
Machine Learning
XGBoost in Oracle 20c
 Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Another of the new machine learning algorithms in Oracle 21c Database is called XGBoost. Most people will have come across this algorithm due to its recent popularity with winners of Kaggle competitions and other similar events.
XGBoost is an open source software library providing a gradient boosting framework in most of the commonly used data science, machine learning and software development languages. It has it’s origins back in 2014, but the first official academic publication on the algorithm was published in 2016 by Tianqi Chen and Carlos Guestrin, from the University of Washington.
The algorithm builds upon the previous work on Decision Trees, Bagging, Random Forest, Boosting and Gradient Boosting. The benefits of using these various approaches are well know, researched, developed and proven over many years. XGBoost can be used for the typical use cases of Classification including classification, regression and ranking problems. Check out the original research paper for more details of the inner workings of the algorithm.
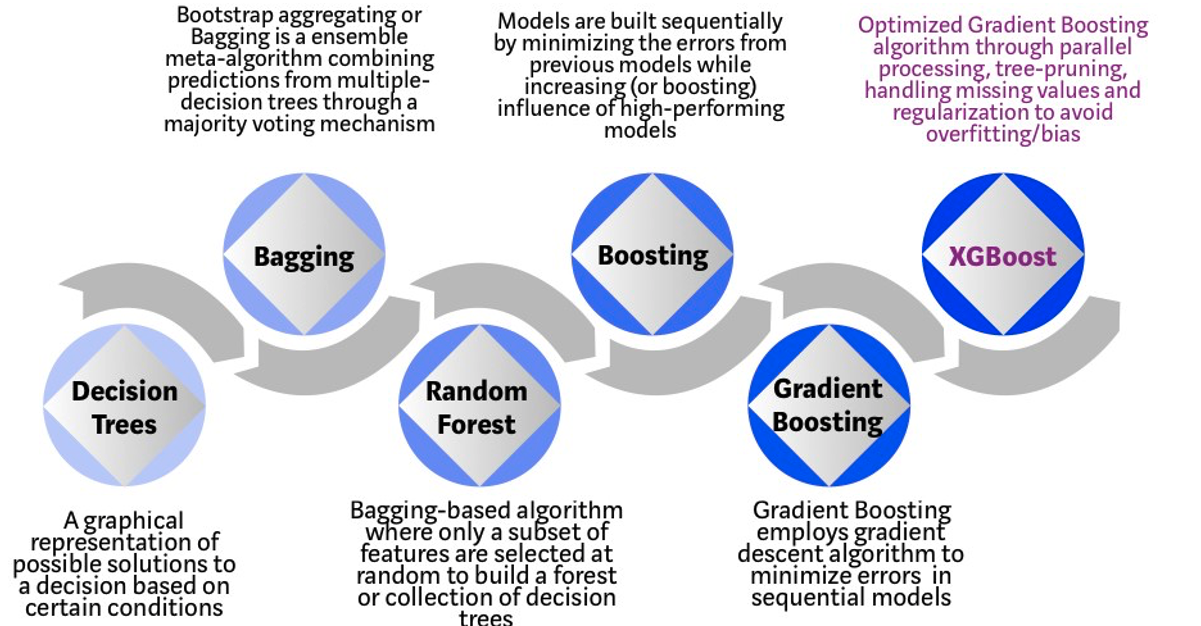
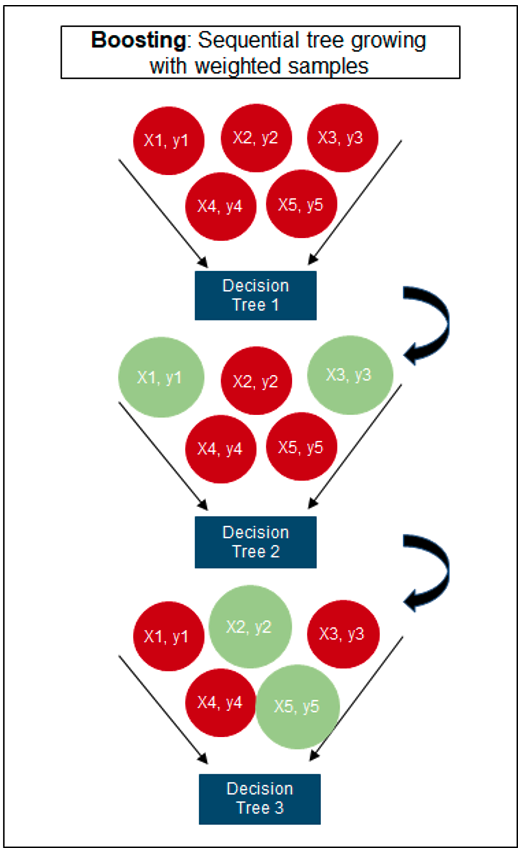
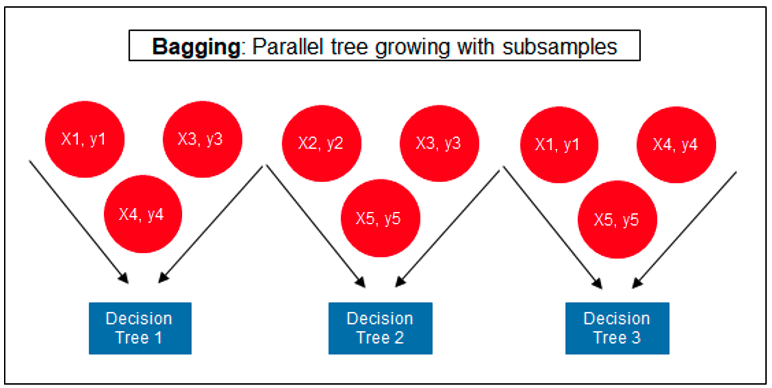
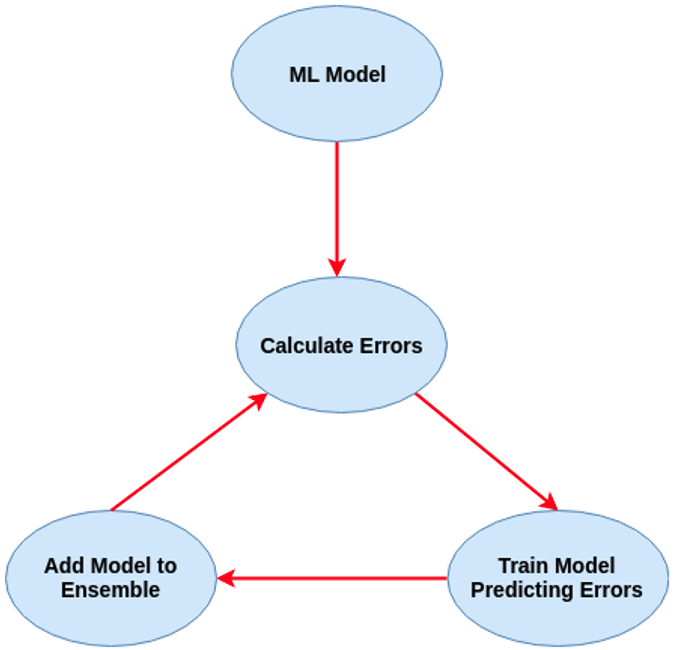 Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
The following three images illustrates the differences between Decision Trees, Random Forest and XGBoost.
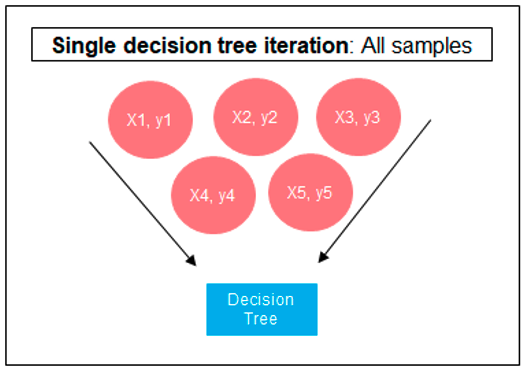
The XGBoost algorithm in Oracle 20c has over 40 different parameter settings, and with most scenarios the default settings with be fine for most scenarios. Only after creating a baseline model with the details will you look to explore making changes to these. Some of the typical settings include:
- Booster = gbtree
- #rounds for boosting = 10
- max_depth = 6
- num_parallel_tree = 1
- eval_metric = Classification error rate or RMSE for regression
As with most of the Oracle in-database machine learning algorithms, the setup and defining the parameters is really simple. Here is an example of minimum of parameter settings that needs to be defined.
BEGIN -- delete previous setttings DELETE FROM banking_xgb_settings; INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_xgboost); -- For 0/1 target, choose binary:logistic as the objective. INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_objective, 'binary:logistic’); commit; END;
To create an XGBoost model run the following. BEGIN DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'BANKING_XGB_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'BANKING_72K', case_id_column_name => 'ID', target_column_name => 'TARGET', settings_table_name => 'BANKING_XGB_SETTINGS'); END;
That’s all nice and simple, as it should be, and the new model can be called in the same manner as any of the other in-database machine learning models using functions like PREDICTION, PREDICTION_PROBABILITY, etc.
One of the interesting things I found when experimenting with XGBoost was the time it took to create the completed model. Using the default settings the following table gives the time taken, in seconds to create the model.

