
Oracle
AUTO_PARTITION – Basic setup
Partitioning is an effective way to improve performance of SQL queries on large volumes of data in a database table. But only so, if a bit of care and attention is taken by both the DBA and Developer (or someone with both of these roles). Care is needed on the database side to ensure the correct partitioning method is deployed and the management of these partitions, as some partitioning methods can create a significantly large number of partitions, which in turn can affect the management of these and possibly performance too, which is not what you want. Care is also needed from the developer side to ensure their code is written in a way that utilises the partitioning method deployed. If doesn’t then you may not see much improvement in performance of your queries, and somethings things can run slower. Which not one wants!
With the Oracle Autonomous Database we have the expectation it will ‘manage’ a lot of the performance features behind the scenes without the need for the DBA and Developing getting involved (‘Autonomous’). This is kind of true up to a point, as the serverless approach can work up to a point. Sometimes a little human input is needed to give a guiding hand to the Autonomous engine to help/guide it towards what data needs particular focus.
In this (blog post) case we will have a look at DBMS_AUTO_PARTITION and how you can do a basic setup, config and enablement. I’ll have another post that will look at the recommendation feature of DBMS_AUTO_PARTITION. Just a quick reminder, DBMS_AUTO_PARTITION is for the Oracle Autonomous Database (ADB) (on the Cloud). You’ll need to run the following as ADMIN user.
The first step is to enable auto partitioning on the ADB using the CONFIGURE function. This function can have three parameters:
- IMPLEMENT : generates a report and implements the recommended partitioning method. (Autonomous!)
- REPORT_ONLY : {default} reports recommendations for partitioning on tables
- OFF : Turns off auto partitioning (reporting and implementing)
For example, to enable auto partitioning and to automatically implement the recommended partitioning method.
exec DBMS_AUTO_PARTITION.CONFIGURE('AUTO_PARTITION_MODE', 'IMPLEMENT');The changes can be inspected in the DBA_AUTO_PARTITION_CONFIG view.
SELECT * FROM DBA_AUTO_PARTITION_CONFIG;When you look at the listed from the above select we can see IMPLEMENT is enabled

The next step with using DBMS_AUTO_PARTITION is to tell the ADB what schemas and/or tables to include for auto partitioning. This first example shows how to turn on auto partitioning for a particular schema, and to allow the auto partitioning (engine) to determine what is needed and to just go and implement that it thinks is the best partitioning methods.
exec DBMS_AUTO_PARTITION.CONFIGURE(
parameter_name => 'AUTO_PARTITION_SCHEMA',
parameter_value => 'WHISKEY',
ALLOW => TRUE);If you query the DBA view again we now get.

We have not enabled a schema (called WHISKEY) to be included as part of the auto partitioning engine.
Auto Partitioning may not do anything for a little while, with some reports suggesting to wait for 15 minutes for the database to pick up any changes and to make suggestions. But there are some conditions for a table needs to meet before it can be considered, this is referred to as being a ‘Candidate’. These conditions include:
- Table passes inclusion and exclusion tests specified by AUTO_PARTITION_SCHEMA and AUTO_PARTITION_TABLE configuration parameters.
- Table exists and has up-to-date statistics.
- Table is at least 64 GB.
- Table has 5 or more queries in the SQL tuning set that scanned the table.
- Table does not contain a LONG data type column.
- Table is not manually partitioned.
- Table is not an external table, an internal/external hybrid table, a temporary table, an index-organized table, or a clustered table.
- Table does not have a domain index or bitmap join index.
- Table is not an advance queuing, materialized view, or flashback archive storage table.
- Table does not have nested tables, or certain other object features.
If you find Auto Partitioning isn’t partitioning your tables (i.e. not a valid Candidate) it could be because the table isn’t meeting the above list of conditions.
This can be verified using the VALIDATE_CANDIDATE_TABLE function.
select DBMS_AUTO_PARTITION.VALIDATE_CANDIDATE_TABLE(
table_owner => 'WHISKEY',
table_name => 'DIRECTIONS')
from dual;If the table has met the above list of conditions, the above query will return ‘VALID’, otherwise one or more of the above conditions have not been met, and the query will return ‘INVALID:’ followed by one or more reasons
Check out my other blog post on using the AUTO_PARTITION to explore it’s recommendations and how to implement.
Running Oracle Database on Docker on Apple M1 Chip
Click on this link to see the latest way to run Oracle 23ai Database on Docker. The instructions below are a bit obsolete, although they work for M1. To run Oracle 23ai Database on Docker on Apple Scilcon check out the instructions on this link.
This post is for you if you have an Apple M1 laptop and cannot get Oracle Database to run on Docker.
The reason Oracle Database, and lots of other software, doesn’t run on the new Apple Silicon is their new chip uses a different instruction set to what is used by Intel chips. Most of the Database vendors have come out to say they will not be porting their Databases to the M1 chip, as most/all servers out there run on x86 chips, and the cost of porting is just not worth it, as there is zero customers.
Are you using an x86 Chip computer (Windows or Macs with intel chips)? If so, follow these instructions (and ignore this post)
If you have been using Apple for your laptop for some time and have recently upgraded, you are now using the M1 chip, and you have probably found some of your software doesn’t run. In my scenario (and with many other people) you can no longer run an Oracle Database 😦
But there does seem to be a possible solution and this has been highlighted by Tom de Vroomen on his blog. A workaround is to spin up an x86 container using Colima. Tom has given some instructions on his blog, and what I list below is an extended set of instructions to get fully set up and running with Oracle on Docker on M1 chip.
1-Install Homebrew
You might have Homebrew installed, but if not run the following to install.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"2-Install colima
You can now install Colima using Homebrew. This might take a minute or two to run.
brew install colima3-Start colima x86 container
With Colima installed, we can now start an x86 container.
colima start --arch x86_64 --memory 4
The container will be based on x86, which is an important part of what we need. The memory is 4GB, but you can probably drop that a little.
The above command should start within a second or two.
4-Install Oracle Database for Docker
The following command will create an Oracle Database docker image using the image created by Gerald Venzi.
docker run -d -p 1521:1521 -e ORACLE_PASSWORD=<your password> -v oracle-volume:/opt/oracle/oradata gvenzl/oracle-xe
23c Database – If you want to use the 23c Database, Check out this post for the command to install
I changed <your password> to SysPassword1.
This will create the docker image and will allow for any changes to the database to be persisted after you shutdown docker. This is what you want to happen.
5-Log-in to Oracle as System
Open the docker client to see if the Oracle Database image is running. If not click on the run button.

When it finishes starting up, open the command line (see icon to the left of the run button), and log in as the SYSTEM user.
sqlplus system/SysPassword1@//localhost/XEPDB1
You are now running Oracle Database on Docker on an M1 chip laptop 🙂
6-Create new user
You shouldn’t use the System user, as that is like using root for everything. You’ll need to create a new user/schema in the database for you to use for your work. Run the following.
create user brendan identified by BTPassword1 default tablespace usersgrant connect, resource to brendan;If these run without any errors you now have your own schema in the Oracle Database on Docker (on M1 chip)
7-Connect using SQL*Plus & SQL Developer
Now let’s connect to the schema using sqlplus.
sqlplus brendan/BTPassword1@//localhost/XEPDB1That should work for you and you can now proceed using the command line tool.
If you refer to use a GUI tool then go install SQL Developer. Jeff Smith has a blog post about installing SQL Developer on M1 chip. Here is the connection screen with all the connection details entered (using the username and password given/used above)

