
SQL
Using SQL to create some festive Christmas Trees
Here are a few examples I found on the “great internet” of how SQL can be used to create some festive Christmas cheer and fun. See links to the original posts. Most of the examples shown below have been run on Oracle 21c Docker image, or on SQL Server or MySQL.
Our first example comes from Gerald Venzi who posted this on twitter. See later in the post for Christmas trees created using similar SQL queries.
WITH tree(lev, xmas) AS (
SELECT 1 lev, RPAD(' ', 10, ' ') || '*' xmas
FROM dual
UNION ALL
SELECT tree.lev+1,
RPAD(' ', 10-tree.lev, ' ') ||
RPAD('^', tree.lev+1, '^') ||
LPAD('^', tree.lev, '^') xmas
FROM tree
WHERE tree.lev < 10
)
SELECT ' Merry Christmas!' AS "Merry Christmas!" FROM dual
UNION ALL
SELECT xmas FROM TREE
UNION ALL
SELECT ' | |' FROM dual
UNION ALL
SELECT ' ~~/ \~~' FROM dual;
Our next example includes using Spatial Data on SQL Server to create a Christmas Tree. This example comes from Niket Kedia.
USE tempdb
GO
— Create a table
CREATE TABLE #xmasTREE (shape GEOMETRY )
–Creating the Christmas tree with stars
INSERT INTO #xmasTREE
VALUES
(‘POLYGON((4 0, 0 0, 4 2, 1 2, 4 4, 1 4, 4 6, 2 6, 5 10, 8 6, 6 6, 9 4, 6 4, 9 2, 6 2, 10 0, 4 0))’ ),
(‘POLYGON((3.5 0, 4 -1, 6 -1, 6.5 0, 3.5 0))’ ),
(‘POLYGON((5 9.5, 4.5 9.25, 4.6 9.9, 4.1 10.2, 4.8 10.2, 5 10.9, 5.2 10.2, 5.9 10.2, 5.4 9.9, 5.5 9.25, 5 9.5))’ ),
(‘POLYGON((2 5.5, 1.5 5.25, 1.6 5.9, 1.1 6.2, 1.8 6.2, 2 6.9, 2.2 6.2, 2.9 6.2, 2.4 5.9, 2.5 5.25, 2 5.5))’ ),
(‘POLYGON((8 5.5, 7.5 5.25, 7.6 5.9, 7.1 6.2, 7.8 6.2, 8 6.9, 8.2 6.2, 8.9 6.2, 8.4 5.9, 8.5 5.25, 8 5.5))’ ),
(‘POLYGON((1 3.5, 0.5 3.25, 0.6 3.9, 0.1 4.2, 0.8 4.2, 1 4.9, 1.2 4.2, 1.9 4.2, 1.4 3.9, 1.5 3.25, 1 3.5))’ ),
(‘POLYGON((9 3.5, 8.5 3.25, 8.6 3.9, 8.1 4.2, 8.8 4.2, 9 4.9, 9.2 4.2, 9.9 4.2, 9.4 3.9, 9.5 3.25, 9 3.5))’ ), (‘POLYGON((1 1.5, 0.5 1.25, 0.6 1.9, 0.1 2.2, 0.8 2.2, 1 2.9, 1.2 2.2, 1.9 2.2, 1.4 1.9, 1.5 1.25, 1 1.5))’ ), (‘POLYGON((9 1.5, 8.5 1.25, 8.6 1.9, 8.1 2.2, 8.8 2.2, 9 2.9, 9.2 2.2, 9.9 2.2, 9.4 1.9, 9.5 1.25, 9 1.5))’ ),
(‘POLYGON((0 -0.5, -0.5 -0.75, -0.4 -0.1, -0.9 0.2, -0.2 0.2, 0 0.9, 0.2 0.2, 0.9 0.2, 0.4 -0.1, 0.5 -0.75, 0 -0.5))’ ),
(‘POLYGON((10 -0.5, 9.5 -0.75, 9.6 -0.1, 9.1 0.2, 9.8 0.2, 10 0.9, 10.2 0.2, 10.9 0.2, 10.4 -0.1, 10.5 -0.75, 10 -0.5))’ ),
(‘POLYGON((5 -2, 4.5 -2, 4.5 -1, 5 -1, 5.5 -1, 5.5 -2, 5 -2))’)
–Create the “Merry Christmas” greetings
INSERT INTO #xmasTREE
VALUES (‘POLYGON((-2 11, -2 12, -1.75 12, -1.5 11.5, -1.25 12, -1 12, -1 11, -1.25 11, -1.25 11.7, -1.5 11.2, -1.75 11.7, -1.75 11, -2 11))’ ),–M
(‘POLYGON((-1 11, -1 12, 0 12, 0 11.8, -0.75 11.8, -0.75 11.6, -0.25 11.6, -0.25 11.4, -0.75 11.4, -0.75 11.2, 0 11.2, 0 11, -1 11))’ ),–E
(‘POLYGON((0 11, 0 12, 1 12, 1 11.5, 0.4 11.5, 1 11, 0.7 11, 0.2 11.4, 0.2 11, 0 11),(0.2 11.8, 0.8 11.8, 0.8 11.7, 0.2 11.7, 0.2 11.8))’ ),–R
(‘POLYGON((1 11, 1 12, 2 12, 2 11.5, 1.4 11.5, 2 11, 1.7 11, 1.2 11.4, 1.2 11, 1 11),(1.2 11.8, 1.8 11.8, 1.8 11.7, 1.2 11.7, 1.2 11.8))’ ),–R
(‘POLYGON((2 12, 2.2 12, 2.5 11.6, 2.8 12, 3 12, 2.6 11.5, 2.6 11, 2.4 11, 2.4 11.5, 2 12))’ ), –Y
(‘POLYGON((4 11, 4 12, 5 12, 5 11.8, 4.25 11.8, 4.25 11.2, 5 11.2, 5 11, 4 11))’ ),–C
(‘POLYGON((5 11, 5 12, 5.2 12, 5.2 11.6, 5.8 11.6, 5.8 12, 6 12, 6 11, 5.8 11, 5.8 11.4, 5.2 11.4, 5.2 11, 5 11))’ ),–H
(‘POLYGON((6 11, 6 12, 7 12, 7 11.5, 6.4 11.5, 7 11, 6.7 11, 6.2 11.4, 6.2 11, 6 11),(6.2 11.8, 6.8 11.8, 6.8 11.7, 6.2 11.7, 6.2 11.8))’ ),–R
(‘POLYGON((7.2 11, 7.2 11.2, 7.4 11.2, 7.4 11.8, 7.2 11.8, 7.2 12, 7.8 12, 7.8 11.8, 7.6 11.8, 7.6 11.2, 7.8 11.2, 7.8 11, 7.2 11))’ ),–I
(‘POLYGON((8 11, 8 11.2, 8.8 11.2, 8.8 11.4, 8 11.4, 8 12, 9 12, 9 11.8, 8.2 11.8, 8.2 11.6, 9 11.6, 9 11, 8 11))’ ),–S
(‘POLYGON((9 11.8, 9 12, 10 12, 10 11.8, 9.6 11.8, 9.6 11, 9.4 11, 9.4 11.8, 9 11.8))’ ),–T
(‘POLYGON((10 11, 10 12, 10.25 12, 10.5 11.5, 10.75 12, 11 12, 11 11, 10.75 11, 10.75 11.7, 10.5 11.2, 10.25 11.7, 10.25 11, 10 11))’ ),–M
(‘POLYGON((11 11, 11 12, 12 12, 12 11, 11.75 11, 11.75 11.3, 11.25 11.3, 11.25 11, 11 11),(11.25 11.5, 11.25 11.8, 11.75 11.8, 11.75 11.5, 11.25 11.5))’ ),–A
(‘POLYGON((12 11, 12 11.2, 12.8 11.2, 12.8 11.4, 12 11.4, 12 12, 13 12, 13 11.8, 12.2 11.8, 12.2 11.6, 13 11.6, 13 11, 12 11))’ )–S
–Decorate the tree with some round bell circles
DECLARE @counter INT = 0
,@x INT
,@y INT ;
WHILE ( @counter < 25 )
BEGIN
INSERT INTO #xmasTREE
VALUES (GEOMETRY::Point(RAND() * 5 + 2.5, RAND() * 8.5, 0).STBuffer(0.3) )
SET @counter+=1 ;
END
Select * from #xmasTREE
Drop table #xmasTREE
Our next example comes from StackOverflow with a similar example for MySQL.
DECLARE @g TABLE (g GEOMETRY, ID INT IDENTITY(1,1));
-- Adjust Color
INSERT INTO @g(g) SELECT TOP 29 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
-- Build Christmas Tree
INSERT INTO @g(g) VALUES (CAST('POLYGON((0 0,900 0,450 400, 0 0 ))' as geometry).STUnion(CAST('POLYGON((80 330,820 330,450 640,80 330 ))' as geometry)).STUnion(CAST('POLYGON((210 590,690 590,450 800, 210 590 ))' as geometry)));
-- Adjust Color
INSERT INTO @g(g) SELECT TOP 294 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
-- Build a Star
INSERT INTO @g(g) VALUES (CAST('POLYGON ((450 910, 465.716 861.631, 516.574 861.631, 475.429 831.738, 491.145 783.369, 450 813.262, 408.855 783.369, 424.571 831.738, 383.426 861.631, 434.284 861.631, 450 910))' as geometry));
-- Build Colored Balls
INSERT INTO @g(g) SELECT TOP 2 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
INSERT INTO @g(g) VALUES (CAST('CURVEPOLYGON (CIRCULARSTRING (80 290, 110 320, 140 290, 110 260, 80 290))' as geometry));
INSERT INTO @g(g) SELECT TOP 2 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
INSERT INTO @g(g) VALUES (CAST('CURVEPOLYGON (CIRCULARSTRING (760 290, 790 320, 820 290, 790 260, 760 290))' as geometry));
INSERT INTO @g(g) SELECT TOP 3 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
INSERT INTO @g(g) VALUES (CAST('CURVEPOLYGON (CIRCULARSTRING (210 550, 240 580, 270 550, 240 520, 210 550))' as geometry));
INSERT INTO @g(g) SELECT TOP 46 CAST('POLYGON((0 0, 0 0.0000001, 0.0000001 0.0000001, 0 0))' as geometry) FROM sys.messages;
INSERT INTO @g(g) VALUES (CAST('CURVEPOLYGON (CIRCULARSTRING (630 550, 660 580, 690 550, 660 520, 630 550))' as geometry));
SELECT g FROM @g ORDER BY ID;
GO
Connor McDonold posted the following SQL to create a Christmas Tree on StackOverflow in 2020, and wrote a blog post for it in December 2021. I just made one very very minor change to it.