As you can see it is VERY quick even for large data sets and gives greater predictive accuracy.
Benchmarking calling Oracle Machine Learning using REST
Over the past year I’ve been presenting, blogging and sharing my experiences of using REST to expose Oracle Machine Learning models to developers in other languages, for example Python.
One of the questions I’ve been asked is, Does it scale?
Although I’ve used it in several projects to great success, there are no figures I can report publicly on how many REST API calls can be serviced 😦
But this can be easily done, and the results below are based on using and Oracle Autonomous Data Warehouse (ADW) on the Oracle Always Free.
The machine learning model is built on a Wine reviews data set, using Oracle Machine Learning Notebook as my tool to write some SQL and PL/SQL to build out a model to predict Good or Bad wines, based on the Prices and other characteristics of the wine. A REST API was built using this model to allow for a developer to pass in wine descriptors and returns two values to indicate if it would be a Good or Bad wine and the probability of this prediction.
No data is stored in the database. I only use the machine learning model to make the prediction
I built out the REST API using APEX, and here is a screenshot of the GET API setup.

Here is an example of some Python code to call the machine learning model to make a prediction.
import json
import requests
country = 'Portugal'
province = 'Douro'
variety = 'Portuguese Red'
price = '30'
resp = requests.get('https://jggnlb6iptk8gum-adw2.adb.us-ashburn-1.oraclecloudapps.com/ords/oml_user/wine/wine_pred/'+country+'/'+province+'/'+'variety'+'/'+price)
json_data = resp.json()
print (json.dumps(json_data, indent=2))
—–
{
"pred_wine": "LT_90_POINTS",
"prob_wine": 0.6844716987704507
}
But does this scale, as in how many concurrent users and REST API calls can it handle at the same time.
To test this I multi-threaded processes in Python to call a Python function to call the API, while ensuring a range of values are used for the input parameters. Some additional information for my tests.
- Each function call included two REST API calls
- Test effect of creating X processes, at same time
- Test effect of creating X processes in batches of Y agents
- Then, the above, with function having one REST API call and also having two REST API calls, to compare timings
- Test in range of parallel process from 10 to 1,000 (generating up to 2,000 REST API calls at a time)
Some of the results. The table shows the time(*) in seconds to complete the number of processes grouped into batches (agents). My laptop was the limiting factor in these tests. It wasn’t able to test when the number of parallel processes when above 500. That is why I broke them into batches consisting of X agents