You can now use the command line as well as SQL Developer to connect to your Oracle Database (on docker on M1).
8-Stop Docker and Colima
After you have finished using the Oracle Database on Docker you will want to shut it down until the next time you want to use it. There are two steps to follow. The first is to stop the Docker image. Just go to the Docker Desktop and click on the Stop button. It might take a few seconds for it to shutdown.
The second thing you need to do is to stop Colima.
colima stopThat’s it all done.
9-What you need to run the next time (and every time after that)
For the second and subsequent time you want to use the Oracle Docker image all you need to do is the following
(a) Start Colima
colima start --arch x86_64 --memory 4
(b) Start Oracle on Docker
Open Docker Desktop and click on the Run button [see Docker Desktop image above]
And to stop everything
(a) Stop the Oracle Database on Docker Desktop
(b) Stop Colima by running ‘colima stop’ in a terminal
Changing In-Memory size in Oracle Database
The pre-built virtual machine provided by Oracle for trying out and playing with Oracle Database comes configured to use the In-Memory option. But memory size is a little limited if you are trying to load anything slightly bigger than a tiny table into memory, for example if the table has more than a few hundred rows.
The amount of memory allocated to In-Memory can be increased to allow for more data to be loaded. There is a requirement that the VM and Database has enough memory allocated to allow this. If you don’t and increase the In-Memory size too large, you will have some problems restarting the database and VM. So proceed carefully.
For the pre-built VM, I typically allocate 4G or 8G of RAM to the VM. This in turn will give more memory to the database when it starts.
To setup In-Memory on the VM run the following:
– Open a terminal window and run this command:
sqlplus sys/oracle as sysdbaThen run these two commands
alter session set container = cdb$root;
alter system set inmemory_size = 200M scope=spfile;Now, bounce the VM, i.e. restart the VM
In-memory will now be enabled on your Database, and you can now create/move tables in and out of in-memory.
How many Data Center Regions by Vendor?
There has been some discussions over the past weeks, months, years on which Cloud provider is the best, or the biggest, or provides the most services, or [insert some other topic]? The old answer to everything related to IT is ‘It Depends’. A recent article by CloudWars (and updated numbers by them) and some of the comments to it, and elsewhere prompted me to have a look at ‘How Many Data Center Regions do each Cloud Vendor have?’ I didn’t go looking at all possible cloud vendors, but instead kept to the main vendors consisting of Microsoft Azure, Google Cloud Platform (GCP), Oracle Cloud and Amazon Web Services (AWS). We know AWS has been around for a long long time, and seems to gather most of the attention and focus within the developer community, etc, you’d expect them to be the biggest. Well, the results from my investigation does not support this.
Now, it is important to remember when reading the results presented below that these are from a particular point in time, and that is the date of this blog post. If you are reading this some time later, the actual number of data centers will be different and will be larger.
When looking at the data, as presented on each vendors website (see link to each vendor below), most list some locations coming in the future. It’s really impressive to see the number of “coming soon” locations. These “coming soon” locations are not included below (as of blog post date).
Before showing a breakdown for each vendor the following table gives the total number of data center regions for each vendor.
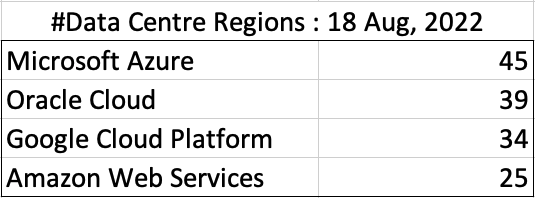
The numbers presented in the above table are different to does presented in the original CloudWars article or their updated numbers. If you look at the comments on that article and the comments on LinkedIn, you will see there was some disagreement of on their numbers. The problem is a data quality one, and vendors presenting their list of data centers in different parts of their website and documentation. Data quality and consistency is always a challenge, and particularly so when publishing data on vendor blogs, documentation and various websites. Indeed, the data I present in this post will be out of date within a few days/weeks. I’ve also excluded locations marked as ‘coming soon’ (see Azure listing).
Looking at the numbers in the above table can be a little surprising, particularly if you look at AWS, and then look at the difference in numbers between AWS and Azure and even Oracle. Very soon Azure will have double the number of data center regions when compared to AWS.
What do these numbers tell you? Based on just these numbers it would appear that Azure and Oracle Cloud are BIG cloud providers, and are much bigger than AWS. But maybe AWS has data centers that are way way bigger than those two vendors. It can be a little challenging to know the size and scale of each data center. Maybe they are going after different types of customers? With the roll out of Cloud over the past few years, there has been numerous challenges from legal and sovereign related issues requiring data to be geographically located within a country or geographic region. Most of these restrictions apply to larger organizations in the financial, insurance, and government related, etc. Given the historical customer base of Microsoft and Oracle, maybe this is driving their number of data center regions.
In more recent times there has been a growing interest, and in some sectors a growing need for organizations to be multi-cloud. Given the number of data center regions, for Azure and Oracle, and commonality in their geographic locations, it isn’t surprising to see the recent announcement from Azure and Oracle of their interconnect agreement and making the Oracle Database Service available (via interconnect) from Azure. I’m sure we will see more services being shared between these two vendors, and other might join in doing something similar.
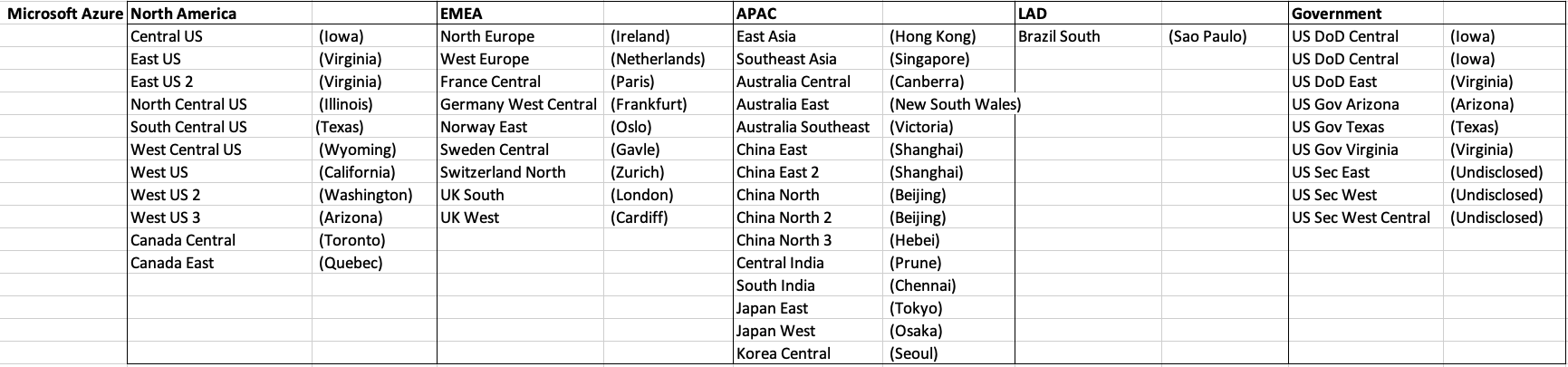
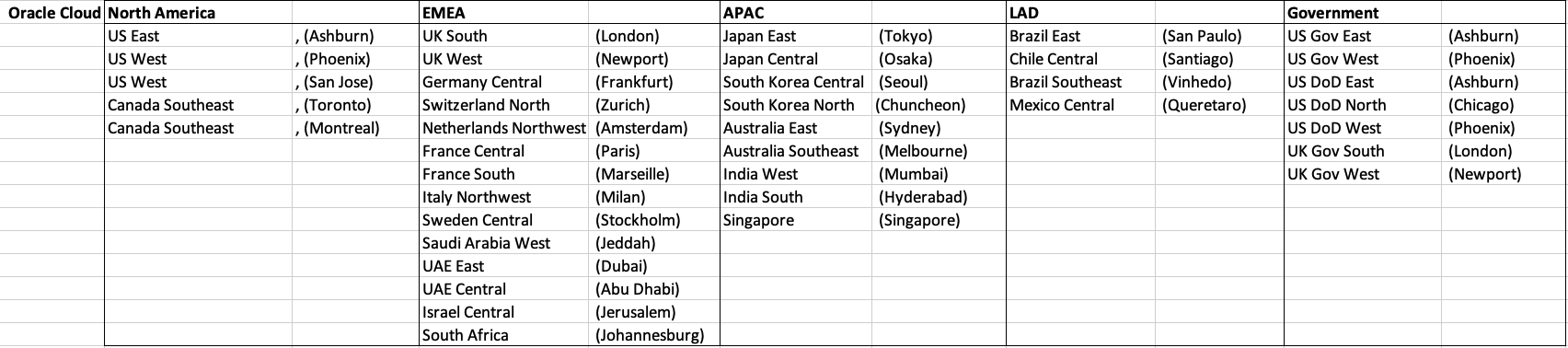
Let’s get back to the numbers and data for each Vendor. I’ve also included a link to the Vendor website where these data was obtained. (just remember these are based on date of blog post)
When you look at the Azure website listing the location, at first look it might appear they have many more locations. When you look closer at these, some/many of them are listed as ‘coming soon’. These ‘coming soon’ locations are not included in the above and below tables.
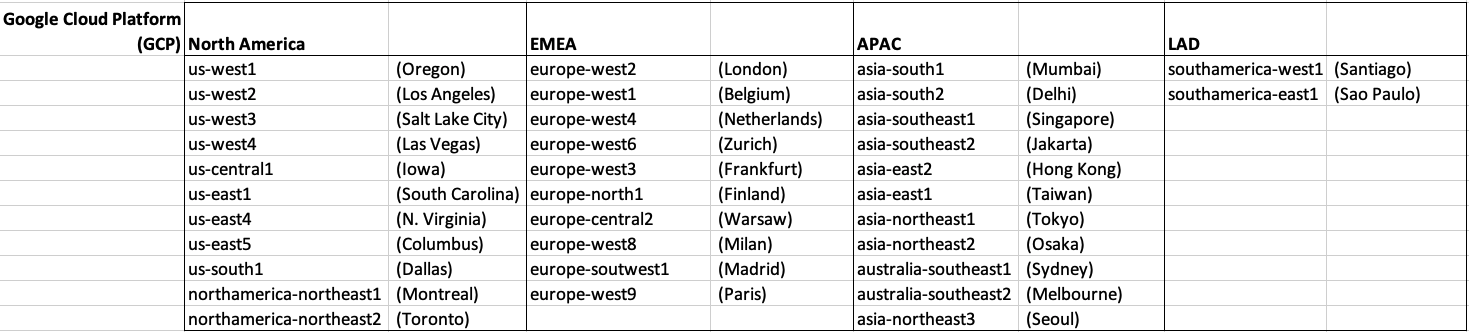
GCP doesn’t list and Government data center regions.