You need to be careful where you run this. It runs best on/in a Linux environment, docker, VM, etc using SQL Command Line or SQL*Plus. For me, SQL Developer struggled to present the results correctly.
select replace(replace(replace(r,'X',chr(27)||'[42m'||chr(27)||'[1;'||to_char(32)||'m'||'X'||chr(27)||'[0m'),
'T',chr(27)||'[43m'||chr(27)||'[1;'||to_char(33)||'m'||'T'||chr(27)||'[0m'),
'@',chr(27)||'[33m'||chr(27)||'[1;'||to_char(31)||'m'||'@'||chr(27)||'[0m') Happy_Christmas
from ( select lpad(' ',20-e-i)|| case when dbms_random.value < 0.3 then substr(s,1,e*2-3+i*2)
else substr(substr(s,1,dbms_random.value(1,e*2-3+i*2-1))||'@'||s,1,e*2-3+i*2) end r
from ( select rpad('X',40,'X') s,rpad('T',40,'T') t from dual ) ,
( select level i, level+2 hop from dual connect by level <= 4 ) , lateral
( select level e from dual connect by level <= hop ) union all select lpad(' ',17)||substr(t,1,3)
from ( select rpad('X',40,'X') s,rpad('T',40,'T') t from dual ) connect by level <= 5 );
Next up we have a simpler Christmas Tree. This comes from Matheus Boesing and his original post on grepora.
clear screen
set feedback off;
set heading off;
set pages 80;
SELECT DECODE(SIGN(FLOOR(maxwidth / 2) - ROWNUM),
1,
LPAD(' ', FLOOR(maxwidth / 2) - (ROWNUM - 1)) ||
RPAD('*', 2 * (ROWNUM - 1) + 1, ' *'),
LPAD('* * *', FLOOR(maxwidth / 2) + 3))
FROM all_objects, (SELECT 40 AS maxwidth FROM DUAL)
WHERE ROWNUM < FLOOR(maxwidth / 2) + 5
union all select ' Happy Christmas from Brendan!' from dual;
set heading on;
set feedback on;
This next example comes from LearnSQL and is similar to the previous example, but this time we get a multiple trees.
clear screen
set feedback off;
set heading off;
set pages 80;
WITH small_tree(tree_depth,pine) AS (
SELECT 1 tree_depth,
rpad(' ',10,' ') || '*'
|| rpad(' ',20,' ') || '*'
|| rpad(' ',20,' ') || '*'
pine
FROM dual
UNION ALL
SELECT small_tree.tree_depth +1 tree_depth,
rpad(' ',10-small_tree.tree_depth,' ') || rpad('*',small_tree.tree_depth+1,'.') || lpad('*',small_tree.tree_depth,'.')
|| rpad(' ',20-small_tree.tree_depth-tree_depth,' ') || rpad('*',small_tree.tree_depth+1,'.') || lpad('*',small_tree.tree_depth,'.')
|| rpad(' ',20-small_tree.tree_depth-tree_depth,' ') || rpad('*',small_tree.tree_depth+1,'.') || lpad('*',small_tree.tree_depth,'.') pine
FROM small_tree
where small_tree.tree_depth < 10
)
SELECT rpad(' ',9,' ') ||'Ho'
|| rpad(' ',19,' ') || 'Ho'
|| rpad(' ',19,' ') || 'Ho'
pine
FROM dual
UNION ALL
SELECT pine
FROM small_tree;
set heading on;
set feedback on;
Hans Viehmann from the Oracle Spatial teams sent me this example using Oracle Spatial and Oracle Spatial Studio. The geospatial data is defined using GeoJSON. The funny coordinates are referencing the Santa Claus village near Rovaniemi in Finnish Lappland, right on the Arctic Circle. Oracle Spatial Studio can be used to view the Christmas tree on a map (see image below).
DROP TABLE XMAS_TREE_JSON;
DROP TABLE XMAS_TREE;
CREATE TABLE XMAS_TREE_JSON (
ID NUMBER(10),
DATA CLOB,
CONSTRAINT XMAS_TREE_PK PRIMARY KEY ( ID ),
CONSTRAINT XMAS_TREE_JSON_CHK CHECK ( DATA IS JSON )
);
INSERT INTO XMAS_TREE_JSON VALUES (
1,
'{
"type": "Feature",
"properties": { "label": "Tree"},
"geometry": {
"type": "Polygon",
"coordinates": [
[[25.84725335240364,
66.5437744044363],
[25.847166180610653,
66.543721555766],
[25.847235918045044,
66.5437231572425],
[25.84712728857994,
66.5436740452493],
[25.84722116589546,
66.54367564672889],
[25.847095102071762,
66.54362012871027],
[25.847205072641373,
66.54362226402098],
[25.847202390432358,
66.54361105363778],
[25.847297608852386,
66.54361212129352],
[25.847297608852386,
66.5436238655039],
[25.84740623831749,
66.5436243993315],
[25.84728017449379,
66.54367724820834],
[25.84736466407776,
66.54367724820834],
[25.847273468971252,
66.54372369106797],
[25.847321748733517,
66.54372369106797],
[25.84725335240364,
66.5437744044363]
]
]
}
}'
);
COMMIT;
CREATE TABLE XMAS_TREE
AS
SELECT
ID,
JSON_VALUE(DATA, '$.geometry' RETURNING SDO_GEOMETRY) AS SHAPE,
JSON_VALUE(DATA, '$.properties.label') AS LABEL
FROM
XMAS_TREE_JSON;
Happy Christmas everyone.
Measuring Kurtosis of Data in Oracle (21c)
Kurtosis is a new analytics function in Oracle 21c (20c) and is one of a set of commonly used statistical functions used to evaluate data to see and understand the behavior of the data.
[See my previous post where I give examples of the new Skewness functions]
Kurtosis is the measurement of the tails of the data distribution and its comparison with that of normal distribution. The Kurtosis of the normal distribution is said to be 3. To make interpenetrating results easier (a Zero) kurtosis measure for gaussian/normal distribution by subtracting 3 from its value, this is called Excess Kurtosis. Kurtosis can be used to describe the height or the breath of the distributions, when compared to a normal distributions, although this is not theoretically correct, it gives a simpler explanation and visualization of it. The following diagram gives an example of a normal distribution, a plot of Positive Kurtosis and Negative Kurtosis.

Prior to the new Kurtosis SQL functions (KURTOSIS_POP and KURTOSIS_SAMP), you had to calculate the Kurtosis value manually using something like the following SQL. These use the same data and attributes set used for the Skewness examples.
select avg(KV) K_value
from (select power((age - avg(age) over ())/stddev(age) over (), 4) KV
from cust_data)
union all
select avg(KV) K_value
from (select power((duration - avg(duration) over ())/stddev(duration) over (), 4) KV
from cust_data);
K_value
------------------------------------------
3.79088571963003808388287765230733611415
23.24420570926391173498028369605428048285
These don’t include the subtraction of 3 to give a zero kurtosis, and these values can be compared to the data distribution charts shown in the Skewness post.
Now with the new Kurtosis functions it simplifies the tasks of getting these values.
SELECT kurtosis_pop(age), kurtosis_samp(age) FROM bank_additional union all SELECT kurtosis_pop(duration), kurtosis_samp(duration) FROM bank_additional; KURTOSIS_POP KURTOSIS_SAMP ------------------ ----------------------------------------- 0.791069803527387 0.79131153115443467194451597661213420763 20.245334438614832 20.24793801497878942299945619307526969226
As you can see the Kurtosis function have the subtraction include.
As with the Skewness functions, the SAMP version works on a sample of the data values and as the number inputs increases, and differences between the POP and SAMP will reduce.
Measuring Skewness of Data in Oracle (21c)
When analyzing data you will look at using a variety of different statistical functions to explore variable data insights.
One of these is the Skewness of the data.
Skewness is a measure of the asymmetry of the probability distribution about its mean. This looks a the tail of the data, with a positive value indicating the tail on the right side of the distribution, and a negative value when the tail is on the left hand side. A zero value indicates the tails on both side balance out, as shown in the following image.
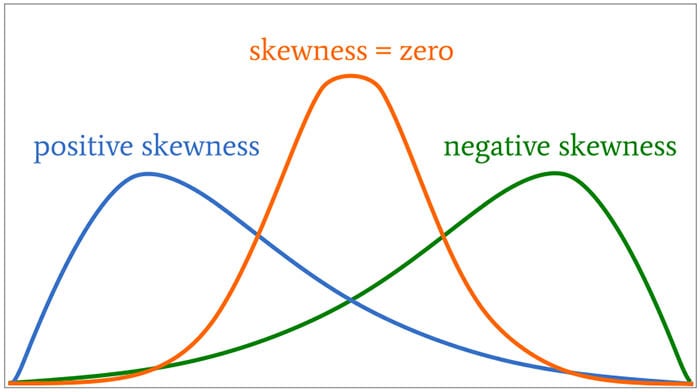
Most SQL dialects support Skewness using with an inbuilt function. But if it doesn’t then you would need to write your own version of the calculation, for example using the following.
SELECT avg(SV) S_value
FROM (SELECT power((age – avg(age) over ())/stddev(age) over (), 3) SV
FROM cust_data)
Here are charts illustrating the data in my table. These include the distributions for the AGE and DURATION attributes.
