91 KF51 | No | https://waterfordwhisky.com/ | @waterforddram | 52.264308 | -7.120997 | Renegade Spirits Ireland Ltd | |
| Wayward Irish Distillery | Kerry | Lakeview House & Estate, Fossa Road, Maulagh, Killarney, Co. Kerry, V93 F7Y5 | V93 F7Y5 | No | https://www.waywardirish.com | @wayward_irish | 52.071045 | -9.590709 | O’Connell Fomily | |
| West Cork Distillers | Cork | Marsh Rd, Marsh, Skibbereen, Co. Cork | P81 YY31 | No | http://www.westcorkdistillers.com/ | @WestCorkDistill | 51.557804 | -9.268941 |
Download Data Set
Irish_Whiskey_Distilleries – Excel Spreadsheet
Irish_Whiskey_Distilleries.csv – Zipped CSV file
I’ll be adding some additional formats soon.
Map of Distilleries
Here is a map with the Distilleries plotted using Google Maps.

Twitter Lists & Twitter Hash Tags
I’ve created a Twitter list containing the twitter accounts for all of these distilleries. You can subscribe to the list to get all the latest posts from these distilleries
Irish Whishkey Distillery Twitter List
Have a look out for these twitter hash tags on a Friday, Saturday or Sunday night, as people from around the world share what whiskeys they are tasting that evening. Irish and Scotish Whiskies are the most common.
#FridayNightDram
#FridayNightSip
#SaturdayNightSip
#SaturdayNightDram
#SundayNightSip
#SundayNightDram
How to send me updates, corrections and details of Distilleries I’ve missed
Let me know, via the my Contact page, if you see any errors in the data set, especially if I’m missing any distilleries.
Data Science (The MIT Press Essential Knowledge series) – available in English, Korean and Chinese
Back in the middle of 2018 MIT Press published my Data Science book, co-written with John Kelleher. It book was published as part of their Essentials Series.
During the few months it was available in 2018 it became a best seller on Amazon, and one of the top best selling books for MIT Press. This happened again in 2019. Yes, two years running it has been a best seller!
2020 kicks off with the book being translated into Korean and Chinese. Here are the covers of these translated books.


The Japanese and Turkish translations will be available in a few months!
Go get the English version of the book on Amazon in print, Kindle and Audio formats.

This book gives a concise introduction to the emerging field of data science, explaining its evolution, relation to machine learning, current uses, data infrastructure issues and ethical challenge the goal of data science is to improve decision making through the analysis of data. Today data science determines the ads we see online, the books and movies that are recommended to us online, which emails are filtered into our spam folders, even how much we pay for health insurance.
Go check it out.

Scottish Whisky Data Set – Updated
The Scottish Whiskey data set consist of tasting notes and evaluations from 86 distilleries around Scotland. This data set has been around a long time andwas a promotional site for a book, Whisky Classified: Choosing Single Malts by Flavour. Written by David Wishart of the University of Saint Andrews, the book had its most recent printing in February 2012.
I’ve been using this data set in one of my conference presentations (Planning my Summer Vacation), but to use this data set I need to add 2 new attributes/features to the data set. Each of the attributes are listed below and the last 2 are the attributes I added. These were added to include the converted LAT and LONG comparable with Google Maps and other similar mapping technology.
Attributes include:
- RowID
- Distillery
- Body
- Sweetness
- Smoky
- Medicinal
- Tobacco
- Honey
- Spicy
- Winey
- Nutty,
- Malty,
- Fruity,
- Floral,
- Postcode,
- Latitude,
- Longitude
- lat — newly added
- long — newly added
Here is the link to download and use this updated Scottish Whisky data set.
The original website is no longer available but if you have a look at the Internet Archive you will find the website.
#GE2020 Comparing Party Manifestos to 2016
A few days ago I wrote a blog post about using Python to analyze the 2016 general (government) elections manifestos of the four main political parties in Ireland.
Today the two (traditional) largest parties released their #GE2020 manifestos. You can get them by following these links
The following images show the WordClouds generated for the #GE2020 Manifestos. I used the same Python code used in my previous post. If you want to try this out yourself, all the Python code is there.
First let us look at the WordClouds from Fine Gael.