Oracle OCI AI Services
Oracle Cloud have been introducing new AI Services over the past few months, and we see a few more appearing over the coming few months. When you look at the list you might be a little surprised that these are newly available cloud services from Oracle. You might be surprised for two main reasons. Firstly, AWS and Google have similar cloud services available for some time (many years) now, and secondly, Oracle started talking about having these cloud services many years ago. It has taken some time for these to become publicly available. Although some of these have been included in other applications and offerings from Oracle, so probably they were busy with those before making them available as stand alone services.

These can be located in your Oracle Cloud account from the hamburger menu, as shown below

As you can see most of these AI Services are listed, except for the OCI Forecasting, which is due to be added “soon”. We can also expect to have an OCI Translation services and possibly some additional ones.
- OCI Language: This services can work with over 75 languages and allows you to detect and perform knowledge extraction from the text to include entity identification and labelling, classification of text into more than 600 categories, sentiment analysis and key phrase extraction. This can be used automate knolwedge extraction from customer feedback, product reviews, discussion forums, legal documents, etc
- OCI Speech: Performs Speech to Text, from live streaming of speech, audio and video recordings, etc creating a transcription. It works across English, Spanish and Portuguese, with other languages to be added. A nice little feature includes Profanity filtering, allowing you to tag, remove or mask certain words
- OCI Vision: This has two parts. The first is for processing documents, and is slightly different to OCI Language Service, in that this service looks at processing text documents in jpeg, pdf, png and tiff formats. Text information extraction is performed identifying keep terms, tables, meta-data extraction, table extraction etc. The second part of OCI Vision deals with image analysis and extracting key information from the image such as objects, people, text, image classification, scene detection, etc. You can use either the pretrained models or include your own models.
- OCI Anomaly Detection: Although anomaly detection is available via algorithms in the Database and OCI Data Science offerings, this new services allow for someone with little programming experience to utilise an ensemble of models, including the MSET algorithm, to provide greater accuracy with identifying unusual patterns in the data.
Note: I’ve excluded some services from the above list as these have been available for some time now or have limited AI features included in them. These include OCI Data Labelling, OCI Digital Assistant.
Some of these AI Services, based on the initial release, have limited functionality and resources, but this will change over time.
Database Vendors on Twitter, Slack, downloads, etc.
Each year we see some changes in the positioning of the most popular databases on the market. “The most popular” part of that sentence can be the most difficult to judge. There are lots and lots of different opinions on this and ways of judging them. There are various sites giving league tables, and even with those some people don’t agree with how they perform their rankings.
The following table contains links for some of the main Database engines including download pages, social media links, community support sites and to the documentation.
One of the most common sites is DB-Engines, and another is TOPDB Top Database index. The images below show the current rankings/positions of the database vendors (in January 2022).
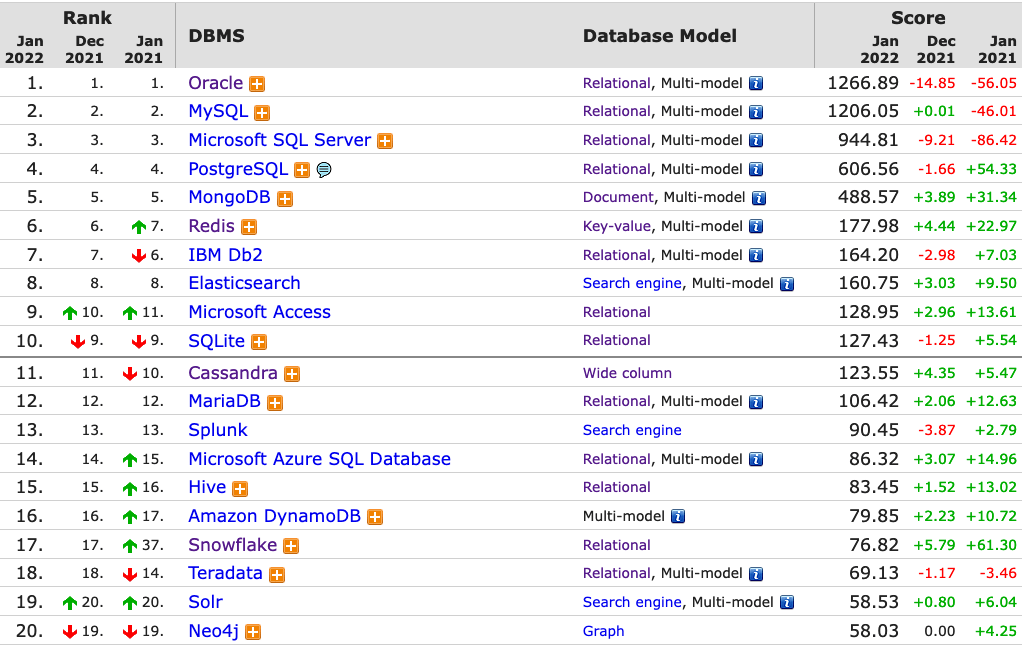
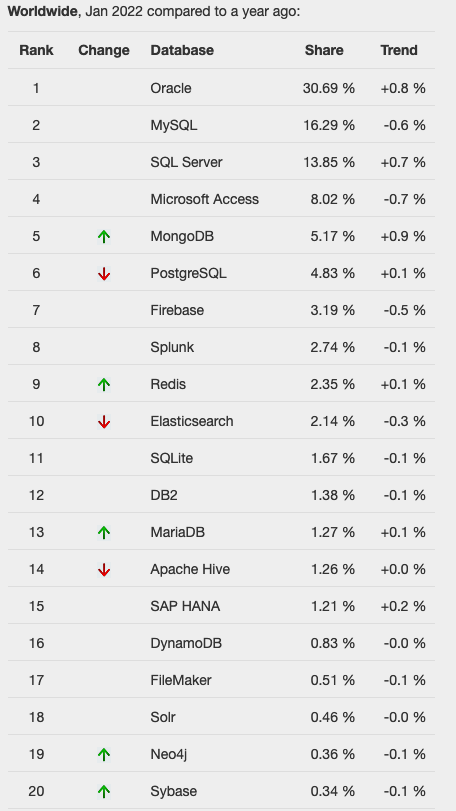