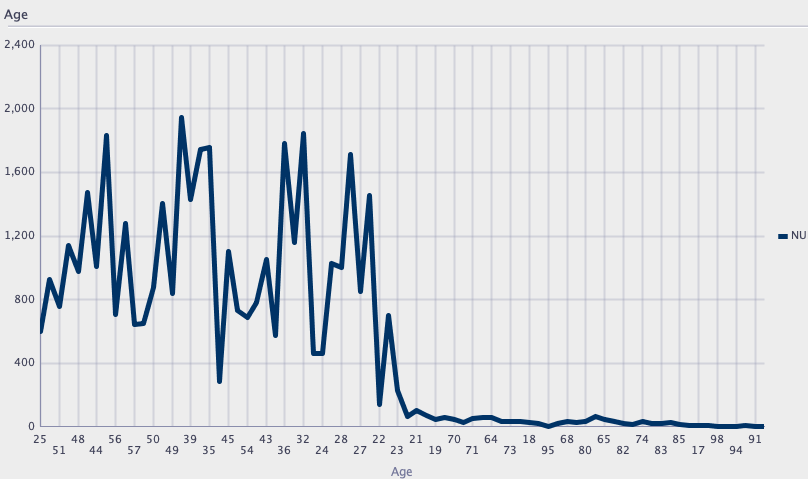

We can see the data is skewed. When we run the above code we get the following values.
Age = 0.78
Duration = 3.26
We can see the skewness of Duration is significantly longer, giving a positive value as the skewness is to the right.
In Oracle 21s we now have new Skewness functions called SKEWNESS_POP and SKEWNESS_SAMP. The POP version of the function considers all records, where as the SAMP function considers a sample of the records. When your data set grows into many millions of records the SKEWNESS_SAMP will give a quicker response as it works with a sample of the data set
Both functions will give similar values but at the number of input records the returned values will returned will converge.
SELECT skewness_pop(age), skewness_samp(age) FROM cust_data;
SELECT skewness_pop(duration), skewness_samp(duration) FROM cust_data;

Adding Text Processing to Classification Machine Learning in Oracle Machine Learning
One of the typical machine learning functions is Classification. This is in widespread use across most domains and geographic regions. I’ve written several blog posts on this topic over many years (and going back many, many year) on how to do this using Oracle Machine Learning (OML) (formally known as Oracle Advanced Analytic and in the Oracle Data Miner tool in SQL Developer). Just do a quick search of my blog to find some of these posts.
When it comes to Classification problems, typically the data set will be contain your typical categorical and numerical variables/features. The Automatic Data Preparation (ADP) feature of OML where it automatically pre-processes and transforms these variable for input to the machine learning algorithm. This greatly reduces the boring work of the data scientist and increases their productivity.
But sometimes data sets come with text descriptions. These will contain production descriptions, free format text, and other descriptive data, for example product reviews. But how can this information be included as part of the input data set to the machine learning algorithms. Oracle allows this kind of input data, and a letting bit of setup is needed to tell Oracle how to process the data set. This uses the in-database feature of Oracle Text.
The following example walks through an example of the steps needed to pre-process and include the text processing as part of the machine learning algorithm.
The data set: The data used to illustrate this and to show the steps needed, is a data set from Kaggle webiste. This data set contains 130K Wine Reviews. This data set contain descriptive information of the wine with attributes about each wine including country, region, number of points, price, etc as well as a text description contain a review of the wine.
The following are 2 files containing the DDL (to create the table) and then Import the data set (using sql script with insert statements). These can be run in your schema (in order listed below).
I’ll leave the Data Exploration to you to do and to discover some early insights.
The ML Question
I want to be able to predict if a wine is a good quality wine, based on the prices and different characteristics of the wine?
Data Preparation
To be able to answer this question the first thing needed is to define a target variable to identify good and bad wines. To do this create a new attribute/feature called POINTS_BIN and populate it based on the number of points a wine has. If it has >90 points it is a good wine, if <90 points it is a bad wine.
ALTER TABLE WineReviews130K_bin ADD POINTS_BIN VARCHAR2(15);
UPDATE WineReviews130K_bin
SET POINTS_BIN = 'GT_90_Points'
WHERE winereviews130k_bin.POINTS >= 90;
UPDATE WineReviews130K_bin
SET POINTS_BIN = 'LT_90_Points'
WHERE winereviews130k_bin.POINTS < 90;
alter table WineReviews130K_bin DROP COLUMN POINTS;
The DESCRIPTION column data type needs to be changed to CLOB. This is to allow the Text Mining feature to work correctly.
-- add a new column of data type CLOB
ALTER TABLE WineReviews130K_bin ADD (DESCRIPTION_NEW CLOB);
-- update new column with data from the DESCRIPTION attribute
UPDATE WineReviews130K_bin SET DESCRIPTION_NEW = DESCRIPTION;
-- drop the DESCRIPTION attribute from table
ALTER TABLE WineReviews130K_bin DROP COLUMN DESCRIPTION;
-- rename the new attribute to replace DESCRIPTION
ALTER TABLE WineReviews130K_bin RENAME COLUMN DESCRIPTION_NEW TO DESCRIPTION;
Text Mining Configuration
There are a number of things we need to define for the Text Mining to work, these include a Lexer, Stop Word list and preferences.
First define the Lexer to use. In this case we will use a basic one and basic settings
BEGIN ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); ctx_ddl.set_attribute ( 'mylex', 'index_themes', 'NO'); ctx_ddl.set_attribute ( 'mylex', 'index_text', 'YES'); END;
Next we can define a Stop Word List. Oracle Text comes with a predefined set of Stop Word lists for most of the common languages. You can add to one of those list or create your own. Depending on the domain you are working in it might be easier to create your own and it is very straight forward to do. For example:
DECLARE v_stoplist_name varchar2(100); BEGIN v_stoplist_name := 'mystop'; ctx_ddl.create_stoplist(v_stoplist_name, 'BASIC_STOPLIST'); ctx_ddl.add_stopword(v_stoplist_name, 'nonetheless'); ctx_ddl.add_stopword(v_stoplist_name, 'Mr'); ctx_ddl.add_stopword(v_stoplist_name, 'Mrs'); ctx_ddl.add_stopword(v_stoplist_name, 'Ms'); ctx_ddl.add_stopword(v_stoplist_name, 'a'); ctx_ddl.add_stopword(v_stoplist_name, 'all'); ctx_ddl.add_stopword(v_stoplist_name, 'almost'); ctx_ddl.add_stopword(v_stoplist_name, 'also'); ctx_ddl.add_stopword(v_stoplist_name, 'although'); ctx_ddl.add_stopword(v_stoplist_name, 'an'); ctx_ddl.add_stopword(v_stoplist_name, 'and'); ctx_ddl.add_stopword(v_stoplist_name, 'any'); ctx_ddl.add_stopword(v_stoplist_name, 'are'); ctx_ddl.add_stopword(v_stoplist_name, 'as'); ctx_ddl.add_stopword(v_stoplist_name, 'at'); ctx_ddl.add_stopword(v_stoplist_name, 'be'); ctx_ddl.add_stopword(v_stoplist_name, 'because'); ctx_ddl.add_stopword(v_stoplist_name, 'been'); ctx_ddl.add_stopword(v_stoplist_name, 'both'); ctx_ddl.add_stopword(v_stoplist_name, 'but'); ctx_ddl.add_stopword(v_stoplist_name, 'by'); ctx_ddl.add_stopword(v_stoplist_name, 'can'); ctx_ddl.add_stopword(v_stoplist_name, 'could'); ctx_ddl.add_stopword(v_stoplist_name, 'd'); ctx_ddl.add_stopword(v_stoplist_name, 'did'); ctx_ddl.add_stopword(v_stoplist_name, 'do'); ctx_ddl.add_stopword(v_stoplist_name, 'does'); ctx_ddl.add_stopword(v_stoplist_name, 'either'); ctx_ddl.add_stopword(v_stoplist_name, 'for'); ctx_ddl.add_stopword(v_stoplist_name, 'from'); ctx_ddl.add_stopword(v_stoplist_name, 'had'); ctx_ddl.add_stopword(v_stoplist_name, 'has'); ctx_ddl.add_stopword(v_stoplist_name, 'have'); ctx_ddl.add_stopword(v_stoplist_name, 'having'); ctx_ddl.add_stopword(v_stoplist_name, 'he'); ctx_ddl.add_stopword(v_stoplist_name, 'her'); ctx_ddl.add_stopword(v_stoplist_name, 'here'); ctx_ddl.add_stopword(v_stoplist_name, 'hers'); ctx_ddl.add_stopword(v_stoplist_name, 'him'); ctx_ddl.add_stopword(v_stoplist_name, 'his'); ctx_ddl.add_stopword(v_stoplist_name, 'how'); ctx_ddl.add_stopword(v_stoplist_name, 'however'); ctx_ddl.add_stopword(v_stoplist_name, 'i'); ctx_ddl.add_stopword(v_stoplist_name, 'if'); ctx_ddl.add_stopword(v_stoplist_name, 'in'); ctx_ddl.add_stopword(v_stoplist_name, 'into'); ctx_ddl.add_stopword(v_stoplist_name, 'is'); ctx_ddl.add_stopword(v_stoplist_name, 'it'); ctx_ddl.add_stopword(v_stoplist_name, 'its'); ctx_ddl.add_stopword(v_stoplist_name, 'just'); ctx_ddl.add_stopword(v_stoplist_name, 'll'); ctx_ddl.add_stopword(v_stoplist_name, 'me'); ctx_ddl.add_stopword(v_stoplist_name, 'might'); ctx_ddl.add_stopword(v_stoplist_name, 'my'); ctx_ddl.add_stopword(v_stoplist_name, 'no'); ctx_ddl.add_stopword(v_stoplist_name, 'non'); ctx_ddl.add_stopword(v_stoplist_name, 'nor'); ctx_ddl.add_stopword(v_stoplist_name, 'not'); ctx_ddl.add_stopword(v_stoplist_name, 'of'); ctx_ddl.add_stopword(v_stoplist_name, 'on'); ctx_ddl.add_stopword(v_stoplist_name, 'one'); ctx_ddl.add_stopword(v_stoplist_name, 'only'); ctx_ddl.add_stopword(v_stoplist_name, 'onto'); ctx_ddl.add_stopword(v_stoplist_name, 'or'); ctx_ddl.add_stopword(v_stoplist_name, 'our'); ctx_ddl.add_stopword(v_stoplist_name, 'ours'); ctx_ddl.add_stopword(v_stoplist_name, 's'); ctx_ddl.add_stopword(v_stoplist_name, 'shall'); ctx_ddl.add_stopword(v_stoplist_name, 'she'); ctx_ddl.add_stopword(v_stoplist_name, 'should'); ctx_ddl.add_stopword(v_stoplist_name, 'since'); ctx_ddl.add_stopword(v_stoplist_name, 'so'); ctx_ddl.add_stopword(v_stoplist_name, 'some'); ctx_ddl.add_stopword(v_stoplist_name, 'still'); ctx_ddl.add_stopword(v_stoplist_name, 'such'); ctx_ddl.add_stopword(v_stoplist_name, 't'); ctx_ddl.add_stopword(v_stoplist_name, 'than'); ctx_ddl.add_stopword(v_stoplist_name, 'that'); ctx_ddl.add_stopword(v_stoplist_name, 'the'); ctx_ddl.add_stopword(v_stoplist_name, 'their'); ctx_ddl.add_stopword(v_stoplist_name, 'them'); ctx_ddl.add_stopword(v_stoplist_name, 'then'); ctx_ddl.add_stopword(v_stoplist_name, 'there'); ctx_ddl.add_stopword(v_stoplist_name, 'therefore'); ctx_ddl.add_stopword(v_stoplist_name, 'these'); ctx_ddl.add_stopword(v_stoplist_name, 'they'); ctx_ddl.add_stopword(v_stoplist_name, 'this'); ctx_ddl.add_stopword(v_stoplist_name, 'those'); ctx_ddl.add_stopword(v_stoplist_name, 'though'); ctx_ddl.add_stopword(v_stoplist_name, 'through'); ctx_ddl.add_stopword(v_stoplist_name, 'thus'); ctx_ddl.add_stopword(v_stoplist_name, 'to'); ctx_ddl.add_stopword(v_stoplist_name, 'too'); ctx_ddl.add_stopword(v_stoplist_name, 'until'); ctx_ddl.add_stopword(v_stoplist_name, 've'); ctx_ddl.add_stopword(v_stoplist_name, 'very'); ctx_ddl.add_stopword(v_stoplist_name, 'was'); ctx_ddl.add_stopword(v_stoplist_name, 'we'); ctx_ddl.add_stopword(v_stoplist_name, 'were'); ctx_ddl.add_stopword(v_stoplist_name, 'what'); ctx_ddl.add_stopword(v_stoplist_name, 'when'); ctx_ddl.add_stopword(v_stoplist_name, 'where'); ctx_ddl.add_stopword(v_stoplist_name, 'whether'); ctx_ddl.add_stopword(v_stoplist_name, 'which'); ctx_ddl.add_stopword(v_stoplist_name, 'while'); ctx_ddl.add_stopword(v_stoplist_name, 'who'); ctx_ddl.add_stopword(v_stoplist_name, 'whose'); ctx_ddl.add_stopword(v_stoplist_name, 'why'); ctx_ddl.add_stopword(v_stoplist_name, 'will'); ctx_ddl.add_stopword(v_stoplist_name, 'with'); ctx_ddl.add_stopword(v_stoplist_name, 'would'); ctx_ddl.add_stopword(v_stoplist_name, 'yet'); ctx_ddl.add_stopword(v_stoplist_name, 'you'); ctx_ddl.add_stopword(v_stoplist_name, 'your'); ctx_ddl.add_stopword(v_stoplist_name, 'yours'); ctx_ddl.add_stopword(v_stoplist_name, 'drink'); ctx_ddl.add_stopword(v_stoplist_name, 'flavors'); ctx_ddl.add_stopword(v_stoplist_name, '2020'); ctx_ddl.add_stopword(v_stoplist_name, 'now'); END;