Now for the Fianna Fail WordClouds.
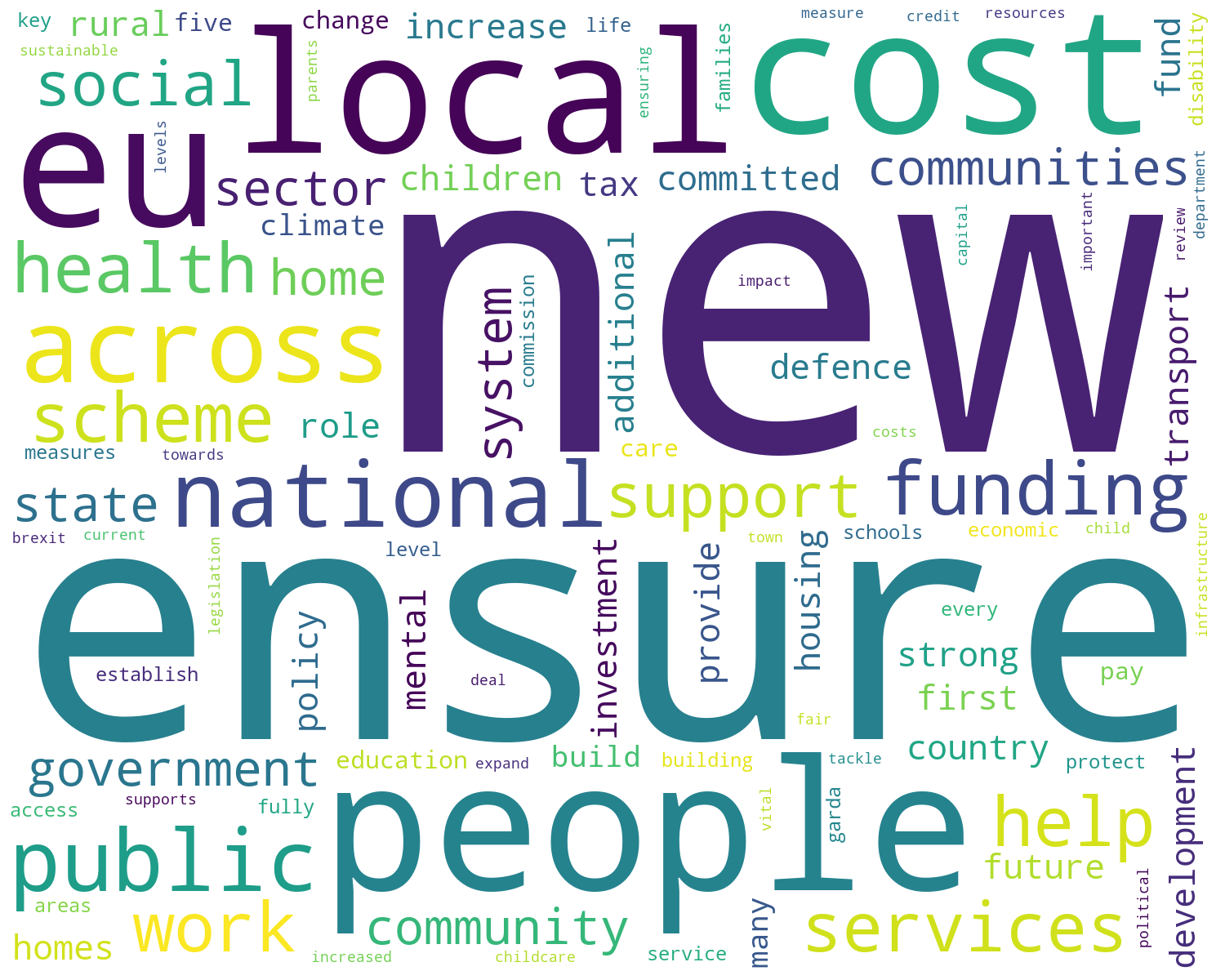
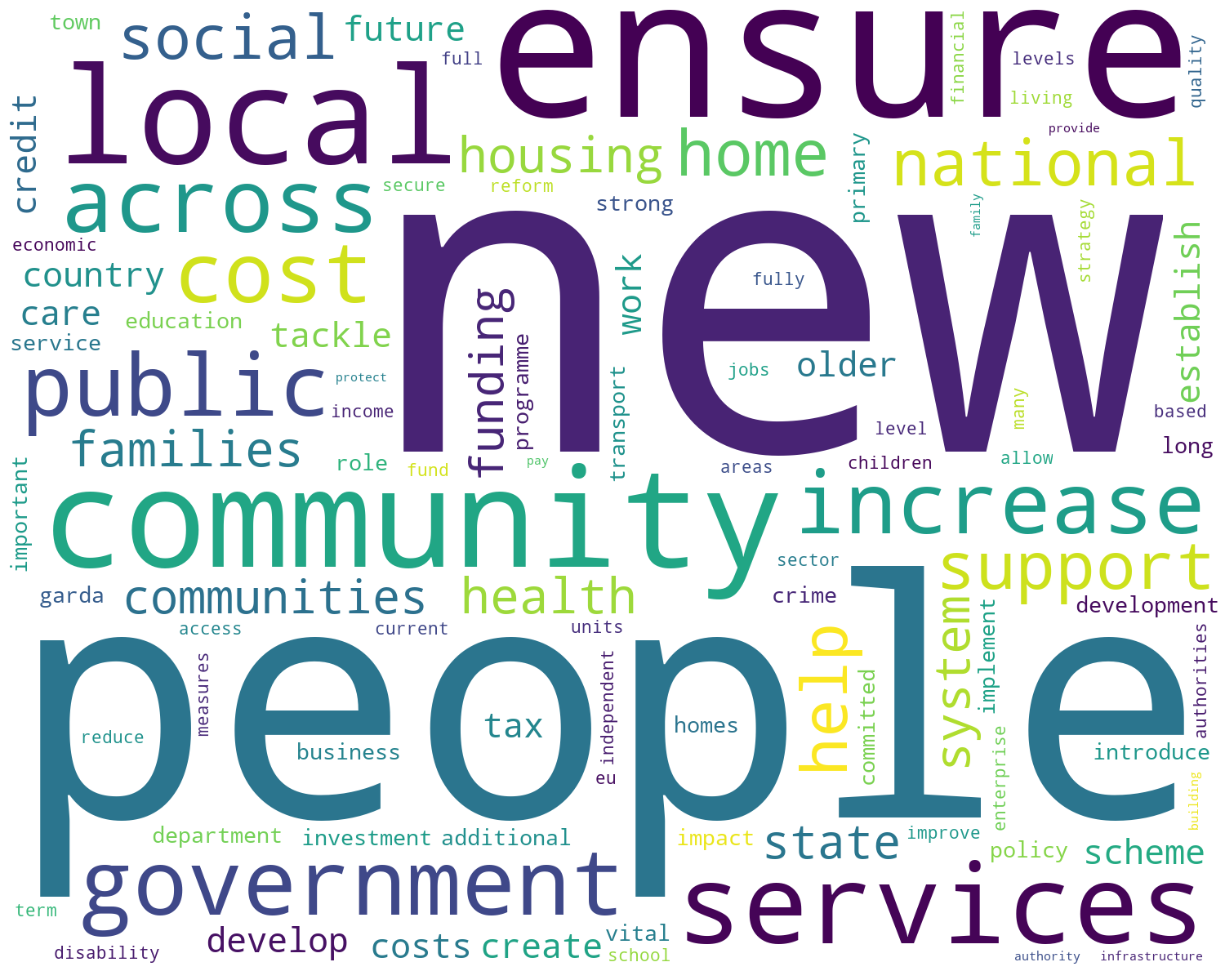
When you look closely at the differences between the manifestos you will notice there are some common themes across the manifestos from 2016 to those in the 2020 manifestos. It is also interesting to see some new words appearing/disappearing for the 2020 manifestos. Some of these are a little surprising and interesting.
#GE2020 Analysing Party Manifestos using Python
The general election is underway here in Ireland with polling day set for Saturday 8th February. All the politicians are out campaigning and every day the various parties are looking for publicity on whatever the popular topic is for that day. Each day is it a different topic.
Most of the political parties have not released their manifestos for the #GE2020 election (as of date of this post). I want to use some simple Python code to perform some analyse of their manifestos. As their new manifestos weren’t available (yet) I went looking for their manifestos from the previous general election. Michael Pidgeon has a website with party manifestos dating back to the early 1970s, and also has some from earlier elections. Check out his website.
I decided to look at manifestos from the 4 main political parties from the 2016 general election. Yes there are other manifestos available, and you can use the Python code, given below to analyse those, with only some minor edits required.
The end result of this simple analyse is a WordCloud showing the most commonly used words in their manifestos. This is graphical way to see what some of the main themes and emphasis are for each party, and also allows us to see some commonality between the parties.
Let’s begin with the Python code.
1 – Initial Setup
There are a number of Python Libraries available for processing PDF files. Not all of them worked on all of the Part Manifestos PDFs! It kind of depends on how these files were generated. In my case I used the pdfminer library, as it worked with all four manifestos. The common library PyPDF2 didn’t work with the Fine Gael manifesto document.
import io import pdfminer from pprint import pprint from pdfminer.converter import TextConverter from pdfminer.pdfinterp import PDFPageInterpreter from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfpage import PDFPage #directory were manifestos are located wkDir = '.../General_Election_Ire/' #define the names of the Manifesto PDF files & setup party flag pdfFile = wkDir+'FGManifesto16_2.pdf' party = 'FG' #pdfFile = wkDir+'Fianna_Fail_GE_2016.pdf' #party = 'FF' #pdfFile = wkDir+'Labour_GE_2016.pdf' #party = 'LB' #pdfFile = wkDir+'Sinn_Fein_GE_2016.pdf' #party = 'SF'