* this is the total time to run all the Python code, including the time taken to create each process.
Some observations:
- Time taken to complete each function/process was between 0.45 seconds and 1.65 seconds, for two API calls.
- When only one API call, time to complete each function/process was between 0.32 seconds and 1.21 seconds
- Average time for each function/process was 0.64 seconds for one API functions/processes, and 0.86 for two API calls in function/process
- Table above illustrates the overhead associated with setting up, calling, and managing these processes
As you can see, even with the limitations of my laptop, using an Oracle Database, in-database machine learning and REST can be used to create a Micro-Service type machine learning scoring engine. Based on these numbers, this machine learning micro-service would be able to handle and process a large number of machine learning scoring in Real-Time, and these numbers would be well within the maximum number of such calls in most applications. I’m sure I could process more parallel processes if I deployed on a different machine to my laptop and maybe used a number of different machines at the same time
How many applications within you enterprise needs to process move than 6,000 real-time machine learning scoring per minute? This shows us the Oracle Always Free offering is capable and suitable for most applications.
Now, if you are processing more than those numbers per minutes then perhaps you need to move onto the paid options.
What next? I’ll spin up two VMs on Oracle Always Free, install Python, copy code into these VMs and have then run in parallel 🙂
Data Science (The MIT Press Essential Knowledge series) – available in English, Korean and Chinese
Back in the middle of 2018 MIT Press published my Data Science book, co-written with John Kelleher. It book was published as part of their Essentials Series.
During the few months it was available in 2018 it became a best seller on Amazon, and one of the top best selling books for MIT Press. This happened again in 2019. Yes, two years running it has been a best seller!
2020 kicks off with the book being translated into Korean and Chinese. Here are the covers of these translated books.


The Japanese and Turkish translations will be available in a few months!
Go get the English version of the book on Amazon in print, Kindle and Audio formats.

This book gives a concise introduction to the emerging field of data science, explaining its evolution, relation to machine learning, current uses, data infrastructure issues and ethical challenge the goal of data science is to improve decision making through the analysis of data. Today data science determines the ads we see online, the books and movies that are recommended to us online, which emails are filtered into our spam folders, even how much we pay for health insurance.
Go check it out.

#GE2020 Analysing Party Manifestos using Python
The general election is underway here in Ireland with polling day set for Saturday 8th February. All the politicians are out campaigning and every day the various parties are looking for publicity on whatever the popular topic is for that day. Each day is it a different topic.
Most of the political parties have not released their manifestos for the #GE2020 election (as of date of this post). I want to use some simple Python code to perform some analyse of their manifestos. As their new manifestos weren’t available (yet) I went looking for their manifestos from the previous general election. Michael Pidgeon has a website with party manifestos dating back to the early 1970s, and also has some from earlier elections. Check out his website.
I decided to look at manifestos from the 4 main political parties from the 2016 general election. Yes there are other manifestos available, and you can use the Python code, given below to analyse those, with only some minor edits required.
The end result of this simple analyse is a WordCloud showing the most commonly used words in their manifestos. This is graphical way to see what some of the main themes and emphasis are for each party, and also allows us to see some commonality between the parties.
Let’s begin with the Python code.
1 – Initial Setup
There are a number of Python Libraries available for processing PDF files. Not all of them worked on all of the Part Manifestos PDFs! It kind of depends on how these files were generated. In my case I used the pdfminer library, as it worked with all four manifestos. The common library PyPDF2 didn’t work with the Fine Gael manifesto document.
import io import pdfminer from pprint import pprint from pdfminer.converter import TextConverter from pdfminer.pdfinterp import PDFPageInterpreter from pdfminer.pdfinterp import PDFResourceManager from pdfminer.pdfpage import PDFPage #directory were manifestos are located wkDir = '.../General_Election_Ire/' #define the names of the Manifesto PDF files & setup party flag pdfFile = wkDir+'FGManifesto16_2.pdf' party = 'FG' #pdfFile = wkDir+'Fianna_Fail_GE_2016.pdf' #party = 'FF' #pdfFile = wkDir+'Labour_GE_2016.pdf' #party = 'LB' #pdfFile = wkDir+'Sinn_Fein_GE_2016.pdf' #party = 'SF'
All of the following code will run for a given manifesto. Just comment in or out the manifesto you are interested in. The WordClouds for each are given below.
2 – Load the PDF File into Python
The following code loops through each page in the PDF file and extracts the text from that page.
I added some addition code to ignore pages containing the Irish Language. The Sinn Fein Manifesto contained a number of pages which were the Irish equivalent of the preceding pages in English. I didn’t want to have a mixture of languages in the final output.
SF_IrishPages = [14,15,16,17,18,19,20,21,22,23,24]
text = ""
pageCounter = 0
resource_manager = PDFResourceManager()
fake_file_handle = io.StringIO()
converter = TextConverter(resource_manager, fake_file_handle)
page_interpreter = PDFPageInterpreter(resource_manager, converter)
for page in PDFPage.get_pages(open(pdfFile,'rb'), caching=True, check_extractable=True):
if (party == 'SF') and (pageCounter in SF_IrishPages):
print(party+' - Not extracting page - Irish page', pageCounter)
else:
print(party+' - Extracting Page text', pageCounter)
page_interpreter.process_page(page)
text = fake_file_handle.getvalue()
pageCounter += 1
print('Finished processing PDF document')
converter.close()
fake_file_handle.close()
FG - Extracting Page text 0 FG - Extracting Page text 1 FG - Extracting Page text 2 FG - Extracting Page text 3 FG - Extracting Page text 4 FG - Extracting Page text 5 ...
3 – Tokenize the Words
The next step is to Tokenize the text. This breaks the text into individual words.
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
tokens = []
tokens = word_tokenize(text)
print('Number of Pages =', pageCounter)
print('Number of Tokens =',len(tokens))
Number of Pages = 140 Number of Tokens = 66975
4 – Filter words, Remove Numbers & Punctuation
There will be a lot of things in the text that we don’t want included in the analyse. We want the text to only contain words. The following extracts the words and ignores numbers, punctuation, etc.
#converts to lower case, and removes punctuation and numbers wordsFiltered = [tokens.lower() for tokens in tokens if tokens.isalpha()] print(len(wordsFiltered)) print(wordsFiltered)
58198 ['fine', 'gael', 'general', 'election', 'manifesto', 's', 'keep', 'the', 'recovery', 'going', 'gaelgeneral', 'election', 'manifesto', 'foreward', 'from', 'an', 'taoiseach', 'the', 'long', 'term', 'economic', 'three', 'steps', 'to', 'keep', 'the', 'recovery', 'going', 'agriculture', 'and', 'food', 'generational', ...
As you can see the number of tokens has reduced from 66,975 to 58,198.
5 – Setup Stop Words
Stop words are general words in a language that doesn’t contain any meanings and these can be removed from the data set. Python NLTK comes with a set of stop words defined for most languages.
#We initialize the stopwords variable which is a list of words like
#"The", "I", "and", etc. that don't hold much value as keywords
stop_words = stopwords.words('english')
print(stop_words)
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', ....
Additional stop words can be added to this list. I added the words listed below. Some of these you might expect to be in the stop word list, others are to remove certain words that appeared in the various manifestos that don’t have a lot of meaning. I also added the name of the parties and some Irish words to the stop words list.
#some extra stop words are needed after examining the data and word cloud #these are added extra_stop_words = ['ireland','irish','ł','need', 'also', 'set', 'within', 'use', 'order', 'would', 'year', 'per', 'time', 'place', 'must', 'years', 'much', 'take','make','making','manifesto','ð','u','part','needs','next','keep','election', 'fine','gael', 'gaelgeneral', 'fianna', 'fáil','fail','labour', 'sinn', 'fein','féin','atá','go','le','ar','agus','na','ár','ag','haghaidh','téarnamh','bplean','page','two','number','cothromfor'] stop_words.extend(extra_stop_words) print(stop_words)
Now remove these stop words from the list of tokens.
# remove stop words from tokenised data set filtered_words = [word for word in wordsFiltered if word not in stop_words] print(len(filtered_words)) print(filtered_words)
31038 ['general', 'recovery', 'going', 'foreward', 'taoiseach', 'long', 'term', 'economic', 'three', 'steps', 'recovery', 'going', 'agriculture', 'food',
The number of tokens is reduced to 31,038
6 – Word Frequency Counts
Now calculate how frequently these words occur in the list of tokens.
#get the frequency of each word from collections import Counter # count frequencies cnt = Counter() for word in filtered_words: cnt[word] += 1 print(cnt)
Counter({'new': 340, 'support': 249, 'work': 190, 'public': 186, 'government': 177, 'ensure': 177, 'plan': 176, 'continue': 168, 'local': 150,
...
7 – WordCloud
We can use the word frequency counts to add emphasis to the WordCloud. The more frequently it occurs the larger it will appear in the WordCloud.
#create a word cloud using frequencies for emphasis
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wc = WordCloud(max_words=100, margin=9, background_color='white',
scale=3, relative_scaling = 0.5, width=500, height=400,
random_state=1).generate_from_frequencies(cnt)
plt.figure(figsize=(20,10))
plt.imshow(wc)
#plt.axis("off")
plt.show()
#Save the image in the img folder:
wc.to_file(wkDir+party+"_2016.png")
The last line of code saves the WordCloud image as a file in the directory where the manifestos are located.
8 – WordClouds for Each Party