I’ve previously written about using the Python pytrends package to explore the relative importance of the different Database engines. The results from pytrends gives results based on number of searches etc in Google. Check out that Blog Post. I’ve rerun the same code for 2021, and the following gallery displays charts for each Database based on their popularity. This will allow you to see what countries are most popular for each Database and how that relates to the other databases. For these charts I’ve included Oracle, MySQL, SQL Server, PostgreSQL and MongoDB, as these are the top 5 Databases from DB-Engines.
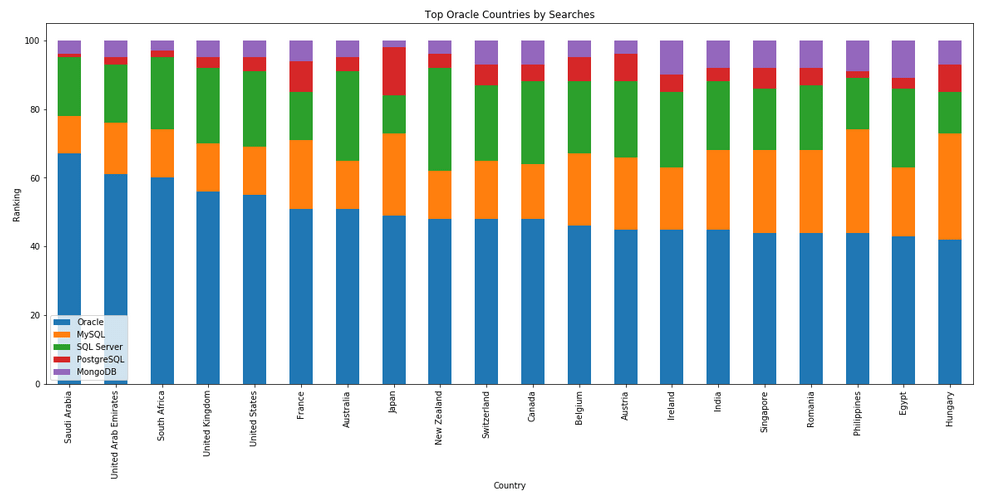
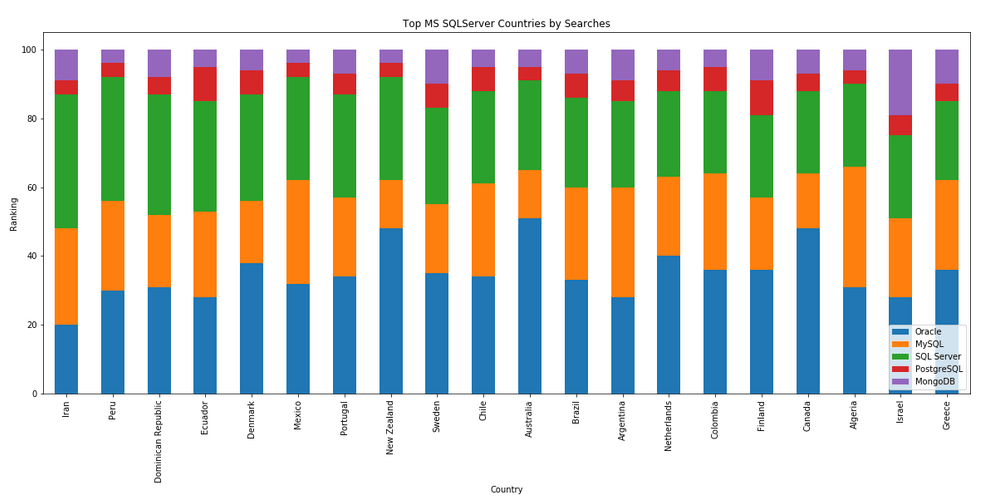
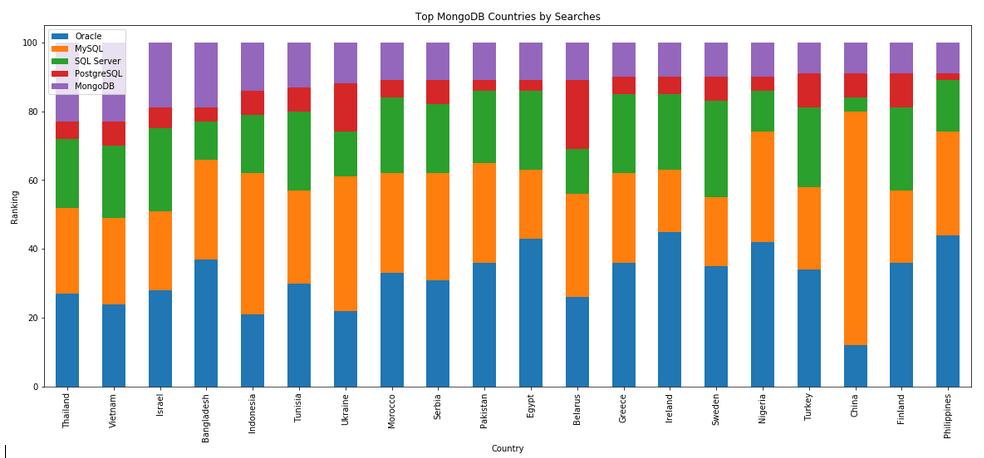
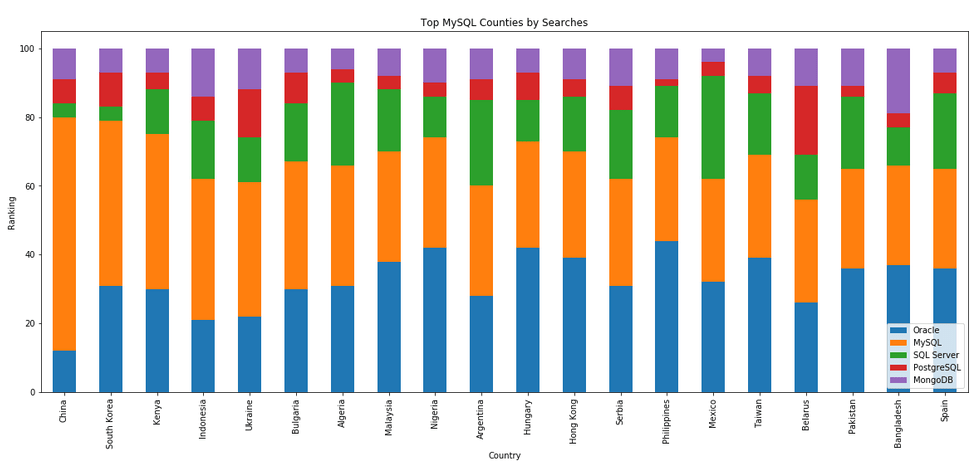
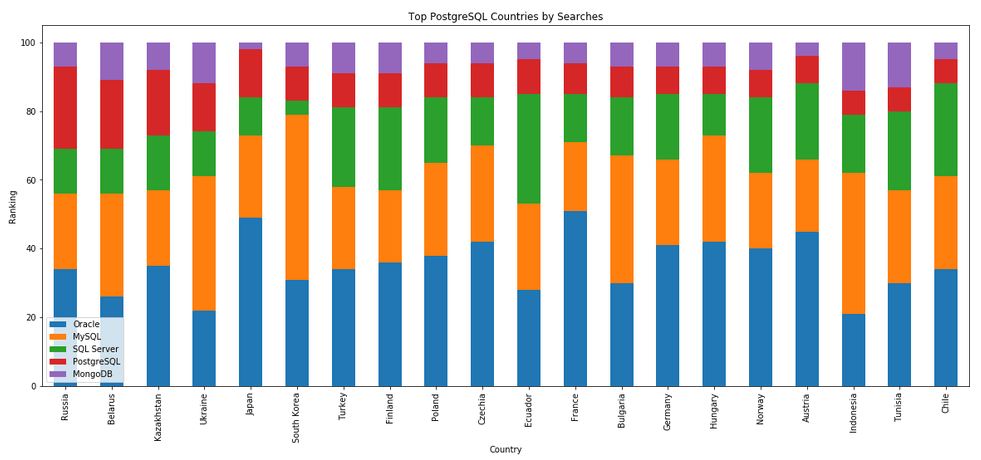
Working with External Data on Oracle DB Docker
With multi-modal databases (such as Oracle and many more) you will typically work with data in different formats and for different purposes. One such data format is with data located external to the database. The data will exist in files on the operating systems on the DB server or on some connected storage device.
The following demonstrates how to move data to an Oracle Database Docker image and access this data using External Tables. (This based on an example from Oracle-base.com with a few additional commands).
For this example, I’ll be using an Oracle 21c Docker image setup previously. Similarly the same steps can be followed for the 18c XE Docker image, by changing the Contain Id from 21cFull to 18XE.
Step 1 – Connect to OS in the Docker Container & Create Directory
The first step involves connecting the the OS of the container. As the container is setup for default user ‘oracle’, that is who we will connect as, and it is this Linux user who owns all the Oracle installation and associated files and directories
docker exec -it 21cFull /bin/bash
When connected we are in the Home directory for the Oracle user.
The Home directory contains lots of directories which contain all the files necessary for running the Oracle Database.
Next we need to create a directory which will story the files.
mkdir ext_data
As we are logged in as the oracle Linux user, we don’t have to make any permissions changes, as Oracle Database requires read and write access to this directory.
Step 3 – Upload files to Directory on Docker container
Open another terminal window on your computer (desktop/laptop). You should have two such terminal windows open. One you opened for Step 1 above, and this one. This will allow you to easily switch between files on your computer and the files in the Docker container.
Download the two Countries files, to your computer, which are listed on Oracle-base.com. Countries1.txt and Countries2.txt.
Now you need to upload those files to the Docker container.
docker cp Countries1.txt 21cFull:/opt/oracle/ext_data/Countries1.txt docker cp Countries2.txt 21cFull:/opt/oracle/ext_data/Countries2.txt
Step 4 – Connect to System (DBA) schema, Create User, Create Directory, Grant access to Directory
If you a new to the Database container, you don’t have any general users/schemas created. You should create one, as you shouldn’t use the System (or DBA) user for any development work. To create a new database user connect to System.
sqlplus system/SysPassword1@//localhost/XEPDB1
To use sqlplus command line tool you will need to install Oracle Instant Client and then SQLPlus (which is a separate download from the same directory for your OS)
To create a new user/schema in the database you can run the following (change the username and password to something more sensible).
create user brendan identified by BtPassword1
default tablespace users
temporary tablespace temp;
grant connect, resource to brendan;
alter user brendan quota unlimited on users;
Now create the Directory object in the database, which points to the directory on the Docker OS we created in the Step 1 above. Grant ‘brendan’ user/schema read and write access to this Directory
CREATE OR REPLACE DIRECTORY ext_tab_data AS '/opt/oracle/ext_data';
grant read, write on directory ext_tab_data to brendan;
Now, connect to the brendan user/schema.
Step 5 – Create external table and test
To connect to brendan user/schema, you can run the following if you are still using SQLPlus