All of the following code will run for a given manifesto. Just comment in or out the manifesto you are interested in. The WordClouds for each are given below.
2 – Load the PDF File into Python
The following code loops through each page in the PDF file and extracts the text from that page.
I added some addition code to ignore pages containing the Irish Language. The Sinn Fein Manifesto contained a number of pages which were the Irish equivalent of the preceding pages in English. I didn’t want to have a mixture of languages in the final output.
SF_IrishPages = [14,15,16,17,18,19,20,21,22,23,24]
text = ""
pageCounter = 0
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager, converter)
for page in PDFPage.get_pages(open(pdfFile,'rb'), caching=True, check_extractable=True):
if (party == 'SF') and (pageCounter in SF_IrishPages):
print(party+' - Not extracting page - Irish page', pageCounter)
else:
print(party+' - Extracting Page text', pageCounter)
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
pageCounter += 1
print('Finished processing PDF document')
converter.close()
fake_file_handle.close()
FG - Extracting Page text 0 FG - Extracting Page text 1 FG - Extracting Page text 2 FG - Extracting Page text 3 FG - Extracting Page text 4 FG - Extracting Page text 5 ...
3 – Tokenize the Words
The next step is to Tokenize the text. This breaks the text into individual words.
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
tokens = []
tokens = word_tokenize(text)
print('Number of Pages =', pageCounter)
print('Number of Tokens =',len(tokens))
Number of Pages = 140 Number of Tokens = 66975
4 – Filter words, Remove Numbers & Punctuation
There will be a lot of things in the text that we don’t want included in the analyse. We want the text to only contain words. The following extracts the words and ignores numbers, punctuation, etc.
#converts to lower case, and removes punctuation and numbers wordsFiltered = [tokens.lower() for tokens in tokens if tokens.isalpha()] print(len(wordsFiltered)) print(wordsFiltered)
58198 ['fine', 'gael', 'general', 'election', 'manifesto', 's', 'keep', 'the', 'recovery', 'going', 'gaelgeneral', 'election', 'manifesto', 'foreward', 'from', 'an', 'taoiseach', 'the', 'long', 'term', 'economic', 'three', 'steps', 'to', 'keep', 'the', 'recovery', 'going', 'agriculture', 'and', 'food', 'generational', ...
As you can see the number of tokens has reduced from 66,975 to 58,198.
5 – Setup Stop Words
Stop words are general words in a language that doesn’t contain any meanings and these can be removed from the data set. Python NLTK comes with a set of stop words defined for most languages.