Remember these WordClouds are for the manifestos from the 2016 general election.
When the parties have released their manifestos for the 2020 general election, I’ll run them through this code and produce the WordClouds for 2020. It will be interesting to see the differences between the 2016 and 2020 manifesto WordClouds.
Machine Learning Evaluation Measures
When developing machine learning models there is a long list of possible evaluation measures. On one hand this can be good as it gives us lots of insights into the models and be able to select the best model that meets the requirements. (BTW this is different to choosing the best model based on the evaluation measures!). On the other hand it can be very confusing what all of these mean as there can appear to be so many of them. In this post I’ll look at some of these evolution measures.
I’m not going to go into the basic set of evaluation measures that come from the typical use of the Confusion Matrix, including True/False Positives, True/False Negatives, Accuracy, Miss-classification rate, Precision, Recall, Sensitivity and F1 score.
The following evaluation measures will be discussed:
- R-Squared (R2)
- Mean Squared Error (MSE)
- Sum of Squared Error (SSE)
- Root Mean Square (RMSE)
R-Squared (R²)
R-squared measures how well your data fits a regression line. It measures the variation of the predicted values, from the model, from that of the actual value. It is typically given as a percentage or in the range of Zero to One (although you can have negative values). It is also known as Coefficient of Determination. The higher the value for R² the better.

R² is always between 0 and 100%:
- 0% indicates that the model explains none of the variability of the response data around its mean.
- 100% indicates that the model explains all the variability of the response data around its mean.

But
Mean Squared Error (MSE)
MSE measures average squared error of our predictions. For each point, it calculates square difference between the predictions and the target and then average those values. The higher this value, the worse the model is.

The larger the number the larger the error. Error in this case means the difference between the observed values and the predicted values. Square each difference, this ensures negative and positive values do not cancel each other out.
Sum of Squared Error (SSE)
SSE is the sum of the squared differences between each observation and its group’s mean. It measures the overall difference between your data and the values predicted by your estimation model.

Root Mean Square Error (RMSE)
RMSE is just the square root of MSE. The square root is introduced to make scale of the errors to be the same as the scale of targets. As the square root of a variance, RMSE can be interpreted as the standard deviation of the unexplained variance. Lower values of RMSE indicate better fit. RMSE is a good measure of how accurately the model predicts the response.
Applying a Machine Learning Model in OAC
There are a number of different tools and languages available for machine learning projects. One such tool is Oracle Analytics Cloud (OAC). Check out my article for Oracle Magazine that takes you through the steps of using OAC to create a Machine Learning workflow/dataflow.