SQL> connect brendan/BtPassword1@//localhost/XEPDB1
or if you exited it, just run this from the command line
sqlplus system/SysPassword1@//localhost/XEPDB1
Create the External Table (same code from oracle-base.com)
CREATE TABLE countries_ext (
country_code VARCHAR2(5),
country_name VARCHAR2(50),
country_language VARCHAR2(50)
)
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER
DEFAULT DIRECTORY ext_tab_data
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE
FIELDS TERMINATED BY ','
MISSING FIELD VALUES ARE NULL
(
country_code CHAR(5),
country_name CHAR(50),
country_language CHAR(50)
)
)
LOCATION ('Countries1.txt','Countries2.txt')
)
PARALLEL 5
REJECT LIMIT UNLIMITED;
It should create for you. If not and you get an error then if will be down to a typo on directory name or the files are not in the directory or something like that.
We can now query the External Table as if it is a Table in the database.
SQL> set linesize 120
SQL> select * from countries_ext order by country_name;
COUNT COUNTRY_NAME COUNTRY_LANGUAGE
----- ------------------------------------ ------------------------------
ENG England English
FRA France French
GER Germany German
IRE Ireland English
SCO Scotland English
USA Unites States of America English
WAL Wales Welsh
7 rows selected.All done!
Oracle 21c XE Database and Docker setup
You know when you are waiting for the 39 bus for ages, and then two of them turn up at the same time. It’s a bit like this with Oracle 21c XE Database Docker image being released a few days after the 18XE Docker image!
Again we have Gerald Venzi to thank for putting these together and making them available.
23c Database – If you want to use the 23c Database, Check out this post for the command to install
Are you running an Apple M1 chip Laptop? If so, follow these instructions (and ignore the rest of this post)
If you want to install Oracle 21c XE yourself then go to the download page and within a few minutes you are ready to go. Remember 21c XE is a fully featured version of their main Enterprise Database, with a few limitations, basically on size of deployment. You’d be surprised how many organisations who’s data would easily fit within these limitations/restrictions. The resource limits of Oracle Database 21 XE include:
- 2 CPU threads
- 2 GB of RAM
- 12GB of user data (Compression is included so you can store way way more than 12G)
- 3 pluggable Databases
It is important to note, there are some additional restrictions on feature availability, for example Parallel Query is not possible, etc.
Remember the 39 bus scenario I mentioned above. A couple of weeks ago the Oracle 18c XE Docker image was released. This is a full installation of the database and all you need to do is to download it and run it. Nothing else is required. Check out my previous post on this.
To download, install and run Oracle 21c XE Docker image, just run the following commands.
docker pull gvenzl/oracle-xe:21-full docker run -d -p 1521:1521 -e ORACLE_PASSWORD=SysPassword1 -v oracle-volume:/opt/oracle/XE21CFULL/oradata gvenzl/oracle-xe:21-full docker rename da37a77bb436 21cFull sqlplus system/SysPassword1@//localhost/XEPDB1
It’s a good idea to create a new schema for your work. Here is an example to create a schema called ‘demo’. First log into system using sqlplus, as shown above, and then run these commands.
create user demo identified by demo quota unlimited on users; grant connect, resource to demo;
To check that schema was created you can connect to it using sqlplus.
connect demo/demo@//localhost/XEPDB1
Then to stop the image from running and to restart it, just run the following
docker stop 21cFull docker start 21cFull
Check out my previous post on Oracle 18c XE setup for a few more commands.
SQL Developer Connection Setup
An alternative way to connect to the Database is to use SQL Developer. The following image shows and example of connecting to a schema called DEMO, which I created above. See the connection details in this image. They are the same as what is shown above when connecting using sqlplus.