#We initialize the stopwords variable which is a list of words like
#"The", "I", "and", etc. that don't hold much value as keywords
stop_words = stopwords.words('english')
print(stop_words)
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', ....
Additional stop words can be added to this list. I added the words listed below. Some of these you might expect to be in the stop word list, others are to remove certain words that appeared in the various manifestos that don’t have a lot of meaning. I also added the name of the parties and some Irish words to the stop words list.
#some extra stop words are needed after examining the data and word cloud #these are added extra_stop_words = ['ireland','irish','ł','need', 'also', 'set', 'within', 'use', 'order', 'would', 'year', 'per', 'time', 'place', 'must', 'years', 'much', 'take','make','making','manifesto','ð','u','part','needs','next','keep','election', 'fine','gael', 'gaelgeneral', 'fianna', 'fáil','fail','labour', 'sinn', 'fein','féin','atá','go','le','ar','agus','na','ár','ag','haghaidh','téarnamh','bplean','page','two','number','cothromfor'] stop_words.extend(extra_stop_words) print(stop_words)
Now remove these stop words from the list of tokens.
# remove stop words from tokenised data set filtered_words = [word for word in wordsFiltered if word not in stop_words] print(len(filtered_words)) print(filtered_words)
31038 ['general', 'recovery', 'going', 'foreward', 'taoiseach', 'long', 'term', 'economic', 'three', 'steps', 'recovery', 'going', 'agriculture', 'food',
The number of tokens is reduced to 31,038
6 – Word Frequency Counts
Now calculate how frequently these words occur in the list of tokens.
#get the frequency of each word from collections import Counter # count frequencies cnt = Counter() for word in filtered_words: cnt[word] += 1 print(cnt)
Counter({'new': 340, 'support': 249, 'work': 190, 'public': 186, 'government': 177, 'ensure': 177, 'plan': 176, 'continue': 168, 'local': 150,
...
7 – WordCloud
We can use the word frequency counts to add emphasis to the WordCloud. The more frequently it occurs the larger it will appear in the WordCloud.
#create a word cloud using frequencies for emphasis
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud(max_words=100, margin=9, background_color='white',
scale=3, relative_scaling = 0.5, width=500, height=400,
random_state=1).generate_from_frequencies(cnt)
plt.figure(figsize=(20,10))
plt.imshow(wc)
#plt.axis("off")
plt.show()
#Save the image in the img folder:
wc.to_file(wkDir+party+"_2016.png")
The last line of code saves the WordCloud image as a file in the directory where the manifestos are located.
8 – WordClouds for Each Party