Oracle Analytics Cloud provides a single unified solution for analyzing data and delivering analytics solutions to businesses. Additionally, it provides functionality for processing data, allowing for data transformations, data cleaning, and data integration. Oracle Analytics Cloud also enables you to build a machine learning workflow, from loading, cleaning, and transforming data and creating a machine learning model to evaluating the model and applying it to new data—without the need to write a line of code. My Oracle Magazine article takes you through the various tasks for using Oracle Analytics Cloud to build a machine learning workflow.
That article covers the various steps with creating a machine learning model. This post will bring you through the steps of using that model to score/label new data.
In the Data Flows screen (accessed via Data->Data Flows) click on Create. We are going to create a new Data Flow to process the scoring/labeling of new data.

Select Data Flow from the pop-up menu. The ‘Add Data Set’ window will open listing your available data sets. In my example, I’m going to use the same data set that I used in the Oracle Magazine article to build the model. Click on the data set and then click on the Add button.

The initial Data Flow will be created with the node for the Data Set. The screen will display all the attributes for the data set and from this you can select what attributes to include or remove. For example, if you want a subset of the attributes to be used as input to the machine learning model, you can select these attributes at this stage. These can be adjusted at a later stages, but the data flow will need to be re-run to pick up these changes.

Next step is to create the Apply Model node. To add this to the data flow click on the small plus symbol to the right of the Data Node. This will pop open a window from which you will need to select the Apply Model.

A pop-up window will appear listing the various machine learning models that exist in your OAC environment. Select the model you want to use and click the Ok button.


The next node to add to the data flow is to save the results/outputs from the Apply Model node. Click on the small plus icon to the right of the Apply Model node and select Save Results from the popup window.

We now have a completed data flow. But before you finish edit the Save Data node to give a name for the Save Data Set, and you can edit what attributes/features you want in the result set.

You can now save and run the Data Flow, and view the outputs from applying the machine learning model. The saved data set results can be viewed in the Data menu.