Next define the preferences for processing the Text, for example what Stop Word list to use, if Fuzzy match is to be used and what language to use for this, number of tokens/words to process and if stemming is to be used.
BEGIN ctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('mywordlist','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('mywordlist','FUZZY_SCORE','1'); ctx_ddl.set_attribute('mywordlist','FUZZY_NUMRESULTS','5000'); ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX','TRUE'); ctx_ddl.set_attribute('mywordlist','STEMMER','ENGLISH'); END;
And the final step is to piece it all together by defining a new Text policy
BEGIN ctx_ddl.create_policy('my_policy', NULL, NULL, 'mylex', 'mystop', 'mywordlist'); END;
Define Settings for OML Model
We will create two models. An Attribute Importance model and a Classification model. The following defines the model parameters for each of these.
CREATE TABLE att_import_model_settings (setting_name varchar2(30), setting_value varchar2(30)); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ALGO_NAME'', ''ALGO_AI_MDL''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''PREP_AUTO'', ''ON''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_POLICY_NAME'', ''my_policy''); INSERT INTO att_import_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_MAX_FEATURES'', ''3000'')';
CREATE TABLE wine_model_settings (setting_name varchar2(30), setting_value varchar2(30)); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ALGO_NAME'', ''ALGO_RANDOM_FOREST''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''PREP_AUTO'', ''ON''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_POLICY_NAME'', ''my_policy''); INSERT INTO wine_model_settings (setting_name, setting_value) VALUES (''ODMS_TEXT_MAX_FEATURES'', ''3000'')';
Create the Training and Test data sets.
CREATE TABLE wine_train_data AS SELECT id, country, description, designation, points_bin, price, province, region_1, region_2, taster_name, variety, title FROM winereviews130k_bin SAMPLE (60) SEED (1);
CREATE TABLE wine_test_data AS SELECT id, country, description, designation, points_bin, price, province, region_1, region_2, taster_name, variety, title FROM winereviews130k_bin WHERE id NOT IN (SELECT id FROM wine_train_data);
All the set up is done, we can move onto the creating the machine learning models.
Create the OML Model (Attribute Importance & Classification)
We are going to create two models. The first is an Attribute Important model. This will look at the data set and will determine what attributes contribute most towards determining the target variable. As we are incorporting Texting Mining we will see what words/tokens from the DESCRIPTION attribute also contribute towards the target variable.
BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'GOOD_WINE_AI', mining_function => DBMS_DATA_MINING.ATTRIBUTE_IMPORTANCE, data_table_name => 'winereviews130k_bin', case_id_column_name => 'ID', target_column_name => 'POINTS_BIN', settings_table_name => 'att_import_mode_settings'); END;
We can query the system views for Oracle ML to find out what are the important variables.
SELECT * FROM dm$vagood_wine_ai ORDER BY attribute_rank;
Here is the listing of the top 15 most important attributes. We can see from the first 15 rows and looking under column ATTRIBUTE_SUBNAME, the words from the DESCRIPTION attribute that seem to be important and contribute towards determining the value in the target attribute.

At this point you might determine, based on domain knowledge, some of these words should be excluded as they are generic for the domain. In this case, go back to the Stop Word List and recreate it with any additional words. This can be repeated until you are happy with the list. In this example, WINE could be excluded by including it in the Stop Word List.
Run the following to create the Classification model. It is very similar to what we ran above with minor changes to the name of the model, the data mining function and the name of the settings table.
BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'GOOD_WINE_MODEL', mining_function => DBMS_DATA_MINING.CLASSIFICATION, data_table_name => 'winereviews130k_bin', case_id_column_name => 'ID', target_column_name => 'POINTS_BIN', settings_table_name => 'wine_model_settings'); END;
Apply OML Model
The model can be applied in similar ways to any other ML model created using OML. For example the following displays the wine details along with the predicted points bin values (good or bad) and the probability score (<=1) of the prediction.
SELECT id, price, country, designation, province, variety, points_bin, PREDICTION(good_wine_mode USING *) pred_points_bin, PREDICTION_PROBABILITY(good_wine_mode USING *) prob_points_bin FROM wine_test_data;
Enhanced Window Clause functionality in Oracle 21c (20c)
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
The Oracle Database has had advanced analytical functions for some time now and with each release we get to have some new additions or some enhancements to existing functionality.
One new enhancement, available and documented in 21c (not yet released at time of writing this), is changing in the way the Window Clause can be defined for analytic functions. Oracle 21c is available on Oracle Cloud as a pre-release for evaluation purposes (but it won’t be available for much longer!). The examples shown below are based on using this 21c pre-release of the database.
NOTE: At this point, no one really knows when or if 20c will be released. I’m sure all the documented 20c new features will be rolled into 21c, whenever that will be released.
Before giving some examples of the new Window Clause functionality, lets have a quick recap on how we could use it up to now (up to 19c database). Here is a simple example of windowing the data by creating partitions based on the distinct values in DEPTNO column
select deptno,
ename,
job,
salary,
avg (salary) over (partition by DEPTNO) avg_sal
from employee
order by deptno;

Here we get to see the average salary being calculated for each window partition and being reset for the next windwo partition.
The SQL:2011 standard support the defining of the Window clause in the query block, after defining the list tables for the query. This allows us to define the window clause one and then reference this for analytic function that need it. The following example illustrate this. I’ve take the able query and altered it to have the newer syntax. I’ve highlighted the new or changed code in blue. In the analytic function, the w1 refers to the Window clause defined later, and is more in keeping with how a query is logically processed.
select deptno,
ename,
sal,
sum(sal) over (w1) sum_sal
from emp
window w1 as (partition by deptno);
As you would expect we get the same results returned.
This newer syntax is particularly useful when we have many more analytic function in our queries, and some of these are using slightly different windowing. To me it makes it easier to read and to make edits, allowing an edit to be preformed once instead of for each analytic function, and avoids any errors. But making it easier to read and understand is by far the greatest benefit. Here is another example which uses different window clauses using the previous syntax.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (PARTITION BY deptno ORDER BY sal) AS avg_dept_sal,
AVG(sal) OVER (PARTITION BY deptno ) AS avg_dept_sal2,
SUM(sal) OVER (PARTITION BY deptno ORDER BY sal desc) AS sum_dept_sal
FROM emp;
Using the newer syntax this gets transformed into the following.
SELECT deptno,
ename,
sal,
AVG(sal) OVER (w1) AS avg_dept_sal,
AVG(sal) OVER (w2) AS avg_dept_sal2,
SUM(sal) OVER (w2) AS avg_dept_sal
FROM emp
window w1 as (PARTITION BY deptno ORDER BY sal),
w2 as (PARTITION BY deptno),
w3 as (PARTITION BY deptno ORDER BY sal desc);
Partitioned Models – Oracle Machine Learning (OML)
Building machine learning models can be a relatively trivial task. But getting to that point and understanding what to do next can be challenging. Yes the task of creating a model is simple and usually takes a few line of code. This is what is shown in most examples. But when you try to apply to real world problems we are faced with other challenges. Some of which include volume of data is larger, building efficient ML pipelines is challenging, time to create models gets longer, applying models to new data in real-time takes longer (not possible in real-time), etc. Yes these are typically challenges and most of these can be easily overcome.