OML4Py – AutoML – Step-by-Step Approach
Automated Machine Learning (AutoML) is or was a bit of a hot topic over the past couple of years. With various analysis companies like Gartner and others pushing for the need for AutoML, lots and lots of vendors have been creating different types of offerings to support this.
I’ve written some blog posts about AutoML already, from describing what it is and the different types, to showing how to do a black box approach using Oracle OML4Py, and also for using Oracle Machine Learning (OML) AutoML UI. Go check out those posts. In this post I will look at the more detailed step-by-step approach to AutoML using OML4Py. The same data set and cloud account/setup will be used. This will make it easier for you to compare the steps, the results and the AutoML experience across the different OML offerings.
Check out my previous post where I give details of the data set and some data preparation. I won’t repeat those here, but will move onto performing the step-by-step AutoML using OML4Py. The following diagram, from Oracle, outlines the steps involved

A little reminder/warning before you use AutoML in OML4Py. It only works for Classification (binary and multi-class) and Regression problems. The following code example illustrates a binary class problem, but in general there is no difference between the each type of Classification and Regression, except for the evaluation metrics, which I will list below.
Step 1 – Prepare the Data Set & Setup
See my previous blog post where I prepare the data set. I’m not going to repeat those steps here to save a little bit of space.
Also have a look at what libraries to load/import.
Step 2 – Automatic Algorithm Selection
The first step to configure and complete is select the “best model” from a selection of available Algorithms. Not all of the in-database algorithms are available to use in AutoML, which is a pity as there are some algorithms that can produce really accurate model. Hopefully with time these will be added.
The function to use is called AlgorithmSelection. This consists of two parts. The first is to define the parameters and the second part is to run it. This function accepts three parameters:
- mining function : ‘classification’ or ‘regression. Classification can be for binary and multi-class.
- score metric : the evaluation metric to evaluate the model performance. The following list gives the evaluation metric for each mining function
binary classification – accuracy (default), f1, precision, recall, roc_auc, f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
multiclass classification – accuracy (default), f1_micro, f1_macro, f1_weighted, recall_micro, recall_macro, recall_weighted, precision_micro, precision_macro, precision_weighted
regression – r2 (default), neg_mean_squared_error, neg_mean_absolute_error, neg_mean_squared_log_error, neg_median_absolute_error
- parallel : degree of parallelism to use. Default it system determined.
The second step uses this configuration and runs the code to find the “best models”. This takes the training data set (in typical Python format), and can also have a number of additional parameters. See my previous blog post for a full list of these, but ignore adaptive sampling. To keep life simple, you only really need to use ‘k’ and ‘cv’. ‘k’ specifies the number of models to include in the return list, default is 3. ‘cv’ tells how many levels of cross validation to perform. To keep things consistent across these blog posts and make comparison easier, I’m going to set ‘cv=5’
as_bank = automl.AlgorithmSelection(mining_function='classification',
score_metric='accuracy', parallel=4)
oml_bank_ms = as_bank.select(oml_bank_X, oml_bank_y, cv=5)
To display the results and select out the best algorithm:
print("Ranked algorithms with Evaluation score:\n", oml_bank_ms)
selected_oml_bank_ms = next(iter(dict(oml_bank_ms).keys()))
print("Best algorithm =", selected_oml_bank_ms)
Ranked algorithms with Evaluation score:
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377)]
Best algorithm = glm
This last bit of code is import, where the “best” algorithm is extracted from the list. This will be used in the next step.
“It Depends” is a phrase we hear/use a lot in IT, and the same applies to using AutoML. The model returned above does not mean it is the “best model”. It Depends on the parameters used, primarily the Evaluation Metric, but also the number set for CV (cross validation). Here are some examples of changing these and their results. As you can see we get a slightly different set of results or “best model” for each. My advice is to set ‘k’ large (eg current maximum values is 8), as this will ensure all algorithms are evaluated and not just a subset of them (potential hard coded ordered list of algorithms)
oml_bank_ms5 = as_bank.select(oml_bank_X, oml_bank_y, k=5)
oml_bank_ms5
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713)]
oml_bank_ms10 = as_bank.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms10
[('glm', 0.8668130990415336), ('glm_ridge', 0.8668130990415336), ('nb', 0.8634185303514377), ('rf', 0.862020766773163), ('svm_linear', 0.8552316293929713), ('nn', 0.8496405750798722), ('svm_gaussian', 0.8454472843450479), ('dt', 0.8386581469648562)]
Here are some examples when the Score Metric is changed, and the impact it can have.
as_bank2 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms2 = as_bank2.select(oml_bank_X, oml_bank_y, k=10)
oml_bank_ms2
[('rf', 0.6163242642976126), ('glm', 0.6160046056419113), ('glm_ridge', 0.6160046056419113), ('svm_linear', 0.5996686913307566), ('nn', 0.5896457765667574), ('svm_gaussian', 0.5829741379310345), ('dt', 0.5747368421052631), ('nb', 0.5269709543568464)]
as_bank3 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms3 = as_bank3.select(oml_bank_X, oml_bank_y, k=10, cv=2)
oml_bank_ms3
[('glm', 0.60365647055431), ('glm_ridge', 0.6034077555816686), ('rf', 0.5990036646816308), ('svm_linear', 0.588201766334537), ('svm_gaussian', 0.5845019676714007), ('nn', 0.5842357537014313), ('dt', 0.5686862482989511), ('nb', 0.4981168003466766)]
as_bank4 = automl.AlgorithmSelection(mining_function='classification',
score_metric='f1', parallel=4)
oml_bank_ms4 = as_bank4.select(oml_bank_X, oml_bank_y, k=10, cv=5)
oml_bank_ms4
[('glm', 0.583504644833276), ('glm_ridge', 0.58343736244422), ('rf', 0.5815952044164737), ('svm_linear', 0.5668069231027809), ('nn', 0.5628153929281711), ('svm_gaussian', 0.5613976370223811), ('dt', 0.5602129668741175), ('nb', 0.49153999668083814)]
The problem we now have with AutoML, it is telling us different answers for “best model”. To most that might be confusing but for the more technical data scientist they will know why. In very very simple terms, you are doing different things with the data and because of this you can get a different answer.
It is because of these different possible answers answers for the “best model”, is the reason AutoML can really only be used as a guide (a pointer towards what might be the “best model”), and cannot be relied upon to give a “best model”. AutoML is still not suitable for the general data analyst despite what some companies are saying.
Lots more could be discussed here but let’s more onto the next step.
Step 3 – Automatic Feature Selection
In the previous steps we have identified a possible “best model”. Let’s pretend the “best model” is the “best model”. The next steps is to look at how this model can be refined and improved using a subset of the features/attributes/columns. FeatureSelection looks are examining the data when combined with the model to find the optimised set of features/attributes/columns, to improve the model performance i.e. make it more accurate or have a better outcome based on the evaluation or score metric. For simplicity I’m going to use the result from the first example produced in the previous step. In a similar way to Step 2, there are two parts to setup and run the Feature Selection (Reduction). Each part is setup in a similar way to Step 2, with the parameters for FeatureSelection being the same values as those used for AlgorithmSelection. For the ‘reduce’ function, pass in the name of the “best model” or “best algorithm” from Step 2. This was extracted to a variable called ‘selected_oml_bank_ms’. Most of the other parameters the ‘reduce’ function takes are similar to the ‘select’ function. Again keeping things consistent, pass in the training data set and set the number of cross validations to 5.
fs_oml_bank = automl.FeatureSelection(mining_function = 'classification',
score_metric = 'accuracy', parallel=4)
oml_bank_fsR = fs_oml_bank.reduce(selected_oml_bank_ms, oml_bank_X, oml_bank_y, cv=5)
We can now look at the results from this listing the reduced set of features/columns and comparing the number of features/columns in the original data set to the reduced set.
#print(oml_bank_fsR)
oml_bank_fsR_l = oml_bank_X[:,oml_bank_fsR]
print("Selected columns:", oml_bank_fsR_l.columns)
print("Number of columns:")
"{} reduced to {}".format(len(oml_bank_X.columns), len(oml_bank_fsR_l.columns))
Selected columns: ['DURATION', 'PDAYS', 'EMP_VAR_RATE', 'CONS_PRICE_IDX', 'CONS_CONF_IDX', 'EURIBOR3M', 'NR_EMPLOYED']
Number of columns:
'20 reduced to 7'
In this example the data set gets reduced from having 20 features/columns in the original data set, down to having 7 features/columns.
Step 4 – Automatic Model Tuning
Up to now, we have identified the “best model” / “best algorithm” and the optimised reduced set of features to use. The final step is to take the details generated from the previous steps and use this to generate a Tuned Model. In a similar way to the previous steps, this involve two parts. The first sets up some parameters and the second runs the Model Tuning function called ‘tune’. Make sure to include the data frame containing the reduced set of features/attributes.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4) oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5) print(oml_bank_mt)
The output is very long and contains the name of the Algorithm, the hyperparameters used for the final model, the features used, and (at the end) lists the various combinations of hyperparameters used and the evaluation metric score for each combination. Partial output shown below.
mt_oml_bank = automl.ModelTuning(mining_function='classification', score_metric='accuracy', parallel=4)
oml_bank_mt = mt_oml_bank.tune(selected_oml_bank_ms, oml_bank_fsR_l, oml_bank_y, cv=5)
print(oml_bank_mt)
{'best_model':
Algorithm Name: Generalized Linear Model
Mining Function: CLASSIFICATION
Target: TARGET_Y
Settings:
setting name setting value
0 ALGO_NAME ALGO_GENERALIZED_LINEAR_MODEL
1 CLAS_WEIGHTS_BALANCED OFF
...
...
, 'all_evals': [(0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 31, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 173, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 174, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 337, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.8544108809341562, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 338, 'GLMS_SOLVER': 'GLMS_SOLVER_CHOL'}), (0.4211156437080018, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 10, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'OFF', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'}), (0.11374128955112069, {'CLAS_WEIGHTS_BALANCED': 'ON', 'GLMS_NUM_ITERATIONS': 30, 'GLMS_SOLVER': 'GLMS_SOLVER_SGD'})]}
The list of parameter settings and the evaluation score is an ordered list in decending order, starting with the best model.
We can extract the different parts of this dictionary object by using the following:
#display the main model details print(oml_bank_mt['best_model'])
Now extract the evaluation metric score and the parameter settings used for the best model, (position 0 of the dictionary)
score, params = oml_bank_mt['all_evals'][0]
And that’s it, job done with using OML4Py AutoML to generate an optimised model.
The example above is for a Classification problem. If you had a Regression problem all you need to do is replace ‘classification’ with ‘regression’, and change the score_metric parameter to ‘r2’, or one of the other Regression metric values (see above for list of these.
OML4Py – AutoML – Oracle GUI for AutoML
In addition to the new AutoML features with OML4Py (Oracle Machine Learning for Python), which is currently available on ADW/ATP using Oracle Machine Learning (OML) Notebooks, Oracle has just released a GUI for AutoML.
As with all new releases there are a few things that Oracle need to tidy up with the interface and CX with this GUI. I’m sure these will be corrected/updated quietly behind the scenes and we will gradually see these improvements over the weeks to come (after product release). Part of the joys of cloud first deployment.
The initial release of AutoML GUI is SO SLOW. It is several, several times slower than trying to do the same task in OML4Py. Plus the Algorithms used and models created seem to be different. Maybe this is down to the “meta-learning” AutoML uses, but for repeatability and ensuring confidence with of outputs, some additional work is needed otherwise it is unreliable and people won’t use something that is unreliable.
To illustrate how to use the AutoML GUI, I’m going to use the same example and same Oracle Cloud environment I’ve used to illustrate the other ways of running AutoML using OML4Py (see post 1, see post 2).
The AutoML GUI can be accessed from the main OML Notebooks welcome page. On the next webpage, called AutoML Experiment, click on the Create button.