Always watching, always listening. Be careful with your data
The saying ‘Big Brother is Watching’ has been around a long time and typically gets associated with government organisations. But over the past few years we have a few new Big Brothers appearing. These are in the form of Google and Facebook and a few others.
These companies gather lots and lots. Some companies gather enormous amounts of data. This data will include details of your interactions with the companies through various websites, applications, etc. But some are gathering data in ways that you might not be aware. For example, take this following video. Data is being gathered about what you do and where you go even if you have disconnected your phone.
Did you know this kind of data was being gathered about you?
Just think of what they could be doing with that data, that data you didn’t know they were gathering about you. Companies like these generate huge amounts of income from selling advertisements and the more data they have about individuals the more the can understand what they might be interested. The generate customer profiles and sell expensive advertising based on having these very detailed customer profiles.
But it doesn’t stop there. Recently Google bought Fitbit. Just think about what they can do now. Combining their existing profiles of you as a person with you activities throughout every day, week and month. Just think about how various health and insurance companies would love to have this data. Yes they would and companies like Google would be able to charge these companies even more money for this level of detail on individuals/customers.
But it doesn’t stop there. There have been lots of reports of various apps sharing health and other related data with various companies, without their customers being aware this is happening.
What about Google Assistant? In a recent article by MIT Technology Review title Inside Amazon’s plan for Alexa to run your entire life, they discuss how Alexa can be used to control virtually everything. In this article Alexa’s cheif scientist say “plan is for the voice assistant to move from passive to proactive interactions. Rather than wait for and respond to requests, Alexa will anticipate what the user might want. The idea is to turn Alexa into an omnipresent companion that actively shapes and orchestrates your life. This will require Alexa to get to know you better than ever before.” When combined with other products this will allow “these new products let Alexa listen to and log data about a dramatically larger portion of your life“.
Just imagine if Google did the same with their Google Assistant! Big Brother isn’t just Watching, they are also Listening!
There has been some recent report of Google looking to get into Banking by offering checking accounts. The project, code-named Cache, is due to launch in 2020. Google has partnered with Citigroup and a credit union at Stanford University, which will administer the accounts. Users will be able to access their accounts through Google’s digital payment platform, Google Pay.
And there are the reports of Google having access to the health records of over 50 million people. In addition to this, Google has signed a deal with Ascension, the second-largest hospital system in the US, to collect and analyze millions of Americans’ personal health data. Ascension operates in 150 hospitals in 21 states.
What if they also had access to your banking details and spending habits? Google is looking at different options to extend financial products from the google pay into more main stream banking. There has been some recent report of them looking at offering current accounts.
I won’t go discussing their attempts at Ethics and their various (failed) attempts at establishing and Ethics Advisory Board. This has been well documented elsewhere.
Things are getting a bit scary and the saying ‘Big Brother is Watching You’, is very, very true.
In the ever increasing connected world, all of us have a responsibility to know what data companies are gathering on us. We need to decide how comfortable we are with this and if you aren’t then you need to take steps to ensure you protect yourself. Maybe part of this protection requires us to become less connected, stop using some apps, turn off more notification, turn off updates, turn off tracking, etc
While taking each product or offering individually, it may seem ok to us for Google and other companies to offer such services and to analyze our data to provide a better service. But for most people the issues arise when each of these products start to be combined. By doing this they get to have greater access and understanding our our data and our behaviors. What role does (digital) ethics play in all of this? This is something for the company and the employees to decide where things should stop. But when/how do you decide this? when do you/they know things have gone too far? how can you undo some of this work to go back to an acceptable level? what is an acceptable level and how do you define this?
As yo can see there are lots of things to consider and a vital component is the role of (digital) ethics. All organizations who process and analyze data need to have an ethics board and ethics needs to be a core part of every project. To support this everyone needs more training and awareness of ethics and what is acceptable or not.
Demographics vs Psychographics for Machine Learning
When preparing data for data science, data mining or machine learning projects you will create a data set that describes the various characteristics of the subject or case record. Each attribute will contain some descriptive information about the subject and is related to the target variable in some way.
In addition to these attributes, the data set will be enriched with various other internal/external data to complete the data set.
Some of the attributes in the data set can be grouped under the heading of Demographics. Demographic data contains attributes that explain or describe the person or event each case record is focused on. For example, if the subject of the case record is based on Customer data, this is the “Who” the demographic data (and features/attributes) will be about. Examples of demographic data include:
- Age range
- Marital status
- Number of children
- Household income
- Occupation
- Educational level
These features/attributes are typically readily available within your data sources and if they aren’t then these name be available from a purchased data set.
Additional feature engineering methods are used to generate new features/attributes that express meaning is different ways. This can be done by combining features in different ways, binning, dimensionality reduction, discretization, various data transformations, etc. The list can go on.
The aim of all of this is to enrich the data set to include more descriptive data about the subject. This enriched data set will then be used by the machine learning algorithms to find the hidden patterns in the data. The richer and descriptive the data set is the greater the likelihood of the algorithms in detecting the various relationships between the features and their values. These relationships will then be included in the created/generated model.
Another approach to consider when creating and enriching your data set is move beyond the descriptive features typically associated with Demographic data, to include Pyschographic data.
Psychographic data is a variation on demographic data where the feature are about describing the habits of the subject or customer. Demographics focus on the “who” while psycographics focus on the “why”. For example, a common problem with data sets is that they describe subjects/people who have things in common. In such scenarios we want to understand them at a deeper level. Psycographics allows us to do this. Examples of Psycographics include:
- Lifestyle activities
- Evening activities
- Purchasing interests – quality over economy, how environmentally concerned are you
- How happy are you with work, family, etc
- Social activities and changes in these
- What attitudes you have for certain topic areas
- What are your principles and beliefs
The above gives a far deeper insight into the subject/person and helps to differentiate each subject/person from each other, when there is a high similarity between all subjects in the data set. For example, demographic information might tell you something about a person’s age, but psychographic information will tell you that the person is just starting a family and is in the market for baby products.
I’ll close with this. Consider the various types of data gathering that companies like Google, Facebook, etc perform. They gather lots of different types of data about individuals. This allows them to build up a complete and extensive profile of all activities for individuals. They can use this to deliver more accurate marketing and advertising. For example, Google gathers data about what places to visit throughout a data, they gather all your search results, and lots of other activities. They can do a lot with this data. but now they own Fitbit. Think about what they can do with that data and particularly when combined with all the other data they have about you. What if they had access to your medical records too! Go Google this ! You will find articles about them now having access to your health records. Again combine all of the data from these different data sources. How valuable is that data?
Oracle ADW how to load new OML notebooks
Oracle Autonomous Database (ADW) has been out a while now and have had several, behind the scenes, improvements and new/additional features added.
If you have used the Oracle Machine Learning (OML) component of ADW you will have seen the various sample OML Notebooks that come pre-loaded. These are easy to open, use and to try out the various OML features.
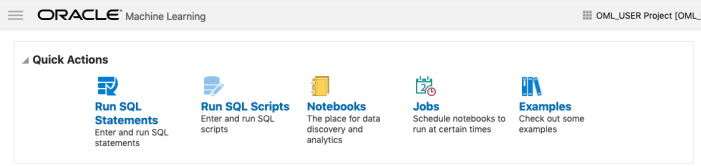
The above image shows the top part of the login screen for OML. To see the available sample notebooks click on the Examples icon. When you do, you will get the following sample OML Notebooks.
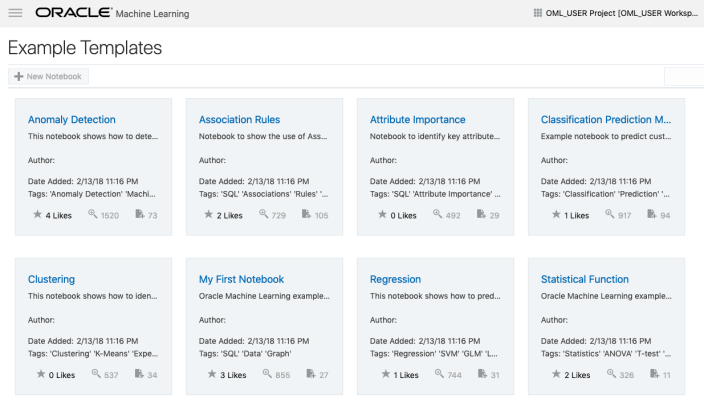
But what if you have a notebook you have used elsewhere. These can be exported in json format and loaded as a new notebook in OML.
To load a new notebook into OML, select the icon (three horizontal line) on the top left hand corner of the screen. Then select Notebooks from the menu.