When building ML solutions for real-world problem you will be faced with building (and deploying) many 10s or 100s of ML models. Why are so many models needed? Almost every example we see for ML takes the entire data set and build a model on that data. When you think about it, not everyone in the data set can be considered in the same grouping (similar characteristics). If we were to build a model on the data set and apply it to new data, we will get a generic prediction. A prediction comparing the new data item (new customer, purchase, etc) with everyone else in the data population. Maybe this is why so many ML project fail as they are building generic solution that performs badly when run on new (and evolving) data.
To overcome this we start to look at the different groups of data in the data set. Can the data set be divided into a number of different parts based on some characteristics. If we could do this and build a separate model on each group (or cluster), then we would have ML models that would be more accurate with their predictions. This is where we will end up creating 10s or 100s of models. As you can imagine the work involved in doing this with be LOTs. Then think about all the coding needed to manage all of this. What about the complexity of all the code needed for making the predictions on new data.
Yes all of this gets complex very, very quickly!
Ideally we want a separate model for each group
But how can you do that efficiently? is it possible?
When working with Oracle Machine Learning, you can use a feature called partitioned models. Partitioned Models are designed to handle this type of problem. They are designed to:
- make the building of models simple
- scales as the data and number of partitions increase
- includes all the steps part of the ML pipeline (all the data prep, transformations, etc)
- make predicting new data using the ML model simple
- make the deployment of the ML model easy
- make the MLOps process simple
- make the use of ML model easy to use by all developers no matter the programming language
- make the ML model build and ML model scoring quick and with better, more accurate predictions.

Let us work through an example. In this example lets start by creating a Random Forest ML model using the entire data set. The following code shows setting up the Parameters settings table. The second code segment creates the Random Forest ML model. The training data set being used in this example contains 72,000 records.
BEGIN
DELETE FROM BANKING_RF_SETTINGS;
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest);
INSERT INTO banking_RF_settings (setting_name, setting_value)
VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on);
COMMIT;
END;
/
-- Create the ML model
DECLARE
v_start_time TIMESTAMP;
BEGIN
DBMS_DATA_MINING.DROP_MODEL('BANKING_RF_72K_1');
v_start_time := current_timestamp;
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'BANKING_RF_72K_1',
mining_function => dbms_data_mining.classification,
data_table_name => 'BANKING_72K',
case_id_column_name => 'ID',
target_column_name => 'TARGET',
settings_table_name => 'BANKING_RF_SETTINGS');
dbms_output.put_line('Time take to create model = ' || to_char(extract(second from (current_timestamp-v_start_time))) || ' seconds.');
END;
/
This is the basic setup and the following table illustrates how long the CREATE_MODEL function takes to run for different sizes of training datasets and with different number of trees per model. The default number of trees is 20.
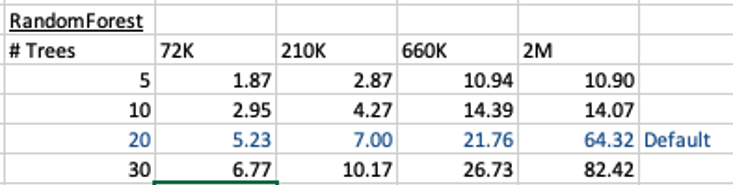
To run this model against new data we could use something like the following SQL query.
SELECT cust_id, target, prediction(BANKING_RF_72K_1 USING *) predicted_value, prediction_probability(BANKING_RF_72K_1 USING *) probability FROM bank_test_v;
This is simple and straight forward to use.
For the 72,000 records it takes just approx 5.23 seconds to create the model, which includes creating 20 Decision Trees. As mentioned earlier, this will be a generic model covering the entire data set.
To create a partitioned model, we can add new parameter which lists the attributes to use to partition the data set. For example, if the partition attribute is MARITAL, we see it has four different values. This means when this attribute is used as the partition attribute, Oracle Machine Learning will create four separate sub Random Forest models all until the one umbrella model. This means the above SQL query to run the model, does not change and the correct sub model will be selected to run on the data based on the value of MARITAL attribute.
To create this partitioned model you need to add the following to the settings table.
BEGIN DELETE FROM BANKING_RF_SETTINGS; INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_random_forest); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL’); COMMIT; END; /
The code to create the model remains the same!
The code to call and use the model remains the same!
This keeps everything very simple and very easy to use.
When I ran the CREATE_MODEL code for the partitioned model, it took approx 8.3 seconds to run. Yes it took slightly longer than the previous example, but this time it is creating four models instead of one. This is still very quick!
What if I wanted to add more attributes to the partition key? Yes you can do that. The more attributes you add, the more sub-models will be be created.
For example, if I was to add JOB attribute to the partition key list. I will now get 48 sub-models (with 20 Decision Trees each) being created. The JOB attribute has 12 distinct values, multiplied by the 4 values for MARITAL, gives us 48 models.
INSERT INTO banking_RF_settings (setting_name, setting_value) VALUES (dbms_data_mining.odms_partition_columns, 'MARITAL,JOB');
How long does this take the CREATE_MODEL code to run? approx 37 seconds!
Again that is quick!
Again remember the code to create the model and to run the model to predict on new data does not change. This means our applications using this ML model does not change. This shows us we can very easily increase the predictive accuracy of our models with only adding one additional model, and by improving this accuracy by adding more attributes to the partition key.
But you do need to be careful with what attributes to include in the partition key. If the attributes have a very high number of distinct values, will result in 100s, or 1000s of sub models being created.
An important benefit of using partitioned models is when a new distinct value occurs in one of the partition key attributes. You code to create the parameters and models does not change. OML will automatically will pick this up and do all the work under the hood.
XGBoost in Oracle 20c
 Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Another of the new machine learning algorithms in Oracle 21c Database is called XGBoost. Most people will have come across this algorithm due to its recent popularity with winners of Kaggle competitions and other similar events.
XGBoost is an open source software library providing a gradient boosting framework in most of the commonly used data science, machine learning and software development languages. It has it’s origins back in 2014, but the first official academic publication on the algorithm was published in 2016 by Tianqi Chen and Carlos Guestrin, from the University of Washington.
The algorithm builds upon the previous work on Decision Trees, Bagging, Random Forest, Boosting and Gradient Boosting. The benefits of using these various approaches are well know, researched, developed and proven over many years. XGBoost can be used for the typical use cases of Classification including classification, regression and ranking problems. Check out the original research paper for more details of the inner workings of the algorithm.
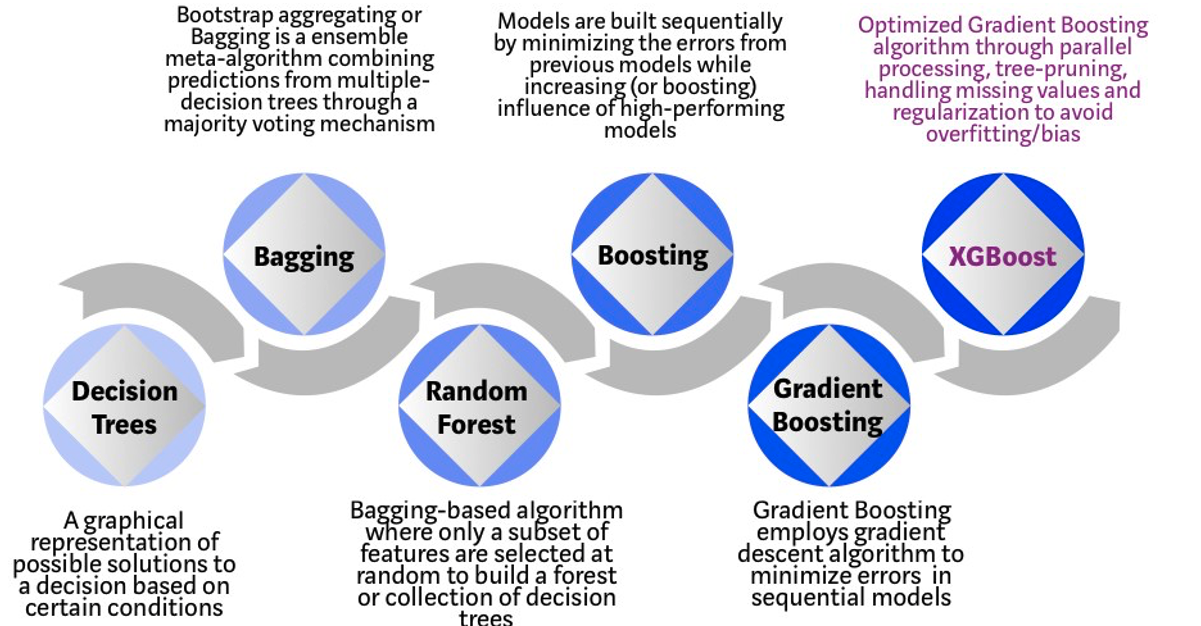
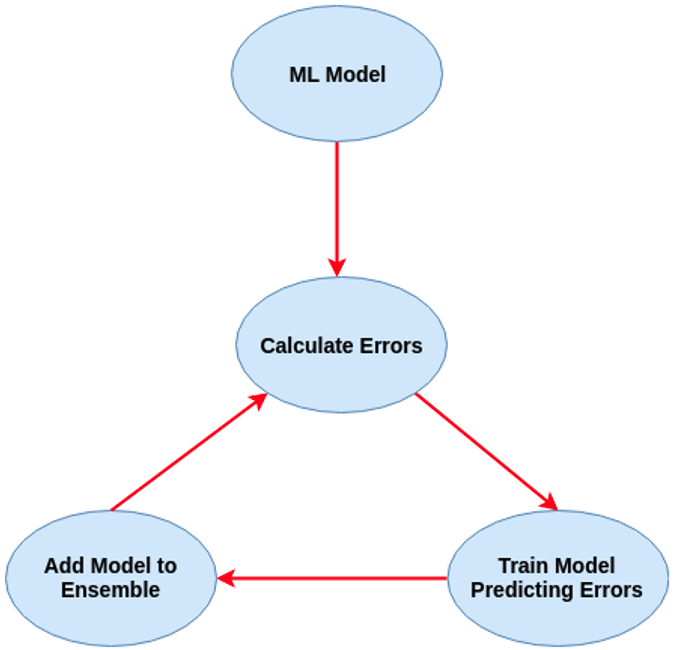 Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
Regular machine learning models, like Decision Trees, simply train a single model using a training data set, and only this model is used for predictions. Although a Decision Tree is very simple to create (and very very quick to do so) its predictive power may not be as good as most other algorithms, despite providing model explainability. To overcome this limitation ensemble approaches can be used to create multiple Decision Trees and combines these for predictive purposes. Bagging is an approach where the predictions from multiple DT models are combined using majority voting. Building upon the bagging approach Random Forest uses different subsets of features and subsets of the training data, combining these in different ways to create a collection of DT models and presented as one model to the user. Boosting takes a more iterative approach to refining the models by building sequential models with each subsequent model is focused on minimizing the errors of the previous model. Gradient Boosting uses gradient descent algorithm to minimize errors in subsequent models. Finally with XGBoost builds upon these previous steps enabling parallel processing, tree pruning, missing data treatment, regularization and better cache, memory and hardware optimization. It’s commonly referred to as gradient boosting on steroids.