Remember these WordClouds are for the manifestos from the 2016 general election.
When the parties have released their manifestos for the 2020 general election, I’ll run them through this code and produce the WordClouds for 2020. It will be interesting to see the differences between the 2016 and 2020 manifesto WordClouds.
Data Profiling in Python
With every data analytics and data science project, one of the first tasks to that everyone needs to do is to profile the data sets. Data profiling allows you to get an initial picture of the data set, see data distributions and relationships. Additionally it allows us to see what kind of data cleaning and data transformations are necessary.
Most data analytics tools and languages have some functionality available to help you. Particular the various data science/machine learning products have this functionality built-in them and can do a lot of the data profiling automatically for you. But if you don’t use these tools/products, then you are probably using R and/or Python to profile your data.
With Python you will be working with the data set loaded into a Pandas data frame. From there you will be using various statistical functions and graphing functions (and libraries) to create a data profile. From there you will probably create a data profile report.
But one of the challenges with doing this in Python is having different coding for handling numeric and character based attributes/features. The describe function in Python (similar to the summary function in R) gives some statistical summaries for numeric attributes/features. A different set of functions are needed for character based attributes. The Python Library repository (https://pypi.org/) contains over 200K projects. But which ones are really useful and will help with your data science projects. Especially with new projects and libraries being released on a continual basis? This is a major challenge to know what is new and useful.
For example the followings shows loading the titanic data set into a Pandas data frame, creating a subset and using the describe function in Python.
import pandas as pd
df = pd.read_csv("/Users/brendan.tierney/Dropbox/4-Datasets/titanic/train.csv")
df.head(5)