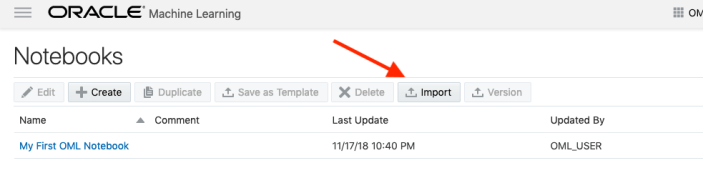
Then select the Import button located at the top of the Notebooks screen. This will open a File window, where you can select the json file from your file system.
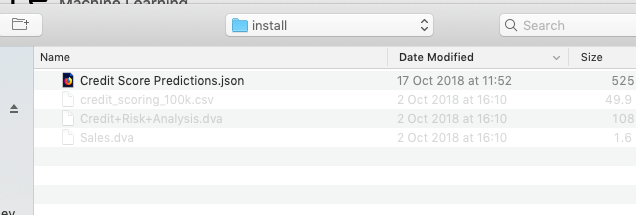
A couple of seconds later the notebook will be available and listed along side any other notebooks you may have created.
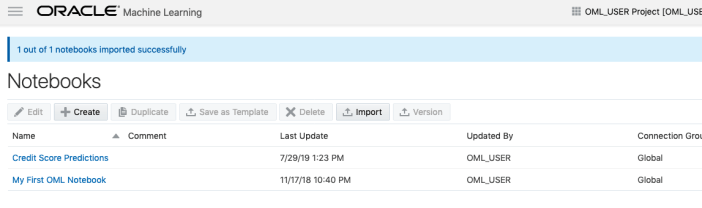
All done!
You have now imported a new notebook into OML and can now use it to process your data and perform machine learning using the in-database features.
Machine Learning on Mobile Devices
You: What? You can’t be serious? Machine Learning on Mobile Devices?
Me: The simple answer is ‘Yes you can!”
You: But, what about all the complex data processing, CPU or GPU, and everything else that is needed for machine learning?
Me: Yes you are correct, those things might not be needed. What’s the answer to everything in IT?
You: It Depends ?
Me: Exactly. Yes It Depends on what you are doing. In most cases you don’t need large amounts of machine processing power to do machine learning. Except if you are doing image processing. Then you do need a bit of power to support that work.
You: But how can a mobile device be used for machine learning?