The following three images illustrates the differences between Decision Trees, Random Forest and XGBoost.
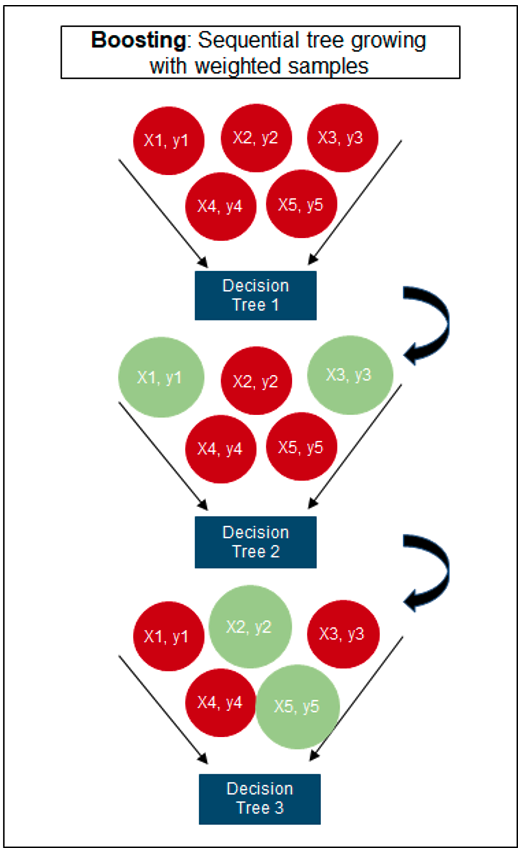
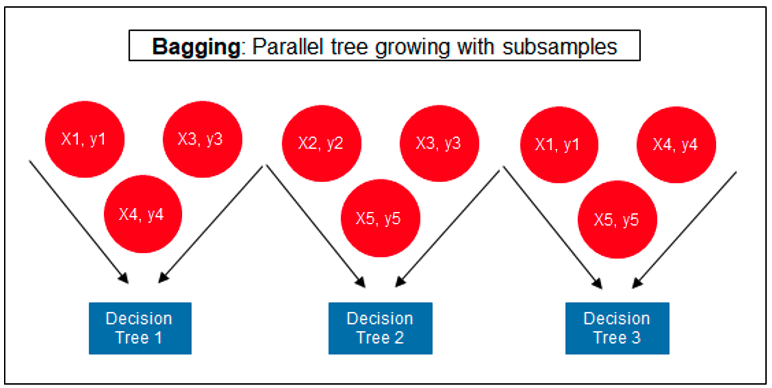
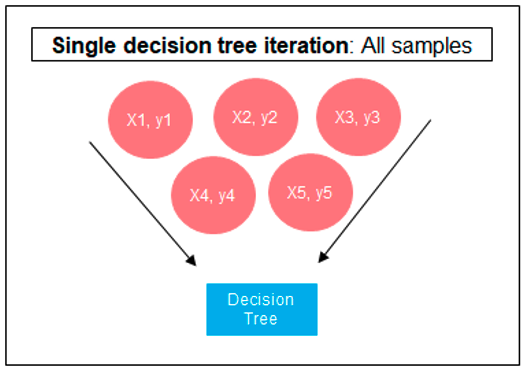
The XGBoost algorithm in Oracle 20c has over 40 different parameter settings, and with most scenarios the default settings with be fine for most scenarios. Only after creating a baseline model with the details will you look to explore making changes to these. Some of the typical settings include:
- Booster = gbtree
- #rounds for boosting = 10
- max_depth = 6
- num_parallel_tree = 1
- eval_metric = Classification error rate or RMSE for regression
As with most of the Oracle in-database machine learning algorithms, the setup and defining the parameters is really simple. Here is an example of minimum of parameter settings that needs to be defined.
BEGIN -- delete previous setttings DELETE FROM banking_xgb_settings; INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_xgboost); -- For 0/1 target, choose binary:logistic as the objective. INSERT INTO BANKING_XGB_SETTINGS (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_objective, 'binary:logistic’); commit; END;
To create an XGBoost model run the following. BEGIN DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'BANKING_XGB_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'BANKING_72K', case_id_column_name => 'ID', target_column_name => 'TARGET', settings_table_name => 'BANKING_XGB_SETTINGS'); END;
That’s all nice and simple, as it should be, and the new model can be called in the same manner as any of the other in-database machine learning models using functions like PREDICTION, PREDICTION_PROBABILITY, etc.
One of the interesting things I found when experimenting with XGBoost was the time it took to create the completed model. Using the default settings the following table gives the time taken, in seconds to create the model.

As you can see it is VERY quick even for large data sets and gives greater predictive accuracy.
MSET (Multivariate State Estimation Technique) in Oracle 20c
Updated: Changed 20c to Oracle 21c, as Oracle 20c Database never really existed 🙂
Oracle 21c Database comes with some new in-database Machine Learning algorithms.
The short name for one of these is called MSET or Multivariate State Estimation Technique. That’s the simple short name. The more complete name is Multivariate State Estimation Technique – Sequential Probability Ratio Test. That is a long name, and the reason is it consists of two algorithms. The first part looks at creating a model of the training data, and the second part looks at how new data is statistical different to the training data.
What are the use cases for this algorithm? This algorithm can be used for anomaly detection.

Anomaly Detection, using algorithms, is able identifying unexpected items or events in data that differ to the norm. It can be easy to perform some simple calculations and graphics to examine and present data to see if there are any patterns in the data set. When the data sets grow it is difficult for humans to identify anomalies and we need the help of algorithms.
The images shown here are easy to analyze to spot the anomalies and it can be relatively easy to build some automated processing to identify these. Most of these solutions can be considered AI (Artificial Intelligence) solutions as they mimic human behaviors to identify the anomalies, and these example don’t need deep learning, neural networks or anything like that.
Other types of anomalies can be easily spotted in charts or graphics, such as the chart below.
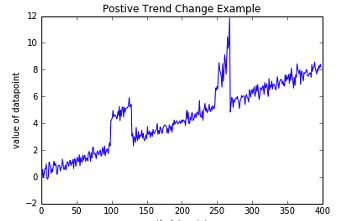
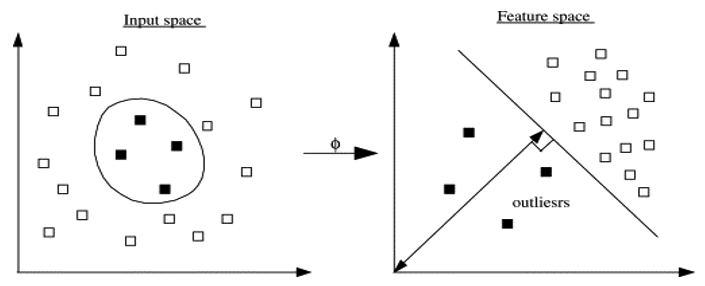 There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
There are many different algorithms available for anomaly detection, and the Oracle Database already has an algorithm called the One-Class Support Vector Machine. This is a variant of the main Support Vector Machine (SVD) algorithm, which maps or transforms the data, using a Kernel function, into space such that the data belonging to the class values are transformed by different amounts. This creates a Hyperplane between the mapped/transformed values and hopefully gives a large margin between the mapped/transformed points. This is what makes SVD very accurate, although it does have some scaling limitations. For a One-Class SVD, a similar process is followed. The aim is for anomalous data to be mapped differently to common or non-anomalous data, as shown in the following diagram.
Getting back to the MSET algorithm. Remember it is a 2-part algorithm abbreviated to MSET. The first part is a non-linear, nonparametric anomaly detection algorithm that calibrates the expected behavior of a system based on historical data from the normal sequence of monitored signals. Using data in time series format (DATE, Value) the training data set contains data consisting of “normal” behavior of the data. The algorithm creates a model to represent this “normal”/stationary data/behavior. The second part of the algorithm compares new or live data and calculates the differences between the estimated and actual signal values (residuals). It uses Sequential Probability Ratio Test (SPRT) calculations to determine whether any of the signals have become degraded. As you can imagine the creation of the training data set is vital and may consist of many iterations before determining the optimal training data set to use.
MSET has its origins in computer hardware failures monitoring. Sun Microsystems have been were using it back in the late 1990’s-early 2000’s to monitor and detect for component failures in their servers. Since then MSET has been widely used in power generation plants, airplanes, space travel, Disney uses it for equipment failures, and in more recent times has been extensively used in IOT environments with the anomaly detection focused on signal anomalies.