df2 = df.iloc[:,[1,2,4,5,6,7,8,10,11]] df2.head(5)

df2.describe()

You will notice the describe function has only looked at the numeric attributes.
One of those 200+k Python libraries is one called pandas_profiling. This will create a data audit report for both numeric and character based attributes. This most be good, Right? Let’s take a look at what it does.
For each column the following statistics – if relevant for the column type – are presented in an interactive HTML report:
- Essentials: type, unique values, missing values
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
- Histogram
- Correlations highlighting of highly correlated variables, Spearman, Pearson and Kendall matrices
- Missing values matrix, count, heatmap and dendrogram of missing values
The first step is to install the pandas_profiling library.
pandas-profiling package naming was changed. To continue profiling data use ydata-profiling instead!
pip3 install pandas_profiling
Now run the pandas_profiling report for same data frame created and used, see above.
import pandas_profiling as pp df2.profile_report()
The following images show screen shots of each part of the report. Click and zoom into these to see more details.







Demographics vs Psychographics for Machine Learning
When preparing data for data science, data mining or machine learning projects you will create a data set that describes the various characteristics of the subject or case record. Each attribute will contain some descriptive information about the subject and is related to the target variable in some way.
In addition to these attributes, the data set will be enriched with various other internal/external data to complete the data set.
Some of the attributes in the data set can be grouped under the heading of Demographics. Demographic data contains attributes that explain or describe the person or event each case record is focused on. For example, if the subject of the case record is based on Customer data, this is the “Who” the demographic data (and features/attributes) will be about. Examples of demographic data include:
- Age range
- Marital status
- Number of children
- Household income
- Occupation
- Educational level
These features/attributes are typically readily available within your data sources and if they aren’t then these name be available from a purchased data set.
Additional feature engineering methods are used to generate new features/attributes that express meaning is different ways. This can be done by combining features in different ways, binning, dimensionality reduction, discretization, various data transformations, etc. The list can go on.
The aim of all of this is to enrich the data set to include more descriptive data about the subject. This enriched data set will then be used by the machine learning algorithms to find the hidden patterns in the data. The richer and descriptive the data set is the greater the likelihood of the algorithms in detecting the various relationships between the features and their values. These relationships will then be included in the created/generated model.
Another approach to consider when creating and enriching your data set is move beyond the descriptive features typically associated with Demographic data, to include Pyschographic data.
Psychographic data is a variation on demographic data where the feature are about describing the habits of the subject or customer. Demographics focus on the “who” while psycographics focus on the “why”. For example, a common problem with data sets is that they describe subjects/people who have things in common. In such scenarios we want to understand them at a deeper level. Psycographics allows us to do this. Examples of Psycographics include:
- Lifestyle activities
- Evening activities
- Purchasing interests – quality over economy, how environmentally concerned are you
- How happy are you with work, family, etc
- Social activities and changes in these
- What attitudes you have for certain topic areas
- What are your principles and beliefs
The above gives a far deeper insight into the subject/person and helps to differentiate each subject/person from each other, when there is a high similarity between all subjects in the data set. For example, demographic information might tell you something about a person’s age, but psychographic information will tell you that the person is just starting a family and is in the market for baby products.
I’ll close with this. Consider the various types of data gathering that companies like Google, Facebook, etc perform. They gather lots of different types of data about individuals. This allows them to build up a complete and extensive profile of all activities for individuals. They can use this to deliver more accurate marketing and advertising. For example, Google gathers data about what places to visit throughout a data, they gather all your search results, and lots of other activities. They can do a lot with this data. but now they own Fitbit. Think about what they can do with that data and particularly when combined with all the other data they have about you. What if they had access to your medical records too! Go Google this ! You will find articles about them now having access to your health records. Again combine all of the data from these different data sources. How valuable is that data?
- ← Previous
- 1
- 2
- 3
- 4
- Next →

You must be logged in to post a comment.