Me: It Depends! 🙂 It depends on what you are doing. Most of the data processing power needed is for creating the models. That is what most people talk about. Very few people talk about the deployment of machine learning. Deployment, as in, using the machine learning models in your applications.
You: But why mobile devices? That sounds a bit silly?
Me: It does a bit. But when you think about it, how much do you use your mobile phone and tablet? Where else have you seen mobile devices being used?
You: I use these all the time, to do nearly everything. Just like everyone else I know.
Me: Exactly! and where else have you seen mobile devices being used?
You: Everywhere! hotels, bars, shops, hospitals, everywhere!
Me: Exactly. And it kind of makes sense to have machine learning scoring done at the point of capture of the data and not some hours or days or weeks later in some data warehouse or something else.
You: But what about the processing power of these devices. They aren’t powerful enough to run the machine learning models? Or are they?
Me: What is a machine learning model? In a simple way it is a mathematical formula of the data that calculates a particular outcome. Something that is a bit more complicated than using a sum function. Could a mobile device do that easily?
You: Yes. That should be really easy and fast for mobile devices? But machine learning is complex. People keep telling me how complex it is and how difficult it is!
Me: True it can be, but for most problems it can be as simple as writing a few lines of code to create a model. 3-4 lines of code in some languages. But the applying of the the machine learning model can be a simple task (maybe 1 line of code), although some simple data formatting might be needed, but that is a simple task too.
You: So, how can a machine learning model be run on a mobile device?
Me: Programmers write code to run applications on mobile devices. This code can be extended to include the machine learning model. This can be used to score or label the data or do some other processing. A few lines of code. A good alternative is to create a web service to all the remove scoring of the data.
You: The programming languages used for mobile development are a bit different to most other applications. Surely those mobile device languages don’t support machine learning.
Me: You’d be surprised by what’s available.
You: OK, What languages can I try? Where can I get started?
Me: Check out Firebase ML Kit, Apple CoreML and TensorFlow Lite. Those should be more than enough for you to get started with. There are a few others. But start with those.
You. Brilliant, thank you Brendan. I’ll let you know how I get on with those.
Embedding Transformation Data Pipeline into ML Model using Oracle Data Mining
I’ve written several blog posts about how to use the DBMS_DATA_MINING.TRANSFORM function to create various data transformations and how to apply these to your data. All of these steps can be simple enough to following and re-run in a lab environment. But the real value with data science and machine learning comes when you deploy the models into production and have the ML models scoring data as it is being produced, and your applications acting upon these predictions immediately, and not some hours or days later when the data finally arrives in the lab environment.
It would be useful to be able to bundle all the transformations into the same process the create the model. The transformations and model become one, together. If this is possible, then that greatly simplifies how the ML model can be deployed into production. It then becomes a simple function or REST call. We need to keep this simple (KISS).
Using the examples from my previous blog posts performing various data transformations, the following example shows how you can bundle these up into one defined set of transformations and then embed these transformations as part of the ML model. To do this we need to define a list of transformations. We can do this using:
xform_list IN TRANSFORM_LIST DEFAULT NULL
Where TRANSFORM_LIST has the following structure:
TRANFORM_REC IS RECORD ( attribute_name VARCHAR2(4000), attribute_subname VARCHAR2(4000), expression EXPRESSION_REC, reverse_expression EXPRESSION_REC, attribute_spec VARCHAR2(4000));
You can use the DBMS_DATA_MINING.SET_TRANSFORM function to defined the transformations. The following example illustrates the transformation of converting the BOOKKEEPING_APPLICATION attribute from a number data type to a character data type.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN dbms_data_mining_transform.SET_TRANSFORM(transform_stack, 'BOOKKEEPING_APPLICATION', NULL, 'to_char(BOOKKEEPING_APPLICATION)', 'to_number(BOOKKEEPING_APPLICATION)', NULL); END;
Alternatively you can use the SET_EXPRESSION function and then create the transformation using it.
You can Stack the transforms together. Using the above example you could express a number of transformations and have these stored in the TRANSFORM_STACK variable. You can then pass this variable into your CREATE_MODEL procedure and have these transformations embedded in your ML model.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN -- Define the transformation list dbms_data_mining_transform.SET_TRANSFORM(transform_stack, 'BOOKKEEPING_APPLICATION', NULL, 'to_char(BOOKKEEPING_APPLICATION)', 'to_number(BOOKKEEPING_APPLICATION)', NULL); -- Create the data mining model DBMS_DATA_MINING.CREATE_MODEL( model_name => 'DEMO_TRANSFORM_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MINING_DATA_BUILD_V', case_id_column_name => 'cust_id', target_column_name => 'affinity_card', settings_table_name => 'demo_class_dt_settings', xform_list => transform_stack); END;
My previous blog posts showed how to create various types of transformations. These transformations were then used to create a view of the data set that included these transformations. To embed these transformations in the ML Model we need to use the STACK function. The following examples illustrate the stacking of the transformations created in the previous blog posts. These transformations are added (or stacked) to a transformation list and then added to the CREATE_MODEL function, embedding these transformations in the model.
DECLARE transform_stack dbms_data_mining_transform.TRANSFORM_LIST; BEGIN -- Stack the missing numeric transformations dbms_data_mining_transform.STACK_MISS_NUM ( miss_table_name => 'TRANSFORM_MISSING_NUMERIC', xform_list => transform_stack); -- Stack the missing categorical transformations dbms_data_mining_transform.STACK_MISS_CAT ( miss_table_name => 'TRANSFORM_MISSING_CATEGORICAL', xform_list => transform_stack); -- Stack the outlier treatment for AGE dbms_data_mining_transform.STACK_CLIP ( clip_table_name => 'TRANSFORM_OUTLIER', xform_list => transform_stack); -- Stack the normalization transformation dbms_data_mining_transform.STACK_NORM_LIN ( norm_table_name => 'MINING_DATA_NORMALIZE', xform_list => transform_stack); -- Create the data mining model DBMS_DATA_MINING.CREATE_MODEL( model_name => 'DEMO_STACKED_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MINING_DATA_BUILD_V', case_id_column_name => 'cust_id', target_column_name => 'affinity_card', settings_table_name => 'demo_class_dt_settings', xform_list => transform_stack); END;
To view the embedded transformations in your data mining model you can use the GET_MODEL_TRANSFORMATIONS function.
SELECT TO_CHAR(expression)
FROM TABLE (dbms_data_mining.GET_MODEL_TRANSFORMATIONS('DEMO_STACKED_MODEL'));
TO_CHAR(EXPRESSION)
--------------------------------------------------------------------------------
(CASE WHEN (NVL("AGE",38.892)<18) THEN 18 WHEN (NVL("AGE",38.892)>70) THEN 70 E
LSE NVL("AGE",38.892) END -18)/52
NVL("BOOKKEEPING_APPLICATION",.880667)
NVL("BULK_PACK_DISKETTES",.628)
NVL("FLAT_PANEL_MONITOR",.582)
NVL("HOME_THEATER_PACKAGE",.575333)
NVL("OS_DOC_SET_KANJI",.002)
NVL("PRINTER_SUPPLIES",1)
(CASE WHEN (NVL("YRS_RESIDENCE",4.08867)<1) THEN 1 WHEN (NVL("YRS_RESIDENCE",4.
08867)>8) THEN 8 ELSE NVL("YRS_RESIDENCE",4.08867) END -1)/7
NVL("Y_BOX_GAMES",.286667)
NVL("COUNTRY_NAME",'United States of America')
NVL("CUST_GENDER",'M')
NVL("CUST_INCOME_LEVEL",'J: 190,000 - 249,999')
NVL("CUST_MARITAL_STATUS",'Married')
NVL("EDUCATION",'HS-grad')
NVL("HOUSEHOLD_SIZE",'3')
NVL("OCCUPATION",'Exec.')
Transforming Outliers in Oracle Data Mining
In previous posts I’ve shown how to use the DBMS_DATA_MINING.TRANSFORM function to transform data is various ways including, normalization and missing data. In this post I’ll build upon these to show how to outliers can be handled.
The following example will show you how you can transform data to identify outliers and transform them. In the example, Winsorsizing transformation is performed where the outlier values are replaced by the nearest value that is not an outlier.
The transformation process takes place in three stages. For the first stage a table is created to contain the outlier transformation data. The second stage calculates the outlier transformation data and store these in the table created in stage 1. One of the parameters to the outlier procedure requires you to list the attributes you do not the transformation procedure applied to (this is instead of listing the attributes you do want it applied to). The third stage is to create a view (MINING_DATA_V_2) that contains the data set with the outlier transformation rules applied. The input data set to this stage can be the output from a previous transformation process (e.g. DATA_MINING_V).
BEGIN -- Clean-up : Drop the previously created tables BEGIN execute immediate 'drop table TRANSFORM_OUTLIER'; EXCEPTION WHEN others THEN null; END; -- Stage 1 : Create the table for the transformations -- Perform outlier treatment for: AGE and YRS_RESIDENCE -- DBMS_DATA_MINING_TRANSFORM.CREATE_CLIP ( clip_table_name => 'TRANSFORM_OUTLIER'); -- Stage 2 : Transform the categorical attributes -- Exclude the number attributes you do not want transformed DBMS_DATA_MINING_TRANSFORM.INSERT_CLIP_WINSOR_TAIL ( clip_table_name => 'TRANSFORM_OUTLIER', data_table_name => 'MINING_DATA_V', tail_frac => 0.025, exclude_list => DBMS_DATA_MINING_TRANSFORM.COLUMN_LIST ( 'affinity_card', 'bookkeeping_application', 'bulk_pack_diskettes', 'cust_id', 'flat_panel_monitor', 'home_theater_package', 'os_doc_set_kanji', 'printer_supplies', 'y_box_games')); -- Stage 3 : Create the view with the transformed data DBMS_DATA_MINING_TRANSFORM.XFORM_CLIP( clip_table_name => 'TRANSFORM_OUTLIER', data_table_name => 'MINING_DATA_V', xform_view_name => 'MINING_DATA_V_2'); END;
The view MINING_DATA_V_2 will now contain the data from the original data set transformed to process missing data for numeric and categorical data (from previous blog post), and also has outlier treatment for the AGE attribute.

You must be logged in to post a comment.