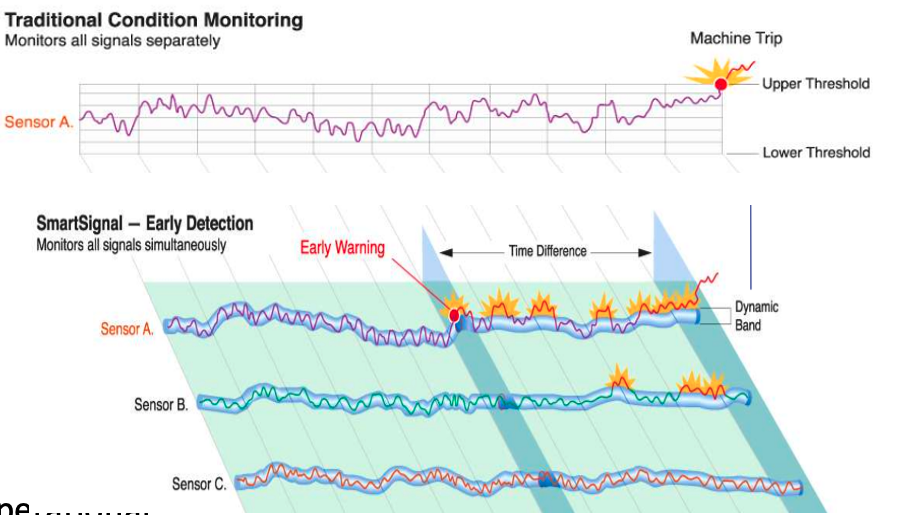
How does MSET work in Oracle 21c?
An important point to note before we start is, you can use MSET on your typical business data and other data stored in the database. It isn’t just for sensor, IOT, etc data mentioned above and can be used in many different business scenarios.
The first step you need to do is to create the time series data. This can be easily done using a view, but a Very important component is the Time attribute needs to be a DATE format. Additional attributes can be numeric data and these will be used as input to the algorithm for model creation.
-- Create training data set for MSET CREATE OR REPLACE VIEW mset_train_data AS SELECT time_id, sum(quantity_sold) quantity, sum(amount_sold) amount FROM (SELECT * FROM sh.sales WHERE time_id <= '30-DEC-99’) GROUP BY time_id ORDER BY time_id;
The example code above uses the SH schema data, and aggregates the data based on the TIME_ID attribute. This attribute is a DATE data type. The second import part of preparing and formatting the data is Ordering of the data. The ORDER BY is necessary to ensure the data is fed into or processed by the algorithm in the correct time series order.
The next step involves defining the parameters/hyper-parameters for the algorithm. All algorithms come with a set of default values, and in most cases these are suffice for your needs. In that case, you only need to define the Algorithm Name and to turn on Automatic Data Preparation. The following example illustrates this and also includes examples of setting some of the typical parameters for the algorithm.
BEGIN DELETE FROM mset_settings; -- Select MSET-SPRT as the algorithm INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.algo_name, dbms_data_mining.algo_mset_sprt); -- Turn on automatic data preparation INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.prep_auto, dbms_data_mining.prep_auto_on); -- Set alert count INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_COUNT, 3); -- Set alert window INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALERT_WINDOW, 5); -- Set alpha INSERT INTO mset_sh_settings (setting_name, setting_value) VALUES(dbms_data_mining.MSET_ALPHA_PROB, 0.1); COMMIT; END;
To create the MSET model using the MST_TRAIN_DATA view created above, we can run:
BEGIN -- DBMS_DATA_MINING.DROP_MODEL(MSET_MODEL'); DBMS_DATA_MINING.CREATE_MODEL ( model_name => 'MSET_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'MSET_TRAIN_DATA', case_id_column_name => 'TIME_ID', target_column_name => '', settings_table_name => 'MSET_SETTINGS'); END;
The SELECT statement below is an example of how to call and run the MSET model to label the data to find anomalies. The PREDICTION function will return a values of 0 (zero) or 1 (one) to indicate the predicted values. If the predicted values is 0 (zero) the MSET model has predicted the input record to be anomalous, where as a predicted values of 1 (one) indicates the value is typical. This can be used to filter out the records/data you will want to investigate in more detail.
-- display all dates with Anomalies SELECT time_id, pred FROM (SELECT time_id, prediction(mset_sh_model using *) over (ORDER BY time_id) pred FROM mset_test_data) WHERE pred = 0;
Storing and processing Unicode characters in Oracle
Unicode is a computing industry standard for the consistent encoding, representation, and handling of text expressed in most of the world’s writing systems (Wikipedia). The standard is maintained by the Unicode Consortium, and contains over 137,994 characters (137,766 graphic characters, 163 format characters and 65 control characters).
The NVARCHAR2 is Unicode data type that can store Unicode characters in an Oracle Database. The character set of the NVARCHAR2 is national character set specified at the database creation time. Use the following to determine the national character set for your database.
SELECT * FROM nls_database_parameters WHERE PARAMETER = 'NLS_NCHAR_CHARACTERSET';
For my database I’m using an Oracle Autonomous Database. This query returns the character set AL16UTF16. This character set encodes Unicode data in the UTF-16 encoding and uses 2 bytes to store a character.
When creating an attribute with this data type, the size value (max 4000) determines the number of characters allowed. The actual size of the attribute will be double.
Let’s setup some data to test this data type.
CREATE TABLE demo_nvarchar2 (
attribute_name NVARCHAR2(100));
INSERT INTO demo_nvarchar2
VALUES ('This is a test for nvarchar2');
The string is 28 characters long. We can use the DUMP function to see the details of what is actually stored.
SELECT attribute_name, DUMP(attribute_name,1016) FROM demo_nvarchar2;
The DUMP function returns a VARCHAR2 value that contains the datatype code, the length in bytes, and the internal representation of a value.

You can see the difference in the storage size of the NVARCHAR2 and the VARCHAR2 attributes.
Valid values for the return_format are 8, 10, 16, 17, 1008, 1010, 1016 and 1017. These values are assigned the following meanings:
8 – octal notation
10 – decimal notation
16 – hexadecimal notation
17 – single characters
1008 – octal notation with the character set name
1010 – decimal notation with the character set name
1016 – hexadecimal notation with the character set name
1017 – single characters with the character set name
The returned value from the DUMP function gives the internal data type representation. The following table lists the various codes and their description.
| Code | Data Type |
|---|---|
| 1 | VARCHAR2(size [BYTE | CHAR]) |
| 1 | NVARCHAR2(size) |
| 2 | NUMBER[(precision [, scale]]) |
| 8 | LONG |
| 12 | DATE |
| 21 | BINARY_FLOAT |
| 22 | BINARY_DOUBLE |
| 23 | RAW(size) |
| 24 | LONG RAW |
| 69 | ROWID |
| 96 | CHAR [(size [BYTE | CHAR])] |
| 96 | NCHAR[(size)] |
| 112 | CLOB |
| 112 | NCLOB |
| 113 | BLOB |
| 114 | BFILE |
| 180 | TIMESTAMP [(fractional_seconds)] |
| 181 | TIMESTAMP [(fractional_seconds)] WITH TIME ZONE |
| 182 | INTERVAL YEAR [(year_precision)] TO MONTH |
| 183 | INTERVAL DAY [(day_precision)] TO SECOND[(fractional_seconds)] |
| 208 | UROWID [(size)] |
| 231 | TIMESTAMP [(fractional_seconds)] WITH LOCAL TIMEZONE |
HiveMall: Transform Categorical features to Numerical
HiveMall is a machine learning library that sits on top of Hive and provides SQL interface to wide range of data preparation and machine learning algorithms.
A common task faced for many machine learning exercises is to convert the data from the format it is captured in (raw data) into a format that is required by the machine learning algorithms. Most ML tools will either have functionality built into the algorithms to do this automatically or will provide functions to allow you to manage this process yourself.
In HiveMall we have the ‘quantified_features’ function and is used for transforming values of non-number columns to indexed numbers, but it does have some unusual but useful features.
In this example I’ll use the titanic data set to illustrate the usage of this feature.

Here we have a mixture of features with categorical and numerical.
select
quantified_features(
${output_row}, PassengerId, Survived, Pclass, Sex, Age, SibSp, Parch, Fare, Cabin, Embarked) as features
from (
select * from titanic
order by Passengerid asc
) t
limit 5;and we get the following output
[1.0,0.0,0.0,3.0,0.0,22.0,1.0,0.0,7.25,0.0,1.0]
[2.0,1.0,1.0,1.0,1.0,38.0,1.0,0.0,71.2833,1.0,2.0]
[3.0,1.0,1.0,3.0,1.0,26.0,0.0,0.0,7.9250,0.0,1.0]
[4.0,1.0,1.0,1.0,1.0,35.0,1.0,0.0,53.1,3.0,1.0]
[5.0,1.0,0.0,3.0,0.0,35.0,0.0,0.0,8.05,0.0,1.0]The ordering within the attributes is important, and some thinking is needed if there is a defined order and you want this reflected in the outputs of the transformed features
If you are a numeric field that you want treated as a categorical, and transformed, you can cast it into a string
e.g.
cast(SibSp as string)Time Series Forecasting in Oracle – Part 2
This is the second part about time-series data modeling using Oracle. Check out the first part here.
In this post I will take a time-series data set and using the in-database time-series functions model the data, that in turn can be used for predicting future values and trends.
The data set used in these examples is the Rossmann Store Sales data set. It is available on Kaggle and was used in one of their competitions.