The Create Experiment page allows you to specify the required details for you AutoML experiment. Although this tool is aims at non-technical people, they still require a certain degree of knowledge of Machine Learning and what the different terms mean! On the Create Experiment page enter the following details, and enter them in this order. Numbers below correspond to numbers on image below
- Name of experiment – free format text – enter a meaningful name
- Data Source – Click on Magnifying Glass – Select your Schema, and Table/View from the list
- Predict – what attribute is the Target variable/column
- Case ID – Select attribute that is unique e.g. PK, or some other attribute. Selecting an attribute for this is not necessary
- Features – Exclude any attributes you don’t want included, for example attributes that are correlated to the target values
You can now run the AutoML process by clicking the Start button at the top of the page (6).

But maybe before you do this, you can look at the Additional Settings, and alter these if you want or just leave them as they are

After clicking the Start button, you are given two options or modes. You can run the AutoML Experiment with “Faster Results” or with “Better Accuracy”. Both of these are SLOW to execute, but I’d advice running using Both options/modes to see how the results differ. This does require you to setup two version of the same AutoML Experiment!
When the AutoML Experiment is running, see image below, the dashboard displays results are each part of the experiment completes. These include the Algorithms, the accuracy levels and the Features/Attributes that are important.

The AutoML Experiment will eventually finish! Even after displaying the details of the last algorithm in the Leaders Board, it will keep running for some time before completing. Initially the dashboard will just display Accuracy for the model. You can expand this list of evaluation metrics by clicking the ‘Metrics’ located just under the Leader Board title, and selecting the additional evaluation metrics from the list. These will now be displayed on the Leaders Board.

That’s it! Relatively simple to use, but you do still know what you are doing, and it isn’t really aimed at novices despite some of the marketing.
One final feature that is kind of nice is the ‘Create Notebook’. Located in Leader Board section, select one of the models, and then click on ‘Create Notebook’ and it will create an OML Notebook for you based on the model you have selected. You will be promoted to give the notebook a name. A message will be displayed at the top of the webpage saying ‘…notebook successfully created’. Go to your list of Notebooks and open it. It will be a basic notebook with code to create/define the data set, setup model settings, create the model, display model details and use the model to label a data set.

AutoML is just too slow at the moment (I’ve tested with several data sets of different sizes). Start the process and go for lunch. It might be finished when you get back! I’ve been told things would run a lot quicker if I wasn’t using the Free Tier. I hope that is true, but how many people have easy access to such an environment to test this? Not many, including myself, which makes it difficult to test and compare the results. The Free Tier is the gateway for people get to try new Oracle products. First impression are important.
I mentioned earlier I used the same data set and Oracle Cloud environment when I showed how to use AutoML in OML4Py (using OML Notebooks). The results from OML4Py AutoML are different to those show above using AutoML (G)UI. Getting different results with similar setttings/configurations is very confusing. Which approach should be used for AutoML? Can you trust the results from AutoML if you are getting different results? If the data scientist uses OML4Py and the data analyst uses the AutoML GUI, then there should be some commonality in what is produced by these same/similar AutoML. Realiability and reproducibility is vital in Data Science, Machine Learning, etc.
In my tests, there was no similarity/commonality with the outputs from AutoML, that was my experience. In such a situation where different AutoML outputs are produced which one should we believe/trust? Who will the business users believe? Who is doing it correctly? Who is producing results the business can rely upon?
Setting up Julia to work with Oracle Database
For Data Science projects the top three languages every data scientist and machine learning practitioner knows are Python, R and SQL. The ranking or order of importance of these is of some debate and the reason answer is, ‘It Depends’. But one thing is for sure no matter what your environment, SQL skills will be needed, because that’s where the data lives, in the various databases of the organization. No matter what the database is SQL is the way to access and analyze it efficiently. But for Python and R, the popularity of these languages really depends on the project team and their background. Deciding between the two can come down to flipping a coin. But every has their favorite!
A (or not so) new language for data science and machine learning is Julia. Actually it has been around for a while now, and life began on it in 2009, whereas R (and S) and Python have their beginnings back in the 1980’s and early 1990’s. Does that make them legacy programming languages? or it just took a bit of time to mature and gain popularity?
There are lots of advantages to Julia, just like there are lots of advantages with the other languages. The following diagram illustrates one of the core advantages of Julia, it isn’t an interpreted language like R and Python, which means Julia will be significantly faster, yet still allows interactive development using Notebooks, just like R and Python. Julia was designed and build for data science and machine learning, and is designed for scale which makes it a good fit for MLOps. The list of advantages and differences can go on a bit and those are not the point of this post.

The remainder of this post will step through what is needed to get Julia working with an Oracle Database, and you have setup an IDE. Check out the Julia website for excellent installation instructions and selecting an IDE. If you coming from an R and/or Python background, using Jupyter Notebooks is a good option, and as you become more experienced there are a number of more advanced IDEs available for you to use. I’m assuming you have installed Julia.
If you have done a new install of Julia, make sure to add the install directory to the search PATH.
First Download load and install Oracle Instant Client. This is needed by the Julia packages to communicate with Oracle Database. After installing make sure to setup the following in your environment (environment variables and Path)
- ORACLE_HOME : points to where you installed Oracle Instant Client
- TNS_ADMIN : points to the directory containing the wallet/tnsnames files. This will be a sub-directory in Oracle Instant Client directory, for example, it points to …/instantclient_19_8/network/admin
- PATH : include the Oracle Instant Client install directory in the PATH.
Next step is to setup the Oracle Client network files. As your DBA for the tnsnames.ora file or for the Wallet Zip file for your database. The Wallet Zip file is the most common approach. Unzip this Wallet file and copy the unzipped files to the TNS_ADMIN directory. See the second bullet point above to for this (…/instantclient_19_8/network/admin).
That’s all you need to do on the Oracle setup. I’m assuming you have a username and password for the Oracle Database you will be using.
Now we can setup Julia to use the Oracle Instant Client software. It is important you have setup those environment variables l’ve listed above.
There is an Oracle.jl package, developed by Felipe Noronha, which runs on top of Oracle Instant Client. To install this, load the Pkg package then then add the Oracle package. The following shows these commands and part of the output from the installation.
julia> using Pkg
julia> Pkg.add("Oracle")
Updating registry at `~/.julia/registries/General`
######################################################################## 100.0%
Resolving package versions...
Installed Reexport ──────────────────── v1.0.0
Installed libsodium_jll ─────────────── v1.0.18+1
Installed Compat ────────────────────── v3.25.0
Installed OrderedCollections ────────── v1.3.3
Installed WebSockets ────────────────── v1.5.9
Installed JuliaInterpreter ──────────── v0.8.8
Installed DataStructures ────────────── v0.18.9
Installed DataAPI ───────────────────── v1.5.1
Installed Requires ──────────────────── v1.1.2
Installed DataValueInterfaces ───────── v1.0.0
Installed Parsers ───────────────────── v1.0.15
Installed FlameGraphs ───────────────── v0.2.5
Installed URIs ──────────────────────── v1.2.0
Installed Colors ────────────────────── v0.12.6
Installed Oracle ────────────────────── v0.2.0
...
...
...
[7240a794] + Oracle v0.2.0
[bac558e1] ↑ OrderedCollections v1.3.2 ⇒ v1.3.3
[69de0a69] ↑ Parsers v1.0.12 ⇒ v1.0.15
[189a3867] ↑ Reexport v0.2.0 ⇒ v1.0.0
[ae029012] ↑ Requires v1.1.1 ⇒ v1.1.2
[3783bdb8] + TableTraits v1.0.0
[bd369af6] + Tables v1.3.2
[0796e94c] ↑ Tokenize v0.5.8 ⇒ v0.5.13
[5c2747f8] + URIs v1.2.0
[104b5d7c] ↑ WebSockets v1.5.2 ⇒ v1.5.9
[8f1865be] ↑ ZeroMQ_jll v4.3.2+5 ⇒ v4.3.2+6
[a9144af2] + libsodium_jll v1.0.18+1
Building Oracle → `~/.julia/packages/Oracle/CEOWz/deps/build.log`
julia>
You are now ready to load this Oracle package and use it to connect to an Oracle Database. Setting up a connection is really simple and in the following example I’m connecting to an ATP Database on Oracle Free Tier. The following sets up some variables, creates a connection, prints a statement and connection information and then closes the connection.
import Oracle
username="oml_user"
password="xxxxxxxxxxx"
dbname="yyyyyyyyyyyy"
conn = Oracle.Connection(username, password, dbname)
println("Connected")
println(conn)
Oracle.close(conn)
Job done 🙂
There is little additional connection information available. To test the connection a bit more let’s list what tables I have in my test/demo schema/user.
import Oracle
username="oml_user"
password="xxxxxxxxxxx"
dbname="yyyyyyyyyyyy"
conn = Oracle.Connection(username, password, dbname)
println("Tables")
println("--------------------")
Oracle.query(conn, "SELECT table_name FROM user_tables") do cursor
for row in cursor
# row values can be accessed using column name or position
println( row["TABLE_NAME"] ) # same as row[1]
end
end
println("")
println("...the end...")
Oracle.close(conn)
If you come from a Python background the syntax is familiar which makes the move other to Julia an easier task.
One other difference is, running the above code does seem to run a lot quicker in Julia. I haven’t measured it and the difference is less than a second but it is noticeable. For me, the above code generate the following output,
Tables -------------------- WINE BANK_ADDITIONAL_FULL MINING_DATA_BUILD_V ...the end...
I’ll have additional posts looking are difference aspects and commands for working with and processing data in an Oracle Database.
Collection of Oracle 21c posts on new Machine Learning and Statistical functions
Oracle 21c was officially released a few days about and this post contains links to some blog posts I’ve written on new machine learning and statistical functions in the new Oracle 21c.
- Adam Optimization Solver for Neural Network Algorithm
- MSET-SPRT Algorithm
- XGBoost Algorithm
- Measuring SKEWNESS Function
- Measuring tailedness of data with KURTOSIS Function
I also have posts on new OML4Py and AutoML too, and I’ll have a different set of posts for those, so look out them.
Also check out my previous blog post that covers new machine learning feature introduced in Oracle 19c.
- ← Previous
- 1
- 2
- 3
- …
- 19
- Next →

You must be logged in to post a comment.