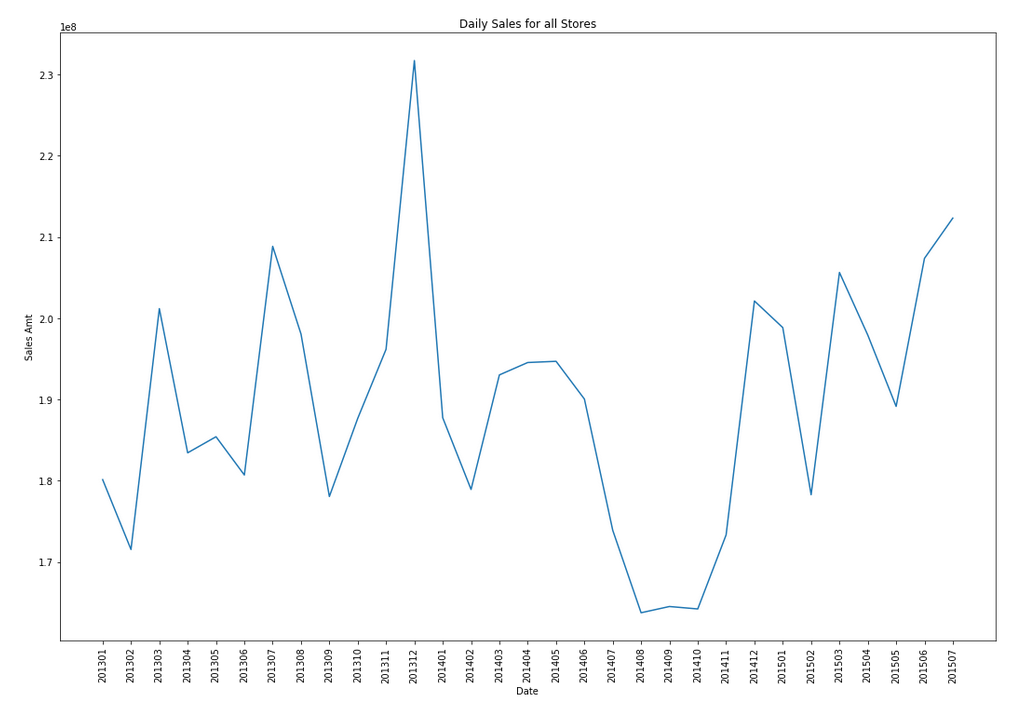
Let’s start by aggregating the data to monthly level. We get.
Data Set-up
Although not strictly necessary, but it can be useful to create a subset of your time-series data to only contain the time related attribute and the attribute containing the data to model. When working with time-series data, the exponential smoothing function expects the time attribute to be of DATE data type. In most cases it does. When it is a DATE, the function will know how to process this and all you need to do is to tell the function the interval.
A view is created to contain the monthly aggregated data.
-- Create input time series create or replace view demo_ts_data as select to_date(to_char(sales_date, 'MON-RRRR'),'MON-RRRR') sales_date, sum(sales_amt) sales_amt from demo_time_series group by to_char(sales_date, 'MON-RRRR') order by 1 asc;
Next a table is needed to contain the various settings for the exponential smoothing function.
CREATE TABLE demo_ts_settings(setting_name VARCHAR2(30),
setting_value VARCHAR2(128));
Some care is needed with selecting the parameters and their settings as not all combinations can be used.
Example 1 – Holt-Winters
The first example is to create a Holt-Winters time-series model for hour data set. For this we need to set the parameter to include defining the algorithm name, the specific time-series model to use (exsm_holt), the type/size of interval (monthly) and the number of predictions to make into the future, pass the last data point.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- set ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_holt);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
commit;
END;
Now we can call the function, generate the model and produce the predicted values.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
When the model is created a number of data dictionary views are populated with model details and some addition views are created specific to the model. One such view commences with DM$VP. Views commencing with this contain the predicted values for our time-series model. You need to append the name of the model created, in our example DEMO_TS_MODEL.
-- get predictions select case_id, value, prediction, lower, upper from DM$VPDEMO_TS_MODEL order by case_id;
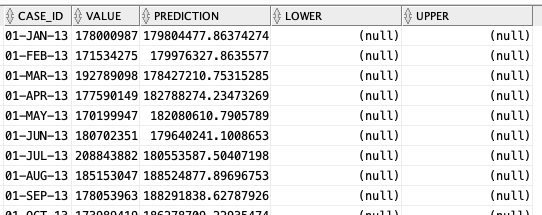
When we plot this data we get.
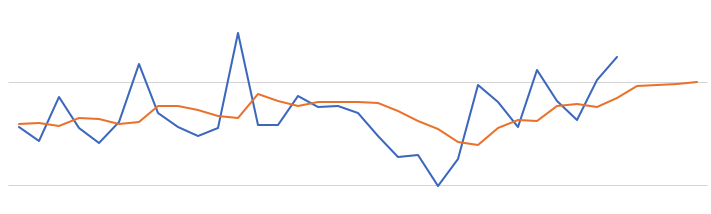
The blue line contains the original data values and the red line contains the predicted values. The predictions are very similar to those produced using Holt-Winters in Python.
Example 2 – Holt-Winters including Seasonality
The previous example didn’t really include seasonality into the model and predictions. In this example we introduce seasonality to allow the model to pick up any trends in the data based on a defined period.
For this example we will change the model name to HW_ADDSEA, and the season size to 5 units. A data set with a longer time period would illustrate the different seasons better but this gives you an idea.
BEGIN
-- delete previous setttings
delete from demo_ts_settings;
-- select ESM as the algorithm
insert into demo_ts_settings
values (dbms_data_mining.algo_name,
dbms_data_mining.algo_exponential_smoothing);
-- set ESM model to be Holt-Winters Seasonal Adjusted
insert into demo_ts_settings
values (dbms_data_mining.exsm_model,
dbms_data_mining.exsm_HW_ADDSEA);
-- set interval to be month
insert into demo_ts_settings
values (dbms_data_mining.exsm_interval,
dbms_data_mining.exsm_interval_month);
-- set prediction to 4 steps ahead
insert into demo_ts_settings
values (dbms_data_mining.exsm_prediction_step,
'4');
-- set seasonal cycle to be 5 quarters
insert into demo_ts_settings
values (dbms_data_mining.exsm_seasonality,
'5');
commit;
END;
We need to re-run the creation of the model and produce the predicted values. This code is unchanged from the previous example.
BEGIN
-- delete the previous model with the same name
BEGIN
dbms_data_mining.drop_model('DEMO_TS_MODEL');
EXCEPTION
WHEN others THEN null;
END;
dbms_data_mining.create_model(model_name => 'DEMO_TS_MODEL',
mining_function => 'TIME_SERIES',
data_table_name => 'DEMO_TS_DATA',
case_id_column_name => 'SALES_DATE',
target_column_name => 'SALES_AMT',
settings_table_name => 'DEMO_TS_SETTINGS');
END;
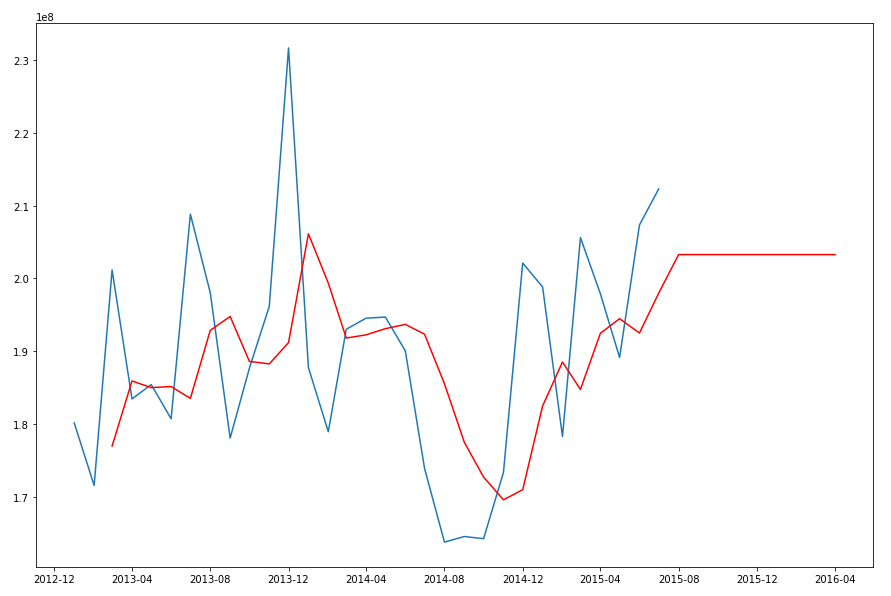
When we re-query the DM$VPDEMO_TS_MODEL we get the new values. When plotted we get.
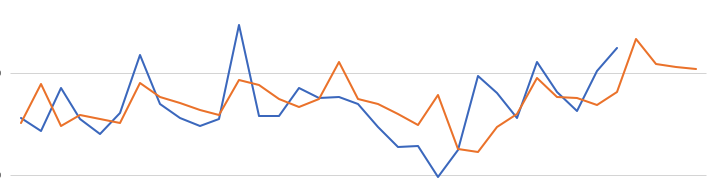
The blue line contains the original data values and the red line contains the predicted values.
Comparing this chart to the chart from the first example we can see there are some important differences between them. These differences are particularly evident in the second half of the chart, on the right hand side. We get to see there is a clearer dip in the predicted data. This mirrors the real data values better. We also see better predictions as the time line moves to the end.
When performing time-series analysis you really need to spend some time exploring the data, to understand what is happening, visualizing the data, seeing if you can identify any patterns, before moving onto using the different models. Similarly you will need to explore the various time-series models available and the parameters, to see what works for your data and follow the patterns in your data. There is no magic solution in this case.
Moving Average in SQL (and beyond)
A very common analytics technique for financial and other data is to calculate the moving average. This can allow you to see a different type of pattern in your data that may not is evident from examining the original data.
But how can we calculate the moving average in SQL?
Well, there isn’t a function to do it, but we can use the windowing feature of analytical SQL to do so. The following example was created in an Oracle Database but the same SQL (more or less) will work with most other SQL databases.
SELECT month,
SUM(amount) AS month_amount,
AVG(SUM(amount)) OVER
(ORDER BY month ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS moving_average
FROM sales
GROUP BY month
ORDER BY month;
This gives us the following with the moving average calculated based on the current value and the three preceding values, if they exist.
MONTH MONTH_AMOUNT MOVING_AVERAGE
---------- ------------ --------------
1 58704.52 58704.52
2 28289.3 43496.91
3 20167.83 35720.55
4 50082.9 39311.1375
5 17212.66 28938.1725
6 31128.92 29648.0775
7 78299.47 44180.9875
8 42869.64 42377.6725
9 35299.22 46899.3125
10 43028.38 49874.1775
11 26053.46 36812.675
12 20067.28 31112.085
In some analytic languages and databases, they have included a moving average function. For example using HiveMall on Hive we have.
SELECT moving_avg(x, 3) FROM (SELECT explode(array(1.0,2.0,3.0,4.0,5.0,6.0,7.0)) as x) series;If you are using Python, there is an inbuilt function in Pandas.
rolmean4 = timeseries.rolling(window = 4).mean()
- ← Previous
- 1
- 2
- 3
- …
- 5
- Next →

You must be logged in to post a comment.